Day 19 编程实战:LSTM股价预测
实战目标
- 理解RNN/LSTM处理序列数据的原理
- 掌握滑动窗口创建训练数据的方法
- 用LSTM预测股价并与MLP对比
- 学习时间序列预测的评估方法
1. 导入必要的库
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import time
import warnings
warnings.filterwarnings('ignore')
from pathlib import Path
# TensorFlow / Keras
import tensorflow as tf
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, LSTM, SimpleRNN, Dropout, Input
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# sklearn
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 设置随机种子
np.random.seed(42)
tf.random.set_seed(42)
# 预设样式
sns.set_style("whitegrid")
#启用LaTeX渲染(设为False避免LaTeX依赖)
plt.rcParams['text.usetex'] = False
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['mathtext.fontset'] = 'dejavusans' # 或 'stix'
print(f"TensorFlow版本: {tf.__version__}")TensorFlow版本: 2.20.02. 生成金融数据
python
def get_stock_prices(ts_code):
"""获取股票量价数据"""
data_path = Path(r"E:\AppData\quant_trade\klines\kline2014-2024")
kline_file = data_path / f"{ts_code}.csv"
df = pd.read_csv(kline_file, usecols=["trade_date", "close", "vol"],
parse_dates=["trade_date"])\
.rename(columns={"trade_date": "date", "vol": "volume"})\
.sort_values(by=["date"])\
.reset_index(drop=True)
df = df.dropna()
return df
# 生成数据
ts_code = "300033.SZ"
ts_code = "600519.SH"
df = get_stock_prices(ts_code)
print(f"数据形状: {df.shape}")
print(df.head())
# 可视化股价
plt.figure(figsize=(14, 5))
plt.plot(df['date'], df['close'], linewidth=1)
plt.xlabel('日期')
plt.ylabel('收盘价')
plt.title(f'{ts_code}股价序列')
plt.grid(True, alpha=0.3)
plt.show()数据形状: (2472, 3)
date close volume
0 2014-01-02 86.8822 21976.66
1 2014-01-03 85.5029 23341.65
2 2014-01-06 83.2615 30229.21
3 2014-01-07 83.1443 18039.46
4 2014-01-08 82.3443 31989.59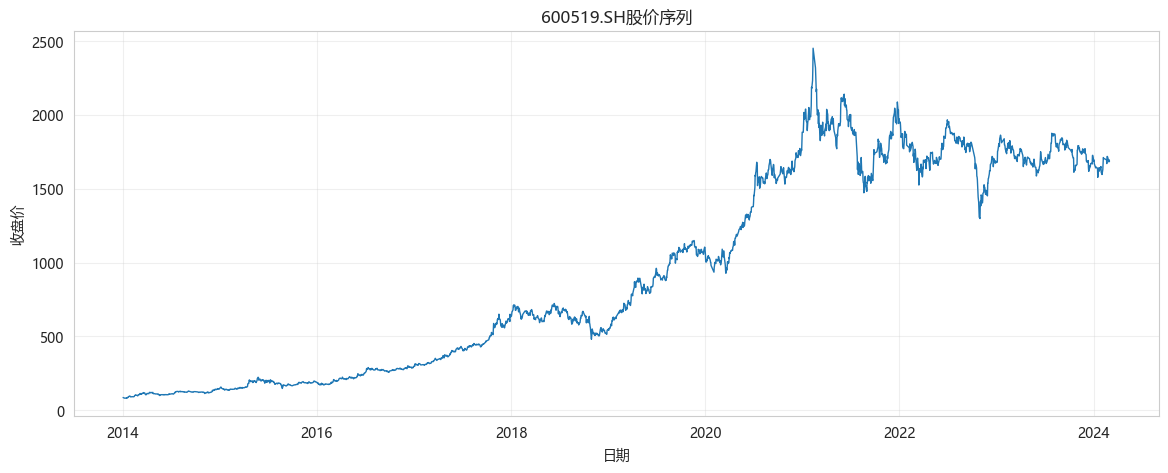
3. 数据预处理
3.1 标准化
python
# 提取收盘价:将一维的"收盘价"列转换为 二维列向量(形状为 (n, 1))
data = df['close'].values.reshape(-1, 1)
# 标准化
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(f"原始价格范围: [{data.min():.2f}, {data.max():.2f}]")
print(f"标准化后范围: [{scaled_data.min():.4f}, {scaled_data.max():.4f}]")
# 可视化标准化的影响
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(data[:200], label='原始价格')
plt.title('原始价格')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(scaled_data[:200], label='标准化后', color='red')
plt.title('标准化后')
plt.legend()
plt.tight_layout()
plt.show()原始价格范围: [81.90, 2450.85]
标准化后范围: [-1.2509, 2.2506]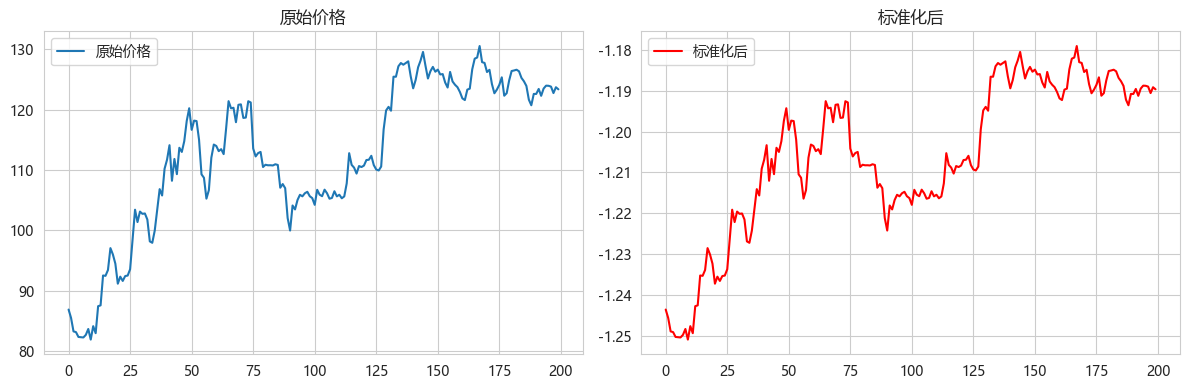
3.2 创建滑动窗口
python
def create_sequences(data, seq_length=20, pred_length=4):
"""创建时间序列滑动窗口
Args:
data: 标准化后的序列数据
seq_length: 输入窗口长度(用过去多少天预测未来)
pred_length: 预测未来多少天的价格,0 表示预测下一交易日的价格
Returns:
X: 输入序列 (n_samples, seq_length, 1)
y: 目标值 (n_samples, 1)
"""
X, y = [], []
for i in range(len(data) - seq_length - pred_length):
X.append(data[i:i+seq_length])
y.append(data[i+seq_length+pred_length])
return np.array(X), np.array(y)
# 设置序列长度
SEQ_LENGTH = 20
# 创建序列
X, y = create_sequences(scaled_data, SEQ_LENGTH)
print(f"X形状: {X.shape}") # (样本数, 时间步, 特征数)
print(f"y形状: {y.shape}")
# 检查数据
print(f"\n第一个输入序列(最近20天):")
print(X[0].flatten())
print(f"第一个目标值(第21天): {y[0][0]:.4f}")
# 可视化一个序列
plt.figure(figsize=(12, 4))
plt.plot(range(SEQ_LENGTH), X[0].flatten(), 'b-o', label='输入序列')
plt.axhline(y=y[0][0], color='r', linestyle='--', label=f'目标值: {y[0][0]:.3f}')
plt.xlabel('时间步')
plt.ylabel('标准化价格')
plt.title('滑动窗口示例(seq_length=20)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()X形状: (2448, 20, 1)
y形状: (2448, 1)
第一个输入序列(最近20天):
[-1.24358771 -1.24562645 -1.24893945 -1.24911268 -1.25029516 -1.25035635
-1.25042774 -1.24979571 -1.24834821 -1.25094759 -1.24765499 -1.24937771
-1.24276205 -1.24255807 -1.23523914 -1.23532058 -1.23388328 -1.22853169
-1.23009123 -1.23234399]
