论文精读:大语言模型 (Large Language Models, LLM) ------ 一项调查
Minaee, Shervin et al. "Large Language Models: A Survey." ArXiv abs/2402.06196 (2024): n. pag.
0. 全文结构导览与阅读路线
论文用一张结构图把全篇组织为"模型谱系---构建方法---使用与增强---数据集---评测---挑战与未来"的闭环:先回答"有什么模型",再回答"怎么训练/对齐/部署",最后回答"如何衡量与未来怎么走"。这图是一条工程流水线:数据与架构给出能力上限,对齐与解码决定可用性与风格,RAG/工具/Agent 把模型从静态文本生成推进到可行动系统。
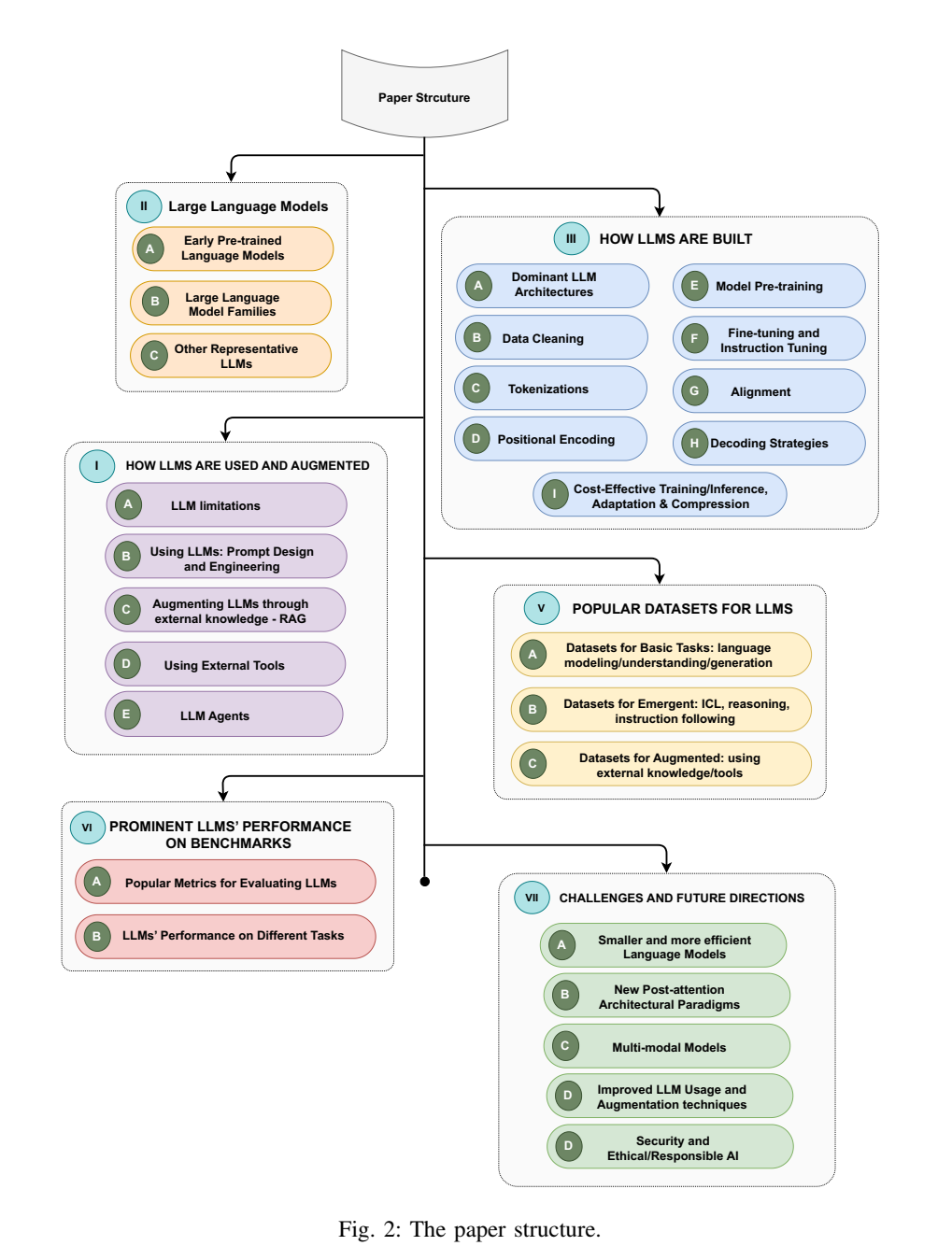
图2解读:这是一张流程式结构图,按章节将论文分成若干块:II 综述 LLM 家族与代表模型,III 讲构建(数据、tokenization、预训练、对齐等),IV 讲使用与增强(prompt、RAG、工具、Agent),V--VI 讲数据集与基准评测,VII 总结挑战与未来方向。
1. LLM 的能力谱系:基础能力、涌现能力与增强能力
论文在引言处用"能力分层"的方式定义 LLM 的关键特征:相比早期预训练语言模型(PLM),LLM 不只是参数更大,而是出现了小模型不明显的涌现能力(in-context learning、指令跟随、多步推理等),并且可以通过外部知识与工具进一步增强,形成面向真实世界的 agent 系统。
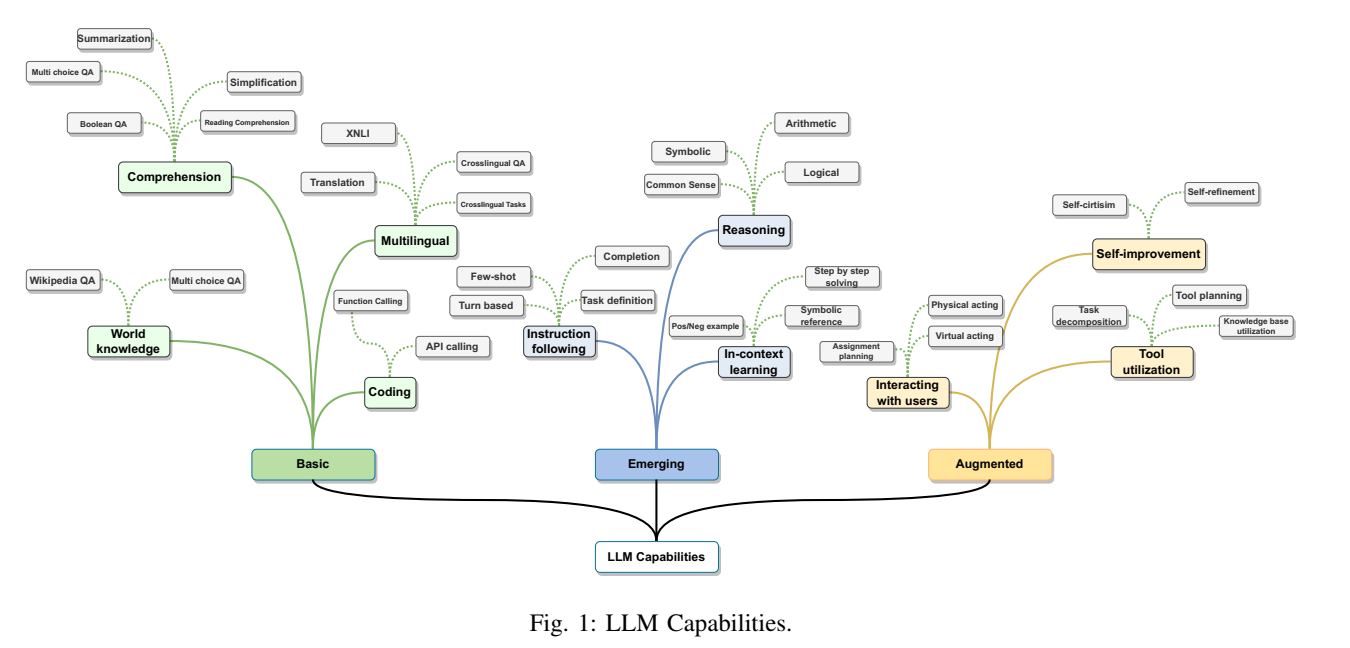
图1解读:图像以"能力类别"为骨架,把 LLM 的能力组织成层级结构:底层是语言理解与生成、知识与推理等基础能力;中间强调涌现(例如 ICL 与 CoT 推理);上层是增强能力(外部知识、工具调用、交互学习),最终指向 AI Agent(感知环境、决策、执行与反馈)。图像的隐含观点是:LLM 的"智能表现"往往来自训练目标与系统增强的叠加,而非单一模型结构。
2. 语言建模的概率基础:从链式分解到神经语言模型
无论是统计语言模型还是大语言模型,其数学核心都是为序列 x1:T=(x1,...,xT)x_{1:T}=(x_1,\dots,x_T)x1:T=(x1,...,xT) 建立概率分布。最基本的链式法则是:
p(x1:T)=∏t=1Tp(xt∣x<t). p(x_{1:T}) = \prod_{t=1}^{T} p(x_t \mid x_{<t}). p(x1:T)=t=1∏Tp(xt∣x<t).
统计语言模型(如 nnn-gram)通过马尔可夫假设缩短条件依赖:
p(xt∣x<t)≈p(xt∣xt−n:t−1). p(x_t \mid x_{<t}) \approx p(x_t \mid x_{t-n:t-1}). p(xt∣x<t)≈p(xt∣xt−n:t−1).
而神经语言模型把离散 token 映射到连续向量空间,用可微函数近似条件分布(例如 softmax 输出)。论文在引言中强调了从"任务特定的早期神经语言模型"走向"任务无关的预训练语言模型(PLM)"的范式跃迁:PLM 先在大规模无标注文本上用自监督目标学习通用表征,再用少量标注数据对齐到具体任务。
3. PLM 到 LLM:三类架构与自监督目标的演化
3.1 编码器模型:BERT 与"掩码重建"的统计含义
BERT 是典型的 encoder-only 结构。论文用图3展示其"预训练---微调"两阶段:预训练用 MLM 与 NSP;微调时在顶层接分类/抽取等任务头。
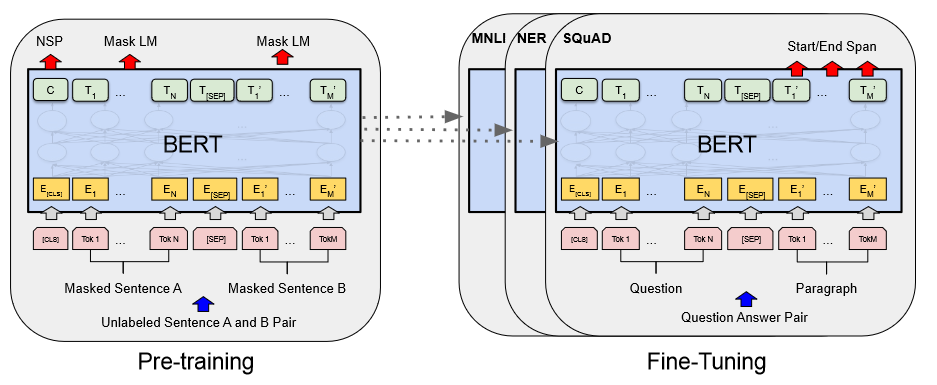
图3解读:图左侧是预训练:输入句对 A/B,部分 token 被 mask,模型同时做 Mask LM 与 Next Sentence Prediction;图右侧是微调:同一 BERT 主体被复用,通过不同任务头适配 MNLI/NER/SQuAD 等。它强调了一个关键工程事实:通用表示来自预训练目标,而迁移来自"冻结主体 + 少量任务特定参数"。
从数学上看,MLM 可写为在被 mask 的位置集合 MMM 上最大化条件似然:
maxθ∑i∈Mlogpθ(xi∣x∖M), \max_\theta \sum_{i\in M}\log p_\theta(x_i\mid x_{\setminus M}), θmaxi∈M∑logpθ(xi∣x∖M),
等价地最小化损失:
L∗MLM(θ)=−∑∗i∈Mlogpθ(xi∣x∖M). \mathcal{L}*{\text{MLM}}(\theta)= -\sum*{i\in M}\log p_\theta(x_i\mid x_{\setminus M}). L∗MLM(θ)=−∑∗i∈Mlogpθ(xi∣x∖M).
