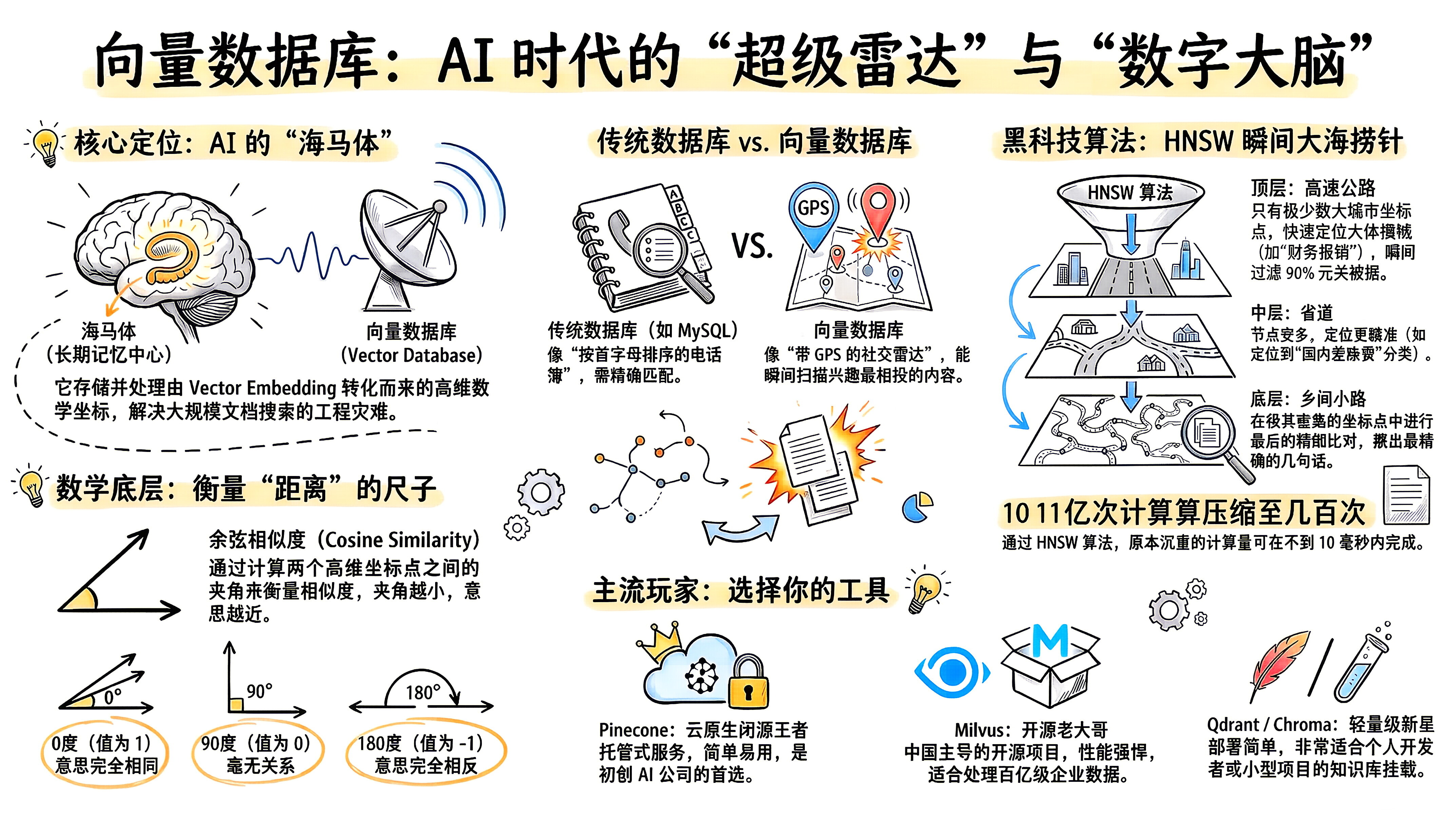
向量数据库 (Vector Database) 是 AI 时代的**"超级雷达"** ,也是大模型和智能体 (Agent) 真正的**"** 海马体 " (人类大脑中负责长期记忆的区域)。
正如我们在上一条聊到的,Vector Embedding 把全人类的知识都变成了一个个拥有上千个维度的"数学坐标"。
但随之而来的是一个巨大的工程灾难:当你的公司拥有几百万份文档,转化为几亿个高维坐标点时,你怎么在零点几秒内,从这几亿个点中找到离你问题"最近"的那几个点?