第一个目标值(第21天): -1.2353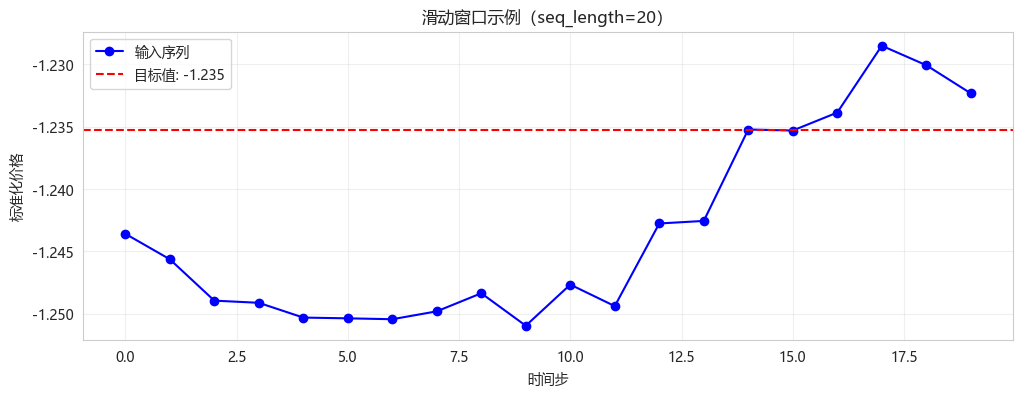
3.3 时间序列划分
python
# 按时间顺序划分(不能随机打乱!)
split_idx = int(len(X) * 0.7)
X_train = X[:split_idx]
y_train = y[:split_idx]
X_test = X[split_idx:]
y_test = y[split_idx:]
print(f"训练集大小: {len(X_train)}")
print(f"测试集大小: {len(X_test)}")
print(f"训练集时间范围: 索引 0-{split_idx}")
print(f"测试集时间范围: 索引 {split_idx}-{len(X)}")
# 验证时间顺序
print(f"\n训练集最后一天预测的是测试集第一天: {split_idx + SEQ_LENGTH}")训练集大小: 1713
测试集大小: 735
训练集时间范围: 索引 0-1713
测试集时间范围: 索引 1713-2448
训练集最后一天预测的是测试集第一天: 17334. LSTM模型构建
4.1 单层LSTM
python
def build_lstm_model(input_shape, units=50, dropout_rate=0.2):
"""
构建一个用于时间序列预测(如股价、天气等)的单层LSTM神经网络模型。
参数说明:
----------
input_shape : tuple
输入数据的形状,不包括批量大小(batch size)。对于LSTM,通常为 (time_steps, features),
例如:(20, 1) 表示使用过去20个时间步的1个特征(如收盘价)来预测下一个值。
units : int, 可选(默认=50)
LSTM层中神经元(记忆单元)的数量。值越大,模型容量越高,但也更容易过拟合。
50 是一个常用的起点,可根据任务复杂度调整。
dropout_rate : float, 可选(默认=0.2)
Dropout 层的丢弃率,用于正则化以防止过拟合。
0.2 表示在训练过程中随机将20%的神经元输出置零。
返回:
-------
model : tf.keras.Model
编译前的Keras顺序模型(Sequential model),可后续调用 compile() 和 fit()。
"""
# 创建一个Keras顺序模型(层按顺序堆叠)
model = Sequential([
# 第一层:LSTM循环神经网络层
LSTM(
units=units, # LSTM单元数量(隐藏状态维度)
activation='tanh', # 输出门的激活函数,控制单元输出范围 [-1, 1]
recurrent_activation='sigmoid', # 遗忘门和输入门的激活函数,输出 [0, 1] 作为门控信号
input_shape=input_shape, # 指定输入形状(仅第一层需要),格式为 (时间步数, 特征数)
return_sequences=False # 是否返回整个序列的输出。False 表示只返回最后一个时间步的输出(适用于单步预测)
),
# 第二层:Dropout 正则化层
Dropout(dropout_rate), # 在LSTM输出上应用Dropout,随机丢弃比例为 dropout_rate 的神经元,
# 以减少神经元间的共适应性,提升泛化能力
# 第三层:全连接(Dense)输出层
Dense(1) # 单个神经元的全连接层,无激活函数(默认 linear),
# 用于回归任务(如预测下一个时间点的连续值,例如股价)
])
# 返回构建好的模型实例
return model
# 构建模型
input_shape = (SEQ_LENGTH, 1)
lstm_model = build_lstm_model(input_shape, units=50, dropout_rate=0.2)
print("LSTM模型结构:")
lstm_model.summary()LSTM模型结构:Model: "sequential_12"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ lstm_9 (LSTM) │ (None, 50) │ 10,400 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_18 (Dropout) │ (None, 50) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_24 (Dense) │ (None, 1) │ 51 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘ Total params: 10,451 (40.82 KB) Trainable params: 10,451 (40.82 KB) Non-trainable params: 0 (0.00 B)说明
-
为什么
return_sequences=False?- 当任务是单步预测(如用过去20天预测第21天的收盘价)时,我们只需要最后一个时间步的输出,因此设为 False。
- 如果是多步预测或序列到序列任务(如机器翻译),则需设为 True,并可能堆叠多个LSTM层。
-
激活函数的选择
tanh和sigmoid是LSTM的标准激活函数组合:tanh用于候选记忆和最终输出,提供非线性且有界;sigmoid用于门控机制(遗忘门、输入门、输出门),决定信息保留/丢弃的比例。
-
总结:
该函数封装了一个简洁、常用的时间序列预测LSTM架构,适合入门和快速实验。通过调整
units和dropout_rate可平衡模型容量与泛化能力。
4.2 双层LSTM
python
def build_stacked_lstm_model(input_shape, units_1=64, units_2=32, dropout_rate=0.2):
