
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言:
- [一. 基础认知:从模型到大语言模型(LLM)](#一. 基础认知:从模型到大语言模型(LLM))
-
- [1.1 模型的本质:从数据中学习规律的数学函数](#1.1 模型的本质:从数据中学习规律的数学函数)
- [1.2 大语言模型(LLM):不止是 "大" 的语言预测器](#1.2 大语言模型(LLM):不止是 “大” 的语言预测器)
-
- (1)神经网络:模仿人脑的复杂决策流水线
- [(2)自监督学习:"完形填空" 超级大师](#(2)自监督学习:“完形填空” 超级大师)
- (3)半监督学习:"师父领进门,修行在个人"
- (4)语言模型:"超级自动补全系统"
- [1.3 业界主流大语言模型](#1.3 业界主流大语言模型)
- [二. LLM 的四大核心能力,重新定义人机交互](#二. LLM 的四大核心能力,重新定义人机交互)
-
- [2.1 语言大师:自然语言理解与创造的革命](#2.1 语言大师:自然语言理解与创造的革命)
- [2.2 知识巨人:可对话的全互联网知识库](#2.2 知识巨人:可对话的全互联网知识库)
- [2.3 逻辑与代码巫师:从思维到实现的跨越](#2.3 逻辑与代码巫师:从思维到实现的跨越)
- [2.4 多模态先知:开启 "全感知" AI 时代](#2.4 多模态先知:开启 “全感知” AI 时代)
- [三. 提示词工程:与 LLM 高效对话的核心秘籍](#三. 提示词工程:与 LLM 高效对话的核心秘籍)
-
- [3.1 CO\-STAR 结构化框架:让提示词无懈可击](#3.1 CO-STAR 结构化框架:让提示词无懈可击)
- [3.2 少样本提示:用示例教会 LLM 你的需求](#3.2 少样本提示:用示例教会 LLM 你的需求)
- [3.3 思维链提示(CoT):让模型学会 "思考"](#3.3 思维链提示(CoT):让模型学会 “思考”)
- [3.4 零样本思维链:一句魔法短语提升推理准确率](#3.4 零样本思维链:一句魔法短语提升推理准确率)
- [3.5 自我批判与迭代:让模型自己优化输出](#3.5 自我批判与迭代:让模型自己优化输出)
- [四. LLM 原生接入实战:三大方式全解析](#四. LLM 原生接入实战:三大方式全解析)
-
- [4.1 API 远程调用:最主流便捷的接入方式](#4.1 API 远程调用:最主流便捷的接入方式)
- [4.2 SDK 接入:API 调用的封装与简化](#4.2 SDK 接入:API 调用的封装与简化)
- [4.3 开源模型本地部署:私有化 LLM 能力的最佳方案](#4.3 开源模型本地部署:私有化 LLM 能力的最佳方案)
- [4.4 原生 LLM 接入的四大核心局限](#4.4 原生 LLM 接入的四大核心局限)
- 五、嵌入模型:大模型应用的语义基石
-
- [5.1 嵌入模型的本质:把人类语言翻译成计算机的数学语言](#5.1 嵌入模型的本质:把人类语言翻译成计算机的数学语言)
- [5.2 嵌入模型的四大核心应用场景](#5.2 嵌入模型的四大核心应用场景)
- [5.3 嵌入模型接入实战](#5.3 嵌入模型接入实战)
- [六、LangChain:连接 LLM 与业务应用的核心桥梁](#六、LangChain:连接 LLM 与业务应用的核心桥梁)
- 结尾:
前言:
随着 GPT、DeepSeek、通义千问等大语言模型的爆发,AI 已经从技术圈的炫技概念,变成了像电一样融入千行百业的数字化基础设施。但对于绝大多数开发者而言,想要把大模型能力落地到实际业务中,绝非简单调用一次 API 就能完成 ------ 原生大模型接口存在上下文长度限制、私有知识缺失、复杂任务拆解能力弱、输出格式不可控等核心痛点。而 LangChain,正是连接大语言模型(LLM)与实际 AI 应用的核心桥梁。本文将从模型的底层数学本质出发,完整拆解 LLM 的核心原理、能力边界、提示词工程秘籍,结合实战代码详解 LLM 与嵌入模型的接入方式,最终带你理解 LangChain 的核心价值,打通大模型应用开发的全链路。
一. 基础认知:从模型到大语言模型(LLM)
很多人会混淆 "模型" 和 "大语言模型" 的概念,二者本质上有天壤之别,也是我们理解大模型技术的起点。


1.1 模型的本质:从数据中学习规律的数学函数
模型,本质上是一个从数据中学习规律的数学函数或程序 ,它通过从数据集中学习模式,完成预测、分类等特定任务。我们可以用一个通俗的比喻来理解:
模型就像一个 "超级加工厂",训练师给它看海量带标注的示例数据,它会自己摸索出输入和输出之间的规则,学成之后就能根据新的输入,生成符合规律的输出。
举个最简单的例子:
-
给模型输入
\[1,2,3\],标注输出为2 -
给模型输入
\[5,10,15\],标注输出为10
模型会自主学习到 "输出是输入数组的中间值" 这一规律,当输入新的数组\[8,9,10\]时,就能准确预测输出为9。
传统模型有三个核心特点:
-
特定任务导向:一个模型通常只擅长一件事,比如识别图片中的猫、预测天气、判断评论情感
-
强依赖标注数据:训练需要大量带 "标准答案" 的标注数据,数据标注成本极高
-
参数规模小:参数是模型学到的 "知识要点",参数少意味着模型复杂度和能力边界有限
1.2 大语言模型(LLM):不止是 "大" 的语言预测器
大语言模型(Large Language Model, LLM),是指基于大规模神经网络(参数规模通常达数十亿至万亿级别),通过自监督或半监督方式,对海量文本进行训练的语言模型。
想要真正理解 LLM,必须先拆解它的四个核心底层概念:
(1)神经网络:模仿人脑的复杂决策流水线
神经网络可以理解为一个极其高效的团队工作流程或条件反射链 ,它完全模仿人脑神经元的工作模式:
