WicePlus C编译器完全指南:EM78系列微控制器开发实战
- 一、引言
-
- [1. 文档概述](#1. 文档概述)
- 二、C语言基础理论
-
- [1. 数据类型详解](#1. 数据类型详解)
-
- (1)基本数据类型表
- [(2) 数据类型转换注意事项](#(2) 数据类型转换注意事项)
- [2. 预处理命令](#2. 预处理命令)
-
- [(1) #include 指令](#include 指令)
- [(2) #define 宏定义](#define 宏定义)
- (3)条件编译指令
- [3. 运算符与优先级](#3. 运算符与优先级)
- [4. 控制语句](#4. 控制语句)
-
- [(1) 条件语句](#(1) 条件语句)
- (2)循环语句
- [(3) 跳转语句](#(3) 跳转语句)
- [5. 函数](#5. 函数)
-
- [(1) 函数声明与定义](#(1) 函数声明与定义)
- [(2) 函数调用约定](#(2) 函数调用约定)
- [6. 特殊数据类型](#6. 特殊数据类型)
-
- [(1) 枚举类型](#(1) 枚举类型)
- [(2) 结构体类型](#(2) 结构体类型)
- [(3) 联合类型](#(3) 联合类型)
- [(4) 数组](#(4) 数组)
- (5) 指针 指针)
- 三、硬件相关编程
-
- [1. 寄存器页(rpage)](#1. 寄存器页(rpage))
- [2. I/O控制寄存器页(iopage)](#2. I/O控制寄存器页(iopage))
- [3. RAM区(bank)](#3. RAM区(bank))
- [4. 位数据类型](#4. 位数据类型)
- [5. 间接寻址](#5. 间接寻址)
- [6. ROM内函数定位](#6. ROM内函数定位)
- [7. 常量数据存储](#7. 常量数据存储)
- [8. 嵌入汇编](#8. 嵌入汇编)
- [9. 中断处理](#9. 中断处理)
-
- (1)中断保护程序
- [(2) 中断服务程序](#(2) 中断服务程序)
- [(3) 寄存器保护策略](#(3) 寄存器保护策略)
- [四、 C语言与内嵌汇编:在高级语言中驾驭底层指令](#四、 C语言与内嵌汇编:在高级语言中驾驭底层指令)
-
- [1. 为什么要用内嵌汇编](#1. 为什么要用内嵌汇编)
- [2. 内嵌汇编的基本语法](#2. 内嵌汇编的基本语法)
- [3. C变量如何在汇编中访问](#3. C变量如何在汇编中访问)
- [4. 页面切换的黄金法则](#4. 页面切换的黄金法则)
- [5. 内嵌汇编与编译器优化的冲突](#5. 内嵌汇编与编译器优化的冲突)
- 五、与汇编代码转换对照表
-
- [1. 基本数据类型转换](#1. 基本数据类型转换)
- [2. 控制结构转换](#2. 控制结构转换)
-
- [(1) 循环语句](#(1) 循环语句)
- [(2) While循环](#(2) While循环)
- [3. 位操作转换](#3. 位操作转换)
- [4. 算术运算转换](#4. 算术运算转换)
- 六、常见问题
-
- [1、 函数参数最多是多少](#1、 函数参数最多是多少)
- [2、 函数调用最深可到多少层?](#2、 函数调用最深可到多少层?)
- 3、数组能开多大
- 4、代码超出ROM范围会提示错误吗?
- [5、 可以给中断子程序分配ROM地址吗?](#5、 可以给中断子程序分配ROM地址吗?)
- [6、 如何在`*.h`文件里定义全局变量?](#6、 如何在
*.h文件里定义全局变量?) - [7、 C语言中如何切换程序页或RAM区](#7、 C语言中如何切换程序页或RAM区)
- [8、 如何分析堆栈调用深度](#8、 如何分析堆栈调用深度)
- [9. 编译器偷偷占用了哪些RAM](#9. 编译器偷偷占用了哪些RAM)
- 七、总结
一、引言
1. 文档概述
核心特性:
- 完整支持ANSI C标准子集
- 集成开发环境(IDE)一体化
- 支持硬件仿真调试
- 提供丰富的寄存器窗口监视功能
二、C语言基础理论
(1)换算关系
1 1 1 字节 = 8 8 8 位 = 8 8 8 比特 ( 1 1 1 位 = 1 1 1 比特) 1 1 1 KB = 1024 1024 1024
字节(Bytes)
在工程实践中,针对您提供的这种硬件寄存器(如 RCC_CR),最标准且可维护性最高的封装方式是使用 C 语言的 结构体(
struct) 结合 位字段(bit-field) 和 联合体(union)。这种封装的核心目的是将硬件的物理地址映射为逻辑结构体,让开发者可以通过访问结构体成员(如 rcc->hseon = 1)来直接操作寄存器,而不是通过晦涩的位运算
(*(volatile uint32_t *)0x40021000 |= (1 << 16))。
c/* 引入标准库,定义基础类型 (遵循规范 5-2 和 5-12) */ #include <stdint.h> /* 假设外设基地址定义 (通常由芯片厂商提供) */ #define RCC_BASE_ADDR 0x40021000UL /* 定义访问权限类型 (遵循规范 6-3 关于 volatile 的使用) */ typedef volatile uint32_t reg32_t;
c/* 封装 RCC_CR 寄存器 */ typedef union { reg32_t value; // 用于整体读写 (32位) struct { /* 高位在前 (Big-endian bit order) 或低位在前取决于编译器 */ /* 以下按图中从 31 到 0 的顺序排列 */ uint32_t reserved_31_26 : 6; // 31:26 保留 uint32_t pllrdy : 1; // 25 PLL 时钟就绪标志 uint32_t pllon : 1; // 24 PLL 使能 uint32_t reserved_23_19 : 5; // 23:19 保留 uint32_t csson : 1; // 18 时钟安全系统使能 uint32_t hsebyp : 1; // 17 HSE 旁路 uint32_t hserdy : 1; // 16 HSE 时钟就绪标志 uint32_t hseon : 1; // 15 HSE 使能 uint32_t hsical : 8; // 7:0 HSI 时钟校准值 uint32_t hsitrim : 5; // 4:0 HSI 时钟微调值 uint32_t reserved_0_1 : 2; // 1:0 保留 (图中 1:0 是 HSI ON? 需核对手册) // 注:原图中 1:0 是 HSI 相关,这里做保留处理 } bits; } RCC_CR_TypeDef; /* --------------------------------------------------------- * 定义 RCC 外设寄存器组 * --------------------------------------------------------- */ typedef struct { RCC_CR_TypeDef CR; // 偏移 0x00: 时钟控制寄存器 // 其他寄存器如 CFGR, CIR... 可以在这里继续添加 // RCC_CFGR_TypeDef CFGR; // 偏移 0x04 } RCC_TypeDef; /* --------------------------------------------------------- * 全局句柄指针 (遵循规范 6-30 简化访问) * --------------------------------------------------------- */ #define RCC ((RCC_TypeDef *)RCC_BASE_ADDR)
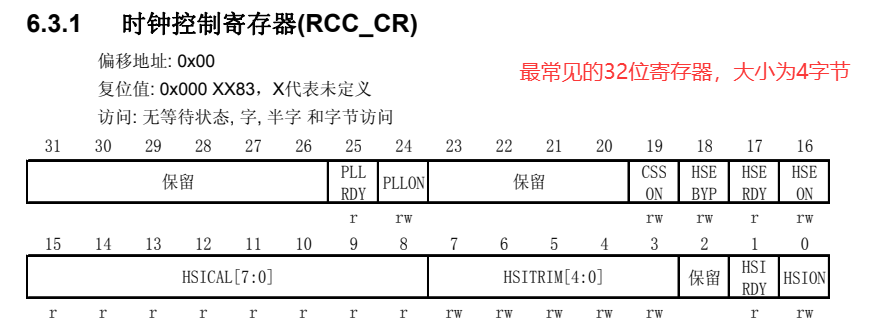
(2)内存常用换算关系
1 1 1 TB = 1024 1024 1024 GB
1 1 1 GB = 1024 1024 1024 MB
1 1 1 MB = 1024 1024 1024 KB
1 1 1 KB = 1024 1024 1024 Byte(字节)
1. 数据类型详解
(1)基本数据类型表
| 类型 | 范围 | 存储大小 | 说明 |
|---|---|---|---|
void |
N/A | 无 | 空类型 |
char |
-128 ~ 127 | 1字节 | 单字符 |
unsigned char |
0 ~ 255 | 1字节 | 无符号字符 |
int |
-128 ~ 127` | 1字节 | 整型 |
unsigned int |
0 ~ 255 | 1字节 | 无符号整型 |
short |
-32768 ~ 32767 | 2字节 | 短型数 |
unsigned short |
0 ~ 65535 | 2字节 | 无符号短型数 |
long |
-2147483648 ~ 2147483647 | 4字节 | 长型数 |
unsigned long |
0 ~ 4294967295 | 4字节 | 无符号长型数 |
bit |
0 ~ 1 | 1位 | 位类型 |
⚠️ 重要限制:
- 不支持 float 和 double 类型
- 数组最大为 32字节(RAM区)
- 常量数组最大有效值为 255字节
(2) 数据类型转换注意事项
c
// CN: 数据类型转换示例 -- EN: Data type conversion examples
// CN: 错误示例 - 可能导致数据丢失 -- EN: Wrong example - may cause data loss
int I1 = 0x11;
int I2 = 0x22;
short S1;
S1 = I1 * I2; // CN: 错误!结果只有1字节 -- EN: Wrong! Result is only 1 byte
// CN: 正确做法 - 强制类型转换 -- EN: Correct approach - type casting
S1 = (short)I1 * (short)I2; // CN: 显式转换确保2字节结果 -- EN: Explicit casting ensures 2-byte result
// CN: 长整型运算注意事项 -- EN: Long integer operation notes
/*
长整型乘法/除法/取模运算会占用 bank 0 的 0x20~0x24 (5字节)
因此在进行这些运算时,请勿使用这些地址
*/2. 预处理命令
(1) #include 指令
c
// CN: #include 指令详解 -- EN: #include directive detail
// CN: 尖括号形式 - 先搜索EMC_INCLUDE目录 -- EN: Angle bracket - search EMC_INCLUDE first
#include <EM78.h> // CN: 系统头文件 -- EN: System header
// CN: 双引号形式 - 先搜索工作目录 -- EN: Quotation marks - search working directory first
#include "project.h" // CN: 用户自定义头文件 -- EN: User defined header
// CN: 多源文件编程示例 -- EN: Multi-source file programming example
/* headfile.h */
unsigned int uaa; // CN: 全局变量声明 -- EN: Global variable declaration
/* kkdr.c */
extern unsigned int uaa; // CN: 外部引用声明 -- EN: External reference declaration
/* testcode.c */
void func(void)
{
uaa = 0x29; // CN: 使用外部变量 -- EN: Use external variable
}(2) #define 宏定义
c
// CN: 宏定义详解 -- EN: Macro definition detail
// CN: 简单宏定义 -- EN: Simple macro
#define MAXVALUE 10
// CN: 带参数宏定义 -- EN: Macro with parameters
#define sqr2(x, y) x * x + y * y
// CN: 多行宏定义(使用反斜杠续行)-- EN: Multi-line macro (using backslash)
#define SetIO(portnum, value) \