"""
构建一个双层堆叠(Stacked)LSTM模型,适用于更复杂的时间序列建模任务(如多步依赖、非线性模式捕捉)。
参数说明:
----------
input_shape : tuple
输入数据的形状(不包括 batch size),格式为 (time_steps, features)。
例如:(50, 2) 表示每个样本包含过去50个时间步,每步有2个特征(如开盘价、成交量)。
units_1 : int, 可选(默认=64)
第一层LSTM的神经元数量。通常第一层设置得较大,以提取丰富的时序特征。
units_2 : int, 可选(默认=32)
第二层LSTM的神经元数量。通常小于或等于第一层,实现特征压缩与抽象。
dropout_rate : float, 可选(默认=0.2)
每个Dropout层的丢弃率,用于正则化,防止过拟合。在训练中随机屏蔽部分神经元输出。
返回:
-------
model : tf.keras.Model
未编译的Keras顺序模型,可后续调用 compile() 配置优化器和损失函数。
"""
# 创建一个Keras顺序模型(Sequential),按顺序堆叠神经网络层
model = Sequential([
# === 第一层:LSTM(返回完整序列)===
LSTM(
units=units_1, # 第一层LSTM单元数(隐藏状态维度)
activation='tanh', # 输出激活函数:tanh,将输出限制在 [-1, 1]
recurrent_activation='sigmoid', # 循环门控激活函数:sigmoid,控制信息流动 [0, 1]
input_shape=input_shape, # 指定输入形状(仅第一层需要),如 (时间步, 特征数)
return_sequences=True # 关键!返回每个时间步的输出(形状变为 (batch, time_steps, units_1)),
# 以便作为下一层LSTM的输入(堆叠LSTM必需)
),
# === 第一层后的Dropout正则化 ===
Dropout(dropout_rate), # 对第一层LSTM的输出应用Dropout,
# 随机将 dropout_rate 比例的神经元置零,增强泛化能力
# === 第二层:LSTM(仅返回最后一步输出)===
LSTM(
units=units_2, # 第二层LSTM单元数,通常比第一层小
activation='tanh',
recurrent_activation='sigmoid',
return_sequences=False # 不再返回序列,只输出最后一个时间步的隐藏状态(形状: (batch, units_2)),
# 适用于单步预测任务(如预测下一个时间点的值)
),
# === 第二层后的Dropout正则化 ===
Dropout(dropout_rate), # 再次应用Dropout,进一步防止过拟合
# === 全连接隐藏层(可选,增强非线性拟合能力)===
Dense(16, activation='relu'), # 添加一个16神经元的全连接层,使用ReLU激活函数,
# 用于对LSTM提取的时序特征进行进一步非线性组合和抽象
# === 输出层 ===
Dense(1) # 单神经元输出层,无激活函数(默认 linear),
# 适用于回归任务(如预测股价、温度等连续值)
])
# 返回构建好的模型实例
return model
stacked_lstm = build_stacked_lstm_model(input_shape)
print("双层LSTM模型结构:")
stacked_lstm.summary()双层LSTM模型结构:Model: "sequential_13"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ lstm_10 (LSTM) │ (None, 20, 64) │ 16,896 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_19 (Dropout) │ (None, 20, 64) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm_11 (LSTM) │ (None, 32) │ 12,416 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_20 (Dropout) │ (None, 32) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_25 (Dense) │ (None, 16) │ 528 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_26 (Dense) │ (None, 1) │ 17 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘ Total params: 29,857 (116.63 KB) Trainable params: 29,857 (116.63 KB) Non-trainable params: 0 (0.00 B)说明
-
为什么第一层
return_sequences=True?- 堆叠多个LSTM层时,除最后一层外,前面所有LSTM层必须设置
return_sequences=True。 - 因为LSTM层期望输入是三维张量
(batch, time_steps, features),若前一层只返回最后一个时间步(二维),则无法作为下一层LSTM的输入。
- 堆叠多个LSTM层时,除最后一层外,前面所有LSTM层必须设置
-
双层 vs 单层 LSTM 的优势
| 特性 | 单层LSTM | 双层堆叠LSTM |
|---|---|---|
