6. 在 RAG 中 Embedding 究竟是什么?如何选择和评估一个 Embedding 模型?
Embedding 我理解就是把一段文本转成一串数字向量的过程。它有一个很关键的特性,就是语义相近的文本,转出来的向量在数学空间里的距离也近。RAG 里的语义检索就是靠这个实现的,不是关键词匹配,而是看两段内容的意思相不相近。
选模型的话,我主要看三个维度:第一是中文支持,中文场景我会优先选 BGE 系列,效果其实比 OpenAI 的模型还要好;第二是向量维度,维度越高精度越好,但存储成本也越大;第三是最大输入长度,这个决定了能处理多长的 chunk。
评估这块我的建议是不要只看通用排行榜,一定要在自己的业务数据上跑召回测试,那个才是真正有参考价值的。
Embedding 是什么?
Embedding 模型做的事情本质上是「语义压缩」,把一段自然语言文本映射成一个固定长度的浮点数向量。比如一个 1024 维的 Embedding 模型,不管输入的文本是 10 个字还是 500 个字,输出都是一个长度为 1024 的数字列表。
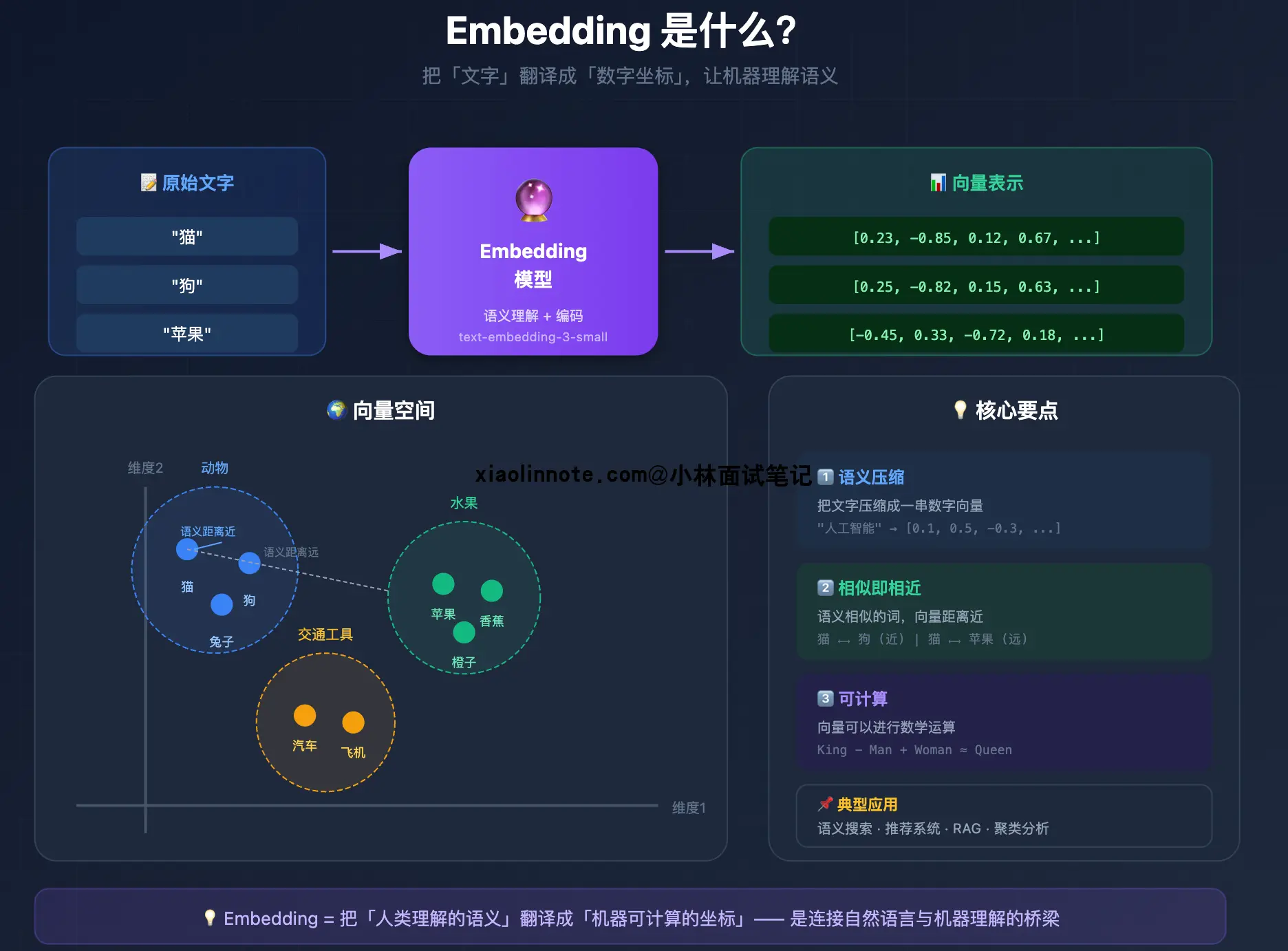 这个映射最关键的性质是:语义相近的文本,向量的余弦相似度高。为什么衡量相似度要用「余弦」而不是直接算两个向量的直线距离?因为在高维空间里,两段文本的向量长度(模长)会受文本长度、表达强度等非语义因素影响,直接比距离会把「长短」和「语义」混在一起。而余弦只看两个向量的方向(也就是夹角),方向越一致余弦值越接近 1,正好把「意思相近」从「文本长短」里剥离出来。你可以把它理解成:两段话如果「指向同一个意思」,它们的向量箭头就朝着同一个方向,至于箭头多长无所谓。
这个映射最关键的性质是:语义相近的文本,向量的余弦相似度高。为什么衡量相似度要用「余弦」而不是直接算两个向量的直线距离?因为在高维空间里,两段文本的向量长度(模长)会受文本长度、表达强度等非语义因素影响,直接比距离会把「长短」和「语义」混在一起。而余弦只看两个向量的方向(也就是夹角),方向越一致余弦值越接近 1,正好把「意思相近」从「文本长短」里剥离出来。你可以把它理解成:两段话如果「指向同一个意思」,它们的向量箭头就朝着同一个方向,至于箭头多长无所谓。