_asm {mov a, @value} \
_asm {iow portnum}
/*
注意事项:
1. 多行宏定义行之间应该用"\"包含起来
2. "\"后不能使用任何字符
*/(3)条件编译指令
c
// CN: 条件编译指令详解 -- EN: Conditional compilation directives
// CN: #if, #else, #elif, #endif -- EN:
#define RAM 30
#if (RAM < 10)
#define MAXVALUE 0
#elif (RAM < 30)
#define MAXVALUE 10
#else
#define MAXVALUE 30
#endif
// CN: #ifdef, #ifndef -- EN:
#define DEBUG 1
#ifdef (DEBUG)
#define MAXVALUE 10
#else
#define MAXVALUE 1000
#endif3. 运算符与优先级
(1)运算符分类
| 类别 | 运算符 | 说明 |
|---|---|---|
| 算术运算 | + - * / % | 加减乘除取模 |
| 增减运算 | ++ -- | 自增自减 |
| 位运算 | & | ~ ^ << >> | 与或非异或移位 |
| 关系运算 | < <= > >= == != | 比较运算 |
| 逻辑运算 | && || ! | 逻辑与或非 |
(2)优先级表(从高到低)
// CN: 运算符优先级 -- EN: Operator precedence
/* 优先级 运算符
---------------------- 最高 () \[\] -> .
! ~ ++ -- -(unary) +(unary) (type) * & sizeof
* / %
<< >>
< <= > >=
== !=
&
^
|
&&
||
?: 最低 = += -= *= /= %= >>= <<= &= |= ^=
*/
4. 控制语句
(1) 条件语句
c
// CN: if-else 语句 -- EN: if-else statement
if (flag == 1) // CN: 条件判断 -- EN: Condition check
{
timeout = 1;
flag = 0;
}
else
{
timeout = 0;
}
// CN: switch 语句 -- EN: switch statement
switch (I) // CN: 表达式将为INT类型,最多256种情形 -- EN: Expression is INT type, max 256 cases
{
case 0: function0(); break;
case 1: function1(); break;
case 2: function2(); break;
default: funerror(); // CN: 默认处理 -- EN: Default handling
}(2)循环语句
c
// CN: while 循环 -- EN: while loop
while (value != 0) // CN: 先判断后执行 -- EN: Check first, then execute
{
value--;
count++;
}
// CN: do-while 循环 -- EN: do-while loop
do // CN: 先执行后判断 -- EN: Execute first, then check
{
value--;
count++;
} while (value != 0);
// CN: for 循环 -- EN: for loop
for (i = 0; i < 10; i++) // CN: 等价于 while 循环 -- EN: Equivalent to while loop
{
value = value + i;
}(3) 跳转语句
c
// CN: break 和 continue -- EN: break and continue
/*
break: 跳出 switch 或循环
continue: 跳过本次循环剩余部分,进入下次循环
*/
for (i = 0; i < 10; i++)
{
flag = indata(port);
if (flag == 0)
continue; // CN: 跳过本次循环 -- EN: Skip this iteration
outdata(port);
}
// CN: goto 语句 -- EN: goto statement
for (i = 0; i < 10; i++)
for (j = 0; j < 100; j++)
for (k = 0; k < 100; k++)
{
flag = crccheck(buffer);
if (flag != 0)
goto error; // CN: 跳转到错误处理 -- EN: Jump to error handling
outbuf(buffer);
}
error:
// CN: 错误处理代码 -- EN: Error handling code5. 函数
(1) 函数声明与定义
c
// CN: 库函数声明格式 -- EN: Library function declaration format
<返回值类型> <函数名>(<参数列表>);
// CN: 函数定义格式 -- EN: Function definition format
<返回类型> <函数名>(<参数列表>)
{
语句
}
// CN: 函数示例 -- EN: Function example
unsigned char sum(unsigned char a, unsigned char b)
{
return (a + b);
}⚠️ 函数使用限制:
- 不支持递归函数
- 不支持函数指针
- 参数必须是固定数量
- 不要使用 struct 或 union 作为函数参数
(2) 函数调用约定
c
// CN: 函数调用注意事项 -- EN: Function call notes
/*
1. 函数必须在调用之前声明
2. 建议在函数内使用全局变量代替局部变量(节省RAM)
3. 所有传递给函数的参数应该是固定数量
*/
// CN: 推荐写法 -- EN: Recommended approach
unsigned char global_var; // CN: 全局变量 -- EN: Global variable
void func(void)
{
global_var = 100; // CN: 使用全局变量 -- EN: Use global variable
}6. 特殊数据类型
(1) 枚举类型
c
// CN: 枚举类型定义 -- EN: Enumeration type definition
enum tagLedGroup
{
LedOff, // CN: 值为0 -- EN: Value is 0
LedOn // CN: 值为1 -- EN: Value is 1
} LEDStatus;
// CN: 带初始值的枚举 -- EN: Enumeration with initial values
enum tagMode
{
MODE_READ = 0,
MODE_WRITE = 1,
MODE_ERROR = 2
};(2) 结构体类型
c
// CN: 结构体定义 -- EN: Structure definition
struct st // CN: 定义结构体类型 -- EN: Define structure type
{
unsigned int b0:1; // CN: 位字段 -- EN: Bit field
unsigned int b1:1;
unsigned int b2:1;
unsigned int b3:1;
unsigned int b4:1;
unsigned int b5:1;
unsigned int b6:1;
unsigned int b7:1;
};
struct st R5@0x05; // CN: R5与地址0x05对应 -- EN: R5 corresponds to address 0x05
// CN: 复杂结构体示例 -- EN: Complex structure example
struct tagSpeechInfo
{
short rate; // CN: 采样率 -- EN: Sample rate
long size; // CN: 数据大小 -- EN: Data size
} SpeechInfo;⚠️ 结构体限制:
- 不要在结构体和联合内使用位数据类型,用位字段代替
- 结构和联合类型不能用做函数参数
(3) 联合类型
c
// CN: 联合类型 -- EN: Union type
union tagTest // CN: 共享存储空间 -- EN: Shared storage space
{
char Test[2]; // CN: 2字节 -- EN: 2 bytes
long RWport; // CN: 4字节,但只占用2字节 -- EN: 4 bytes, but only uses 2 bytes
} Test;(4) 数组
c
// CN: 数组定义 -- EN: Array definition
int array1[3][10]; // CN: 二维数组 -- EN: 2D array
char port[4]; // CN: 一维数组 -- EN: 1D array
// CN: const 数组 - 数据存放在ROM -- EN: const array - data stored in ROM
const int myarr[2] = {0x11, 0x22}; // CN: 放在ROM内 -- EN: Stored in ROM💡 注意: 如果用
const声明数组,数据将存放在ROM内。
(5) 指针
c
// CN: 指针定义 -- EN: Pointer definition
int *pt; // CN: 指针占用1字节 -- EN: Pointer takes 1 byte
/*
注意:
1. 所有指针类型占用1个字节
2. 不支持指针函数
*/
// CN: 指针使用示例 -- EN: Pointer usage example
int value = 100;
int *ptr;
ptr = &value;
三、硬件相关编程
1. 寄存器页(rpage)
c
// CN: 寄存器页变量声明 -- EN: Register page variable declaration
// 语法: <变量名> @<地址>: rpage <寄存器页数>
unsigned int myReg1 @0x03: rpage 0; // CN: page 0 的 0x03 地址 -- EN: page 0 address 0x03
unsigned int myReg2 @0x05: rpage 1; // CN: page 1 的 0x05 地址 -- EN: page 1 address 0x05⚠️ 重要说明:
- 必须明确申明显寄存器页,包括 rpage 0
- 只有全局变量才能定义为 rpage
- 不能同时定义为 bank、iopage 或 indir
寄存器页结构示意:
+---------------------------+
| rpage 0 | rpage 1 |
|---------------------------|
| 0x00 | |
| 0x03(myReg1)| |
| ... | 0x05(myReg2)|
| 0xFF | |
+---------------------------+2. I/O控制寄存器页(iopage)
c
// CN: I/O控制寄存器页声明 -- EN: I/O control register page declaration
// 语法: io <变量名> @<地址>: iopage <io控制页数>
io unsigned int myIOC1 @0x05: iopage 0; // CN: iopage 0 的 0x05 -- EN: iopage 0 address 0x05
io unsigned int myIOC2 @0x05: iopage 1; // CN: iopage 1 的 0x05 -- EN: iopage 1 address 0x05I/O控制寄存器页结构:
+---------------------------+
| iopage 0 | iopage 1 |
|---------------------------|
| IOC5~IOCF | |
| 0x05(myIOC1)| 0x05(myIOC2)|
+---------------------------+3. RAM区(bank)