| 表达能力 | 有限 | 更强,可学习多层次时序抽象 |
| 适用场景 | 简单模式 | 复杂依赖(如长期记忆、多尺度趋势) |
| 计算开销 | 低 | 较高 |
例如:第一层捕捉短期波动,第二层整合长期趋势。
- 中间 Dense 层的作用
虽然LSTM已能输出特征,但添加一个小型全连接层(如Dense(16, 'relu'))可以:- 引入额外的非线性变换;
- 融合LSTM输出的多个维度信息;
- 提升模型对复杂目标函数的拟合能力。
- 总结:
该函数实现了一个经典的双层堆叠LSTM + Dropout + 全连接头架构,兼顾了时序建模能力与正则化,适合中等复杂度的时间序列预测任务。通过调整 units_1、units_2 和 dropout_rate,可灵活控制模型容量与泛化性能。
5. 对比模型:MLP
5.1 MLP模型(将序列展平)
python
def build_mlp_model(seq_length):
"""
构建一个多层感知机(MLP)模型,用于处理时间序列数据。
该方法将输入的时间序列"展平"为一维向量,忽略其时序结构,仅作为普通特征输入MLP。
参数说明:
----------
seq_length : int
输入序列的长度(即时间步数)。例如,若使用过去30天的数据预测第31天,
则 seq_length = 30。
输入数据的实际形状应为 (batch_size, seq_length, 1),其中 1 表示单变量时间序列(如仅收盘价)。
返回:
-------
model : tf.keras.Model
一个未编译的Keras顺序模型,适用于回归任务(如预测下一个时间点的连续值)。
注意:
此模型**不保留时间依赖关系**,通常作为基线模型(baseline),
用于与真正利用时序结构的模型(如LSTM、Transformer)进行对比。
"""
# 创建一个Keras顺序模型(Sequential)
model = Sequential([
# === 输入层 ===
Input(shape=(seq_length, 1)), # 显式定义输入形状:(时间步数, 特征数)
# 例如 (30, 1) 表示30个时间步,每步1个特征
# 注意:Input 层不是必须的(可通过第一层指定 input_shape),
# 但显式写出可提高代码可读性
# === 展平层(关键步骤)===
tf.keras.layers.Flatten(), # 将三维输入 (batch, seq_length, 1) 展平为二维 (batch, seq_length * 1)
# 例如:(32, 30, 1) → (32, 30)
# 此操作**完全丢弃了时间顺序信息**,仅将序列视为30个独立特征
# === 第一个全连接隐藏层 ===
Dense(128, activation='relu'), # 128个神经元的全连接层,使用ReLU激活函数
# ReLU 提供非线性,帮助模型学习复杂模式
# === 第一个Dropout正则化层 ===
Dropout(0.3), # 随机丢弃30%的神经元输出,防止过拟合
# 在训练阶段生效,推理阶段自动关闭
# === 第二个全连接隐藏层 ===
Dense(64, activation='relu'), # 64个神经元,继续提取高层特征
# === 第二个Dropout正则化层 ===
Dropout(0.3), # 再次应用Dropout,增强泛化能力
# === 第三个全连接隐藏层 ===
Dense(32, activation='relu'), # 32个神经元,进一步压缩和抽象特征表示
# === 输出层 ===
Dense(1) # 单神经元输出层,无激活函数(默认 linear 激活)
# 适用于回归任务(如预测股价、温度等连续值)
])
# 返回构建好的模型实例
return model
mlp_model = build_mlp_model(SEQ_LENGTH)
print("MLP模型结构:")
mlp_model.summary()
# 注意:MLP需要将输入reshape
print(f"MLP输入形状: (batch, {SEQ_LENGTH})")MLP模型结构:Model: "sequential_15"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ flatten_4 (Flatten) │ (None, 20) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_31 (Dense) │ (None, 128) │ 2,688 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_23 (Dropout) │ (None, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_32 (Dense) │ (None, 64) │ 8,256 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_24 (Dropout) │ (None, 64) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_33 (Dense) │ (None, 32) │ 2,080 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_34 (Dense) │ (None, 1) │ 33 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘ Total params: 13,057 (51.00 KB) Trainable params: 13,057 (51.00 KB) Non-trainable params: 0 (0.00 B)MLP输入形状: (batch, 20)说明:
-
为什么叫"将序列展平"?