向量数据库,就是专门为了解决这个"高维空间寻宝"难题而诞生的全新基础设施。
1.🆚 传统数据库的无奈:为什么不用 MySQL?
要理解向量数据库的伟大,我们先看看陪伴了程序员几十年的传统关系型数据库(如 MySQL、PostgreSQL)为什么会在 AI 时代"水土不服"。
|------|--------------------------------|---------------------------------------|
| 维度 | 传统数据库 (如 MySQL) | 向量数据库 (如 Milvus, Pinecone) |
| 存储内容 | 结构化数据(如字符串、整数、日期)。 | 高维浮点数数组(如 1536 维的向量坐标)。 |
| 查找逻辑 | 精确匹配 (Exact Match)。要么等于,要么不等于。 | 相似度匹配 (Similarity Match)。找距离最近的邻居。 |
| 查询指令 | SELECT * WHERE keyword = '苹果' | "帮我找到与坐标 0.1, -0.4... 夹角最小的 5 个点" |
| 适用场景 | 财务记账、用户密码校验、库存管理。 | RAG 知识库、以图搜图、音乐推荐系统。 |
传统数据库就像是**"按首字母排序的电话簿"** ,你必须知道准确的名字才能查到人;而向量数据库就像是**"带 GPS 的社交雷达"** ,它能瞬间扫出方圆 5 公里内和你兴趣最相投的人。
2.🧮 寻找最近的邻居:底层的数学逻辑
在向量数据库中,衡量两个概念是否相似,本质上就是在计算两个高维坐标点之间的"距离"。目前业界最常用的是余弦相似度 ( Cosine Similarity ),它的底层逻辑是计算两个向量在多维空间中的夹角:
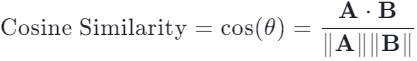
-
如果夹角是 0度 (余弦值为 1):两个向量方向完全一致,意味着两句话意思完全相同。
-
如果夹角是 90度 (余弦值为 0):意味着两句话毫无关系。
-
如果夹角是 180度 (余弦值为 -1):意味着两句话意思完全相反。
3.⚡ 核心黑科技:如何做到"瞬间大海捞针"?
如果你有 10 亿个坐标点,每次提问都要用上面的公式把 10 亿个点全部算一遍(这叫暴力搜索 K-NN),就算是最顶级的服务器也会当场宕机。
向量数据库之所以快得离谱,是因为它使用了一套极其聪明的算法------ANN (Approximate Nearest Neighbor,近似最近邻搜索) 。其中目前统治业界的王者算法叫做 HNSW (分层可导航小世界图)。
你可以把 HNSW 算法理解为**"高速公路与乡间小路的立体交通网"** :
-
顶层(高速公路):只有极少数的几个"大城市的坐标点"。系统先在这里快速定位你大体在哪个省(比如:确定你的问题属于"财务报销"领域,瞬间过滤掉 90% 的无关数据)。
-
中层(省道):顺着高速公路的出口往下走,节点变多,定位更精准(比如:定位到"国内差旅费"分类)。
-
底层(乡间小路):包含所有极其密集的坐标点。系统在这里做最后的精细比对,揪出离你最近的那 3 句话。
结果:通过这种"跳跃式"的降维打击,原本需要计算 10 亿次的搜索,现在只需要计算几百次就能搞定,耗时不到 10 毫秒!
4.🏢 目前的主流玩家
目前,由于 RAG 技术的井喷,向量数据库赛道也是神仙打架。作为开发者或企业,通常有几类选择:
-
云原生/闭源王者 :Pinecone。极其简单好用,完全托管,注册个 API 就能把向量丢进去,是很多初创 AI 公司的首选。
-
开源老大哥 :Milvus。中国人主导的开源项目,性能极其强悍,适合处理百亿级别的大规模企业级数据。
-
轻量级新星 :Qdrant , Chroma。部署简单,非常适合个人开发者在本地或者小型项目中挂载知识库。