自建API服务 天气查询 Agent 进阶教程
🎯 你将构建的程序
基于本地大模型的 AI Agent,输入城市名即可查询实时天气。与简化版不同,本教程从零搭建模型服务:
你:上海今天天气怎么样?
AI:上海今天天气晴朗,温度 23.4°C,湿度 52%,风速 8.8 km/h与简化版教程的区别
| 简化版(ollama-quickstart) | 本版本(langgraph-agent) | |
|---|---|---|
| 文件数 | 1 个 (weather.py) |
3 个 |
| 模型 | Ollama 自动管理 | 手动下载 + 自建服务 |
| 学习重点 | LangGraph 基础 | 完整链路(下载→自建API服务→Agent) |
| 推荐顺序 | 先学简化版 ✅ | 再学本版本 |
设计原则:零跳跃学习
传统路线的问题:知识点A → 知识点C(发现需要B,回头补B)→ 知识点D(发现需要前置知识X)
本路线的目标:知识点A → 知识点B(A的自然延伸)→ 知识点C(B的必然发展)→ 知识点D(C的合理进阶)
目录
- 第一章:项目总览
- 第二章:环境准备
- 第三章:模型下载(download_model.py)
- [3.1 什么是变量和常量](#3.1 什么是变量和常量)
- [3.2 什么是 Path 路径](#3.2 什么是 Path 路径)
- [3.3 什么是函数](#3.3 什么是函数)
- [3.4 什么是 import](#3.4 什么是 import)
- [3.5 什么是 if/else](#3.5 什么是 if/else)
- [3.6 什么是 try/except](#3.6 什么是 try/except)
- [3.7 完整代码](#3.7 完整代码)
- [3.8 运行效果](#3.8 运行效果)
- 第四章:模型服务(model_server.py)
- [4.1 什么是 HTTP 和 API](#4.1 什么是 HTTP 和 API)
- [4.2 什么是 FastAPI](#4.2 什么是 FastAPI)
- [4.3 什么是 Pydantic 数据模型](#4.3 什么是 Pydantic 数据模型)
- [4.4 什么是 SSE 流式输出](#4.4 什么是 SSE 流式输出)
- [4.5 什么是 GPU 和 CUDA](#4.5 什么是 GPU 和 CUDA)
- [4.6 完整代码](#4.6 完整代码)
- [4.7 运行效果](#4.7 运行效果)
- [第五章:Agent 构建(weather_agent.py)](#第五章:Agent 构建(weather_agent.py))
- [5.1 什么是消息(Message)](#5.1 什么是消息(Message))
- [5.2 什么是工具(Tool)](#5.2 什么是工具(Tool))
- [5.3 什么是状态(State)](#5.3 什么是状态(State))
- [5.4 什么是图(Graph)](#5.4 什么是图(Graph))
- [5.5 什么是 Agent 循环](#5.5 什么是 Agent 循环)
- [5.6 完整代码](#5.6 完整代码)
- [5.7 运行效果](#5.7 运行效果)
- 第六章:运行与调试
- 附录:技术名词速查表
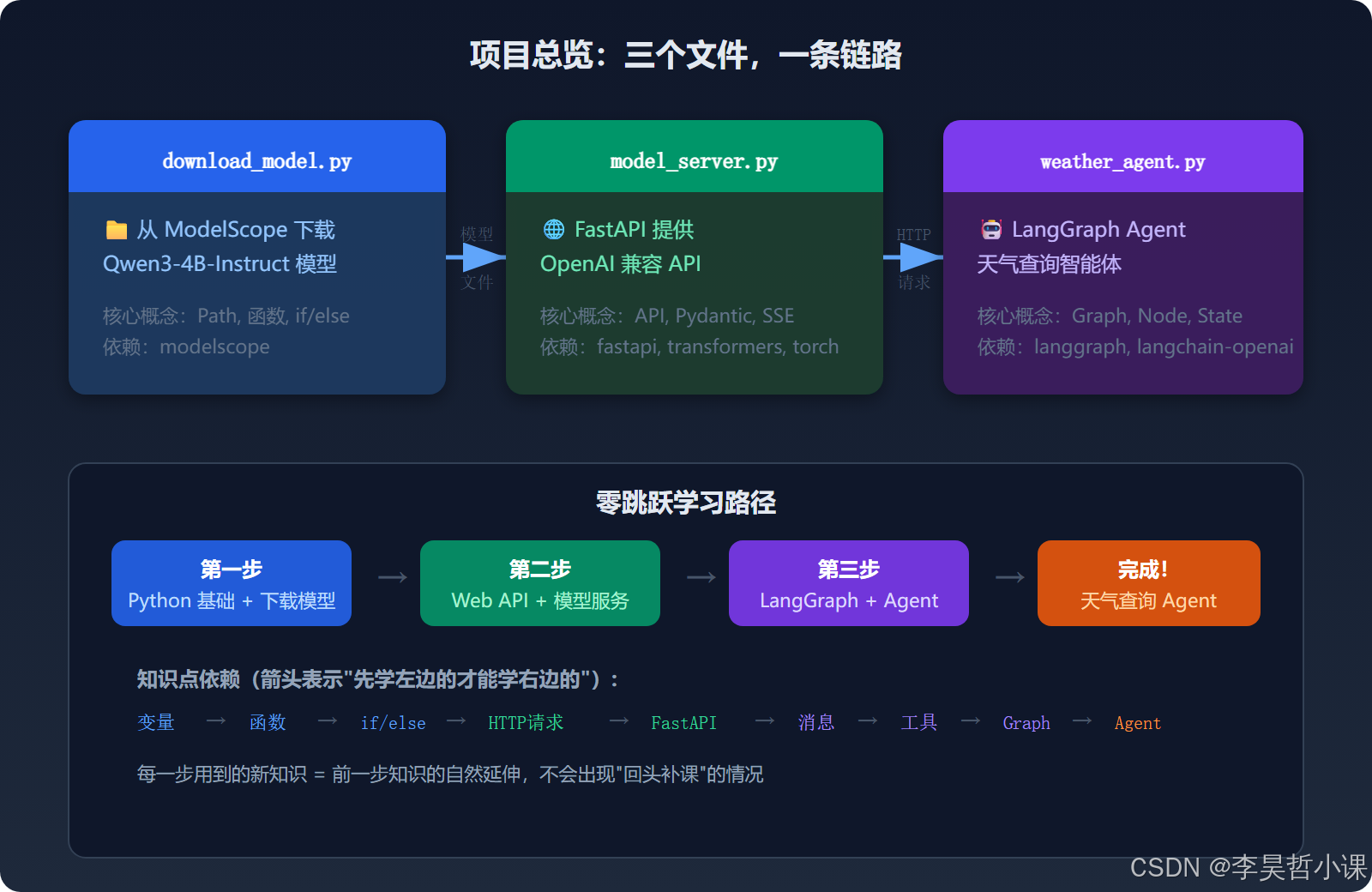
第一章:项目总览
你要构建什么?
一个完整的 AI Agent 系统,由三个 Python 文件组成:
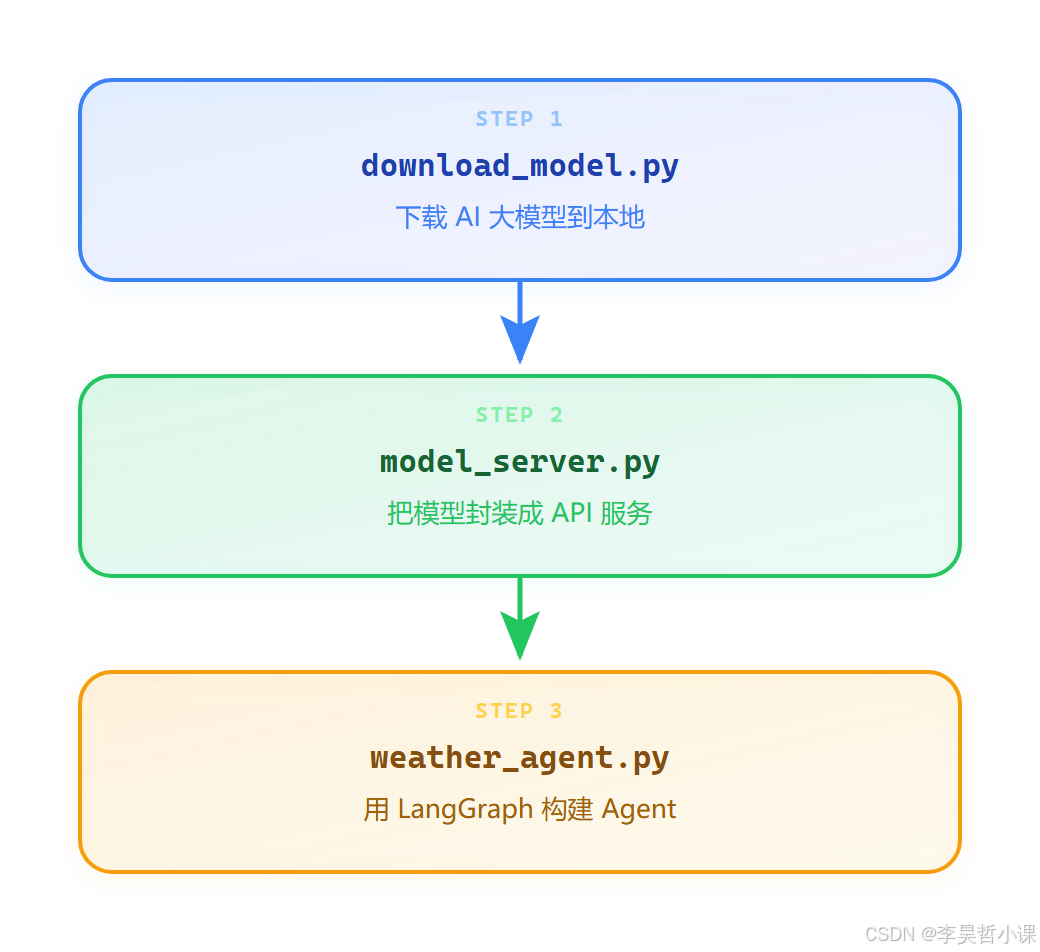
三个文件各自做什么?
