5 Datasets and Benchmarks
5.1 Datasets
我们在表1中总结了广泛使用的数据集中的各种场景类别和标注格式。我们主要指明了数据量,将其分为物体、室内和室外场景 ,并明确数据来自真实环境还是合成生成。
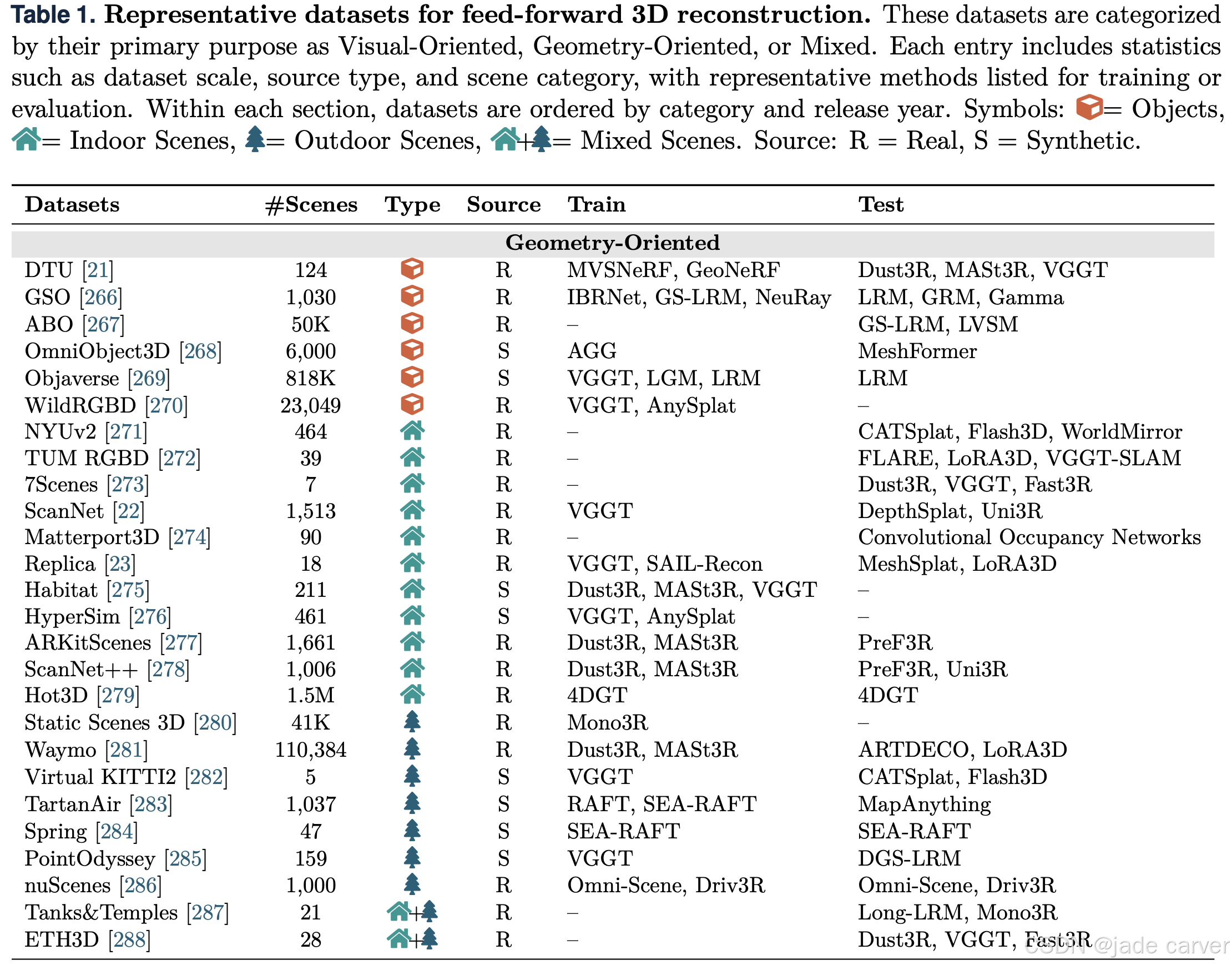
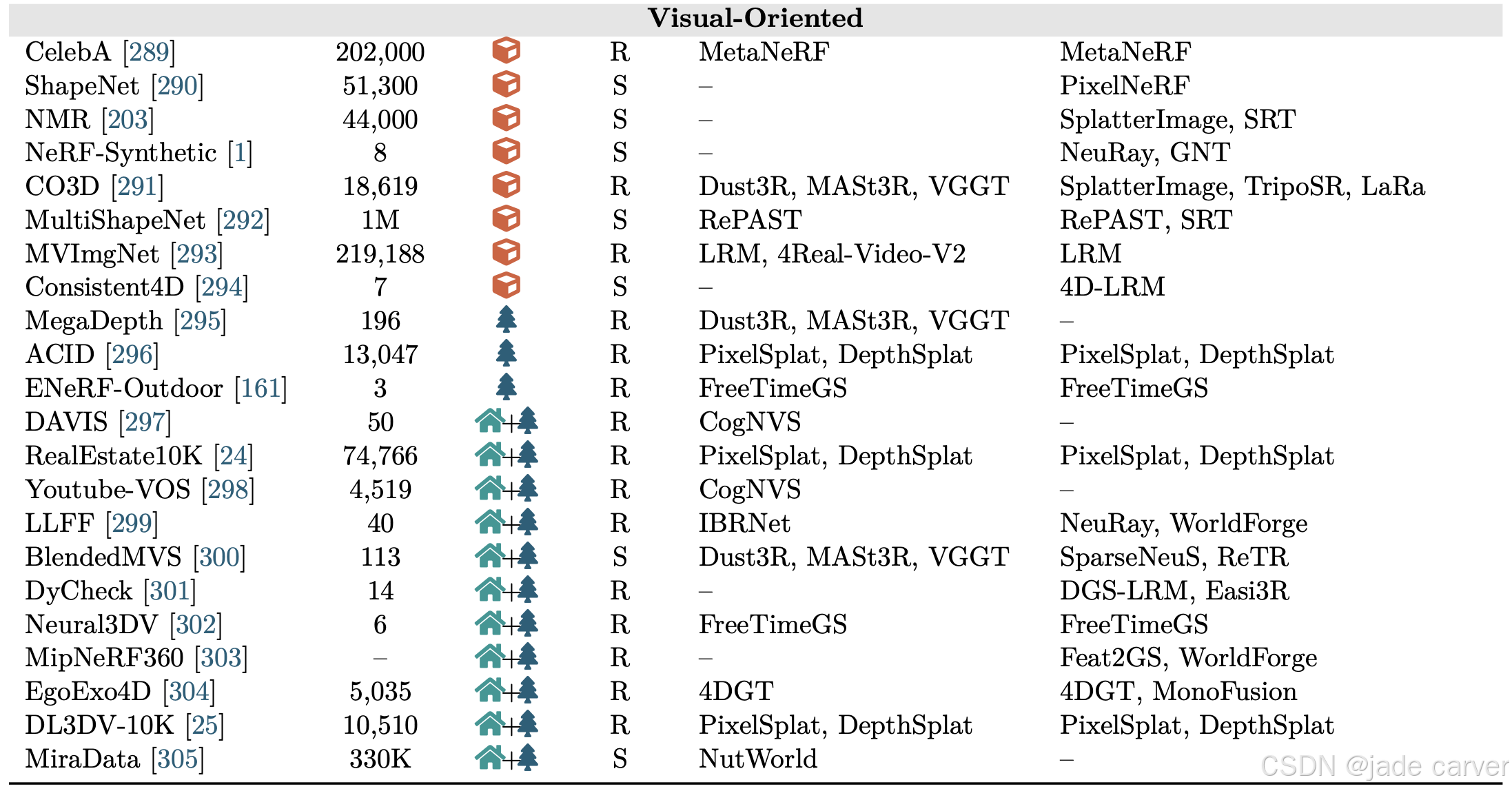
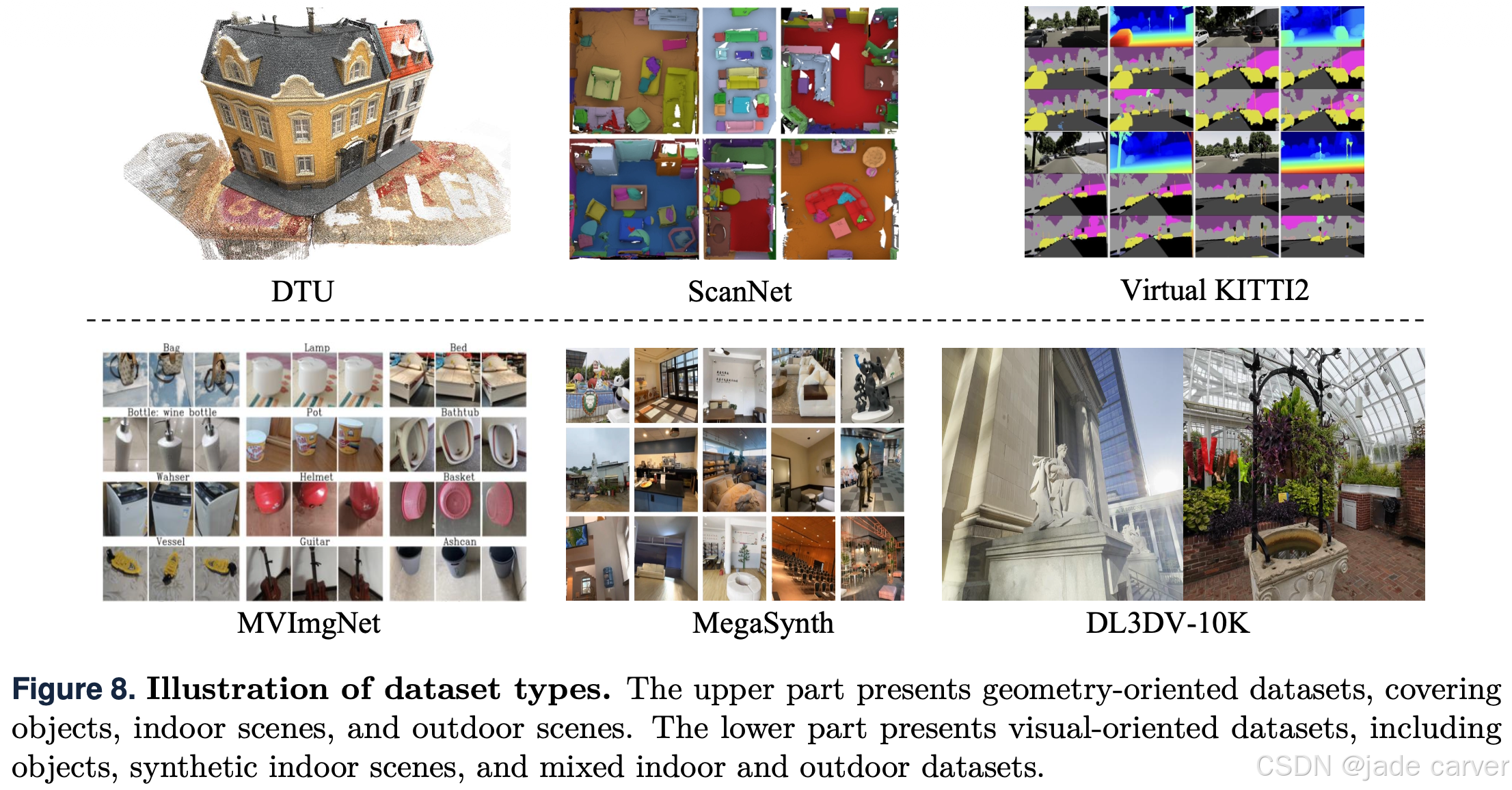
我们还引入了一个新的分类视角,即根据数据集是几何导向型 还是视觉导向型 进行分类,如图8所示。几何导向型数据集提供可靠的3D表示真值(如点云、深度图和相机位姿) ,而不是从图像重建得到的几何信息。因此,这类数据集特别适用于需要精确几何信息的任务 。相比之下,视觉导向型数据集通常来源于真实场景或精心策划的视频,更适合用于新视图合成和照片级真实感渲染等应用。引入这一区分,为3D重建社区提供了一个重要的概念性贡献。
5.2 Metrics
在前馈式3D重建和视图合成场景中,通常采用多种指标进行可靠的评估。
