
🎬 个人主页 :艾莉丝努力练剑
❄专栏传送门 :《C语言》《数据结构与算法》《C/C++干货分享&学习过程记录》
《Linux操作系统编程详解》《笔试/面试常见算法:从基础到进阶》《Python干货分享》
⭐️为天地立心,为生民立命,为往圣继绝学,为万世开太平
🎬 艾莉丝的简介:

文章目录
- 前言
- [1 ~> 认知的起点:被"降维打击"的共享资源](#1 ~> 认知的起点:被“降维打击”的共享资源)
-
- [1.1 为什么会出现"负数"?------ 拆解非原子性的灾难在](#1.1 为什么会出现“负数”?—— 拆解非原子性的灾难在)
- [1.2 "滞后写回"导致的降维打击:](#1.2 “滞后写回”导致的降维打击:)
- [2 ~> 锁的哲学悖论:申请的是"执行许可"](#2 ~> 锁的哲学悖论:申请的是“执行许可”)
- [3 ~> 深度解析:原子性(Atomicity)的硬件根基](#3 ~> 深度解析:原子性(Atomicity)的硬件根基)
-
- [3.1 锁的底层推演(伪代码还原)](#3.1 锁的底层推演(伪代码还原))
- [3.2 深度剖析一下](#3.2 深度剖析一下)
- [4 ~> 实践:Mutex 操作规范与约定](#4 ~> 实践:Mutex 操作规范与约定)
-
- [4.1 代码验证](#4.1 代码验证)
- [4.2 架构师的避坑指南](#4.2 架构师的避坑指南)
- [5 ~> 性能权衡:临界区粒度的艺术](#5 ~> 性能权衡:临界区粒度的艺术)
- [6 ~> 干货整理](#6 ~> 干货整理)
- [7 ~> 线程互斥收尾](#7 ~> 线程互斥收尾)
-
- [7.1 互斥量的封装](#7.1 互斥量的封装)
- [7.2 补充](#7.2 补充)
-
- [7.2.1 互斥量(Mutex)的底层封装](#7.2.1 互斥量(Mutex)的底层封装)
- [7.2.2 C++11 标准库互斥量的应用](#7.2.2 C++11 标准库互斥量的应用)
- [7.2.3 RAII 风格锁管理:LockGuard](#7.2.3 RAII 风格锁管理:LockGuard)
- [7.2.4 临界区逻辑与线程睡眠](#7.2.4 临界区逻辑与线程睡眠)
- [7.2.5 补充:关于"锁的理论收尾"](#7.2.5 补充:关于“锁的理论收尾”)
- 结尾
前言
在系统级编程的宏大架构中,并发往往伴随着最隐蔽、最致命的数据灾难。多线程虽然能通过并行计算极大提升程序的吞吐量,但如果缺乏严谨的同步与互斥机制,原本高效的 C/C++ 代码就会沦为制造薛定谔 Bug 的温床。今天,我们将穿透高级语言的迷雾,直击 CPU 体系结构与硬件上下文,深度剖析 Linux 线程互斥与锁的本质。
1 ~> 认知的起点:被"降维打击"的共享资源
在多线程环境中,线程默认会共享进程的文件描 述符表以及全局变量等资源 。这种物理上的共享性,正是导致并发访问出现线程安全问题的根源。
以经典的"售票系统"为例,假设我们有 1000 张票,代码逻辑是 if (tickets > 0) { usleep(1000); tickets--; }。运行结果往往令人大跌眼镜:票数不仅会错乱,甚至会被抢到负数(如 -1、-2) 。
1.1 为什么会出现"负数"?------ 拆解非原子性的灾难在
C/C++ 中看似极简的一行 tickets--,在底层汇编(x86 架构)实际上会被拆解为三个不可分割的步骤:
- 1、Load (读取) :
mov eax, [tickets],将内存中的全局变量加载到 CPU 的私有寄存器(如eax)中 。 - 2、Update (更新) :
sub eax, 1,在 CPU 内部完成减法计算 。 - 3、Store (写回) :
mov [tickets], eax,将计算后的新值写回主存 。
1.2 "滞后写回"导致的降维打击:
全局变量存在于共享的数据段,而寄存器和栈是每个线程私有的硬件上下文 。假设当前 tickets = 100:
- 线程 A 执行了 Load 操作,其私有寄存器
eax拿到了100。就在此时,时钟中断到来,线程 A 被 OS 强行剥夺 CPU,进入等待队列。OS 会保存 A 的硬件上下文(记住它手里捏着 100) 。 - 线程 B 被调度上台,它执行极快,一口气完成了 Load-Update-Store,将内存中的票数改为了
99。随后其他线程继续疯狂抢票,将内存中的票数减到了1。 - 此时,线程 A 恢复执行!它根本不知道外界发生了什么,依然从上次中断的地方继续:
100 - 1 = 99,然后执行 Store 操作,将99强行覆盖回内存 。 - 结局:线程 B 和其他线程辛辛苦苦扣减的票数瞬间蒸发,已经被卖出的 98 张票在内存中"诡异复活" 。
为了防止这种微观层面的数据篡改,我们必须将被多线程并发访问的共享资源保护起来,这部分被保护的资源被称为临界资源 。而代码中访问这些资源的那段逻辑,则被称为临界区。
2 ~> 锁的哲学悖论:申请的是"执行许可"
要保护临界区,我们需要引入"互斥"(Mutex)机制。互斥的理念非常霸道:它保证在任何时刻,有且只有一个执行流能够进入临界区,对其他线程形成一堵物理高墙 。
但在实现这把锁时,我们会遇到一个极致的逻辑悖论:
大家都必须先去申请锁,前提是所有线程都必须先"看到"同一把锁 。这意味着,锁本身也是一个被多线程共享的临界资源 !