c
// CN: RAM区变量声明 -- EN: RAM area variable declaration
// 语法: <变量名> @<地址>: bank <bank数值>
unsigned int myData1 @0x22: bank 0; // CN: bank 0 变量 -- EN: bank 0 variable
unsigned int myData2 @0x22: bank 1; // CN: bank 1 变量 -- EN: bank 1 variable
unsigned short myshort @0x20: bank 2; // CN: 占用 0x20~0x21 -- EN: occupies 0x20~0x21
unsigned long myLong @0x24: bank 1; // CN: 占用 0x24~0x27 -- EN: occupies 0x24~0x27RAM Bank 结构示意:
+--------+----------+
| Bank 0 | Bank 1 |
|--------|----------|
| 0x20 | 0x20 |
| 0x22 | 0x22 |
| (myData1)|(myData2)|
| 0x24 | 0x24 |
| | (myLong) |
+--------+----------+4. 位数据类型
c
// CN: 位数据类型 -- EN: Bit data type
// 语法: bit <变量名> @<地址>[@<位序号>]: bank/rpage <页号>
bit myBit1; // CN: 编译器自动分配地址 -- EN: Auto allocated by compiler
bit myBit2 @0x03: rpage 0; // CN: 默认第0位 -- EN: Default bit 0
bit myBit3 @0x04 @5: rpage 1; // CN: rpage 1 的 0x04 第5位 -- EN: rpage 1 address 0x04 bit 5
bit myBit4 @0x05 @6: rpage 1; // CN: rpage 1 的 0x05 第6位 -- EN: rpage 1 address 0x05 bit 6
bit myBit5 @0x22 @3: bank 1; // CN: bank 1 的 0x22 第3位 -- EN: bank 1 address 0x22 bit 3⚠️ 位类型限制:
- 不能用于结构和联合内部
- 不能作为函数参数
- 不能与其他数据类型进行算术运算
- I/O控制寄存器不支持位类型
- 只有全局变量才能定义为位类型
5. 间接寻址
c
// CN: 间接寻址声明 -- EN: Indirect addressing declaration
// 语法: indir <变量名> @<地址>: ind <ind数字>
indir int nData1; // CN: 默认 ind 0,数据RAM -- EN: Default ind 0, data RAM
indir int nData2 @0x30: ind 0; // CN: 数据RAM区 -- EN: Data RAM area
indir int nData3 @0x01: ind 1; // CN: LCD RAM区 -- EN: LCD RAM area间接寻址区域:
+------------------+------------------+
| Data RAM | LCD RAM |
|------------------|------------------|
| 0x30 (nData2) | 0x01 (nData3) |
+------------------+------------------+6. ROM内函数定位
c
// CN: ROM内函数定位 -- EN: Function positioning in ROM
// 语法: <返回值> <函数名>(<参数>) @<地址>: page <页数>
void myFun1(int x, int y) @0x33
// CN: 放在 page 0 的 0x33 处 -- EN: Positioned at page 0 address 0x33
{
// 函数体
}
void myFun2(int x, int y) @0x33: page 1
// CN: 放在 page 1 的 0x33 处 -- EN: Positioned at page 1 address 0x33
{
// 函数体
}⚠️ 函数定位限制:
- 只有函数可以分配页
- 不要在ROM内给中断保护程序或中断服务程序分配页
7. 常量数据存储
c
// CN: 常量数据存放在ROM -- EN: Constant data stored in ROM
// 语法: const <变量名>
const int myData[] = {1, 2, 3, 4, 5};
const char myString[2][3] = {
"Hi!",
"ABC"
};
// CN: 使用TBL指令读取ROM数据 -- EN: Use TBL instruction to read ROM data💡 说明: 编译器使用TBL指令将常量数据存放在ROM内,以节省有限的RAM空间。
8. 嵌入汇编
c
// CN: 嵌入汇编语法 -- EN: Inline assembly syntax
// 保留字: _asm { ... }
_asm
{
// CN: 汇编指令区域 -- EN: Assembly instruction area
mov a, 0xFF
mov %temp, a
}
// CN: 在汇编中使用C变量 -- EN: Use C variables in assembly
mov a, %<variable name> // CN: 将变量值给ACC -- EN: Move variable value to ACC
mov a, @%<variable name> // CN: 将变量地址给ACC -- EN: Move variable address to ACC
// CN: 综合示例 -- EN: Complete example
int temp;
temp = 0x03; // CN: 假设temp位于bank 0的0x21地址 -- EN: Assume temp at bank 0 address 0x21
_asm {mov a, %temp} // CN: 将0x03给ACC -- EN: Move 0x03 to ACC
_asm {mov a, @%temp} // CN: 将0x21给ACC -- EN: Move 0x21 to ACC⚠️ 嵌入汇编注意事项:
- 0x10-0x1F寄存器为编译器保留,不建议使用
- 如果需要切换rpage、iopage或bank,必须先保存后恢复
9. 中断处理
(1)中断保护程序
c
// CN: 中断保护程序声明 -- EN: Interrupt protection routine declaration
// 语法: void _intcall <函数名>_l(void) @<中断向量地址>: low_int <中断向量数>
void _intcall INTERRUPT1_l(void) @0x08: low_int 0
{
// CN: 保存ACC, R3, R4, R5 -- EN: Save ACC, R3, R4, R5
_asm
{
MOV 0X1F, A
SWAPA 0X4
BS 0X4, 6
BS 0X4, 7
MOV 0X3F, A
// ... 更多保存操作
}
}(2) 中断服务程序
c
// CN: 中断服务程序声明 -- EN: Interrupt service routine declaration
// 语法: void _intcall <函数名>(void) @int <中断向量数>
void _intcall INTERRUPT1(void) @int 0
{
// CN: 备份C系统寄存器 -- EN: Backup C system registers
_asm
{
MOV A, 0X10
MOV 0X3C, A
// ... 更多保存操作
}
// CN: 中断处理代码 -- EN: Interrupt handling code
// CN: 恢复C系统寄存器 -- EN: Restore C system registers
_asm
{
MOV A, 0X3C
MOV 0X10, A
// ... 更多恢复操作
}
}(3) 寄存器保护策略
c
// CN: 通用寄存器保护详解 -- EN: General register protection detail
/*
16个通用寄存器(0x10~0x1f)是为某些运算保留的
中断发生时,建议用户备份以下寄存器:
| 运算类型 | 需要备份的寄存器 |
|----------------|------------------------|
| * / % | 0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x18, 0x19 |
| << >> | 0x14 |
| 仅+ - & | ^ | 无需备份 |
*/
// CN: 简化备份示例 -- EN: Simplified backup example
int nBuf[5];
void _intcall INTERRUPT2(void) @int 0
{
// CN: 保存寄存器 -- EN: Save registers
_asm
{
mov a, 0x10
mov %nBuf, a
mov a, 0x14
mov %nBuf + 1, a
mov a, 0x18
mov %nBuf + 2, a
mov a, 0x1B
mov %nBuf + 3, a
mov a, 0x1C
mov %nBuf + 4, a
}
// CN: 中断处理代码 -- EN: Interrupt handling code
// CN: 恢复寄存器 -- EN: Restore registers
_asm
{
mov a, %nBuf
mov 0x10, a
// ... 更多恢复操作
}
}⚠️ 中断编程限制:
- 中断程序只支持单字节数据类型操作(char、int)
- 不允许在中断函数中使用长整型的 *、/、%
- 0x10-0x1F的RAM空间已被用作寄存器备份
四、 C语言与内嵌汇编:在高级语言中驾驭底层指令
在MCU开发中,C语言已经能覆盖绝大多数应用场景。但总有一些时刻,
您需要直接操控某条特殊的机器指令------比如精确控制时序、访问C语言无法表达的硬件特性、或者实现极致优化的关键代码段。这时,内嵌汇编就成了C语言与底层硬件之间的"桥梁"。
1. 为什么要用内嵌汇编
内嵌汇编并非日常开发的标配,但在以下场景中不可或缺:
(1) 访问C语言无法触及的硬件特性
某些MCU的特殊指令(如休眠指令SLEEP、看门狗清零指令CLRWDT、空操作NOP等)在C语言中没有对应语法。只能通过汇编直接发出。
(2) 精确时序控制
当您需要精确到指令周期的延时(如软件模拟某些通信协议时),C语句无法保证生成的指令数量和顺序。内嵌汇编让您"所见即所得"。
(3)上下文保护与恢复
在中断服务程序中,您常常需要手动保存和恢复关键寄存器(如累加器、状态寄存器)。这项工作只能通过汇编完成。
c
// CN:内嵌汇编的典型应用场景 -- EN:Typical use cases for inline assembly
// CN:场景1:执行C语言无法表达的硬件指令 -- EN:Case 1: Execute hardware instructions not expressible in C
__asm
{
NOP ; CN:空操作,精确延时一个指令周期 -- EN:No operation, precise 1-cycle delay
CLRWDT ; CN:清零看门狗定时器 -- EN:Clear Watchdog Timer
SLEEP ; CN:进入休眠模式 -- EN:Enter sleep mode
}
// CN:场景2:中断保护------保存关键寄存器 -- EN:Case 2: Interrupt protection - save key registers
void __interrupt ISR(void)
{
__asm
{
MOV 0x1F, A ; CN:保存累加器 -- EN:Save accumulator
SWAPA 0x3 ; CN:保存状态寄存器 -- EN:Save status register
MOV 0x1E, A
}
// ... CN:ISR主体代码 -- EN:ISR body code ...