-
时间序列原始形状:
(batch, time_steps, features)→ 例如(32, 30, 1) -
经
Flatten()后变为:(batch, time_steps × features)→(32, 30) -
结果 :模型把"第1天的值"、"第2天的值"......"第30天的值"当作30个独立的输入特征 ,不认为它们有先后顺序或依赖关系。
-
-
适用场景与局限性
| 优点 | 缺点 |
|---|---|
| 结构简单,训练快 | 无法捕捉时间依赖(如趋势、周期性) |
| 可作为强基线(有时MLP表现意外地好) | 对长序列效率低(参数爆炸) |
| 适合短序列或弱时序依赖任务 | 无法处理变长序列 |
典型用途 :在论文或项目中作为 baseline 模型,验证"是否真的需要复杂的时序模型"。
- 总结:该函数实现了一个将时间序列视为普通特征向量的MLP模型 。虽然简单,但在某些任务中(如噪声大、时序弱的场景)可能表现不俗。其核心价值在于提供一个不利用时序结构的对照组,帮助评估更复杂模型(如LSTM)是否真正带来了性能提升。
5.2 简单RNN(对比LSTM)
python
def build_simple_rnn_model(input_shape, units=50):
"""
构建一个单层简单循环神经网络(Simple RNN)模型,用于基础的时间序列建模任务。
参数说明:
----------
input_shape : tuple
输入数据的形状(不包括 batch size),格式为 (time_steps, features)。
例如:(30, 1) 表示使用过去30个时间步的1个特征(如收盘价)进行预测。
units : int, 可选(默认=50)
SimpleRNN 层中隐藏单元(神经元)的数量,决定了模型的记忆容量和表达能力。
值越大,模型越复杂,但也更容易过拟合或出现梯度问题。
返回:
-------
model : tf.keras.Model
未编译的Keras顺序模型,适用于单步回归预测任务(如预测下一个时间点的连续值)。
注意:
SimpleRNN 是最基础的RNN结构,**容易出现梯度消失/爆炸问题**,
因此在长序列任务中表现通常不如 LSTM 或 GRU。
"""
# 创建一个Keras顺序模型(Sequential),按顺序堆叠网络层
model = Sequential([
# === SimpleRNN 循环层 ===
SimpleRNN(
units=units, # 隐藏状态的维度(即RNN单元数量)
activation='tanh', # 激活函数:tanh 将隐藏状态限制在 [-1, 1] 范围内,
# 有助于稳定数值,是RNN的经典选择
input_shape=input_shape, # 指定输入形状(仅第一层需要),如 (时间步数, 特征数)
return_sequences=False # 只返回最后一个时间步的输出(形状: (batch, units)),
# 适用于单步预测任务(如预测下一个值)
),
# === Dropout 正则化层 ===
Dropout(0.2), # 随机丢弃20%的RNN输出神经元,防止过拟合
# 在训练时生效,推理时自动关闭
# === 输出层 ===
Dense(1) # 单神经元全连接层,无激活函数(默认 linear),
# 用于回归任务(输出连续值,如股价、温度等)
])
# 返回构建好的模型实例
return model
rnn_model = build_simple_rnn_model(input_shape)
print("简单RNN模型结构:")
rnn_model.summary()简单RNN模型结构:Model: "sequential_16"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ simple_rnn_3 (SimpleRNN) │ (None, 50) │ 2,600 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_25 (Dropout) │ (None, 50) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_35 (Dense) │ (None, 1) │ 51 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘ Total params: 2,651 (10.36 KB) Trainable params: 2,651 (10.36 KB) Non-trainable params: 0 (0.00 B)说明:
该函数实现了一个最简RNN模型,代码简洁但功能有限。它适合入门学习或作为对照实验,在实际时间序列任务中,LSTM 或 GRU 通常是更优选择。若使用此模型,建议限制输入序列长度,并密切监控训练中的梯度稳定性
6. 模型训练
6.1 编译配置
python
def compile_model(model, learning_rate=0.001):
"""
为给定的Keras模型配置优化器、损失函数和评估指标,完成模型编译。
参数说明:
----------
model : tf.keras.Model
待编译的Keras模型实例(如通过 build_lstm_model 等函数构建的模型)。
learning_rate : float, 可选(默认=0.001)
优化器的学习率,控制每次参数更新的步长。
0.001 是 Adam 优化器的常用默认值,适用于大多数回归任务。
返回:
-------
model : tf.keras.Model
已编译的模型,可直接调用 fit() 进行训练。
"""
# === 配置优化器:Adam + 梯度裁剪 ===
optimizer = Adam(
learning_rate=learning_rate, # 设置学习率;较小值(如0.001)有助于稳定收敛,
# 较大值可能加快训练但导致震荡
clipnorm=1.0 # 启用梯度裁剪(Gradient Clipping):
# 将梯度的 L2 范数限制在 1.0 以内,
# 防止梯度爆炸(尤其在RNN/LSTM中常见)
)
# === 编译模型 ===
model.compile(
optimizer=optimizer, # 使用上述配置的 Adam 优化器
loss='mse', # 损失函数:均方误差(Mean Squared Error)
# 适用于回归任务(如预测股价、温度等连续值),
# 对大误差惩罚更重(平方项)
metrics=['mae'] # 评估指标:平均绝对误差(Mean Absolute Error)
# 更直观地反映预测值与真实值的平均偏差(单位与目标一致)
)
# 返回已编译的模型
return model
# 编译各模型
lstm_model = compile_model(lstm_model)
stacked_lstm = compile_model(stacked_lstm)
mlp_model = compile_model(mlp_model)
rnn_model = compile_model(rnn_model)
print("所有模型编译完成")所有模型编译完成说明:
-
为什么使用
Adam优化器?-
自适应学习率:Adam 结合了 AdaGrad(处理稀疏梯度)和 RMSProp(处理非平稳目标)的优点。
-
动量机制:加速收敛并减少震荡。
-
默认首选:在大多数深度学习任务中表现稳健,无需大量调参。
-
-
梯度裁剪(
clipnorm=1.0)的作用-