| 文件 | 一句话解释 | 类比 |
|---|---|---|
download_model.py |
从网上下载 AI 大脑 | 从应用商店下载 App |
model_server.py |
让 AI 大脑可以通过网络调用 | 给 App 开一个网页版入口 |
weather_agent.py |
让 AI 大脑能查天气并回答问题 | 让 App 能调用地图 API |
它们之间的调用关系
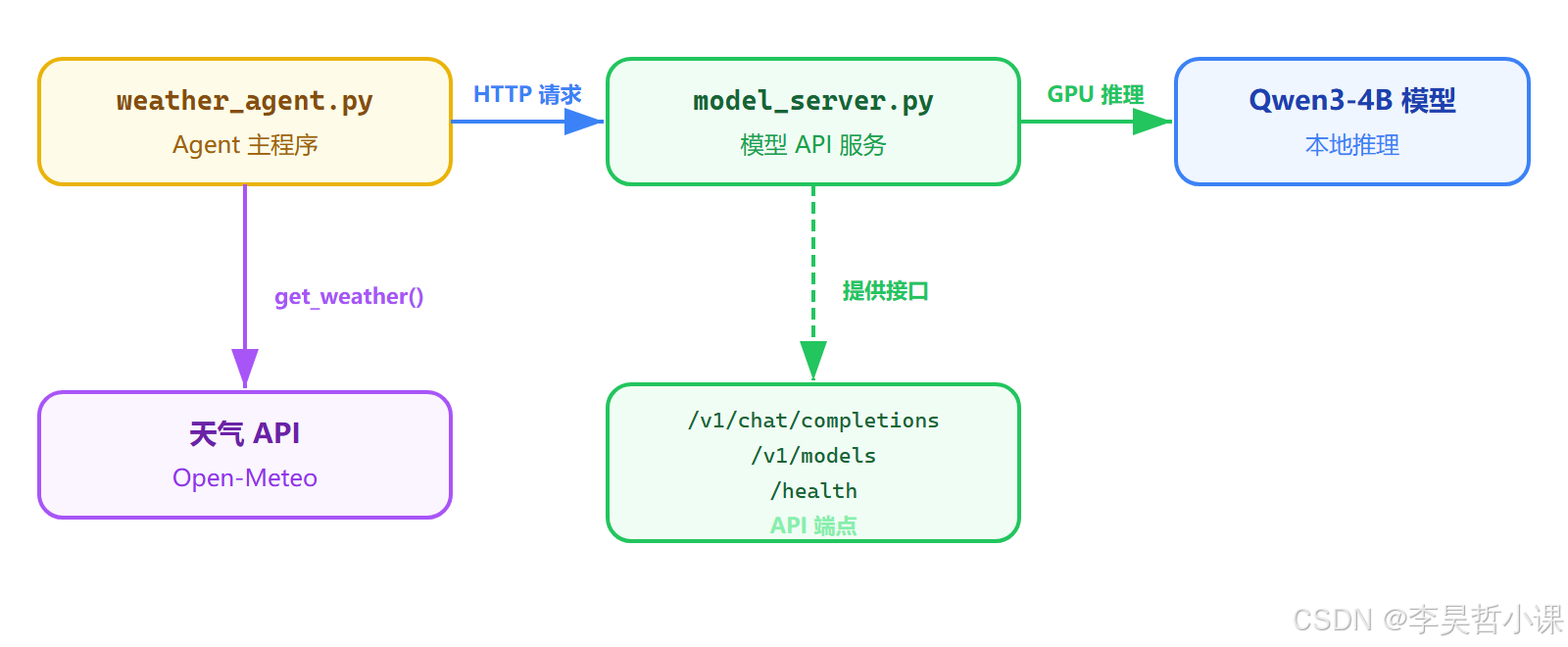
执行流程(运行时发生了什么)
当用户问"上海天气"时,程序内部的完整过程:
weather_agent.py收到用户输入"上海天气"- 调用 LLM(通过 HTTP 请求发往
model_server.py) model_server.py将请求发给 Qwen3-4B 模型进行 GPU 推理- LLM 决定需要查天气,返回
tool_calls: [get_weather(city="上海")] weather_agent.py执行get_weather("上海"),调用 Open-Meteo API- Open-Meteo 返回天气数据:晴朗,23.4°C,湿度52%
- 天气数据作为
ToolMessage发回给 LLM - LLM 根据天气数据生成自然语言回复:"上海今天天气晴朗,温度 23.4°C..."
第二章:环境准备
⚠️ 动手之前,先确保以下环境就绪。
2.1 硬件要求
| 项目 | 最低要求 | 推荐配置 |
|---|---|---|
| 显卡 | NVIDIA 6GB 显存 | NVIDIA 8GB+ 显存 |
| 内存 | 16GB | 32GB |
| 磁盘 | 15GB 可用空间 | 30GB+ |
| 操作系统 | Windows 10/11 | Windows 10/11 或 Linux |
💡 为什么需要显卡?
大模型有 40 亿个参数,每次推理需要做大量矩阵运算。CPU 做这个运算可能需要几十秒甚至几分钟,GPU 只需要几秒钟。
如果没有 NVIDIA 显卡,也能用 CPU 运行,但速度会慢很多。
2.2 软件安装
第一步:安装 Python 3.10+
bash
# 下载地址:https://www.python.org/downloads/
# 安装时勾选 "Add Python to PATH"
python --version # 应输出 Python 3.10 或更高版本第二步:安装 CUDA(GPU 驱动)
bash
# 如果有 NVIDIA 显卡,安装 CUDA Toolkit
# 下载地址:https://developer.nvidia.com/cuda-downloads
nvidia-smi # 应显示 GPU 信息第三步:安装 Python 依赖
gpu 版本
bash
pip install torch==2.11.0 torchvision==0.26.0 torchaudio==2.11.0 --index-url https://download.pytorch.org/whl/cu130
# 模型下载依赖
pip install modelscope transformers accelerate
# 模型服务依赖
pip install fastapi uvicorn[standard] pydantic
# Agent 依赖
pip install langchain langchain-openai langgraph requestscpu版本
bash
# 模型下载依赖
pip install modelscope transformers torch torchvision torchaudio accelerate
# 模型服务依赖
pip install fastapi uvicorn[standard] pydantic
# Agent 依赖
pip install langchain langchain-openai langgraph requests| 包名 | 作用 | 哪个文件用到 |
|---|---|---|
modelscope |
从 ModelScope 下载模型 | download_model.py |
transformers |
加载和运行大模型 | model_server.py |
torch |
PyTorch 深度学习框架 | model_server.py |
fastapi |
构建 Web API 服务 | model_server.py |
uvicorn |
运行 FastAPI 的服务器 | model_server.py |
pydantic |
数据格式校验 | model_server.py |
langchain |
LLM 应用框架 | weather_agent.py |
langchain-openai |
OpenAI 兼容客户端 | weather_agent.py |
langgraph |
状态图编排框架 | weather_agent.py |
requests |
HTTP 请求(调用天气 API) | weather_agent.py |
第四步:验证环境
bash
python -c "import torch; print('GPU:', torch.cuda.is_available())"
python -c "import fastapi; print('FastAPI OK')"
python -c "import langgraph; print('LangGraph OK')"全部通过后,进入下一步。
第三章:模型下载(download_model.py)
📍 当前进度 :① 环境准备 ✅ → ② 下载模型 ← 📍 → ③ 启动服务 → ④ 运行 Agent
本文件共约 60 行有效代码。你将学会:变量、Path 路径、函数、import、if/else、try/except
3.1 什么是变量和常量
在开始写代码之前,先理解两个最基本的概念。
什么是变量?
变量就像一个贴了标签的盒子,盒子里可以放数据:
python
# 把 "上海" 放进贴着 city 标签的盒子
city = "上海"
# 把 23.4 放进贴着 temperature 标签的盒子
temperature = 23.4
# 可以用标签名取出数据
print(city) # 输出:上海
print(temperature) # 输出:23.4什么是常量?
常量就是"约定不改的变量"。Python 本身不支持真正的常量,但约定全大写命名的变量不会被修改:
python
# 常量:全大写命名,约定不修改
MODEL_ID = "Qwen/Qwen3-4B-Instruct-2507" # 模型的唯一标识
LOCAL_DIR = "./models/Qwen3-4B-Instruct" # 本地保存路径💡 为什么要分变量和常量?
变量在程序运行过程中会变化(如温度、用户输入),常量则是配置项(如模型名称、端口号)。
把配置项抽成常量的好处:只需要改一个地方,整个程序都生效。
在 download_model.py 中,有两个常量:
python
# 模型在 ModelScope 平台上的唯一标识
# 格式:组织名/模型名,就像 GitHub 仓库地址
MODEL_ID = "Qwen/Qwen3-4B-Instruct-2507"
# 模型保存到本地的路径
# Path(__file__) 获取当前文件的路径
# .parent 获取上一级目录
# / "models" / "Qwen3-4B-Instruct-2507" 拼接子目录
LOCAL_DIR = Path(__file__).parent / "models" / "Qwen3-4B-Instruct-2507"3.2 什么是 Path 路径
Path 是 Python 提供的路径操作工具,比手动拼接字符串更安全:
python
from pathlib import Path
# ❌ 手动拼接(容易出错,Windows 用 \,Linux 用 /)
path = "F:\\lang\\models\\Qwen3-4B"
# ✅ 使用 Path(自动处理不同系统的分隔符)
path = Path("F:/lang") / "models" / "Qwen3-4B"
# 常用操作
path.exists() # 路径是否存在?→ True 或 False
path.mkdir() # 创建目录
path.is_file() # 是文件吗?
path.is_dir() # 是目录吗?在 download_model.py 中,Path 用来构建模型保存路径:
python
from pathlib import Path
# 自动计算:当前文件所在目录/models/模型名
LOCAL_DIR = Path(__file__).parent / "models" / "Qwen3-4B-Instruct-2507"
# 例如:F:\lang\models\Qwen3-4B-Instruct-25073.3 什么是函数
函数是一段可以重复使用的代码块。就像数学函数 f(x) = x + 1:
python
# 定义函数
def say_hello(name):
print(f"你好,{name}!")