既然锁是临界资源,那"申请锁"这个动作本身由谁来保护?如果申请锁的操作也不是原子的,那么多线程并发申请锁时就会直接导致锁机制崩溃。因此,申请锁的过程,必须是原子的 。在这个意义上,申请互斥锁的本质,就是在向系统申请唯一的**"执行许可"** 。
3 ~> 深度解析:原子性(Atomicity)的硬件根基
在并发语境下,原子性意味着一个操作不会被任何调度机制打断,该操作只有两态:要么彻底完成,要么完全未完成 。
为了打破上述的"锁悖论",现代 CPU 直接在硬件层面提供了降维打击般的支持。大部分体系结构都提供了一条特殊的汇编指令:swap 或 exchange(如 x86 的 xchgb) 。
这条指令的作用是:一步到位地将内存单元与 CPU 寄存器的数据进行交换,且在硬件总线级别保证不可中断 。
3.1 锁的底层推演(伪代码还原)
假设内存中有一把锁 mutex = 1(1 代表锁可用,0 代表锁被占用)。
bash
lock:
movb $0, %al ; 将线程私有寄存器 al 初始化为 0
xchgb %al, mutex ; 【神来之笔】:原子交换寄存器 al 和内存 mutex 的值
if (al 寄存器的内容 > 0) {
return 0; ; 加锁成功,进入临界区
} else {
挂起等待; ; 加锁失败,让出 CPU
goto lock;
}3.2 深度剖析一下
1、线程 A 执行 xchgb 后,内存的 mutex 变成了 0,而 A 的私有寄存器 al 拿到了 1。
2、exchange 指令的绝妙之处在于:它以原子的方式,把一个共享的数据内容,变成了一个线程私有的内容!
3、此时线程 B 再来执行 xchgb,它只能用自己的 0 换回内存里的 0,从而陷入阻塞。只有当线程 A 退出临界区,执行 unlock(将内存 mutex 置回 1)时,其他线程才有机会抢到这把锁 。
注:在早期的单核时代,内核甚至可以通过直接"关闭时钟中断"来拒绝上下文切换 ,从而简单粗暴地实现系统级原子操作 。
4 ~> 实践:Mutex 操作规范与约定
4.1 代码验证
在 Linux 环境下使用 pthread 库进行系统编程时,锁就是一个类型为 pthread_mutex_t 的变量。
c
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
// 静态初始化全局锁
pthread_mutex_t glock = PTHREAD_MUTEX_INITIALIZER;
int tickets = 1000;
void* thread_run(void* arg) {
while (1) {
// 原子操作:申请执行许可,失败则当前线程挂起等待
pthread_mutex_lock(&glock);
// ============ 临界区开始 ============
if (tickets > 0) {
usleep(1000); // 模拟耗时操作,但在锁的保护下绝对安全
printf("Selling ticket: %d\n", tickets);
tickets--;
pthread_mutex_unlock(&glock); // 释放锁
} else {
pthread_mutex_unlock(&glock); // 异常或分支退出前,必须释放锁!
