前言
最近点开大厂的暑期实习 JD,可能会发现一个明显的信号:一类全新的岗位要求正急剧攀升------AI Agent开发。
以字节跳动 为例:
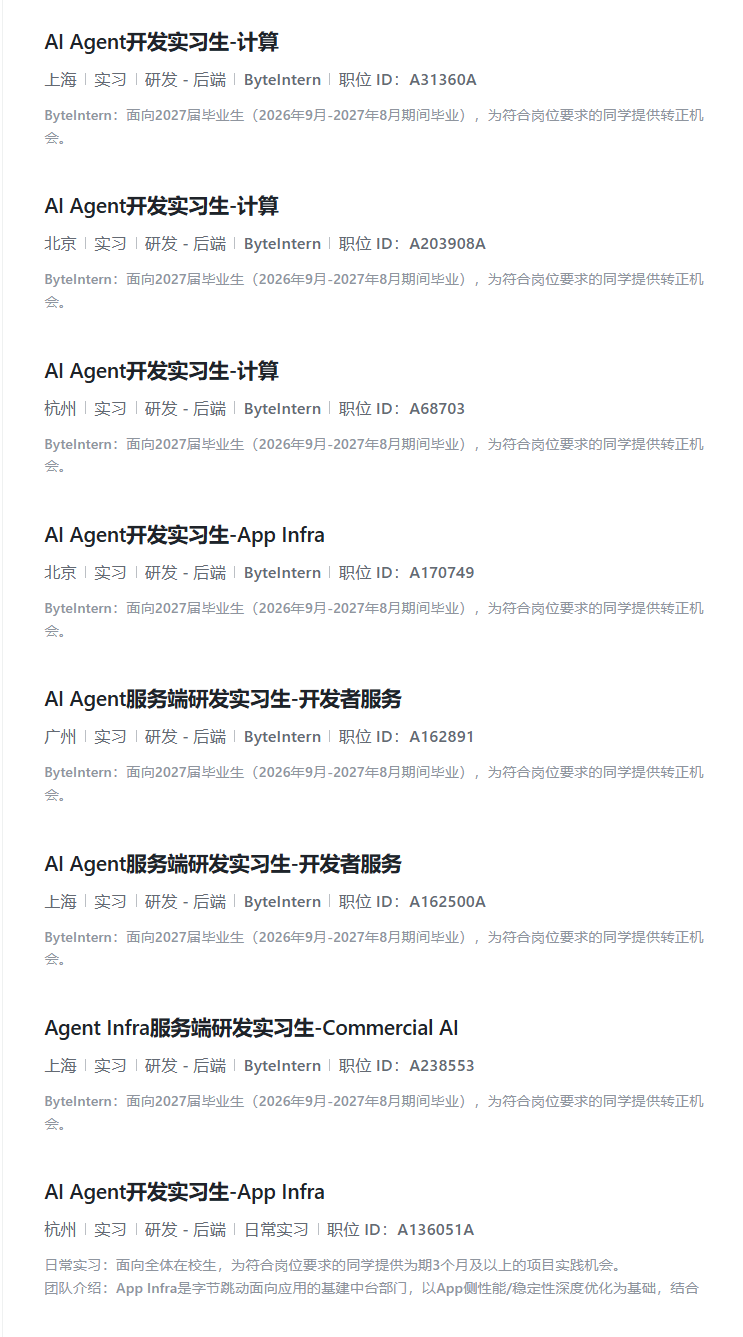
这背后藏着一个尴尬的现实:大语言模型(LLM)本身,其实是一个 token预测机器。
它能用李白的文风写诗,却不知道今天北京有没有下雨;它能用 30 秒解完一道高数证明题,却没法帮你发一封邮件或抓取一份最新的 PDF 财报。
更致命的是,它经常在信息盲区中毫不脸红地编造事实------也就是臭名昭著的 "幻觉"。
于是 Agent(智能体) 应运而生。它不再只是"调用模型",而是让模型变成一个可以 使用工具、感知反馈、自主决策 的代理。
但麻烦也来了:思考要怎么编排?行动要如何调度? 一个 Agent 是该先想好全盘计划再动手,还是边想边干、见招拆招?