就像教小朋友识别猫,我们不会只给一条 "有胡子就是猫" 的规则,而是让他看海量猫的图片,大脑里的神经元会分工协作:有的识别尖耳朵、有的识别胡须、有的识别毛茸茸的尾巴,最终综合所有信息判断 "这是猫"。
神经网络就是由大量虚拟 "神经元"(即参数)和连接组成的多层结构,前一层的输出作为后一层的输入。通过海量数据训练,网络会自主调整每个神经元的权重(参数值),最终形成一套复杂的决策系统。参数就是 LLM 的 "脑细胞",参数规模越大,模型的思考复杂度和全面性就越强 。
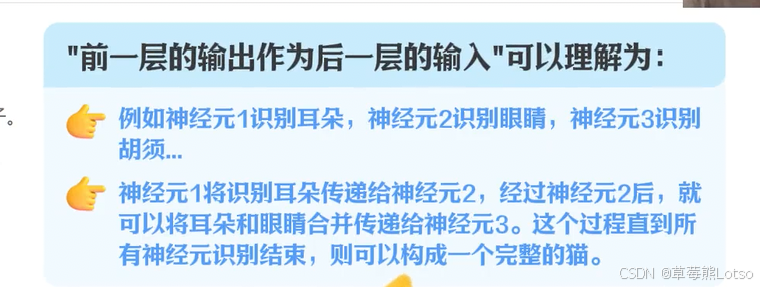

(2)自监督学习:"完形填空" 超级大师
自监督学习是 LLM 最核心的训练方式,本质上是让模型自己给自己当老师,从无标注的原始文本中自主学习规律。
我们可以用学外语的场景类比:没有老师出题和批改,我们就拿一本外语小说玩 "完形填空",随机盖住一个词,根据上下文猜测这个词是什么。经过亿万次练习,我们就能彻底掌握这门语言的语法、词汇搭配和上下文逻辑。
LLM 的自监督学习正是这个过程:面对互联网上海量的无标注文本,它随机遮住一句话中的某个词,尝试根据上下文预测被遮住的内容。通过这种方式,它无需人工标注,就能高效学习到整个语言世界的底层规律。

(3)半监督学习:"师父领进门,修行在个人"
半监督学习是自监督学习的补充,核心是少量标注数据入门 + 海量无标注数据自学的结合模式。
就像学做菜,师傅先教你几道招牌菜(少量带标注的数据),让你掌握基本功;再让你尝遍天下美食,自己研究其中的门道(海量无标注数据),最终你不仅能复刻招牌菜,还能创新出新菜式。这种方式能让模型在有限的标注数据下,快速提升通用能力。

(4)语言模型:"超级自动补全系统"
语言模型的核心本质,是一个语言预测器,它的核心任务就是 "根据前文,预测下一个最合理的词"。
我们手机输入法的联想功能,就是一个微型语言模型:输入 "今天天气真",它会自动提示 "好""冷""不错" 等后续词汇。而强大的 LLM,能通过逐词预测,生成一整段通顺的话、一篇完整的文章,甚至是复杂的代码。

基于以上核心概念,我们可以把 LLM 翻译成大白话:
它是用大规模神经网络搭建的、拥有数百亿甚至上万亿参数的超级自动补全系统,通过海量完形填空式的自监督学习,从互联网全量文本中学会了语言的底层规律,最终具备了跨任务的通用能力。
LLM 相比传统模型,有四个颠覆性的核心特点:
-
规模巨大:参数量达数十亿至万亿级别,具备极强的复杂信息处理能力
-
通用性强:不是为单一任务训练,能把语言底层规律举一反三,应用到聊天、翻译、写代码等无数场景,具备强大的 "涌现" 能力
-
训练效率极高:主要使用自监督学习,不依赖人工标注数据,能轻松实现规模扩张
-
交互方式革命:无需学习复杂的代码或软件操作,用自然语言下达指令,模型就能听懂并执行
1.3 业界主流大语言模型
| 模型名称 | 厂商 | 核心优势 |
|---|---|---|
| GPT-5 | OpenAI | 支持 400k 超长上下文、128k 最大输出,在多轮复杂推理、创意写作中表现突出 |
| DeepSeek R1 | 深度求索 | 开源模型,专注逻辑推理与数学求解,支持 128K 长上下文和 20 + 语言,科技领域表现优异 |
| Qwen2.5-72B-Instruct | 阿里巴巴 | 通义千问开源核心模型,擅长代码生成、结构化数据处理、角色扮演,支持 29 种语言,适配企业级复杂任务 |
| Gemini 2.5 Pro | 多模态融合标杆,支持图像 / 代码 / 文本混合输入,完美适配图文生成、技术文档解析等跨模态任务 |

二. LLM 的四大核心能力,重新定义人机交互
LLM 之所以能引发生产力革命,核心在于它具备了四大跨越性的能力,彻底打破了机器与人类的沟通壁垒。
2.1 语言大师:自然语言理解与创造的革命
LLM 真正实现了对人类语言的深度理解,它不仅能识别字面意思,还能读懂上下文、情感倾向甚至潜台词,完成高质量的语言创作。
-
学生可以让它生成论文引言段落,快速搭建写作框架
-
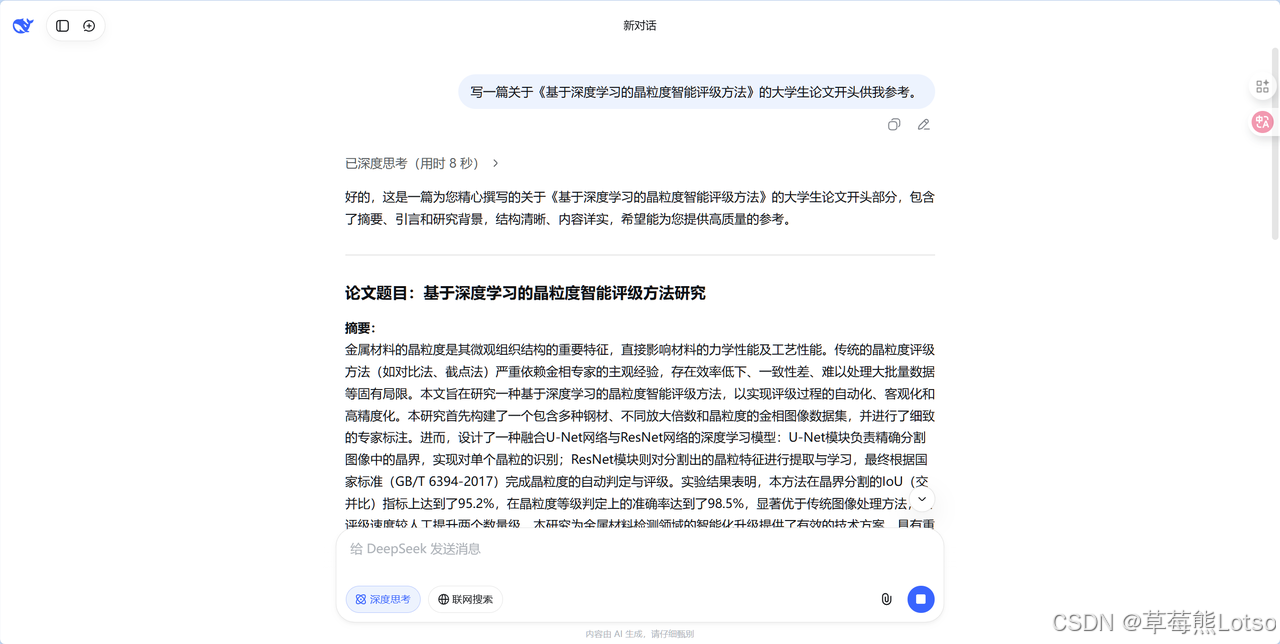
职场人可以让它撰写礼貌又坚决的投诉邮件、商务函件,稍作修改即可使用
-
创作者可以让它生成故事脚本、诗歌文案,提供无限的创作灵感
2.2 知识巨人:可对话的全互联网知识库
LLM 通过学习海量的公开数据,构建了一个立体的、可对话的知识网络,覆盖了物理、化学、哲学、历史等几乎所有学科领域。
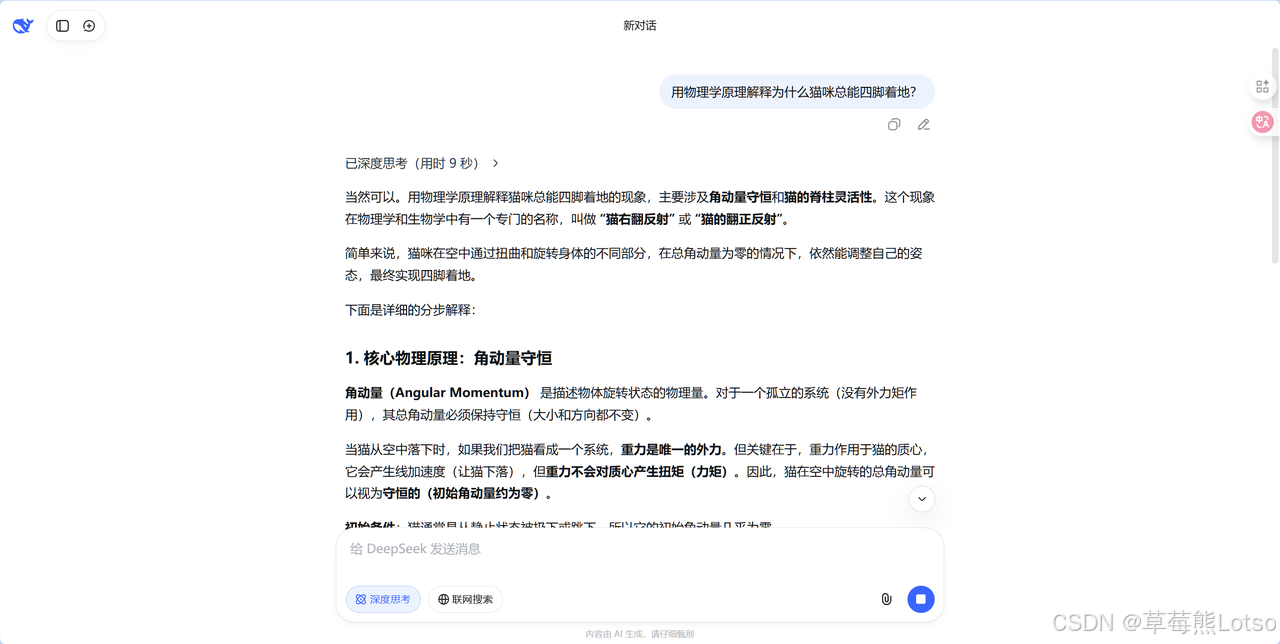
- 你可以问它 "用物理学原理解释为什么猫咪总能四脚着地",它会从角动量守恒的角度,一步步给你讲清 "猫的正反射" 原理
- 你也可以让它 "对比古希腊哲学和春秋战国百家争鸣的异同",它能从历史背景、思想内核、发展脉络等维度,给出完整的对比分析

2.3 逻辑与代码巫师:从思维到实现的跨越
LLM 的能力早已突破 "文科" 范畴,进入了需要极致精准的逻辑推理和编程领域。
- 程序员可以用自然语言描述需求,比如 "写一个 Python 函数,自动爬取网页最新标题并保存到 Excel",模型能瞬间生成可直接运行的代码
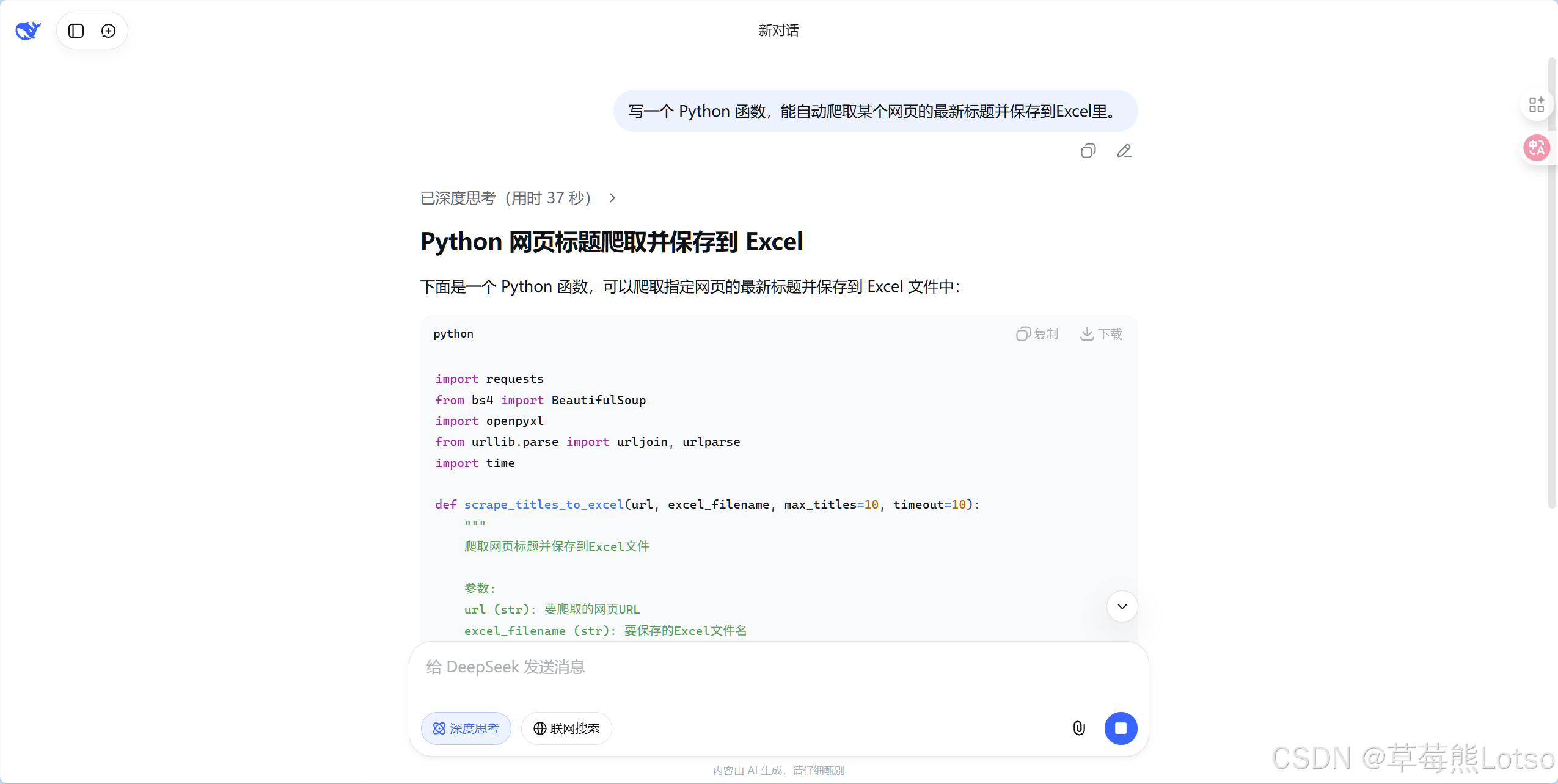
- 学生可以把复杂的微分方程、数学题丢给它,它不仅能给出答案,还能一步步展示完整的解题过程,成为一对一的私人家教

2.4 多模态先知:开启 "全感知" AI 时代
主流 LLM 已经打破了纯文本的边界,实现了文本、图像、音频、视频的多模态融合,让 AI 更接近人类的感知方式。
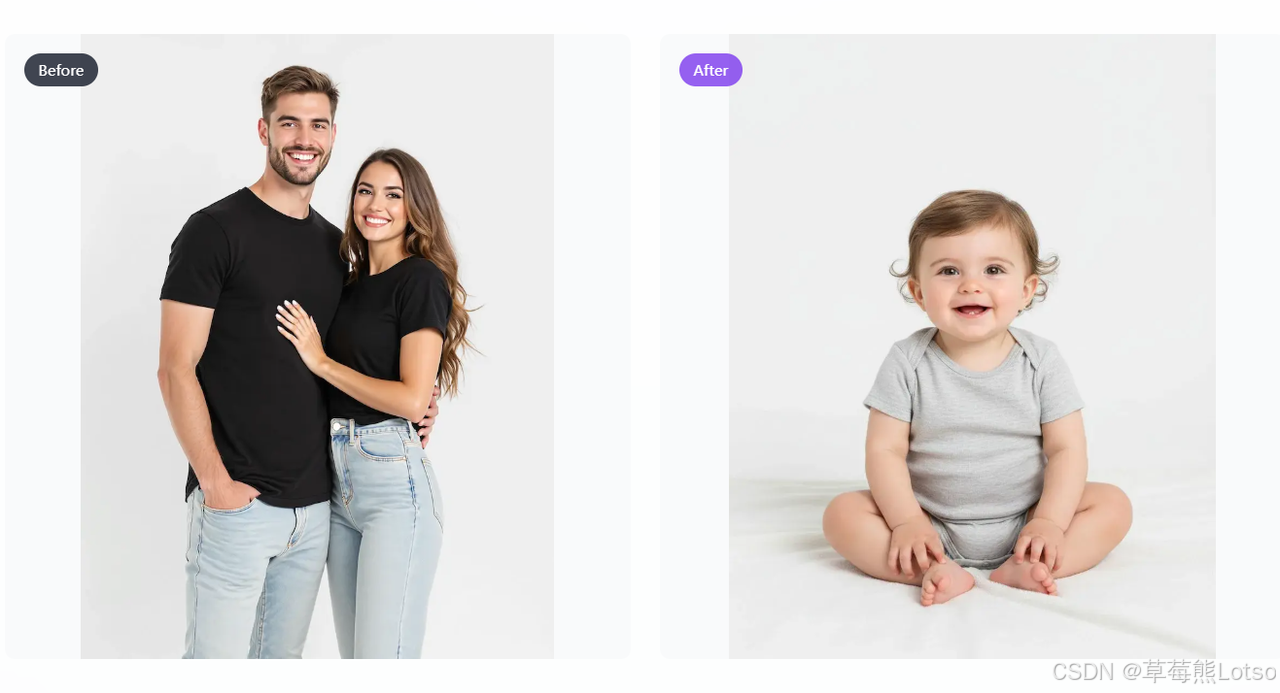
- 上传一张照片,搭配文字描述,就能完成创意修图、3D 建模、场景渲染等工作

- 可以基于父母的照片,生成融合双方特征的婴儿预测图像
