基本原理
Elasticsearch 的 Enrich 功能通过以下流程实现数据 enrichment:首先,基于源索引(source index)通过 Enrich Policy 提前生成中间缓存索引(enrich index),该缓存索引不支持实时或局部更新,只能全局更新;同时会对缓存索引进行优化以支持高效的反向查询。后续在目标索引(target index)的数据写入、更新或重建过程中,系统会反向查询中间缓存索引,将所需数据补充到目标索引中,从而实现数据的丰富处理。
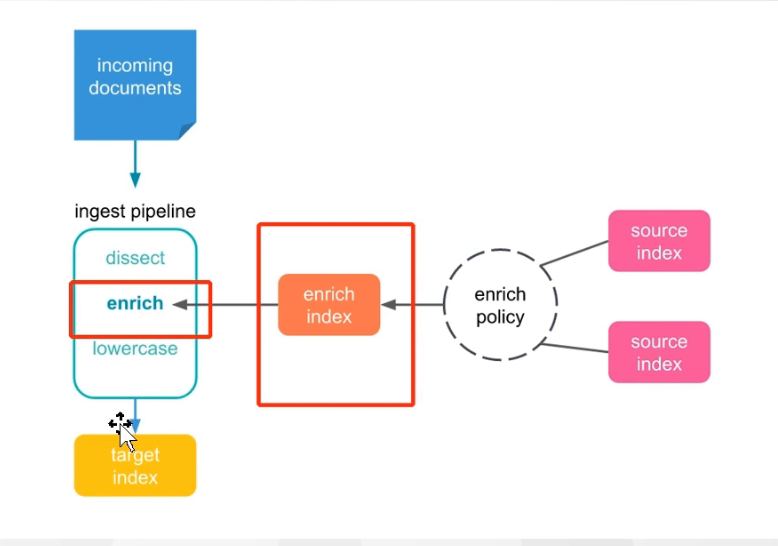
在接下来的文章中使用的是出租车打车的两个数据来演示enrich进行大宽表的设计:
PUT green_tripdata_2026/_doc/1
{
"improvement_surcharge": "0.3",
"passenger_count": "1",
"payment_type": "2",
"tip_amount": "0",
"fare_amount": "8",
"@timestamp": "2023-02-06T15:31:39.264196541Z",
"RatecodeID": "1",
"mta_tax": "0.5",
"store_and_fwd_flag": "N",
"ehail_fee": null,
"tolls_amount": "0",
"lpep_pickup_datetime": "2020-12-31 23:57:51",
"VendorID": "2",
"trip_distance": "1.99",
"congestion_surcharge": "0",
"lpep_dropoff_datetime": "2021-01-01 00:04:56",
"total_amount": "9.3",
"trip_type": "1",
"PULocationID": "168",
"extra": "0.5",
"DOLocationID": "75"
}
PUT taxi_zone_2026/_doc/1
{
"LocationID": "33",
"service_zone": "Boro Zone",
"@timestamp": "2023-02-06T15:18:12.161902885Z",
"Borough": "Brooklyn",
"Zone": "Brooklyn Heights"
}
PUT taxi_zone_2026/_doc/2
{
"LocationID": "75",
"service_zone": "Boro Zone",
"@timestamp": "2023-02-06T15:18:12.161902885Z",
"Borough": "Brooklyn",
"Zone": "Brooklyn Heights"
}
PUT taxi_zone_2026/_doc/3
{
"LocationID": "168",
"service_zone": "Boro Zone",
"@timestamp": "2023-02-06T15:18:12.161902885Z",
"Borough": "Brooklyn",
"Zone": "Brooklyn Heights"
} 实战案例展示
在上面的 例子中,我们的源数据(source_data)就是taxi_zone这个数据,
创建enrich策略
这里需要注意:创建之后还没有执行,也就是没有形成缓存的index
PUT _enrich/policy/taxi_zone_lookup_policy_001
{
"match": {
"indices": "taxi_zone_2026",
"match_field": "LocationID",
"enrich_fields": [