对于新视图合成,常用指标包括PSNR(峰值信噪比)、SSIM(结构相似性指数)311和LPIPS(学习感知图像块相似度)312。
在相机位姿评估 方面,常用的指标包括RTA(相对平移精度)、RRA(相对旋转精度)和AUC(曲线下面积)。其中,RTA和RRA分别报告图像对之间平移和旋转的相对角度误差;而AUC则通过计算不同角度误差阈值下的精度曲线面积,综合反映整体性能。
对于点图评估,常用指标包括点云精度(准确率)、完整性(召回率)和Chamfer距离。精度计算每个预测点到其对应真实表面位置的最近邻平均距离,用于衡量预测的准确程度。完整性计算真实点到预测重建结果的最近邻平均距离,反映表面对覆盖的完整程度。Chamfer距离则综合了精度和完整性两个指标的度量。
在动态点追踪任务中,常用指标包括OA(遮挡精度)、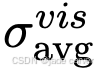 和AJ(平均Jaccard指数)313。其中,遮挡精度衡量遮挡预测的二值准确率;表示在给定像素阈值内被正确追踪的点的比例;AJ将遮挡精度和预测精度整合为一个综合评分。
和AJ(平均Jaccard指数)313。其中,遮挡精度衡量遮挡预测的二值准确率;表示在给定像素阈值内被正确追踪的点的比例;AJ将遮挡精度和预测精度整合为一个综合评分。
5.3 Benchmarks
为了清晰地概述当前最先进的前馈式3D重建和视图合成方法,我们整理了多个基准测试和数据集上的结果。以下总结了三项关键对比,每项对应一个不同的评估表格。
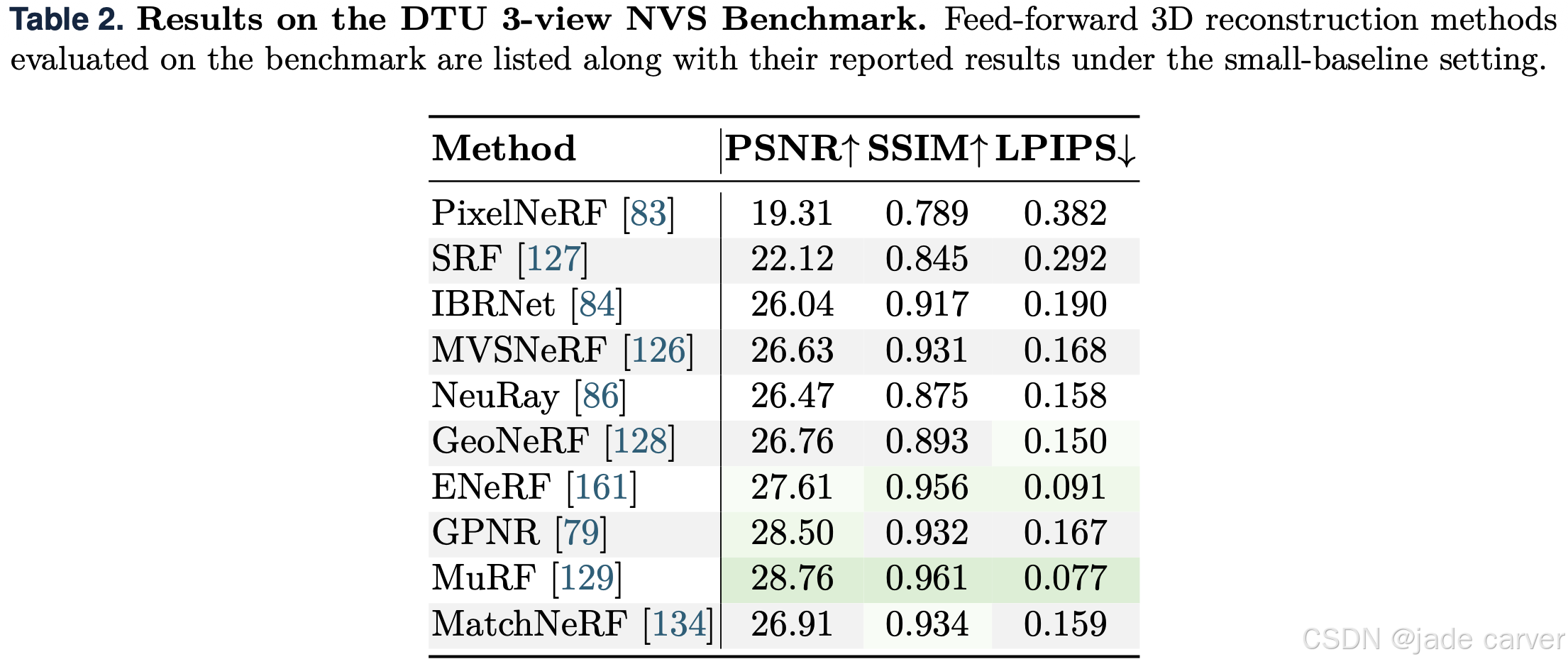
对于DTU 3视角基准(表2),早期的基于NeRF的方法通常在相对较小的数据集上评估。在本研究中,我们选择了DTU数据集,并将所有方法的输入视图数量统一设为3。结果表明,MuRF 129 在该基准上取得了最佳性能。
对于re10k基准(表3),与DTU相比,re10k是一个规模大得多的数据集,并提供了更广泛的测试基准。我们评估了早期的基于NeRF的方法和近期基于3DGS的方法,总共汇总了34种方法的结果。通常情况下,每种方法输入两个视图;对于使用不同配置的方法,我们在表格下部明确指出了具体情况。对比结果表明,ReSplat 在re10k基准上取得了最佳性能。
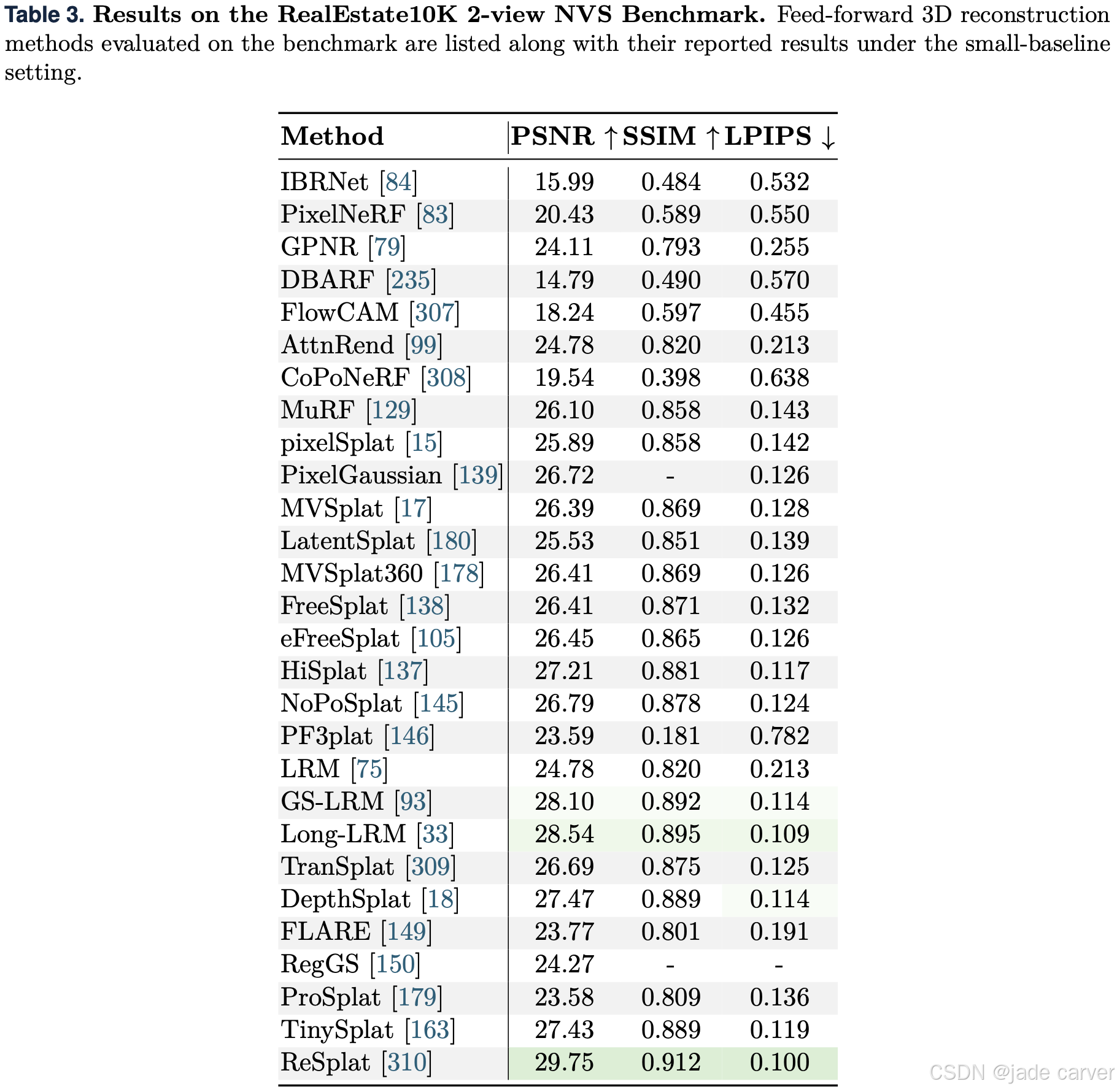
