P1127 词链
题目描述
如果单词 X 的末字母与单词 Y 的首字母相同,则 X 与 Y 可以相连成 X.Y。(注意:X、Y 之间是英文的句号 .)。例如,单词 dog 与单词 gopher,则 dog 与 gopher 可以相连成 dog.gopher。
另外还有一些例子:
dog.gophergopher.ratrat.tigeraloha.alohaarachnid.dog
连接成的词可以与其他单词相连,组成更长的词链,例如:
aloha.arachnid.dog.gopher.rat.tiger
注意到,. 两边的字母一定是相同的。
现在给你一些单词,请你找到字典序最小的词链,使得每个单词在词链中出现且仅出现一次。注意,相同的单词若出现了 k 次就需要输出 k 次。
输入格式
第一行是一个正整数 n(1≤n≤1000),代表单词数量。
接下来共有 n 行,每行是一个由 1 到 20 个小写字母组成的单词。
输出格式
只有一行,表示组成字典序最小的词链,若不存在则只输出三个星号 ***。
输入输出样例
输入 #1复制
6
aloha
arachnid
dog
gopher
rat
tiger输出 #1复制
aloha.arachnid.dog.gopher.rat.tiger说明/提示
对于 40% 的数据,有 n≤10;对于 100% 的数据,有 n≤1000。
实现代码:
cpp
#include<cmath>
#include<cstring>
#include<cstdio>
#include<iostream>
#include<algorithm>
#include<map>
using namespace std;
const int maxn=1e5+5;
string a[maxn];
string ans[maxn];
string now[maxn];
int sum=0;
int len[maxn];
int book[maxn];
map<char,int> s1,s2;
int n;
int flag=0;
void dfs(int last,int step)
{
if(flag==1)
return;
if(step==n)
{
flag=1;
for(int i=1;i<=sum;i++)
{
ans[i]=now[i];
}
return;
}
for(int i=1;i<=n;i++)
{
if(book[i]==1)
continue;
if(a[last][a[last].length()-1]==a[i][0])
{
now[++sum]=a[i];
book[i]=1;
dfs(i,step+1);
sum--;
book[i]=0;
}
}
}
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
cin>>a[i];
len[i]=a[i].length();
s1[a[i][0]]++;
s2[a[i][len[i]-1]]++;
}
int start=1;
sort(a+1,a+1+n);
char s,t;
for(char c='a';c<='z';c++)
{
if(abs(s1[c]-s2[c])==1)
{
if(s1[c]-s2[c]==1)
s=c;
else
if(s2[c]-s1[c]==1)
t=c;
}
}
int cnt=s2[t];
for(int i=1;i<=n;i++)
{
if(a[i][0]==s && (a[i][len[i]-1]!=t || cnt!=1))
{
start=i;
break;
}
}
book[start]=1;
now[++sum]=a[start];
dfs(start,1);
if(flag==0)
{
printf("***\n");
return 0;
}
for(int i=1;i<=n;i++)
{
if(i!=n)
cout<<ans[i]<<".";
else
cout<<ans[i];
}
printf("\n");
return 0;
}P2853 USACO06DEC Cow Picnic S
题目描述
K(1≤K≤100) 只奶牛分散在 N(1≤N≤1000) 个牧场.现在她们要集中起来进餐。牧场之间有 M(1≤M≤10000) 条有向路径连接(没有路径将牧场连接到自身)。她们进餐的地点必须是所有奶牛都可到达的地方。那么,有多少这样的牧场可供进食呢?
