提示工程是大模型时代人人必备的核心技能,也是大模型应用工程师的入门第一课。它不需要你懂复杂的算法和数学,只需要学会用结构化的语言和大模型 "沟通",就能让大模型的能力提升 10 倍以上。
据 OpenAI 官方统计,80% 的大模型应用问题都可以通过优化提示词解决,而一个优秀的提示词能让模型输出质量提升 300%-500%。
第一章 提示工程基础理论层
1.1 核心定义与价值
1.1.1 什么是提示工程?
提示工程(Prompt Engineering) 是通过设计、优化输入文本(提示词),向大模型传递清晰的任务目标、上下文、约束条件和输出要求,引导大模型输出高质量、符合预期结果的技术体系。
简单来说,提示工程就是教你如何 "问对问题",让大模型听懂你的需求,并且给出你想要的答案。
1.1.2 提示工程的核心价值
| 价值点 | 详细说明 |
|---|---|
| 低成本高效能 | 无需修改模型参数,无需训练数据,几分钟就能优化模型输出 |
| 解决幻觉问题 | 通过提供上下文和约束,大幅降低大模型 "胡说八道" 的概率 |
| 标准化输出 | 统一输出格式,让模型输出可被程序直接解析,无需额外处理 |
| 提升推理能力 | 引导模型进行多步思考,解决复杂的数学、逻辑和规划问题 |
| 快速适配场景 | 几分钟就能将通用大模型适配到客服、文案、代码、教育等特定场景 |
1.1.3 提示工程的适用边界
✅ 非常适合:
- 文本生成(文案、报告、代码、邮件)
- 信息提取(人名、地名、关键词、数据)
- 推理分析(数学计算、逻辑推理、问题解决)
- 内容改写(翻译、润色、缩写、扩写)
- 简单决策(分类、排序、评估)
❌ 不适合(需结合 RAG / 微调):
- 需要深度领域知识注入(如医疗诊断、法律条文解读)
- 需要强风格对齐(如模仿特定作家的写作风格)
- 需要高精度数值计算(如复杂的科学计算)
- 需要处理大量私有数据(如企业内部文档问答)
1.2 大模型工作原理与提示工程底层逻辑
1.2.1 大模型的本质:下一个词预测器
所有的大语言模型(GPT、Claude、LLaMA、Qwen 等)本质上都是 **"下一个词预测器"**。它们通过学习海量的文本数据,掌握了语言的统计规律,能够根据前面的文本,预测下一个最可能出现的词。
1.2.2 影响模型输出的核心参数
大模型的输出不仅取决于提示词,还受到以下几个核心参数的影响:
| 参数 | 作用 | 取值范围 | 最佳实践 |
|---|---|---|---|
| Temperature(温度) | 控制输出的随机性 | 0-2 | 0 = 确定性输出(适合代码、数据提取)0.7 = 平衡(适合大多数场景)1.5 = 高创造性(适合创意写作) |
| Top-P | 控制采样的词汇范围 | 0-1 | 0.1 = 只选择最可能的 10% 词汇0.9 = 选择累积概率达到 90% 的词汇 |
| Max Tokens | 限制输出的最大长度 | 1 - 模型上下文窗口 | 根据任务需求设置,避免过长或过短 |
| Frequency Penalty | 惩罚重复出现的词 | -2.0-2.0 | 0.1-1.0,避免模型重复输出相同内容 |
1.2.3 提示工程的底层逻辑