整个社区不约而同地走向了两条经典路线:ReAct(Reasoning + Acting,推理与行动协同) 和 Plan-and-Execute(先计划后执行)。
那么接下来,我们开始搞懂这些内容。坐稳让我们发车吧。
一、什么是 Agent ------从 LLM 和工具开始
我们之前有讲到: LLM 是被困在一个"信息茧房"里的天才。因为它的训练数据有截止日期,并且没有感知实时世界的额能力。
为了解决这一痛点,诞生了 Tools.
工具(Tools) 就是让这个大脑长出手脚的机会。搜索引擎、计算器、代码解释器、API 调用、数据库查询,这些都属于工具。它们能真正被调用来行动或获取最新信息。
但工具自己是"死"的,不会主动判断什么时候该被调用。所以这时。Agent 则站上了 AI 领域的舞台。
Agent(智能体) 则是把 LLM 和工具粘在一起的"神经系统"。它的核心能力是:
- **思考:**接下来应该做什么
- **行动:**选择性调用工具,产生对外影响
于是,Agent 不再是一个只会说"作为一个人工智能,我无法......"的聊天框,而变成了可以 自主执行多步任务 的智能体。一个最小化 Agent 循环就是:思考 → 行动 → 再思考...... 直到目标完成。
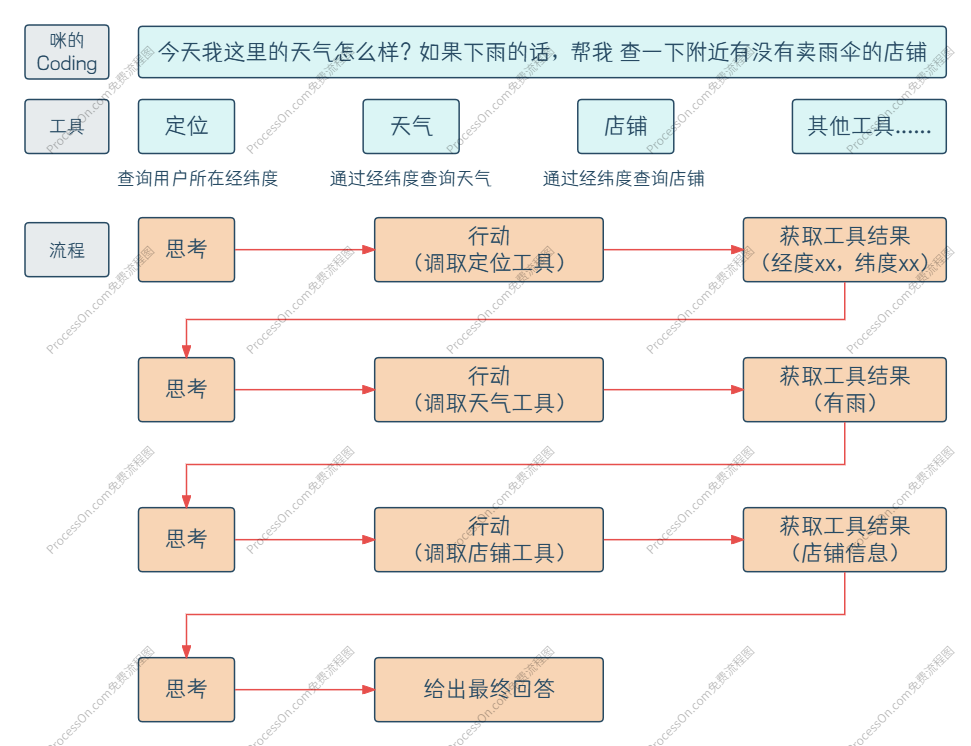
到这里我们也就知道了 Agent 的一个重要特性:自主性。它就像人一样会在思考后决定自己的行为。
这个循环听起来很自然,但真正让它在工程上跑起来,需要解决一个关键问题:如何编排"推理"和"行动"的顺序? 是每一步都推理并立即行动,还是全局规划好再分步执行?这就引出了两大流派:ReAct 和 Plan-and-Execute。
二、Agent 主流范式(一):ReAct ------ 推理与行动交织
ReAct 是当前最通用、最灵活的 Agent 范式,几乎成了"LLM Agent"的代名词。它的名字本身就是 Reasoning(推理) + Acting(行动) 的合成词,很好地说明了它的本质:将思考步骤与工具调用步骤像纺线一样交织在一起。
1. 从 CoT 与 Act-only 到 ReAct
要理解 ReAct 为何出现,我们必须先了解它的两个"前辈"------思维链(CoT) 和 纯行动(Act-only) 。
CoT:一步一步地想,但闭门造车
思维链(Chain-of-Thought, CoT)是一种提示技术,让模型在给出最终答案前,先生成一系列中间推理步骤。比如:
用户 :一个班有 30 个学生,今天新来了 5 个,然后走了 3 个,又新来了 2 个,现在有多少学生?