# 调用函数
say_hello("小明") # 输出:你好,小明!
say_hello("小红") # 输出:你好,小红!download_model.py 中有两个函数:
python
def download_model():
"""下载模型到本地"""
# ... 下载逻辑 ...
def verify_model(model_path):
"""验证模型文件是否完整"""
# ... 验证逻辑 ...💡 函数的参数和返回值
- 参数 (括号里的):输入,如
def f(x)中的x- 返回值 (
return):输出,调用方可以拿到这个值
python
def add(a, b): # a, b 是参数(输入)
result = a + b
return result # return 是返回值(输出)
answer = add(1, 2) # answer = 33.4 什么是 import
import 就是"引入工具"。Python 有很多内置工具和第三方库,用 import 引入后才能使用:
python
# 引入 Python 内置工具
import os # 操作系统接口(检查文件是否存在等)
from pathlib import Path # 路径操作
# 引入第三方库(需要 pip install 安装)
from modelscope import snapshot_download # ModelScope 下载 API💡 为什么有时用
import os,有时用from pathlib import Path?
import os:引入整个os模块,使用时写os.path.exists()from pathlib import Path:只引入Path这一个东西,使用时直接写Path()
download_model.py 用的是延迟导入 ------把 from modelscope import snapshot_download 放在函数内部:
python
def download_model():
# ...
try:
from modelscope import snapshot_download # 在这里才引入
model_dir = snapshot_download(MODEL_ID, ...)
except ImportError:
print("请运行: pip install modelscope")💡 为什么要延迟导入?
如果
modelscope没装,放在文件顶部会让整个脚本都无法加载。放在函数内部:脚本可以正常加载,只在真正调用时才报错,并给出安装提示。
3.5 什么是 if/else
if/else 是程序做判断的方式:
python
age = 18
if age >= 18:
print("你是成年人") # 条件为 True 时执行
else:
print("你是未成年人") # 条件为 False 时执行在 download_model.py 中,if/else 用来判断模型是否已经下载:
python
# 检查模型目录是否存在且非空
if LOCAL_DIR.exists() and any(LOCAL_DIR.iterdir()):
print("✅ 模型已存在,跳过下载")
return str(LOCAL_DIR) # 已下载 → 直接返回路径
else:
# 未下载 → 开始下载
LOCAL_DIR.mkdir(parents=True, exist_ok=True)
# ... 下载逻辑 ...💡
and是什么意思?两个条件同时满足 才为 True。
LOCAL_DIR.exists()--- 目录存在?
any(LOCAL_DIR.iterdir())--- 目录里有文件?两个都是 → 模型已下载。任一不是 → 模型没下载。
3.6 什么是 try/except
try/except 是处理错误的方式。就像"先试试看,出错了再补救":
python
try:
result = 1 / 0 # 这行会出错(除以零)
except ZeroDivisionError:
print("除以零了!") # 出错时执行这里在 download_model.py 中,try/except 处理两种错误:
python
try:
from modelscope import snapshot_download
model_dir = snapshot_download(...) # 可能网络错误
return model_dir
except ImportError:
print("❌ 未安装 modelscope")
print(" 请运行: pip install modelscope")
return None # 失败返回 None
except Exception as e:
print(f"❌ 下载失败: {str(e)}")
return None3.7 完整代码
将以下代码保存为 download_model.py:
python
"""
模型下载脚本 --- 从 ModelScope 下载 Qwen3-4B-Instruct 模型
"""
import os
from pathlib import Path
# ==================== 配置 ====================
MODEL_ID = "Qwen/Qwen3-4B-Instruct-2507"
LOCAL_DIR = Path(__file__).parent / "models" / "Qwen3-4B-Instruct-2507"
def download_model():
"""从 ModelScope 下载模型到本地。已下载则跳过。"""
print("=" * 60)
print("ModelScope 模型下载工具")
print("=" * 60)
print(f"模型 ID: {MODEL_ID}")
print(f"本地目录: {LOCAL_DIR}")
print("-" * 60)
# 检查是否已下载
if LOCAL_DIR.exists() and any(LOCAL_DIR.iterdir()):
print("✅ 模型已存在,跳过下载")
return str(LOCAL_DIR)
# 创建目录
LOCAL_DIR.mkdir(parents=True, exist_ok=True)
print("🚀 开始下载模型...")
print(" 这可能需要几分钟,请耐心等待...")
try:
from modelscope import snapshot_download
model_dir = snapshot_download(
MODEL_ID,
local_dir=str(LOCAL_DIR),
revision="master"
)
print("-" * 60)
print("✅ 模型下载完成!")
print(f" 模型路径: {model_dir}")
return model_dir
except ImportError:
print("❌ 错误: 未安装 modelscope 库")
print(" 请运行: pip install modelscope")
return None
except Exception as e:
print(f"❌ 下载失败: {str(e)}")
return None
def verify_model(model_path):
"""验证模型文件是否完整。"""
if not model_path or not os.path.exists(model_path):
return False
required_files = ["config.json", "tokenizer.json"]
for file_name in required_files:
if not (Path(model_path) / file_name).exists():
print(f"⚠️ 缺少文件: {file_name}")
return False
print("✅ 模型验证通过")
return True
if __name__ == "__main__":
model_path = download_model()
if model_path:
verify_model(model_path)
print("-" * 60)
print("📝 后续步骤:")
print(" 1. 启动模型服务: uvicorn model_server:app --host 0.0.0.0 --port 8000")
print(" 2. 运行天气 Agent: python weather_agent.py")3.8 运行效果
bash
python download_model.py首次运行:
============================================================
ModelScope 模型下载工具
============================================================
模型 ID: Qwen/Qwen3-4B-Instruct-2507
本地目录: F:\lang\models\Qwen3-4B-Instruct-2507
------------------------------------------------------------
🚀 开始下载模型...
这可能需要几分钟,请耐心等待...
------------------------------------------------------------
✅ 模型下载完成!
模型路径: F:\lang\models\Qwen3-4B-Instruct-2507
✅ 模型验证通过
------------------------------------------------------------
📝 后续步骤:
1. 启动模型服务: uvicorn model_server:app --host 0.0.0.0 --port 8000
2. 运行天气 Agent: python weather_agent.py再次运行(幂等性):
✅ 模型已存在,跳过下载
模型路径: F:\lang\models\Qwen3-4B-Instruct-2507
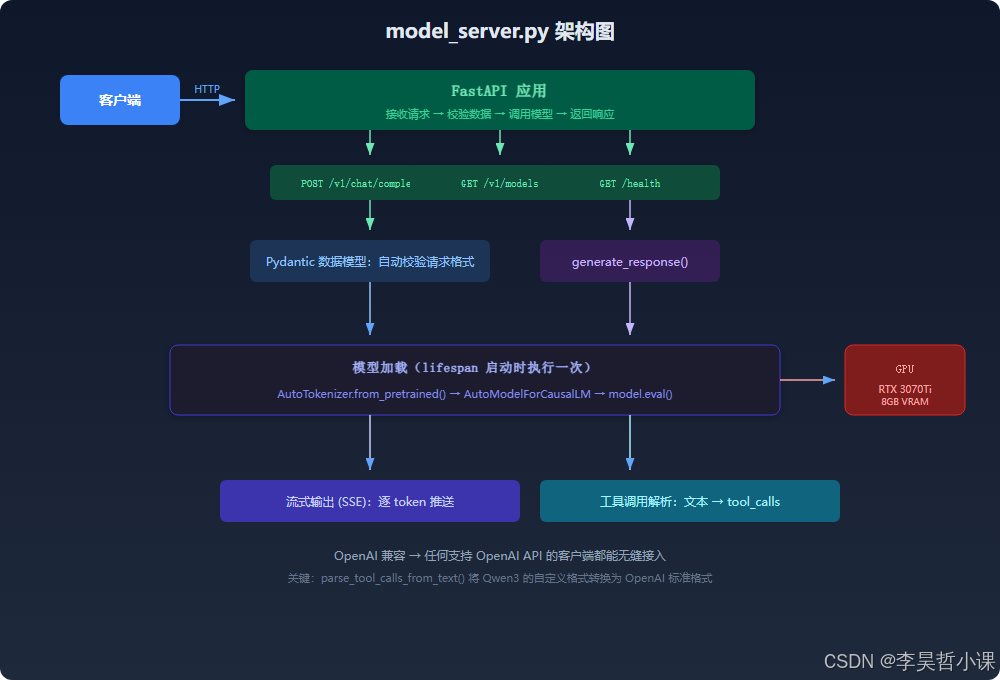
第四章:模型服务(model_server.py)
📍 当前进度 :① 环境准备 ✅ → ② 下载模型 ✅ → ③ 启动服务 ← 📍 → ④ 运行 Agent
本文件是项目中最复杂的一个(约 300 行有效代码)。你将学会:HTTP、API、FastAPI、Pydantic、SSE、GPU
💡 先理解一个比喻
download_model.py把 AI 大脑下载到了电脑上。但大脑在硬盘里,不能直接用。
model_server.py给大脑装了一个"电话"------其他程序可以通过 HTTP 请求"打电话"给大脑,大脑思考后"回电话"给出回答。这个"电话"就是 API。
4.1 什么是 HTTP 和 API
HTTP(超文本传输协议)是互联网通信的规则。你每次打开网页,浏览器都在用 HTTP 跟服务器对话。
一次 HTTP 请求包含四个部分:
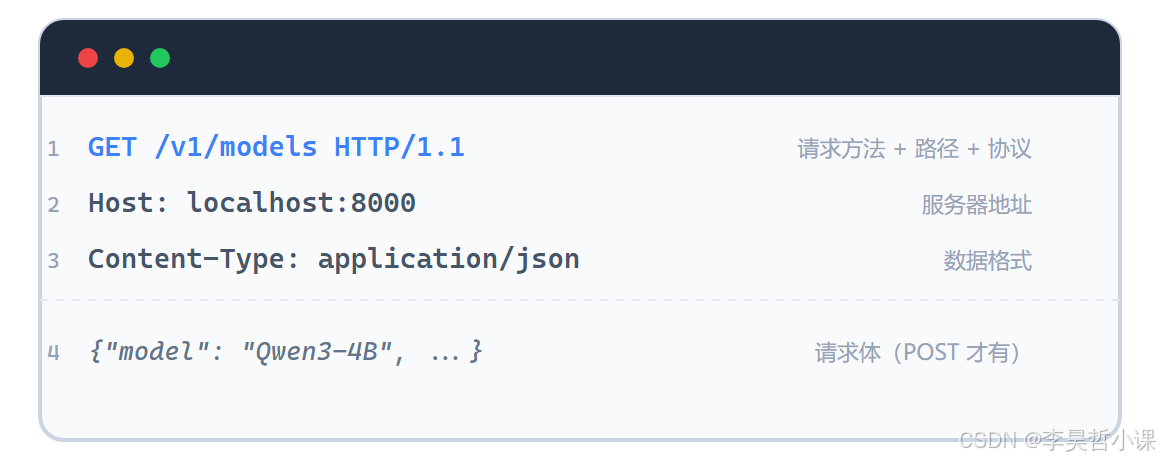
API(应用程序接口)就是一组约定好的"电话号码"和"通话格式":
电话号码:http://localhost:8000/v1/chat/completions
通话格式:发送 JSON → 收到 JSON
请求:
{"model": "Qwen3-4B", "messages": [{"role": "user", "content": "你好"}]}
响应:
{"choices": [{"message": {"content": "你好!有什么可以帮助你的?"}}]}💡 为什么叫 "OpenAI 兼容"?