你可能会觉得这没什么了不起的,关键词搜索不也能找到相关内容吗?还真不一样。
比如「苹果手机怎么截图」和「iPhone 如何截屏」,这两句话一个字都不一样,关键词搜索根本匹配不上,但经过 Embedding 之后,两个向量的余弦相似度可能高达 0.95;而「苹果手机」和「苹果汁」虽然都有「苹果」,但语义相差很远,向量距离也会拉开。
这就是语义检索比关键词匹配强的核心原因,它能处理同义词、近义词和不同的表达方式。很多人以为向量检索就是高级的关键词匹配,其实完全不是一回事,它是从「意思」层面在做匹配。
常见 Embedding 模型对比
理解了 Embedding 的原理,接下来就是选模型了。Embedding 模型这两年迭代很快,目前主流的选择大概分几类。
-
第一类是 OpenAI 的 text-embedding 系列 ,
text-embedding-3-small是性价比最高的,1536 维,支持降维到 256 维来节省存储,调用方便,英文效果非常好;缺点是 API 调用有费用,而且数据要发到 OpenAI 服务器,有些企业有数据出境合规问题。 -
第二类是 BGE 系列(北京智源研究院出品) ,
bge-large-zh-v1.5是经典的中文开源模型,1024 维,可以本地部署,数据不出境。不过要注意的是,BGE 虽然仍然是很好的选择,但已经不是中文场景的唯一首选了。bge-m3是 BGE 的多语言版本,同时支持中英日等多种语言,1024 维,而且支持三种检索模式(稠密向量、稀疏向量、ColBERT 式多向量),适合中英文混排的场景。 -
第三类是新一代高性能模型 ,这两年涌现了一批在 MTEB 排行榜上超过 BGE 的模型。
Qwen3-Embedding(阿里通义出品)在多语言基准上表现突出,中文效果很强;Voyage-3-large在英文检索上精度超过 OpenAI 的模型;Cohere embed-v4支持 128K 超长上下文,适合长文档场景;Gemini Embedding(Google 出品)在多个评测中表现均衡。如果你在 2025-2026 年做新项目,建议关注这些新模型,在自己的数据上做测评后再选型。
如何选择 Embedding 模型?