- 可以解析技术图纸、PDF 文档、手写笔记,完成信息提取和深度分析
三. 提示词工程:与 LLM 高效对话的核心秘籍
想要让 LLM 输出高质量的结果,核心在于编写合理有效的提示词(Prompt)。好的提示词能精准限定需求范围,让模型完全理解你的意图,输出效果会有质的提升。
下面是经过工业界验证的五大核心提示词技巧,覆盖了绝大多数开发和应用场景。
3.1 CO-STAR 结构化框架:让提示词无懈可击
CO-STAR 框架由新加坡政府技术局开发,是目标设定、问题解决场景下的黄金提示词框架,它能确保你的提示词全面、结构清晰,让模型输出更精准。
| 模块 | 核心说明 | 示例 |
|---|---|---|
| Context | 任务背景与上下文 | "你是电商客服,需解答用户关于 iPhone 17 的咨询,知识库包含最新价格和库存" |
| Objective | 核心目标 | "准确回答价格、发货时间,推荐适配配件" |
| Steps | 执行步骤 | "1. 识别用户问题类型;2. 检索知识库;3. 用亲切语气整理回复" |
| Tone | 语言风格 | "口语化,避免专业术语,使用'亲~''呢'等语气词" |
| Audience | 目标用户 | "20-35 岁年轻消费者,对价格敏感,关注性价比" |
| Response | 输出格式 | "价格:XXX 元 \n 库存:XXX 件 \n 推荐配件:XXX" |
我们用一个实际案例看优化效果:
-
优化前(模糊低效):
我该怎么吃才能更健康? -
优化后(清晰有效):
Plain
角色:你是一个基于科学证据的 AI 营养顾问。
重要约束:你提供的所有建议都仅为通用信息,不能替代专业医疗诊断,在给出任何具体建议前,必须首先声明此免责条款。
任务:基于以下用户信息,提供一份个性化的每日饮食原则性建议。
用户信息:
• 年龄:30岁
• 性别:男性
• 目标:减脂增肌
• 日常活动水平:办公室久坐,每周进行3次力量训练
回答要求:
1. 首先,输出免责声明:"请注意:以下建议为通用健康信息..."
2. 核心原则应围绕"控制总热量摄入,确保充足蛋白质"
3. 分别对早餐、午餐、晚餐和训练加餐提出各1条核心建议
4. 推荐2种适合该用户的具体健康零食
5. 避免推荐任何具体的保健品或药物
输出格式:
【免责声明】
[此处输出声明]
【核心原则】
[此处输出内容]
【分餐建议】
早餐:...
午餐:...
【健康零食推荐】
1. ...
2. ...3.2 少样本提示:用示例教会 LLM 你的需求
少样本提示的核心思想,是给模型提供 1-3 个输入 - 输出的示例,让它 "照葫芦画瓢",精准学习你需要的格式、风格和逻辑,比单纯用文字描述规则高效得多。
适用场景:格式固定、风格独特、逻辑复杂的任务,比如风格仿写、数据提取、复杂格式生成。
实际案例:客户反馈信息提取
- 优化前(零样本提示):
Plain
请分析以下客户反馈,提取产品名称、情感倾向和具体问题。
反馈:"我刚买的耳机,才用了一周左边就没声音了,太让人失望了。"- 优化后(少样本提示):
Plain
请根据以下示例,分析后续的客户反馈,并提取产品名称、情感倾向和具体问题。
示例1:
反馈:"笔记本的电池续航太差了,完全达不到宣传的10小时,最多就4小时。"
分析:
• 产品名称:笔记本电池
• 情感倾向:负面
• 具体问题:续航远低于宣传
示例2:
反馈:"客服响应很快,非常专业地帮我解决了软件激活问题,点赞!"
分析:
• 产品名称:客服服务
• 情感倾向:正面
• 具体问题:无
现在请分析这个:
• 反馈:"我刚买的耳机,才用了一周左边就没声音了,太让人失望了。"3.3 思维链提示(CoT):让模型学会 "思考"
思维链提示(Chain of Thought, CoT),核心是要求模型在给出答案前,先展示完整的推导过程,模仿人类解决问题的思考方式,能大幅提升模型在复杂推理任务上的准确率。
适用场景:数学题、逻辑推理、复杂决策、需要解释过程的任务。

实际案例:
Plain
示例1:
Q:"罗杰有五个网球,他又买了两盒网球,每盒有3个网球,请问他现在总共有多少个网球?"
A:"罗杰起初有五个网球,又买了两盒网球,每盒3个,所以,他总共买了 2×3=6 个网球,将起始的数量和购买的数量相加,可以得到他现在总共的网球数量: 5+6=11 ,所以罗杰现在总共有11个网球"
问:"食堂总共有23个苹果,如果他们用掉20个苹果,然后又买了6个苹果,请问现在食堂总共有多少个苹果?"模型会模仿示例中的思维链,一步步完成计算,大幅降低计算错误的概率。
3.4 零样本思维链:一句魔法短语提升推理准确率
零样本思维链是少样本思维链的简化版,无需编写示例,只需在提示词末尾加上一句 "请一步步进行推理并得出结论",就能强制模型先完成内部推理,再给出最终答案。
这是成本最低、适用范围最广的推理提升技巧,尤其适合你也不清楚具体推理步骤的场景。比如经典的逻辑题:
Plain
一个杂耍者可以杂耍16个球。其中一半的球是高尔夫球,其中一半的高尔夫球是蓝色的。请问总共有多少个蓝色高尔夫球?请一步步进行推理并得出结论。不加这句提示时,模型很容易直接给出错误答案 "8";加上之后,模型会先拆解计算步骤,最终得出正确答案 "4"。
3.5 自我批判与迭代:让模型自己优化输出
自我批判与迭代的核心,是将 "生成" 和 "评审" 两个步骤分离,让模型从特定角度对自己的输出进行审查和优化,能显著提升内容的严谨性和质量。
适用场景:代码审查、文案优化、论证强化、安全检查。
实际案例:Python 代码编写与优化
Plain
请执行以下两个步骤:
步骤一:编写代码
写一个Python函数 find_max ,用于计算一个数字列表中的最大值。
步骤二:自我审查与优化
现在,请从代码健壮性和可读性的角度,审查你上面编写的代码。
请回答:
1. 如果输入是空列表,函数会怎样?如何改进?