提示工程之所以有效,是因为大模型具备上下文学习(In-Context Learning) 能力。也就是说,大模型不需要重新训练,只需要在提示词中提供几个示例,就能学会完成特定的任务。
核心原理 :大模型在预训练阶段已经学习了海量的知识和模式,提示工程的作用就是激活大模型已经掌握的这些知识和模式,引导它进入正确的 "任务模式"。
1.3 提示设计核心原则(CRISP 原则)
经过全球数百万开发者的实践总结,优秀的提示词都遵循以下 5 个核心原则,简称CRISP 原则:
1.3.1 清晰性(Clarity)
避免模糊、歧义的表述,使用精确、具体的语言。
❌ 坏例子 :帮我写一篇关于人工智能的文章
✅ 好例子 :帮我写一篇面向小学生的人工智能科普文章,主题是"人工智能如何改变我们的生活",字数500字左右,语言通俗易懂,多用比喻。
1.3.2 具体性(Specificity)
明确任务的所有要求,包括输出的长度、格式、风格、受众等。
❌ 坏例子 :帮我写一个Python函数
✅ 好例子 :帮我写一个Python函数,功能是计算一个列表中所有偶数的和。函数名是sum_even_numbers,参数是一个整数列表,返回值是偶数的和。请添加详细的注释,并提供3个测试用例。
1.3.3 完整性(Integrity)
提供完成任务所需的全部上下文信息,不要假设模型知道你知道的事情。
❌ 坏例子 :帮我分析一下这个数据(没有提供数据)
✅ 好例子 :帮我分析以下销售数据,找出销售额最高的月份和最低的月份,并计算全年的总销售额和平均月销售额。数据:1月:10万,2月:15万,3月:12万,4月:18万,5月:20万,6月:16万,7月:14万,8月:17万,9月:19万,10月:22万,11月:25万,12月:30万。
1.3.4 结构化(Structure)
使用分点、编号、标题、分隔符等方式组织提示内容,让模型更容易理解。
✅ 结构化提示示例:
java
# 任务:生成一份产品需求文档
## 产品名称:智能 todo 清单应用
## 目标用户:大学生和职场新人
## 核心功能:
1. 任务添加与删除
2. 任务分类与标签
3. 截止日期提醒
4. 任务完成统计
## 输出要求:
- 文档结构清晰,包含引言、功能需求、非功能需求、技术栈建议
- 字数控制在1000字左右
- 语言专业、简洁1.3.5 优先级(Priority)
将最重要的要求放在提示的开头和结尾,因为大模型对开头和结尾的信息注意力更高。
✅ 优先级示例:
【最重要要求:所有输出必须使用中文,禁止使用任何英文】
请帮我解释什么是Transformer架构,包括它的核心组成部分和工作原理。
【再次强调:请用通俗易懂的语言解释,避免使用专业术语,让没有技术背景的人也能听懂。】1.4 标准提示的基本组成结构
一个完整、专业的提示词应该包含以下 6 个核心模块,可根据任务灵活增减:
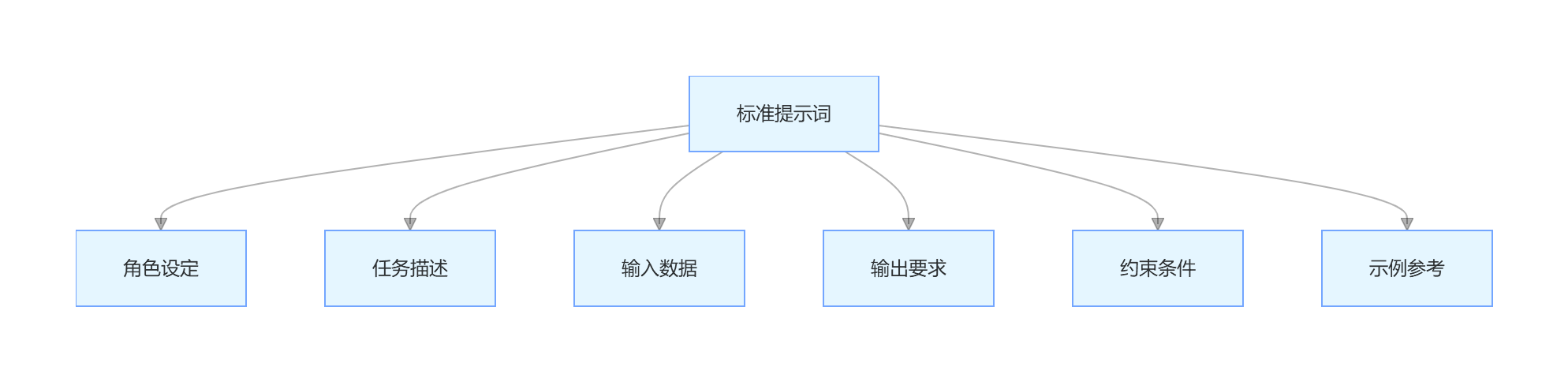
1.4.1 角色设定
赋予模型特定的身份和专业背景,让它站在该角色的角度思考和回答问题。
示例 :你是一位拥有10年经验的资深Java开发工程师,精通Spring Boot框架和微服务架构,擅长代码优化和最佳实践。
1.4.2 任务描述
明确说明需要模型完成的具体任务,用动词开头,简洁明了。
示例 :请帮我优化以下Java代码,提高它的运行效率和可读性。
1.4.3 输入数据