__asm
{
SWAPA 0x1E ; CN:恢复状态寄存器 -- EN:Restore status register
MOV 0x3, A
SWAP 0x1F ; CN:恢复累加器 -- EN:Restore accumulator
SWAPA 0x1F
}
}2. 内嵌汇编的基本语法
不同编译器对内嵌汇编的语法约定略有不同,但核心思想一致:用特定关键字标识汇编块的开始和结束,在块内直接书写目标MCU的汇编指令。
| 编译器/平台 | 内嵌汇编关键字 | 示例 |
|---|---|---|
| 8位MCU编译器(本文) | _asm 或 __asm |
__asm { MOV A, 0x10 } |
| GCC (ARM/AVR等) | __asm__ __volatile__ |
__asm__ __volatile__ ("nop"); |
| Keil C51 | __asm ... __endasm |
__asm MOV A, #0xFF __endasm |
| IAR Embedded Workbench | asm |
asm("NOP"); |
c
// CN:不同编译器的内嵌汇编语法示例 -- EN:Inline assembly syntax examples for different compilers
// CN:语法风格1:块级内嵌(如WicePlus)-- EN:Style 1: Block-level inline (e.g., WicePlus)
__asm
{
mov a, 0x20 ; CN:单条指令 -- EN:Single instruction
add a, 0x21
mov 0x22, a ; CN:结果存回 -- EN:Store result back
}
// CN:语法风格2:单行内嵌(如GCC)-- EN:Style 2: Single-line inline (e.g., GCC)
__asm__ __volatile__ ("nop");
__asm__ __volatile__ ("mov r0, #0");3. C变量如何在汇编中访问
内嵌汇编之所以强大,在于它能和C代码共享数据。您可以在汇编语句中直接读取C变量的值,或修改C变量的内容。编译器通过特殊符号与寻址方式实现这种互操作。
c
// CN:在汇编中访问C变量 -- EN:Accessing C variables in assembly
int temp; // CN:假设temp位于bank 0的0x21地址 -- EN:Assume temp is at bank 0 address 0x21
temp = 0x03;
// CN:方式1:获取变量值 -- EN:Method 1: Get variable value
__asm { mov a, %temp }
// CN:效果:累加器A = 0x03 -- EN:Effect: Accumulator A = 0x03
// CN:方式2:获取变量地址 -- EN:Method 2: Get variable address
__asm { mov a, @%temp }
// CN:效果:累加器A = 0x21(temp的地址)-- EN:Effect: Accumulator A = 0x21 (address of temp)
// CN:方式3:修改变量值 -- EN:Method 3: Modify variable value
__asm { mov %temp, a }
// CN:效果:将累加器A的值写入temp -- EN:Effect: Write accumulator A's value into temp| 汇编表达式 | 含义 | 说明 |
|---|---|---|
%变量名 |
变量的值 | 读取变量内容到寄存器,或从寄存器写入变量 |
@%变量名 |
变量的地址 | 获取变量在内存中的地址编号 |
4. 页面切换的黄金法则
在带有bank/page机制的MCU中,内嵌汇编中如果需要切换页面,必须遵循"保存→操作→恢复"三步法则。任何遗漏都会让程序进入"数据错乱"的诡异状态。
c
// CN:页面切换的标准模板 -- EN:Standard template for page switching
void switch_page_example(void)
{
unsigned char page_backup; // CN:用于保存页面状态 -- EN:Used to save page state
__asm
{
// CN:第1步------保存当前页面寄存器 -- EN:Step 1 - Save current page register
mov a, 0x03 ; CN:读状态/页寄存器 -- EN:Read status/page register
mov %page_backup, a ; CN:存入备份变量 -- EN:Store in backup variable
// CN:第2步------切换到目标页面 -- EN:Step 2 - Switch to target page
bs 0x03, 5 ; CN:通过位操作切到目标页 -- EN:Switch to target page via bit operation
bs 0x03, 6
// CN:第3步------在目标页面执行操作 -- EN:Step 3 - Perform operations in target page
mov a, 0x20 ; CN:读取目标页的数据 -- EN:Read data from target page
add a, #1
mov 0x20, a ; CN:写回 -- EN:Write back
// CN:第4步------恢复原页面 -- EN:Step 4 - Restore original page
mov a, %page_backup ; CN:从备份变量取回原值 -- EN:Retrieve original value from backup
mov 0x03, a ; CN:恢复页寄存器 -- EN:Restore page register
}
}⚠️ 常见错误:忘记恢复页面
如果在汇编块中切换了bank/page却没有恢复,后续的C代码会在错误的页面下读写变量。例如,您定义在bank 0的
int counter,可能被错误地当作bank 1的某个地址来操作。这种错误的症状往往是"某个变量值莫名其妙地变了",极难排查。
5. 内嵌汇编与编译器优化的冲突
现代C编译器会进行各种优化(如寄存器分配、指令重排)。当C代码和汇编混用时,编译器可能不知道汇编块内部做了什么,从而做出错误的优化决策。因此,与编译器"沟通"您的意图非常重要。
c
// CN:使用volatile告知编译器不要优化 -- EN:Use volatile to inform compiler not to optimize
unsigned char status_register; // CN:可能被硬件或汇编修改 -- EN:May be modified by hardware or assembly
void check_status(void)
{
// CN:volatile确保每次都从内存读取,而非寄存器缓存 -- EN:volatile ensures reading from memory every time, not from register cache
volatile unsigned char sr;
__asm { mov a, 0x03 } ; CN:从硬件寄存器读取 -- EN:Read from hardware register
__asm { mov %sr, a } ; CN:存入C变量 -- EN:Store into C variable
if (sr & 0x80)
{
// CN:处理状态变化 -- EN:Handle status change
}
}💡 最佳实践总结:
- 能C则C:不要为了"炫技"而用汇编。能用C表达的逻辑,优先用C,编译器通常能生成足够好的代码。
- 封装为宏:将常用的汇编操作封装成带参数的宏,提高可读性和复用性。
- 严格管理页面:汇编块内切换bank/page,必须"借前存档,用完归还"。
- 中断中慎用:ISR中使用内嵌汇编时,务必确保寄存器备份覆盖汇编块中修改的所有寄存器。
- 标注volatile :被汇编代码修改的C变量,应声明为
volatile,防止编译器将其优化掉。
c
// CN:封装为宏------提高可读性 -- EN:Encapsulate as macro - improve readability
#define DISABLE_INTERRUPTS() __asm { BCF 0x0B, 7 }
#define ENABLE_INTERRUPTS() __asm { BSF 0x0B, 7 }
#define NOP() __asm { NOP }
void critical_section(void)
{
DISABLE_INTERRUPTS(); // CN:关中断 -- EN:Disable interrupts
// CN:临界区代码 -- EN:Critical section code
NOP();
ENABLE_INTERRUPTS(); // CN:开中断 -- EN:Enable interrupts
}内嵌汇编是C语言与硬件底层之间的"精密手术刀"。它给您完全的控制力,但也要求您承担完全的责任。理解了C变量与汇编寄存器的映射关系、页面切换的准则、以及与编译器优化的共存之道,您就能在必要时安全地使用这个强大工具。
五、与汇编代码转换对照表
1. 基本数据类型转换
| C语句 | 汇编代码 | 转换率 |
|---|---|---|
intVar1 = 0xFF; |
MOV A, @0xFF; MOV %intVar1, A | 100% |
charVar1 = 0xFF; |
MOV A, @0xff; MOV %charVar1, A | 100% |
shortVar1 = 0x1234; |
MOV A, @0x34; MOV %shortVar1, A; MOV A, @0x12; MOV %shortVar1+1, A | 100% |
longVar1 = 0x123456; |
MOV A, @0x56; MOV %longVar1, A; MOV A, @0x34; MOV %longVar1+1, A; MOV A, @0x12; MOV %longVar1+2, A | 100% |
2. 控制结构转换
(1) 循环语句
c