标准回答 :34 个。
CoT 回答:一开始 30 个,新来 5 个变成 35 个,走了 3 个变成 32 个,再新来 2 个变成 34 个。所以答案是 34。
CoT 大幅提升了大模型在算术、推理等任务上的表现,尤其配合 few-shot 示例时效果拔群。但它有一个致命缺陷:推理过程完全封闭在模型内部,不与外部世界发生任何交互。
这意味着,当需要实时信息或精确知识时,CoT 极易产生幻觉,而且这种幻觉会沿着思维链传播和放大。
比如你问:"2024 年诺贝尔物理学奖得主的年龄分别是多少?"如果模型不知道获奖者是谁,CoT 可能会编造一个看似合理的名字,然后基于这个假名字编造年龄,全程毫无事实依据。
Act-only:直接动手,缺乏思考
与 CoT 相对,Act-only 让模型上来就直接调用工具,生成动作。比如搜索"2024 年诺贝尔物理学奖得主",但它缺少"我现在需要什么信息、为什么需要这个信息"的思考环节。
当任务稍微复杂(比如需要先提取获奖者姓名,再分别查询出生日期,最后计算岁数),缺乏推理规划的动作序列很容易跑偏。。
ReAct:将推理与行动编织在一起
2023 年的论文《ReAct: Synergizing Reasoning and Acting in Language Models》提出了一种将二者结合的方法:让模型在每一步都显式地输出一段 Thought(思考) ,决定接下来要调用什么工具并采取 Action(行动) ,然后接收环境反馈的 Observation(观察),三者循环递进。