break;
}
// ============ 临界区结束 ============
}
return NULL;
}4.2 架构师的避坑指南
1、局部锁的生命周期 :全局锁可以使用宏静态分配 。但如果是局部锁,必须使用 pthread_mutex_init 动态分配,且在线程结束前严格调用 pthread_mutex_destroy 销毁以防止内存泄漏 。更重要的是,局部锁必须通过指针传参(如放入结构体中),确保所有线程竞争的是同一块物理内存上的锁 。
2、防君子不防小人 :加锁保护本质上是一种程序员之间的 "代码约定" 。如果线程 A 规规矩矩地调用 lock(),而线程 B 耍小聪明直接绕过锁去强改 tickets,互斥机制依然会土崩瓦解。不守规矩的并发不是在利用机制,而是在写 Bug 。
5 ~> 性能权衡:临界区粒度的艺术
并发编程的核心矛盾,就是用性能换取安全性 。
一旦加锁,原本并行的多线程就在临界区前变成了排队串行执行 ,这必然会引起效率的骤降 。因此,高级系统程序员必须恪守一条铁律:临界区粒度最小化 。
只将不可分割的核心共享资源访问逻辑(如 if (tickets > 0) 和 tickets--)放在锁的内部。任何耗时的非共享操作(如无关的局部变量计算、终端日志打印 printf 等)都应毫不留情地移出临界区。串行比重越小,多核 CPU 的并发天花板才越高。
6 ~> 干货整理
- "临界资源:多线程执行流被保护的共享的资源就叫做临界资源;临界区:每个线程内部,访问临界资源的代码,就叫做临界区。"
- "原子性:不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完成。"
- "大家都必须先申请的前提是必须先看到锁。所以锁本身也是临界资源!这就要求申请锁的过程,必须是原子的。申请锁的本质是在申请执行许可!"
- "
交换指令(exchange)的本质不就是:把一个共享的数据内容,变成一个线程私有的内容!" - "加锁保护,是一种约定,大家都要遵守!"
7 ~> 线程互斥收尾
7.1 互斥量的封装
- 我们写一个C++11的关于全局变量抢票demo
在代码中去除了冗余逻辑,并遵循了RAII风格锁管理,确保在异常或逻辑跳转时不会发生死锁。
7.1.1 抢票逻辑实现(Main.cc)
cpp
#include <iostream>
#include <thread>
#include <mutex>
#include <vector>
#include <chrono>
/**
* 全局共享资源
* (1)g_tickets: 剩余票数 [cite: 18, 41]
* (2)g_mtx: 保护票数的互斥锁 [cite: 20]
*/
int g_tickets = 1000;
std::mutex g_mtx;
/**
* 抢票执行函数
* @param thread_id 线程编号,用于区分不同线程输出 [cite: 22, 69]
*/
void grabTicket(int thread_id) {
while (true) {
// 临界区范围限制
{
// 使用 std::lock_guard 实现 RAII 风格加锁 [cite: 74, 84]
// 构造时自动加锁,作用域结束析构时自动解锁