这类目标的关键区别在于"可见上下文"是双向的,因此 encoder-only 模型天然擅长理解类任务(分类、抽取、匹配)。论文也据此概括了后续改进(RoBERTa、ALBERT、DeBERTa 等)的主线:更大规模训练、更合理的目标/结构偏置、更高效的参数使用。
3.2 ELECTRA:用 RTD 提高样本效率
论文用图4强调 RTD(replaced token detection)相较 MLM 的"监督密度优势":MLM 只在少量 mask 位置产生梯度,而 RTD 对每个位置都进行真假判别,从而更样本高效。
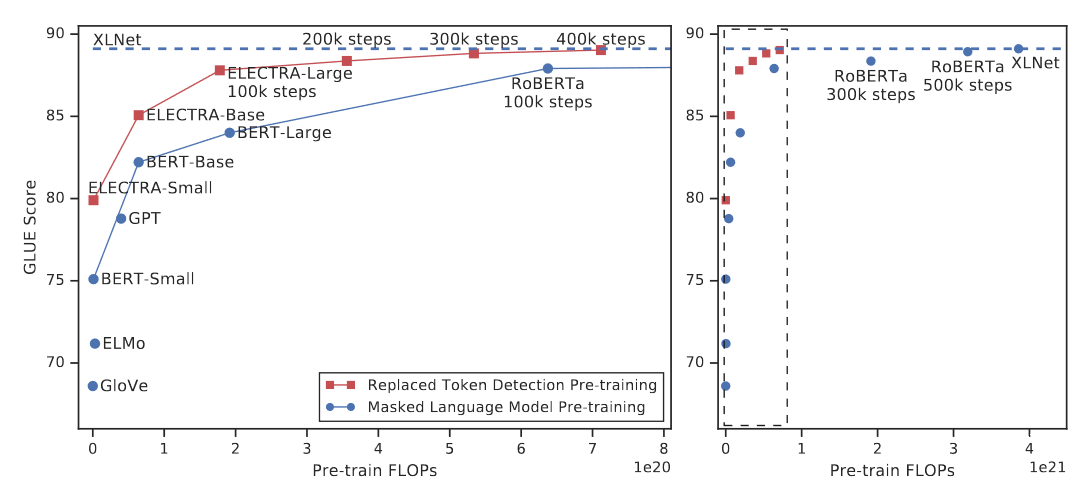
图4解读:图像以"预训练 FLOPs"为横轴,"GLUE 分数"为纵轴,用点与曲线对比两类预训练策略。红色(RTD)在较低 FLOPs 下即可达到较高分数,蓝色(MLM)则需要更多计算。右侧子图像是在更细尺度上比较不同步数的 RoBERTa/XLNet 等点位。图像传递的核心信息是:在同等计算预算下,目标函数设计会显著影响效率。
3.3 跨语言与统一预训练:XLM 与 UniLM
论文用图5说明 XLM 的两类目标:单语 MLM 与结合平行语料的 TLM(translation language modeling),其直觉是在预测被 mask 的词时允许跨语言互相对齐,从而学到共享表征。
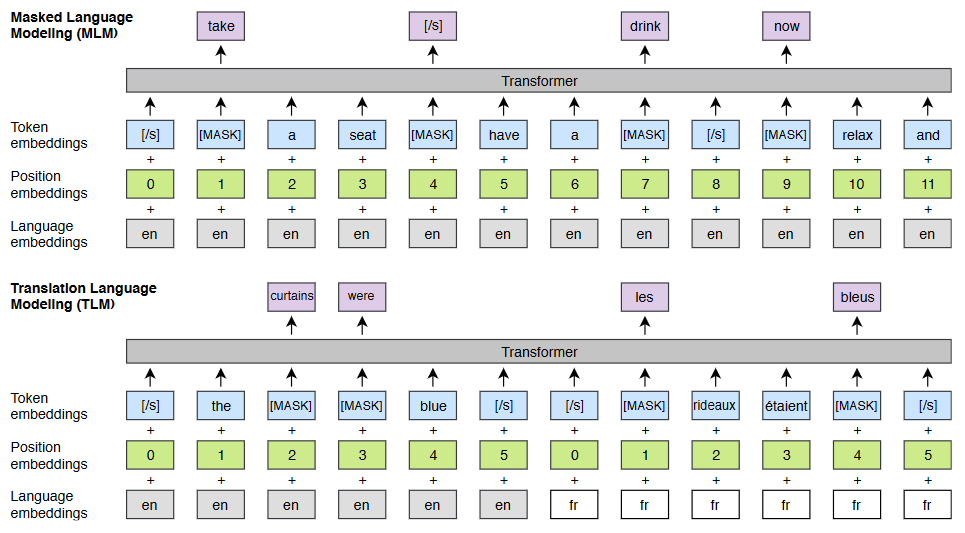
图5解读:图上半展示单语 MLM:同一语言序列中插入 MASK,模型在 Transformer 上下文中恢复 token;下半展示 TLM:把英法平行句拼接,mask 后预测时可同时 attend 两种语言,从而促使表示对齐。
论文用图6说明 UniLM 的统一思想:通过不同 self-attention mask,在同一 Transformer 中模拟双向 LM、左到右 LM 与 seq2seq LM,从而用一套参数覆盖理解与生成。
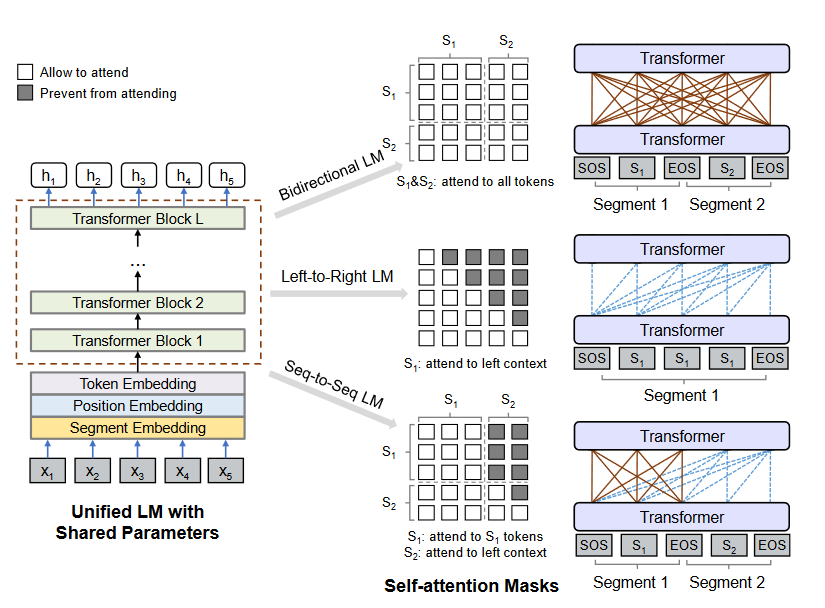
图6解读:图左是共享参数的统一 LM;图中三块展示三种 attention mask:双向 LM 允许全局可见,左到右 LM 只看左侧,seq2seq 在源段全局可见而目标段因果可见。右侧对应不同任务输入形式(两段文本、单段文本等)。
3.4 解码器模型:GPT 的自回归预训练与迁移
论文在 II-A 中强调 GPT-1/2 为后续 LLM(GPT-3/4)奠基,其关键范式是 decoder-only Transformer 的"生成式预训练 + 任务微调"。
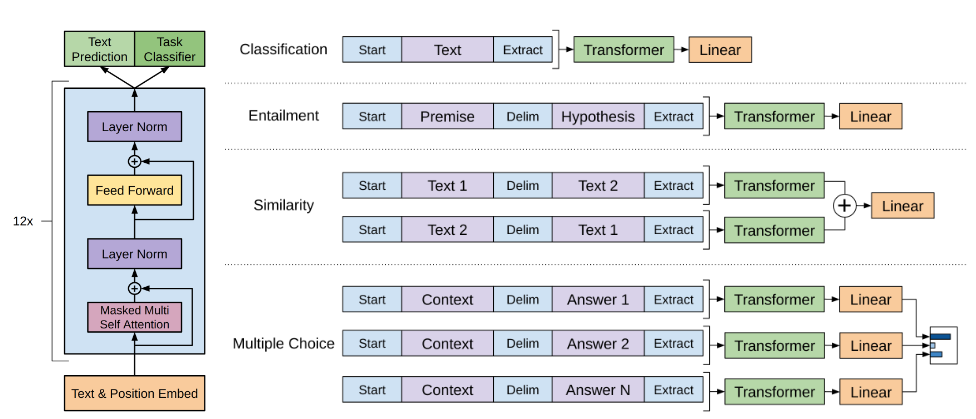
图7解读:左侧是 GPT 结构块(mask self-attention + FFN + LayerNorm 等堆叠),右侧展示把不同任务"拼接成序列"后用同一模型处理:分类、蕴含、相似度、多选题等都被转写为"输入 + 特殊分隔符 + 输出候选"的形式。它体现了自回归模型通过 prompt 统一任务接口的可能性。
自回归预训练目标在原文中以 log-likelihood 形式出现,其标准写法是:
maxθlogpθ(x1:T)=maxθ∑t=1Tlogpθ(xt∣x<t). \max_\theta \log p_\theta(x_{1:T}) = \max_\theta \sum_{t=1}^{T}\log p_\theta(x_t\mid x_{<t}). θmaxlogpθ(x1:T)=θmaxt=1∑Tlogpθ(xt∣x<t).
令 zt∈R∣V∣z_t\in\mathbb{R}^{|V|}zt∈R∣V∣ 为位置 ttt 的 logits,则
pθ(xt=v∣x<t)=exp(zt,v)∑u∈Vexp(zt,u), p_\theta(x_t=v\mid x_{<t})=\frac{\exp(z_{t,v})}{\sum_{u\in V}\exp(z_{t,u})}, pθ(xt=v∣x<t)=∑u∈Vexp(zt,u)exp(zt,v),
从而最常用的 token 级交叉熵损失为
L∗CLM(θ)=−∑∗t=1Tlogpθ(xt∣x<t). \mathcal{L}*{\text{CLM}}(\theta)= -\sum*{t=1}^{T}\log p_\theta(x_t\mid x_{<t}). L∗CLM(θ)=−∑∗t=1Tlogpθ(xt∣x<t).
(这正是"下一 token 预测"的数学化表达,也是论文在预训练部分强调的 decoder-only 主线。)
4. 三大 LLM 家族与代表模型:从"模型谱系"看关键技术路线
论文在 II-B 以 GPT、LLaMA、PaLM 三条主线组织"最具代表性的 LLM 家族",并用图8把它们的谱系关系可视化;同时在 II-C 以若干代表模型说明重要技术支线(指令微调、检索增强、MoE、开源权重、对话对齐等)。
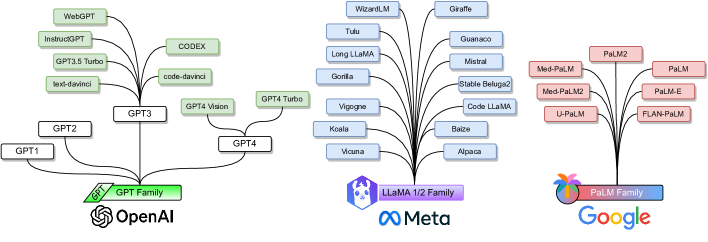
图8解读:图像把三大阵营并排画成"族谱树"。左侧是 OpenAI 的 GPT 系列(GPT-1/2/3/4 与 InstructGPT、ChatGPT、CodeX 等分支),中间是 Meta 的 LLaMA 生态(LLaMA、LLaMA-2 及大量衍生指令/对话模型),右侧是 Google 的 PaLM 系列(PaLM、PaLM2、Med-PaLM、Flan-PaLM 等)。该图的重点并非穷举,而是突出"预训练基座 + 对齐/领域适配分支"的演化模式。