2. 变量命名和代码结构是否清晰?能否让它更易于理解?
3. 请根据你的审查,给出一个优化后的最终版本。实战提示:在企业级开发中,以上技巧通常会组合使用,比如先用 CO-STAR 框架设定基础结构和角色,在执行步骤中融入思维链指令,对复杂格式补充少样本示例,最后要求模型完成自我审查,能实现最佳的输出效果。
Cursor 官方提示词:提示词
四. LLM 原生接入实战:三大方式全解析
想要自己开发 AI 应用,就必须通过代码接入 LLM 的原生能力。目前业界主流的原生接入方式有三种:API 远程调用 、开源模型本地部署 、官方 SDK 接入,下面我们结合代码逐一拆解。
4.1 API 远程调用:最主流便捷的接入方式
API 远程调用是目前最主流的接入方式,通过 HTTP 请求直接调用模型厂商部署在云端的模型服务,无需管理任何硬件资源,适合快速开发、应用集成场景。
核心流程
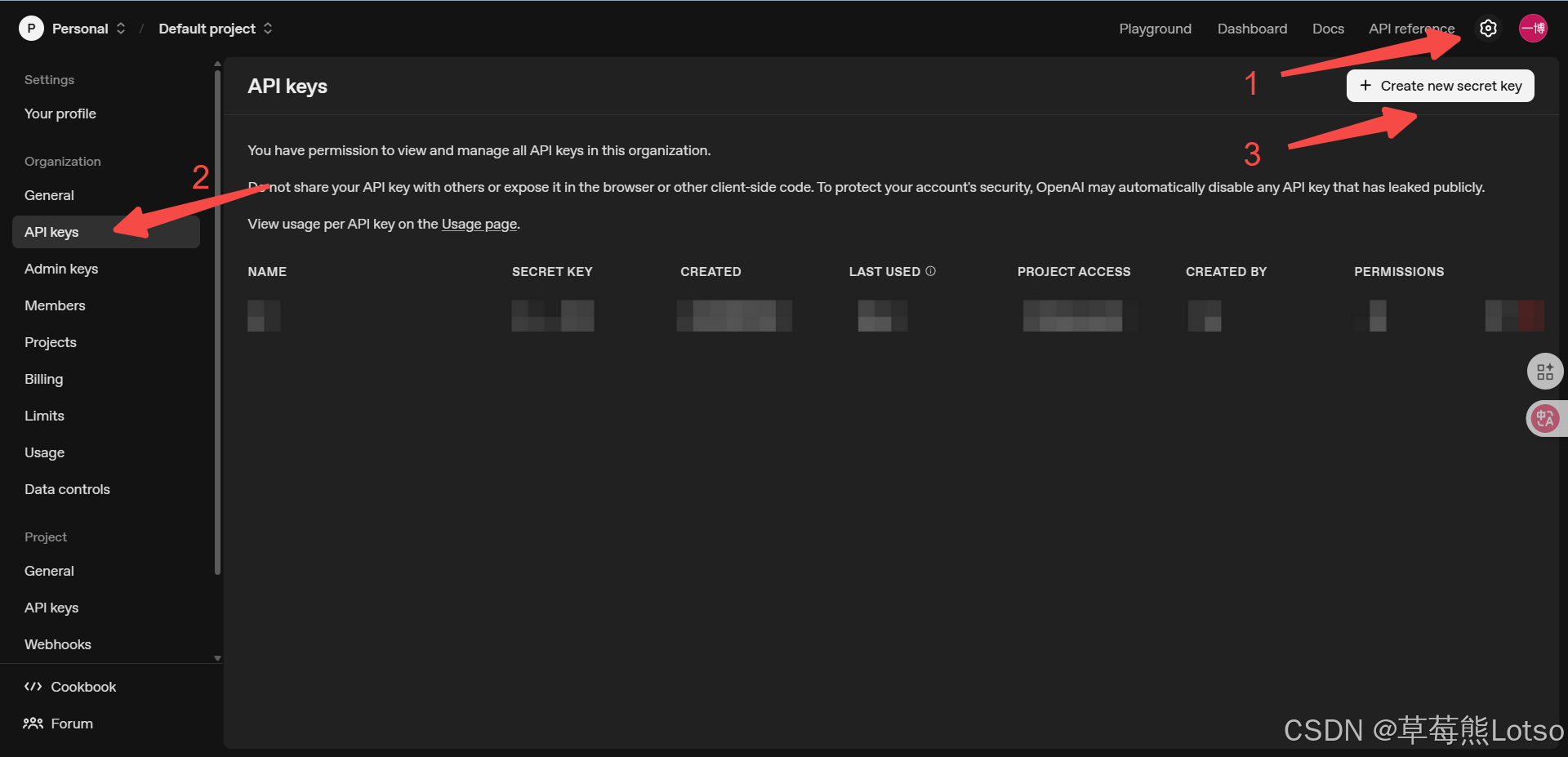
-
注册账号并获取 API Key:在模型厂商平台注册,获取用于身份验证的密钥
-
查阅 API 文档:了解请求端点、参数规范和返回数据格式
-
构建 HTTP 请求:使用 HTTP 客户端库,构建包含 API Key 和请求体的请求
-
发送请求并处理响应:解析返回的 JSON 数据,提取模型生成的内容
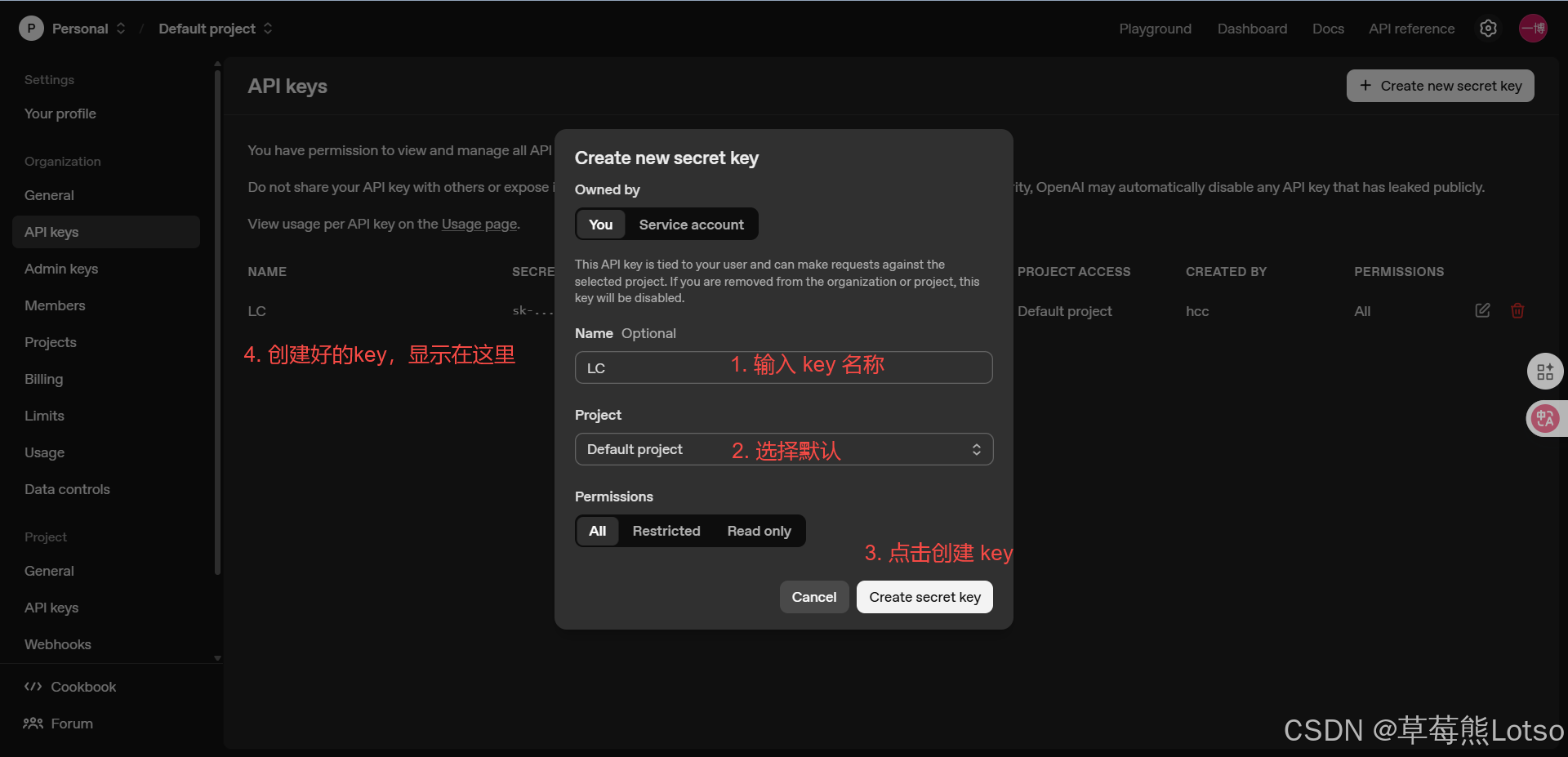
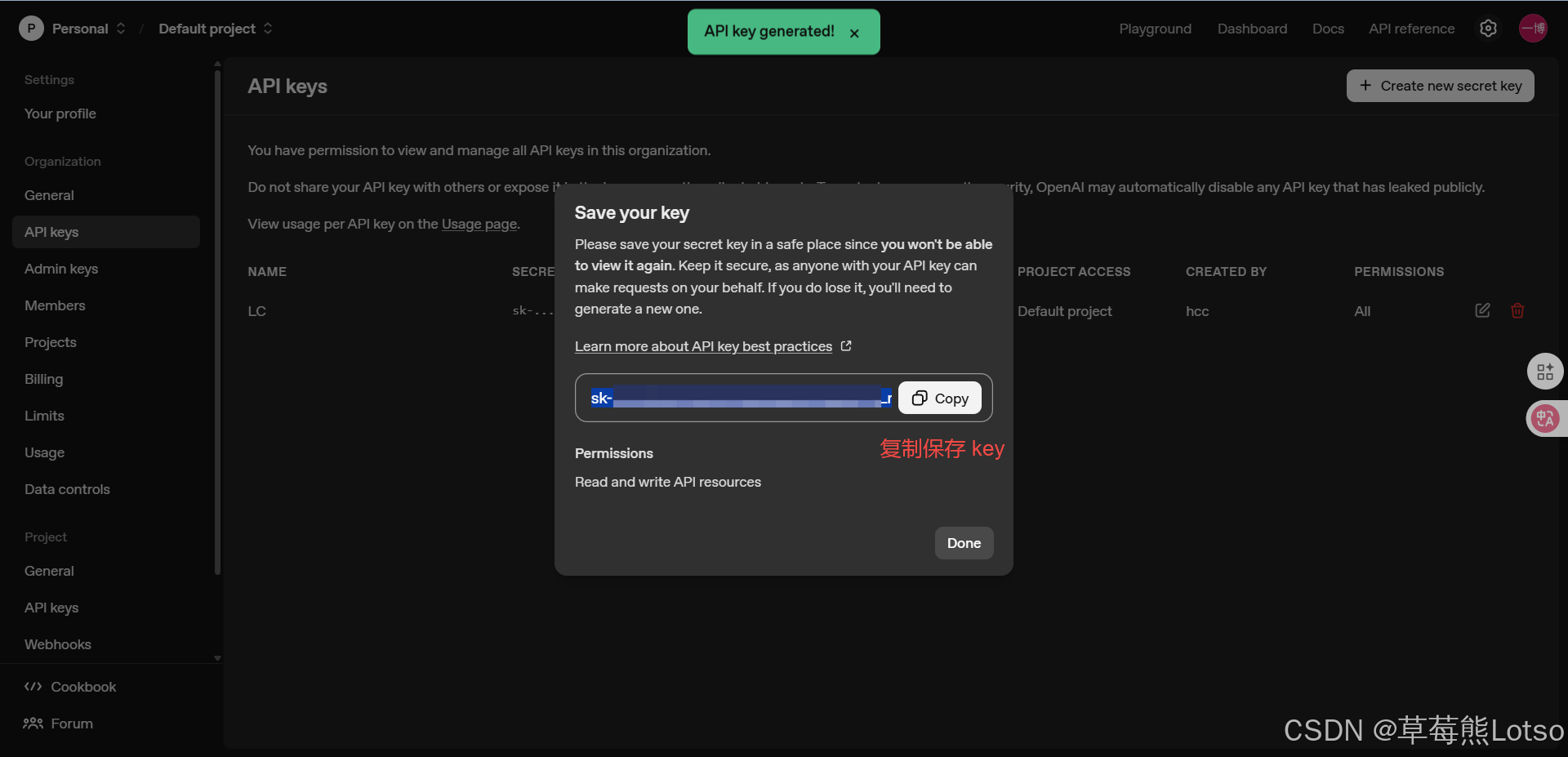
实战代码:curl 调用 OpenAI API
bash
# OpenAI 对话API调用示例
curl "https://api.openai.com/v1/responses" \
# 设置请求体格式为JSON
-H "Content-Type: application/json" \
# 携带API Key完成身份认证,$OPENAI_API_KEY为环境变量存储的密钥
-H "Authorization: Bearer $OPENAI_API_KEY" \
# 请求体:指定模型和用户输入
-d '{
"model": "gpt-5",
"input": "Write a one-sentence bedtime story about a unicorn."
}'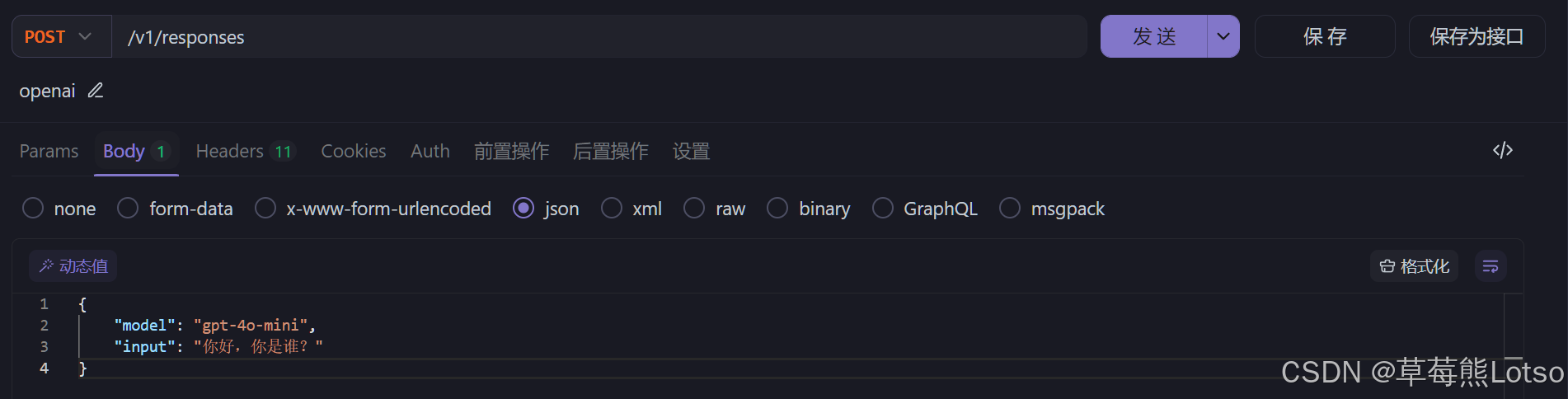
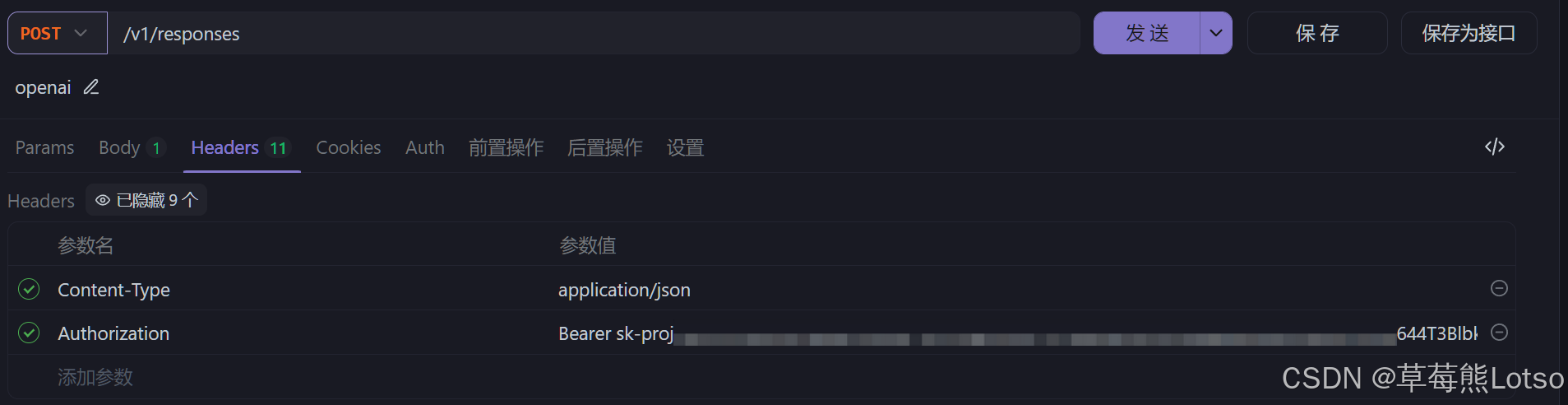
- 这里展示的是deepseek的
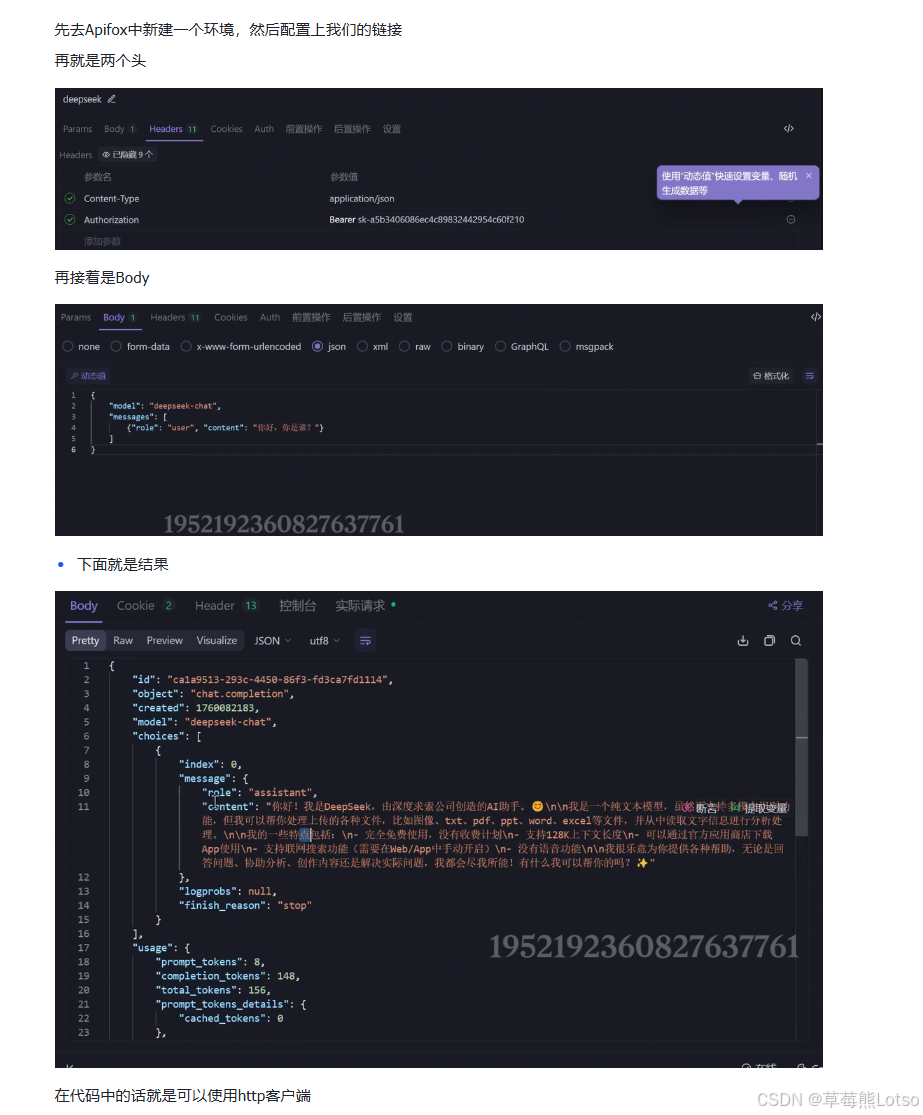
响应结果核心字段解析
API 会返回 JSON 格式的响应,核心字段如下:
json
{
"id": "resp_xxxxxx", // 本次请求的唯一ID,用于问题排查
"status": "completed", // 请求状态:completed成功/incomplete失败
"model": "gpt-4o-mini-2024-07-18", // 实际响应的模型
"output": [
{
"type": "message",
"role": "assistant", // 角色:assistant模型输出/user用户输入
"content": [