std::lock_guard<std::mutex> lock(g_mtx);
if (g_tickets > 0) {
// 模拟业务处理耗时,增加并发冲突概率 [cite: 28, 77]
std::this_thread::sleep_for(std::chrono::milliseconds(1));
--g_tickets; [cite: 29, 78]
std::cout << "Thread [" << thread_id << "] grabbed a ticket. Remaining: "
<< g_tickets << std::endl; [cite: 30, 78]
} else {
// 票已抢完,退出循环 [cite: 83]
break;
}
}
// 适当在锁外短暂休眠,模拟线程处理其他逻辑,防止单线程"饥饿"式霸占锁
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
}
int main()
{
const int thread_count = 4; // 启动 4 个线程进行抢票 [cite: 40, 42]
std::vector<std::thread> workers;
// 创建线程 [cite: 41]
for (int i = 1; i <= thread_count; ++i) {
workers.emplace_back(grabTicket, i);
}
// 等待所有线程完成 [cite: 13]
for (auto& t : workers) {
t.join();
}
std::cout << "All tickets are sold out." << std::endl;
return 0;
}7.1.2 补充与严谨性检查
以下几点在实际工程中需要优化的细节:
(1) 锁的粒度控制 在你的代码片段中,std::cout 位于锁内。在 Linux 内核开发中,std::cout(底层调用 write 系统调用)是相对沉重的 I/O 操作。如果并发量极高,将打印操作放在锁内会导致严重的性能瓶颈。
- 优化建议:在高性能场景下,应先在锁内拷贝剩余票数,解锁后再进行打印。
(2) RAII 锁的禁用拷贝语义 正如文档中提到的"锁一般是禁止被拷贝的"。在 C++11 中,std::mutex 原生就通过以下方式禁用了拷贝,你在封装自己的 Mutex 类时也应效仿:
cpp
// 在你的 Mutex 类中加入:
Mutex(const Mutex&) = delete;
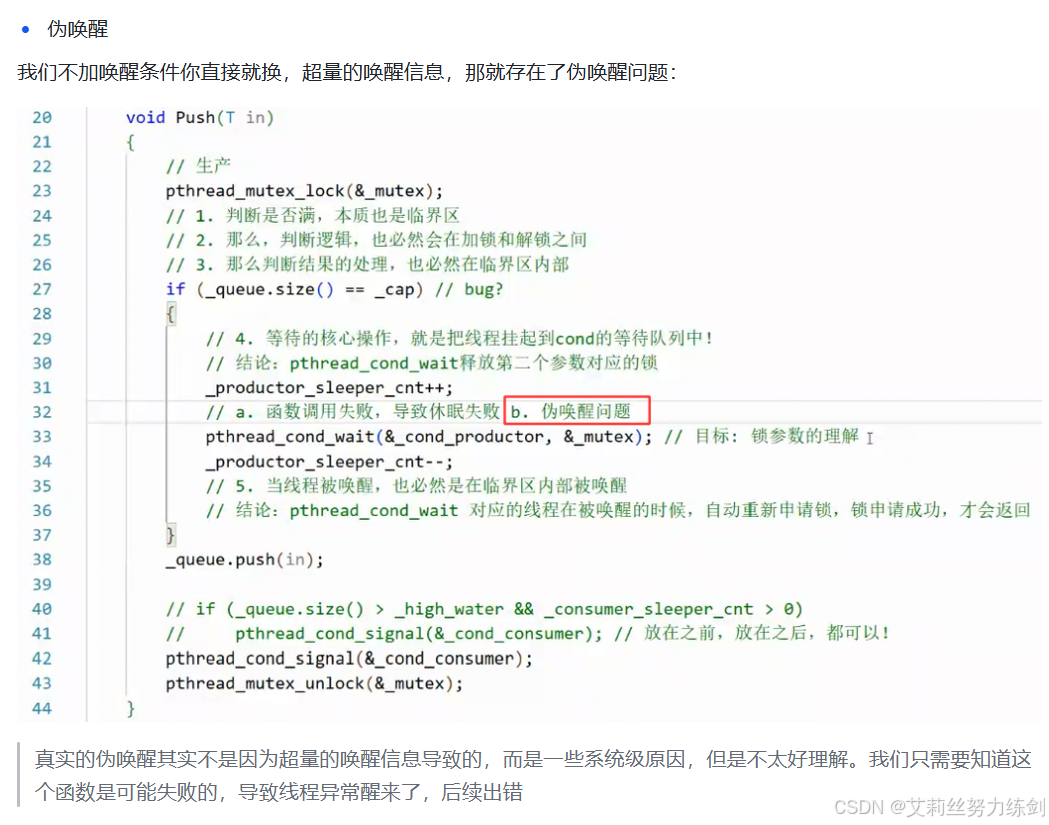
Mutex& operator=(const Mutex&) = delete;(3) 虚假唤醒与原子性 ,使用 if (tickets > 0) 进行判断。
1、因此,我们一般不喜欢写if判断,而是改成
while条件(也有判断能力),做了一次可靠性的保证。2、用
while条件语句会多次检查,增强了代码的健壮性。
这在简单的抢票场景中是足够的,但如果是更复杂的生产环境(涉及等待队列),通常需要配合 std::condition_variable 并使用 while 循环检查条件,以防止系统层面的 "虚假唤醒"。
-
我们下一篇博客会介绍"伪唤醒(虚假唤醒)",这里算是提前预告一下哇!