输入格式
第 1 行:三个以空格分隔的整数,分别为:K, N, M。
第 2 行到第 K+1 行:每行包含一个整数 Ci(1≤Ci≤N),表示第 i 头奶牛所在的牧场编号。
第 K+2 行到第 M+K+1 行:每行包含两个以空格分隔的整数 A 和 B,表示一条从牧场 A 到牧场 B 的单向路径。(1≤A,B≤N,A=B)
输出格式
第一行:一个整数,即所有奶牛都可以到达的牧场数量。
输入输出样例
输入 #1复制
2 4 4
2
3
1 2
1 4
2 3
3 4输出 #1复制
2说明/提示
奶牛可以在 3 或 4 号牧场相遇。
实现代码:
cpp
#include <queue>
#include <cstdio>
#include <iostream>
using namespace std;
bool vis[1010];
int k,n,m,ans;
int mk[1010],a[1010];
vector <int> b[1010];
void dfs(int x)
{
vis[x]=1; mk[x]++;
for(int i=0;i<b[x].size();i++)
if(!vis[b[x][i]])
dfs(b[x][i]);
}
int main()
{
int x,y;
cin>>k>>n>>m;
for(int i=1;i<=k;i++) cin>>a[i];
for(int i=1;i<=m;i++)
{
cin>>x>>y;
b[x].push_back(y);
}
for(int i=1;i<=k;i++) { for(int j=1;j<=n;j++) vis[j]=0; dfs(a[i]);}
for(int i=1;i<=n;i++) if(mk[i]==k) ans++;
cout<<ans;
return 0;
}P1363 幻象迷宫
题目背景
(喵星人 LHX 和 WD 同心协力击退了汪星人的入侵,不幸的是,汪星人撤退之前给它们制造了一片幻象迷宫。)
WD:呜呜,肿么办啊......
LHX:momo...我们一定能走出去的!
WD:嗯,+U+U!
题目描述
幻象迷宫可以认为是无限大的,不过它由若干个 N×M 的矩阵重复组成。矩阵中有的地方是道路,用 . 表示;有的地方是墙,用 # 表示。LHX 和 WD 所在的位置用 S 表示。也就是对于迷宫中的一个点(x,y),如果 (xmodn,ymodm) 是 . 或者 S,那么这个地方是道路;如果 (xmodn,ymodm) 是#,那么这个地方是墙。LHX 和 WD 可以向上下左右四个方向移动,当然不能移动到墙上。
请你告诉 LHX 和 WD,它们能否走出幻象迷宫(如果它们能走到距离起点无限远处,就认为能走出去)。如果不能的话,LHX 就只好启动城堡的毁灭程序了......当然不到万不得已,他不想这么做。
输入格式
输入包含多组数据。
每组数据的第一行是两个整数 N,M。
接下来是一个 N×M 的字符矩阵,表示迷宫里 (0,0) 到 (n−1,m−1) 这个矩阵单元。
输出格式
对于每组数据,输出一个字符串,Yes 或者 No。
输入输出样例
输入 #1复制
5 4
##.#
##S#
#..#
#.##
#..#
5 4
##.#
##S#
#..#
..#.
#.##输出 #1复制
Yes
No说明/提示
- 对于 30% 的数据,1≤N,M≤20;
- 对于 50% 的数据,1≤N,M≤100;
- 对于 100% 的数据,1≤N,M≤1500,每个测试点不超过 10 组数据。
实现代码:
cpp
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
const int MAXN = 1500 + 1;
const int dx[4] = {1, -1, 0, 0};
const int dy[4] = {0, 0, 1, -1};
int n, m;
int st_x, st_y;
int vis[MAXN][MAXN][3];
bool fl, a[MAXN][MAXN];
char ch;
void dfs(int x, int y, int lx, int ly) {
if(fl) return;
if(vis[x][y][0] && (vis[x][y][1]!=lx || vis[x][y][2]!=ly)) {
fl = 1;
return;
}
vis[x][y][1] = lx, vis[x][y][2] = ly, vis[x][y][0] = 1;
for(int i=0; i<4; ++i) {
int xx = (x + dx[i] + n) % n, yy = (y + dy[i] + m) % m;
int lxx = lx + dx[i], lyy = ly + dy[i];
if(!a[xx][yy]) {
if(vis[xx][yy][1]!=lxx || vis[xx][yy][2]!=lyy || !vis[xx][yy][0])