我靠!ReSplat两视图PSNR 29.75!😲
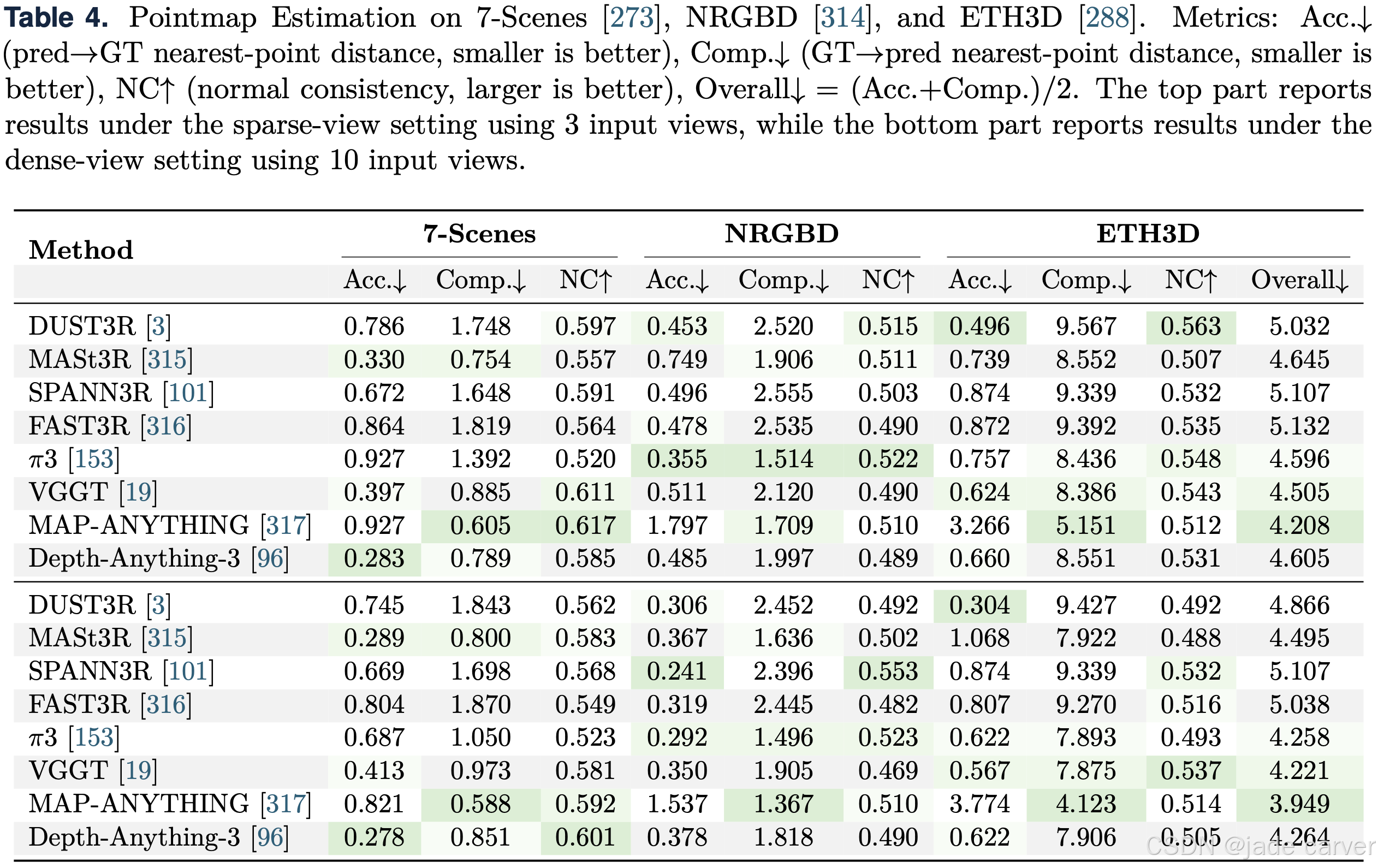
对于点云与位姿重建基准(表4),除了新视图合成外,我们还在7-Scenes 273、NRGBD 314和ETH3D 288上,分别在稀疏视图(3个输入视图)和密集视图(10个输入视图)设置下评估了点图估计。我们报告了精度、完整性、法向一致性和综合评分作为评估指标。
结果表明,在稀疏视图设置下,Depth-Anything-3、π3和Map-Anything分别在7-Scenes、NRGBD和ETH3D上取得了最佳性能。在密集视图设置下,这些方法在其对应数据集上仍然保持最佳表现,观察到了类似的趋势。
6 Applications
在这些场景中,一个共同的目标是用单次前向推理替代逐场景优化,这种推理方式在稀疏或带噪声输入下既要具备可扩展性,又要足够鲁棒。在自动驾驶领域,重点是大规模动态重建,同时需要严格的实时性和时间一致性要求。在机器人领域,快速可泛化的3D表示支持下游决策任务,包括操作和带有显式场景记忆的长期导航。除此之外,前馈式3D先验正越来越多地被用作语义场景理解、SfM/SLAM、数字人,甚至是几何感知的视频生成等任务的骨干。
6.1 Autonomous Driving
自动驾驶为前馈式3D重建带来了独特的挑战,包括大规模动态环境、稀疏的摄像头覆盖范围,以及对低延迟、时序一致场景表示的需求。近期的研究工作聚焦于利用学习先验的前馈式、数据驱动架构,以实现快速且鲁棒的3D场景重建。
静态到动态的扩展 :研究重点已从城市场景的大规模静态重建 (SCube, InfiniCube)转向动态场景建模。通过直接预测4D高斯分布(STORM, Driv3R等)并结合生成式模型(WorldSplat),来捕捉移动物体并保证时序一致性。
鲁棒性解决方案 :针对自动驾驶中常见的稀疏或非重叠摄像头视角问题,研究者们正利用几何先验和深度特征(DrivingForward, EVolSplat, EDUS)来强化模型在信息缺失情况下的单次推断能力。
任务驱动的高效性 :为了满足自动驾驶的实时性要求,出现了面向特定下游任务(如路面建模、全景重建、动态街道生成)的专用流程(BEV-GS, Omni-Scene, DriveGen3D),实现了定制化的实时重建。