{
"type": "output_text",
"text": "你好!我是一个人工智能助手..." // 模型生成的核心文本
}
]
}
],
"usage": {
"input_tokens": 11, // 输入提示词消耗的token数
"output_tokens": 27, // 输出内容消耗的token数
"total_tokens": 38 // 本次请求总消耗token数,用于计费
}
}4.2 SDK 接入:API 调用的封装与简化
SDK 接入并非独立的接入方式,而是对原生 API 调用的封装和简化。模型厂商会发布对应编程语言的官方 SDK,封装底层 HTTP 请求细节,提供更符合编程习惯的函数库,让代码更简洁、易读、易维护。
实战代码:OpenAI Python SDK 接入
第一步:安装 SDK
bash
pip install openai第二步:核心代码与逐行解析
python
# 1. 导入OpenAI SDK的核心客户端类
from openai import OpenAI
# 2. 初始化客户端,传入API Key完成身份认证
client = OpenAI(api_key="your-api-key")
# 3. 调用模型接口,发起生成请求
response = client.responses.create(
model="gpt-5", # 指定要调用的模型名称
input="介绍一下你自己。" # 用户输入的提示词内容
)
# 4. 提取并打印模型生成的文本
print(response.output_text)相比原生 HTTP 请求,SDK 已经帮我们完成了请求头封装、JSON 序列化、响应解析等工作,开发者只需关注核心业务逻辑,大幅降低开发成本。
4.3 开源模型本地部署:私有化 LLM 能力的最佳方案
本地部署,就是将开源大语言模型(如 DeepSeek-R1、Llama、Qwen 等)部署在自己的硬件环境中,完全掌控模型能力,适合数据敏感、有私有化合规要求的场景。
我们以业界最易用的本地部署工具 Ollama 为例,完成完整的部署和接入实战。
步骤 1:下载安装 Ollama
Ollama 是一款专为本地 LLM 部署设计的开源工具,一键支持 macOS、Linux、Windows 系统,无需复杂的环境配置。
-
官网下载:https://ollama.ai
-
安装完成后,打开终端输入以下命令验证安装:
bash
ollama --version
# 输出示例:ollama version is 0.9.3,即安装成功
步骤 2:模型拉取与配置
Ollama 支持修改模型存储路径,避免默认占用 C 盘空间,有两种配置方式:
- 配置系统环境变量:新增变量名
OLLAMA\_MODELS,变量值为自定义的模型存储路径
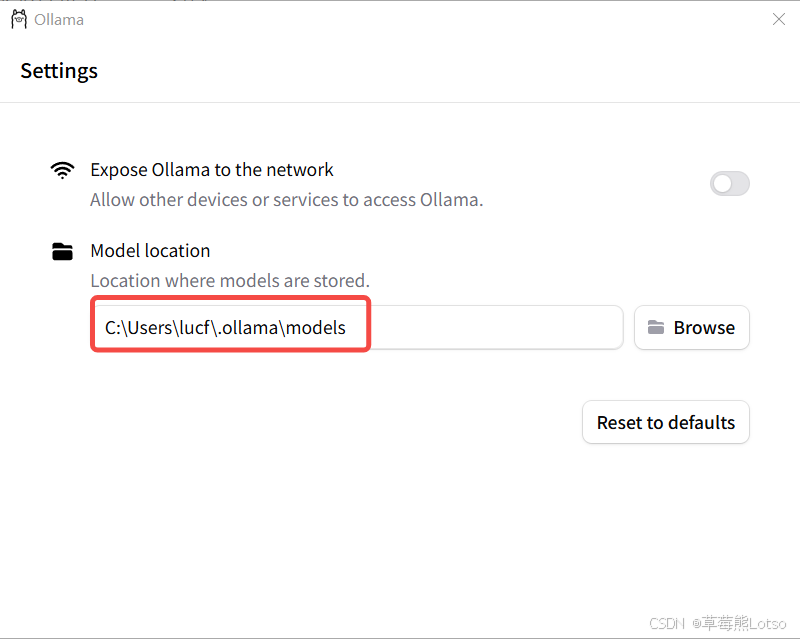
- 图形化设置:打开 Ollama 设置界面,在
Model location中修改存储路径
配置完成后,重启 Ollama 即可生效,使用以下命令拉取模型:
bash
# 拉取DeepSeek-R1 1.5B版本,适合入门级设备
ollama run deepseek-r1:1.5b模型选型说明:模型名称中的
