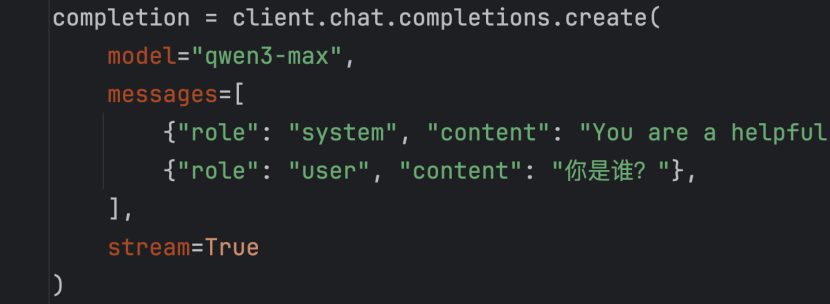
1、OpenAI库的基础使用:
(1)role角色:
①system角色:设定助手的整体行为、角色和规则,为对话提供上下文框架,是全局的背景设定,影响后续所有交互
②assistant角色:代表AI助手的回答,可以在代码中认为设定
③user角色:代表用户,发送问题、指令或需求
(2)OpenAI库的流式输出:stream=True;for chunk in response:
if chunk.choices0.delta.content:
print(chunk.choices0.delta.content,end="",flush=True)
(3)附带历史消息的传入:在messages的list内,组织历史消息提供给模型(json.dumps(字典或列表);json.loads(将json字符串转换为python))
2、提示词工程:
(1)应用场景:用户意图和模型之间的桥梁
①任务定义模糊性
②输出格式控制
③领域知识适配
④偏见与安全性控制
⑤复杂任务拆解
(2)技术挑战
(3)实际价值
①降低模型微调成本
②提升用户体验
③工程拓展性
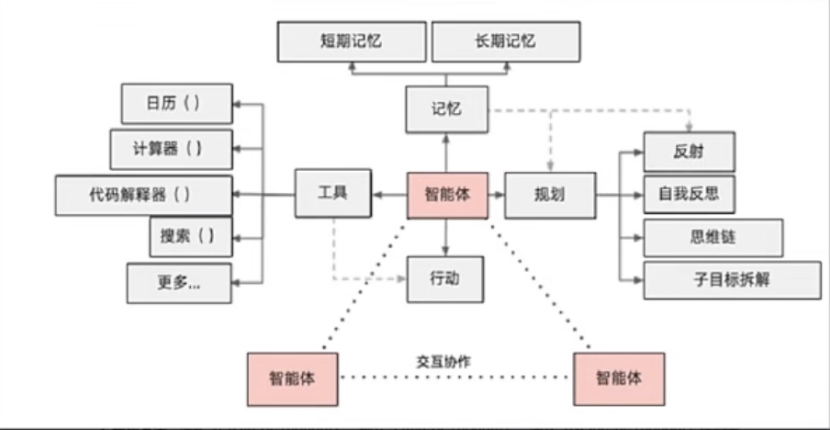
3、Agent搭建=大语言模型(大脑)+工具集(手脚)+决策逻辑(思维)
(1)ReAct范式(Reasoning+acting)
①思考Reasoning:分析问题,判断现有信息是否足够,明确下一步
②行动Action:执行思考阶段策略
③观察Observation:获取行动结构,提取有效信息
(2)middleware中间件
①日志记录、分析、调试;转换提示词、工具选择;重试、备用、提前终止等逻辑控制;安全防护、个人身份检测

(3)搭建部分核心要素(稳定性、效率、可拓展性):
①定义任务
②选择模型
③设计工作流
④集成工具
⑤处理数据
(4)主流框架:LangChain、AutoGpt、Hugging Face、Transformers Agents
(5)核心定义和能力:通过感知环境、自主决策、调用工具完成复杂任务的智能体
①任务拆解
②工具调用
③记忆与状态管理
④自我迭代
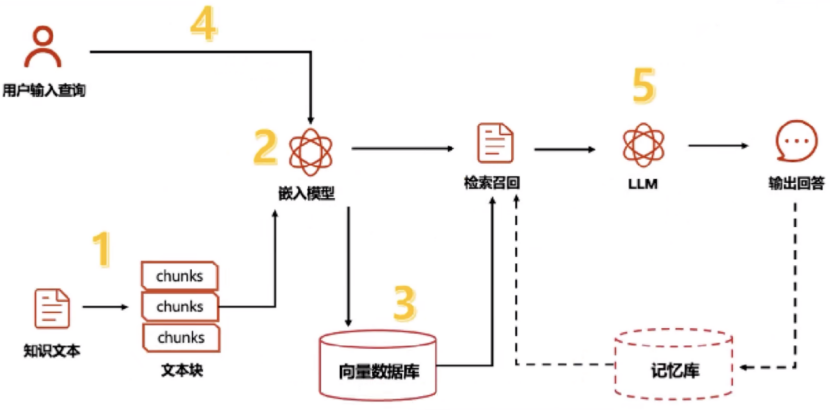
4、RAG流程(检索增强生成):检索和生成
(1)检索阶段:用户输入处理、文档检索
(2)增强阶段:文档处理、信息整合
(3)生成阶段:生成回答、后处理
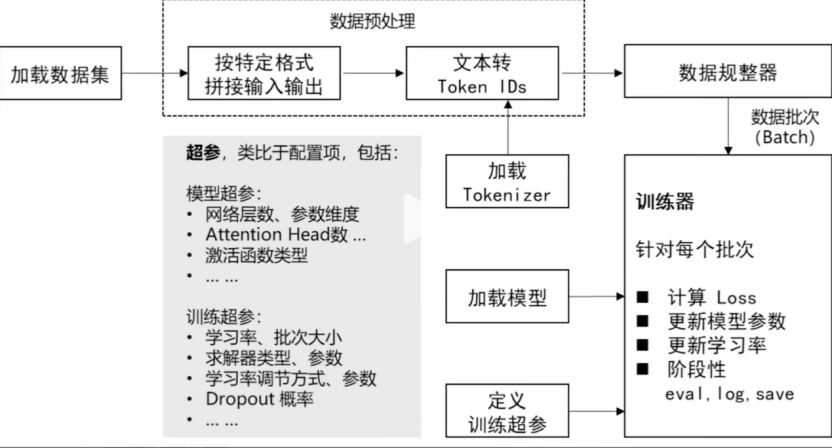
5、大模型微调流程(在预训练好的模型基础上,针对特定任务或领域的数据进行进一步训练):
(1)确定任务目标
(2)准备数据
(3)数据预处理
(4)选择预训练模型
(5)调整模型结构
(6)设置训练参数
(7)训练过程
(8)评估与验证
①明确评估目标
②技术指标评估
③业务场景适配
④效率稳定性
⑤长期监控和迭代