-
后面推荐用语言的锁。
7.1.3 自己来封装一个互斥量
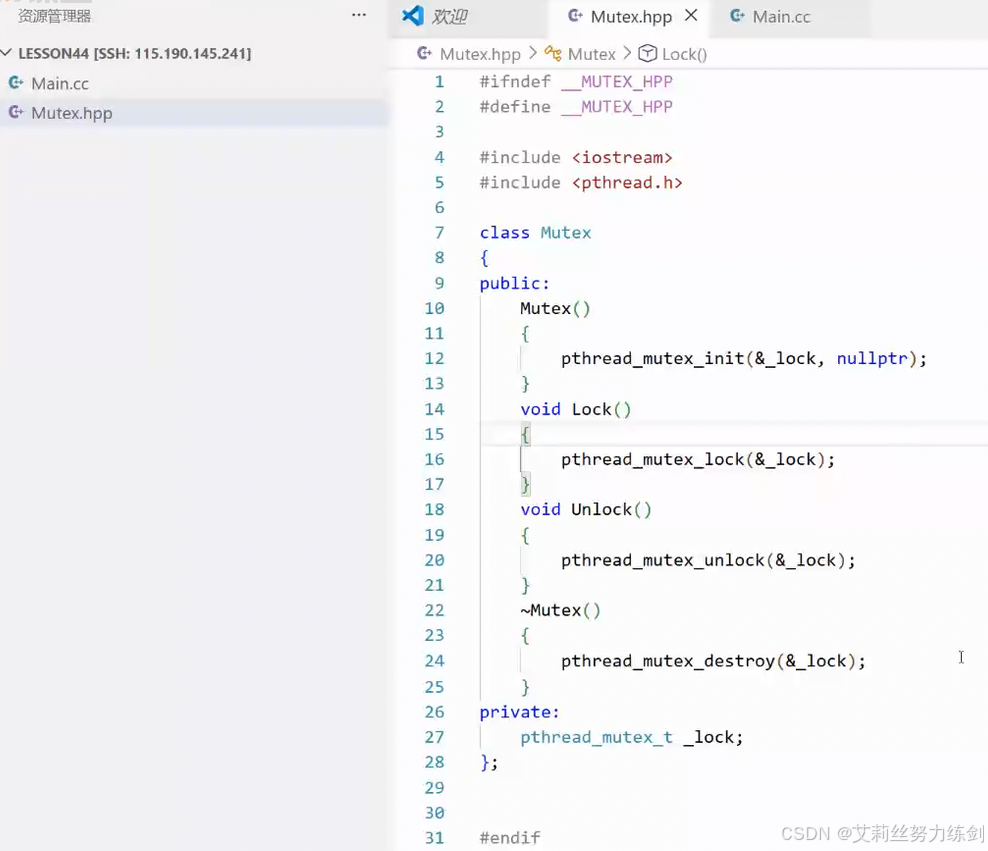
- 我们自己来封装一个互斥量
对锁进行完整的封装------特别简单:
加锁的逻辑,未来也可以自己封装一个。
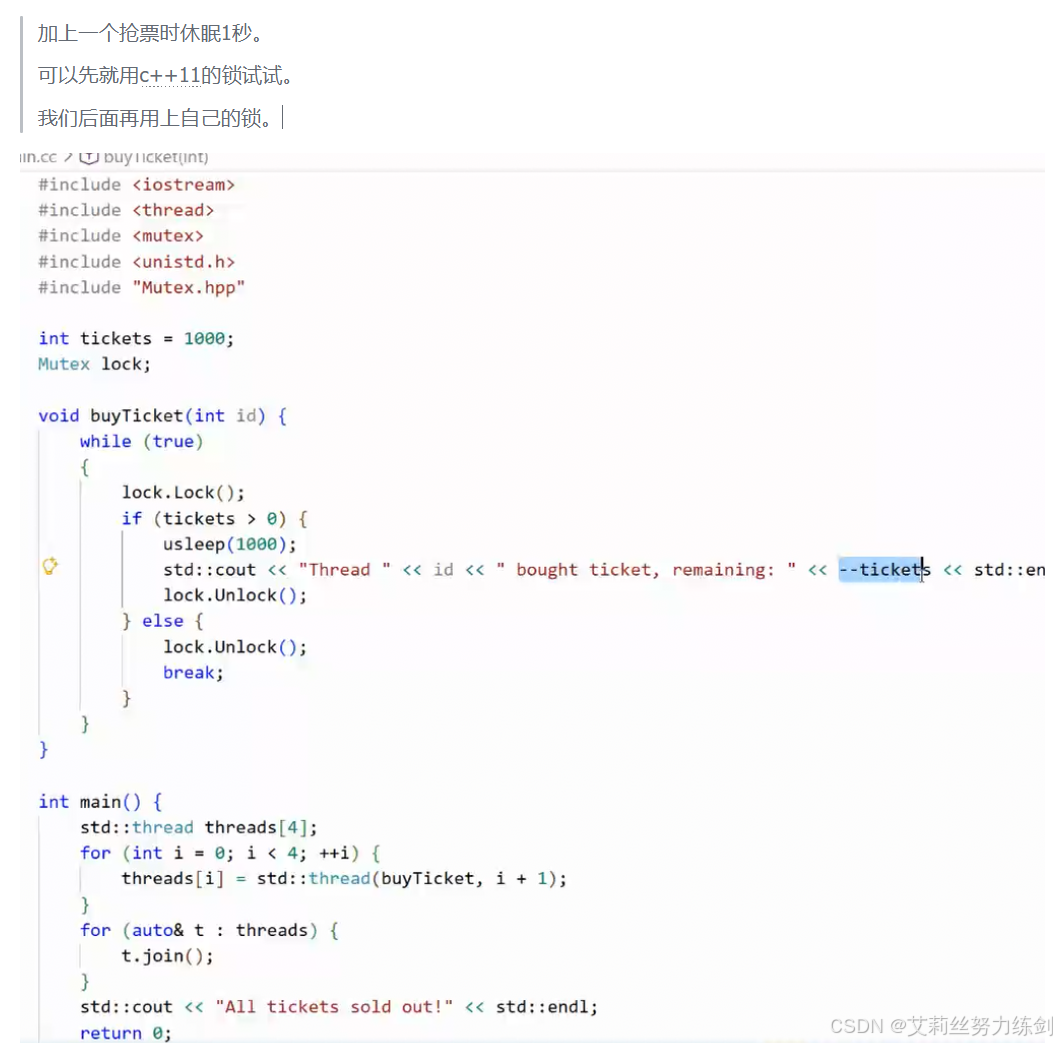
今天不带加锁减锁,直接四个进程:
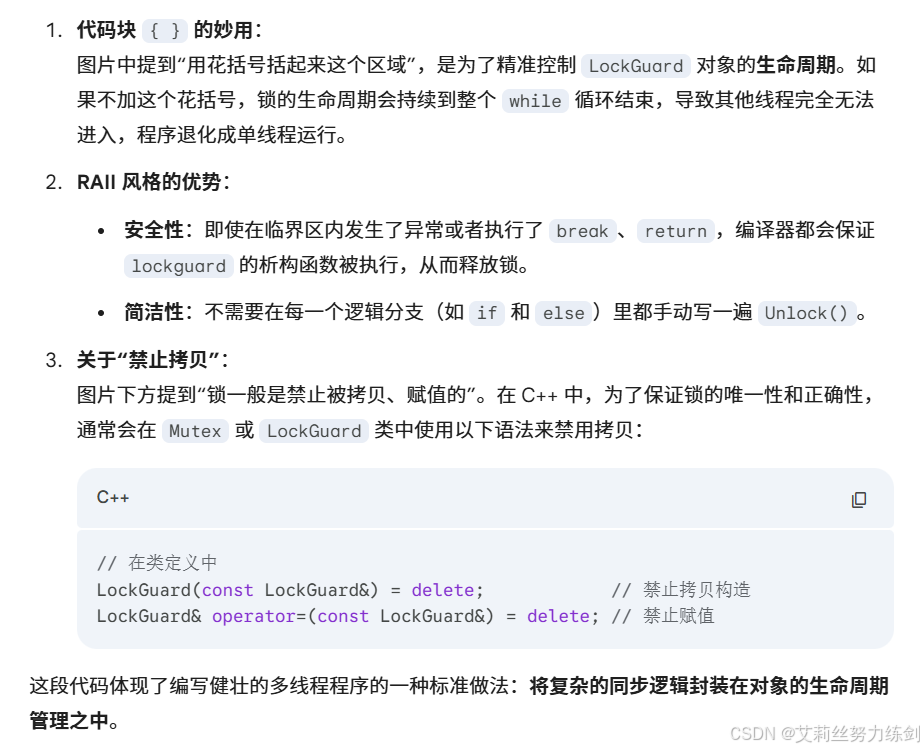
我们再对这个锁进行一下改写,如果再加上一个锁的守卫呢?


为了方便我们理解和看可以用花括号括起来这个区域(可以不带看自己)。

这个区域就是临界区,我们把这种风格的加锁逻辑就叫做RAII风格的加锁逻辑。(9:50~10:01睡着了)
- 锁一般是禁止被拷贝、赋值的,可以把构造函数私有化或delete掉。
可以把锁改成不允许拷贝的,但是这样可能会复杂点不方便使用。
cpp
#include <iostream>
#include <thread>
#include <unistd.h>
#include "Mutex.hpp" // 假设内部包含了 Mutex 类
#include "LockGuard.hpp" // 假设内部包含了图片中的 LockGuard 类
int tickets = 1000; // 共享资源:总票数
Mutex lock; // 全局互斥锁
void buyTicket(int id) {
while (true) {
// 使用花括号 {} 显式定义一个局部作用域
// 这个区域就是所谓的"临界区"
{
// RAII 风格加锁:
// 创建 lockguard 对象时,构造函数自动调用 lock.Lock()
LockGuard lockguard(&lock);
if (tickets > 0) {
usleep(1000); // 模拟购票耗时
std::cout << "Thread " << id << " bought ticket, remaining: " << --tickets << std::endl;
// 离开这个花括号时,lockguard 声明周期结束