b是Billion(十亿)的缩写,代表参数量级。参数量越大,模型能力越强,硬件要求越高:
1.5B/7B 版本:适合普通 PC,8GB 内存即可流畅运行
14B/32B 版本:需要 16GB + 显存的 GPU
70B/671B 版本:需要专业级服务器 GPU
步骤 3:命令行交互测试
模型拉取完成后,终端会自动进入对话界面,可直接输入内容与模型交互:
bash
>>> 你好
你好!很高兴见到你,有什么我可以帮忙的吗?
>>> 你是谁
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何问题,我会尽我所能为您提供帮助。
步骤 4:本地 API 接口调用
Ollama 启动后,会默认开启本地 API 服务,地址为http://127\.0\.0\.1:11434,可通过 HTTP 请求调用,与云端 API 使用方式完全一致。
实战代码:curl 调用本地模型 API
bash
# Ollama 本地对话API调用
curl "http://127.0.0.1:11434/api/chat" \
-d '{
"model": "deepseek-r1:1.5b", # 本地已拉取的模型名称
"messages": [
{"role": "user", "content": "夸夸我"} # 对话上下文
],
"stream": false # 关闭流式输出,一次性返回结果
}'4.4 原生 LLM 接入的四大核心局限
无论使用哪种原生接入方式,都无法回避 LLM 本身的四大核心局限,这也是绝大多数开发者落地大模型应用时的核心痛点:
-
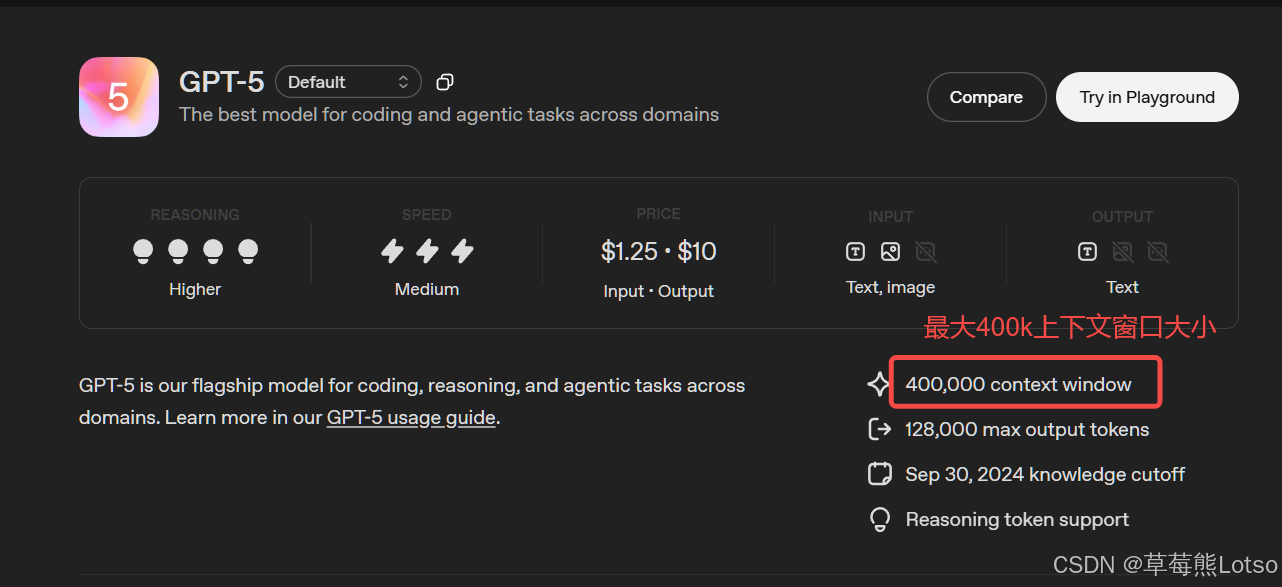
输入长度限制:所有 LLM 都有固定的上下文窗口(如 4K、128K、400K Token),无法直接将整本几百页的 PDF、整个公司知识库传入模型
-
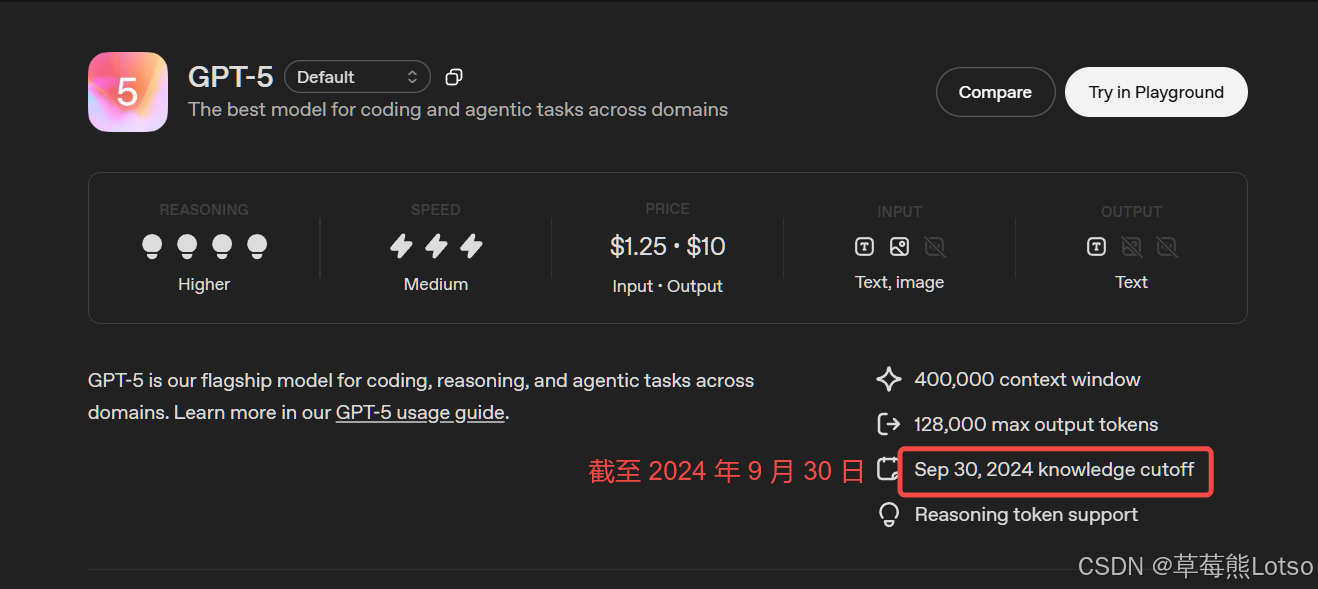
缺乏私有知识:模型的训练数据有固定截止日期,且不包含企业内部文档、个人私有数据,无法精准回答相关问题,极易产生 "幻觉"
-
复杂任务处理能力弱:原生 API 本质是 "一问一答" 的接口,对于需要多步骤的复杂任务(如分析财报→总结要点→生成 PPT 大纲),需要开发者手动编写复杂逻辑拆解任务、管理中间状态
-
输出格式不可控:仅靠提示词无法 100% 保证输出格式合规,极易出现 JSON 格式错误、内容溢出等问题,需要额外编写大量后处理代码校验和清洗
而LangChain 框架,正是为了系统性解决这些问题而诞生的,它就像一座坚固的桥梁,让开发者无需淌水过河,就能轻松将 LLM 能力落地到实际应用中。
五、嵌入模型:大模型应用的语义基石
想要解决 LLM 的私有知识缺失、上下文限制问题,核心是检索增强生成(RAG)技术,而嵌入模型正是 RAG 的语义基石。
5.1 嵌入模型的本质:把人类语言翻译成计算机的数学语言
嵌入模型(Embedding Model)和 LLM 有本质区别:
-
LLM 是生成式模型,核心目标是理解输入并生成新的文本
-
嵌入模型是表示型模型,核心目标是为输入的文本创建富含语义的数值表示(高维向量)
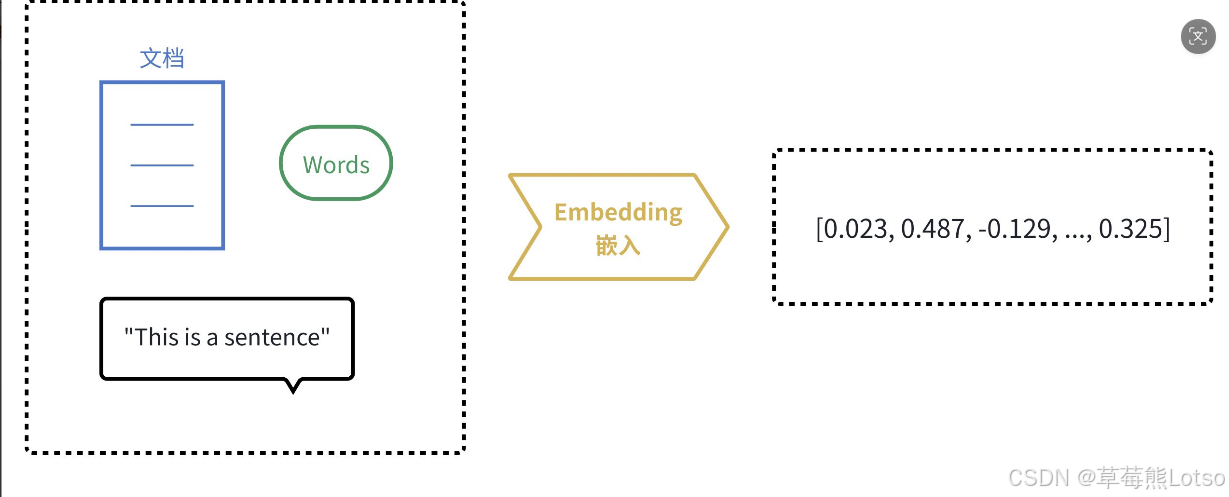
