语音识别的目标是实现语音信号与文本的相互转换,而自然语言处理的目标是理解文本的内涵,二者相辅相成。
语言复杂性使计算方法变得越来越困难。然而,随着深度学习的到来,计算方法从基于规则的方法转变为直接从数据学习。为人机交互开辟了新途径。
语音识别是一个传统上由特征工程和模型调参技术主导的领域,它将深度学习融入其特征提取方法中,成效上获得了显著提高。
然后又是从机器学习开始介绍。
机器学习
首先,机器学习分为监督学习,无监督学习,强化学习。深度学习是这三个领域的一部分。
监督学习,它从每个样本都带有标签的数据集里学习,(预测输出)。分为两类:分类和回归。分类问题的输出是类别,回归问题的输出是一个值。
无监督学习,根据没有标签的数据确定类别。可以采用聚类或相似性的形式。
半监督学习,从已标记和未标记的数据中共同学习。
迁移学习,思想是帮助模型适应以前从未遇到过的情况。这种学习形式依赖于将通用模型适配到新的领域。
强化学习,旨在在给定一个动作或一组动作的情况下使奖励最大化。对算法进行训练以奖励某些行为并阻止其他行为。
深度学习简史
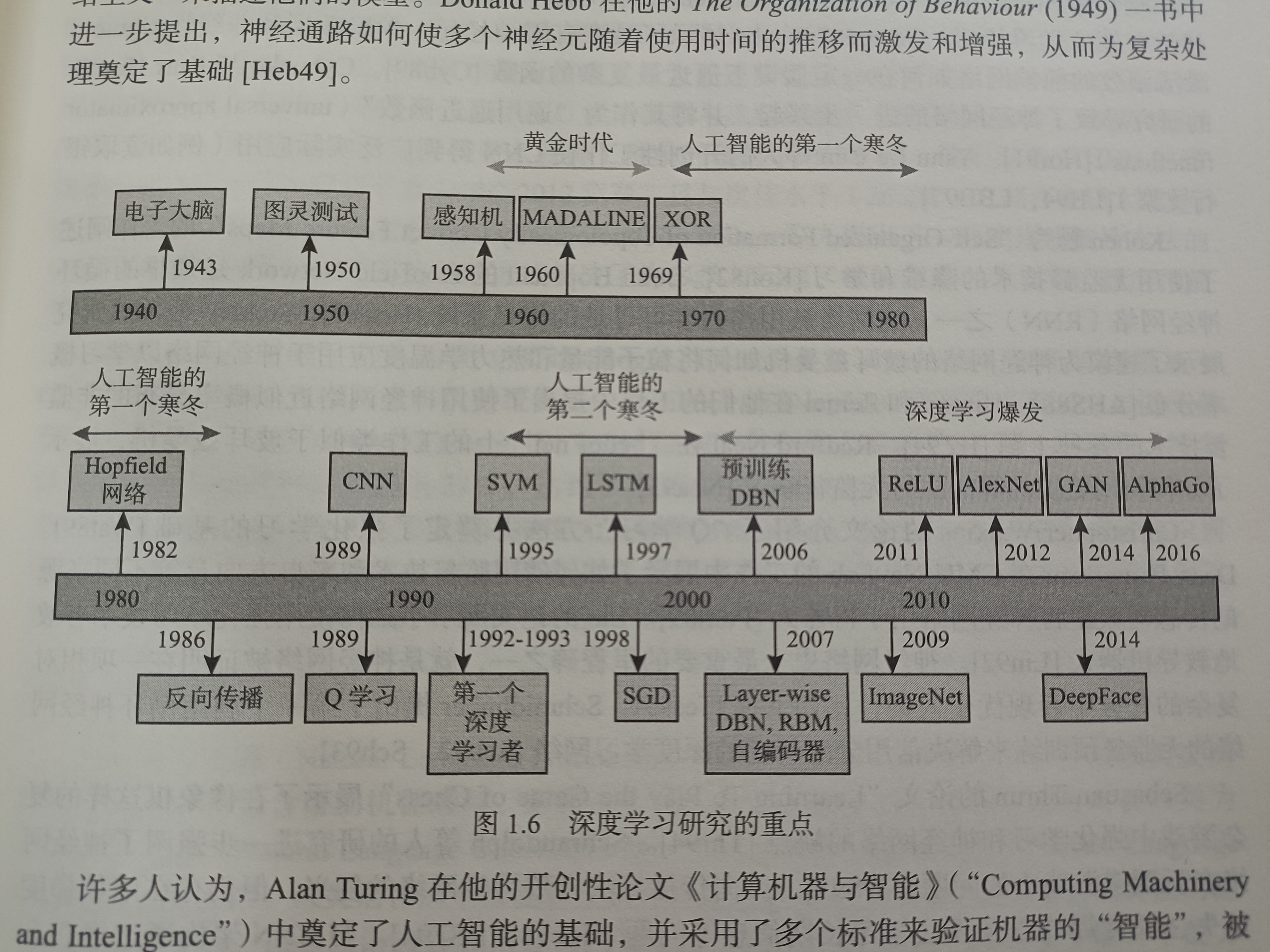
194x年,使用成为阈值逻辑单元的简单电路模拟大脑工作方式。用输入和输出对第一个神经元建模,当加权总和低于阈值时生成0,否则生成1。权重不是学会的而是调整的。创造了联结主义来描述他们的模型。
1950年,图灵测试。验证机器的智能。
1959年,发现了构成基本视觉皮层的简单细胞和复杂细胞,对包括神经网络设计的许多领域产生了广泛影响。Frank Rosenblatt使用Mark I感知机来扩展McCulloch-Pitts神经元,Mark I接收输入,产生输出并具有线性阈值逻辑,通过依次传递输入并减小所生成的输出与期望输出之间的差异来学习感知机中的权重。后来,Bernard Widrow和Marcian Hoff进一步采用了感知机的概念,开发了多元自适应线性神经元(MADALINE),用于消除电话线中的噪声。
Marvin Minsky和Seymour Papert出版Perceptrons一书展示了感知机在学习简单异或函数方面的局限性。由于生成输出需要进行大量迭代以及计算时间所带来的限制,它们最终证明了多层网络无法实现感知机。多年的资金枯竭限制了神经网络的研究,因此被称为"人工智能的第一个寒冬"。
1986年,David Rumelhart,Geoff Hinton和Ronald Williams发表了开创性的著作"Learning representations by back-propagating errors",该著作展示了多层神经网络不仅可以用相对简单的方法有效的训练,而且还可以利用"隐藏"层来克服感知机在学习复杂模式时的弱点。
由于LeCun等人的研究,神经网络能够识别数字签名所使用的手写数字 ,并首次广泛应用于美国邮政服务。这表明了在现代卷积神经网络CNN中卷积运算和权重共享如何有效地学习特征。
Hopfield Nnetwork是最早的循环神经网络RNN之一 ,该网络被用作内容可寻址的记忆系统。
Christopher Watkins的论文介绍了**"Q学习"方法并奠定了强化学习的基础** 。Dean Pomerkeau在CMU NavLab的工作中展示了如何使用监督技术和来自方向盘等不同来源的传感器数据将神经网络用于机器人。Lin的论文展示了如何使用强化学习技术有效的教导机器人。神经网络史上最重要的里程碑之一,就是神经网络被证明在一项相对复杂的任务中表选优于人类(比如下棋)。Schmidhuber提出了第一个利用循环神经网络的无监督预训练来解决信用分配问题的深度学习网络。