dfs(xx, yy, lxx, lyy);
}
}
}
int main() {
ios::sync_with_stdio(false);
while(cin >> n >> m) {
fl = 0;
memset(a, 0, sizeof(a));
memset(vis, 0, sizeof(vis));
for(int i=0; i<n; ++i)
for(int j=0; j<m; ++j) {
cin >> ch;
if(ch == '#') a[i][j] = 1;
if(ch == 'S') st_x = i, st_y = j;
}
dfs(st_x, st_y, st_x, st_y);
if(fl) puts("Yes");
else puts("No");
}
}P1983 NOIP 2013 普及组 车站分级
题目背景
NOIP2013 普及组 T4
题目描述
一条单向的铁路线上,依次有编号为 1,2,...,n 的 n 个火车站。每个火车站都有一个级别,最低为 1 级。现有若干趟车次在这条线路上行驶,每一趟都满足如下要求:如果这趟车次停靠了火车站 x,则始发站、终点站之间所有级别大于等于火车站 x 的都必须停靠。
注意:起始站和终点站自然也算作事先已知需要停靠的站点。
例如,下表是 5 趟车次的运行情况。其中,前 4 趟车次均满足要求,而第 5 趟车次由于停靠了 3 号火车站(2 级)却未停靠途经的 6 号火车站(亦为 2 级)而不满足要求。
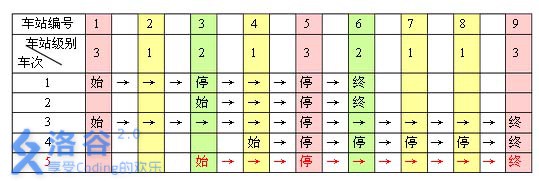
现有 m 趟车次的运行情况(全部满足要求),试推算这 n 个火车站至少分为几个不同的级别。
输入格式
第一行包含 2 个正整数 n,m,用一个空格隔开。
第 i+1 行 (1≤i≤m) 中,首先是一个正整数 si (2≤si≤n),表示第 i 趟车次有 si 个停靠站;接下来有 si 个正整数,表示所有停靠站的编号,从小到大排列。每两个数之间用一个空格隔开。输入保证所有的车次都满足要求。
输出格式
一个正整数,即 n 个火车站最少划分的级别数。
输入输出样例
输入 #1复制
9 2
4 1 3 5 6
3 3 5 6 输出 #1复制
2输入 #2复制
9 3
4 1 3 5 6
3 3 5 6
3 1 5 9 输出 #2复制
3说明/提示
对于 20% 的数据,1≤n,m≤10;
对于 50% 的数据,1≤n,m≤100;
对于 100% 的数据,1≤n,m≤1000。
实现代码:
cpp
#include<iostream>
#include<cstdio>
#include<cstring>
#define ZYS 1005
using namespace std;
int n,m,ans,st[ZYS],s,tuopu[ZYS][ZYS],de[ZYS],tt[ZYS],top;
bool is[ZYS],bo[ZYS];
int main() {
scanf("%d %d",&n,&m);
for(int i=1;i<=m;i++) {
memset(is,0,sizeof(is));
scanf("%d",&s);
for(int j=1;j<=s;j++)
scanf("%d",&st[j]),is[st[j]]=true;
for(int j=st[1];j<=st[s];j++)
if(!is[j])
for(int k=1;k<=s;k++)
if(!tuopu[j][st[k]]) tuopu[j][st[k]]=1,de[st[k]]++;
}
do{
top=0;
for(int i=1;i<=n;i++)
if(de[i]==0&&!bo[i]) {
tt[++top]=i,bo[i]=true;
}
for(int i=1;i<=top;i++)
for(int j=1;j<=n;j++)
if(tuopu[tt[i]][j]) tuopu[tt[i]][j]=0,de[j]--;
ans++;
} while(top);
printf("%d",ans-1);
return 0;
}P1347 ECNA 2001 排序
题目描述
一个不同的值的升序排序数列指的是一个从左到右元素依次增大的序列,例如,一个有序的数列 A,B,C,D 表示 A<B,B<C,C<D。在这道题中,我们将给你一系列形如 A<B 的关系,并要求你判断是否能够根据这些关系确定这个数列的顺序。
输入格式
第一行有两个正整数 n,m,n 表示需要排序的元素数量,2≤n≤26,第 1 到 n 个元素将用大写的 A,B,C,D,... 表示。m 表示将给出的形如 A<B 的关系的数量。
接下来有 m 行,每行有 3 个字符,分别为一个大写字母,一个 < 符号,一个大写字母,表示两个元素之间的关系。
输出格式
若根据前 x 个关系即可确定这 n 个元素的顺序 yyy..y(如 ABC),输出
Sorted sequence determined after x relations: yyy...y.