嵌入的核心思想,是将人类语言的符号(单词、句子、段落),转换为计算机能够理解的数值向量,并且这种转换能完整保留原始文本的语义和关系。
通俗来说,嵌入模型就是一个 "翻译官",把人类语言翻译成计算机的 "数学语言"。翻译完成后,我们就能用数学方法度量文本之间的语义相似度,业界最常用的是余弦相似度:
-
在向量空间中,向量的方向代表语义含义,向量的长度代表文本长度
-
余弦相似度只关注向量方向的差异,不受文本长度影响,完美适配语义匹配场景
-
两个向量的余弦相似度越高,代表它们的语义越接近
5.2 嵌入模型的四大核心应用场景
(1)语义搜索
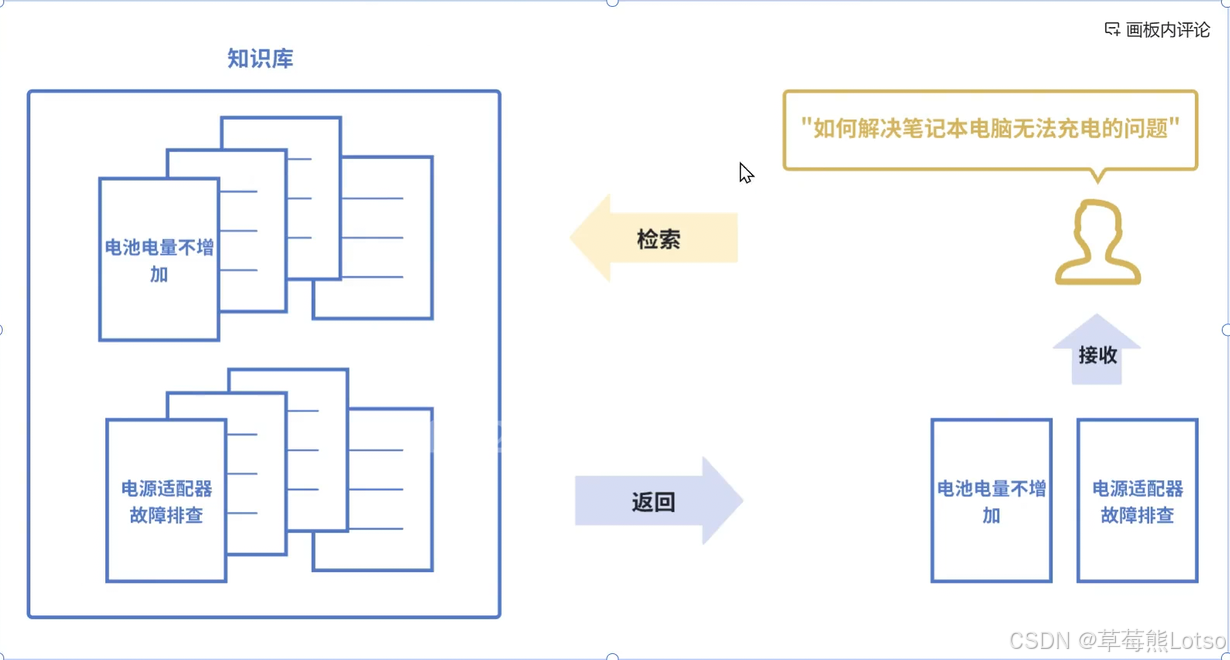
传统搜索依赖关键词精确匹配,搜 "苹果" 只能找到包含 "苹果" 这个词的文档;而语义搜索通过向量相似度匹配,即使文档中没有精确关键词,只要语义相关就能被检索到。
比如用户搜 "电池电量不增加",语义搜索能精准找到 "如何解决笔记本电脑无法充电的问题" 的相关文档,这是传统搜索无法实现的。

(2)检索增强生成(RAG)
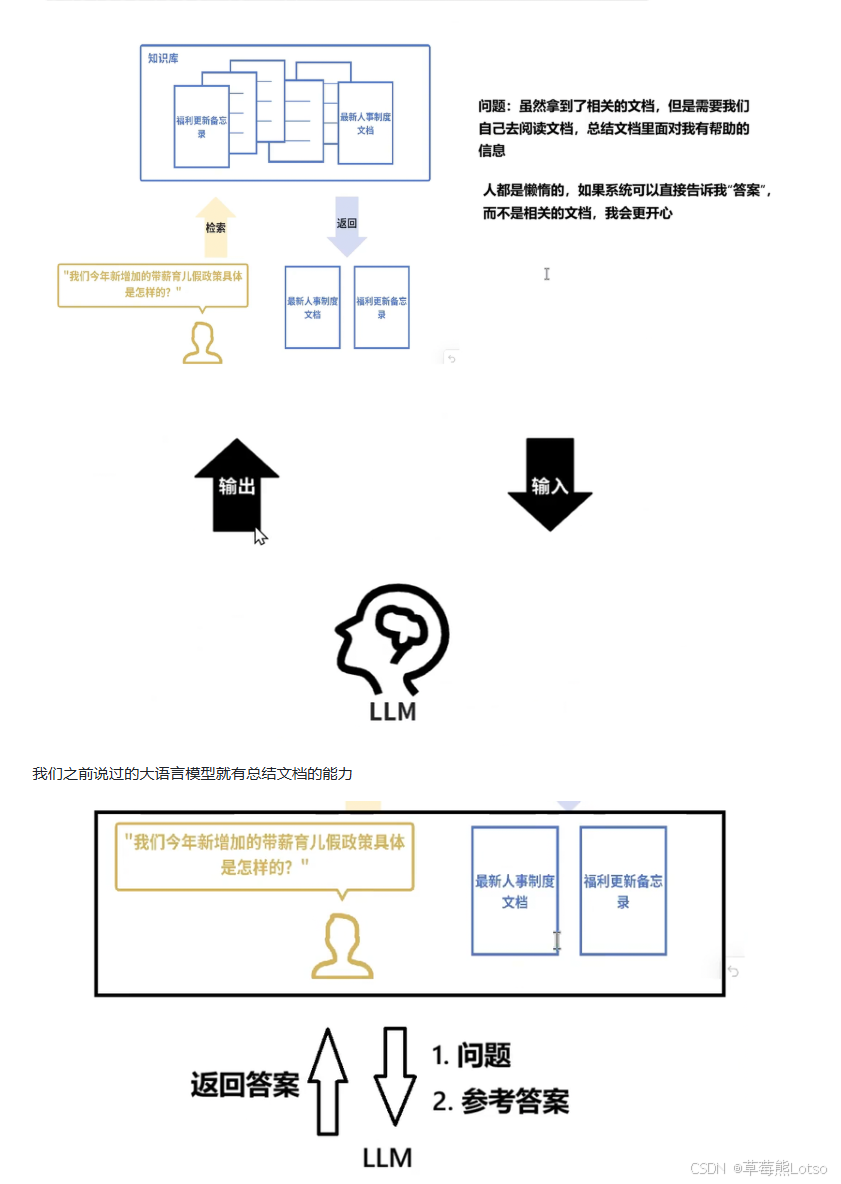
这是当前 LLM 企业级应用的核心模式,也是解决 LLM 私有知识缺失、幻觉问题的最佳方案。
核心流程:当用户向 LLM 提问时,系统首先用嵌入模型在私有知识库中做语义搜索,找到最相关的内容,再把这些内容和用户问题一起交给 LLM,让模型基于精准的私有知识生成答案,而非仅凭训练数据泛泛而谈。
比如企业内部客服机器人,员工问 "今年新增的带薪育儿假政策是怎样的?",系统会先从人事制度文档中检索到相关条款,再交给 LLM 生成精准回答,完全避免过时信息和幻觉。

(3)推荐系统
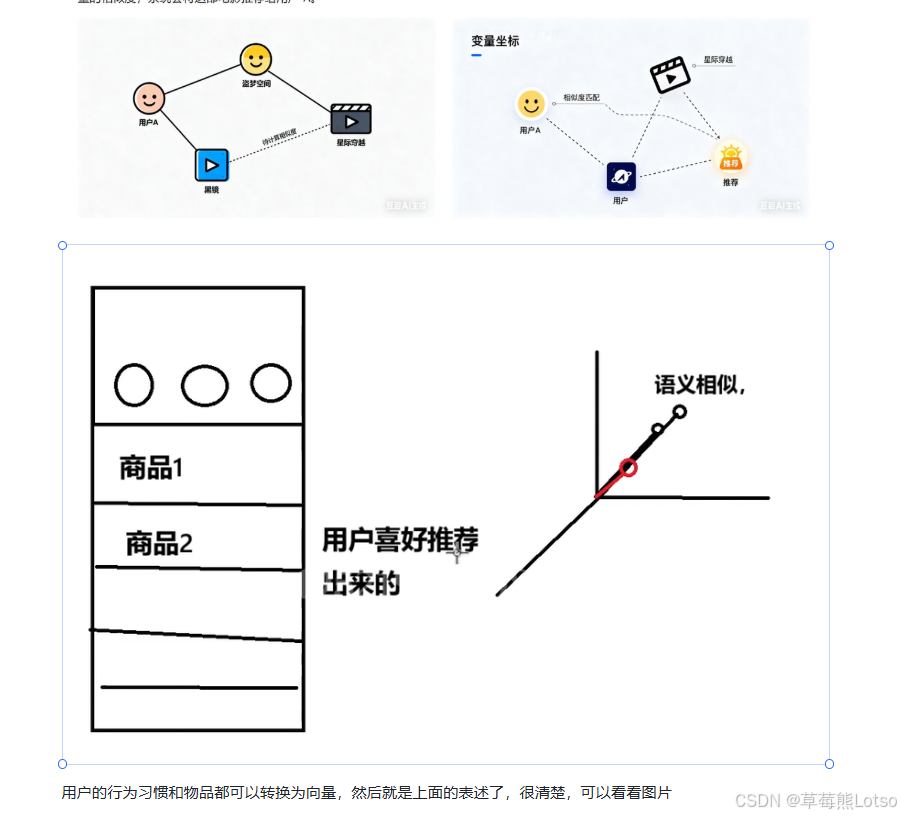
将用户的历史行为、偏好,和商品、内容的特征都转换为向量,喜欢相似物品的用户,向量会高度接近;相似的物品,向量也会聚集。通过计算用户和物品的向量相似度,就能实现精准的个性化推荐。
(4)异常检测
正常业务数据的向量会在空间中形成固定的聚集区,当一个新数据的向量远离这个聚集区时,就大概率是异常点。这个能力被广泛应用于垃圾邮件识别、信用卡交易反欺诈、工业设备故障预警等场景。
5.3 嵌入模型接入实战
主流嵌入模型
| 模型名称 | 厂商 | 核心参数 |
|---|---|---|
| text-embedding-3-large | OpenAI | 默认维度 3072,支持降维,输入令牌长度 8192,多语言能力优异 |
| Qwen3-Embedding-8B | 阿里巴巴 | 开源模型,支持 100 + 语言,上下文长度 32k,最高维度 4096,支持自定义输出维度 |
| gemini-embedding-001 | 支持 100 + 语言,默认维度 3072,支持降维,多语言检索表现突出 |
实战代码:OpenAI 嵌入模型 Python SDK 接入
第一步:安装 SDK(已安装可跳过)
bash
pip install openai第二步:核心代码与逐行解析
python
# 1. 导入OpenAI SDK客户端类
from openai import OpenAI
# 2. 初始化客户端,传入API Key完成身份认证
client = OpenAI(api_key="your-api-key")