提供任务所需的原始数据或上下文信息,用分隔符(如 ```、---)包裹,避免与提示词混淆。
示例:
java
需要优化的代码:
```java
public class UserService {
public List<User> getUsers() {
List<User> users = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
User user = new User();
user.setId(i);
user.setName("User" + i);
users.add(user);
}
return users;
}
}1.4.4 约束条件
约束条件是告诉模型必须遵守的规则、限制、禁止行为,能大幅减少幻觉、格式错乱、回答跑偏。
作用:
- 限定输出语言(必须中文 / 必须英文)
- 限定内容范围(不允许编造信息)
- 限定风格与长度
- 限定禁止行为(不使用专业术语、不生成敏感内容)
示例:
约束条件:
1. 必须使用中文回答,禁止出现英文
2. 禁止编造任何没有依据的信息
3. 回答长度不超过300字
4. 语言必须通俗易懂,适合小学生理解1.4.5 示例参考(少样本提示)
示例参考是给模型看 1~3 个正确答案,让模型模仿格式与逻辑输出。
为什么有效 :大模型具有极强的模式模仿能力,给示例 = 给标准答案模板。
示例写法:
示例1:
输入:苹果
输出:水果,红色/绿色,可食用
示例2:
输入:桌子
输出:家具,木质/金属,用于放置物品1.4.6 标准提示词六要素完整示例
这是最标准、最专业、企业级通用的提示词结构,小白直接背会就能吊打 90% 用户。
【角色设定】你是一位专业的小学数学老师,说话温和、有耐心。
【任务描述】请为小学生讲解一道数学应用题。
【输入数据】
题目:小明有5颗糖,妈妈又给他买了4颗,他吃掉了2颗,现在有多少颗?
【输出要求】
1. 分步骤讲解
2. 语言简单、易懂、生动
3. 最后给出明确答案
【约束条件】
1. 禁止使用方程式
2. 禁止使用专业术语
3. 必须用中文
【示例参考】
示例:
问题:小红有3个苹果,又得到2个,现在有几个?
回答:原来有3个,加上2个,3+2=5,现在一共有5个。2.2 推理增强提示
大模型在处理数学计算、逻辑推理等复杂任务时,经常会出错。推理增强提示通过引导模型逐步展示推理过程,大幅提升复杂任务的准确率。
2.2.1 思维链提示(Chain-of-Thought, CoT)
思维链提示是目前最流行的推理增强技巧,它要求模型在给出答案之前,先展示详细的推理过程。
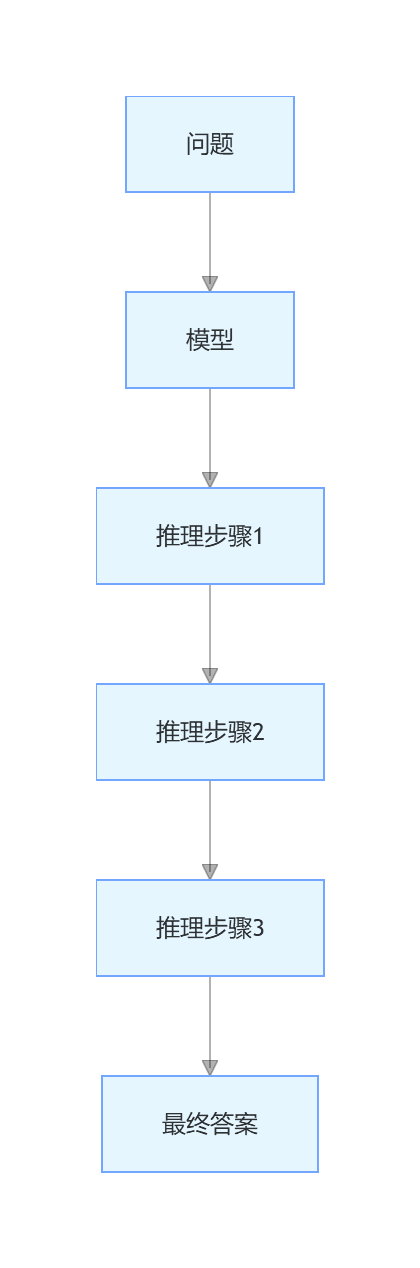
图 2-2:思维链提示效果对比图
经典句式 :让我们一步一步来思考。
示例:
问题:一个商店有12个苹果,卖了5个,又进货8个,现在有多少个苹果?
回答:让我们一步一步来思考。
1. 商店原来有12个苹果
2. 卖了5个后,剩下12-5=7个
3. 又进货8个,现在有7+8=15个
所以,现在商店有15个苹果。2.2.2 零样本思维链(Zero-Shot CoT)
不需要提供示例,只需要在问题的结尾加上 "让我们一步一步来思考" 这句话,就能触发模型的推理能力。
示例:
问题:小明买了3支铅笔,每支2元,又买了一个笔记本,花了5元,他一共花了多少钱?