后来人们发现了下棋等游戏中强化学习和神经网络的缺点和问题。反向传播算法 导致神经网络的复兴,但仍存在诸如梯度消失、梯度爆炸以及无法学习长期信息等问题 。与CNN架构通过卷积和权重共享改善神经网络的方法类似,Hochreiter和Schmidhuber提出的长短期记忆神经网络LSTM克服了反向传播中具有长期记忆依赖性的问题 。与此同时,统计学习理论------尤其是**支持向量机(SVM)**迅速成为解决各类问题的一种非常流行的算法。这些变换促成了"人工智能的第二个寒冬"。
2006年,"A Fast Learing Algorithm for Deep Belief Nets"引发了深度学习的复兴。该论文首次提出"深度学习"这个词,还使用无监督方法对网络逐层进行训练,然后进行有监督的"微调",该方法在MNIST手写数字识别数据集上取得了最优结果。在此之后,Bengio等人又发表了另一项开创性著作,揭示了为什么与浅层神经网络或支持向量机相比,多层的深度学习网络可以分层次地学习特征。该论文对为何使用无监督方法为DBN、RBM和自编码器进行预训练提出深刻见解,这样做不仅可初始化权重以实现最优解,还为用于学习的数据提供了良好表示。Bengio和LeCun的论文"Scaling Algorithms Towards AI"重申了CNN、RBM、DBN等深度学习框架以及无监督预训练/微调等技术的好处,激发了下一轮深度学习的热潮。使用非线性激活函数,如ReLU,能克服反向传播算法的许多问题。

自然语言处理简史
自然语言处理NLP是计算机科学中涉及交流的领域。她包含帮助机器理解、解释、生成人类语言的方法。这些方法被归类为自然语言理解和自然语言生成。传统NLP采用基于语言学的方法,基于语言的基本语义和句法元素建立。现代的深度学习方法可以避开对这些中间元素的需求,学习其自身用于广义任务的层次表示。https://chat.deepseek.com/share/cb57hr5u9a42p7v23o
1954年,IBM-Georgetown实验通过机器把大约60个句子从俄语翻译到英语。
1956年,在达特茅斯会议上创造了"人工智能"一词。
1957年,《句法结构出版》,强调句子语法在语言理解中的重要性。https://chat.deepseek.com/share/18m0stxrj1lldqioij
LISP(John McCarthy在1958年完成)和ELIZA(最早的聊天机器人)等软件对图灵测试的尝试,对整个AI领域产生巨大影响。
1964年,ALPAC报告,几乎使NLP研究停滞。https://chat.deepseek.com/share/4d11pmznr8p3jycodk
20世纪60年代~70年代,强调语义而不是句法结构。从属理论。SHRDLU是一个简单系统,可以使用语法、语义和推理来理解基本问题并以自然语言回答。20世纪80年代初,语法学阶段开始。
20世纪90年代是统计语言处理的时代,
21世纪初,Bengio等人在21世纪初提出了第一个神经语言模型,该模型使用n个前面单词的映射,使用查找表将其作为隐藏层输入到前馈网络,并通过softmax层平滑输出结果以预测单词。Bengio的研究是NLP历史上首次使用"稠密向量表示"而不是"独热向量"或词袋模型,https://chat.deepseek.com/share/m2rbgel8r1xtwesusm。后来提出的许多基于循环神经网络和长短期记忆的语言模型已经成为最先进技术。Papineni等人提出的双语评估替换度量标准直到今天仍被用作机器翻译的标准度量。Pang等人引入了感情分类。......

以后再看吧......