对比 ReAct 与 CoT 的核心区别
关键区别只有一句话:是否与外部世界交互。
- CoT 是一条直线式的内部推理链,所有知识都来自模型参数,推理可能建立在虚假事实上。
- ReAct 则是在推理链上不断插入"与外界的对话节点"。每一次观察都会修正、扩充或推翻模型原本的内部认知,形成一条"推理---行动---观察---推理"的螺旋前进轨迹。
2. ReAct 解决的 LLM 三大痛点
可以说,ReAct 的出现正是为了填上 LLM 在实际应用中最致命的三个坑。
痛点一:事实幻觉(Hallucination)
LLM 生成内容时,总会试图给你一个"看起来合理"的回答,即使它根部不知道事实。在长链条推理中,一个幻觉会像多米诺骨牌那样压垮整个答案。
ReAct 的应对之道是强行用工具执行的客观结果,替代模型想象的虚假事实 。当思考要求"搜索2024年诺奖获奖者",行动返回的 Observation 是真真切切的search("2024年诺奖获奖者") API 返回值,不是捏造出来的。事实被硬生生注入到上下文中,幻觉被从源头掐断。
痛点二:动态适应能力(Dynamic Adaptation)
真实世界的任务极少是一条直线。比如你想做一次竞品分析,搜到某家公司后,发现它旗下还有几个子品牌需要深入调查,这些子品牌是你最初并不知道的。传统 CoT 即使能输出计划,也是静态的,没法在面对新信息时自动调整。