聊完了模型分类,具体到你自己的项目,该怎么选?选模型的时候主要看这几个判断点。
-
第一是中英文比例 :知识库以中文为主,可以选
bge-large-zh-v1.5或者更新的Qwen3-Embedding;中英混合,选bge-m3;纯英文或追求省事,选text-embedding-3-small。 -
第二是数据合规要求:数据不能出境,就必须用可以本地部署的开源模型,BGE 系列和 Qwen3-Embedding 都是很好的选择。
-
第三是向量维度对存储和检索速度的影响:维度越高精度越好,但存储空间和检索时间都会增加。百万量级的知识库,1024 维是个合理的平衡点;如果规模很小,1536 维也无所谓。有些新模型(如 text-embedding-3-small)支持 Matryoshka 降维,可以灵活调整维度来平衡精度和成本。
如何评估 Embedding 模型?
这里有一个常见的误区:很多人拿 MTEB 这类通用排行榜的分数来选模型,觉得分数高就一定好。MTEB 是一个权威的文本 Embedding 通用排行榜,用多种标准数据集评测模型的语义搜索能力,是好的参考。
但它用的是通用数据集,你的业务场景(比如医疗问诊、法律文档、客服知识库)和通用数据分布差异很大,排行榜第一的模型不一定适合你。就好比高考状元不一定擅长你那个行业的专业考试,测评的数据分布不对,分数就没有参考意义。
正确的评估方法是在自己的业务数据上测:准备几百条业务相关的「问题 + 正确答案 chunk」对,分别用候选模型做检索,看正确的 chunk 有没有出现在前 K 条结果里。这个指标叫 Hit@K,Hit@5 = 0.8 的意思就是,80% 的问题,它对应的答案都出现在了检索结果的前 5 条里。通常 Hit@5 低于 0.7 就要考虑换模型或者改进 Chunking 策略了。这种贴近真实场景的评估,比排行榜分数更有参考价值。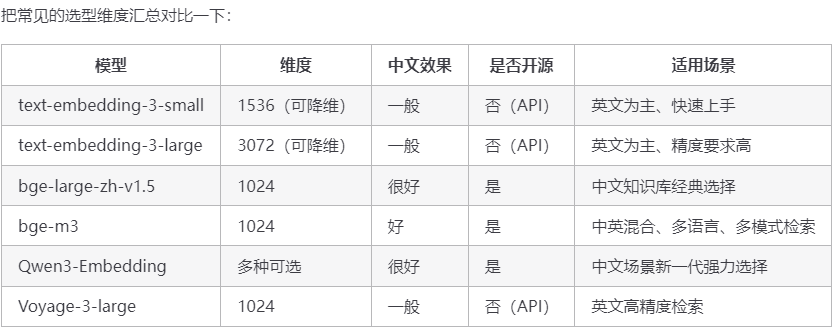
回答要讲清三点。
第一,Embedding 不只是「文本变向量」,关键是语义相近的文本向量距离近,这才是语义检索的基础。
第二,选模型要看场景:中文场景 BGE 和 Qwen3-Embedding 都是很好的开源选择,中英混合用 bge-m3,有数据合规要求就用开源模型本地部署。
第三,评估模型不要只看 MTEB 排行榜,要在自己的业务数据上跑 Hit@K 测试,这才是真正有参考价值的。
如果面试官追问「你用的什么模型,为什么选它」,你可以说「中文场景用 bge-large-zh-v1.5 或 Qwen3-Embedding,在自己的业务数据上 Hit@5 达到 0.8 以上,最终根据测评结果选的」,这个回答有理有据。
7. Embedding 有哪几种算法你了解过吗?
Embedding 算法大致经历了三代演进。
第一代是静态词向量,以 Word2Vec 和 GloVe 为代表,把每个词映射成固定向量,但同一个词不管上下文是什么,向量永远不变,处理不了多义词。
第二代是以 BERT 为代表的上下文相关向量,同一个词在不同语境下有不同的向量,表达能力大幅提升,但 BERT 本身输出的是 token 级别的向量,两个句子要比较相似度就必须拼在一起跑,百万条文档就要跑百万次,检索速度完全不可接受。
第三代是以 SBERT、SimCSE、BGE 为代表的句子级对比学习 Embedding,专门为「两段文本有多相似」这个任务优化,能提前把所有文档向量算好存起来,查询时只需算一次,是 RAG 场景的标配。
为什么 Embedding 算法要一代代演进
要理解各代算法的设计动机,先想一个最简单的问题:怎么让计算机理解「苹果手机怎么截图」和「iPhone 如何截屏」是同一个问题?