// CN: for循环 -- EN: for loop
for (i = 0; i < 5; i++)
{
// 语句
}
// CN: 对应汇编 -- EN: Corresponding assembly
CLR %i
JMP L2
L1:
// 语句
L2:
INC %i
MOV A, @0x05
SUB A, 0x14
JBS 0x03, 0
JMP L1(2) While循环
c
// CN: while循环 -- EN: while loop
while (cnt != 1)
{
// 语句
}
// CN: 对应汇编 -- EN: Corresponding assembly
L1:
// 语句
MOV A, %cnt
XOR A, @0X01
JBS 0X03, 2
JMP L13. 位操作转换
c
// CN: 左移1位 -- EN: Shift left 1 bit
f = e << 1;
// CN: 对应汇编 -- EN: Corresponding assembly
MOV A, %e
MOV 0x14, A
BC 0x03, 0
RLCA 0x14
MOV %f, A
// CN: 转换率 167% -- EN: Conversion rate 167%
// CN: 右移1位 -- EN: Shift right 1 bit
f = e >> 1;
// CN: 对应汇编 -- EN: Corresponding assembly
MOV A, %e
MOV 0x14, A
BC 0x03, 0
RRCA 0x14
MOV %f, A
// CN: 转换率 167% -- EN: Conversion rate 167%4. 算术运算转换
c
// CN: 加法 -- EN: Addition
f = e + d;
// CN: 对应汇编 -- EN: Corresponding assembly
MOV A, %e
ADD A, %d
MOV %f, A
// CN: 转换率 100% -- EN: Conversion rate 100%
// CN: 乘法 -- EN: Multiplication
c = a * b;
// CN: 对应汇编 -- EN: Corresponding assembly
MOV A, %a
MOV 0X1C, A
MOV A, %b
MOV 0X18, A
CLRA
L1:
ADD A, 0X1C
DJZ 0X18
JMP L1
MOV %c, A
// CN: 转换率 100% -- EN: Conversion rate 100%
// CN: 除法 -- EN: Division
c = a / b;
// CN: 对应汇编 -- EN: Corresponding assembly
// CN: (使用减法循环实现除法) -- EN: (Division implemented using subtraction loop)
六、常见问题
1、 函数参数最多是多少
函数参数最多能传多少个?这个问题的答案并非一个固定数字,而是由目标MCU的硬件架构和编译器的调用约定共同决定的。简单来说,参数传递的上限主要受限于可用寄存器数量和栈空间大小。
当主调函数需要将实参传递给被调函数时,编译器会遵循一套既定的"调用约定"。这套约定定义了参数传递的优先级,通常分为两个阶段:
-
阶段一:寄存器传递 。
现代MCU架构(如ARM Cortex-M系列)会预留若干通用寄存器专门用于传递函数参数。
例如,在ARM的AAPCS(ARM架构过程调用标准)中, R 0 R0 R0到 R 3 R3 R3这4个寄存器首先被用来传递参数。如果参数数量少且类型适合,编译器会优先将它们放入寄存器中,这种方式速度最快。
-
阶段二:栈传递
当参数数量超过可用的寄存器数量,或者参数类型复杂(如大型结构体)无法完全放入寄存器时,剩下的参数就会被"压入"内存中的栈空间 (Stack) 进行传递。
因此,参数个数的极限就转化为一个资源限制问题:
参数总个数 = 可用于传参的寄存器个数 + (可用栈空间 / 每个参数占用的平均空间)
对于资源极度受限的8位MCU(如经典的8051或本文所基于的架构),其内核通常只有一个或极少数通用寄存器可用于寻址,因此编译器往往会强制所有参数都通过栈来传递。此时,参数个数的瓶颈就几乎完全取决于物理RAM的大小 。
例如:如果一片MCU仅有32字节的RAM,除去系统保留和全局变量占用的空间,剩下的栈空间可能只够传递有限个字节的参数。
💡 最佳实践: 在MCU编程中,为保证代码的可移植性和效率,应尽量避免传递过多参数。一个推荐的做法是使用结构体指针,即传递一个指向包含所有数据的结构体的指针,这样无论数据量多大,都只占用1个指针大小的参数空间。
c
// CN:不推荐:参数过多,消耗栈空间 -- EN:Not recommended: Too many parameters, consumes stack space
void update_device(int id, short mode, short value, char status, long timestamp);
// CN:推荐:通过结构体指针传递,仅占用一个指针参数 -- EN:Recommended: Pass via struct pointer, uses only one pointer argument
struct DeviceData
{
int id;
short mode;
short value;
char status;
long timestamp;
};
void update_device_efficient(struct DeviceData *params);综上所述,当您估算函数参数上限时,请查阅您的MCU数据手册和编译器的调用约定文档,答案就隐藏在寄存器和RAM的细节之中。
2、 函数调用最深可到多少层?
函数调用的最大深度,即最多能嵌套调用多少层函数,并不由C语言本身决定,而是由MCU的硬件堆栈(Hardware Stack)深度 直接限制。
每一次函数调用,处理器都需要将"返回地址"(即调用点下一条指令的地址)压入堆栈。如果函数有局部变量或需要保存寄存器上下文,这些数据同样会被压栈。当函数执行完毕返回时,处理器再从堆栈中弹出返回地址,跳转回主调函数继续执行。这个"压入-弹出"的过程,就是堆栈工作的基本原理。
因此,函数嵌套调用的深度可以这样估算:
最大调用深度 ≈ 硬件堆栈总深度 / 每层调用平均压栈量
对于不同架构的MCU,硬件堆栈的实现方式差异很大:
-
独立硬件堆栈 :
在许多8位MCU(如PIC、EM78系列等)中,堆栈是一块独立于通用RAM的专用硬件。它只有固定的几层(如4级、8级或16级),完全不能扩展。一旦嵌套调用超过了这个硬件级数,就会发生堆栈溢出,导致程序返回地址被破坏,系统崩溃或行为不可预测。
-
共享RAM堆栈 :
在ARM Cortex-M等现代32位架构中,堆栈位于通用RAM区域内。理论上只要RAM足够大,堆栈可以很深。但深度依然受限于分配给栈区的RAM总量。编译器和链接器脚本会设定一个初始的栈指针,栈从此处向下增长。如果嵌套太深导致栈"撞上"了数据区,就发生了栈溢出,这在调试中是极难排查的致命错误。
💡 最佳实践:
- 查阅手册:对于资源紧张的8位MCU,务必查阅芯片数据手册,明确硬件堆栈的级数上限。
- 避免深递归:递归算法会快速消耗堆栈。在MCU开发中,除非深度可控,否则应优先用循环替代递归。
- 减少局部变量:大尺寸的局部变量或数组会显著增加每层调用的压栈量。尽量使用全局变量或静态变量来存储临时数据。
- 编译时检查:编译完成后,可以通过查看输出的链接文件或工具提供的调用图信息,确认最坏情况下的函数调用深度是否安全。
c
// CN:递归示例------在MCU中需谨慎使用 -- EN:Recursion example - use with caution in MCU
long factorial(int n)
{
// CN:每次调用都会压栈,n较大时容易溢出 -- EN:Each call pushes the stack, easy to overflow for large n
if (n <= 1)
return 1;
return n * factorial(n - 1);
}
// CN:推荐:用循环替代递归 -- EN:Recommendation: use loop instead of recursion
long factorial_loop(int n)
{
long result = 1;
for (int i = 2; i <= n; i++)
{
result *= i;
}
return result;
}总而言之,函数调用深度是MCU开发中一个"隐形"的硬约束。理解您的芯片堆栈机制,并养成估算调用深度的习惯,是写出稳健嵌入式代码的关键一步。
3、数组能开多大
数组的最大尺寸,本质上由MCU的可用RAM空间总量决定。但这个"可用"二字大有讲究,不能简单地和芯片标称的RAM容量划等号。
在MCU中,RAM通常被划分为多个逻辑区域,每个区域各司其职:
a. 全局/静态数据区
全局变量(在函数体外定义的变量)和用static修饰的局部变量都存放在这个区域。编译器在链接阶段为它们分配固定地址,这些地址在程序运行期间不会改变。您定义的全局数组,就落在这个区域内。
c
// CN:这两个数组都在全局/静态数据区内分配 -- EN:These two arrays are allocated in the global/static data area
unsigned char global_buffer[64]; // CN:占据64字节 -- EN:Occupies 64 bytes
static int local_static[10]; // CN:占据20字节(假设int为2字节) -- EN:Occupies 20 bytes (assuming int is 2 bytes)b. 栈区(Stack)
函数的返回地址、局部变量、函数参数等都存储在栈区。栈的大小由链接器脚本或启动代码设定。如果您在函数内定义了一个大数组,比如char local_array[256],这个数组就会在函数调用时从栈上分配,函数返回时释放。对于栈容量极小的MCU(例如只有几十字节),这样的操作几乎必然导致栈溢出。
c
void process_data(void)
{
// CN:危险操作------大数组在栈上分配,极易溢出 -- EN:Dangerous operation - large array allocated on stack, very likely to overflow
char local_buffer[256];
// ...
