一、卷积神经网络案例
咱们使用前面学习到的知识来构建一个卷积神经网络, 并训练该网络实现图像分类. 要完成这个案例,咱们需要学习的内容如下:
1、了解 CIFAR10 数据集
2、搭建卷积神经网络
3、编写训练函数
4、编写预测函数
首先我们导入一下工具包:
python
# 导包
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor # pip install torchvision -i https://mirrors.aliyun.com/pypi/simple/
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import matplotlib.pyplot as plt
# from torchsummary import summary二、CIFAR10 数据集
CIFAR-10数据集5万张训练图像、1万张测试图像、10个类别、每个类别有6k个图像,图像大小32×32×3。下图列举了10个类,每一类随机展示了10张图片:

PyTorch 中的 torchvision.datasets 计算机视觉模块封装了 CIFAR10 数据集, 使用方法如下:



三、搭建图像分类网络
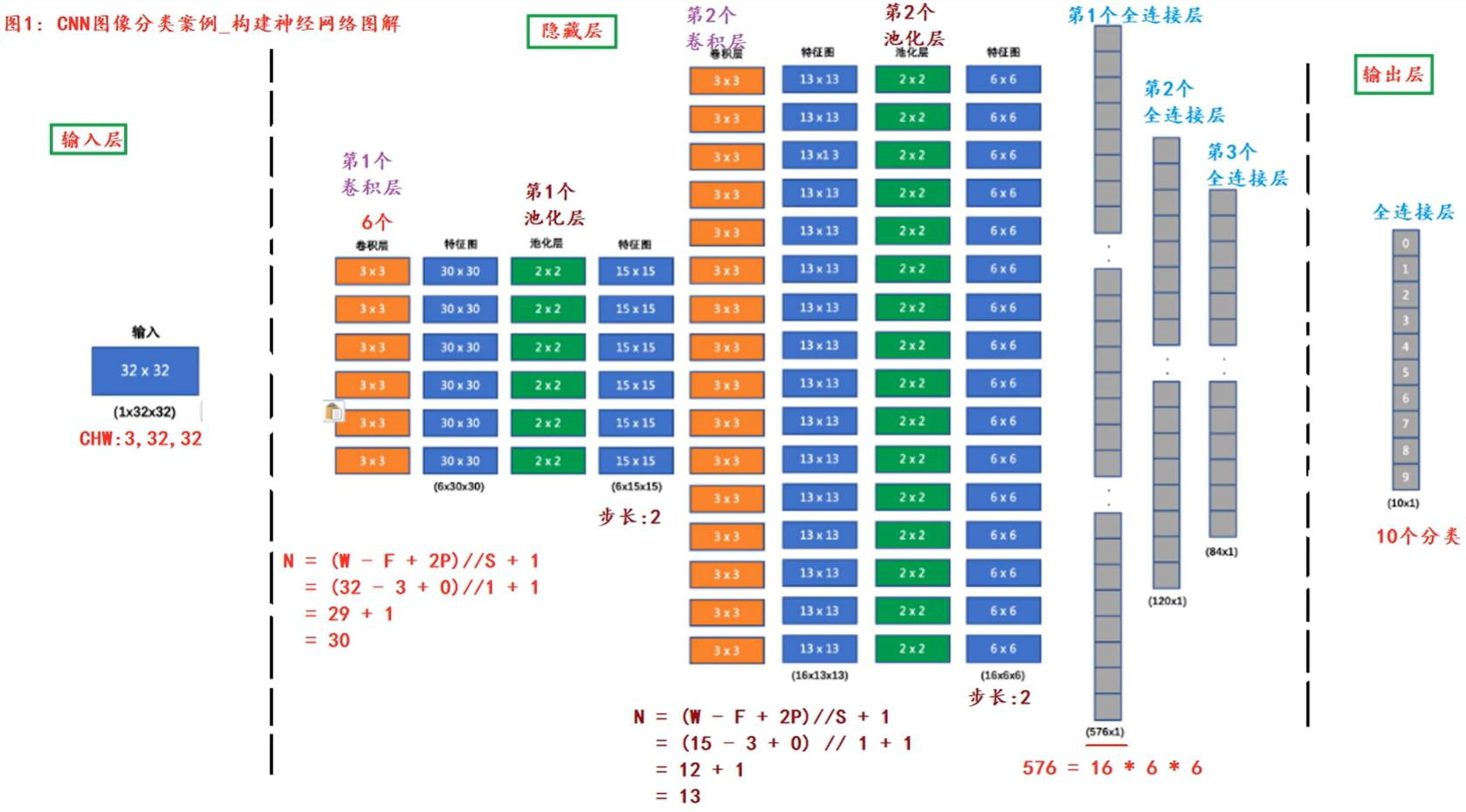
我们要搭建的网络结构如下:
1、输入形状: 32x32
2、第一个卷积层输入 3 个 Channel, 输出 6 个 Channel, Kernel Size 为: 3x3
3、第一个池化层输入 30x30, 输出 15x15, Kernel Size 为: 2x2, Stride 为: 2
4、第二个卷积层输入 6 个 Channel, 输出 16 个 Channel, Kernel Size 为 3x3
5、第二个池化层输入 13x13, 输出 6x6, Kernel Size 为: 2x2, Stride 为: 2
6、第一个全连接层输入 576 维, 输出 120 维
7、第二个全连接层输入 120 维, 输出 84 维
8、最后的输出层输入 84 维, 输出 10 维
我们在每个卷积计算之后应用 relu 激活函数来给网络增加非线性因素。