关键词匹配完全没用,因为这两句话没有一个共同的词。早期 NLP 系统为了解决这个问题,走向了「把词变成向量」这条路,向量空间里的距离代表语义距离,这就是 Embedding 的核心出发点。
你可能会想,既然都是把文本变成向量,搞一套方案不就行了,为什么还要一代一代演进?原因很简单:每一代方案解决了一类问题的同时,都暴露出了新的短板。第一代处理不了多义词,第二代处理了多义词但在检索场景下慢得无法实用,第三代才真正把「语义检索」这件事做到既能用又好用。理解了这个「每一代在补上一代的坑」的逻辑,后面三代算法的设计思路就很好懂了。
第一代:静态词向量(Word2Vec / GloVe / FastText)
先来看第一代算法。它们的核心思路非常朴素:用一个词周围的词来预测这个词,或者反过来用这个词来预测周围的词。通过大量文本训练,语义相近的词自然就会在向量空间里被推到一起。
Word2Vec 是这一代最有影响力的代表,2013 年 Google 提出。它有两种训练方式:CBOW(用周围词预测中心词)和 Skip-gram(用中心词预测周围词)。为什么 Skip-gram 更常用?因为它从一个词能产生多个训练样本(用这个词预测周围每一个词),样本利用率更高,对低频词尤其友好;CBOW 在大数据集上收敛更快,但两者最终效果通常比较接近,细节上 Skip-gram 对生僻词表现更好,所以更常作为默认选项。训练完之后,每个词对应一个固定的向量,「国王 - 男人 + 女人 ≈ 女王」这个著名的类比就是用 Word2Vec 向量做到的,当时整个 NLP 圈都为之兴奋。
GloVe(Global Vectors for Word Representation)是斯坦福提出的,思路和 Word2Vec 类似但更系统,直接对整个语料库的词共现矩阵做分解,对全局统计信息的利用更充分。实际效果和 Word2Vec 差不多,很多场景两者可以互换。
FastText 是 Facebook 提出的改进,解决了一个很实际的问题:Word2Vec 处理不了「未登录词」,也就是训练集里从没见过的词。你可能会觉得这有什么大不了的,但在真实业务里,新词、专有名词、网络流行语不断冒出来,处理不了新词就意味着检索直接断链。FastText 的解法很巧妙------把词拆成字符级别的 n-gram 子词,比如「苹果」会被拆成「苹」「果」「苹果」等子片段,每个子片段有自己的向量,一个词的向量是其子片段向量的平均。这样遇到没见过的新词,只要子片段见过,就还能估算出一个合理的向量。
这一代算法的共同局限性是两个字:静态。每个词只有一个固定向量,不管上下文如何。「我吃了苹果」里的「苹果」和「苹果手机发布了」里的「苹果」,向量完全相同。很多人以为 Word2Vec 已经理解了语义,其实它只是记住了「哪些词经常一起出现」,真正的语义理解还差得远。这个致命缺陷直接催生了第二代算法。
第二代:上下文相关向量(ELMo / BERT)
理解了第一代「一个词永远只有一个向量」的局限,第二代算法的改进方向就很明确了:让词的向量随上下文动态变化,同一个词在不同句子里有不同的向量表示。
ELMo(2018 年,Allen NLP 提出)用双向 LSTM 来建模,同时从左往右和从右往左扫描句子,把两个方向的隐藏状态拼起来作为词的上下文向量。ELMo 是第一个实用的上下文 Embedding,当时在多个 NLP 任务上大幅刷新了成绩。
BERT(2018 年,Google 提出)用 Transformer 替代 LSTM,引入了 Masked Language Model 预训练任务,效果全面超越 ELMo,成为 NLP 领域最重要的里程碑之一。BERT 用 CLS token 来表示整个句子,同时看到前后文(双向),表达能力远超单向模型。
但问题来了,BERT 这么强,为什么 RAG 检索不用它?很多人以为 BERT 效果好就万事大吉,其实不是。
BERT 有一个在检索场景下极其致命的缺陷:要比较两个句子的相似度,必须把两个句子拼在一起喂给 BERT,让 CLS 来做判断。这意味着每次检索都要把查询和每一个候选 chunk 拼在一起跑 BERT,百万条文档的知识库就要跑百万次。
你可能觉得百万次也不算多吧?别忘了 BERT 一次前向传播就要几十毫秒,百万次就是好几个小时,用户根本等不起。这个问题直接导致了第三代的诞生。
第三代:句子级对比学习 Embedding(SBERT / SimCSE / BGE)
第二代 BERT 虽然语义理解能力强,但「必须两两拼接」这个限制让它在检索场景下完全没法用,这就引出了第三代的核心理念:能不能让每个句子独立生成一个向量,然后直接用余弦相似度来比较?