}c. 堆区(Heap)
当您使用malloc()和free()进行动态内存分配时,内存就来自堆区。然而,绝大多数小型8位MCU的C编译器根本不支持malloc和free,甚至不提供堆区。即便在支持堆的MCU上,频繁的动态分配也可能造成内存碎片 ,使系统在运行一段时间后因"有空间但无连续块"而分配失败。因此,嵌入式开发中通常禁用或严格限制动态内存分配。
综合以上几点,在MCU中声明数组应遵循以下原则:
💡 最佳实践:
- 用全局不用局部 :对于尺寸较大的数组,应定义为全局变量(或
static变量),使其落在可预测的静态数据区,而不是局促的栈区。- 善用
const:如果数组内容是常量(如查找表、字库、波形表),务必用const修饰。编译器会将其放入ROM/Flash,完全不占用宝贵的RAM。- 查看编译输出:编译完成后,仔细阅读链接器生成的map文件。它详细列出了各区域的起始地址、已用大小和剩余空间,是判断数组是否越界的最可靠依据。
c
// CN:推荐做法 -- EN:Recommended approach
// CN:1. 大数组定义为全局 -- EN:1. Define large arrays as global
unsigned char large_buffer[128];
// CN:2. 常量数据用const,存入ROM -- EN:2. Use const for constant data, stored in ROM
const unsigned char sine_wave_table[256] =
{
128, 131, 134, 137, /* ... 值省略 ... */
};
void my_func(void)
{
// CN:只声明小的临时变量在栈上 -- EN:Only declare small temporary variables on stack
int i;
for (i = 0; i < 128; i++)
{
large_buffer[i] = sine_wave_table[i * 2];
}
}总之,数组大小的上限,就是您MCU的RAM总量减去系统保留区、其它全局变量和栈需求后的"剩余配额"。养成阅读map文件和规划内存布局的习惯,比记住一个死板的数值重要得多。
4、代码超出ROM范围会提示错误吗?
答案是会 ,但这个错误并非在写代码时出现,而是在编译流程的最后阶段------链接阶段被检测出来。
要理解这个错误的发生机制,我们需要先回顾一下C语言程序从源码到可执行文件的全过程:
a. 预处理
预处理器处理#include、#define、#if等指令,展开所有宏和头文件,生成一个纯净的.i或.i中间文件。这个阶段不涉及地址分配,因此不会报告ROM溢出。
b. 编译
编译器将预处理后的C代码翻译成对应MCU架构的汇编语言。每个.c文件被独立编译成一个目标文件(.o或.obj)。此时,编译器只关注语法和单文件的逻辑,并不知道最终程序会放在ROM的哪个地址。因此,单文件编译阶段也不会报ROM溢出。
c. 汇编
汇编器将汇编代码翻译成机器码,生成可重定位的目标文件。目标文件中包含代码和数据,但地址尚未最终确定,以"相对偏移"的形式存在。
d. 链接
这是最关键的一步。链接器将多个目标文件(以及用到的库文件)合并成一个完整的可执行镜像。在这个阶段,链接器根据链接器脚本中定义的存储布局,为每一段代码和每一份数据分配最终的物理ROM地址。
链接器脚本明确规定了ROM的起始地址和总大小。当分配完所有代码段、常量数据段、中断向量表等内容后,如果累计的总大小超过了脚本定义的最大ROM容量,链接器就会立即报错。
c
CN:典型错误信息示例:
EN:Typical error message example:
Region `ROM` overflowed by 1234 bytes
section `.text' will not fit in region `ROM'💡 链接器报错时的常见信号:
region 'ROM' overflowed by ... bytessection '.text' will not fitaddress overflow at ...cannot allocate space for ...
一旦出现这类错误,意味着您的程序已经"塞不下"了。这时可以从以下几个方向着手优化:
1. 代码优化
- 开启编译器的优化选项(如
-Os,即优化尺寸)。编译器会自动进行内联裁剪、死代码消除、循环展开等,往往能缩减可观的代码体积。 - 检查是否有未使用的函数或变量,将其删除。有些编译器/IDE能自动识别未引用的代码。
2. 算法与数据结构优化
- 用查表法替换复杂的
switch-case或计算密集的算法,虽然表本身占ROM,但有时代码的缩减量远超表的大小。 - 精简字符串和打印信息,格式化字符串(
printf格式串)有时会占用大量ROM。
3. 常量数据管理
- 确认
const数组是否正确放在了ROM中。如果误用(例如某些编译器需要特定关键字),常量数据可能会被复制到RAM初始化区,双重浪费空间。 - 压缩查找表数据,例如使用更小的数据类型(
char替代int),或对数据进行简单编码后运行时解码。
c
// CN:示例:减少ROM占用的几种方法 -- EN:Example: several methods to reduce ROM usage
// CN:1. 开启优化选项(编译器命令行)
// EN:1. Enable optimization option (compiler command line)
// -Os
// CN:2. 删除未使用的函数 -- EN:2. Remove unused functions
// void unused_function(void) { ... } // CN:直接删除 -- EN:Just delete it
// CN:3. 缩小数据类型 -- EN:3. Reduce data type size
// CN:用1字节char代替2字节int -- EN:Use 1-byte char instead of 2-byte int
const char week_days[7] = {"Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"};
// CN:4. 简化字符串 -- EN:4. Simplify strings
// CN:减少调试信息的字符串长度 -- EN:Reduce the length of debug message strings
// printf("Err") 比 printf("Error: invalid parameter at line 100") 省ROM总而言之,ROM溢出错误是链接器对开发者的"硬约束"。它虽然令人沮丧,但至少是明确、可定位的错误。最危险的情况其实是没有报错,程序刚好占满ROM,却因堆栈或数据意外溢出而间歇性崩溃。因此,建议始终为ROM保留至少5%-10%的安全余量,以应对未来代码维护和边界情况。
5、 可以给中断子程序分配ROM地址吗?
答案是绝对不可以。随意给中断服务程序(ISR)指定一个"看起来空着"的ROM地址,是嵌入式开发中非常危险的做法,会引发不可预知的、难以调试的错误。
要理解为什么,我们需要明白MCU的中断响应机制和编译器的"幕后工作"。
a. 中断向量表------硬件的"呼叫中心"
每个支持中断的MCU,在ROM的最前端或某个固定起始位置,都有一张中断向量表 。这张表里的每一个条目,不是代码,而是一个跳转地址。当某个中断事件发生时,硬件会自动根据中断号,去向量表中对应的位置读取那个预设的地址,然后强制程序计数器(PC)跳转到该地址开始执行。
这个跳转目标地址就是中断服务程序的入口地址。它是由编译器和链接器在编译链接阶段,根据ISR函数的定义自动计算并填入向量表的。如果您手动给ISR分配了另一个地址,就破坏了这条硬件调用的完整链路。
CN:中断向量表示意图:
EN:Interrupt Vector Table Illustration:
+-------------------------+ <---- CN:ROM起始地址 -- EN:ROM Start Address
| 0x0000: Reset Vector | → CN:复位后第一条指令的地址 -- EN:Address of first instruction after reset
|-------------------------|
| 0x0004: Timer0 Vector | → CN:Timer0中断入口地址 -- EN:Timer0 interrupt entry address
|-------------------------|
| 0x0008: External Int0 | → CN:外部中断0入口地址 -- EN:External interrupt 0 entry address
|-------------------------|
| 0x0010: UART Vector | → CN:串口中断入口地址 -- EN:UART interrupt entry address
+-------------------------+b. 编译器的自动编排------看不见的"脚手架"
当您用标准方式定义一个ISR时,编译器并非仅仅生成您写的那些C代码。它会在您的函数体前后自动插入额外的上下文保护和恢复代码,包括:
- 保护所有可能被ISR修改的寄存器(将它们压入堆栈)。
- 切换到正确的中断RAM区或寄存器页。
- 执行您写的ISR主体代码。
- 恢复之前保存的寄存器上下文。
- 执行"中断返回"指令,让CPU回到主程序被中断的位置。
如果强行将ISR放到一个自定义地址,这个精心编排的"脚手架"就会被破坏,导致上下文切换失败、寄存器被意外篡改,最终系统死机或功能异常。
💡 正确做法: 永远使用编译器规定的标准语法来定义ISR。编译器会自动将它链接到正确的向量地址。
c
// CN:正确做法:使用标准关键字,让编译器处理地址分配 -- EN:Correct approach: use standard keywords, let compiler handle address allocation
// CN:无需手动指定@地址,编译器会自动将ISR放入向量表 -- EN:No need to manually specify @address, compiler will auto-place ISR in vector table
void __interrupt Timer0_ISR(void)
{
// CN:中断服务程序代码 -- EN:Interrupt service routine code
static unsigned int tick_count;
tick_count++;
if (tick_count >= 1000)
{
tick_count = 0;
toggle_led();
}
}c. 唯一合法的"例外":Bootloader中的中断重映射
在某些包含Bootloader的系统中,应用程序区的中断向量表被整体搬移到了ROM的另一块区域。这是通过配置硬件的中断向量基址寄存器实现的,而不是手动给单个ISR指定地址。即便在这种情形下,ISR依然由编译器在"新"向量表区域内自动分配,开发者不能手动干预单个ISR的绝对地址。
CN:Bootloader场景下的中断重映射:
EN:Interrupt remapping in Bootloader scenario:
+-------------------------+ <---- CN:Flash起始地址 -- EN:Flash Start Address
| Bootloader区 |
| (含自身的向量表) |
|-------------------------| <---- CN:应用区起始 -- EN:Application area start
| 应用区向量表(重映射后) | → CN:硬件跳转至此表获取应用ISR地址 -- EN:Hardware jumps here for app ISR addresses
|-------------------------|
| 应用区代码 |
+-------------------------+总而言之,中断向量地址是硬件和编译器之间的"神圣契约"。开发者只需要按照标准语法写好ISR函数,其余一切地址编排工作,交给编译器和链接器即可。任何试图手工干预的尝试,都会破坏这个契约,带来未知的致命风险。
6、 如何在*.h文件里定义全局变量?