ReAct 的 TAO 循环则具备环境感知与实时决策能力:每一次观察都可能改变之前的想法,下一步的行动是由最新的上下文动态决定的。这种"边看边走"的机制,让 Agent 能够应对高度不确定的复杂场景。
痛点三:决策过程封闭(Closed Decision-Making)
黑箱决策在关键业务中是不可接受的。你没法知道模型到底是一本正经地胡说,还是真的进行了合理推理。
ReAct 将 Thought 显式输出,把整个决策链路像日志一样展平。你可以看到 Agent 每一步在想什么、为什么调用这个工具、拿到什么结果后改变了策略。这种可解释性对调试、审计和信任构建极其重要。
3. 工作原理:TAO 闭环
ReAct 的运行可以抽象为一个不休止的 TAO 闭环 :Thought(思考)→ Action(行动)→ Observation(观察)。
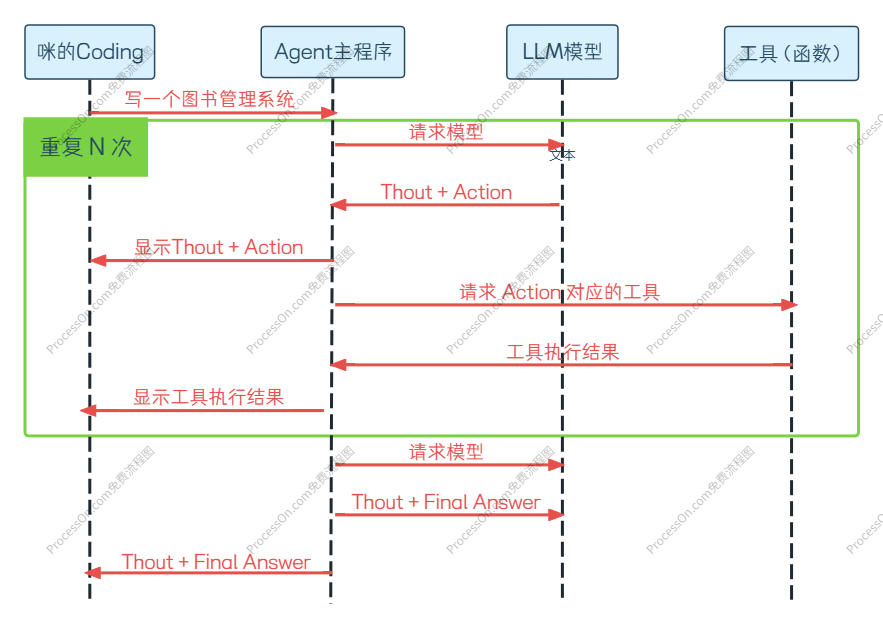
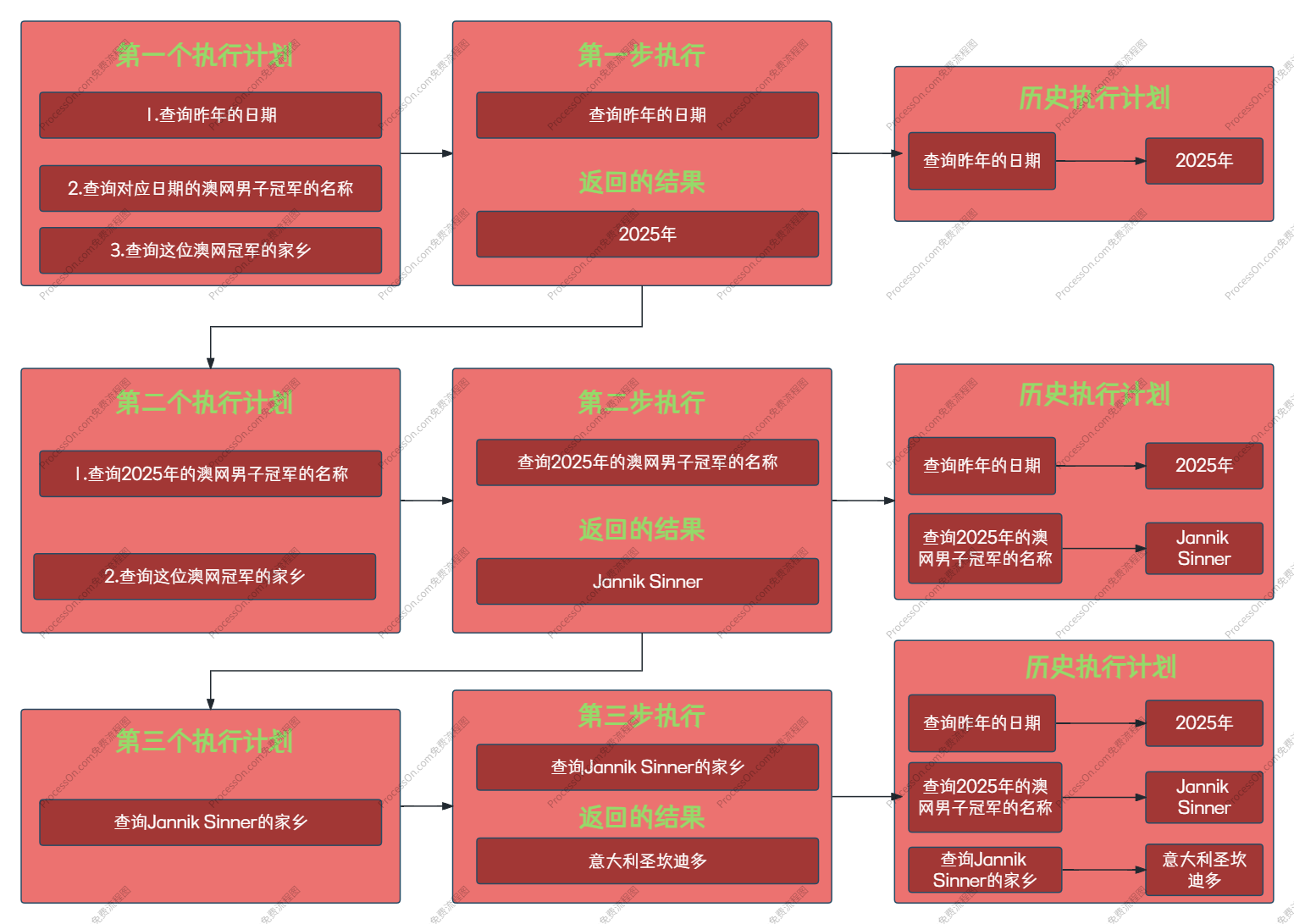
我们用一个实际的多步任务来走一遍流程:"计算 2024 年诺贝尔物理学奖得主的平均年龄。"
-
第 1 轮
- T(思考):我需要先知道 2024 年诺贝尔物理学奖得主是谁。可以用搜索引擎查询。
- A(行动) :
Search[2024 年诺贝尔物理学奖得主] - O(观察):返回 "John Hopfield 和 Geoffrey Hinton......"