// 析构函数会被自动调用,执行 lock.Unlock()
}
else {
// 同样的,即便在这里 break 掉循环
// 只要出了这个花括号的作用域,锁就会被自动释放
break;
}
}
// 临界区结束,锁已释放,其他线程可以竞争了
}
}
int main() {
std::thread threads[4];
// 创建4个线程模拟抢票
for (int i = 0; i < 4; ++i) {
threads[i] = std::thread(buyTicket, i + 1);
}
// 等待所有线程结束
for (auto& t : threads) {
t.join();
}
std::cout << "All tickets sold out!" << std::endl;
return 0;
}展示了多线程编程中一个非常重要的改进:使用 RAII(资源获取即初始化)风格来管理互斥锁。
相比于你之前那张手动调用 Lock() 和 Unlock() 的代码,这里引入了一个 LockGuard 对象。它的核心逻辑是:构造时自动加锁,析构(即超出作用域)时自动解锁。这样可以有效防止因忘记手动解锁或代码提前 break/return 导致的死锁问题。
运行:
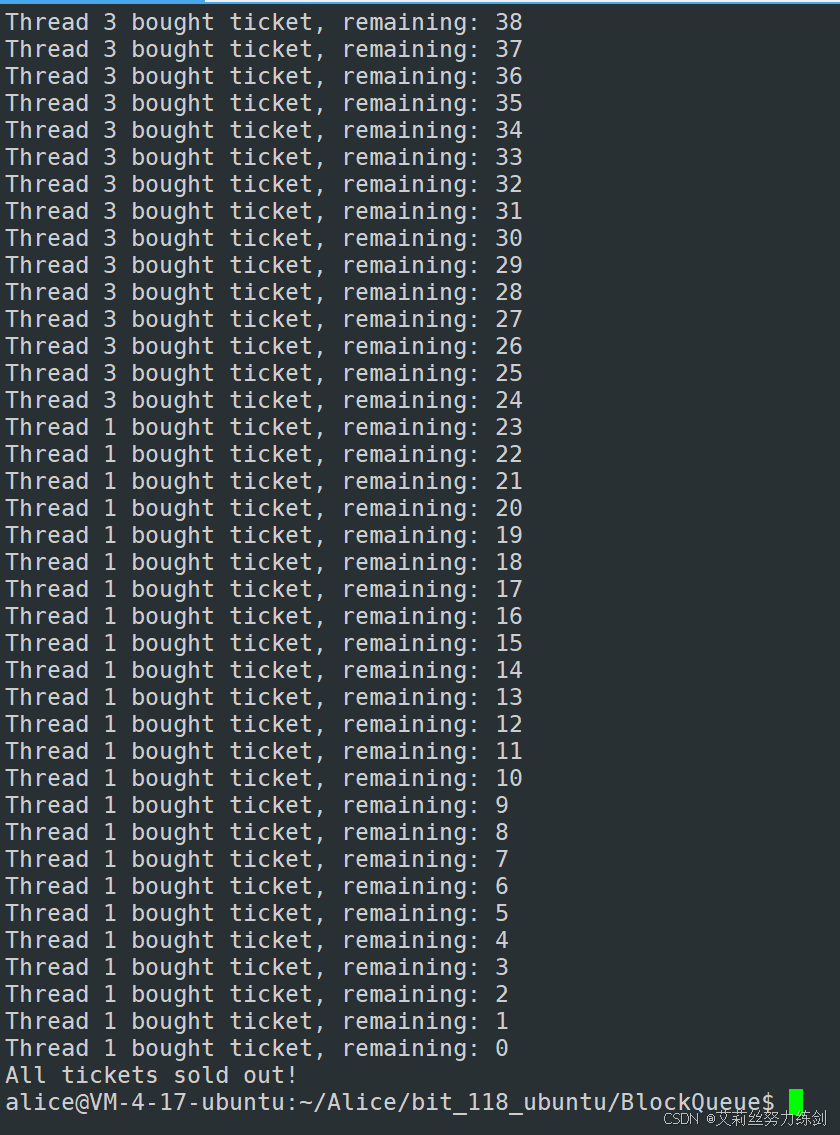
理解一下这种改进的好处:
7.2 补充
7.2.1 互斥量(Mutex)的底层封装
文档中展示了对 pthread_mutex_t 的类封装。在内核视角下,互斥锁不仅仅是一个变量,它涉及到原子操作(Atomic Ops)和进程的状态切换(挂起与唤醒)。
- 构造与析构 :利用
pthread_mutex_init和pthread_mutex_destroy管理锁的生命周期。 - 行为封装 :将
Lock()和Unlock()封装为成员函数,隐藏了pthread原生 API 的繁琐细节。 - 严谨性补充 :
- 拷贝控制 :互斥锁在逻辑上是独占的,物理上绑定了特定的内存地址。严禁拷贝或者赋值 。在 C++ 中应显式使用
= delete禁用拷贝构造和赋值运算符,防止因浅拷贝导致多个对象尝试销毁同一个内核互斥量。 - 返回值检查 :原生的