在MCU开发中,全局变量往往需要在多个.c源文件之间共享。但很多人会在头文件里直接写int my_var;,这在单文件编译时没问题,一旦多个文件都包含这个头文件,链接阶段就会报错。要理解为什么,必须先厘清C语言中声明 与定义这两个核心概念。
a. 声明 vs 定义------一张图搞懂
| 概念 | 作用 | 是否分配内存 | 可出现的次数 |
|---|---|---|---|
| 声明 | 告诉编译器"这个变量存在于某个地方" | 否 | 多次,任意文件 |
| 定义 | 真正为变量分配存储空间 | 是 | 全局范围内有且仅有一次 |
b. 经典错误:在头文件中直接定义变量
c
// CN:错误做法:在头文件中直接定义变量 -- EN:Wrong approach: defining a variable directly in a header file
/* globals.h */
int my_var; // CN:这是定义,不是声明! -- EN:This is a definition, not a declaration! 当file1.c和file2.c都#include "globals.h"时,两个目标文件中都会出现一个名为my_var的全局定义。链接器在合并这两个文件时,会发现全局符号my_var重复定义了,从而抛出错误:
CN:典型错误信息:
EN:Typical error message:
multiple definition of `my_var'c. 正确做法:头文件中声明,源文件中定义
正确的跨文件共享全局变量,需要遵循"一处定义,到处声明"的原则:
c
// CN:正确做法 - 步骤1:在头文件中声明 -- EN:Correct approach - Step 1: Declare in header file
/* globals.h */
#ifndef GLOBALS_H
#define GLOBALS_H
// CN:extern关键字 = 仅仅声明,不分配内存 -- EN:extern keyword = declaration only, no memory allocated
extern int my_var;
#endif
c
// CN:正确做法 - 步骤2:在某个.c文件中定义 -- EN:Correct approach - Step 2: Define in one .c file
/* main.c */
#include "globals.h"
// CN:不带extern = 真正的定义,分配内存 -- EN:Without extern = real definition, memory allocated
int my_var = 0;
void main(void)
{
my_var = 10;
// ...
}
c
// CN:正确做法 - 步骤3:其他.c文件直接包含头文件使用 -- EN:Correct approach - Step 3: Other .c files just include the header
/* sensor.c */
#include "globals.h"
void read_sensor(void)
{
// CN:直接使用,无需再次声明 -- EN:Use directly, no need to re-declare
if (my_var > 100)
{
// ...
}
}d. MCU特有变量的声明与定义
对于MCU中带有硬件地址的特殊变量(如位于特定寄存器页、I/O页或RAM区的变量),规则完全一致。只是语法上需要额外携带地址信息。这些关键词(如io、rpage、bank等)在声明时必须完全保留。
c
// CN:MCU特有变量的声明与定义 -- EN:Declaration and definition of MCU-specific variables
/* globals.h */
#ifndef GLOBALS_H
#define GLOBALS_H
// CN:声明(带完整修饰符,用extern前缀)-- EN:Declaration (with full modifiers, using extern prefix)
extern io unsigned int DIR_PORT;
extern unsigned int data_buffer @0x22 : bank 1;
#endif
c
/* hardware.c */
#include "globals.h"
// CN:定义(带完整修饰符和地址,不带extern)-- EN:Definition (with full modifiers and address, without extern)
io unsigned int DIR_PORT @0x06 : iopage 0;
unsigned int data_buffer @0x22 : bank 1;💡 核心口诀:
- 头文件 中:永远用
extern声明,永远不写地址。- 源文件 中:不用
extern,才写地址,完成真正的定义。- 这样做既避免了链接器报"重复定义"错误,也让变量所在的硬件位置一目了然。
好的,我来为您扩展"如何在C中切换程序页或RAM区"这个问题,使其更具普遍性,适用于解释任意MCU平台下的通用原理。
7、 C语言中如何切换程序页或RAM区
这个问题的答案分两种情况:纯C编程几乎不需要手动干预,但一旦涉及内嵌汇编,就必须亲力亲为。
要理解"切换"的必要性,我们得先回顾一下8位或16位MCU的一个经典设计限制:地址空间分页。
a. 为什么要分页?
很多中小型MCU的CPU字长有限,例如8位机的程序计数器(PC)可能只有12位或14位宽,直接寻址范围只有4K或16K。当芯片的ROM或RAM实际容量超过这个范围时,硬件设计师就引入了"页面"的概念------将整个存储空间划分成多个大小相同的"页",通过一组专门的页面选择寄存器来切换当前CPU"看向"的是哪一页。
bash
CN:分页存储示意:
EN:Paged Memory Illustration:
ROM(Program Memory) RAM(Data Memory)
+----------------------------+ +----------------------------+
| Page 0: 0x0000 - 0x0FFF | | Bank 0: 0x00 - 0xFF |
| (可直接寻址) | | (可直接寻址) |
|----------------------------| |----------------------------|
| Page 1: 0x1000 - 0x1FFF | | Bank 1: 0x00 - 0xFF |
| (切换后可见) | | (切换后可见) |
|----------------------------| |----------------------------|
| Page 2: 0x2000 - 0x2FFF | | Bank 2: 0x00 - 0xFF |
| (切换后可见) | | (切换后可见) |
+----------------------------+ +----------------------------+b. 纯C编程:编译器全权负责
好消息是,现代嵌入式C编译器已经足够智能,能自动处理分页切换。当您在C代码中用绝对定位语法声明了一个位于某页的变量,编译器会在读写该变量前后,自动插入页面切换指令。
c
// CN:纯C编程------编译器自动切换页面 -- EN:Pure C programming - compiler auto-switches pages
// CN:三个变量位于不同RAM区 -- EN:Three variables located in different RAM banks
unsigned int data_a @0x20 : bank 0;
unsigned int data_b @0x20 : bank 1;
unsigned int data_c @0x20 : bank 2;
void main(void)
{
data_a = 10; // CN:编译器自动切到bank 0,写入,再切回 -- EN:Compiler auto-switches to bank 0, writes, then switches back
data_b = 20; // CN:编译器自动切到bank 1,写入,再切回 -- EN:Compiler auto-switches to bank 1, writes, then switches back
data_c = 30; // CN:编译器自动切到bank 2,写入,再切回 -- EN:Compiler auto-switches to bank 2, writes, then switches back
}作为开发者,您完全不需要知道页面寄存器在哪个地址、切换指令是什么。编译器生成的汇编代码会自动处理一切。这是C语言相较汇编最大的生产力优势之一。
c. 内嵌汇编:开发者全责管理
但一旦您在C代码中插入了__asm块,编写了自定义的汇编语句,页面管理的责任就完全落到了您的肩上。如果在汇编块内切换了页面,必须在退出汇编块之前恢复原状,否则后续的C代码会在错误的页面下执行,导致数据读写错乱。
c
// CN:内嵌汇编时的正确做法------保存和恢复 -- EN:Correct approach when using inline assembly - save and restore
void func_with_asm(void)
{
unsigned char nbuf[2]; // CN:临时存储,用于保存页面状态 -- EN:Temporary storage for saving page state
__asm
{
// CN:第1步------保存当前页寄存器 -- EN:Step 1 - Save current page register
mov a, 0x03 ; CN:假设0x03是状态/页寄存器 -- EN:Assuming 0x03 is the status/page register
mov %nbuf, a ; CN:存入nbuf[0] -- EN:Store into nbuf[0]
mov a, 0x04 ; CN:假设0x04是另一页寄存器 -- EN:Assuming 0x04 is another page register
mov %nbuf+1, a ; CN:存入nbuf[1] -- EN:Store into nbuf[1]
// CN:第2步------切换到目标页面 -- EN:Step 2 - Switch to target page
bs 0x03, 6 ; CN:设置位6,切换到目标bank -- EN:Set bit 6, switch to target bank
bs 0x03, 7 ; CN:设置位7 -- EN:Set bit 7
// CN:第3步------在目标页面执行操作 -- EN:Step 3 - Perform operations in target page
mov a, 0x20 ; CN:读取目标页的0x20地址 -- EN:Read address 0x20 in target page
// ...