-
第 2 轮
- T:现在有了两位得主的名字,我需要分别查询他们的出生日期。先查 John Hopfield。
- A :
Search[John Hopfield 出生日期] - O:返回 "John Hopfield 出生于 1933 年 7 月 15 日。"
-
第 3 轮
- T:得到了 Hopfield 的出生年份,现在去查 Hinton 的出生日期。
- A :
Search[Geoffrey Hinton 出生日期] - O:返回 "Geoffrey Hinton 出生于 1947 年 12 月 6 日。"
-
第 4 轮
- T:我现在有了两人出生年份(1933 和 1947),可以计算他们当前的年龄(假设今年 2026 年),然后求平均值。先计算 Hopfield 年龄:2026 - 1933 = 93。
- A :
Calculator[2026 - 1933] - O:93
-
第 5 轮
- T:再算 Hinton 年龄。
- A :
Calculator[2026 - 1947] - O:79
-
第 6 轮
- T:现在求平均年龄 (93 + 79) / 2。
- A :
Calculator[(93 + 79) / 2] - O:86
-
第 7 轮
- T:平均年龄是 86 岁,我可以完成回答了。
- A :
Finish[2024 年诺贝尔物理学奖得主的平均年龄是 86 岁。]
实际运行中,这个循环一直持续,直到模型输出 "Finish" 或类似的结束动作,或者执行循环层触发了最大步数限制 。每一轮的 Observation 都会被追加到对话上下文中,使模型能在不断增长的真实信息上做推理。
4. 技术架构:三层解耦设计
要在工程上实现如此灵活的交互,最优雅的做法不是把所有逻辑写在一个巨大的脚本里,而是采用三层解耦架构。每一层各司其职,可独立升级、测试。
第一层:核心逻辑层(LLM + Prompt)
这一层只有模型和提示词,负责纯粹的思考与规划,完全不知道工具具体怎么实现。
你需要设计一个精巧的 System Prompt,强制模型按特定格式输出 Thought 和 Action。
该层输出的就是一串字符串,包含 Thought 段和 Action 段。重点在于 Prompt 的约束 ------ 不仅要告诉模型可以使用哪些工具,还要让模型懂得何时该停止(输出 Finish 动作),并维持整个任务的全局目标感。
第二层:执行循环层(代码逻辑)
这是 Agent 的"心跳"。它的本质就是一个 while 循环:
- 调用 LLM 核心逻辑层,得到带 Thought 和 Action 的文本。
- 解析输出,提取 Action 和 Action Input(通常用 JSON 解析)。
- 如果是 Action 是 Final,不需要调用工具,则直接输出结果。
- 否则,根据 Action 的名字去外部交互层匹配对应的工具函数,传入 Action Input 执行。
- 获得工具返回的结果,将其包装为 "Observation: 结果",拼接到对话历史中。
- 把更新后的上下文再次送入 LLM,回到步骤 1。
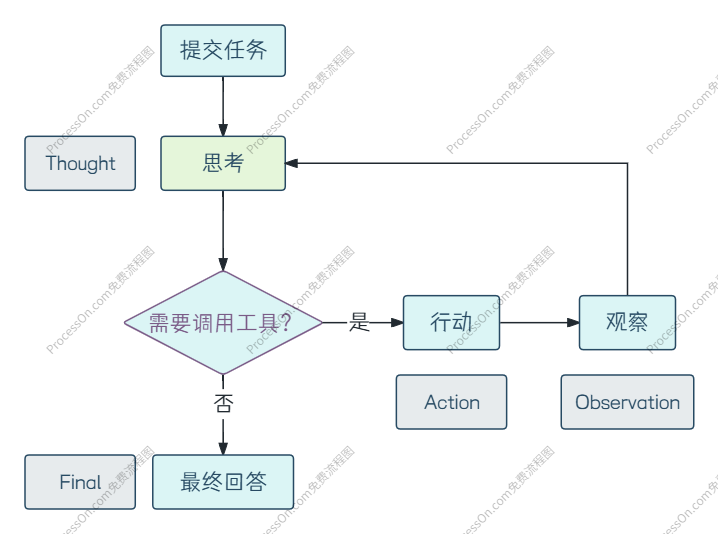