让我们一步一步来思考。2.2.3 少样本思维链(Few-Shot CoT)
在示例中展示完整的推理过程,效果比零样本思维链更好。
示例:
任务:解决数学应用题
示例1:
问题:一个长方形的长是5厘米,宽是3厘米,它的周长是多少厘米?
回答:让我们一步一步来思考。
1. 长方形的周长公式是:周长=2×(长+宽)
2. 已知长=5厘米,宽=3厘米
3. 代入公式:周长=2×(5+3)=2×8=16厘米
所以,长方形的周长是16厘米。
问题:一个正方形的边长是4米,它的面积是多少平方米?
回答:效果对比:
- 普通提示:数学题准确率约 30%
- 零样本思维链:准确率约 60%
- 少样本思维链:准确率约 80%
2.3 角色与风格控制
通过角色设定和风格控制,可以让模型的输出更符合特定场景的需求。
2.3.1 角色设定法
赋予模型特定的专业身份,让它站在该角色的角度思考和回答问题。
角色设定公式 :你是一位[经验年限]的[职业],擅长[技能],[行为准则]。
示例:
你是一位拥有20年临床经验的儿科医生,擅长儿童常见病的诊断和治疗,说话温和、有耐心,会用通俗易懂的语言向家长解释病情。常见角色:
- 技术类:资深开发工程师、架构师、数据分析师
- 教育类:小学老师、大学教授、英语外教
- 商业类:产品经理、市场营销专家、财务顾问
- 生活类:营养师、健身教练、心理咨询师
2.3.2 风格控制
指定输出的语气、文体、专业程度和长度。
常见风格参数:
| 参数 | 可选值 |
|---|---|
| 语气 | 正式、非正式、幽默、严肃、亲切、专业 |
| 文体 | 记叙文、说明文、议论文、诗歌、散文、邮件、报告 |
| 专业程度 | 小白友好、入门级、中级、高级、专家级 |
| 长度 | 一句话、简短、中等、详细、长篇大论 |
示例:
用小学生能听懂的语言,简短地解释什么是黑洞。
用正式、专业的语气,写一封给客户的道歉邮件,说明产品延迟发货的原因,并提出解决方案。2.3.3 角色 + 风格组合示例
你是一位幽默风趣的历史老师,擅长用讲故事的方式讲解历史事件。请用生动有趣的语言,给初中生讲解三国时期的赤壁之战,字数800字左右。2.4 结构化输出控制
结构化输出是大模型应用开发中最重要的技巧之一,它能让模型输出可被程序直接解析的格式,无需额外的文本处理。
2.4.1 常见输出格式
| 格式 | 适用场景 | 优点 |
|---|---|---|
| Markdown | 文档、报告、文章 | 结构清晰,易于阅读 |
| JSON | API 调用、数据提取 | 可被程序直接解析 |
| XML | 数据交换、配置文件 | 标签化,易于解析 |
| CSV | 表格数据 | 可直接导入 Excel |
| 表格 | 数据对比、统计 | 直观易懂 |
2.4.2 JSON 格式输出(最常用)
JSON 是大模型应用开发中最常用的输出格式,几乎所有的大模型都支持 JSON 输出。
语法:
请提取以下文本中的信息,输出为JSON格式,格式如下:
{
"字段1": "值1",
"字段2": "值2",
"字段3": ["值3-1", "值3-2"]
}
文本:[需要提取的文本]示例:
请提取以下文本中的人名、地名和时间,输出为JSON格式,格式如下:
{
"names": ["姓名1", "姓名2"],
"places": ["地名1", "地名2"],
"times": ["时间1", "时间2"]
}
文本:2023年10月1日,张三和李四一起去北京天安门广场观看升旗仪式。模型输出:
json
javascript
{
"names": ["张三", "李四"],
"places": ["北京天安门广场"],
"times": ["2023年10月1日"]
}2.4.3 代码示例:调用 OpenAI API 实现结构化输出
python
python
from openai import OpenAI
# 初始化客户端
client = OpenAI(api_key="你的API_KEY")
# 提示词
prompt = """
请提取以下文本中的产品信息,输出为JSON格式,格式如下:
{
"product_name": "产品名称",
"price": "价格",
"color": "颜色",
"features": ["特点1", "特点2", "特点3"]
}
文本:这款iPhone 15 Pro手机,售价9999元,有黑色、白色和蓝色三种颜色,搭载A17 Pro芯片,支持USB-C接口,拍照效果非常好。
"""