问题背景 :RNN/LSTM 在训练长序列时容易出现梯度爆炸(梯度值极大),导致模型发散。
-
解决方案:若梯度向量的 L2 范数 > 1.0,则将其缩放至范数为 1.0。
-
效果:显著提升训练稳定性,尤其对循环神经网络至关重要。
-
梯度裁剪公式 :
若 ∥g∥2>1.0\|\mathbf{g}\|_2 > 1.0∥g∥2>1.0 ,则g=g∥g∥2\mathbf{g} = \cfrac{\mathbf{g}}{\|\mathbf{g}\|_2}g=∥g∥2g
- 损失函数与评估指标的选择
| 组件 | 选择 | 原因 |
|---|---|---|
| Loss | 'mse' |
回归任务标准损失;可导且强调大误差 |
| Metric | 'mae' |
更易解释(如"平均预测偏差±5元");对异常值不敏感 |
- 总结 :该函数封装了面向时间序列回归任务的标准编译配置 ,通过 Adam + 梯度裁剪 确保训练稳定性,MSE + MAE 组合兼顾优化目标与结果可解释性。是工程实践中简洁而有效的模板。
6.2 回调函数
python
def create_callbacks(model_name):
"""
为模型训练创建一组 Keras 回调函数(Callbacks),用于监控训练过程、防止过拟合并自动保存最优模型。
参数说明:
----------
model_name : str
模型的名称(或标识符),用于生成保存文件的路径。
例如:传入 "lstm_stock" 将生成 "lstm_stock_best.keras" 文件。
返回:
-------
callbacks : list of tf.keras.callbacks.Callback
包含两个回调对象的列表,可直接传入 model.fit(callbacks=callbacks)。
"""
# 定义回调列表
callbacks = [
# === 1. EarlyStopping:早停机制 ===
EarlyStopping(
monitor='val_loss', # 监控验证集损失(validation loss)
# 当 val_loss 不再下降时触发早停
patience=15, # 容忍多少个 epoch 内 val_loss 不改善
# 例如:patience=15 表示若连续15个epoch验证损失未降低,则停止训练
restore_best_weights=True, # 训练结束后自动恢复到验证损失最低时的模型权重
# 避免使用过拟合后的最终权重
verbose=1 # 打印早停日志(如 "Epoch 00045: early stopping")
),
# === 2. ModelCheckpoint:模型检查点保存 ===
ModelCheckpoint(
filepath=f'{model_name}_best.keras', # 保存路径和文件名
# 使用 .keras 格式(Keras 推荐的现代保存格式)
monitor='val_loss', # 同样监控验证损失
save_best_only=True, # 仅在 val_loss 创新低时保存模型
# 避免保存大量无用的中间模型
verbose=0 # 不打印保存日志(设为1可显示保存信息)
)
]
# 返回回调列表
return callbacks说明:
-
EarlyStopping 的作用
- 防止过拟合:当模型在验证集上性能不再提升时,及时停止训练,避免继续学习训练集噪声。
- 节省计算资源:无需等到预设的最大 epoch 数才结束。
- 自动回滚 :通过
restore_best_weights=True,确保最终模型是历史上验证效果最好的版本,而非最后一个 epoch 的版本。
📌 典型场景 :
若第 30 轮达到最佳 val_loss,之后持续上升,则:
- 第 45 轮(30 + 15)触发早停;
- 模型权重自动回退到第 30 轮的状态。
-
ModelCheckpoint 的作用
- 持久化最优模型:将性能最好的模型权重保存到磁盘,便于后续加载、部署或评估。
- 避免手动筛选:无需训练后从多个 checkpoint 中挑选最佳模型。
- 支持断点续训 :结合
load_weights()可实现训练中断后恢复。
-
文件命名规范
- 输出文件名示例:
lstm_stock_best.keras - 使用
.keras扩展名(TensorFlow 2.12+ 推荐格式),替代旧的.h5,支持更完整的模型结构保存。
- 输出文件名示例:
-
总结 :该函数实现了工业级训练的标准实践------通过早停防止过拟合 + 自动保存最优模型,显著提升训练效率与模型可靠性。是深度学习项目中不可或缺的组件。
6.3 训练所有模型
python
# MLP需要reshape输入
X_train_mlp = X_train.reshape(X_train.shape[0], -1)
X_test_mlp = X_test.reshape(X_test.shape[0], -1)
models = {
'LSTM': (lstm_model, X_train, X_test),
'Stacked LSTM': (stacked_lstm, X_train, X_test),
'SimpleRNN': (rnn_model, X_train, X_test),
'MLP': (mlp_model, X_train_mlp, X_test_mlp)
}
histories = {}
print("="*60)
print("开始训练各模型")
print("="*60)
for name, (model, X_tr, X_te) in models.items():
print(f"\n训练 {name}...")
start_time = time.time()
callbacks = create_callbacks(name.lower().replace(' ', '_'))
history = model.fit(
X_tr, y_train,
epochs=100,
batch_size=32,
validation_split=0.1,
callbacks=callbacks,
verbose=0
)
train_time = time.time() - start_time
histories[name] = history
# 预测
y_pred = model.predict(X_te, verbose=0)
# 反标准化
y_pred_original = scaler.inverse_transform(y_pred)
y_test_original = scaler.inverse_transform(y_test)
mse = mean_squared_error(y_test_original, y_pred_original)
mae = mean_absolute_error(y_test_original, y_pred_original)
print(f" 训练时间: {train_time:.2f}秒")
print(f" 最佳轮数: {len(history.history['loss'])}")
print(f" 测试集MSE: {mse:.4f}")
print(f" 测试集MAE: {mae:.4f}")============================================================
开始训练各模型
============================================================
训练 LSTM...