这一层还负责安全网:设置最大循环步数防止死循环,处理解析失败的容错(如让模型重试),以及记录每一步的完整 trace。
第三层:外部交互层(工具 + API)
这是具体干活的工具集合。每个工具可以是一个 Python 函数,并带有一个描述其功能的 schema(类似 Function Calling 中的 JSON Schema)。
工具实现可能是调用谷歌搜索 API、执行 SQL 语句,或者控制一个浏览器。工具返回的字符串会直接作为 Observation 回传给模型。
三层解耦的好处
你可以单独改进 Prompt 提升模型推理质量,单独优化循环逻辑控制成本,单独扩展工具生态而不必动其他部分。这种设计让 Agent 从一个原型,快速成长为一个可以放心迭代的系统。
三、Agent 主流范式(二):Plan-and-Execute ------先谋后动,步步为营
ReAct 虽然强大,但在面对复杂长程任务时容易暴露它的天然短板:走一步看一步,缺乏对全局的俯瞰。这就引入了另一种风格------Plan-and-Execute(计划-执行)。
1. 从 ReAct 的不足到全局规划
ReAct 的局部决策有时像一个人走进了迷宫,每一步都沿着眼前的信息选择方向,却没有一张地图。当任务有十几个子步骤、需要严格顺序或者需要生成结构化输出时(比如写一份包含对比表格和投资建议的竞品分析报告),ReAct 极易出现:
- 路径偏移:搜着搜着去读一篇不相关的文章了。
- 循环困境:多次重复相似的搜索,无法跳出。
- Token 浪费:每个 Thought 和 Action 都在消耗上下文窗口,长任务成本激增。
Plan-and-Execute 借鉴了人类处理大型项目的方法:先制定一个高级计划,再按计划分步执行,遇到偏差时重规划。 它把问题的解决分成显式的两个阶段:规划(Plan) 和 执行(Execute),从而在宏观上锁定了任务骨架。
2. 解决了什么痛点
- 长程任务迷失:有了计划列表作为"待办事项清单",执行器不会忘记最初的最终目标,每一步都是在完成清单上的一个条目。
- 低效试错:规划阶段可以把复杂目标分解成有逻辑顺序的子任务,并识别依赖关系(例如"先下载财报,再计算指标"),减少无效的工具调用。
- 复杂目标分解:让 LLM 一次性规划整个任务,远比让它每走一步都重新做决策要容易,因为规划阶段可以通盘考虑,没有执行噪音的干扰。
3. 工作原理:规划 - 执行 - 重规划
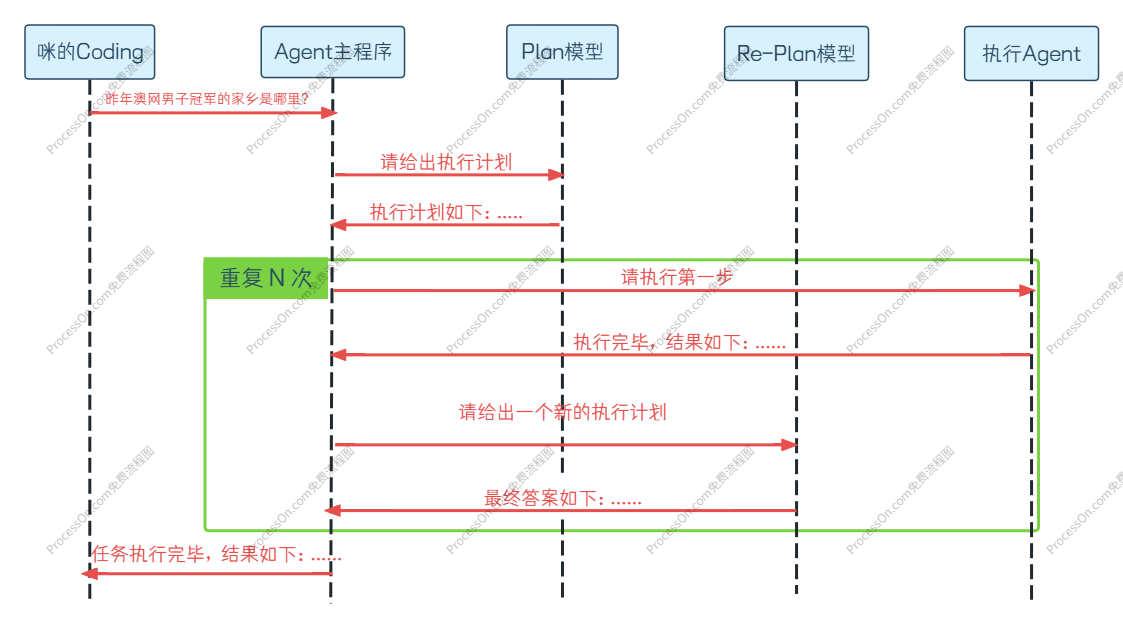
Plan-and-Execute 的典型流程像一个项目管理闭环:
-
规划阶段(Plan)
Planner(通常也是一个 LLM)接受用户目标,输出一个可执行的步骤列表。
-
执行阶段(Execute)
Executor 遍历计划列表,逐条执行。每完成一步,将结果记录到任务状态中。
这里有个关键点:执行器本身也可以是一个 Agent,比如,每一步执行都可以交给一个 ReAct Agent 去完成,以保证子任务也有动态适应力。
-
验证与重规划(Replan)
某一步的执行结果可能暴露计划的不合理。此时,Executor 可以触发重规划,把当前已完成的成果状态发送给 Planner,Planner 生成一个新的修订计划,覆盖未来的步骤。这个循环让整体方案既有确定性,又不失灵活性。