pthread函数会返回错误码(如EBUSY、EDEADLK)。在封装时,应当通过assert或异常机制处理这些错误,而非保持静默。
- 拷贝控制 :互斥锁在逻辑上是独占的,物理上绑定了特定的内存地址。严禁拷贝或者赋值 。在 C++ 中应显式使用
7.2.2 C++11 标准库互斥量的应用
文档提到了 C++11 的 std::mutex 抢票 Demo。
- 核心逻辑 :定义全局
std::mutex g_mutex和共享资源g_tickets。在操作资源前调用lock(),操作完成后调用unlock()。 - 严谨性补充 :
- 临界区粒度 :文档中在
if (g_tickets > 0)之前加锁,直到票数递减并打印后才解锁。在真实高并发环境下,std::cout属于慢速 I/O 操作。如果将其放在锁内,会大幅度降低并发性能。原则:锁的粒度越小越好。 - 线程安全陷阱 :单纯依靠锁保护
g_tickets递减是不够的,如果后续逻辑依赖该值进行判断,必须确保整个 "检查-决策-执行" 过程是原子的。
- 临界区粒度 :文档中在
7.2.3 RAII 风格锁管理:LockGuard
这是文档中最重要的进阶内容。LockGuard 类通过构造函数加锁,析构函数自动解锁。
- 自动化优势 :它解决了由于
if分支提前返回、break 跳出循环或函数抛出异常导致的死锁(Deadlock)风险。 - 作用域控制 :文档提到可以使用
{}花括号人为控制局部作用域。当LockGuard对象超出花括号范围时,析构函数自动触发,释放锁。 - 内核级视角补充 :
- 性能开销:RAII 风格在 C++ 中几乎是零开销的(Zero-overhead),编译器会将其优化为直接的加解锁指令。
- LockGuard vs UniqueLock:虽然文档实现了简易的
LockGuard,但工业级代码通常会考虑std::lock_guard(轻量)或std::unique_lock(支持条件变量、手动提前解锁)。
7.2.4 临界区逻辑与线程睡眠
在抢票代码中,使用了 usleep 或 sleep_for 来模拟业务处理。
- 意图分析:通过睡眠让出 CPU 时间片,故意暴露多线程在没有锁保护时可能产生的并发问题(如票数变为负数)。