4.1 GPT 家族:从规模到涌现,再到 RLHF 驱动的对齐
论文把 GPT-3 视为 LLM 关键节点之一,并特别强调 in-context learning(ICL):模型在不更新参数的情况下,通过上下文示例"像是在学习"。图9用曲线把这一现象的规模效应展示得很直观:示例数 KKK 增大时准确率上升,且大模型(175B)上升更显著。
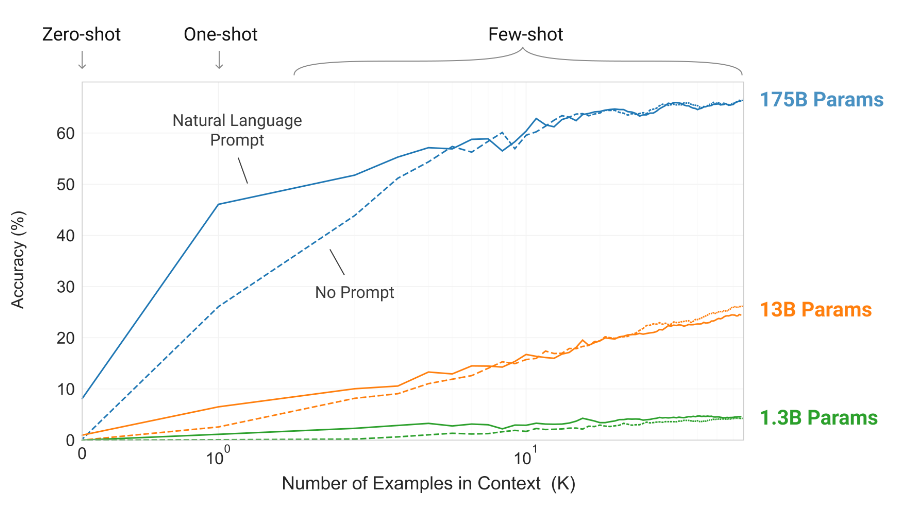
图9解读 :横轴是上下文示例数 KKK(从 zero-shot、one-shot 到 few-shot),纵轴是准确率;同一任务下有"Natural Language Prompt"与"No Prompt"的曲线对比,并分别画出 1.3B/13B/175B 的模型曲线。图像传达的实质结论是:提示不仅提供任务描述,更提供"输入---输出映射"的条件化结构,而大模型更能利用这种条件信息。
对齐方面,论文用图10概括 RLHF 三阶段:先收集示范数据做监督微调(SFT),再收集比较数据训练奖励模型(RM),最后用强化学习(如 PPO)优化策略模型,使输出符合偏好。
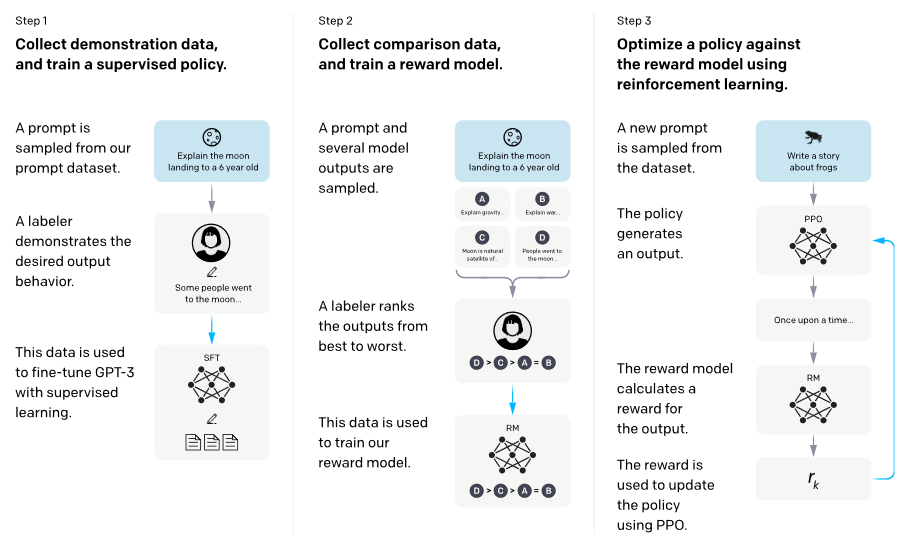
图10解读 :三列分别标注 Step 1/2/3。Step 1 展示标注者给出理想回答用于 SFT;Step 2 展示对同一 prompt 采样多个回答并排序用于训练 RM;Step 3 展示 PPO 迭代:策略生成输出,RM 给出奖励 rkr_krk,用奖励更新策略。该图强调"偏好信号"是对齐的核心数据源。
GPT-4 的能力提升在论文中通过考试型基准的分布图展示(图11)。需要强调的是,这类图更像"可量化的能力剖面",它证明的是"在这些基准上,系统性能整体右移",而非宣称模型具有人类式理解。
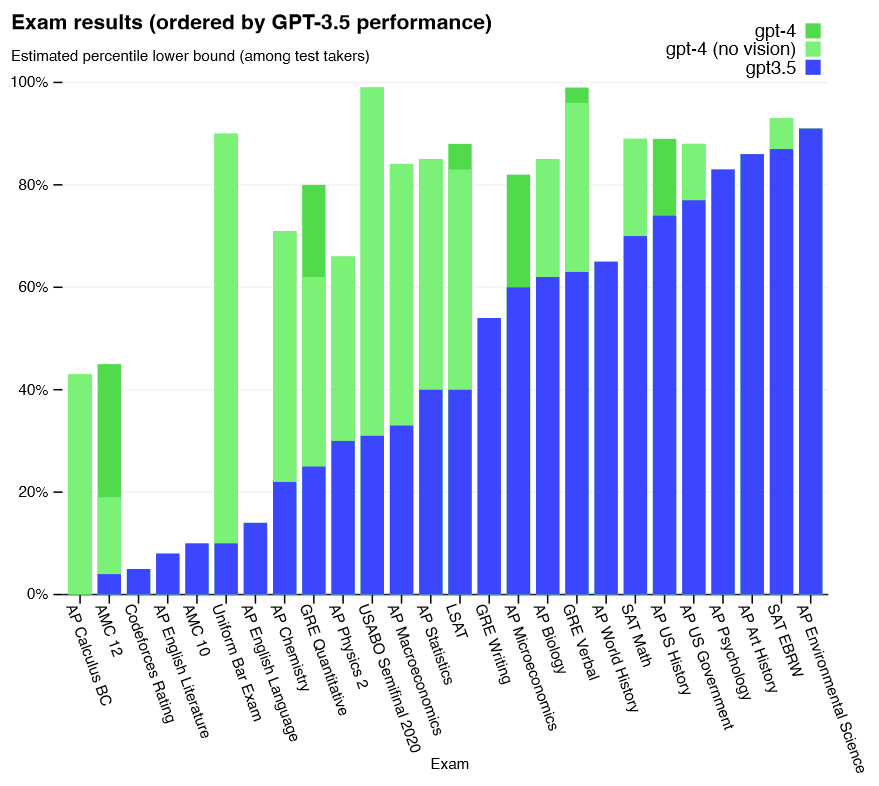
图11解读:柱状条按"GPT-3.5 表现排序"的考试类别排列,蓝色代表 GPT-3.5,绿色代表 GPT-4(无视觉)。多数条形绿色部分显著高于蓝色,表示 GPT-4 在多个考试上分位数更高。
4.2 LLaMA 家族:开放权重、生态扩散与对话对齐流水线
论文强调 LLaMA 系列的重要性在于"开源/开放权重推动研究与应用生态"。图12给出 LLaMA-2 Chat 的训练管线:预训练得到 base 模型,再经 SFT 与 RLHF 形成 chat 模型,并区分 helpful 与 safety reward 的建模。
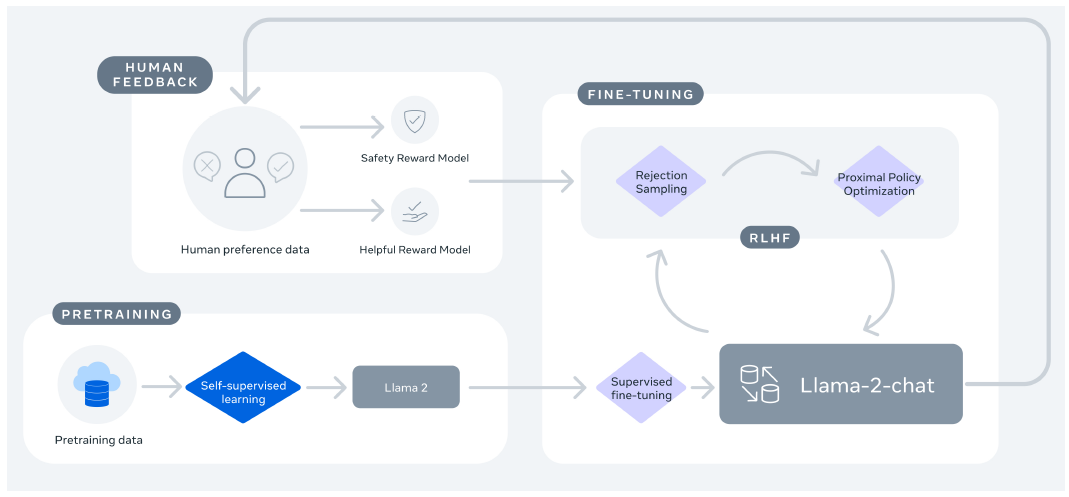
图12解读:图左下角是预训练数据到 Llama 2;右侧是 fine-tuning 区,包含 supervised fine-tuning 与 RLHF 环路,RLHF 中又出现 rejection sampling 与 PPO。左上角的人类偏好数据被分流到 Safety RM 与 Helpful RM,说明对齐既包括"有用性"也包括"安全性"。
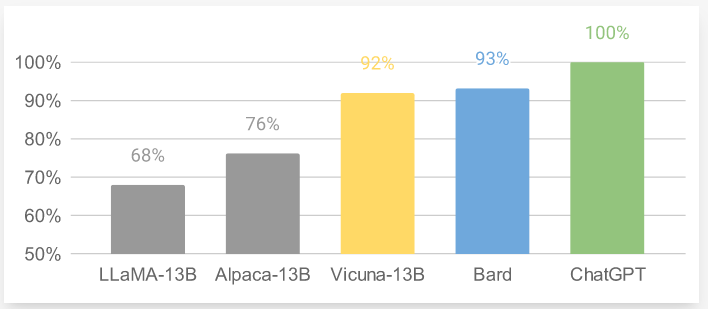
开源对话模型的可用性对比在图13中被直观展示(以 GPT-4 作为评估者的相对分数为例):Vicuna-13B 的柱形明显高于早期 Alpaca/LLaMA-13B,接近闭源对话系统的体验层级。
4.3 PaLM 家族:Pathways 规模化训练与大规模指令微调
论文介绍 PaLM 的规模化训练背景(Pathways + TPU)以及后续 U-PaLM、Flan-PaLM 的"持续训练 + 指令微调 + CoT 数据"路线,并用图14展示 Flan-PaLM 微调任务的覆盖面:473 个数据集被归入多个任务组。
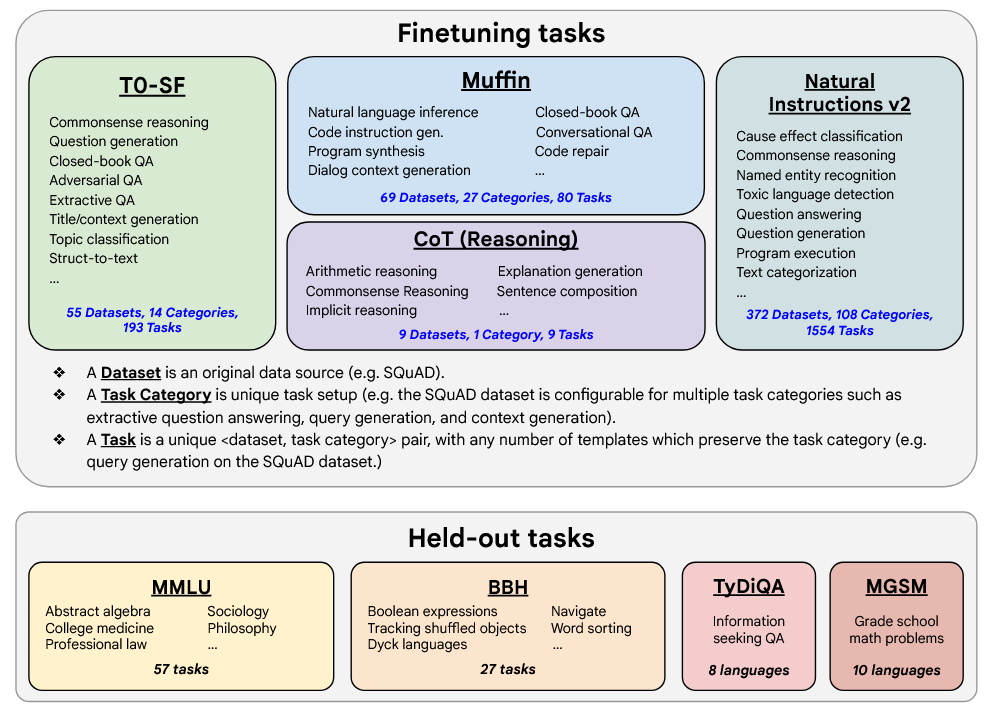
图14解读:图中把微调任务分成多个大盒子(如自然指令、CoT 推理、不同任务集合),并把 held-out tasks(如 MMLU、BBH、TyDiQA、MGSM)列在底部,强调"训练任务多样性"与"泛化评测"之间的对应关系。
4.4 其他代表模型:把"关键技术分支"显式化
论文在 II-C 选择了一组代表模型,用来说明 LLM 发展中最重要的技术分支:指令微调范式(FLAN/T0)、规模与超参系统研究(Gopher/Chinchilla)、知识增强与检索增强(ERNIE/RETRO)、稀疏专家模型(GLaM)、开源大模型与长上下文(OPT/BLOOM)、对话安全闭环(Sparrow)、统一预训练目标(UL2)等。
图15用"预训练-微调""提示""指令微调"三种范式并列,指出 instruction tuning 的核心优势在于:同一模型通过多任务指令数据获得更强的零样本/泛化能力。
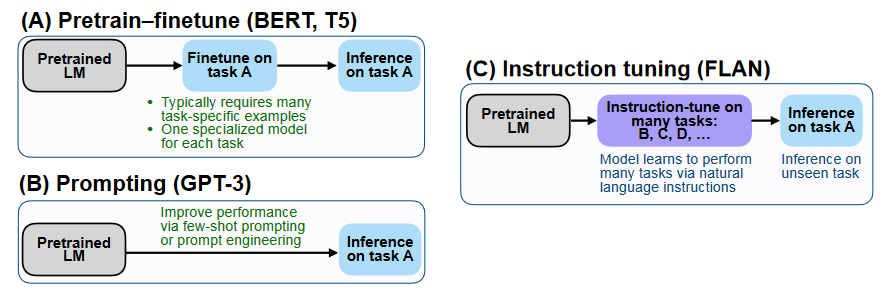
图17强调 ERNIE 3.0 把大规模文本与知识图谱纳入统一框架,并在结构上融合 auto-regressive 与 auto-encoding 网络,以兼顾理解与生成。
图18展示 RETRO 的检索增强架构:冻结的检索器(如 BERT)在外部库中检索邻居片段,编码后通过 chunked cross-attention(CCA)注入到生成过程,从而在不等比例增加参数的情况下"引入更大外部记忆"。
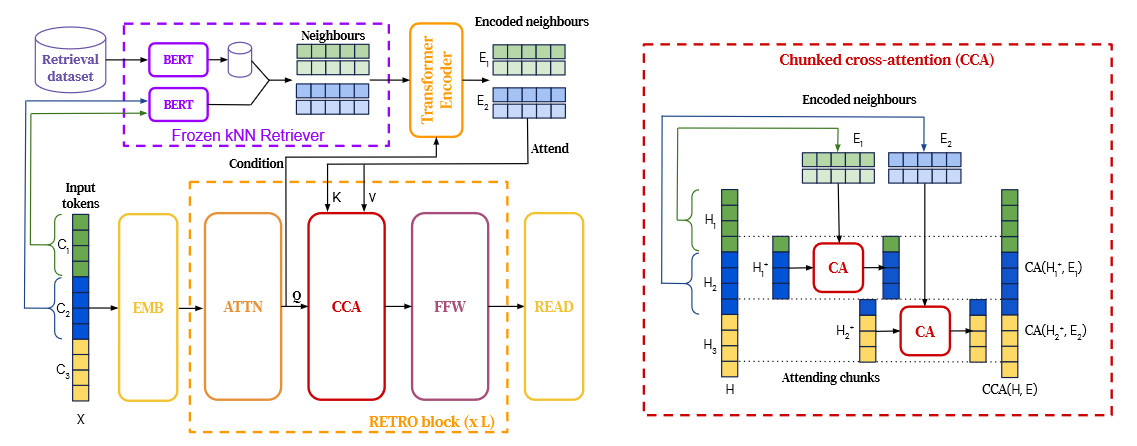
图19展示 GLaM 的 MoE 层:通过 gating 选择少数专家 FFN 激活,使"参数容量"与"计算量"解耦。
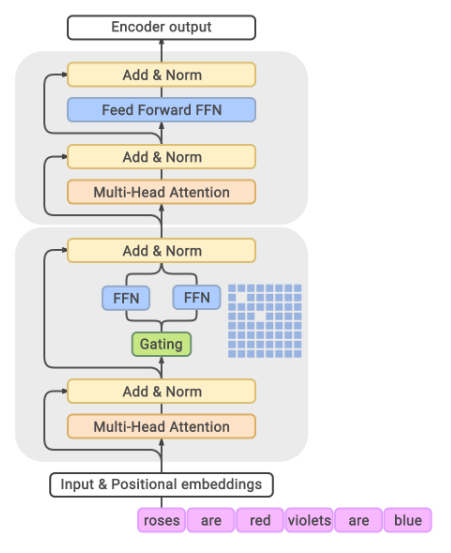