OpenAI 是最知名的大模型公司,它定义了一套 API 格式。很多开源项目(包括本项目)都采用同样的格式。
好处:任何支持 OpenAI API 的客户端(LangChain、Cursor、ChatBox 等)都能直接用,不需要改代码。
4.2 什么是 FastAPI
FastAPI 是一个 Python Web 框架,用来快速搭建 API 服务:
python
from fastapi import FastAPI
app = FastAPI()
@app.get("/hello")
def hello():
return {"message": "你好!"} # 自动转为 JSON 响应
@app.get("/user/{name}")
def get_user(name):
return {"name": name} # URL 中的 {name} 自动传入启动服务后:
bash
uvicorn 文件名:app --host 0.0.0.0 --port 8000浏览器访问 http://localhost:8000/hello → 看到响应。
model_server.py 定义了三个 API 端点:
| 端点 | 方法 | 作用 |
|---|---|---|
/v1/chat/completions |
POST | 核心接口:对话补全(兼容 OpenAI) |
/v1/models |
GET | 查询可用模型列表 |
/health |
GET | 健康检查(服务是否正常) |
4.3 什么是 Pydantic 数据模型
Pydantic 用来自动校验请求数据。如果客户端发送的数据格式不对,自动返回错误:
python
from pydantic import BaseModel, Field
# 定义数据模型
class ChatMessage(BaseModel):
role: str = Field(..., description="消息角色") # 必填
content: str = Field(None, description="消息内容") # 可选
# FastAPI 自动校验
@app.post("/chat")
def chat(msg: ChatMessage):
return {"reply": f"你说了:{msg.content}"}如果客户端发送 {"role": "user"}(缺少 content),Pydantic 会自动返回 422 错误并说明哪里有问题。
model_server.py 定义了 7 个 Pydantic 模型:
| 模型 | 作用 | 对应 OpenAI API |
|---|---|---|
ChatMessage |
单条消息 | message 对象 |
ToolFunction |
工具函数描述 | tool.function |
Tool |
工具定义 | tool 对象 |
ChatCompletionRequest |
请求体 | 请求参数 |
ChatCompletionChoice |
响应选择项 | choice 对象 |
Usage |
Token 统计 | usage 对象 |
ChatCompletionResponse |
完整响应 | 响应体 |
4.4 什么是 SSE 流式输出
SSE(Server-Sent Events)是一种"一边生成一边返回"的技术。
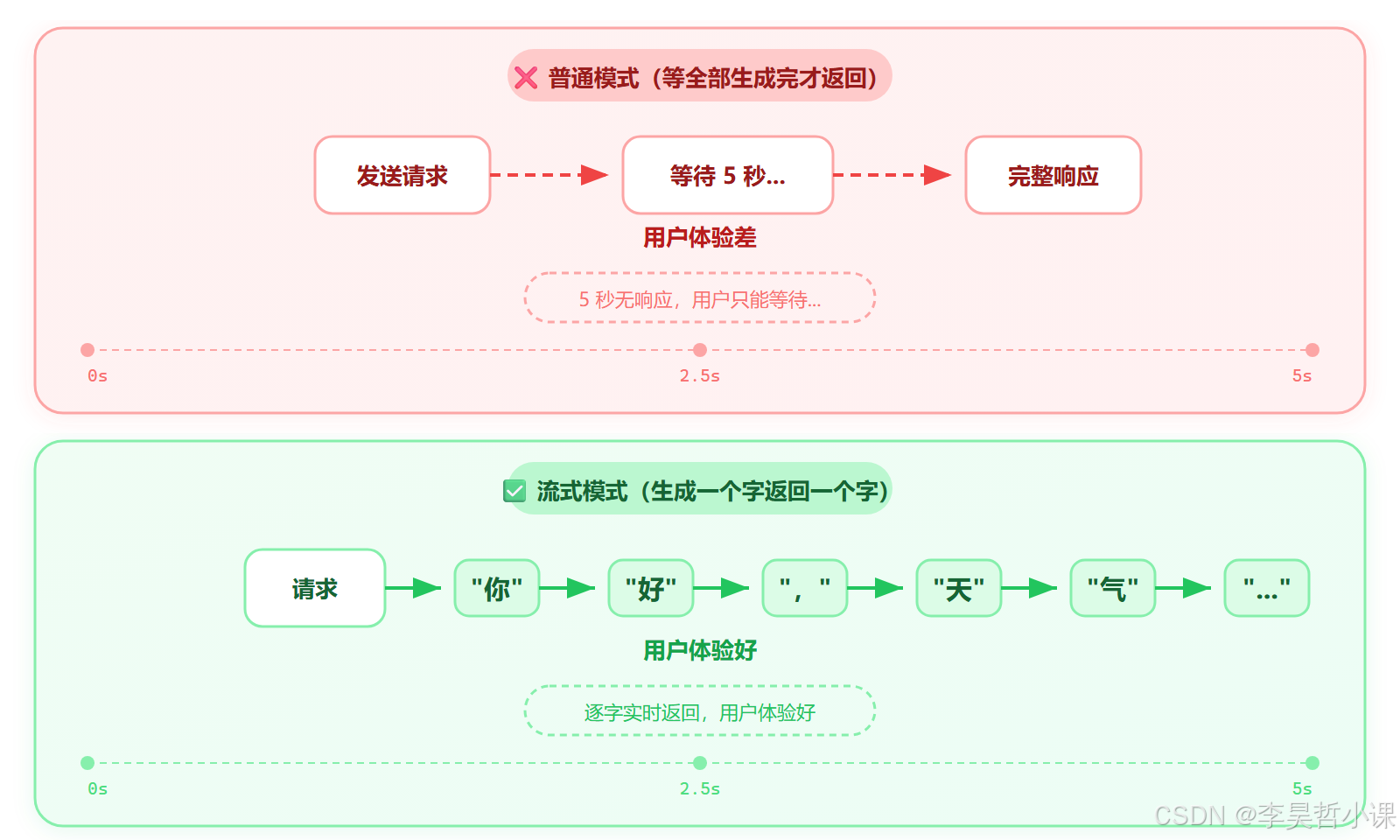
流式输出的用户体验更好------不用干等,可以实时看到生成过程。
SSE 的数据格式很简单:
data: {"choices":[{"delta":{"content":"你"}}]} ← 每个 token 一行
data: {"choices":[{"delta":{"content":"好"}}]}
data: [DONE] ← 结束标记4.5 什么是 GPU 和 CUDA
GPU(图形处理器)最初为游戏设计,但它的并行计算能力非常适合 AI 推理。
CUDA 是 NVIDIA 提供的 GPU 编程平台,让 Python 代码能调用 GPU 进行计算。
python
import torch
# 检查 GPU 是否可用
if torch.cuda.is_available():
print("GPU 可用")
print(f"GPU 名称: {torch.cuda.get_device_name(0)}")
print(f"显存大小: {torch.cuda.get_device_properties(0).total_mem / 1024**3:.1f} GB")
else:
print("GPU 不可用,将使用 CPU(速度较慢)")在 model_server.py 中,模型加载时自动选择设备:
python
# GPU 可用 → 用 float16(半精度,省显存,速度快)
# GPU 不可用 → 用 float32(全精度,兼容 CPU)
model = AutoModelForCausalLM.from_pretrained(
str(MODEL_PATH),
torch_dtype=torch.float16 if device == "cuda" else torch.float32,
device_map="auto" if device == "cuda" else None,
trust_remote_code=True
)💡 什么是 float16 和 device_map="auto"?
float16:每个数字用 16 位存储(默认 32 位),节省 50% 显存,精度损失极小device_map="auto":自动把模型分配到 GPU 上。如果模型太大放不下,自动把部分层放到 CPU
4.6 完整代码
python
"""
FastAPI 模型服务 --- OpenAI 兼容的本地模型 API
"""
import os, re, json, uuid, time, asyncio, threading
from pathlib import Path
from typing import List, Optional, Dict, Any, Union, AsyncGenerator
from contextlib import asynccontextmanager
from fastapi import FastAPI, HTTPException
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel, Field
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
# ==================== 配置 ====================
MODEL_PATH = Path(__file__).parent / "models" / "Qwen3-4B-Instruct-2507"
MODEL_NAME = "Qwen3-4B-Instruct-2507"
HOST = os.getenv("HOST", "0.0.0.0")
PORT = int(os.getenv("PORT", 8000))
MAX_NEW_TOKENS = int(os.getenv("MAX_NEW_TOKENS", 4096))
TEMPERATURE = float(os.getenv("TEMPERATURE", 0.7))
TOP_P = float(os.getenv("TOP_P", 0.9))
# ==================== 数据模型 ====================
class ChatMessage(BaseModel):
role: str = Field(..., description="消息角色: system/user/assistant/tool")
content: Optional[str] = Field(None, description="消息内容")
tool_calls: Optional[List[Dict[str, Any]]] = Field(None, description="工具调用")
tool_call_id: Optional[str] = Field(None, description="工具调用ID")
class ToolFunction(BaseModel):
name: str = Field(..., description="函数名称")
description: str = Field(..., description="函数描述")
parameters: Dict[str, Any] = Field(..., description="参数 schema")
class Tool(BaseModel):
type: str = Field(default="function", description="工具类型")
function: ToolFunction = Field(..., description="工具函数")
class ChatCompletionRequest(BaseModel):
model: str = Field(default=MODEL_NAME, description="模型名称")
messages: List[ChatMessage] = Field(..., description="消息列表")
tools: Optional[List[Tool]] = Field(None, description="可用工具列表")
temperature: Optional[float] = Field(TEMPERATURE, description="温度参数")
top_p: Optional[float] = Field(TOP_P, description="Top-p 采样")
max_tokens: Optional[int] = Field(MAX_NEW_TOKENS, description="最大生成 token 数")
stream: Optional[bool] = Field(False, description="是否流式输出")
class ChatCompletionChoice(BaseModel):
index: int = Field(0)
message: ChatMessage = Field(...)
finish_reason: str = Field(...)
class Usage(BaseModel):
prompt_tokens: int = Field(0)
completion_tokens: int = Field(0)
total_tokens: int = Field(0)
class ChatCompletionResponse(BaseModel):
id: str = Field(...)
object: str = Field(default="chat.completion")
created: int = Field(...)
model: str = Field(...)
choices: List[ChatCompletionChoice] = Field(...)
usage: Usage = Field(...)