(9)部署与应用
6、生成内容合规性(技术、流程和制度):
(1)技术层面:训练模型与部署关键控制
①数据清洗与预过滤
②RLHF(人类反馈强化学习)
③合规性微调
④实时内容过滤
⑤输出概率阈值控制
(2)流程层面:构建审核闭环
①多级审核机制
②可解释性工具
③版本灰度发布
(3)制度层面:合规体系搭建
①法规映射
②权限分级控制
③日志溯源与问责
④第三方审计
(4)前沿技术补充:
①宪法式AI
②数字水印
7、利用大模型实现多模态任务(处理多种类型数据)
(1)核心思路:多模态融合与联合建模
①注意力机制(视觉编码器、文字编码器)处理视频中的时序信息
(2)技术实现路径
①统一编码器
②模态适配器
③预训练-微调犯事
④提示学习
(3)关键技术与解决方案
①模态对齐不足
②长视频建模困难
③数据稀缺
(4)实例参考
(5)未来方向
8、向量数据库
(1)本质差异:数据结构与处理能力的适配性
①数据结构兼容性:传统数据库擅长处理结构化数据,而大模型应用中大量涉及非结构化数据(文本、图像、音频、视频),向量数据库通过Embedding技术将非结构化数据转化为高纬向量,直接储存向量表示,天然适配AI模型的数据处理需求
②相似性搜索的高效性
1)欧几里得距离
2)余弦相似度
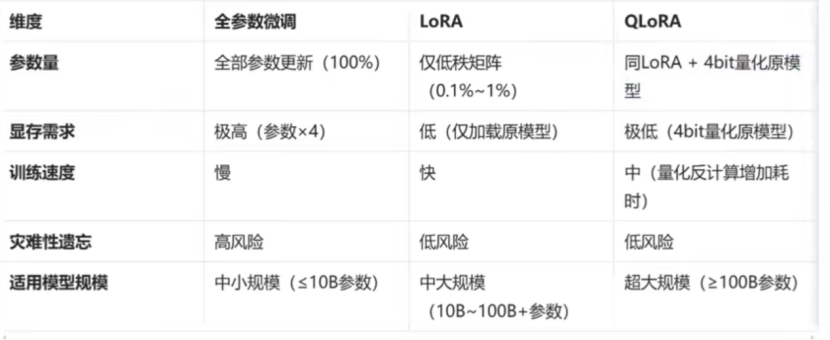
3)QLoRA量化
(2)技术优势:性能与扩展性
(3)应用场景与大模型落地的关键支撑
(4)行业趋势与生态成熟度
9、LangChain框架:
(1)定义;开源的开发框架,帮助开发者快速构建LLM应用程序,通过模块化设计简化了大模型交互的复杂性,支持灵活集成外部工具和数据源,使开发者能够快速实现复杂的AI应用逻辑
(2)核心功能
①优化提示词(Prompts)
②模型集成(Models)
③构建智能体(Agent)
④模块化组件
⑤管理和分析各类文档(Indexes)
⑥链式调用(Chains)
⑦记忆机制(History)
⑧代理与工具
⑨数据增强
(3)典型运用场景
①智能问答系统
②对话机器人
③文档分析
④自动化流程
⑤代码生成
(4)核心优势
①模块化设计
②灵活性
③拓展性
④开发效率
10、模型蒸馏和模型量化:
(1)模型蒸馏:将大型复杂知识迁移到轻量小模型,核心使让小模型模仿大模型
①核心原理:软标签;温度参数;损失函数设计
(2)模型量化:将模型权重或激活值高精度转为低精度,降低计算和存储开销
①核心原理:动态范围校准;量化感知训练;后训练量化
11、意图识别:
(1)定义:从用户输入的文本中识别其背后的目标或意图
(2)核心任务和关键难点:
①分类问题:将用户输入映射到与定义的意图类别
②关键难点:语义多样性;短文本信息稀疏
(3)大模型意图识别的技术流程
①数据准备与增强(模型标注,数据增强)
②模型选型与训练
③部署与优化
12、大模型epoch和学习率
(1)epoch:模型遍历全体训练数据的完整周期,相当于"学习资料通读次数"
