

一、超节点:AI算力基础设施的革命性演进
1. 超节点的概念与演进历程
超节点(SuperPod)是英伟达率先提出的创新概念,特指在AI服务器集群中,通过超高速互联技术将16张以上GPU紧密连接形成的纵向扩展(Scale Up)系统。这一概念的诞生标志着AI计算从"分散作战"向"集团军作战"的根本性转变。
演进历程:

2. 超节点与传统集群的本质区别
| 维度 | 传统AI集群 | 超节点系统 | 技术影响 |
|---|---|---|---|
| 互联架构 | 服务器间通过网络互联 | 芯片间直接高速互联 | 通信延迟降低10-100倍 |
| 资源视图 | 分散的独立资源 | 统一的全局资源池 | 编程模型大幅简化 |
| 性能瓶颈 | 网络通信成为瓶颈 | 计算本身成为瓶颈 | 真正释放算力潜力 |
| 运维复杂度 | 需要管理大量独立节点 | 单一系统映像管理 | 运维效率提升显著 |
二、GB200 NVL72:超节点技术的巅峰之作
1. 系统架构深度解析
GB200 NVL72的整体架构:

核心技术突破:
NVLink-C2C芯片互联:
- 带宽:900GB/s,是PCIe 5.0的15倍
- 延迟:纳秒级别,比传统互联低1-2个数量级
- 能效:单位比特传输能耗降低5倍
统一内存架构:

2. 计算核心:Grace+Blackwell的完美融合
Grace CPU的创新设计:

Blackwell GPU的突破性性能:

3. 互联背板:超节点的心脏与动脉
3.1 机柜内部互联网络
NVSwitch 5.0交换架构:

铜缆互联的成本优势:
3.2 节点间互联技术
Infiniband网络:
- 采用NVIDIA ConnectX-7网卡
- 支持400Gb/s HDR Infiniband
- 提供跨节点的RDMA支持
- 确保多超节点间的协同训练
Quantum-2交换平台:
- 单交换机支持64个400Gb/s端口
- 提供微秒级跨节点通信
- 支持自适应路由和拥塞控制
4. 供电与散热:兆瓦级系统的工程奇迹
4.1 供电系统设计
功率需求分析:
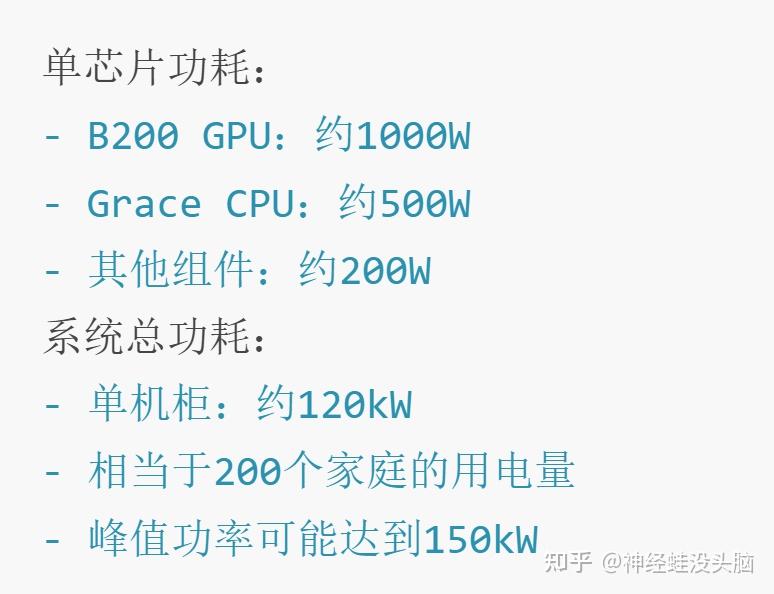
供电架构:
电源设计:
├─ 高压直流供电:480V DC输入
├─ 分布式电源模块:N+1冗余
├─ 智能功率管理:动态调频调压
└─ 备用电源系统:UPS+发电机
4.2 先进散热技术
冷板式液冷系统:

系统级热管理:
监控体系:
├─ 芯片级:2000+温度传感器
├─ 板卡级:流量和压力监控
├─ 机柜级:进出水温差控制
└─ 机房级:冷却塔和泵组管理
5. 软件栈:超节点的智能大脑
5.1 统一系统管理
NVIDIA Base Command Manager:

5.2 AI软件生态
全栈优化软件:
AI框架层:
├─ TensorFlow with NVIDIA优化
├─ PyTorch with Transformer引擎支持
├─ JAX with CUDA加速
└─ 自定义框架支持
开发工具链:
├─ NVIDIA AI Enterprise
├─ Triton推理服务器
├─ NeMo Megatron训练框架
└─ CUDA-X AI库集合
三、超节点为何成为AI算力"新宠"?
1. 技术驱动因素
大模型发展的算力需求:

通信瓶颈的突破:

2. 经济性分析
总体拥有成本(TCO)优化:
| 成本类别 | 传统集群 | 超节点系统 | 节省幅度 |
|---|---|---|---|
| 硬件投资 | 分散采购,兼容性成本高 | 一体化设计,优化成本 | 15-25% |
| 能源消耗 | PUE 1.5-1.8,效率低下 | PUE 1.1-1.2,高效节能 | 40-50% |
| 运维人力 | 需要大量运维人员 | 自动化管理,人力需求少 | 50-60% |
| 空间占用 | 机架密度低,空间浪费 | 高密度设计,空间节省 | 60-70% |
| 训练效率 | 通信开销大,利用率低 | 接近理论峰值性能 | 性能提升2-3倍 |
3. 战略价值
技术护城河构建:
生态系统壁垒:
├─ 硬件:专用芯片+互联技术
├─ 软件:全栈优化软件生态
├─ 算法:与框架深度集成
└─ 服务:端到端解决方案
商业价值:
├─ 缩短模型训练时间
├─ 支持更大模型规模
├─ 降低AI应用门槛
└─ 推动AGI技术发展
四、超节点产业生态格局
1. 英伟达:垂直整合的领导者
GB200 NVL72生态系统:

商业模式分析:

2. 华为:自主可控的挑战者

硬件技术路线:

市场策略:

3. 腾讯:开放生态的探索者
开放架构设计:
硬件开放:
├─ 基于标准以太网技术
├─ 与多厂商硬件兼容
├─ 支持异构计算平台
└─ 开源硬件设计
软件开放:
├─ 开源集群管理软件
├─ 标准API接口
├─ 多框架支持
└─ 社区驱动发展
商业模式创新:

4. 其他国内厂商生态布局
4.1 技术路线对比
| 厂商 | 技术路线 | 互联技术 | 目标市场 | 发展阶段 |
|---|---|---|---|---|
| 壁仞科技 | 光互连技术 | LightSphere X | 高端计算 | 产品化阶段 |
| 沐曦 | 传统互联优化 | Shanghai Cube | 企业市场 | 规模部署 |
| 摩尔线程 | 全栈方案 | KUAE集群 | 多元市场 | 生态建设 |
| 燧原科技 | 液冷专注 | 云燧ESL | 云服务商 | 商业落地 |
5. 超节点产业生态模式对比分析
| 维度 | 垂直整合模式 (英伟达代表) | 协议开放模式 (华为代表) | 开源开放模式 (腾讯ETH-X代表) |
|---|---|---|---|
| 核心技术 | - 专有芯片架构 - NVLink/NVSwitch互联 - CUDA封闭生态 | - 自研NPU芯片 - MatrixLink互联协议 - CANN计算架构 | - 标准以太网技术 - 开放硬件接口 - 开源软件栈 |
| 生态开放性 | ★☆☆☆☆ 高度封闭 | ★★★☆☆ 有限开放 | ★★★★★ 完全开放 |
| 性能表现 | ★★★★★ 业界领先 | ★★★★☆ 接近顶尖 | ★★★☆☆ 中等水平 |
| 开发门槛 | 高 需深度适配专有技术 | 中 需遵循华为技术规范 | 低 基于开放标准开发 |
| 成本结构 | 高 硬件溢价+软件授权 | 中高 硬件成本+服务费用 | 低 标准化硬件+社区支持 |
| 典型客户 | - 大型互联网公司 - 顶级科研机构 - 资金雄厚企业 | - 政企客户 - 对自主可控有要求 - 华为生态用户 | - 中小型企业 - 学术研究 - 开发者社区 |
| 商业模式 | - 硬件销售 - 软件授权 - 云服务订阅 - 专业服务 | - 整体解决方案 - 云服务 - 技术服务 - 生态合作 | - 技术服务 - 云平台 - 生态合作 - 开源商业化 |
| 优势 | - 性能最优 - 技术领先 - 生态完整 - 稳定性高 | - 自主可控 - 本地化服务 - 安全性强 - 政策支持 | - 成本低廉 - 灵活性强 - 避免锁定 - 创新快速 |
| 劣势 | - 供应商锁定 - 成本高昂 - 定制困难 - 依赖单一厂商 | - 生态相对封闭 - 技术路线风险 - 国际竞争压力 | - 性能瓶颈 - 技术支持有限 - 标准化挑战 |
| 技术演进 | - 持续迭代专有技术 - 向下兼容 - 性能优先 | - 自主技术演进 - 生态协同发展 - 安全可靠优先 | - 社区驱动发展 - 标准演进 - 兼容性优先 |
超节点技术正以前所未有的速度推动着AI算力基础设施的变革。从GB200 NVL72到各厂商的解决方案,这场技术竞赛不仅关乎商业利益,更决定着未来AI产业发展的主导权。随着技术的不断成熟和成本的持续下降,超节点将从现在的"奢侈品"逐渐成为AI计算的"标配",为通用人工智能的到来奠定坚实的算力基础。
---转自博客园jzssuanfa