图20给出 OPT 不同规模模型的结构超参(层数、头数、dmodeld_{\text{model}}dmodel、学习率、batch 等),其意义在于把"可复现的开源训练配方"显式化。
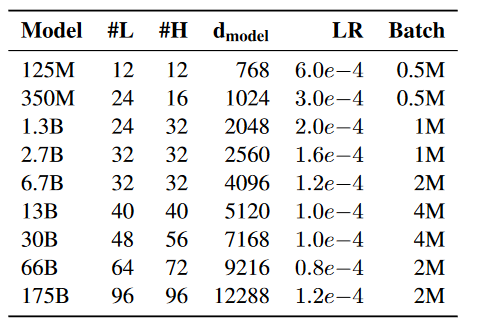
图21把 Sparrow 的对齐框架画成"人类参与的持续闭环":偏好奖励与规则奖励共同驱动强化学习,目标是更 helpful、correct、harmless。
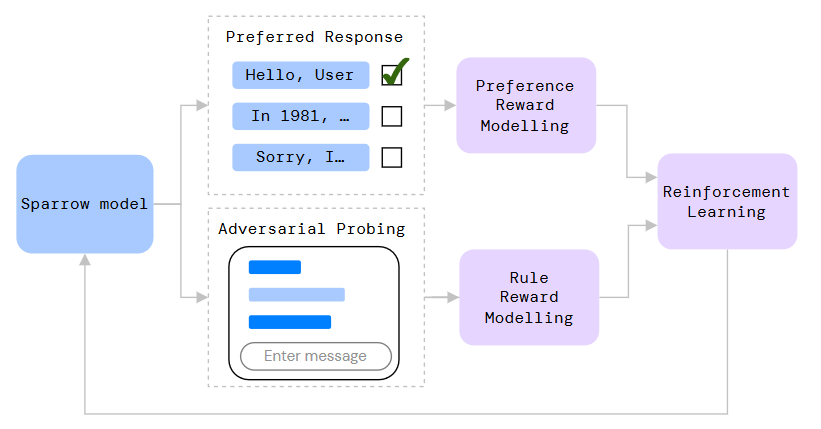
图22展示 UL2 的 mixture-of-denoisers:不同"去噪器"对应不同腐蚀方式与跨度,从而统一多种学习范式与任务范式。
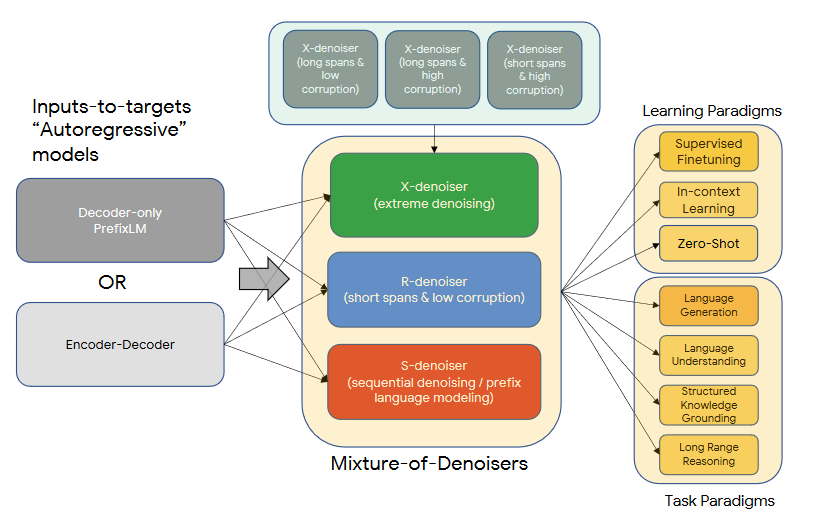
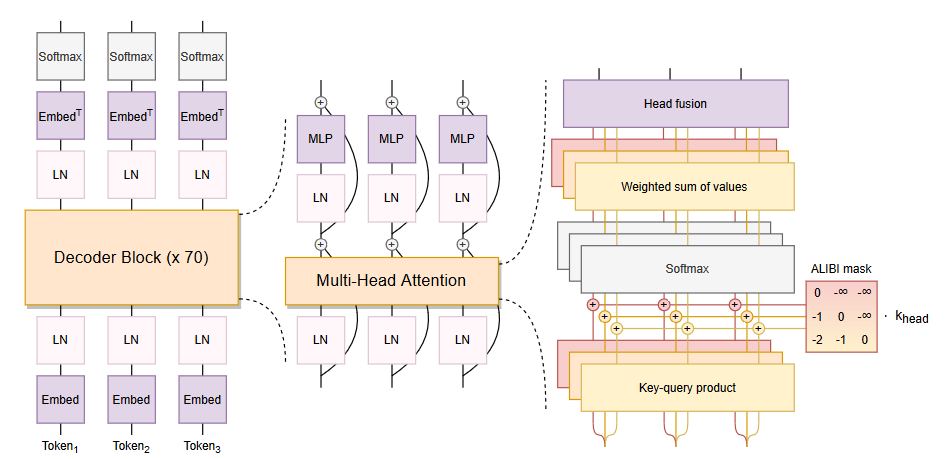
图23展示 BLOOM 的 decoder-only 架构与注意力细节,并在右侧显式标出 ALiBi mask 等长上下文相关机制。
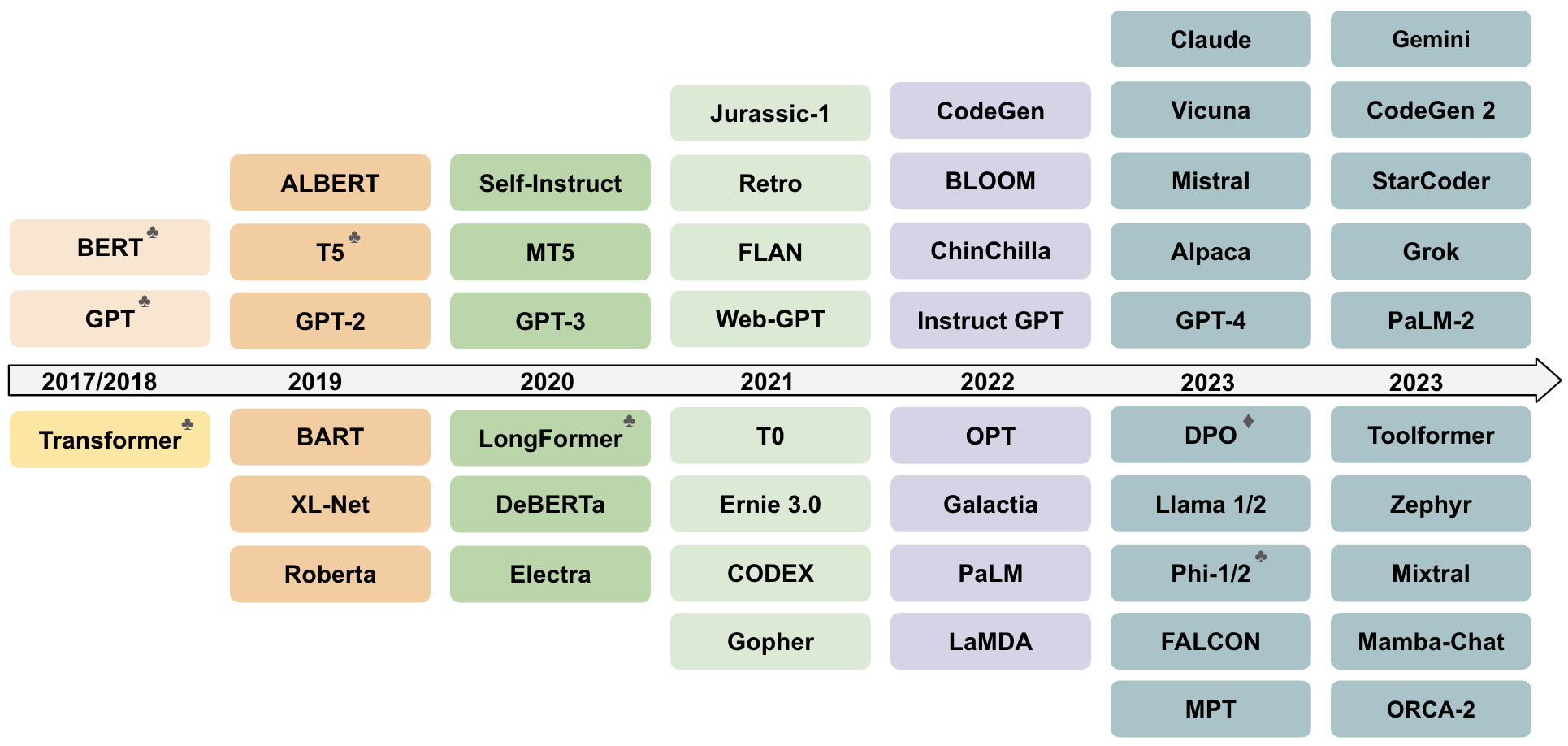
最后,图24给出"代表模型与关键工作"的时间线式概览,强调 LLM 的演进是多条技术线并进:规模化、对齐、检索、MoE、开源、长上下文与系统增强在不同时间点交汇。
5. 如何构建 LLM:从"组件图"到可落地的数学与工程细节(III)
5.1 构建流程的系统视角:数据→分词→预训练→指令微调→对齐
论文在 III 章用图25把构建流程拆为多个可控模块:数据准备(收集、清洗、去重)、tokenization、预训练、指令微调与对齐。
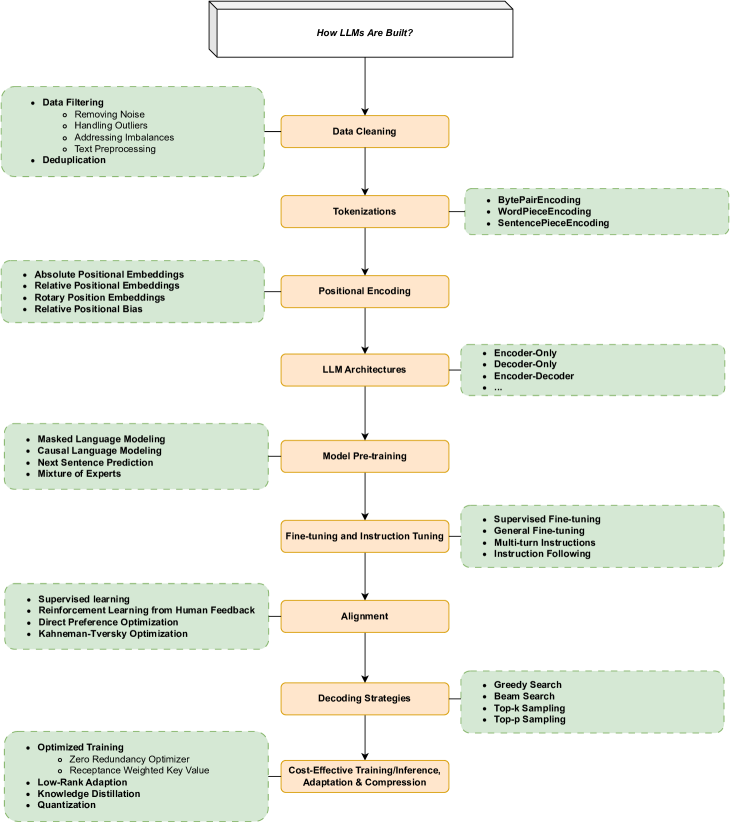
图25解读:图像像"工程流程图",把训练 LLM 的关键部件串成链条:从数据到 tokenization,再到预训练目标与对齐方法,并暗示后续还要接解码策略与效率优化。它隐含的指导原则是:能力与错误往往可以回溯到流程中的具体环节。
5.2 Transformer:注意力的数学形式与多头机制
论文在 III-A 回顾 Transformer,并用图26给出其上层结构。
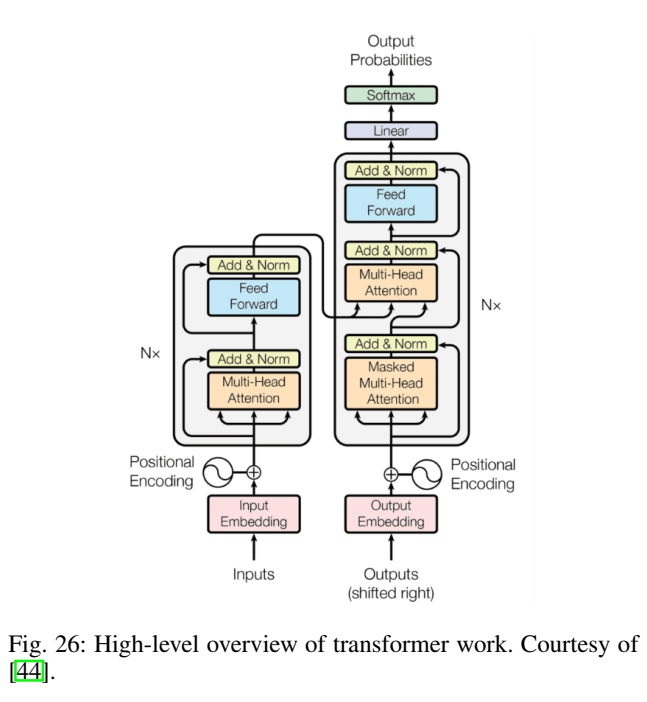
图26解读:图像展示 encoder/decoder 堆叠结构,核心模块是 multi-head attention 与 position-wise FFN,并通过残差与归一化稳定训练。它把 Transformer 的"并行可扩展性"显式呈现出来:自注意力在一个层内可以对所有位置同时计算。
注意力机制可用标准的 scaled dot-product 形式写为:
Att(Q,K,V)=softmax!(QK⊤dk)V, \mathrm{Att}(Q,K,V)=\mathrm{softmax}!\left(\frac{QK^\top}{\sqrt{d_k}}\right)V, Att(Q,K,V)=softmax!(dk QK⊤)V,
其中 Q=XWQ, K=XWK, V=XWVQ=XW_Q,\ K=XW_K,\ V=XW_VQ=XWQ, K=XWK, V=XWV,dkd_kdk 是 key 的维度。多头注意力把表示空间拆成 hhh 个子空间并并行计算:
MHA(X)=Concat(Att1,...,Atth)WO. \mathrm{MHA}(X)=\mathrm{Concat}(\mathrm{Att}_1,\dots,\mathrm{Att}_h)W_O. MHA(X)=Concat(Att1,...,Atth)WO.
从概率视角,softmax 输出可被理解为对"把信息从哪个位置取回来"的离散分布;从优化视角,dk\sqrt{d_k}dk 的缩放用于避免 QK⊤QK^\topQK⊤ 随维度增大而数值爆炸,从而让 softmax 梯度更稳定。
5.3 数据清洗:改变训练分布的"漏斗效应"
论文在 III-B 强调数据质量与过滤、去重对性能的决定性影响,并以 Falcon40B 的 RefinedWeb 过滤流程为例说明:大规模网页数据经过多阶段过滤会被大幅削减,但留下的数据更高质量、更一致。
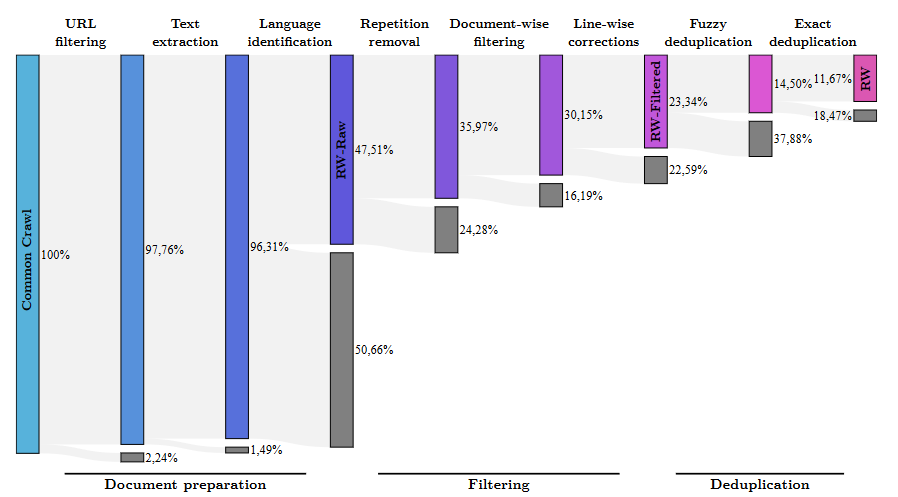
图27解读 :这是一个多级漏斗图,展示 CommonCrawl 文档在若干过滤器(规则、模型判别、去重等)后保留比例急剧下降,最终得到高质量子集。图像传达的要点是:训练分布 ptrain(x)p_{\text{train}}(x)ptrain(x) 并非"原始互联网分布",而是被工程化重塑后的分布,这会直接改变模型学到的先验偏好。
5.4 Tokenization:BPE/WordPiece/SentencePiece 的共同目标
论文在 tokenization 小节强调子词方法的核心作用:在控制词表规模的同时处理 OOV、提升跨域/跨语言泛化。
以 BPE 的"频繁对合并"为例,其迭代可抽象为:在当前符号表 V\mathcal{V}V 与语料统计 C(⋅)C(\cdot)C(⋅) 下选取频数最大的相邻对 (a,b)(a,b)(a,b) 合并为新符号 ababab。若用极简形式表示:
(a∗,b∗)=argmax(a,b)C(a,b),V←V∪ab. (a^*,b^*)=\arg\max_{(a,b)} C(a,b),\qquad \mathcal{V}\leftarrow \mathcal{V}\cup{ab}. (a∗,b∗)=arg(a,b)maxC(a,b),V←V∪ab.