四、编写训练函数
python
# 3. 模型训练.
def train(train_dataset):
# 1. 创建数据加载器.
dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
# 2. 创建模型对象.
model = ImageModel()
# 3. 创建损失函数对象.
criterion = nn.CrossEntropyLoss() # 多分类交叉熵损失函数 = softmax()激活函数 + 损失计算.
# 4. 创建优化器对象.
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 5. 循环遍历epoch, 开始 每轮的 训练动作.
# 5.1 定义变量, 记录训练的总轮数.
epochs = 20
# 5.2 遍历, 完成每轮的 所有批次的 训练动作.
for epoch_idx in range(epochs):
# 5.2.1 定义变量, 记录: 总损失, 总样本数据量, 预测正确样本个数, 训练(开始)时间
total_loss, total_samples, total_correct, start = 0.0, 0, 0, time.time()
# 5.2.2 遍历数据加载器, 获取到 每批次的 数据.
for x, y in dataloader:
# 5.2.3 切换训练模式.
model.train()
# 5.2.4 模型预测.
y_pred = model(x)
# 5.2.5 计算损失.
loss = criterion(y_pred, y)
# 5.2.6 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 5.2.7 统计预测正确的样本个数.
# print(y_pred) # 批次中, 每张图 每个分类的 预测概率.
# argmax() 返回最大值对应的索引, 充当 -> 该图片的 预测分类.
# tensor([9, 8, 5, 5, 1, 5, 8, 5])
# print(torch.argmax(y_pred, dim=-1)) # -1这里表示行. 预测分类
# print(y) # 真实分类
# print(torch.argmax(y_pred, dim=-1) == y) # 是否预测正确
# print((torch.argmax(y_pred, dim=-1) == y).sum()) # 预测正确的样本个数.
total_correct += (torch.argmax(y_pred, dim=-1) == y).sum()
# 5.2.8 统计当前批次的总损失. 第1批平均损失 * 第1批样本个数
total_loss += loss.item() * len(y) # [第1批总损失 + 第2批总损失 + 第3批总损失 + ...]
# 5.2.9 统计当前批次的总样本个数.
total_samples += len(y)
# break 每轮只训练1批, 提高训练效率, 减少训练时长, 只有测试会这么写, 实际开发绝不要这样做.
# 5.2.10 走这里, 说明一轮训练完毕, 打印该轮的训练信息.
print(f'epoch: {epoch_idx + 1}, loss: {total_loss / total_samples:.5f}, acc:{total_correct / total_samples:.2f}, time:{time.time() - start:.2f}s')
# break # 这里写break, 意味着只训练一轮.
# 6. 保存模型.
torch.save(model.state_dict(), './model/image_model.pth')五、编写预测函数
加载训练好的模型,对测试集中的 1 万条样本进行预测,查看模型在测试集上的准确率。
python
# 4. 模型测试.
def evaluate(test_dataset):
# 1. 创建测试集 数据加载器.
dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# 2. 创建模型对象.
model = ImageModel()
# 3. 加载模型参数.
model.load_state_dict(torch.load('./model/image_model.pth')) # pickle文件
# 4. 定义变量统计 预测正确的样本个数, 总样本个数.
total_correct, total_samples = 0, 0
# 5. 遍历数据加载器, 获取到 每批次 的数据.
for x, y in dataloader:
# 5.1 切换模型模式.
model.eval()
# 5.2 模型预测.
y_pred = model(x)
# 5.3 因为训练的时候用了CrossEntropyLoss, 所以搭建神经网络时没有加softmax()激活函数, 这里要用 argmax()来模拟.
# argmax()函数功能: 返回最大值对应的索引, 充当 -> 该图片的 预测分类.
y_pred = torch.argmax(y_pred, dim=-1) # -1 这里表示行.
# 5.4 统计预测正确的样本个数.
total_correct += (y_pred == y).sum()
# 5.5 统计总样本个数.
total_samples += len(y)
# 6. 打印正确率(预测结果).
print(f'Acc: {total_correct / total_samples:.2f}')从程序的运行结果来看,网络模型在测试集上的准确率并不高。我们可以从以下几个方面来进行优化:
1、增加卷积核输出通道数
2、增加全连接层的参数量
3、调整学习率
4、调整优化方法
5、修改激活函数
6、等等...