# 调用API
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0, # 温度设为0,保证输出确定性
response_format={"type": "json_object"} # 强制输出JSON格式
)
# 解析输出
import json
result = json.loads(response.choices[0].message.content)
print(result)
print("产品名称:", result["product_name"])
print("价格:", result["price"])运行结果:
javascript
{'product_name': 'iPhone 15 Pro', 'price': '9999元', 'color': ['黑色', '白色', '蓝色'], 'features': ['搭载A17 Pro芯片', '支持USB-C接口', '拍照效果非常好']}
产品名称: iPhone 15 Pro
价格: 9999元2.4.4 表格格式输出
适用于数据对比、统计等场景。
示例:
请对比以下三款手机的参数,输出为Markdown表格。
手机1:iPhone 15,售价5999元,屏幕6.1英寸,处理器A16,电池3279mAh
手机2:华为Mate 60,售价5999元,屏幕6.69英寸,处理器麒麟9000S,电池4750mAh
手机3:小米14,售价3999元,屏幕6.36英寸,处理器骁龙8 Gen3,电池4610mAh模型输出:
| 手机型号 | 售价 | 屏幕尺寸 | 处理器 | 电池容量 |
|---|---|---|---|---|
| iPhone 15 | 5999 元 | 6.1 英寸 | A16 | 3279mAh |
| 华为 Mate 60 | 5999 元 | 6.69 英寸 | 麒麟 9000S | 4750mAh |
| 小米 14 | 3999 元 | 6.36 英寸 | 骁龙 8 Gen3 | 4610mAh |
第三章 高级提示技巧层(解决复杂推理与规划问题)
3.1 多路径推理增强
对于高风险、高复杂度的推理任务,单一的推理路径可能会出错。多路径推理增强通过让模型生成多个不同的推理路径,然后选择最优的结果,大幅提升准确率。
3.1.1 自洽性(Self-Consistency)
自洽性方法的核心思想是:正确的答案往往会被更多的推理路径得到。

实现步骤:
- 设置较高的温度系数(如 0.7),让模型生成多个不同的推理路径和答案
- 生成 N 个结果(一般为 5-10 个)
- 统计每个答案出现的次数
- 选择出现次数最多的答案作为最终结果
3.1.2 代码示例:自洽性方法实现
python
from openai import OpenAI
from collections import Counter
client = OpenAI(api_key="你的API_KEY")
def self_consistency_answer(question, num_samples=5):
answers = []
prompt = f"""
请解决以下数学问题,展示详细的推理过程,并在最后给出最终答案。
问题:{question}
让我们一步一步来思考。
"""
for i in range(num_samples):
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.7 # 较高的温度,生成不同的结果
)
answer = response.choices[0].message.content
# 提取最终答案(这里简单处理,实际应用中需要更复杂的提取逻辑)
final_answer = answer.split("所以")[-1].strip()
answers.append(final_answer)
print(f"结果{i+1}:{final_answer}")
# 统计出现次数最多的答案
counter = Counter(answers)
most_common = counter.most_common(1)[0]
print(f"\n最终答案(自洽性):{most_common[0]},出现次数:{most_common[1]}")
return most_common[0]
# 测试
question = "一个数加上5,乘以3,减去10,再除以2,结果是10。这个数是多少?"