- 内核逻辑补充 :
- 在 Linux 内核中,当一个线程在持有锁的情况下进入睡眠,这是极其危险的行为(除非是可睡眠锁如
mutex)。虽然在用户态这只是效率问题,但会导致其他竞争该锁的线程长时间在内核态处于TASK_UNINTERRUPTIBLE或TASK_INTERRUPTIBLE状态。 - 建议:在生产环境中,严禁在临界区内进行不必要的阻塞操作。
- 在 Linux 内核中,当一个线程在持有锁的情况下进入睡眠,这是极其危险的行为(除非是可睡眠锁如
7.2.5 补充:关于"锁的理论收尾"
以下是内核开发中必须知道的两个进阶概念:
(1)原子性(Atomicity) :加锁的本质是保证操作的原子性。在 x86 架构下,锁的底层通常对应着 lock 前缀的汇编指令,确保对总线或缓存行的锁定。
(2)公平性(Fairness) :原生互斥锁通常是不保证公平的(Non-fair) ,即等待最久的线程不一定最先拿到锁。如果你的业务对顺序有严格要求,需要结合 信号量(Semaphore) 或特定的调度策略。
结尾
uu们,本文的内容到这里就全部结束了,艾莉丝在这里再次感谢您的阅读!
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| ### 艾莉丝努力练剑 C/C++ & Linux 底层探索者 | 一个正在努力练剑的技术博主 *** ** * ** *** 👀 【关注】 跟随我一起深耕技术领域,见证每一次成长。 ❤️ 【点赞】 让优质内容被更多人看见,让知识传递更有力量。 ⭐ 【收藏】 把核心知识点存好,在需要时随时查、随时用。 💬 【评论】 分享你的经验或疑问,评论区一起交流避坑! 不要忘记给博主"一键四连"哦! "今日练剑达成!"  "技术之路难免有困惑,但同行的人会让前进更有方向。" |
"技术之路难免有困惑,但同行的人会让前进更有方向。" |
结语:希望对学习Linux相关内容的uu有所帮助,不要忘记给博主"一键四连"哦!
往期回顾:
【Linux线程】Linux系统多线程(四):线程ID及进程地址空间布局,线程封装
🗡博主在这里放了一只小狗,大家看完了摸摸小狗放松一下吧!🗡 ૮₍ ˶ ˊ ᴥ ˋ˶₎ა