# ==================== 全局变量 ====================
model = None
tokenizer = None
device = None
# ==================== 生命周期管理 ====================
@asynccontextmanager
async def lifespan(app: FastAPI):
global model, tokenizer, device
print("=" * 60)
print("Starting model service...")
print("=" * 60)
if torch.cuda.is_available():
device = "cuda"
print(f"GPU detected: {torch.cuda.get_device_name(0)}")
print(f"VRAM: {torch.cuda.get_device_properties(0).total_mem / 1024**3:.1f} GB")
else:
device = "cpu"
print("No GPU detected, using CPU")
if not MODEL_PATH.exists():
raise FileNotFoundError(f"Model not found at {MODEL_PATH}")
print(f"Model path: {MODEL_PATH}")
print("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(str(MODEL_PATH), trust_remote_code=True)
print("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
str(MODEL_PATH),
torch_dtype=torch.float16 if device == "cuda" else torch.float32,
device_map="auto" if device == "cuda" else None,
trust_remote_code=True
)
if device == "cpu":
model = model.to(device)
model.eval()
print("Model loaded successfully")
print("-" * 60)
yield
print("Shutting down service...")
del model
del tokenizer
if torch.cuda.is_available():
torch.cuda.empty_cache()
# ==================== FastAPI 应用 ====================
app = FastAPI(title="Qwen3-4B-Instruct API", version="1.0.0", lifespan=lifespan)
app.add_middleware(CORSMiddleware, allow_origins=["*"], allow_credentials=True,
allow_methods=["*"], allow_headers=["*"])
# ==================== 工具函数 ====================
def parse_tool_calls_from_text(response_text):
"""从模型输出中解析工具调用,转换为 OpenAI 标准格式。"""
# 方法1:匹配自定义标签 【...】
match = re.search(r'【\s*(.*?)\s*】', response_text, re.DOTALL)
if match:
try:
tool_call = json.loads(match.group(1).strip())
if "name" in tool_call:
args = tool_call.get("arguments", tool_call.get("parameters", {}))
return [{"id": f"call_{uuid.uuid4().hex[:24]}", "type": "function",
"function": {"name": tool_call["name"],
"arguments": json.dumps(args) if isinstance(args, dict) else args}}]
except json.JSONDecodeError:
pass
# 方法2:直接匹配 JSON
name_match = re.search(r'"name"\s*:\s*"([^"]+)"', response_text)
if name_match:
args_match = re.search(r'"arguments"\s*:\s*(\{[^}]*(?:\{[^}]*\}[^}]*)*\})', response_text, re.DOTALL)
if args_match:
try:
args = json.loads(args_match.group(1))
return [{"id": f"call_{uuid.uuid4().hex[:24]}", "type": "function",
"function": {"name": name_match.group(1), "arguments": json.dumps(args)}}]
except json.JSONDecodeError:
pass
return None
def format_messages(messages):
"""Pydantic 模型 → 字典,过滤空值字段。"""
formatted = []
for msg in messages:
item = {"role": msg.role}
if msg.content: item["content"] = msg.content
if msg.tool_calls: item["tool_calls"] = msg.tool_calls
if msg.tool_call_id: item["tool_call_id"] = msg.tool_call_id
formatted.append(item)
return formatted
def format_tools(tools):
"""Pydantic 工具模型 → 字典。"""
if not tools:
return None
return [{"type": t.type, "function": {"name": t.function.name,
"description": t.function.description, "parameters": t.function.parameters}} for t in tools]
def generate_response(messages, tools=None, temperature=TEMPERATURE, top_p=TOP_P, max_tokens=MAX_NEW_TOKENS):
"""生成模型响应(非流式)。"""
text = tokenizer.apply_chat_template(messages, tools=tools, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=max_tokens, temperature=temperature,
top_p=top_p, do_sample=True, pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id)
generated_ids = outputs[0][inputs.input_ids.shape[1]:]
response_text = tokenizer.decode(generated_ids, skip_special_tokens=True)
tool_calls = parse_tool_calls_from_text(response_text)
if tool_calls:
return {"content": None, "tool_calls": tool_calls,
"prompt_tokens": inputs.input_ids.shape[1], "completion_tokens": len(generated_ids)}
return {"content": response_text, "tool_calls": None,
"prompt_tokens": inputs.input_ids.shape[1], "completion_tokens": len(generated_ids)}
async def generate_stream(messages, tools=None, temperature=TEMPERATURE, top_p=TOP_P,
max_tokens=MAX_NEW_TOKENS, request_id=""):
"""生成模型响应(流式 SSE)。"""
text = tokenizer.apply_chat_template(messages, tools=tools, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text, return_tensors="pt").to(device)
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
gen_kwargs = {**inputs, "max_new_tokens": max_tokens, "temperature": temperature, "top_p": top_p,
"do_sample": True, "pad_token_id": tokenizer.pad_token_id,
"eos_token_id": tokenizer.eos_token_id, "streamer": streamer}
thread = threading.Thread(target=model.generate, kwargs=gen_kwargs)
thread.daemon = True
thread.start()
for token in streamer:
chunk = {"id": request_id, "object": "chat.completion.chunk", "created": int(time.time()),
"model": MODEL_NAME, "choices": [{"index": 0, "delta": {"content": token}, "finish_reason": None}]}
yield f"data: {json.dumps(chunk, ensure_ascii=False)}\n\n"
final = {"id": request_id, "object": "chat.completion.chunk", "created": int(time.time()),
"model": MODEL_NAME, "choices": [{"index": 0, "delta": {}, "finish_reason": "stop"}]}
yield f"data: {json.dumps(final, ensure_ascii=False)}\n\n"
yield "data: [DONE]\n\n"
# ==================== API 路由 ====================
@app.get("/health")
async def health_check():
return {"status": "healthy", "model": MODEL_NAME}
@app.get("/v1/models")
async def list_models():
return {"object": "list", "data": [{"id": MODEL_NAME, "object": "model",
"created": int(time.time()), "owned_by": "local"}]}
@app.post("/v1/chat/completions")
async def chat_completions(request: ChatCompletionRequest):
request_id = f"chatcmpl-{int(time.time() * 1000)}"
formatted_messages = format_messages(request.messages)
formatted_tools = format_tools(request.tools)
if request.stream:
return StreamingResponse(
generate_stream(formatted_messages, formatted_tools, request.temperature,
request.top_p, request.max_tokens, request_id),
media_type="text/event-stream")
try:
result = generate_response(formatted_messages, formatted_tools,
request.temperature, request.top_p, request.max_tokens)
msg_data = {"role": "assistant", "content": result["content"]}
if result.get("tool_calls"):
msg_data["tool_calls"] = result["tool_calls"]
finish_reason = "tool_calls"
else:
finish_reason = "stop"
return ChatCompletionResponse(id=request_id, created=int(time.time()), model=MODEL_NAME,
choices=[ChatCompletionChoice(index=0, message=ChatMessage(**msg_data),
finish_reason=finish_reason)],
usage=Usage(prompt_tokens=result["prompt_tokens"],
completion_tokens=result["completion_tokens"],
total_tokens=result["prompt_tokens"] + result["completion_tokens"]))
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
import uvicorn, argparse
parser = argparse.ArgumentParser(description="Qwen3-4B-Instruct API Service")
parser.add_argument("--host", type=str, default=HOST)
parser.add_argument("--port", type=int, default=PORT)
args = parser.parse_args()
print(f"Service URL: http://{args.host}:{args.port}")
print(f"API Docs: http://{args.host}:{args.port}/docs")
uvicorn.run(app, host=args.host, port=args.port, log_level="info")4.7 运行效果
bash
uvicorn model_server:app --host 0.0.0.0 --port 8000启动输出:
============================================================
Starting model service...
============================================================
GPU detected: NVIDIA GeForce RTX 3070 Ti Laptop GPU
VRAM: 8.0 GB
Model path: F:\lang\models\Qwen3-4B-Instruct-2507
Loading tokenizer...
Loading model...
Model loaded successfully
------------------------------------------------------------
INFO: Uvicorn running on http://0.0.0.0:8000测试接口:
bash
# 测试健康检查
curl http://localhost:8000/health
# → {"status": "healthy", "model": "Qwen3-4B-Instruct-2507"}
# 测试对话
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"Qwen3-4B-Instruct-2507","messages":[{"role":"user","content":"你好"}]}'打开浏览器访问 http://localhost:8000/docs 可以看到自动生成的 API 文档(Swagger UI)。
第五章:Agent 构建(weather_agent.py)
📍 当前进度 :① 环境准备 ✅ → ② 下载模型 ✅ → ③ 启动服务 ✅ → ④ 运行 Agent ← 📍
本文件是 Agent 的核心(约 150 行有效代码)。你将学会:Message、Tool、State、Graph、Agent 循环
前提 :确保model_server.py已启动(第三章的服务)
5.1 什么是消息(Message)
在 Agent 系统中,所有的对话内容都以"消息"的形式存储。不同角色发送不同类型的消息:
| 消息类型 | 角色 | 什么时候产生 | 例子 |
|---|---|---|---|
HumanMessage |
用户 | 用户输入时 | "上海天气怎么样?" |
AIMessage |
AI | AI 回复时 | "上海今天天气晴朗..." |
ToolMessage |
工具 | 工具执行后 | "晴朗,23.4°C,湿度52%..." |
三种消息依次产生,形成 Agent 的"对话历史":
python
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
# 用户提问
msg1 = HumanMessage(content="上海天气")
# AI 决定调用工具
msg2 = AIMessage(content="", tool_calls=[{"name": "get_weather", "args": {"city": "上海"}}])
# 工具返回结果
msg3 = ToolMessage(content="晴朗,23.4°C,湿度52%", tool_call_id="call_123")
# AI 根据工具结果回复
msg4 = AIMessage(content="上海今天天气晴朗,温度23.4°C...")💡 为什么
AIMessage有时content=""?当 AI 决定调用工具时,它不需要生成文字回答,只需要告诉系统"我想调用 get_weather"。
此时
content为空,tool_calls包含工具调用信息。
5.2 什么是工具(Tool)
工具是 Agent 的"手脚"。AI 是大脑,负责思考;工具负责执行具体操作。
定义工具非常简单------用 @tool 装饰一个普通 Python 函数:
python
from langchain_core.tools import tool
@tool
def get_weather(city: str) -> str:
"""获取指定城市的实时天气信息。"""
# 1. 调用地理编码 API:城市名 → 经纬度
# 2. 调用天气 API:经纬度 → 天气数据
# 3. 格式化返回
return f"城市: {city}\n天气: 晴朗\n温度: 23.4°C"💡
@tool装饰器做了什么?