6.2 Robotics
6.2.1 Manipulation.
近年来,前馈式3D重建方法通过提供密集的几何与语义表示,实现了快速且可泛化的机器人操作。GraspNeRF 328 从多视角图像中预测 TSDF(截断有符号距离函数),用于高效的 6-DoF(六自由度)抓取检测,包括具有挑战性的透明和镜面物体。ManiGaussian 337 和 ManiGaussian++ 338 利用前馈式 3DGS(3D高斯溅射)来捕捉物体几何形状与动力学特性,其中 ManiGaussian++ 采用分层高斯世界模型来支持复杂的多体及双臂操作。GAF 339、QGFS 340、GaussianGrasper 341 和 EmbodiedSplat 342 将该范式扩展至动作推理、强化学习、开放词汇指令跟随以及个性化真实-仿真-真实导航,所有这些均在前馈式3D框架内完成。
6.2.2 Navigation.
前馈式3D场景表示也通过提供大规模、时间一致的地图用于规划与定位,增强了机器人导航能力。UnitedVLN 343 集成了基于3DGS的记忆,用于全景观测和语义聚合,以支持视觉-语言导航查询。VR-Robo 344 采用GS-网格混合记忆,将照片级真实的3DGS渲染与精确的物理模拟相结合,以实现鲁棒的真实-仿真迁移。GS-LTS 345 利用视觉-语言模型(CLIP、SAM)来检测环境变化,并逐步优化3DGS地图,用于以物体为中心的导航和自适应规划。IGL-Nav 329 从单目视频中构建3DGS,并使用由粗到精的匹配策略,实现有效的实时图像目标定位。
6.3 Scene Understanding
6.3.1 Semantic Feature Fields
前馈式3D重建最近实现了将视觉-语言语义高效集成到3D表示中,支持开放词汇、部件感知和时间一致的3D场景理解,且无需逐场景优化。Semantic Gaussians 346、SemanticSplat 347 和 UniForward 348 将2D语义特征嵌入到3D高斯分布中,同时联合重建几何与外观。
为了提升从稀疏或无位姿视图中的泛化能力,几种方法采用了不同的策略。SLGaussian 330 和 SegMASt3R 349 利用多视图分割一致性,GSemSplat 350 和 LSM 351 采用特征聚合和基于Transformer的编码,而 PartField 352 和 AlignGS 353 则专注于分层或语义-几何正则化。
6.3.2 Spatial Reasoning
前馈式3D方法正越来越多地被用于为多模态大语言模型(MLLMs)提供空间感知能力。许多方法将来自视觉-几何基础模型(例如 VGGT 19、CUT3R 107)的几何先验隐式地融入到视觉编码器中,以增强结构推理和多视图一致性。具有代表性的工作包括:3DRS 354,它从 VGGT 中蒸馏出丰富的3D先验;Spatial-MLLM 355,它添加了一个由 VGGT 初始化的空间分支,并采用空间感知的帧采样策略;VG-LLM 356,它在图像块级别将几何特征与视觉标记进行融合;以及 VLM3R 357,它将几何主干网络替换为 CUT3R,以提升对第一人称视角视频的时间理解能力。
其他方法则维护显式的3D表示来支持时空推理。例如,ST-LLM 358 将第一人称视角视频与离线的点云和相机位姿对齐,为时间推理提供结构化的3D线索。这些方法共同说明了前馈式3D流程如何能够增强视觉-语言模型中的隐式和显式空间推理能力。
6.4 SfM and SLAM
从图像中重建3D场景几何和相机运动是计算机视觉与机器人领域的核心挑战。前馈式和可微分的架构正越来越多地用于统一运动恢复结构(SfM)与即时定位与地图构建(SLAM),使得无需逐场景优化即可直接预测几何和相机位姿。
| 对比维度 | **传统优化范式(SfM / SLAM)** | 新兴前馈可微分范式 |
|---|---|---|
| 核心流程 | 增量式、迭代优化:通过特征匹配、光束法平差、位姿图/因子图优化等步骤,逐步、迭代地求解几何和位姿。 | 端到端、前馈推理:通过可微分神经网络,直接从输入图像(序列)一次性、前向传播地预测出几何和位姿。 |
| 计算方式 | 依赖非线性优化求解器,通常需要针对每个具体场景进行计算密集的迭代优化。 | 通过预训练的通用模型进行一次性前馈计算,无需逐场景的在线优化。 |
| 主要优势 | 精度高,理论成熟,在数据良好、优化充分的场景下结果精确。 | 速度快、效率高,具备可扩展性,便于与深度学习流程集成,在计算资源受限或需要实时性的场景中优势明显。 |
| 主要挑战 | 计算成本高,对初始化敏感,容易陷入局部最优,难以处理无纹理或动态场景,难以端到端训练。 | 对大规模、多样化训练数据依赖性强,模型泛化能力是关键,目前在绝对精度和长期稳定性上可能仍逊于精细优化的传统方法。 |
| 本质区别 | 基于几何与优化理论,将问题建模为能量最小化。 | 基于数据驱动与表示学习,让模型从数据中学习"如何重建和定位"的隐式先验。 |
| 任务领域 | 方法名称 | 核心贡献/技术特点 |
|---|---|---|
| **SfM(运动恢复结构)** | VGGSfM 331 | 端到端可微分架构,从多视图图像联合推断场景几何(如深度、法向)和相机位姿,实现全局一致性重建,避免传统增量SfM的累积误差和串行瓶颈。 |
| **SfM(运动恢复结构)** | Light3R-SfM 359 | 强调轻量化和效率的可微分SfM框架,旨在保持精度的同时大幅提升重建速度,可能采用了高效的网络设计和表示(如3D高斯)。 |