第三代专门针对「句子相似度」和「语义检索」这个任务优化,是 RAG 系统的标配。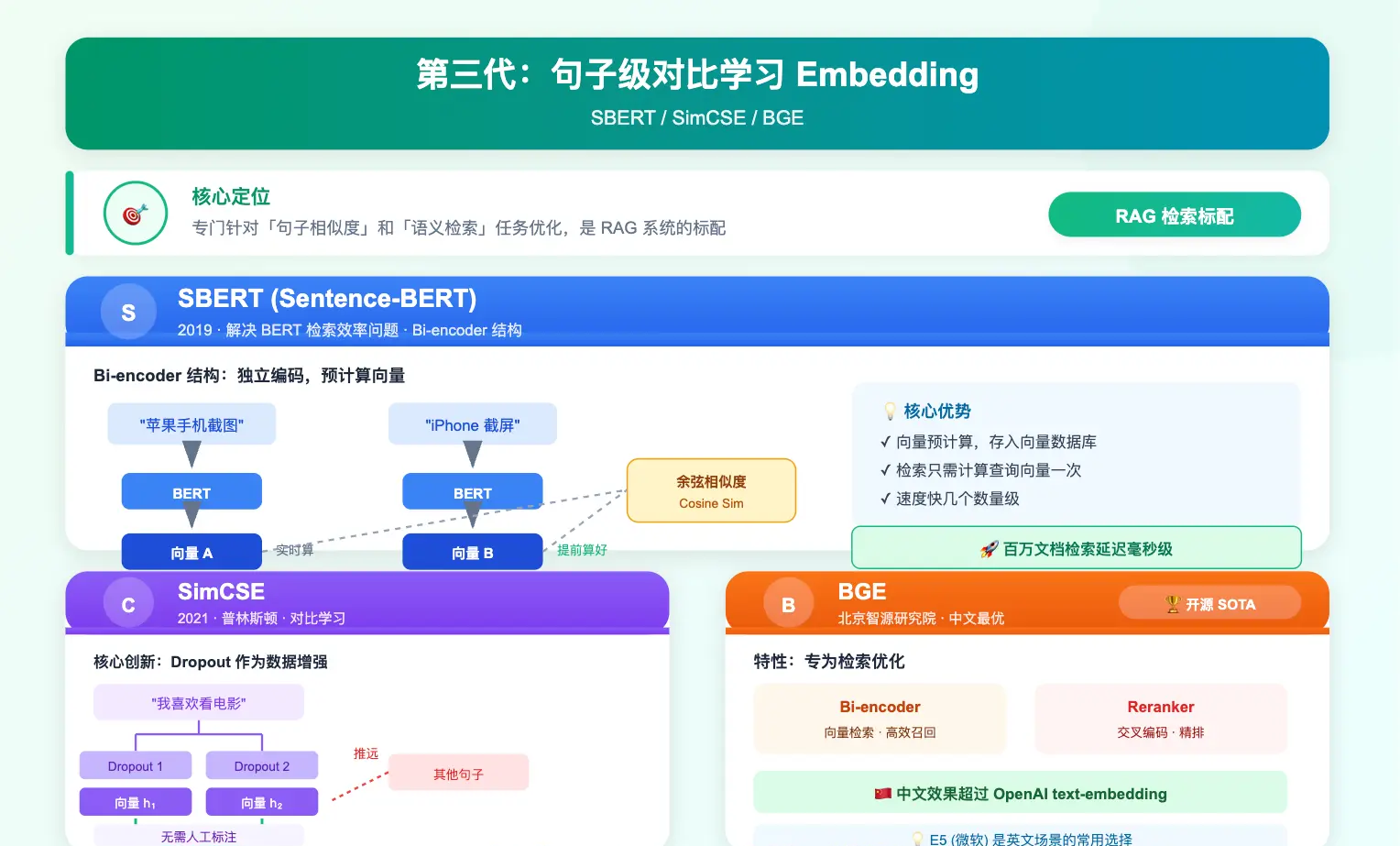
SBERT(Sentence-BERT,2019 年)就是用这个思路解决了 BERT 在检索场景下用不了的问题。它用 bi-encoder 结构:两个句子分别独立过 BERT,各自得到一个句子级向量,然后只用余弦相似度来衡量两个向量的距离。
你可能会问,这样精度不会下降吗?确实会一点,因为两个句子是分开编码的,模型在编码阶段看不到两句话 token 之间的交叉关系(Cross-Encoder 那种「每个 token 都能和另一句的每个 token 互相注意到」的深度交互就被牺牲掉了),所以在特别微妙的匹配上会不如 Cross-Encoder。
但换来的是速度提升了几个数量级,知识库里所有文档的向量可以提前算好存起来,每次检索时只需要算一次查询向量,然后做余弦相似度就行,毫秒级返回。在 RAG 这种「速度优先」的场景里,这个取舍完全值得。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
# 查询和文档分别独立编码,不需要拼在一起
query = "苹果手机怎么截图"
doc = "iPhone 截屏方法"
query_vec = model.encode(query) # 检索时实时算
doc_vec = model.encode(doc) # 提前算好,存向量库
# 余弦相似度衡量语义距离
from sklearn.metrics.pairwise import cosine_similarity