这种机制的统计意义在于:把高频字符串"凝结"为稳定 token,使模型更容易学习词形与语义,而把低频词拆为可复用的子结构,降低稀疏性。
5.5 位置编码:把"顺序"注入注意力相似度(图28)
论文并列介绍绝对位置嵌入、相对位置嵌入、RoPE 与相对位置偏置(如 ALiBi),并用图28把四者放在同一张图中对比。
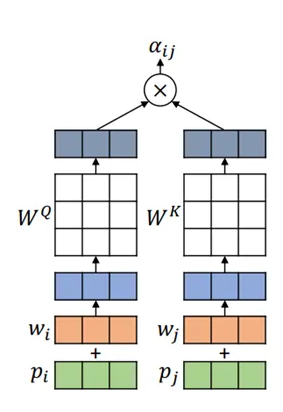
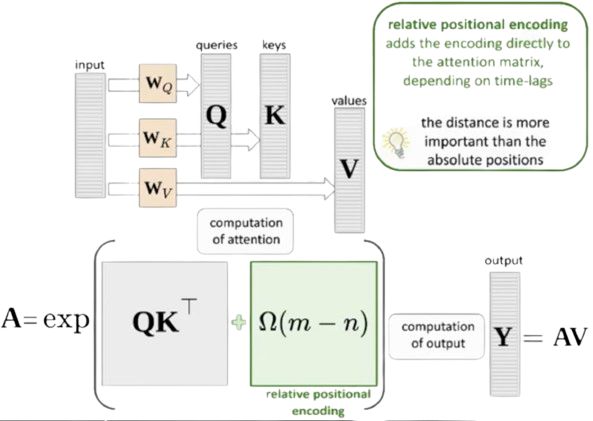
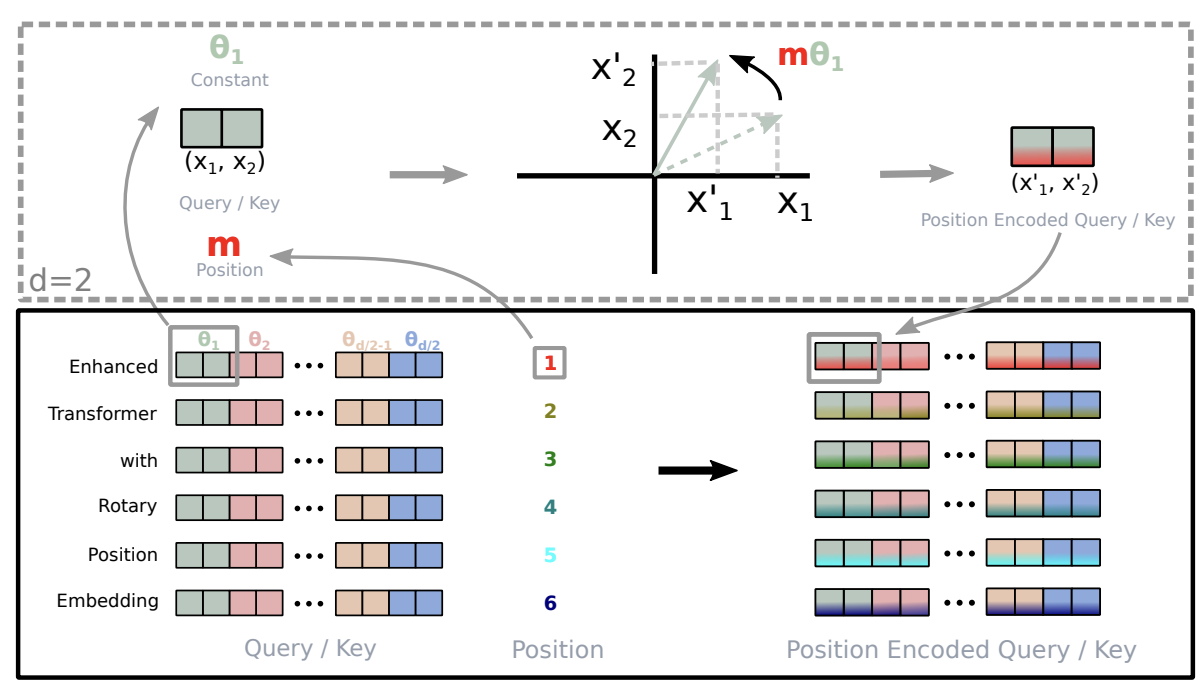

图28解读:四张子图分别对应四种把位置信息引入注意力的方式。APE 是把位置向量直接加到 token embedding;RPE 是在注意力打分中显式加入相对距离项;RoPE 用旋转变换把位置编码到 query/key 的几何结构里;ALiBi 则以线性偏置惩罚远距离注意力。整体信息是:长上下文能力不仅取决于模型规模,也高度取决于位置机制的"外推性"。
在数学上,正弦位置编码(经典 Transformer 版本)常写为:
PE(pos,2i)=sin!(pos100002i/d),PE(pos,2i+1)=cos!(pos100002i/d). \mathrm{PE}(pos,2i)=\sin!\left(\frac{pos}{10000^{2i/d}}\right),\qquad \mathrm{PE}(pos,2i+1)=\cos!\left(\frac{pos}{10000^{2i/d}}\right). PE(pos,2i)=sin!(100002i/dpos),PE(pos,2i+1)=cos!(100002i/dpos).
ALiBi 的思想可概括为:对注意力分数加入与距离成比例的偏置,设 sij=qi⊤kjdks_{ij}=\frac{q_i^\top k_j}{\sqrt{d_k}}sij=dk qi⊤kj,则
s~∗ij=s∗ij−m⋅(i−j), \tilde{s}*{ij}=s*{ij}-m\cdot (i-j), s~∗ij=s∗ij−m⋅(i−j),
其中 m>0m>0m>0(可按 head 设定),使得越远的历史位置越难被关注,从而在长长度上更稳健外推。
5.6 稀疏专家模型:MoE 把"参数容量"与"计算量"解耦(图29)
论文在预训练技术中强调 MoE,并用图29(Switch Transformer)展示把 dense FFN 替换为 switch FFN 的方式。
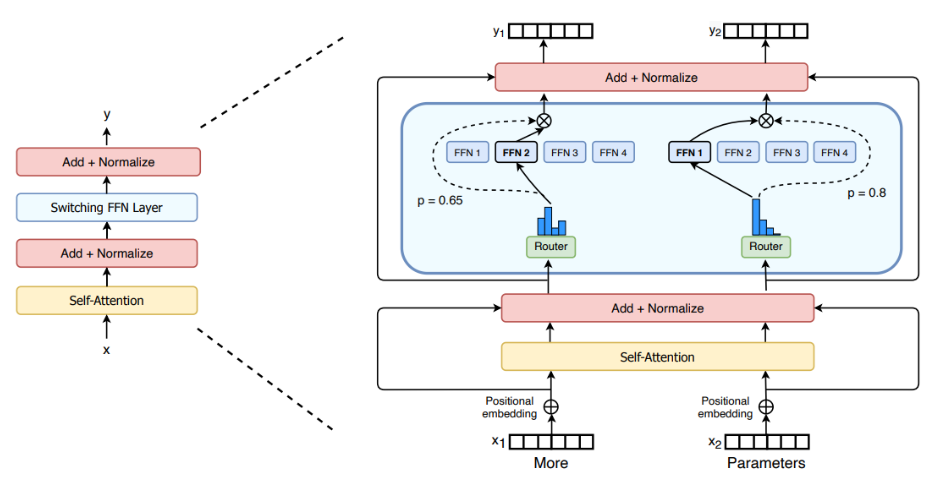
图29解读:图中把标准 Transformer block 与含 MoE 的 block 并列,突出差异发生在 FFN:MoE 有多个"专家 FFN",路由器(router)为每个 token 选择少数专家激活。图像直观表达了"稀疏激活"的节省:参数多,但每步只算一小部分。
MoE 的路由可写为:
p(e∣h)=softmax(Wrh)e, p(e\mid h)=\mathrm{softmax}(W_r h)_e, p(e∣h)=softmax(Wrh)e,
Top-kkk 激活的输出:
MoE(h)=∑e∈Top-kp(e∣h),fe(h). \mathrm{MoE}(h)=\sum_{e\in \text{Top-}k} p(e\mid h), f_e(h). MoE(h)=e∈Top-k∑p(e∣h),fe(h).
实际系统中还常加入负载均衡项,防止路由塌缩到少数专家(附录将给出一种常见形式)。
5.7 对齐新趋势:DPO 与 KTO(图30、图31)
论文在对齐部分指出 RLHF 的有效性与复杂性并存,近年来出现了更直接的偏好优化方法;并用图30、图31分别展示 DPO 与 KTO 的动机与流程。
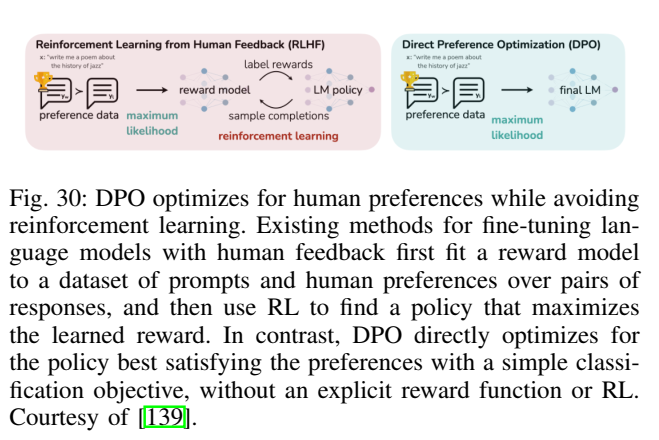
图30解读:图像把 RLHF 管线(需要奖励模型与 RL 优化)与 DPO(直接用偏好对做目标优化)对比,强调 DPO 试图减少系统组件,使训练更稳定、更易实现。
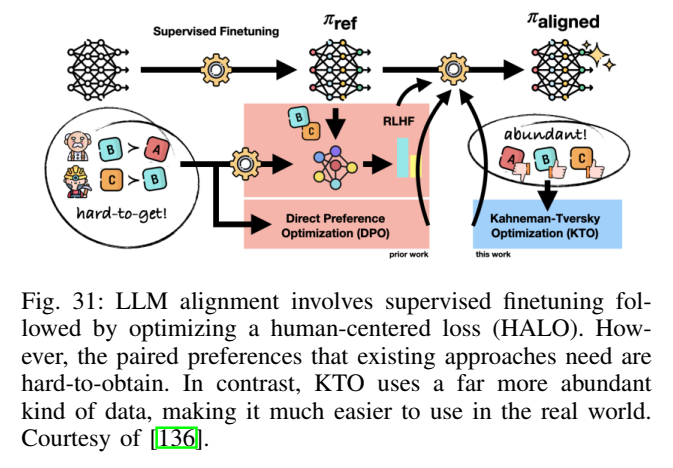
图31解读:图像呈现 KTO 的思路:相较需要"成对偏好"(chosen vs rejected)的 DPO/RLHF,KTO 强调用更易获得的单样本反馈信号进行对齐,从而降低数据采集成本。
正文中我们将给出 DPO 的标准数学形式(源自偏好建模),并在附录把"从偏好概率模型到 DPO 损失"的推导补全,使其与图30的直觉对应。
5.8 解码策略:温度 softmax 与采样控制
论文在解码部分给出温度 softmax 形式(用于控制输出随机性)。其标准写法为:
softmaxT(zi)=ezi/T∑jezj/T. \mathrm{softmax}_T(z_i)=\frac{e^{z_i/T}}{\sum_j e^{z_j/T}}. softmaxT(zi)=∑jezj/Tezi/T.
当 T→0+T\to 0^+T→0+,分布趋于 argmax\arg\maxargmax(近似贪心);当 TTT 变大,分布更平坦、熵更高。论文同时讨论了 top-kkk 与 top-ppp(nucleus sampling)等截断采样策略,这可被理解为在集合 S\mathcal{S}S 上做条件化重归一:
pS(v)=p(v∣v∈S)=p(v)∑u∈Sp(u). p_{\mathcal{S}}(v)=p(v\mid v\in\mathcal{S})=\frac{p(v)}{\sum_{u\in\mathcal{S}}p(u)}. pS(v)=p(v∣v∈S)=∑u∈Sp(u)p(v).
5.9 成本优化:RWKV、复杂度对比、LoRA 与蒸馏(图32--图35)
论文在效率章节提到非 Transformer 的 LLM(如 RWKV)以及复杂度对比,并给出 LoRA 与蒸馏的示意图。
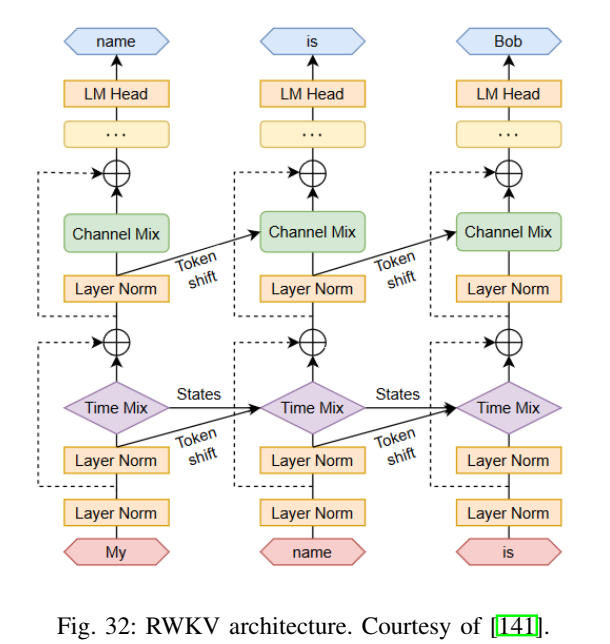
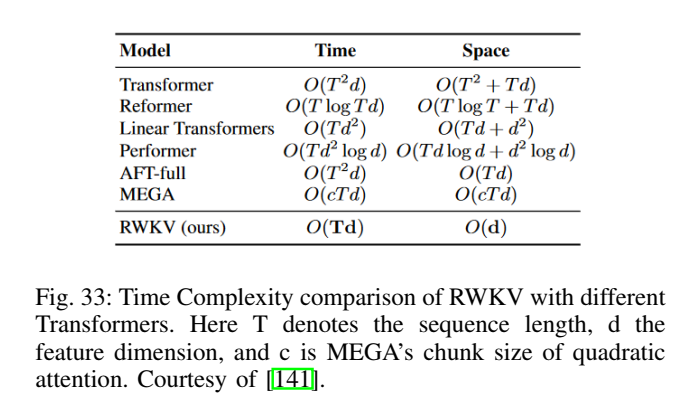
图32--33解读 :图32强调 RWKV 试图在序列建模中融合 RNN 风格的递推与 Transformer 的表达优势;图33则以表格/坐标形式对比不同架构对序列长度 TTT 的复杂度(典型自注意力为 O(T2)O(T^2)O(T2)),突出长上下文场景下"复杂度结构"本身就是性能与成本的瓶颈。
论文重点介绍 LoRA(低秩适配)并在图34形象说明"冻结大模型权重,仅训练低秩增量"。
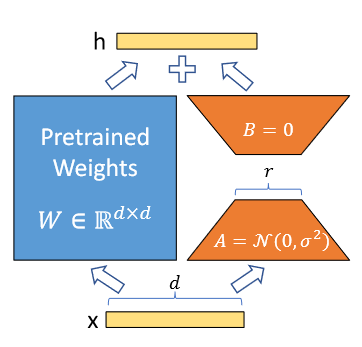
在数学上,设预训练权重为 W0∈Rd×kW_0\in\mathbb{R}^{d\times k}W0∈Rd×k,LoRA 将微调增量约束为秩 rrr 的分解:
W=W0+ΔW,ΔW=BA,B∈Rd×r, A∈Rr×k, r≪min(d,k). W = W_0+\Delta W,\qquad \Delta W = BA,\quad B\in\mathbb{R}^{d\times r},\ A\in\mathbb{R}^{r\times k},\ r\ll \min(d,k). W=W0+ΔW,ΔW=BA,B∈Rd×r, A∈Rr×k, r≪min(d,k).