| **SLAM(同步定位与建图)** | MASt3R-SLAM 315 | 端到端前馈SLAM系统,能够实时估计相机轨迹并重建环境的几何表示,不依赖显式的后端优化(如位姿图优化)。 |
| **SLAM(同步定位与建图)** | SLAM3R 360 | 类似MASt3R-SLAM,专注于通过单一前馈网络实现定位与建图的统一推理,强调架构的统一性和实时性。 |
| **SLAM(同步定位与建图)** | VGGT-SLAM 19 | 可能利用视觉-几何-Transformer(VGGT)架构,通过注意力机制更好地建模长序列中的时空依赖关系,提升在复杂轨迹中的鲁棒性。 |
| 高级/混合SLAM系统 | ARTDECO 361 | 整合了多传感器融合(如视觉、惯性、轮式里程计等),利用前馈网络处理异构数据,实现更鲁棒的全局对齐和状态估计。 |
| 高级/混合SLAM系统 | EC3R-SLAM 362 | 可能引入了因子图优化思想的轻量化集成,在保持前馈效率的同时,融入一定的几何优化约束,以提升精度和一致性。 |
| 高级/混合SLAM系统 | MASt3R-Fusion 363 | MASt3R-SLAM的增强版,可能专注于分层高斯解码器,以生成更高保真度、可渲染的场景表示(如用于NeRF的3D高斯),实现"建图即模型"。 |
| 高级/混合SLAM系统 | ViSTA-SLAM 364 | 可能在架构中显式地建模时空注意力 ,专门为处理长序列、复杂视觉轨迹而设计,确保在长时间、大范围运行中的全局一致性。 |
6.5 Video Generation
视频基础模型发展迅速,但时空一致性仍是主要瓶颈。前馈式三维重建为将几何先验注入视频生成提供了有效途径,提升了跨帧一致性、新视角真实感和物理合理性。更广泛地说,视频生成与前馈式重建的结合连接了像素级合成与结构感知建模 ,大致可分为两个方向:重建增强的视频生成 ,即显式三维重建改进视频合成,最终输出仍是视频序列;以及基于视频生成的场景重建,即视频生成模型作为先验,用于产生显式的三维或四维场景表示或几何感知的世界模型
| 对比维度 | 范式一:重建增强的视频生成 | 范式二:基于视频生成的场景重建 |
|---|---|---|
| 核心逻辑 | "以重建促生成" :将3D重建作为结构约束 或先验,提升2D视频的质量。 | "以生成助重建" :利用2D视频生成模型作为知识先验,解决3D/4D重建的数据稀疏性问题。 |
| 主要目标 | 提升输出视频的时空一致性、几何合理性、物理真实感,减少闪烁、抖动、视角错误等。 | 从稀疏或多视角输入中,获得时空一致、高质量的3D/4D显式场景 ,或构建可交互、可推理的世界模型。 |
| 最终输出 | 一个改进后的2D视频序列(像素空间)。 | 一个结构化的3D/4D场景表示 (如点云、网格、高斯、NeRF、动态场)或一个可模拟的世界模型。 |
| 技术关系 | 3D重建服务于视频生成。 | 视频生成服务于3D重建与世界建模。 |
| 类比 | "精装修":在毛坯房(原始视频)基础上,利用3D蓝图(重建)来精确调整,使其更稳固美观。 | "由照片建三维模型":通过大量2D照片(视频生成)的信息,逆向工程出建筑物的完整3D模型。 |
6.5.1 Reconstruction-enhanced video generation
重建增强的视频生成(代表方法)
| 技术路径 | 核心理念 | 代表方法 | 方法与贡献 |
|---|---|---|---|
| 直接耦合 | 在单次前向过程中,将3D重建模块与2D视频生成模型(如扩散模型)紧密集成。 | MVSplat360 178 | 将3D高斯表示与扩散过程结合,在生成每一帧时都通过共享的3D几何场进行约束,确保多视角间的结构一致性。 |
| 在单次前向过程中,将3D重建模块与2D视频生成模型(如扩散模型)紧密集成。 | JOG3R 365 | 引入基于运动恢复结构的稀疏几何,为扩散模型提供相机姿态和场景点云作为条件,引导生成几何合理的视频。 | |
| 迭代优化 | 构建"生成 → 重建 → 优化 → 再生成"的循环流程,通过多次迭代精炼结果。 | GenFusion 366 | 1. 先生成初始视频; 2. 将其重建为3D表示 (如NeRF); 3. 在3D空间应用物理/几何约束进行优化; 4. 从优化后的3D表示渲染出新视角视频,或将其作为条件引导扩散模型生成更一致的视频。 |
| 构建"生成 → 重建 → 优化 → 再生成"的循环流程,通过多次迭代精炼结果。 | Envision 367 | 侧重于物体中心的表示,将视频分解为多个动态物体的3D表示,分别优化其运动和交互,再重新合成,以提升复杂场景的物理合理性和运动一致性。 |
6.5.2 Video generation-based scene reconstruction
| 研究分支 | 核心目标 | 代表方法 | 方法详解与贡献 |
|---|---|---|---|
| 显式动态重建 | 利用视频生成模型强大的2D先验,从稀疏或单目 输入中,生成高质量的3D静态 或4D动态场景模型。 | 4DNex 335 Lyra 368 ShapeGen4D 369 | 通过知识蒸馏 或分数蒸馏采样等技术,从预训练的大规模视频扩散模型中提取关于物体运动、形变、材质的信息,驱动一个可优化的4D场景表示(如动态NeRF、4D高斯),实现"开箱即用"的高质量4D重建。 |
| 几何感知控制 | 在视频生成过程中,通过引入几何感知的中间表示或约束 ,实现精准的视角、布局和运动控制。 | Geometry Forcing 370 | 在扩散模型的去噪过程中,通过一个中间分支预测并"强制"执行3D几何约束(如深度一致性、表面法向),使生成内容在几何上自洽。 |