self_consistency_answer(question, num_samples=5)运行结果:
结果1:这个数是5。
结果2:这个数是5。
结果3:这个数是5。
结果4:这个数是5。
结果5:这个数是5。
最终答案(自洽性):这个数是5。,出现次数:53.1.3 思维树(Tree of Thoughts, ToT)
思维树是思维链的进阶,它将复杂问题分解为多个步骤,每个步骤生成多个可能的解决方案,形成树状结构,然后评估和剪枝,最终找到最优解。
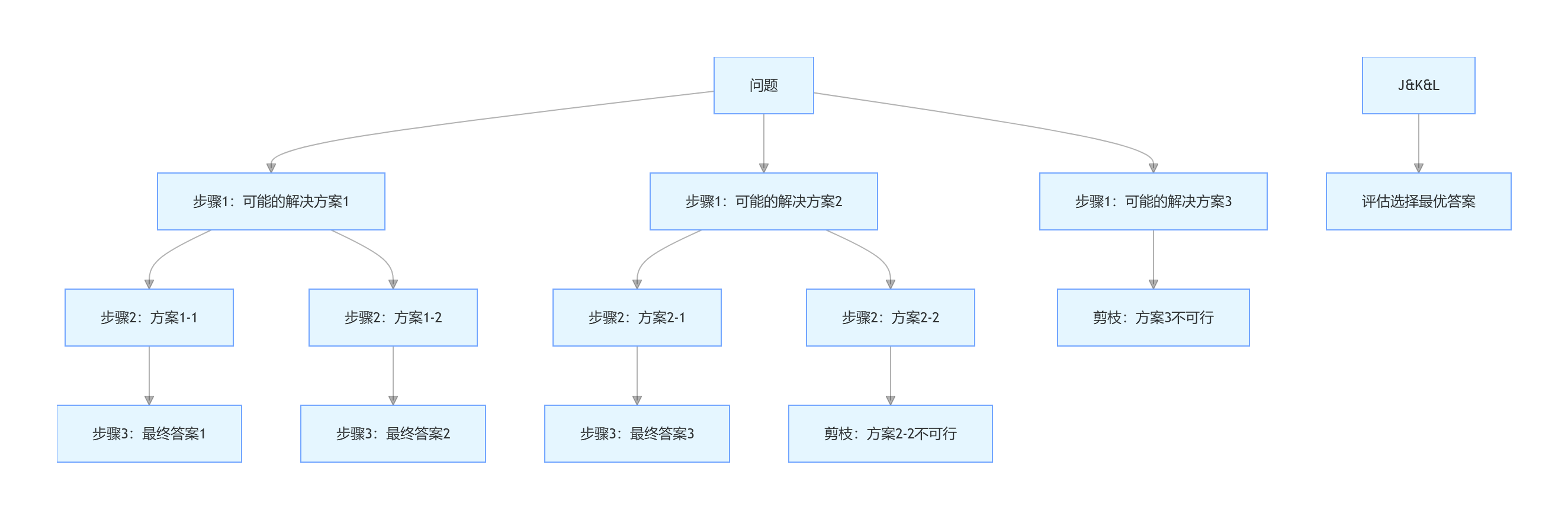
图 3-2:思维树(ToT)结构示意图
适用场景:
- 创意写作(如写小说、策划方案)
- 复杂问题解决(如数学证明、逻辑谜题)
- 策略规划(如项目计划、旅行攻略)
示例:
请用思维树的方法,为我制定一个3天的北京旅游攻略。
要求:
1. 每天的行程不要太赶
2. 包含必去的景点
3. 推荐当地的美食
4. 考虑交通和住宿
请按照以下步骤思考:
步骤1:列出北京必去的景点和美食
步骤2:根据地理位置将景点分组,规划每天的行程
步骤3:为每天的行程添加美食推荐和交通建议
步骤4:评估每个方案的可行性,选择最优方案3.2 自我反思与修正
自我反思与修正通过让模型对自己的输出进行批评和修正,进一步提升输出质量。
3.2.1 反思提示(Reflection)
反思提示的核心流程是:生成初步答案 → 反思不足 → 修正答案
语法:
请先回答以下问题,然后反思你的答案是否正确,是否有遗漏或错误,最后给出修正后的答案。
问题:[你的问题]示例:
请先回答以下问题,然后反思你的答案是否正确,是否有遗漏或错误,最后给出修正后的答案。
问题:如何提高大模型RAG系统的准确率?模型输出结构:
初步答案:
[模型生成的初步答案]
反思:
1. 遗漏了重排序技术
2. 没有提到文档分块策略的优化
3. 对向量数据库的选择描述不够详细
修正后的答案:
[修正后的完整答案]3.2.2 自我批评提示(Self-Criticism)
专门让模型扮演批评者的角色,指出初步结果的问题。
语法:
请先回答以下问题,然后扮演一个严格的批评者,指出你答案中的所有缺点和不足,最后根据批评意见给出改进后的答案。
问题:[你的问题]3.2.3 迭代优化提示
通过多轮对话,逐步优化模型的输出结果。
示例流程:
- 用户:
帮我写一个产品介绍文案 - 模型:生成第一版文案
- 用户:
这个文案太正式了,能不能更活泼一点,更吸引年轻人? - 模型:生成第二版文案
- 用户:
再突出一下产品的性价比优势 - 模型:生成第三版文案
3.3 工具调用与规划提示
大模型本身存在很多能力短板(如无法获取实时信息、无法进行精确计算、无法操作外部工具)。工具调用与规划提示让大模型能够调用外部工具,弥补这些短板。
3.3.1 Function Calling(函数调用)
Function Calling 是 OpenAI 推出的一项功能,它允许大模型根据用户的问题,自动决定是否需要调用外部工具,并生成工具调用的参数。
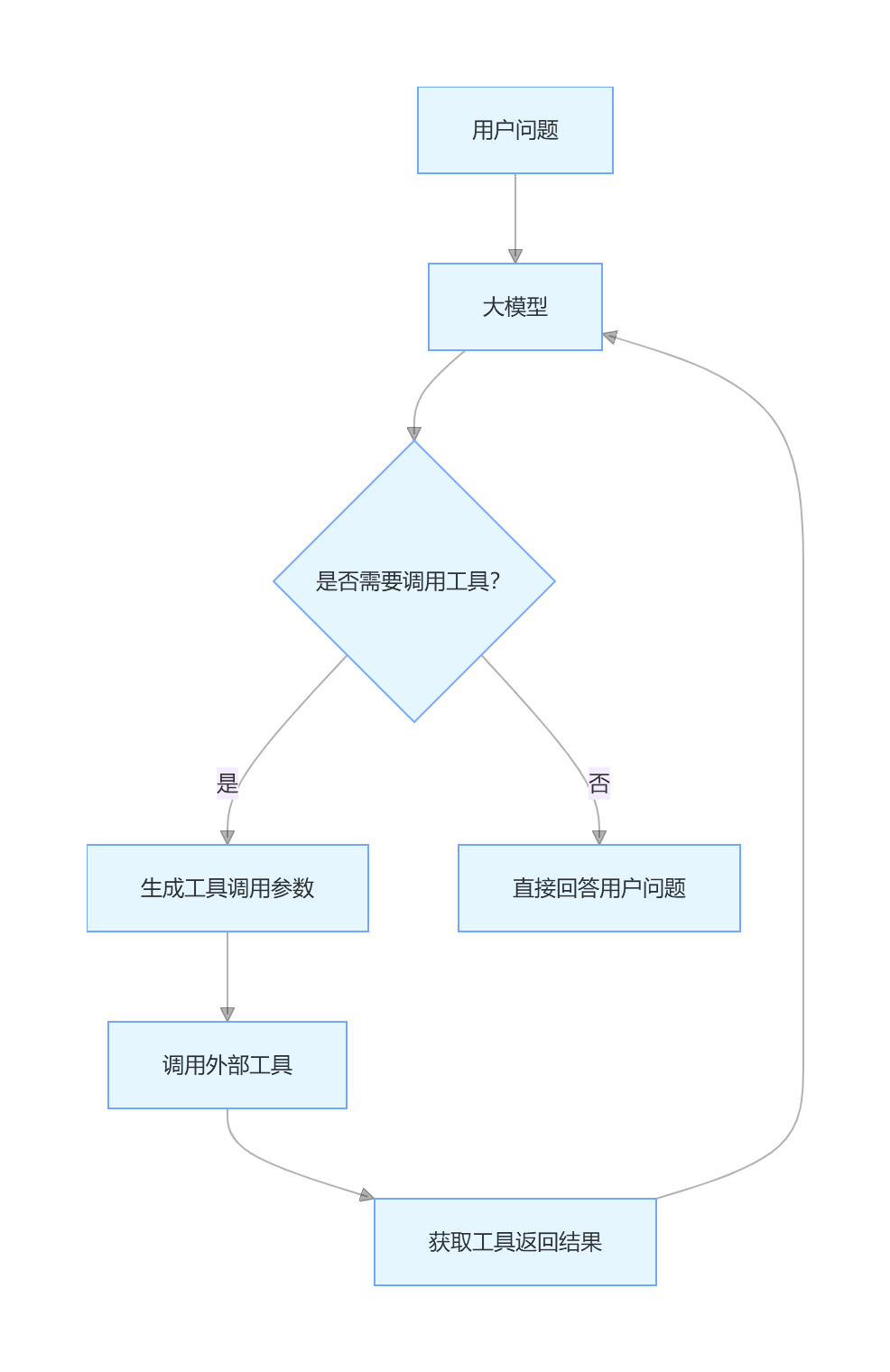
3.3.2 代码示例:Function Calling 实现天气查询
python
from openai import OpenAI
import json
import requests