# 3. 准备需要向量化的输入文本
text = "这是一段需要转换为向量的文本。"
# 4. 调用嵌入模型API,生成语义向量
response = client.embeddings.create(
model="text-embedding-3-large", # 指定使用的嵌入模型
input=text, # 待向量化的输入文本
dimensions=1024 # 可选:自定义输出向量维度,可从3072维降到1024维
)
# 5. 从响应结果中提取嵌入向量
embedding = response.data[0].embedding
# 6. 打印向量维度和内容
print(f"向量维度:{len(embedding)}")
print(embedding)代码运行后,会输出 1024 维的浮点数向量,这个向量就完整保留了输入文本的语义信息,可直接用于语义检索、聚类、RAG 等场景。
- 像我们之前的LLM还有API接入和本地接入,这个也有
六、LangChain:连接 LLM 与业务应用的核心桥梁
回到最开始的比喻:直接调用原生 LLM 接口,就像淌水过河,会遇到上下文限制、私有知识缺失、复杂任务拆解难等各种问题;而 LangChain,就是为我们搭建的一座坚固、全面的桥梁。
LangChain 是一个开源的大语言模型应用开发框架,它封装了 LLM 接入、嵌入模型、向量数据库、任务拆解、工具调用、Agent 编排等全链路能力,系统性解决了原生 LLM 的所有核心局限。
它的核心价值体现在:
-
统一的接口抽象:适配所有主流 LLM 和嵌入模型,一套代码可无缝切换不同厂商的模型,无需大量重复开发
-
内置 RAG 全链路能力:提供了文档加载、文本分块、嵌入、检索、重排、生成的全流程组件,几行代码就能搭建企业级 RAG 系统
-
智能 Agent 与任务编排:内置 ReAct、CoT 等推理框架,能让 LLM 自主拆解复杂任务,调用外部工具完成多步骤操作,实现真正的智能体应用
-
强格式输出管控:内置多种输出解析器,能 100% 保证 JSON、XML、Pydantic 等格式的输出合规,无需额外后处理
-
丰富的生态集成:对接了数百种第三方工具、数据库、文档加载器,开箱即用,大幅降低 AI 应用的开发门槛
结尾:
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:本文从模型的底层数学本质出发,完整拆解了大语言模型的核心原理、四大能力边界,详解了工业级提示词工程的五大秘籍,结合实战代码完成了 LLM 和嵌入模型的全流程接入,最终点明了 LangChain 作为 LLM 应用开发框架的核心价值。大模型技术的发展,已经从 "能不能用" 进入了 "好不好用" 的阶段。对于开发者而言,LLM 不是一个拿来就能用的黑盒,只有吃透它的底层原理,掌握工程化落地的方法,才能真正把它的能力转化为业务价值,在 AI 时代构建出有竞争力的应用。后续我会持续更新 LangChain 实战系列,从 RAG 系统落地到智能 Agent 开发,带你从零搭建企业级大模型应用。欢迎关注我的 CSDN 博客,一起交流学习,在 AI 时代共同成长。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