- 读取函数名
get_weather→ 作为工具名称- 读取参数类型
city: str→ 生成参数 schema- 读取 docstring → 作为工具描述
- 把以上信息打包成 JSON,发给 LLM,让 LLM 知道"有这个工具可以用"
@tool 自动生成的工具描述(LLM 看到的):
{
"name": "get_weather",
"description": "获取指定城市的实时天气信息。",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
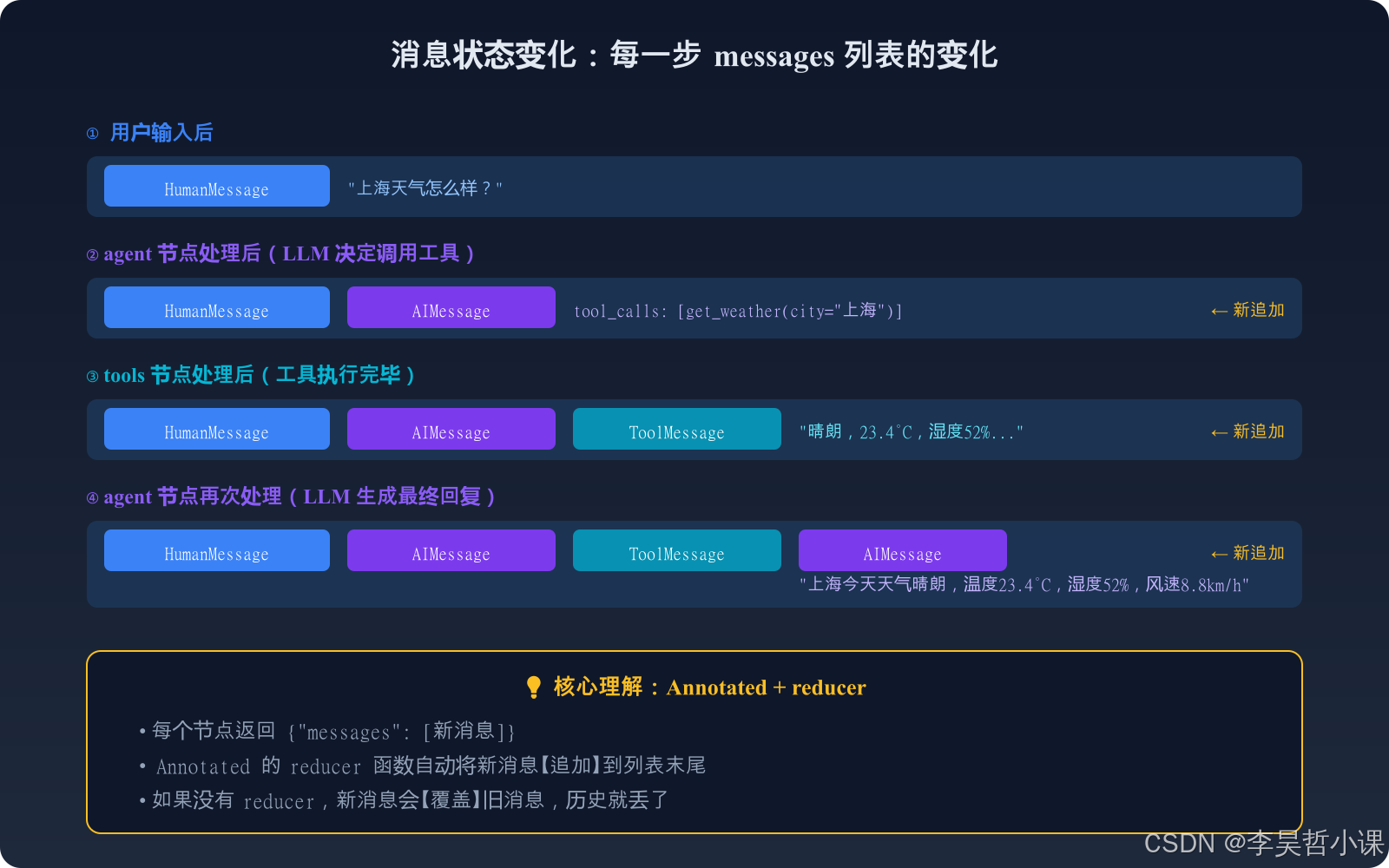
}5.3 什么是状态(State)
状态(State)是 Agent 的"记忆"。在 LangGraph 中,所有节点共享同一个状态对象,通过状态传递数据:
python
from typing import TypedDict, Annotated, Sequence
from langchain_core.messages import BaseMessage
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], "消息历史"]只有一行代码,但涉及 4 个概念:
| 概念 | 作用 | 类比 |
|---|---|---|
TypedDict |
给字典加类型约束 | 有格式的笔记本 |
Sequence[BaseMessage] |
消息的有序列表 | 排好队的消息队列 |
Annotated |
给类型附加元数据 | 给类型贴标签 |
"消息历史" |
reducer 描述 | 规则:新消息追加,不覆盖 |
💡 什么是 reducer?为什么需要它?
默认情况下,节点返回的值会覆盖 旧值。
但消息需要累积 (不能丢掉历史),所以需要 reducer 告诉 LangGraph:"新消息追加到列表末尾"。
如果没有 reducer,每次 agent 节点运行后,之前的消息就丢了。
5.4 什么是图(Graph)
LangGraph 用"图"来定义 Agent 的工作流程。图由三个要素组成:
| 要素 | 代码 | 类比 |
|---|---|---|
| 节点 (Node) | add_node("agent", agent_node) |
流水线上的工位 |
| 边 (Edge) | add_edge("tools", "agent") |
工位之间的传送带 |
| 条件边 | add_conditional_edges(...) |
带岔路口的传送带 |
构建图的步骤:
python
from langgraph.graph import StateGraph, END
from langgraph.prebuilt import ToolNode
# 1. 创建图
workflow = StateGraph(AgentState)
# 2. 添加节点
workflow.add_node("agent", agent_node) # AI 推理节点
workflow.add_node("tools", ToolNode(tools=tools)) # 工具执行节点
# 3. 设置入口
workflow.set_entry_point("agent")