学习率:参数更新的步长幅度,控制模型"学习速度"
(2)核心关系:
①学习率过大:震荡不收敛,错过最优解
②学习率过小:收敛过慢,原地踏步
③echop:欠拟合或过拟合
13、vllm推理加速:
(1)核心技术点:内存优化(将key/value缓存分块)、连续批处理、内存池(申请大块显存池,循环利用)、并行计算、调度策略
(2)项目价值:突出延迟、吞吐量、节省成本
14、大模型幻觉问题:
(1)定义:模型生成不准确或虚构的信息(训练数据噪声、过拟合或缺乏领域知识)
(2)类型划分:事实性幻觉、逻辑性幻觉、指令跟随偏差
(3)解决方案:RAG增强,知识检索增强;添加规则引擎,过滤矛盾表述;强化SFT数据中的指令对齐能力
(4)业务影响:降低法律风险;减少人工审核成本
15、拟合和欠拟合
(1)定义:过拟合使模型在训练数据上表现极佳,但在新数据上表现能力欠佳。本质是模型过度学习了训练数据中的噪声和细节,导致泛化能力差
欠拟合是指模型在训练和测试数据上表现都不佳,无法捕捉数据中的基本模式。通常因模型过于简单或导致训练不足
(2)原因分析:
①过拟合:模型复杂度高;训练数据不足或噪声多;训练时间过长;特征冗余或特征过多
②欠拟合:模型复杂多过低;特征不足或者缺乏代表性;训练不充分
(3)解决方法:
①过拟合:增加数据量;降低模型复杂度;正则化技术;早停法;交叉验证
②欠拟合:增加模型复杂度;特征工程;减少正则化强度;延长训练时间
16、微调时模型遗忘:
(1)数据层面:混合原始任务数据与新任务数据
(2)训练策略:正则化约束/学习率控制/渐进式学习
(3)多任务学习/Adapter模块/模型融合
(4)评估监控:新旧任务指标同步验证
17、Transformer多头注意力机制:
(1)基本结构:允许模型同时关注不同位置信息
①分头策略设计
②矩阵变换实现
③多视角特征捕获
④融合正则化
⑤工程优化
18、prefix LM和Causal LM差异:
(1)prefix LM:支持多轮上下文依赖,避免重复提问或信息遗漏,将历史对话作为前缀,生成回复时可见上下文
(2)Causal LM:无法直接确定历史对话信息,依赖外部的状态管理。无需上下文干扰,专注生成目标内容
19、梯度消失和爆炸的解决:
(1)问题本质:反向传播链式发则;梯度指数级变化;深层参数冻结
(2)解决纬度:
①模型架构调整:残差连接;Pre-LayerNorm;门控机制;项目验证数据
②优化策略改进:自适应优化器;梯度裁剪;学习率调整;项目验证效果
③训练技巧应用:混合精度训练;梯度累积;参数初始化;训练效率提升
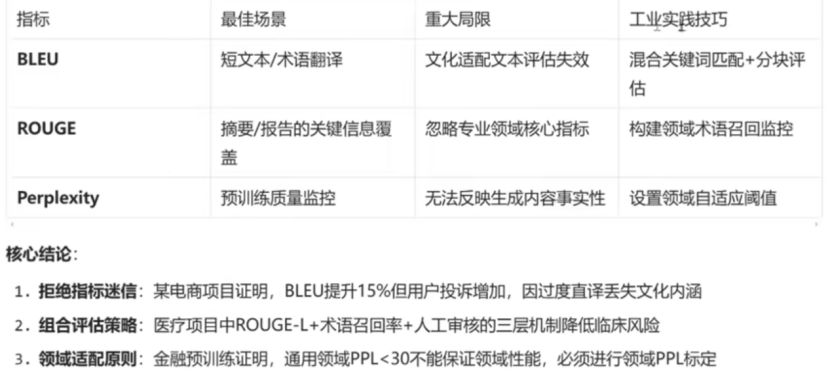
20、大模型评估指标:BLEU、ROUGE;Perplexity
(1)BLEU:基于精度的机器翻译的评估,侧重译文与参考译文的词汇匹配
(2)ROUGE:基于召回率的文本生成评估,关注与关键信息覆盖率
(3)Perplexity:语言模型内在评估,衡量概率分布预测能力