对输入 x∈Rkx\in\mathbb{R}^{k}x∈Rk,前向为:
h=Wx=W0x+BAx. h = W x = W_0x + BAx. h=Wx=W0x+BAx.
其新增参数量为 r(d+k)r(d+k)r(d+k),远小于原始 dkdkdk,解释了论文强调的"参数高效微调"。
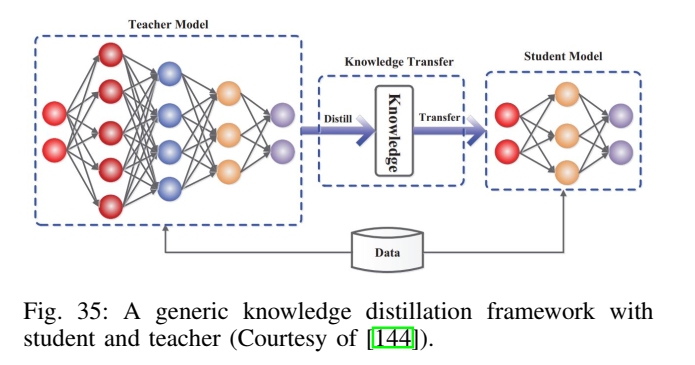
蒸馏框架在图35中被总结为 teacher--student:teacher 输出软目标,student 学习模仿以获得更小模型。
6. 如何使用与增强:Prompt、RAG、工具与 Agent(IV)
论文在 IV 章的核心观点是:LLM 本质上是静态的条件生成模型,而现实系统需要动态信息、可控性与可验证性;因此必须用 prompt 工程、检索增强(RAG)、外部工具与 agent 框架把模型嵌入闭环。总览图36把这些主题整合到同一张系统图中。
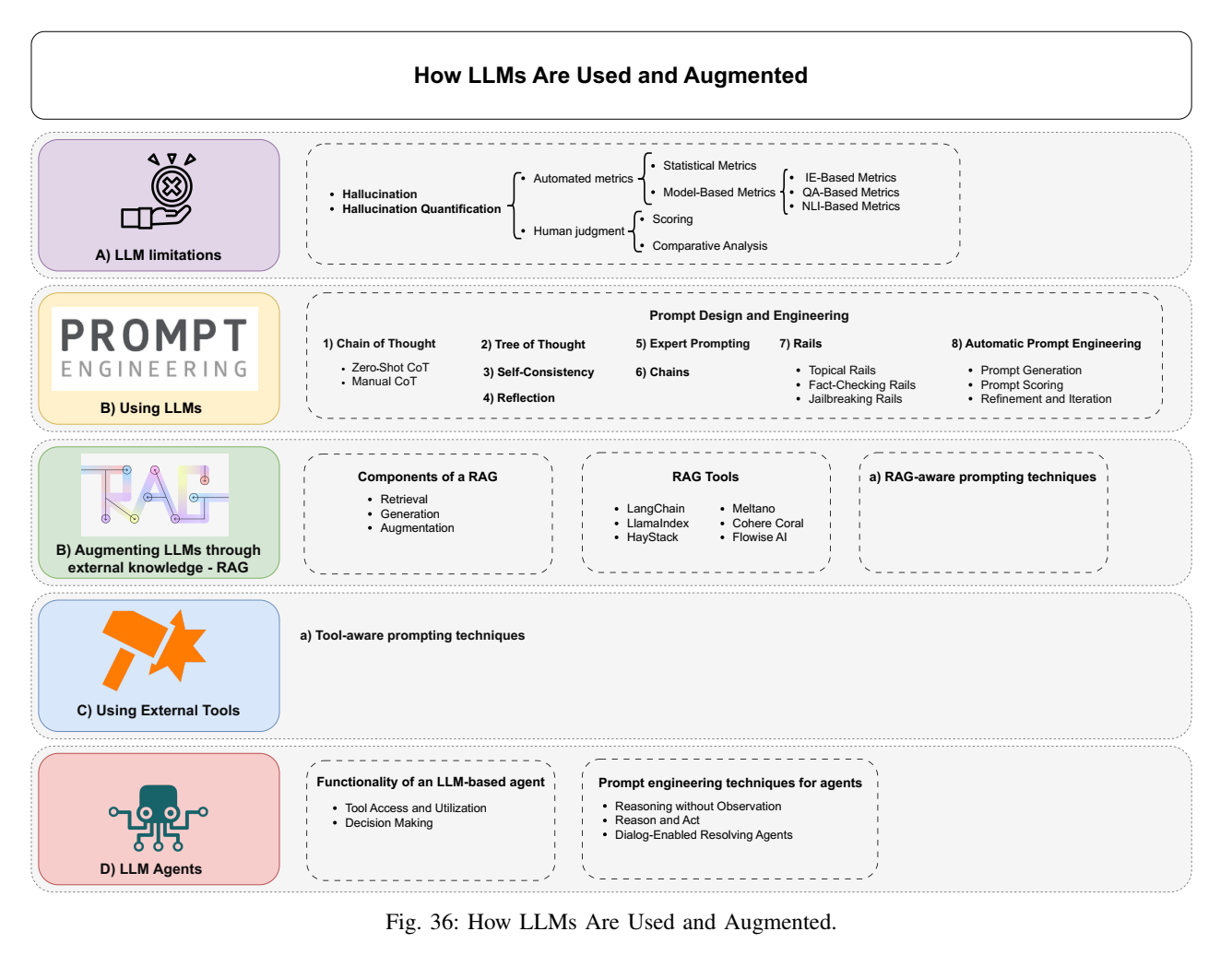
图36解读:图像把四类内容并列:其一是 LLM 局限与幻觉评估;其二是提示工程方法簇(CoT/ToT/自一致性/反思/自动提示生成等);其三是 RAG(检索---增强---生成)及其工具链;其四是外部工具与 agent 系统(规划、执行、记忆、反馈)。图像隐含一个实践准则:可靠系统往往是"模型 + 结构化外部组件"的组合。
6.1 提示工程:把"任务条件"显式注入 pθ(y∣x)p_\theta(y\mid x)pθ(y∣x)
论文在提示工程部分提到 CoT(chain-of-thought)、ToT(tree-of-thought)、self-consistency、reflection、APE(automatic prompt engineering)等方法,其共同点是:不改变参数,而是通过改变条件输入 xxx 的结构,让模型在条件分布 pθ(y∣x)p_\theta(y\mid x)pθ(y∣x) 上落入更可控/更具推理性的区域。
用一个统一表述可以把提示工程理解为"条件化重写":设原始输入为 xxx,经提示模板 π(⋅)\pi(\cdot)π(⋅) 变为 x′=π(x)x'=\pi(x)x′=π(x),则生成分布从 pθ(y∣x)p_\theta(y\mid x)pθ(y∣x) 变为 pθ(y∣x′)p_\theta(y\mid x')pθ(y∣x′)。CoT/ToT 的核心是让 x′x'x′ 强制包含中间推理结构,从而提高最终答案的可解释性与正确率(尽管中间文本并不等价于真实思维过程)。
6.2 RAG:把"外部知识"作为隐变量注入生成(图37、图38)
论文指出 LLM 的一个根本限制是知识可能过时或缺乏私域信息,RAG 因此成为关键增强范式。图37用问答场景画出了 RAG 的基本环路:从输入抽取 query,到外部知识源检索,再把检索结果拼到增强上下文中交给 LLM 生成。
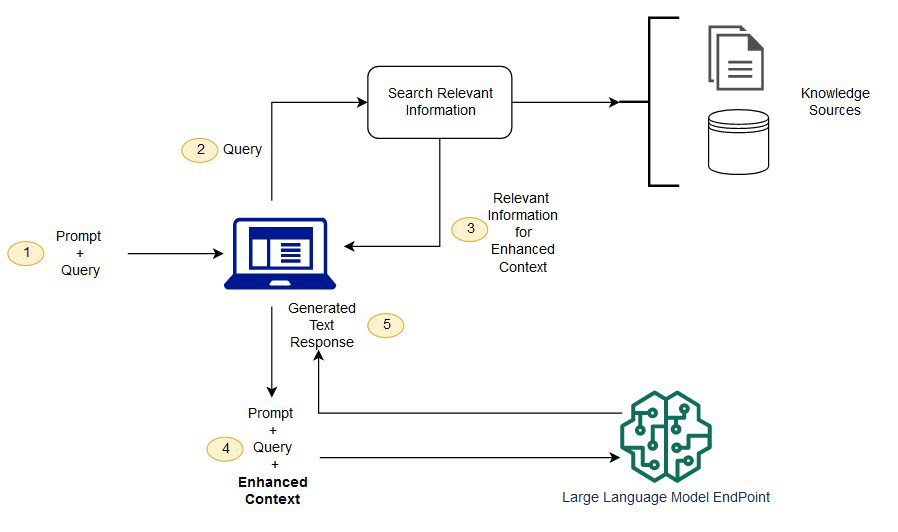
图37解读:图中用编号 1--5 标注步骤:1 输入 prompt+query;2 抽取 query;3 在知识源(文档库/数据库)检索相关信息;4 把检索片段加入增强上下文;5 LLM endpoint 生成最终回答。它强调检索不是一次性"查资料",而是生成过程的显式条件。
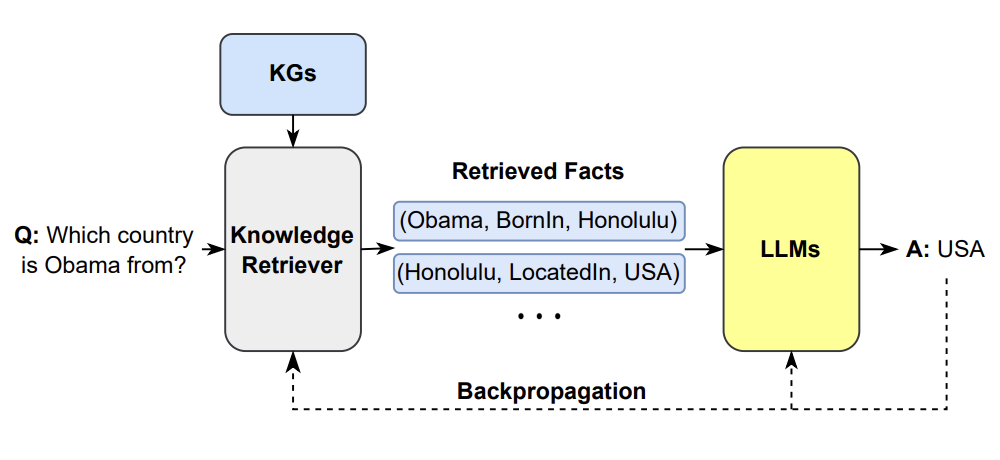
论文同时给出知识图谱作为 retriever 的示例(图38),说明"检索"不局限于文本库,也可以是结构化知识。
从概率角度,RAG 可以写成带隐变量 ddd(检索到的文档/证据)的条件生成:
p(y∣x)=∑dp(y∣x,d),p(d∣x). p(y\mid x)=\sum_{d} p(y\mid x,d),p(d\mid x). p(y∣x)=d∑p(y∣x,d),p(d∣x).