client = OpenAI(api_key="你的API_KEY")
# 定义工具函数:获取天气信息
def get_weather(city):
"""获取指定城市的天气信息"""
# 这里使用一个免费的天气API,实际应用中可以替换为自己的API
url = f"https://api.openweathermap.org/data/2.5/weather?q={city}&appid=你的天气API_KEY&units=metric"
response = requests.get(url)
data = response.json()
if data["cod"] == 200:
weather = {
"city": city,
"temperature": data["main"]["temp"],
"description": data["weather"][0]["description"],
"humidity": data["main"]["humidity"]
}
return json.dumps(weather)
else:
return json.dumps({"error": "无法获取天气信息"})
# 定义工具描述
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,如北京、上海"
}
},
"required": ["city"]
}
}
}
]
def chat_with_tools(message):
messages = [{"role": "user", "content": message}]
# 第一次调用API,让模型决定是否调用工具
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
tools=tools,
tool_choice="auto"
)
response_message = response.choices[0].message
messages.append(response_message)
# 如果模型需要调用工具
if response_message.tool_calls:
for tool_call in response_message.tool_calls:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
# 调用工具函数
if function_name == "get_weather":
function_response = get_weather(function_args["city"])
# 将工具返回结果添加到消息中
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": function_name,
"content": function_response
})
# 第二次调用API,让模型根据工具返回结果回答问题
second_response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
return second_response.choices[0].message.content
else:
# 不需要调用工具,直接返回答案
return response_message.content