Epoch 88: early stopping
Restoring model weights from the end of the best epoch: 73.
训练时间: 33.69秒
最佳轮数: 88
测试集MSE: 6702.3761
测试集MAE: 62.0380
训练 Stacked LSTM...
Epoch 42: early stopping
Restoring model weights from the end of the best epoch: 27.
训练时间: 28.54秒
最佳轮数: 42
测试集MSE: 9973.6052
测试集MAE: 80.2964
训练 SimpleRNN...
Epoch 31: early stopping
Restoring model weights from the end of the best epoch: 16.
训练时间: 9.24秒
最佳轮数: 31
测试集MSE: 5274.0711
测试集MAE: 55.5941
训练 MLP...
Epoch 18: early stopping
Restoring model weights from the end of the best epoch: 3.
训练时间: 4.84秒
最佳轮数: 18
测试集MSE: 15639.8911
测试集MAE: 100.22517. 训练曲线对比
python
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
axes = axes.ravel()
for idx, (name, history) in enumerate(histories.items()):
axes[idx].plot(history.history['loss'], 'b-', label='训练损失', linewidth=2)
axes[idx].plot(history.history['val_loss'], 'r-', label='验证损失', linewidth=2)
axes[idx].set_xlabel('Epoch')
axes[idx].set_ylabel('MSE')
axes[idx].set_title(f'{name} 训练曲线')
axes[idx].legend()
axes[idx].grid(True, alpha=0.3)
plt.suptitle('各模型训练损失对比', fontsize=14)
plt.tight_layout()
plt.show()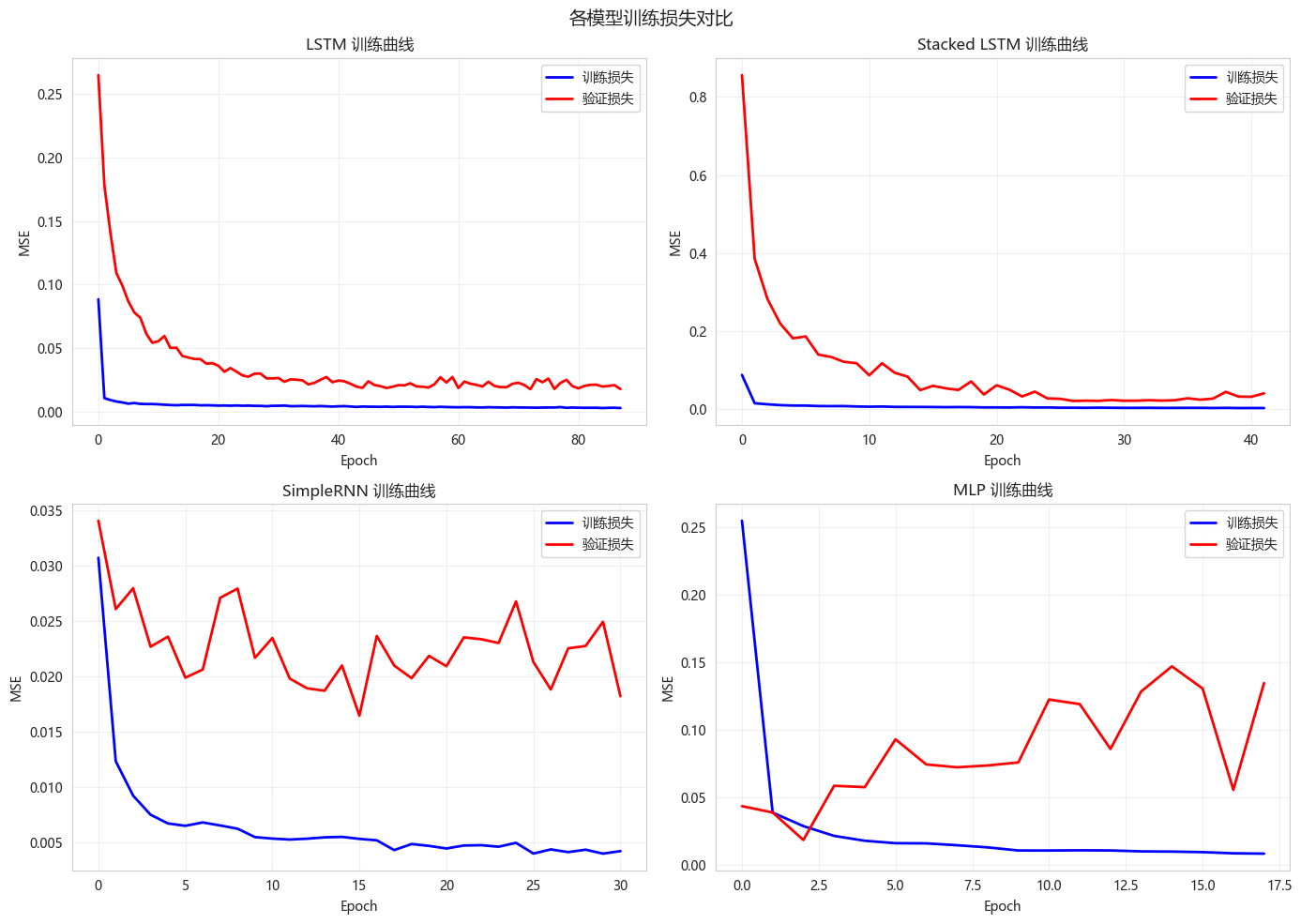
8. 预测效果对比
8.1 预测值与真实值对比
python
# 使用最佳LSTM模型进行预测
best_model = lstm_model
y_pred_lstm = best_model.predict(X_test, verbose=0)
# 反标准化
y_pred_original = scaler.inverse_transform(y_pred_lstm)
y_test_original = scaler.inverse_transform(y_test)
plt.figure(figsize=(14, 6))
# 预测 vs 真实
plt.subplot(1, 2, 1)
plt.plot(y_test_original, 'b-', label='真实值', linewidth=1.5, alpha=0.7)
plt.plot(y_pred_original, 'r-', label='LSTM预测值', linewidth=1.5, alpha=0.7)
plt.xlabel('时间步')
plt.ylabel('价格')
plt.title('LSTM预测 vs 真实(测试集)')
plt.legend()