实际系统通常用 top-KKK 近似:
p(y∣x)≈∑d∈TopK(x)p(y∣x,d),p(d∣x), p(y\mid x)\approx \sum_{d\in \mathrm{TopK}(x)} p(y\mid x,d),p(d\mid x), p(y∣x)≈d∈TopK(x)∑p(y∣x,d),p(d∣x),
并且常进一步采用"拼接上下文"把 ddd 直接并入输入,从而用单次解码近似实现 p(y∣x,d)p(y\mid x,d)p(y∣x,d).(附录将对这一近似的统计含义做进一步解释。)
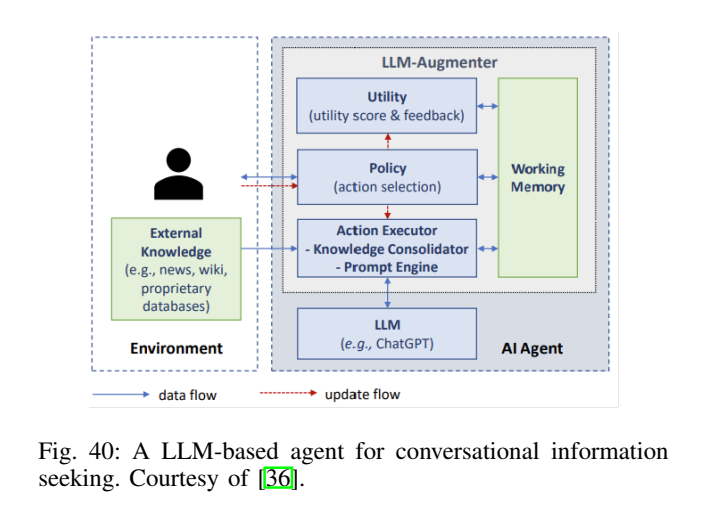
6.3 工具调用与 Agent:从"生成文本"走向"行动闭环"(图39、图40)
论文把工具(tools)视为 RAG 的一般化:不仅能检索信息,还能调用任意外部 API/函数,实现计算、执行、购买、控制等行动。进一步,把 LLM 放在包含记忆、策略、执行器、评估器的系统中,就得到 agent。
图39展示 HuggingGPT 的 agent 式工具编排:LLM 负责规划与调度,外部模型/工具完成具体子任务。
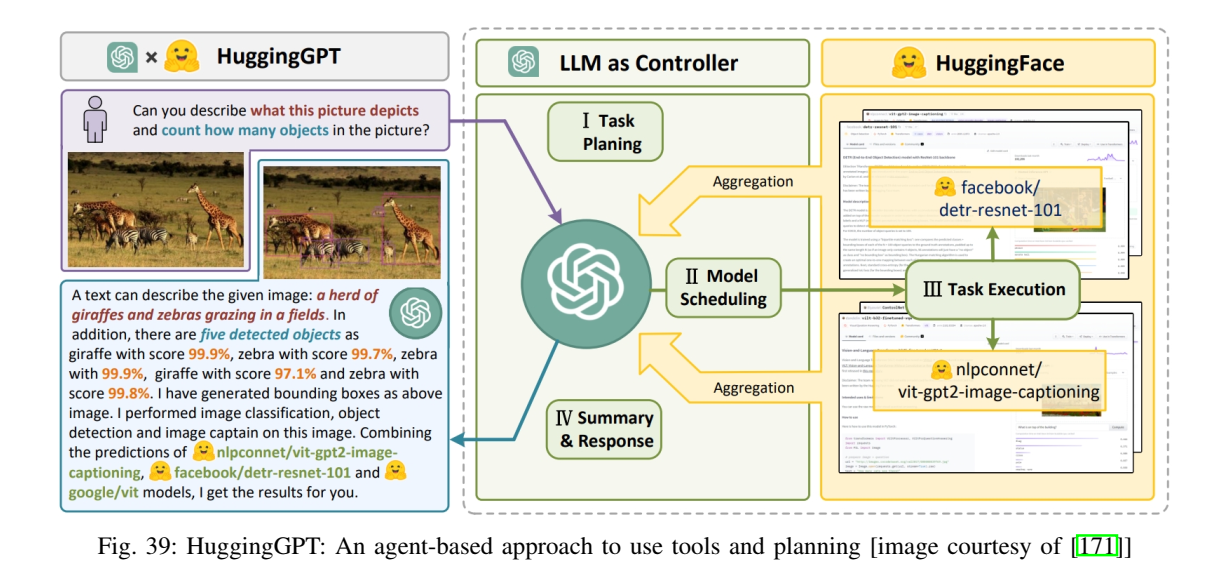
图40展示对话式信息检索 agent:工作记忆跟踪对话状态,policy 选择行动,executor 执行检索/生成,utility 模块评估对齐程度并反馈改进。
6.4 幻觉:定义、类型与评估困难
论文沿用主流定义,把幻觉视为"生成内容不忠于来源或不可证实",并区分内在幻觉(与给定来源冲突)与外在幻觉(无法核验)。同时,论文指出传统文本相似度指标(ROUGE、BLEU)更偏向表面匹配,难以覆盖事实一致性;模型判别式指标(如 BERTScore、NLI/QA-based 指标)虽然更语义化,但引入"用模型评估模型"的误差链。
7. 数据集与评测:能力导向的基准组织(V--VI)
7.1 数据集的"应用分布"与"许可证分布"(图41、图42)
论文在 V 章强调:LLM 的应用已从传统 NLP 扩展到代码、金融等多领域,因此数据集也应按能力/应用维度分类。图41与图42分别从"应用类别"和"许可证"角度对数据集进行统计式概览。
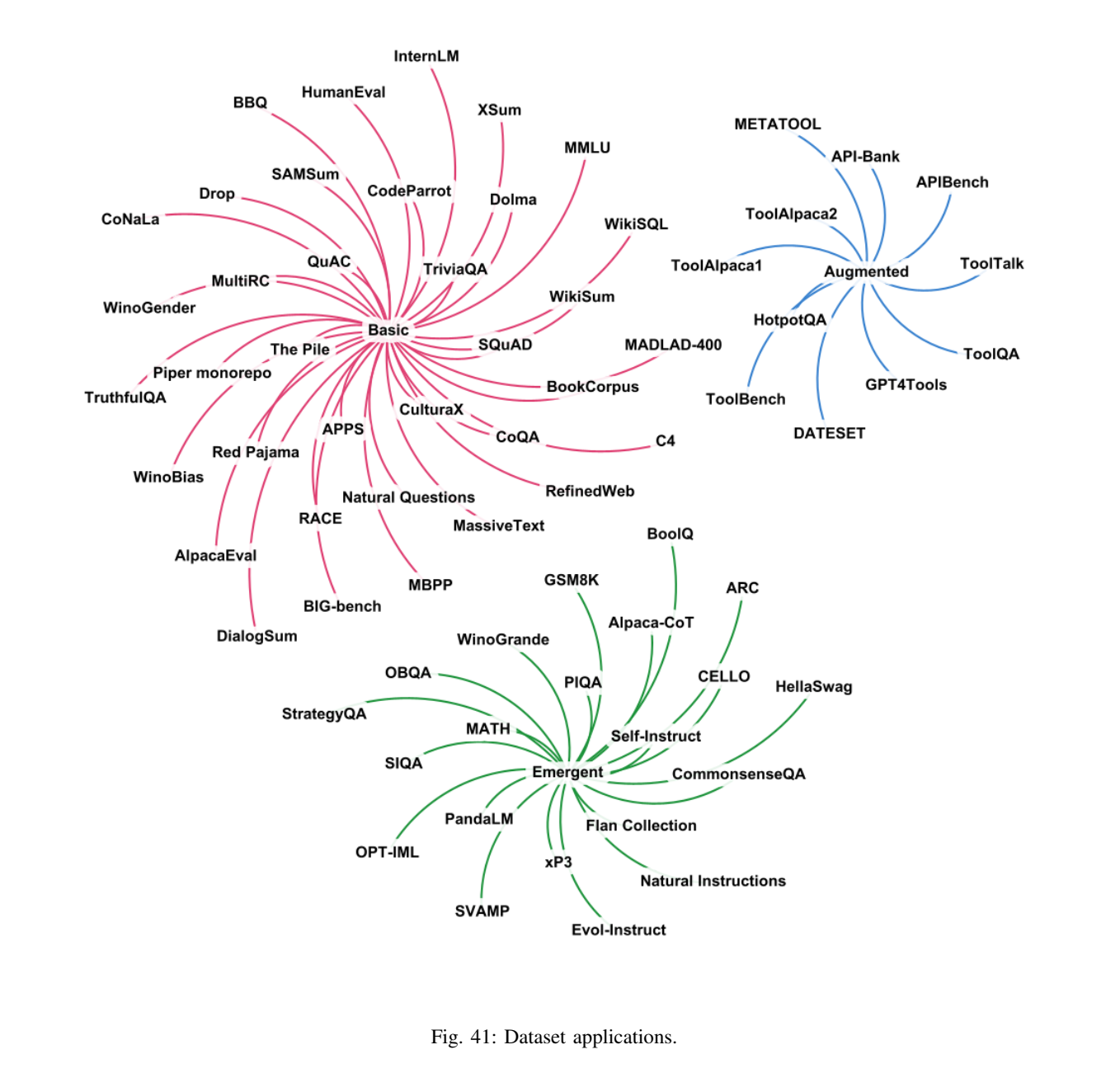
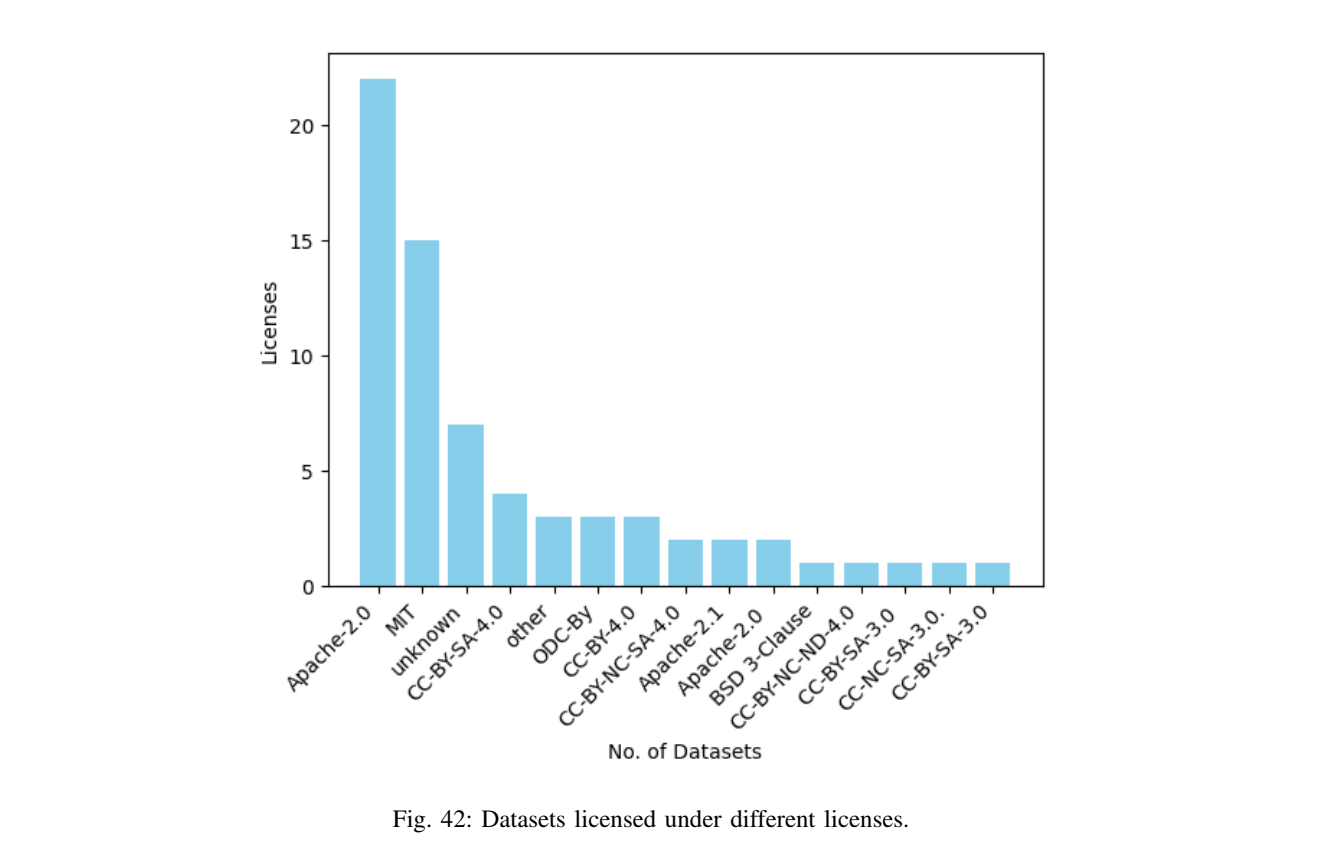
图41--42解读:图41用分类统计展示数据集覆盖的应用面(例如通用语言任务、推理、工具/对话等);图42则统计不同许可协议下的数据集比例,暗示"可用数据"不仅受技术约束,也受法律与合规约束。
7.2 评测指标:从分类指标到生成指标,再到对话指标
论文在 VI-A 概括了指标谱系:选择式任务可用 accuracy、precision、recall、F1;生成式任务常用 ROUGE、BLEU,但这些多是基于 nnn-gram 的表面相似,难以评估事实性;对话/阅读理解场景出现 HEQ(human equivalence score)等指标,用"是否超过人类平均 F1"定义等价性。
把 accuracy 与 F1 写成数学形式有助于理解其差异。设二分类下 TP/FP/FN 分别为真阳/假阳/假阴,则
Precision=TPTP+FP,Recall=TPTP+FN,F1=2⋅Precision⋅RecallPrecision+Recall. \mathrm{Precision}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}},\quad \mathrm{Recall}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}},\quad \mathrm{F1}=\frac{2\cdot \mathrm{Precision}\cdot \mathrm{Recall}}{\mathrm{Precision}+\mathrm{Recall}}. Precision=TP+FPTP,Recall=TP+FNTP,F1=Precision+Recall2⋅Precision⋅Recall.
生成指标 BLEU(简化理解)以 nnn-gram 精确率乘以 brevity penalty 表征相似度;ROUGE 更偏召回视角。论文的态度很明确:这些指标在"有参考答案"的场景有用,但对开放生成与事实一致性不充分。
7.3 代表模型在基准上的表现:差异来自"数据+对齐+规模+系统增强"的组合
论文在 VI-B 以多张表格汇总不同能力维度的代表性结果,并提醒读者:各模型并未在所有基准上完整报告,横向比较要谨慎。
从这些汇总可以抽象出一条更稳定的解释框架:
模型性能并非只由参数规模决定,而是由训练 token 数与数据质量、对齐方法(SFT/RLHF/DPO/KTO 等)、推理策略(解码与自一致性)、以及是否引入检索/工具增强共同决定。就这一点而言,论文把"LLM 表现"从单模型研究转向系统工程研究,具有方法论意义。
7.4 LLM 分类体系(图43)与表格定义
论文在 VI-A 给出 LLM 的分类维度(规模、类型、来源、可用性等),并用图43做可视化总结。
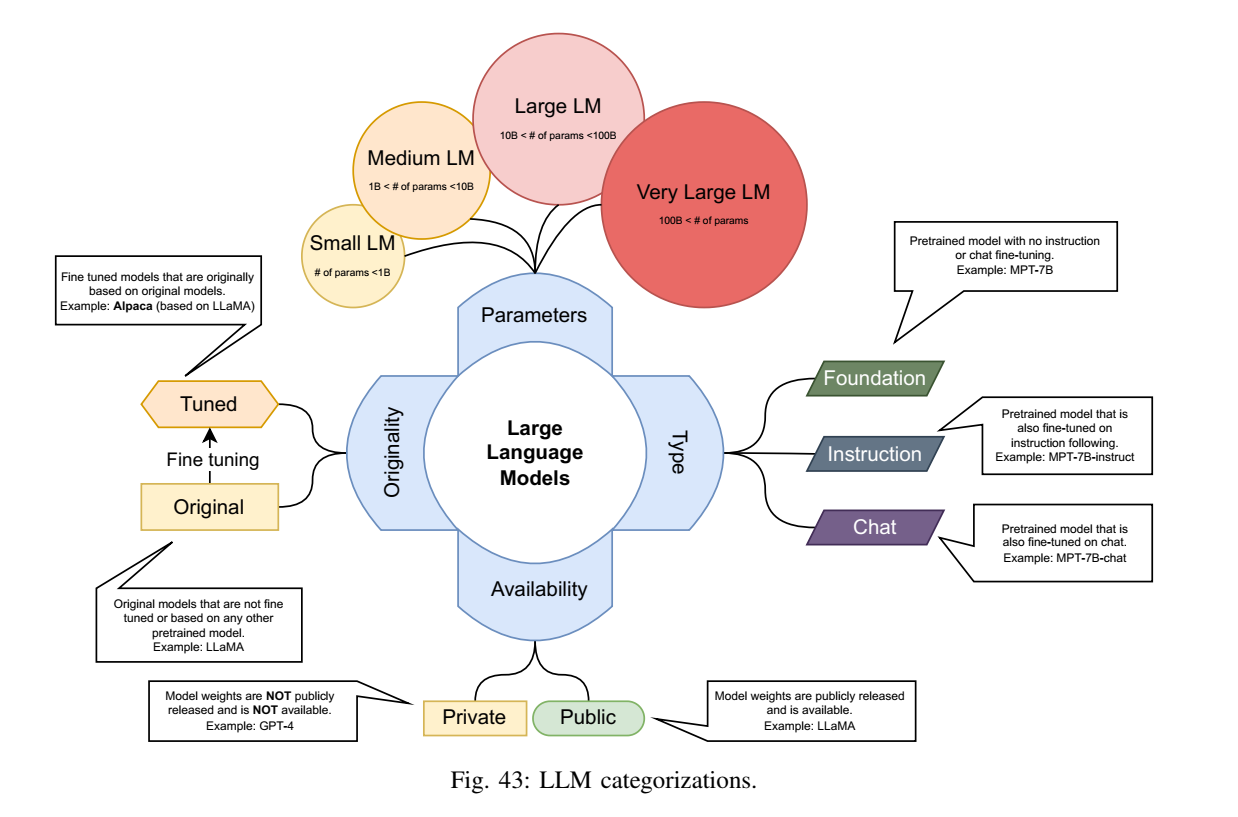
图43解读:图中把模型按多个维度分桶,例如参数规模(small/medium/large/very large)、类型(foundation/instruction/chat)、可用性(公开/非公开)、来源(原始/微调)。其价值在于给"模型名混乱"提供统一坐标系:同名不同版本(base vs chat)在行为上可能完全不同。
附录:原文数学推导补全
A. 从极大似然到交叉熵与困惑度:为何自回归预训练等价于最小化 KL
设真实数据分布为 pdata(x1:T)p_{\text{data}}(x_{1:T})pdata(x1:T),模型分布为 pθ(x1:T)p_\theta(x_{1:T})pθ(x1:T)。最大化期望对数似然:
maxθ E∗x∼p∗datalogpθ(x). \max_\theta\ \mathbb{E}*{x\sim p*{\text{data}}}\big\\log p_\\theta(x)\\big. θmax E∗x∼p∗datalogpθ(x).