score = cosine_similarity([query_vec], [doc_vec])SimCSE(2021 年,普林斯顿提出)进一步提升了句子 Embedding 的质量。核心思路是对比学习:把同一句话做两次 dropout 得到两个不同的向量,把这两个向量作为正样本对,让模型学会把它们拉近;同时把同一个 batch 里其他句子的向量作为负样本,把它们推远。这个方法训练非常简单,不需要人工标注,但效果很好。
它解决了一个很多人不知道的问题:BERT 原生的句子向量存在「各向异性」,也就是说向量分布是扭曲的,都挤在一个窄小的锥形区域里,没有充分利用向量空间。SimCSE 通过对比学习把向量「撑开」了,让语义空间变得更均匀。
BGE(BAAI General Embedding,北京智源研究院)是中文 RAG 场景非常流行的开源模型,基于对比学习在大规模中英文数据上训练,同时支持 bi-encoder 和 reranker 两种形态,专门为检索场景优化。E5(微软)是另一个常用的英文对比学习 Embedding,效果同样优秀。
值得一提的是,第三代模型还在持续进化。2025-2026 年出现了几个重要的新趋势。
指令感知 Embedding(比如 Qwen3-Embedding),模型能根据检索指令动态调整向量表示,同一段文本在「找相似问题」和「找答案」两种意图下会产生不同的向量。
Matryoshka 表示学习(MRL),模型训练时让向量的前 N 维就能表达有意义的语义,这样你可以灵活地截断维度来平衡精度和存储成本。
多模态 Embedding,同一个模型既能编码文本也能编码图片,让 RAG 可以做到文本和图片的跨模态检索。
这些新趋势不是独立的第四代,而是在第三代对比学习的基础上做的增强,但面试时如果能提到,会显示你对最新进展有关注。
8. 什么是向量数据库?有没有做过向量数据库的对比选型?