其中 x 表示上述的前 x 个关系。
若根据前 x 个关系即发现存在矛盾(如 A<B,B<C,C<A),输出
Inconsistency found after x relations.
其中 x 表示的意义同上。
若根据这 m 个关系无法确定这 n 个元素的顺序,输出
Sorted sequence cannot be determined.
(提示:确定 n 个元素的顺序后即可结束程序,可以不用考虑确定顺序之后出现矛盾的情况)
输入输出样例
输入 #1复制
4 6
A<B
A<C
B<C
C<D
B<D
A<B输出 #1复制
Sorted sequence determined after 4 relations: ABCD.输入 #2复制
3 2
A<B
B<A输出 #2复制
Inconsistency found after 2 relations.输入 #3复制
26 1
A<Z输出 #3复制
Sorted sequence cannot be determined.说明/提示
2≤n≤26,1≤m≤600。
实现代码:
cpp
#include <bits/stdc++.h>
#define MAXN 50
using namespace std;
int n,m;
struct Node{
int u;
int val;
Node(int u=0,int val=0):u(u),val(val){}
};
vector<int> vec[MAXN];
int ru[MAXN];
int sum;
int ans;
int k;
set<int> s1;
void make(){
queue<int> q;
int ru1[MAXN];
memset(ru1,0,sizeof(ru1));
for(int i=0; i<26; i++){
for(int j=0; j<vec[i].size(); j++){
ru1[vec[i][j]]++;
}
}
for(int i=0; i<26; i++){
if(ru1[i]==0&&s1.count(i)){
q.push(i);
cout<<char(i+'A');
}
}
while(!q.empty()){
int u=q.front();
q.pop();
for(int i=0; i<vec[u].size(); i++){
int v=vec[u][i];
ru1[v]--;
if(ru1[v]==0){
q.push(v);
cout<<char(v+'A');
}
}
}
}
int have;
void topo(){
queue<Node> q;
for(int i=0; i<26; i++){
if(ru[i]==0&&s1.count(i)){
q.push(Node(i,1));
sum++;
}
}
while(!q.empty()){
int u=q.front().u;
int val=q.front().val;
q.pop();
for(int i=0; i<vec[u].size(); i++){
int v=vec[u][i];
ru[v]--;
if(ru[v]==0){
sum++;
q.push(Node(v,val+1));
ans=max(ans,val+1);
}
}
}
if(ans==n){
printf("Sorted sequence determined after %d relations: ",k);
make();
cout<<".";
exit(0);
}
if(sum!=have){
printf("Inconsistency found after %d relations.",k);
exit(0);
}
}
int ru2[MAXN];
int main(){
cin>>n>>m;
for(int i=1; i<=m; i++){
string s;
cin>>s;
k=i;
vec[s[0]-'A'].push_back(s[2]-'A');
s1.insert(s[0]-'A');
s1.insert(s[2]-'A');
have=s1.size();
ru2[s[2]-'A']++;
sum=0;
ans=0;
memcpy(ru,ru2,sizeof(ru2));
topo();
}
printf("Sorted sequence cannot be determined.");
return 0;
}