"service_zone","Borough","Zone"
]
}
}-
`indices`:定义Enrich策略的**数据源索引**,即用于提供补充信息的维表/字典索引,所有匹配和字段补充操作均基于该索引的数据执行。
-
`match_field`:指定数据源索引中**用于匹配的关键字段**,Enrich处理器将以此字段的值为依据,与主数据中对应字段的值进行关联匹配。
-
`enrich_fields`:定义匹配成功后,需要从数据源索引中**追加到目标文档中的字段列表**,这些字段的值将被自动复制并补充到主数据中,实现数据富化。
执行策略:
就是生成缓存的enrich index
POST _enrich/policy/taxi_zone_lookup_policy_001/_execute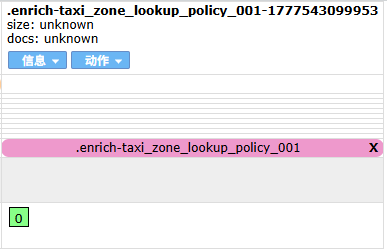
执行之后我们可以发现生成了索引。
关于这里小编总结了一些他的特性:
- Enrich 缓存索引由 Elasticsearch 内部自动创建,属于系统级只读索引,用户无需手动定义。
- 该类索引受系统机制保护,禁止手动直接删除,手动删除操作会直接报错。
- 执行
_execute命令刷新 Enrich 策略时,会生成全新版本的富化缓存索引。 - 新版本缓存索引生效后,旧索引会被标记为待删除,由 ES 后台进程自动回收清理。
- 常规运行状态下,集群仅保留当前最新一份 Enrich 缓存索引,不会无限堆积。
- 若仅停用富化业务、保留 Enrich 策略不删除,当前生效的缓存索引会永久留存。
- 手动删除 Enrich 策略时,该策略关联的所有版本缓存索引会同步自动清除。
- 集群异常、策略执行中断等特殊场景,可能产生残留的 Enrich 历史索引。
- 残留富化索引可通过
.enrich-*前缀匹配,进行手动强制清理。 - Enrich 索引强依赖对应 Enrich 策略,策略删除则无关联富化缓存索引。
enrich结合ingest pipeline数据处理:
PUT _ingest/pipeline/green_taxi_pipeline
{
"description": "使用enrich创建大宽表 ",
"processors": [
{
"enrich": {
"policy_name": "taxi_zone_lookup_policy_001",
"field": "PULocationID",
"target_field": "pickup_zone"
}
},
{
"enrich": {
"policy_name": "taxi_zone_lookup_policy_001",
"field": "DOLocationID",
"target_field": "dropoff_zone",
"max_matches": "1"
}
}
]
}policy_name
指定当前 enrich 处理器需要绑定的富化策略名称。该参数用于关联预先定义好的 enrich 策略,处理器将依据策略中的匹配规则、数据源索引和补充字段完成数据富化。
field
指定待富化数据中用于关联匹配的字段 。该字段的值会与 enrich 策略中定义的 match_field 进行等值匹配,从而找到对应的维度数据并完成字段补充。
target_field
指定富化结果数据的存放目标字段。匹配成功后,所有从维度表中补充的字段(如区域、行政区、服务 zone)会作为子字段存入该目标字段中。
执行模拟测试:
POST _ingest/pipeline/green_taxi_pipeline/_simulate
{
"docs": [
{
"_source": {
"improvement_surcharge": "0.3",
"passenger_count": "1",