# 测试
print(chat_with_tools("今天北京的天气怎么样?"))运行结果:
今天北京的天气情况如下:
- 温度:22℃
- 天气状况:晴
- 湿度:45%3.3.3 ReAct 框架
ReAct 框架将推理(Reasoning)和行动(Acting)结合起来,让模型在思考和行动之间交替进行,逐步解决复杂问题。
ReAct 流程:
- 思考(Thought):模型思考下一步要做什么
- 行动(Action):模型调用工具执行操作
- 观察(Observation):模型获取工具返回的结果
- 重复以上步骤,直到完成任务
示例:
问题:2024年奥运会在哪里举办?
Thought:我需要知道2024年奥运会的举办地点,这是实时信息,我需要调用搜索引擎。
Action:搜索("2024年奥运会举办地点")
Observation:2024年夏季奥林匹克运动会将在法国巴黎举办。
Thought:我已经知道了答案,可以回答用户了。
Answer:2024年奥运会将在法国巴黎举办。3.3.4 计划与执行(Plan-and-Execute)
计划与执行框架先让模型制定一个详细的执行计划,然后按照计划逐步执行。适用于复杂的多步骤任务。
示例:
请帮我分析一下2023年中国新能源汽车市场的发展情况,并生成一份分析报告。
请按照以下步骤执行:
1. 制定一个详细的分析计划,包括需要收集的数据和分析的维度
2. 收集2023年中国新能源汽车市场的相关数据(销量、增长率、市场份额等)
3. 分析市场的主要趋势和特点
4. 分析主要厂商的表现
5. 预测2024年的市场发展趋势
6. 生成一份完整的分析报告3.4 多轮对话提示设计
多轮对话是大模型应用中最常见的场景,如智能客服、聊天机器人、个人助理等。
3.4.1 上下文管理
大模型的上下文窗口是有限的,需要合理管理对话历史,保留关键信息,删除无关信息。
上下文管理技巧:
- 滚动上下文:只保留最近的 N 轮对话
- 摘要上下文:定期对对话历史进行摘要,保留关键信息
- 关键信息提取:提取对话中的关键信息(如用户姓名、需求、偏好),单独存储
3.4.2 状态保持
在多轮对话中保持角色、任务和上下文的一致性。
示例:
【系统提示】
你是一个智能客服,负责回答用户关于产品的问题。
用户信息:姓名:张三,购买了我们的iPhone 15手机,订单号:123456。
你的任务是:
1. 用亲切的语气回答用户的问题
2. 不要泄露其他用户的信息
3. 如果无法回答用户的问题,引导用户转人工客服3.4.3 引导式提问
当用户的需求不明确时,通过提问的方式引导用户提供完成任务所需的信息。
示例:
用户:我想退货。
客服:您好,请问您是要退哪件商品呢?订单号是多少?
用户:订单号123456,iPhone 15。
客服:好的,请问您退货的原因是什么呢?
用户:手机有质量问题,屏幕有亮点。
客服:了解了,我马上为您办理退货手续。请您将手机寄回以下地址:...3.4.4 对话终止条件
明确任务完成的标准,避免无限循环。
常见终止条件:
- 用户明确表示任务完成
- 所有问题都已解决
- 用户要求结束对话
本文详细讲解了提示工程的基础理论、基础技巧和高级技巧,涵盖了从 0 基础到进阶的核心内容。通过学习本文,你已经能够:
- 理解提示工程的核心原理和设计原则
- 写出清晰、有效的提示词
- 使用思维链、角色设定、结构化输出等基础技巧
- 使用自洽性、自我反思、工具调用等高级技巧
- 设计多轮对话提示