# 4. 添加条件边:agent 之后走哪?
workflow.add_conditional_edges(
"agent", # 从 agent 节点出发
should_continue, # 用这个函数做判断
{"tools": "tools", END: END} # 返回 "tools" → 去工具节点;返回 END → 结束
)
# 5. 添加普通边:工具执行完回 agent
workflow.add_edge("tools", "agent")
# 6. 编译
app = workflow.compile()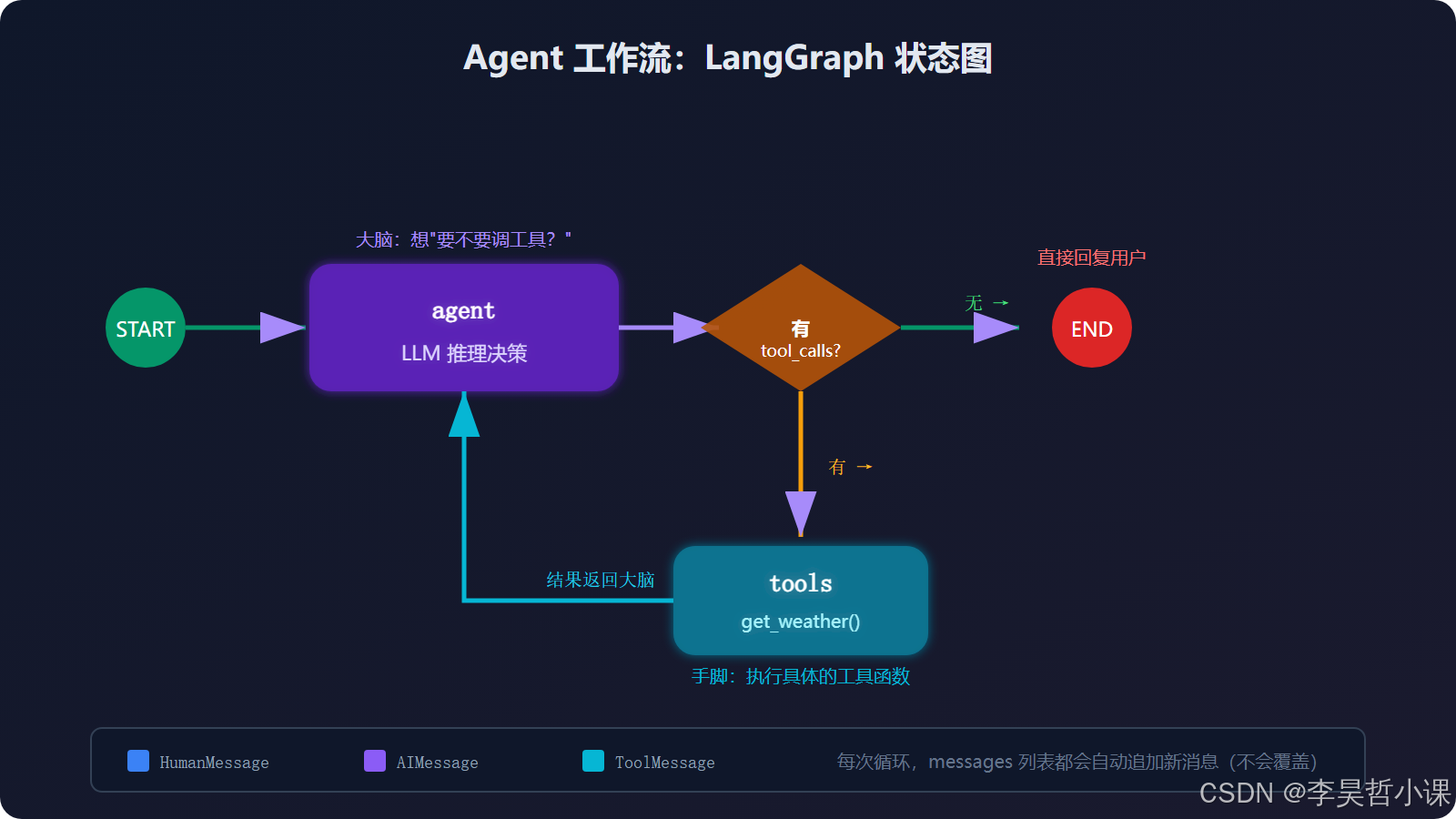
5.5 什么是 Agent 循环
Agent 的核心机制是一个循环:思考 → 行动 → 思考 → ...直到得出答案
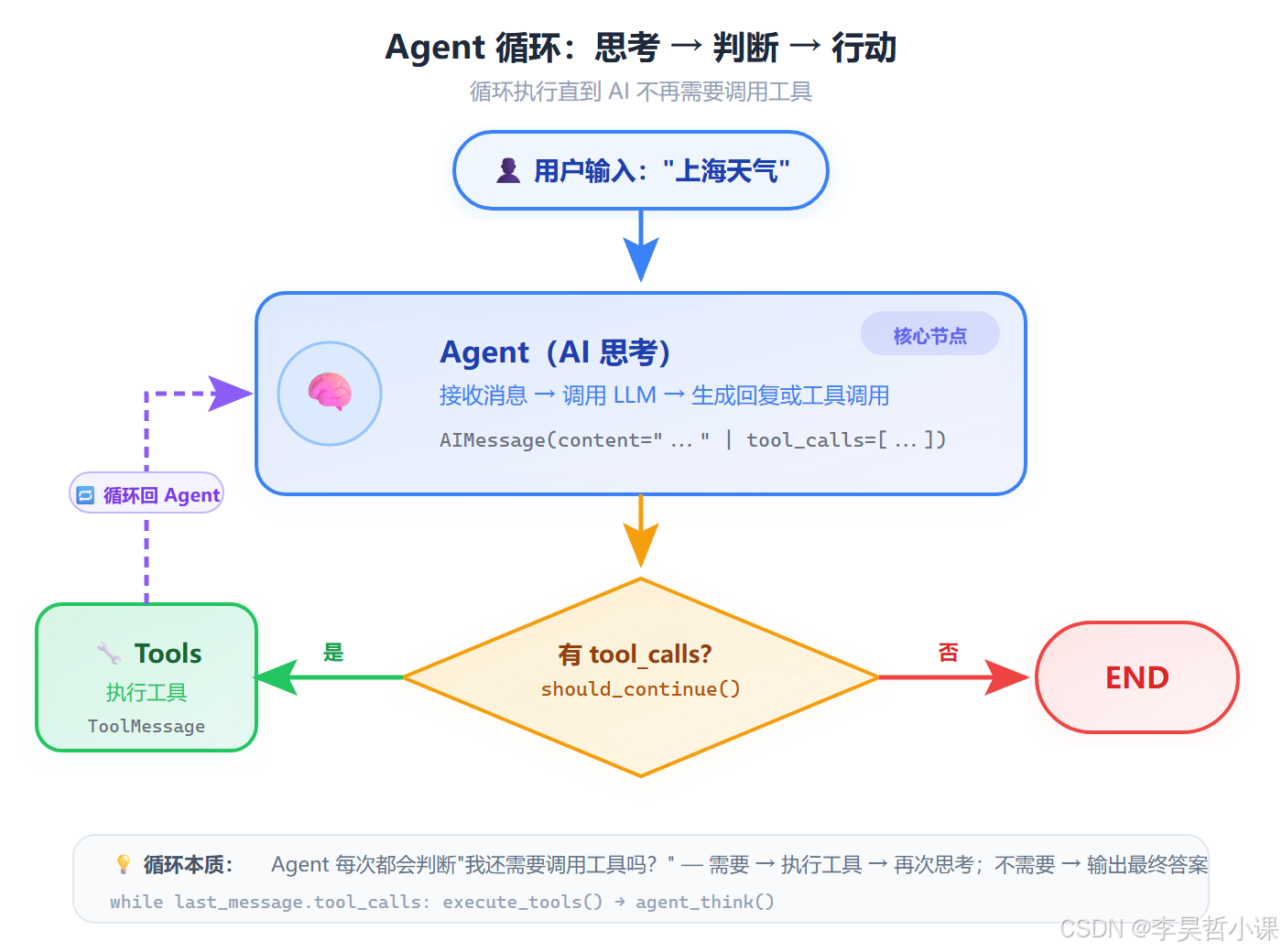
用户:"上海天气"
第 1 轮:
agent(思考)→ "我需要查天气" → 输出 AIMessage(tool_calls=[get_weather])
should_continue → 有 tool_calls → 路由到 tools
第 2 轮:
tools(行动)→ 执行 get_weather("上海") → 返回 ToolMessage("晴朗,23.4°C")
回到 agent
第 3 轮:
agent(再思考)→ "现在我有数据了" → 输出 AIMessage("上海今天天气晴朗...")
should_continue → 无 tool_calls → 结束 (END)Open-Meteo API tools 节点 should_continue agent 节点 用户 Open-Meteo API tools 节点 should_continue agent 节点 用户 HumanMessage("上海天气") LLM 推理 AIMessage(tool_calls=get_weather) 有 tool_calls → 路由到 tools GET /v1/forecast?latitude=31.2&longitude=121.5 {"temperature": 23.4, "humidity": 52, ...} ToolMessage("晴朗,23.4°C...") LLM 再次推理(带着天气数据) AIMessage("上海今天天气晴朗...") 无 tool_calls → END → 返回最终回复
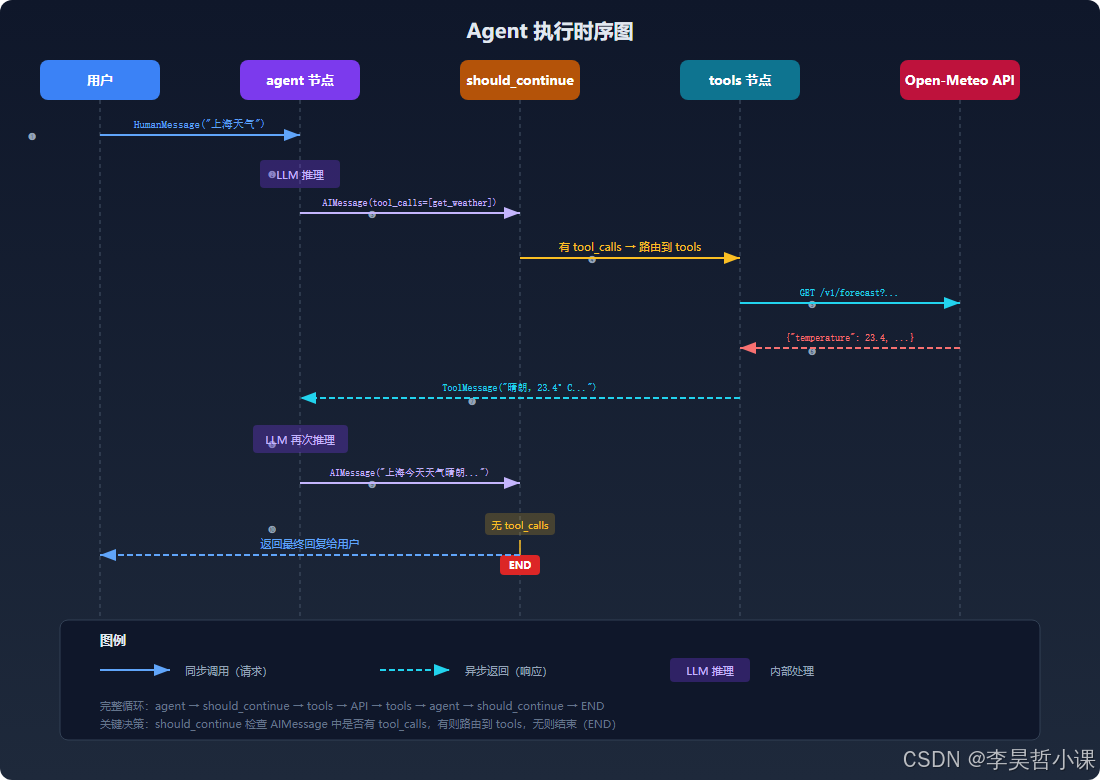
5.6 完整代码
python
"""
天气查询 Agent(基于本地模型)
"""
import requests
from typing import TypedDict, Annotated, Sequence
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage, ToolMessage
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, END
# ==================== 工具定义 ====================
@tool
def get_weather(city: str) -> str:
"""获取指定城市的实时天气信息。"""
try:
# 第一步:地理编码(城市名 → 经纬度)
geo_response = requests.get("https://geocoding-api.open-meteo.com/v1/search",
params={"name": city, "count": 1, "language": "zh"}, timeout=10)
geo_data = geo_response.json()
if not geo_data.get("results"):
return f"未找到城市: {city}"
location = geo_data["results"][0]
latitude, longitude = location["latitude"], location["longitude"]
city_name = location.get("name", city)
# 第二步:查询天气
weather_response = requests.get("https://api.open-meteo.com/v1/forecast",
params={"latitude": latitude, "longitude": longitude,
"current": "temperature_2m,relative_humidity_2m,weather_code,wind_speed_10m",
"timezone": "auto"}, timeout=10)
weather_data = weather_response.json()
current = weather_data.get("current", {})
temp = current.get("temperature_2m", "N/A")
humidity = current.get("relative_humidity_2m", "N/A")
weather_code = current.get("weather_code", 0)
wind_speed = current.get("wind_speed_10m", "N/A")
weather_map = {0: "晴朗", 1: "大部晴朗", 2: "多云", 3: "阴天",
45: "雾", 61: "小雨", 63: "中雨", 65: "大雨",
71: "小雪", 73: "中雪", 75: "大雪", 95: "雷暴"}
weather_desc = weather_map.get(weather_code, f"未知({weather_code})")
return f"城市: {city_name}\n天气: {weather_desc}\n温度: {temp}°C\n湿度: {humidity}%\n风速: {wind_speed} km/h"
except Exception as e:
return f"查询天气失败: {str(e)}"
tools = [get_weather]
# ==================== 模型配置 ====================
llm = ChatOpenAI(
model="Qwen3-4B-Instruct-2507",
base_url="http://localhost:8000/v1",
api_key="local",
temperature=0.7
)
llm_with_tools = llm.bind_tools(tools)
# ==================== 状态定义 ====================
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], "消息历史"]
# ==================== 节点函数 ====================
def agent_node(state: AgentState) -> dict:
"""Agent 节点:调用 LLM 生成响应或工具调用请求。"""
messages = state["messages"]
response = llm_with_tools.invoke(messages)
return {"messages": [response]}
def tool_node(state: AgentState) -> dict:
"""工具节点:执行 LLM 请求的工具调用。"""
messages = state["messages"]
last_message = messages[-1]
tool_messages = []
for tool_call in last_message.tool_calls:
tool_name = tool_call["name"]
tool_args = tool_call["args"]
if tool_name == "get_weather":
result = get_weather.invoke(tool_args)
else:
result = f"未知工具: {tool_name}"
tool_messages.append(ToolMessage(content=result, tool_call_id=tool_call["id"]))
return {"messages": tool_messages}
# ==================== 条件判断 ====================
def should_continue(state: AgentState) -> str:
"""判断是否需要继续执行工具调用。"""
messages = state["messages"]
last_message = messages[-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
return "tools"
return END
# ==================== 工作流构建 ====================
workflow = StateGraph(AgentState)
workflow.add_node("agent", agent_node)
workflow.add_node("tools", tool_node)
workflow.set_entry_point("agent")
workflow.add_conditional_edges("agent", should_continue, {"tools": "tools", END: END})
workflow.add_edge("tools", "agent")
app = workflow.compile()
# ==================== 主程序 ====================
def run_agent(user_input: str) -> str:
"""运行 Agent 处理用户输入。"""
messages = [HumanMessage(content=user_input)]
result = app.invoke({"messages": messages})
for message in reversed(result["messages"]):
if isinstance(message, AIMessage):
return message.content
return "无法生成响应"
if __name__ == "__main__":
print("=" * 60)
print("🌤️ 天气查询 Agent(基于本地 Qwen3-4B-Instruct)")
print("=" * 60)
print("📝 使用说明:")
print(" - 输入城市名查询天气,如:北京天气怎么样?")