注意 KL 散度:
KL!(pdata∣pθ)=E∗x∼p∗data!logpdata(x)pθ(x)=E∗x∼p∗datalogpdata(x)−E∗x∼p∗datalogpθ(x). \mathrm{KL}!\left(p_{\text{data}}|p_\theta\right) =\mathbb{E}*{x\sim p*{\text{data}}}!\left\\log\\frac{p_{\\text{data}}(x)}{p_\\theta(x)}\\right =\mathbb{E}*{x\sim p*{\text{data}}}\\log p_{\\text{data}}(x)-\mathbb{E}*{x\sim p*{\text{data}}}\\log p_\\theta(x). KL!(pdata∣pθ)=E∗x∼p∗data!logpθ(x)pdata(x)=E∗x∼p∗datalogpdata(x)−E∗x∼p∗datalogpθ(x).
其中第一项与 θ\thetaθ 无关,因此
maxθ E∗x∼p∗datalogpθ(x)⟺minθ KL(pdata∣pθ). \max_\theta\ \mathbb{E}*{x\sim p*{\text{data}}}\\log p_\\theta(x) \quad\Longleftrightarrow\quad \min_\theta\ \mathrm{KL}(p_{\text{data}}|p_\theta). θmax E∗x∼p∗datalogpθ(x)⟺θmin KL(pdata∣pθ).
对自回归分解 pθ(x)=∏tpθ(xt∣x<t)p_\theta(x)=\prod_t p_\theta(x_t\mid x_{<t})pθ(x)=∏tpθ(xt∣x<t),负对数似然为:
−logpθ(x)=∑t=1T−logpθ(xt∣x<t), -\log p_\theta(x)=\sum_{t=1}^{T} -\log p_\theta(x_t\mid x_{<t}), −logpθ(x)=t=1∑T−logpθ(xt∣x<t),
这就是 token 级交叉熵损失。困惑度(perplexity)定义为平均负对数似然的指数:
PPL=exp(1T∑t=1T−logpθ(xt∣x<t)). \mathrm{PPL}=\exp\left(\frac{1}{T}\sum_{t=1}^{T}-\log p_\theta(x_t\mid x_{<t})\right). PPL=exp(T1t=1∑T−logpθ(xt∣x<t)).
因此"降低困惑度"与"提高对数似然"完全等价;更深层地,它等价于让模型分布在 KL 意义上逼近数据分布。
B. MLM 目标的统计本质:伪似然(pseudo-likelihood)与信息利用差异
MLM 的目标是最大化被 mask token 的条件概率:
L∗MLM(θ)=−∑∗i∈Mlogpθ(xi∣x∖M). \mathcal{L}*{\text{MLM}}(\theta)= -\sum*{i\in M}\log p_\theta(x_i\mid x_{\setminus M}). L∗MLM(θ)=−∑∗i∈Mlogpθ(xi∣x∖M).
与自回归不同,MLM 并非对 pθ(x1:T)p_\theta(x_{1:T})pθ(x1:T) 的严格似然最大化(因为它不对应一个唯一的、可直接写出的联合分布分解),更接近一种伪似然思想:用一组条件分布的乘积近似联合分布。经典伪似然可写为:
logp~∗θ(x)=∑∗t=1Tlogpθ(xt∣x∖t). \log \tilde{p}*\theta(x)=\sum*{t=1}^{T}\log p_\theta(x_t\mid x_{\setminus t}). logp~∗θ(x)=∑∗t=1Tlogpθ(xt∣x∖t).
MLM 是在随机子集 MMM 上对该目标做稀疏采样估计。它的优势是利用双向上下文的信息量更大;劣势是生成时需要额外机制(如把 MLM 模型改成 seq2seq 或结合其他目标),因此在"开放式生成"上通常不如纯自回归自然。
C. 温度缩放的熵与"Boltzmann 分布"解释:为何 TTT 控制随机性
给定 logits zzz,温度采样分布:
pT(i)=ezi/T∑jezj/T. p_T(i)=\frac{e^{z_i/T}}{\sum_j e^{z_j/T}}. pT(i)=∑jezj/Tezi/T.
这与统计物理的 Boltzmann 分布同构,其中"能量"可视作 Ei=−ziE_i=-z_iEi=−zi,"温度"就是 TTT。当 TTT 增大,分布更接近均匀,熵 H(pT)H(p_T)H(pT) 增大;当 TTT 变小,概率质量集中到最大 logit,熵下降。可用一个定性结论表达:
T1<T2 ⇒ pT1 更尖锐(更低熵),pT2 更平坦(更高熵). T_1<T_2\ \Rightarrow\ p_{T_1}\ \text{更尖锐(更低熵)},\quad p_{T_2}\ \text{更平坦(更高熵)}. T1<T2 ⇒ pT1 更尖锐(更低熵),pT2 更平坦(更高熵).
因此温度不是"让模型更聪明",而是改变采样分布的探索程度;在事实性任务中常取更低 TTT,在创作任务中常取更高 TTT。
D. 从偏好概率模型推导 DPO:把对齐化为"带参考策略的成对对数似然"
设给定输入 xxx,人类对两个回答 y+y^+y+(偏好)与 y−y^-y−(不偏好)给出比较。常用 Bradley--Terry/Luce 型偏好模型:
P(y+≻y−∣x)=σ(r(x,y+)−r(x,y−)), \mathbb{P}(y^+\succ y^-\mid x) =\sigma\big(r(x,y^+)-r(x,y^-)\big), P(y+≻y−∣x)=σ(r(x,y+)−r(x,y−)),
其中 σ(u)=11+e−u\sigma(u)=\frac{1}{1+e^{-u}}σ(u)=1+e−u1,r(x,y)r(x,y)r(x,y) 是"潜在奖励"。RLHF 的做法是先拟合 rrr 再做 RL。DPO 的关键在于把"奖励差"与"策略对数比"联系起来:假设存在参考策略 πref\pi_{\text{ref}}πref,并定义优化目标策略 πθ\pi_\thetaπθ。在一类最大熵/相对熵约束的设定下,可得到奖励与策略比值的关系(直观上:更高奖励的输出在目标策略下相对参考策略更常见):
r(x,y)∝βlogπθ(y∣x)πref(y∣x), r(x,y)\propto \beta \log\frac{\pi_\theta(y\mid x)}{\pi_{\text{ref}}(y\mid x)}, r(x,y)∝βlogπref(y∣x)πθ(y∣x),
于是奖励差:
r(x,y+)−r(x,y−)∝βlogπθ(y+∣x)πref(y+∣x)−logπθ(y−∣x)πref(y−∣x). r(x,y^+)-r(x,y^-)\propto \beta\left \\log\\frac{\\pi_\\theta(y\^+\\mid x)}{\\pi_{\\text{ref}}(y\^+\\mid x)} -\\log\\frac{\\pi_\\theta(y\^-\\mid x)}{\\pi_{\\text{ref}}(y\^-\\mid x)} \\right. r(x,y+)−r(x,y−)∝βlogπref(y+∣x)πθ(y+∣x)−logπref(y−∣x)πθ(y−∣x).
代回偏好概率并对数据最大化对数似然,得到 DPO 损失(常见写法):
L∗DPO(θ)=−E∗(x,y+,y−)logσ(β(logπθ(y+∣x)πref(y+∣x)−logπθ(y−∣x)πref(y−∣x))). \mathcal{L}*{\text{DPO}}(\theta)= -\mathbb{E}*{(x,y^+,y^-)}\left \\log \\sigma\\left( \\beta\\left( \\log\\frac{\\pi_\\theta(y\^+\\mid x)}{\\pi_{\\text{ref}}(y\^+\\mid x)} -\\log\\frac{\\pi_\\theta(y\^-\\mid x)}{\\pi_{\\text{ref}}(y\^-\\mid x)} \\right)\\right) \\right. L∗DPO(θ)=−E∗(x,y+,y−)logσ(β(logπref(y+∣x)πθ(y+∣x)−logπref(y−∣x)πθ(y−∣x))).
这解释了图30的流程对比:DPO 不需要显式训练奖励模型并跑 PPO,而是把偏好学习直接变成"成对对数似然"的监督优化;β\betaβ 起到"对齐强度/温度"的作用,控制偏好信号对策略更新的影响。
E. KTO 的一种统一理解:从成对偏好到单样本"可接受性"反馈
若偏好数据更容易以"单个回答是否可接受(good/bad)"形式获得,可设标签 s∈+1,−1s\in{+1,-1}s∈+1,−1 表示接受/拒绝。一个与 DPO 兼容的写法是:仍然用参考策略 πref\pi_{\text{ref}}πref 作为基准,把目标策略相对参考策略的对数优势定义为:
Δθ(x,y)=logπθ(y∣x)πref(y∣x). \Delta_\theta(x,y)=\log\frac{\pi_\theta(y\mid x)}{\pi_{\text{ref}}(y\mid x)}. Δθ(x,y)=logπref(y∣x)πθ(y∣x).
则可用 logistic 回归式目标学习 sss:
L∗KTO(θ)=−E∗(x,y,s)logσ(s⋅βΔθ(x,y)). \mathcal{L}*{\text{KTO}}(\theta)= -\mathbb{E}*{(x,y,s)}\left\\log \\sigma\\big(s\\cdot \\beta \\Delta_\\theta(x,y)\\big)\\right. L∗KTO(θ)=−E∗(x,y,s)logσ(s⋅βΔθ(x,y)).
当 s=+1s=+1s=+1(好回答),目标倾向于让 πθ\pi_\thetaπθ 相对 πref\pi_{\text{ref}}πref 提高该回答概率;当 s=−1s=-1s=−1(坏回答),则相反。与 DPO 相比,它不需要 (y+,y−)(y^+,y^-)(y+,y−) 成对结构,因而更贴近图31强调的"低成本反馈对齐"。
F. LoRA 的低秩约束为何有效:子空间适配与参数/显存节省的定量关系
LoRA 将权重更新限制为 ΔW=BA\Delta W=BAΔW=BA,其中 rank(ΔW)≤r\mathrm{rank}(\Delta W)\le rrank(ΔW)≤r。这等价于假设"下游任务的最优更新方向"落在一个 rrr 维子空间中。更直观地,令 u=Ax∈Rru=Ax\in\mathbb{R}^ru=Ax∈Rr,则
ΔWx=B(Ax)=Bu, \Delta W x = B(Ax)=Bu, ΔWx=B(Ax)=Bu,
意味着更新后的表示只能通过 rrr 维瓶颈向量 uuu 影响输出,rrr 控制了适配自由度。参数量对比:
dk⏟∗全量微调vsr(d+k)⏟∗LoRA 新增. \underbrace{dk}*{\text{全量微调}} \quad \text{vs}\quad \underbrace{r(d+k)}*{\text{LoRA 新增}}. dk∗全量微调vs r(d+k)∗LoRA 新增.
当 d≈kd\approx kd≈k 且 r≪dr\ll dr≪d 时,LoRA 参数占比约为 2rd\frac{2r}{d}d2r,例如 d=4096, r=16d=4096,\ r=16d=4096, r=16 时占比约 0.780.78%0.78,这解释了其在大模型微调中的显著优势。图34中常出现缩放 α/r\alpha/rα/r,其作用可理解为把有效更新幅度与秩 rrr 解耦,避免 rrr 改变时更新尺度剧烈波动。
G. MoE 的负载均衡:为何需要额外正则项
MoE 的风险是路由塌缩:大多数 token 被分到少数专家,导致这些专家过载且训练不稳定。常见做法是加入负载均衡损失。设 batch 内 token 路由到专家 eee 的概率均值为 pˉe\bar{p}_epˉe,实际分配比例为 fˉe\bar{f}_efˉe,则一种典型正则是鼓励两者接近均匀分布,例如:
L∗lb=∣E∣∑∗e=1∣E∣pˉefˉe, \mathcal{L}*{\text{lb}}=|E|\sum*{e=1}^{|E|}\bar{p}_e\bar{f}_e, L∗lb=∣E∣∑∗e=1∣E∣pˉefˉe,
或使用熵/方差形式鼓励均匀。其本质是把"稀疏激活带来的效率"与"训练稳定性"同时纳入目标。
H. RAG 的隐变量视角与 top-KKK 近似误差:何时会"检索噪声放大"
在
p(y∣x)=∑dp(y∣x,d),p(d∣x) p(y\mid x)=\sum_d p(y\mid x,d),p(d\mid x) p(y∣x)=d∑p(y∣x,d),p(d∣x)
中,若检索分布 p(d∣x)p(d\mid x)p(d∣x) 的质量不高(召回不足或噪声高),top-KKK 近似会出现两类误差:
其一是截断误差:正确证据 d∗d^*d∗ 不在 top-KKK;其二是条件漂移:拼接噪声证据使 p(y∣x,d)p(y\mid x,d)p(y∣x,d) 的生成分布偏离真实意图。形式上,若定义截断集合 DK\mathcal{D}_KDK,则误差上界与 p(d∗∉DK∣x)p(d^*\notin\mathcal{D}_K\mid x)p(d∗∈/DK∣x) 强相关;而条件漂移可通过比较
KL!(pθ(⋅∣x) ∣ pθ(⋅∣x,DK)) \mathrm{KL}!\left(p_\theta(\cdot\mid x)\ |\ p_\theta(\cdot\mid x,\mathcal{D}_K)\right) KL!(pθ(⋅∣x) ∣ pθ(⋅∣x,DK))
来量化。实践中"检索增强反而变差"的常见原因,正是噪声证据导致模型把注意力分配到错误片段上。
I. 后注意力范式的一个数学入口:结构化状态空间模型(SSM)的离散递推
论文在挑战部分提到 SSM(S4、Mamba、Hyena 等)。一个经典线性 SSM 可写为连续时间形式:
s˙(t)=As(t)+Bu(t),y(t)=Cs(t)+Du(t), \dot{s}(t)=As(t)+Bu(t),\qquad y(t)=Cs(t)+Du(t), s˙(t)=As(t)+Bu(t),y(t)=Cs(t)+Du(t),
离散化(步长 Δt\Delta tΔt)后可得递推:
st+1=Aˉst+Bˉut,yt=Cˉst+Dˉut. s_{t+1}=\bar{A}s_t+\bar{B}u_t,\qquad y_t=\bar{C}s_t+\bar{D}u_t. st+1=Aˉst+Bˉut,yt=Cˉst+Dˉut.
其中 Aˉ,Bˉ\bar{A},\bar{B}Aˉ,Bˉ 由 A,BA,BA,B 的离散化方案决定。与注意力不同,这类模型通过状态递推实现长程依赖,理论上可实现接近线性的序列计算复杂度,从而成为论文所说"post-attention"候选路线之一。