| 在视频生成过程中,通过引入几何感知的中间表示或约束 ,实现精准的视角、布局和运动控制。 | Spmem 371 | 引入一个持久化的空间记忆模块,在生成长视频时记录和维持场景的全局3D布局,防止物体"忘记"或"漂移",确保长时程空间一致性。 | |
| 在视频生成过程中,通过引入几何感知的中间表示或约束 ,实现精准的视角、布局和运动控制。 | SteerX 372 | 在推理时,通过计算生成帧的几何损失(如与给定深度图的一致性)作为奖励信号,引导采样过程,实现无需重新训练的、基于几何条件的可控生成。 | |
| 世界建模 | 构建一个可长期推演、交互和规划的、具备内在几何与物理理解的世界模型。 | EvoWorld 373 WorldForge 374 FantasyWorld 375 | 将视频生成器与显式3D空间记忆、物体轨迹预测、物理引擎或隐式3D场 相结合。不仅能生成下一帧,还能在内部维护一个不断演化的3D世界状态,支持对场景的长远未来进行一致性推演,是实现具身智能和开放世界模拟的关键一步。 |
6.6 Others
全景图Panorama
360° 全景场景重建 是具有挑战性的三维视觉任务,全景重建的独特挑战(宽基线、球面畸变、高分辨率需求)催生了高度专业化 的解决方案。这些方法不是简单套用普通三维重建框架,而是从**问题本质的几何属性(球面几何)** 出发,进行针对性的模型设计。
- 球面几何建模 :无论是 Splatter-360 的球面代价体积 ,还是 PanSplat 的球面高斯表示 ,都明确地将计算和表示建立在球面坐标系上,这是处理畸变和宽基线的根本途径。
- 高效渲染表示 :3D 高斯泼溅 技术成为主流选择,因其具备可微分、渲染速度快、质量高的特点。PanSplat 进一步将其层次化 和球面化,完美匹配了全景数据对渲染效率的极致要求。
- 鲁棒的神经网络架构 :PanoVGGT 引入了置换等变 Transformer ,这是一种在架构层面内置了对球面图像无序性和畸变不变性的归纳偏置,显著提升了几何参数(位姿、深度)估计的鲁棒性。
从重建到合成的演进:
- Splatter-360 侧重于三维几何的重建本身,提供了一个快速、可泛化的管道。
- PanSplat 则更侧重于重建后的高质量、高效率渲染与合成,目标产出视觉上令人沉浸的全景视觉内容。
- PanoVGGT 聚焦于重建流程中最基础的几何推理环节(位姿与深度估计),为后续的高质量重建与渲染提供可靠输入。
范式统一与前景 :这些工作共同展示了如何将可微分渲染(3DGS) 、几何先验(球面模型) 和鲁棒的深度学习架构(等变Transformer) 相结合,形成一个强大的、端到端的前馈全景处理范式。这不仅是三维重建领域的一个精专分支,其技术(如等变网络、球面表示)也对更广泛的全方位(Omnidirectional)视觉感知 和沉浸式媒体生成具有重要的借鉴意义,标志着我们正从处理"朝向一个方向的场景"迈向理解"包裹整个观察者的环境"。
Localization
传统方法的瓶颈在于特征匹配的脆弱性 和迭代优化的耗时性 。新范式通过神经网络,绕过或简化了显式匹配和复杂优化,要么直接预测结果(姿态回归),要么预测更鲁棒、更易求解的中间表示(密集3D对应),要么将整个场景知识编码进一个可查询的神经模型(神经场景表示)。
直接预测路径(捷径) :如 Reloc3r 和 FastForward,追求极致的速度和简洁性,适用于对实时性要求极高、可接受一定精度损失的场景(如移动AR、机器人快速重定位)。
稠密对应路径(平衡) :如 Multi-View 3D Point Tracker,在"直接回归"和"传统几何"之间取得平衡。它用神经网络学习稳健的、高层语义引导的几何对应 ,再辅以轻量级几何求解,兼顾了鲁棒性、精度和效率,是目前非常活跃的研究方向。
神经场景路径(统一) :如 SAIL-Recon,代表了最彻底的范式变革 。它不再区分"建图"和"定位",而是将整个空间环境学习为一个连续的、可微分的神经函数。定位变为对该函数的查询过程。这为构建通用、紧凑、包含语义和几何的场景记忆开辟了道路,是通向"视觉大模型"或"世界模型"的重要一步。
视觉定位正在从一个独立的几何计算模块,演变为一个基于神经表示的、可学习的场景空间感知能力。这不仅提升了在复杂环境下的定位性能,也为其与更高层次的场景理解、交互和内容生成任务深度融合奠定了技术基础。
Digital humans
近期研究工作已开始探索联合的人-场景建模。在前馈方法中,Human3R 336 将前馈重建扩展至统一的4D人-场景建模,通过单次前向传播联合估计多个SMPL-X人体模型、稠密3D场景和相机轨迹。这一研究方向表明,前馈重建可以超越孤立的人体化身建模,迈向整体性的动态人-场景理解。
Calibration, inpainting and reflection.
近期的前馈方法还被应用于自标定、场景修复(Inpainting)和反射感知重建 等相关问题。在这些任务中,传统的多阶段优化流程在面对未知内参、跨视角歧义或几何缺失时,往往计算成本极其高昂。LoRA3D 382 针对场景特定的重建任务解决了自标定 问题;BevSplat 383 通过基于高斯泼溅的鸟瞰图(BEV)表示,提升了跨视角定位 精度。InstaInpaint 384 利用参考图像引导的前馈重建,从2D修复建议中执行连贯的3D场景补全 ;而 Reflect3R 385 则将镜面反射视为虚拟视角,以支持单图重建和位姿优化。