print(" - 输入 'quit' 退出程序")
print("-" * 60)
test_query = "上海今天天气怎么样?"
print(f"🤖 测试查询: {test_query}")
print("-" * 60)
try:
response = run_agent(test_query)
print(f"🤖 AI 回答:\n{response}")
except Exception as e:
print(f"❌ 错误: {str(e)}")
print(" 请确保模型服务已启动: uvicorn model_server:app --host 0.0.0.0 --port 8000")5.7 运行效果
bash
# 先启动模型服务(终端 1)
uvicorn model_server:app --host 0.0.0.0 --port 8000
# 再运行 Agent(终端 2)
python weather_agent.py输出:
============================================================
🌤️ 天气查询 Agent(基于本地 Qwen3-4B-Instruct)
============================================================
📝 使用说明:
- 输入城市名查询天气,如:北京天气怎么样?
- 输入 'quit' 退出程序
------------------------------------------------------------
🤖 测试查询: 上海今天天气怎么样?
------------------------------------------------------------
🤖 AI 回答:
根据查询结果,上海今天的天气情况如下:
- 天气:晴朗
- 温度:23.4°C
- 湿度:52%
- 风速:8.8 km/h
总体来说天气不错,适合外出活动!第六章:运行与调试
完整运行步骤
第一步:下载模型(只需运行一次)
bash
python download_model.py第二步:启动模型服务(每次使用都要先启动)
bash
uvicorn model_server:app --host 0.0.0.0 --port 8000第三步:运行 Agent
bash
python weather_agent.pyAPI 文档
启动模型服务后,浏览器打开 http://localhost:8000/docs 可以看到自动生成的交互式 API 文档(Swagger UI),可以直接在网页上测试接口。
常见问题
| 问题 | 原因 | 解决方案 |
|---|---|---|
ModuleNotFoundError: modelscope |
未安装 modelscope | pip install modelscope |
Model not found at ... |
模型未下载 | 先运行 python download_model.py |
ConnectionError |
模型服务未启动 | 先运行 uvicorn model_server:app ... |
CUDA out of memory |
显存不足 | 换更小的模型或用 CPU 模式 |
Tool calls not working |
工具调用格式不兼容 | 确认 model_server.py 是最新版 |
附录:技术名词速查表
| 名词 | 英文 | 通俗解释 | 类比 |
|---|---|---|---|
| 变量 | Variable | 存数据的盒子 | 贴标签的盒子 |
| 常量 | Constant | 约定不改的变量 | 固定标签 |
| 函数 | Function | 可重复使用的代码块 | 菜谱 |
| import | Import | 引入外部工具 | 从工具箱拿工具 |
| if/else | Conditional | 根据条件做不同的事 | 路口分流 |
| try/except | Exception Handling | 出错时的补救措施 | 安全网 |
| HTTP | HyperText Transfer Protocol | 互联网通信规则 | 电话通话规则 |
| API | Application Programming Interface | 程序之间通信的约定 | 电话号码+通话格式 |
| FastAPI | FastAPI | Python Web 框架 | 餐厅前台 |
| Pydantic | Pydantic | 数据格式校验库 | 门票验证员 |
| SSE | Server-Sent Events | 流式推送协议 | 实时字幕 |
| GPU | Graphics Processing Unit | 图形处理器 | 加速引擎 |
| CUDA | CUDA | NVIDIA GPU 编程平台 | GPU 的驱动程序 |
| LLM | Large Language Model | 大语言模型 | 博学但没有手脚的人 |
| Agent | Agent | 能自主决策的 AI | 有大脑和手脚的人 |
| Tool | Tool | Agent 可调用的功能 | AI 的手脚 |
| Message | Message | 对话中的单条信息 | 聊天中的一句话 |
| State | State | 工作流中传递的数据 | 共享笔记本 |
| Node | Node | 工作流中的处理站 | 流水线工位 |
| Edge | Edge | 节点间的连接 | 传送带 |
| Graph | Graph | 完整的工作流程 | 工厂流水线设计图 |
| Reducer | Reducer | 状态更新规则 | "追加"还是"覆盖" |
| ModelScope | ModelScope | 阿里云模型托管平台 | 模型的 App Store |
| FP16 | Float16 | 半精度浮点数 | 省空间的数据格式 |
快速参考
运行命令
bash
# 1. 下载模型(只需一次)
python download_model.py
# 2. 启动模型服务(终端 1)
uvicorn model_server:app --host 0.0.0.0 --port 8000
# 3. 运行 Agent(终端 2)
python weather_agent.py核心代码模板
python
# 1. 定义工具
@tool
def my_tool(param: str) -> str:
"""工具描述(LLM 会读到这段文字)"""
return "结果"
# 2. 定义状态
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], "消息历史"]
# 3. 创建模型客户端(连接本地服务)
llm = ChatOpenAI(model="Qwen3-4B-Instruct-2507", base_url="http://localhost:8000/v1", api_key="local")
llm_with_tools = llm.bind_tools([my_tool])
# 4. 定义节点
def agent_node(state):
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}
def tool_node(state):
# 执行工具,返回 ToolMessage
...
def should_continue(state):
if state["messages"][-1].tool_calls:
return "tools"
return END
# 5. 构建图
workflow = StateGraph(AgentState)
workflow.add_node("agent", agent_node)
workflow.add_node("tools", ToolNode([my_tool]))
workflow.set_entry_point("agent")
workflow.add_conditional_edges("agent", should_continue, {"tools": "tools", END: END})
workflow.add_edge("tools", "agent")
app = workflow.compile()
# 6. 运行
result = app.invoke({"messages": [HumanMessage(content="问题")]})
print(result["messages"][-1].content)完整的工作流程 | 工厂流水线设计图 |
| Reducer | Reducer | 状态更新规则 | "追加"还是"覆盖" |
| ModelScope | ModelScope | 阿里云模型托管平台 | 模型的 App Store |
| FP16 | Float16 | 半精度浮点数 | 省空间的数据格式 |
快速参考
运行命令
bash
# 1. 下载模型(只需一次)
python download_model.py
# 2. 启动模型服务(终端 1)
uvicorn model_server:app --host 0.0.0.0 --port 8000
# 3. 运行 Agent(终端 2)
python weather_agent.py核心代码模板
python
# 1. 定义工具
@tool
def my_tool(param: str) -> str:
"""工具描述(LLM 会读到这段文字)"""
return "结果"
# 2. 定义状态
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], "消息历史"]
# 3. 创建模型客户端(连接本地服务)
llm = ChatOpenAI(model="Qwen3-4B-Instruct-2507", base_url="http://localhost:8000/v1", api_key="local")
llm_with_tools = llm.bind_tools([my_tool])
# 4. 定义节点
def agent_node(state):
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}
def tool_node(state):
# 执行工具,返回 ToolMessage
...
def should_continue(state):
if state["messages"][-1].tool_calls:
return "tools"
return END
# 5. 构建图
workflow = StateGraph(AgentState)
workflow.add_node("agent", agent_node)
workflow.add_node("tools", ToolNode([my_tool]))
workflow.set_entry_point("agent")
workflow.add_conditional_edges("agent", should_continue, {"tools": "tools", END: END})
workflow.add_edge("tools", "agent")
app = workflow.compile()
# 6. 运行
result = app.invoke({"messages": [HumanMessage(content="问题")]})
print(result["messages"][-1].content)