4. 技术架构:同样的三层解耦,不同侧重
Plan-and-Execute 也能完美映射到三层架构,但每层职责重心发生变化:
-
核心逻辑层(LLM + Prompt) :这里通常会区分 Planner 模型 和 Executor 模型 (有时用同一个模型但 Prompt 不同)。Planner 的 Prompt 要求输出结构化的步骤列表(常用 JSON 格式,比如
{"steps": ["...", "..."]})。重规划时,Prompt 还会包含"当前已完成步骤及结果"、"未完成步骤"等上下文,促使它给出修正后的计划。 -
执行循环层(代码逻辑) :不再是简单的单步 while 循环,而是一个任务状态机。它维护一个计划步骤队列、当前步骤指针、已收集的变量池等。循环逻辑是:取下一步 → 交给 Executor 执行 → 将结果保存 → 判断步骤是否失败或是否满足重规划条件 → 若是,调用 Planner 修正后续队列;若否,继续下一步,直到队列清空。
-
外部交互层(工具 + API):与 ReAct 完全一致。只是调用方从"单步思考后立即行动"变成了"计划中的一个步骤任务"。这意味着你的工具库可以同时服务于两种范式,复用性极高。
四、两种范式的对比与融合
下表可以让你一目了然地把握两者的核心差异:
| 维度 | ReAct | Plan-and-Execute |
|---|---|---|
| 决策方式 | 推理与行动交织,边想边干 | 先全局规划,再分步执行 |
| 适用场景 | 探索性、高动态性、需要即时反馈的任务 | 流程明确、步骤多、输出结构化的长程任务 |
| 可解释性 | 每一步思考可见,轨迹细腻 | 计划列表清晰,宏观可读性强 |
| 应对偏差 | 实时动态适应,自然纠偏 | 依赖显式重规划机制 |
| Token 效率 | 每步都有思考与观察,上下文迅速膨胀 | 计划是压缩的指令,初始消耗小 |
| 陷入死循环风险 | 较高,需要步数限制和合理 Prompt 约束 | 较低,有明确的待办项推进 |
在实际开发中,两者不是非黑即白的取舍。越来越多的框架开始混合使用:
用 Plan-and-Execute 做一个整体计划 ,比如"收集资料---分析---写报告",然后在"收集资料"这一步内部调用一个 ReAct Agent 去完成细节操作。
这正是 LangChain 等工具中 Agent 的实现方式,也最符合人类解决问题的方式------整体宏观规划,细节灵活机动。
总结
Agent 的本质,是让大模型自主用工具去触碰、感知并改造世界。而 ReAct 和 Plan-and-Execute,就是两种智慧体现的编排思维与行动模式。
- ReAct 边想边做,通过 TAO 闭环在推理和行动间高速切换,彻底打破了 LLM 的幻觉和不透明,适合动态任务。
- Plan-and-Execute 预先计划,先制定蓝图再步步为营,在偏差时主动调整,更适合解决长链条、结构化的复杂目标。
理解它们的原理与三层解耦架构,是深入 Agent 生态的基石。往后无论是手写 Agent 循环,还是使用 LangGraph、AutoGen 等先进框架,才能做到思考其底层设计的取舍与意图。
感谢你看到这里,如果喜欢的话可以点个关注支持一下吧!也欢迎各位在评论区留言!