向量数据库是专门用来存储和检索高维向量的数据库,核心能力是近似最近邻搜索,也叫 ANN,能在百万甚至亿级的向量里快速找出最相似的几条。
普通关系型数据库的索引结构对高维向量基本上是失效的,所以需要专门的数据库来处理这个场景。
我自己做过一些选型,本地开发阶段我用 Chroma,零配置上手极快;生产环境的中小规模我推荐 Qdrant,性能不错、API 也比较简洁;如果到了超大规模就要考虑 Milvus 了,字节和小米都在用;不想自己运维的话 Pinecone 是一个云托管的选项;如果项目里已经有 PostgreSQL,也可以直接用 pgvector 插件,不用引入新组件。
什么是向量数据库?
向量数据库就是专门用来存储和检索「向量」的数据库。
这里的向量,指的是嵌入模型(Embedding Model)把文本、图片、音频这些内容转换成的一串浮点数,比如一句话可能被转换成 0.12, -0.87, 0.34, ... 这样一个 768 维或 1024 维的数组。每一个向量代表了这段内容的「语义含义」,语义越相近的内容,它们的向量在高维空间里的距离就越近。
向量数据库支持的核心操作叫做 近似最近邻搜索(ANN,Approximate Nearest Neighbor):给你一个查询向量,在库里找出和它最相似的 K 个向量,返回对应的原始内容。这正是 RAG 里「检索」那一步的底层支撑------用户问了一个问题,先把问题转成向量,再去向量数据库里找最相关的文档片段,最后喂给大模型生成回答。
很多人会把向量数据库和「MySQL 加个向量字段」混为一谈,其实这两者有本质区别。用一句话概括就是:MySQL 擅长精确匹配(WHERE id = 123),向量数据库擅长语义相似(「找和这个意思最接近的内容」)。两者解决的是完全不同的问题,不是互相替代的关系。
为什么需要专门的向量数据库?
理解了向量数据库是干什么的,接下来自然会问:为什么不直接在 MySQL 或者 ES 里存向量,非要引入一个新的数据库?
普通的关系型数据库(MySQL、PostgreSQL)在存储结构化数据时靠 B-tree 索引,查询 WHERE id = 123 这种精确匹配效率极高。但向量检索要做的事完全不同------不是找「等于」的,而是找「最相近」的,没有精确匹配,只有相似度排序。
高维向量(比如 1024 维)的相似度搜索如果暴力遍历,把查询向量和库里每一条向量都算一遍余弦相似度,百万条数据就要算一百万次,延迟完全不可接受。
那为什么不用 B-tree 加速?因为 B-tree 只能处理一维的有序索引,对高维向量这种「多个维度同时要考虑距离」的场景基本是失效的。你不可能对一个 1024 维的向量建一个 B-tree,然后说「帮我找和它最近的」,因为「近」本身是一个高维空间的综合判断,不是某一个维度上的排序。
向量数据库的价值就在于用专门的索引结构把这个搜索加速,在可接受的精度损失下把延迟降到毫秒级。理解了这个核心价值,接下来我们看它是怎么做到的。
核心索引算法:HNSW 和 IVF
向量数据库之所以能做到毫秒级检索,秘密全在索引算法上。目前主流的索引算法有两种:
先说 HNSW(Hierarchical Navigable Small World),这是目前召回率最高的 ANN 算法之一。它构建的是一个多层图结构,查询时从最上层的稀疏图开始导航,逐层收窄范围,最终在底层找到最近邻。你可以把它想象成在地图上找最近的餐厅:不是把全国所有餐厅都遍历一遍,而是先在全国层面找到大致方向,再锁定到省、市、区,一层一层缩小,效率极高。HNSW 的优点是召回率高(通常在相同延迟下能到 95%+ 的召回率)、查询速度快;缺点是建索引时内存消耗大,不适合内存极度受限的场景。Qdrant、Milvus、Chroma 默认都用 HNSW。
IVF(Inverted File Index) 是另一种思路,它先对向量做聚类,把相似的向量分进同一个「桶」里,查询时只搜最相关的几个桶,而不是全量遍历。这就像图书馆的分类体系:找一本编程书,不需要把整个图书馆翻一遍,先找到「计算机科学」那个区域,再在里面找,范围大幅缩小。IVF 的优点是内存占用小、适合超大规模;缺点是精度比 HNSW 略低,需要调参(聚类数量 nlist、搜索桶数量 nprobe)。Milvus 在超大规模场景下会用 IVF 系列索引。