"payment_type": "2",
"tip_amount": "0",
"fare_amount": "8",
"@timestamp": "2023-02-06T15:31:39.264196541Z",
"RatecodeID": "1",
"mta_tax": "0.5",
"store_and_fwd_flag": "N",
"ehail_fee": null,
"tolls_amount": "0",
"lpep_pickup_datetime": "2020-12-31 23:57:51",
"VendorID": "2",
"trip_distance": "1.99",
"congestion_surcharge": "0",
"lpep_dropoff_datetime": "2021-01-01 00:04:56",
"total_amount": "9.3",
"trip_type": "1",
"PULocationID": "168",
"extra": "0.5",
"DOLocationID": "75"
}
}
]
}实战演示--数据更新:
通过修改数据,有ingest中配置的enrich可以完成数据的更新和修改
POST green_tripdata_2026/_update_by_query?pipeline=green_taxi_pipeline
{
"query": {
"match_all": {}
}
}实战演练--索引重建
POST _reindex
{
"source": {
"index":"green_tripdata_2026"
},
"dest": {
"index": "new_index",
"pipeline": "green_taxi_pipeline"
}
}实战演练--数据写入
在直接进行数据的写入时可以指定
POST write_index/_doc?pipeline=green_taxi_pipeline
{
"improvement_surcharge": "0.3",
"passenger_count": "1",
"payment_type": "2",
"tip_amount": "0",
"fare_amount": "8",
"@timestamp": "2023-02-06T15:31:39.264196541Z",
"RatecodeID": "1",
"mta_tax": "0.5",
"store_and_fwd_flag": "N",
"ehail_fee": null,
"tolls_amount": "0",
"lpep_pickup_datetime": "2020-12-31 23:57:51",
"VendorID": "2",
"trip_distance": "1.99",
"congestion_surcharge": "0",
"lpep_dropoff_datetime": "2021-01-01 00:04:56",
"total_amount": "9.3",
"trip_type": "1",
"PULocationID": "168",
"extra": "0.5",
"DOLocationID": "75"
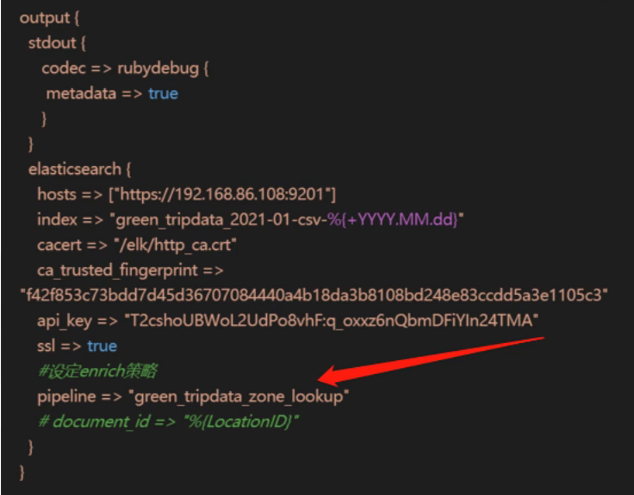
}可以在使用logstash写入时,指定pipeline参数:
logstash这个知识在接下来的文章中会给大家详细的介绍一下.
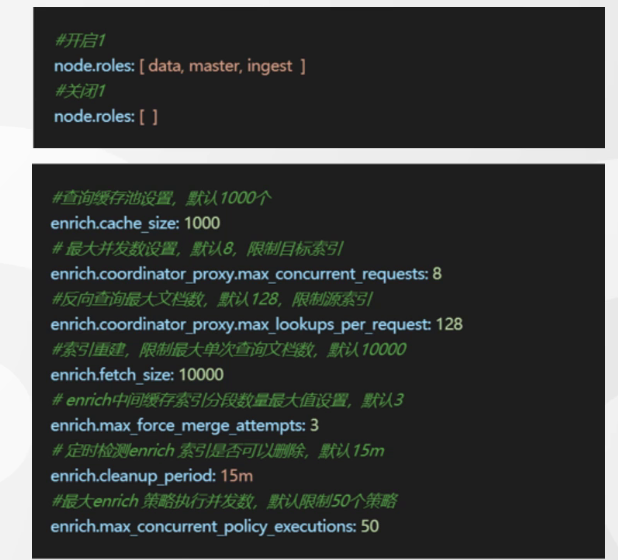
Enrich Node 数据处理节点配置:
我们在使用enrich进行大宽表的生成的时候,会出现很多的反查的逻辑,为了集群的性能,我们可以将集群中的节点作为ingest节点,将其他节点的ingest角色直接禁用.