// CN:第4步------恢复原页面(关键!忘记这步会死机)-- EN:Step 4 - Restore original page (critical! Forgetting this causes crash)
mov a, %nbuf ; CN:从nbuf[0]取出原值 -- EN:Retrieve original value from nbuf[0]
mov 0x03, a ; CN:恢复页寄存器0x03 -- EN:Restore page register 0x03
mov a, %nbuf+1 ; CN:从nbuf[1]取出原值 -- EN:Retrieve original value from nbuf[1]
mov 0x04, a ; CN:恢复页寄存器0x04 -- EN:Restore page register 0x04
}
}💡 黄金法则:汇编页切换的"借-用-还"原则
在内嵌汇编中操作页面,务必遵循三步:
- 借前存档:在修改页寄存器之前,先把它的当前值读出来,存入一个临时变量。
- 专心办事:在正确的页面下执行你的操作。
- 原样归还:退出汇编块之前,从临时变量恢复页寄存器的原值。
任何违反此原则的操作,都会导致程序行为异常------这种bug通常极难排查,因为症状(如变量值莫名改变)会在远离出问题点的地方才显现。
总之,纯C编程时,请放心地把页管理交给编译器。但凡写下一行自定义汇编,就必须把页面状态的"借还"当成铁律来遵守。这是嵌入式底层开发的基本功,也是区分新手和资深工程师的重要细节。
8、 如何分析堆栈调用深度
在MCU开发中,提前掌握函数调用的最大嵌套深度至关重要,因为它直接关系到我们上一篇提到的"函数调用能嵌套多少层"这个硬约束。幸运的是,编译器会为我们提供分析堆栈调用深度的关键信息,主要藏在这两个地方:输出窗口的编译日志 和map文件。
a. 通过输出窗口快速查看
在多数集成开发环境中,当编译和链接全部完成后,"输出"或"编译"窗口会打印一条摘要信息,其中往往包含调用深度的分析结果。双击带有警告或信息标识的行,有时还能直接定位到相关函数。
CN:输出窗口中可能显示的典型信息:
EN:Typical information displayed in the output window:
Info: maximum stack usage is 8 bytes at function 'process_data'
Info: call graph depth is 5 levels (including interrupts)
Warning: possible stack overflow at call chain 'main -> parser -> validator' 这些信息直接告诉您:最坏情况下,从main函数到最深层嵌套函数,一共会消耗多少字节的栈空间,最深会达到几级调用。如果编译器给出了"堆栈溢出"的警告,务必严肃对待。
b. 通过map文件深入分析
输出窗口的信息是摘要性的,而map文件 则是编译器生成的完整链接布局报告。它通常以.map为扩展名,位于工程编译输出目录下。用文本编辑器打开后,您可以找到以下关键章节:
1. 调用图(Call Graph)
部分编译器会在map文件中直接生成全局函数调用图。它以缩进或树状结构展示每个函数调用了哪些子函数,帮助您直观地看到调用链路。
CN:map文件中的调用图示例:
EN:Call Graph Example in map file:
Call Graph (partial):
main
-> init_system
-> read_sensors
-> i2c_start
-> i2c_read
-> delay_us
-> process_data
-> calculate_average
-> update_display
-> spi_send 从这个调用图中,您可以数出main -> read_sensors -> i2c_read -> delay_us这条路径的调用深度为4级。如果这个MCU的硬件堆栈深度是8级,那么还剩4级安全余量。
2. 堆栈使用分析(Stack Usage)
这是最精确的信息。编译器会为每个函数计算其"栈帧"大小(即该函数被调用时需要在栈上消耗的字节数),并在map文件中逐函数列出。
CN:map文件中的堆栈使用列表:
EN:Stack Usage List in map file:
Stack Usage (in bytes):
main: 4
init_system: 2
read_sensors: 8
i2c_start: 2
i2c_read: 6
delay_us: 2
process_data: 4
calculate_average: 12
update_display: 6
spi_send: 2有了每个函数的栈消耗量,再结合调用图,您就可以精确计算出最坏路径的总栈消耗。
c. 手动计算最坏路径栈消耗
在大型或复杂工程中,调用图可能非常庞大。此时需要找出消耗最大的调用链 。方法是从main开始深度优先遍历整个调用树,计算每条路径的累计栈消耗,取最大值。同时必须将中断服务程序的栈消耗也叠加在最坏路径之上,因为中断可能在任意时刻打断主程序。
CN:最坏路径栈消耗计算示例:
EN:Worst-case stack consumption calculation example:
路径1:main(4) -> init_system(2) = 6 bytes
路径2:main(4) -> read_sensors(8) -> i2c_read(6) -> delay_us(2) = 20 bytes
路径3:main(4) -> process_data(4) -> calculate_average(12) = 20 bytes
CN:所有路径最大栈消耗 = 20 bytes -- EN:Maximum stack consumption of all paths = 20 bytes
CN:叠加ISR栈消耗(假设Timer ISR需要10 bytes)-- EN:Add ISR stack consumption (assuming Timer ISR needs 10 bytes)
CN:最坏总栈消耗 = 20 + 10 = 30 bytes -- EN:Worst-case total stack consumption = 20 + 10 = 30 bytesd. 静态分析与动态验证
| 方法 | 操作方式 | 优点 | 缺点 |
|---|---|---|---|
| 静态分析 | 阅读map文件和调用图,手动计算 | 覆盖所有路径,可给出理论上界 | 人工工作量大,复杂工程易遗漏 |
| 动态验证 | 在栈顶区域填充已知魔数(如0xAA),运行一段时间后检查被覆盖的范围 | 真实反映实际运行情况 | 不保证覆盖到最坏路径 |
💡 最佳实践:
- 编译后必查map:每次成功编译后,打开map文件看看调用深度和栈使用摘要。
- 关注直接递归 :
recursive_call()这样的函数如果在调用图中指向自身,要特别留意最大递归深度。- 设置栈安全余量:如果硬件堆栈深度是8级,代码最坏使用了6级,余量为2级。记得为未来的功能修改预留空间。
- 中断叠加计算:永远把ISR的栈消耗叠加上去,这是最容易在计算中被忽略的一环。
只要您养成了查看map文件调用图和栈使用摘要的习惯,并理解其背后的物理含义,就能在99%的情况下避免堆栈溢出这种灾难性bug。
记住,map文件是编译器写给开发者的"内存使用说明书",读懂它,是嵌入式进阶的必修课。
9. 编译器偷偷占用了哪些RAM
很多MCU开发者都听说过"编译器会保留一部分RAM自用"的说法,但对于具体占用了哪些区域、在什么情况下会额外占用,往往一知半解。这个问题如果理解不透彻,写出的代码就可能与编译器产生冲突,导致程序行为异常。
a. 编译器的"保留区域"从何而来
C语言的标准运算(尤其是多字节乘除法、移位等)在8位MCU上没有对应的单条机器指令。编译器为了实现这些运算,会调用一些预编译好的内部辅助函数。这些辅助函数需要一些临时存储空间来做中间计算,于是编译器就从通用RAM中划出一块固定区域,作为"内部临时寄存器"。
这个区域通常位于通用RAM的某一段连续地址,大小取决于编译器的设计。在本文基于的架构中,就是0x10~0x1F这16个字节。在其它MCU架构中,具体地址不同,但原理完全一致。
CN:编译器保留RAM示意:
EN:Compiler Reserved RAM Illustration:
+---------------------------+ <---- RAM起始地址
| 0x00 - 0x0F: 特殊功能寄存器 |
|---------------------------|
| 0x10 - 0x1F: 编译器保留区 | ← CN:用于乘除/移位等运算的临时存储 -- EN:Temp storage for mul/div/shift operations
|---------------------------|
| 0x20 - 0x3F: 用户可用区 | ← CN:全局变量 + 局部变量 -- EN:Global variables + local variables
+---------------------------+b. 什么情况下编译器会额外"扩张"
除了这个固定的保留区外,当您在函数内定义了局部变量 时,编译器还需要为这些局部变量分配存储空间。由于堆栈在小型MCU上往往很小甚至不存在,许多8位编译器采用的策略是:将局部变量直接分配到RAM的可用区域。
这就是原文提到的"编译器会用到bank 03的0x200x3F地址"的原因------您的局部变量会悄悄占用这些地址,和全局变量混在一起。
c
// CN:局部变量→会占用开发者可用的RAM区 -- EN:Local variables → occupy RAM space otherwise available to the developer
void process(void)
{
// CN:这三个变量会被分配到0x20~0x3F范围内的某个地址 -- EN:These 3 variables will be assigned somewhere in 0x20~0x3F
unsigned int i;
unsigned short result;
char buffer[4];
for (i = 0; i < 10; i++)
{
result += i;
}
}c. 不同运算占用的保留寄存器不同
编译器并非在任何情况下都占用全部保留区。不同运算所需的临时存储量不同,下表展示了典型运算与保留寄存器的对应关系:
| 运算类型 | 需要占用的保留寄存器(示例) | 说明 |
|---|---|---|
+ - & ` |
^` |
通常不占用额外寄存器 |
* / % |
0x1C 0x1D 0x1E等 |
乘除需要循环累加/减 |
<< >>(多位移) |
0x14等 |
移位需逐位操作 |
长整型* / % |
0x10~0x19等更多寄存器 |
多字节运算复杂 |
了解这些对应关系,在编写中断服务程序时尤为重要。如果您的ISR中只用到了加减逻辑,那么需要备份的保留寄存器就少很多。
💡 最佳实践:
- 中断中尽量用全局变量:ISR中使用全局变量而非局部变量,既减少了编译器额外占用RAM的风险,也避免了复杂的栈操作。
- 编译后检查输出:编译完成后,输出窗口会明确告知哪些保留寄存器被占用。根据这些信息,决定在ISR中需要备份哪些寄存器。
- 不要假设"空着就能用":即使肉眼看着保留区似乎没被占用,下一秒加一个乘法运算,编译器就可能静默使用它们。
c
// CN:推荐做法------ISR中用全局变量 -- EN:Recommended approach - use global variables in ISR
unsigned int tick_count; // CN:全局变量,不占用临时寄存器 -- EN:Global variable, doesn't occupy temp registers
void __interrupt Timer_ISR(void)
{
// CN:只有简单的++和比较,不涉及乘除 -- EN:Only simple ++ and comparison, no mul/div involved
tick_count++;
if (tick_count >= 1000)
{
tick_count = 0;
trigger_flag = 1; // CN:全局标志位 -- EN:Global flag
}
}总之,编译器保留区是MCU开发中的"隐形规则"。作为开发者,您需要清楚哪些区域被保留、哪些运算会触发额外占用,并在中断编程中严格遵循备份规范。养成交付前阅读map文件和编译日志的习惯,是规避这类底层冲突的最有效手段。
七、总结
- 开发建议
- 代码优化: 优先使用局部变量和全局变量,减少RAM占用
- 中断安全: 始终备份0x10~0x1F寄存器
- 调试技巧: 充分利用WicePlus的监视窗口和断点功能
- 代码移植: 注意数据类型和运算符的转换率