你可能会问,HNSW 精度高、速度快,为什么还需要 IVF?原因很简单:HNSW 的内存消耗和向量数量成正比,到了亿级规模内存可能扛不住。IVF 用聚类换内存,牺牲一点精度就能处理超大规模数据,两者各有适用场景。
向量数据库的核心能力
搞清楚了索引算法这个底层核心,再来看向量数据库在工程层面需要具备哪些能力。光有 ANN 搜索还不够,生产级系统还要支持几个关键特性:
第一个是 Metadata 过滤,也叫混合检索。实际业务里,知识库往往有多个部门、多个产品线的文档,用户查的时候只想搜「技术部的文档」或者「2024 年更新的内容」。向量数据库支持给每个向量挂上 metadata 字段,检索时加过滤条件,只在符合条件的子集里做 ANN 搜索。你可能会想,为什么不先 ANN 搜完再过滤?因为那样可能搜出来的 Top-K 结果大部分都不满足条件,白白浪费了检索名额。先过滤再 ANN 搜索,能保证召回的每一条都是真正想要的。
第二个是实时更新。RAG 的知识库经常需要新增、修改、删除文档,向量数据库需要支持增量更新。很多人以为向量索引建好就不能动了,其实主流的向量数据库都支持在线写入,新数据进来后增量构建索引,不需要停服重建。
第三个是与关键词检索融合。纯向量检索对一些精确词语(比如产品型号「GPT-4o」、专有名词)的效果不好,有些向量数据库同时支持向量检索 + BM25 关键词检索,做混合召回效果更好。
选型建议
了解了向量数据库的核心原理和能力之后,最后来看一个很实际的问题:到底选哪个?
选向量数据库主要看三个维度:数据规模、部署方式、是否需要混合检索。
中小到大规模、团队小、快速上线,首选 Qdrant,性能好、API 设计简洁、文档完善,Docker 一条命令就能部署,Rust 写的性能很稳。Qdrant 现在也支持分布式模式(分片 + 副本),实际已经有亿级规模的生产案例,覆盖面比较广。很多团队一开始用 Chroma 做原型,后来上生产就切到 Qdrant,这个路径很常见。
说到 Chroma ,它确实是上手最快的选项,Python 直接 pip install,本地内存运行,零配置,配合 LangChain/LlamaIndex 原生集成非常方便。Chroma 现在也支持了 Client-Server 模式和 Chroma Cloud 托管服务,不再只是本地嵌入式了,而且在 2025 年还加入了 BM25/SPLADE 稀疏向量的混合检索支持。不过要注意的是,Chroma 的分布式能力还在成熟中,对于超大规模(千万级以上)的生产场景,它的稳定性和性能还不如 Milvus 和 Qdrant 这些专门为大规模设计的方案。总结来说,Chroma 适合快速原型验证和中小规模的生产使用,超大规模就要考虑其他选项了。
数据规模在千万到亿级,需要分布式,选 Milvus,国内大厂用得最多,支持多种索引类型,有完整的集群方案,但部署运维复杂度也高,团队需要有足够的人力来维护。
不想运维,数据在云上,用 Pinecone,全托管 SaaS,按用量付费,适合快速验证商业化产品。不过要注意数据出境的问题,如果业务数据有合规要求,Pinecone 就不合适了。
已经在用 PostgreSQL,数据量不是特别大,可以直接用 pgvector 插件,不用引入新组件,查询可以和业务数据做 SQL JOIN,运维成本为零。
向量数据库是专门为高维向量的相似度搜索设计的,核心能力是 ANN(近似最近邻搜索),普通关系型数据库的 B-tree 索引对高维向量检索基本是失效的,这不是加个字段就能解决的问题。
面试官追问选型标准的时候,你要从数据规模、部署方式、是否需要混合检索三个维度来回答。
快速原型验证用 Chroma,中小到大规模生产环境推荐 Qdrant,超大规模选 Milvus 做分布式,不想运维就上 Pinecone,已有 PostgreSQL 的项目直接用 pgvector 插件就够了。
每个选项的适用场景和优劣势都要说清楚,千万别拿 GitHub Star 数量当选型依据。另外,索引算法至少要能讲清楚 HNSW 和 IVF 的区别和适用场景,这是向量数据库的核心技术,面试官一定会问。