plt.grid(True, alpha=0.3)
# 散点图
plt.subplot(1, 2, 2)
plt.scatter(y_test_original, y_pred_original, alpha=0.5)
plt.plot([y_test_original.min(), y_test_original.max()],
[y_test_original.min(), y_test_original.max()],
'r--', linewidth=2, label='理想线')
plt.xlabel('真实价格')
plt.ylabel('预测价格')
plt.title('预测 vs 真实散点图')
plt.legend()
plt.grid(True, alpha=0.3)
plt.suptitle('LSTM预测效果', fontsize=14)
plt.tight_layout()
plt.show()
8.2 所有模型预测对比
python
# 收集各模型预测结果
predictions = {}
for name, (model, X_tr, X_te) in models.items():
y_pred = model.predict(X_te, verbose=0)
predictions[name] = scaler.inverse_transform(y_pred)
# 可视化
plt.figure(figsize=(14, 8))
# 真实值
plt.plot(y_test_original[-100:], 'k-', label='真实值', linewidth=2, alpha=0.8)
# 各模型预测
colors = {'LSTM': 'blue', 'Stacked LSTM': 'green', 'SimpleRNN': 'orange', 'MLP': 'red'}
for name, pred in predictions.items():
plt.plot(pred[-100:], color=colors[name], label=name, linewidth=1.5, alpha=0.7)
plt.xlabel('时间步')
plt.ylabel('价格')
plt.title('各模型预测对比(测试集)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()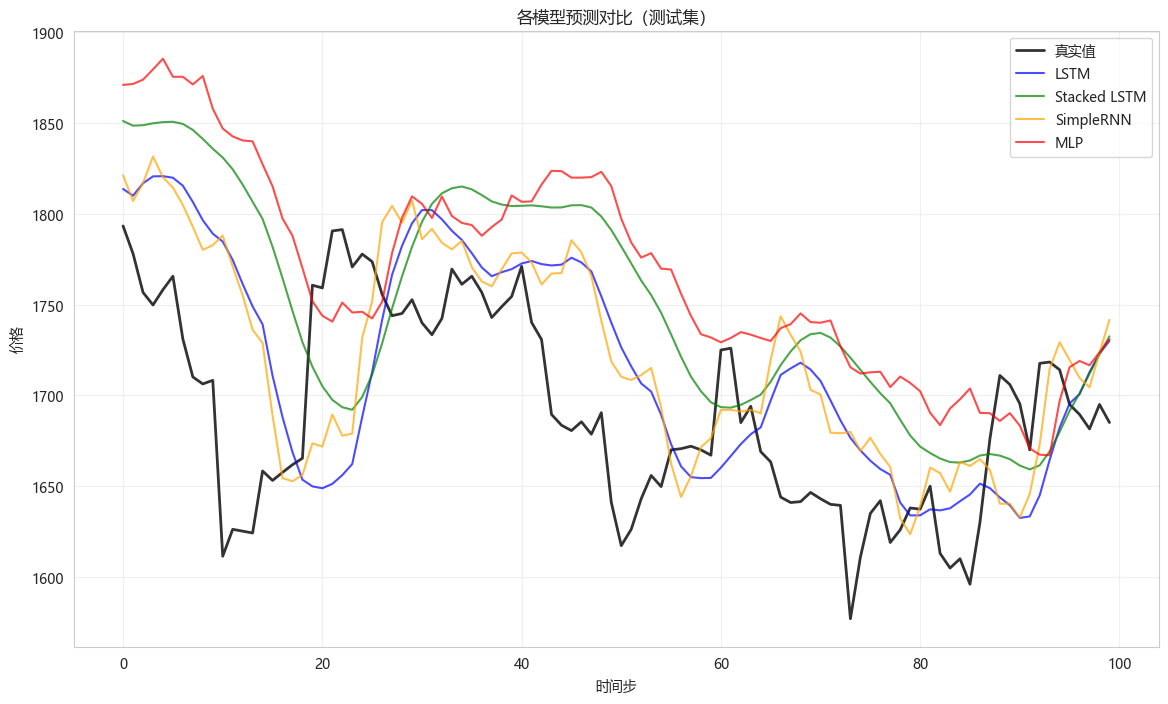
9. 模型评估
性能指标汇总
python
results = []
for name, (model, X_tr, X_te) in models.items():
y_pred = model.predict(X_te, verbose=0)
y_pred_orig = scaler.inverse_transform(y_pred)
mse = mean_squared_error(y_test_original, y_pred_orig)
mae = mean_absolute_error(y_test_original, y_pred_orig)
r2 = r2_score(y_test_original, y_pred_orig)
results.append({
'模型': name,
'MSE': mse,
'MAE': mae,
'R²': r2
})
results_df = pd.DataFrame(results)
print("="*60)
print("模型性能对比")
print("="*60)
print(results_df.to_string(index=False))
# 可视化
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
metrics = ['MSE', 'MAE', 'R²']
for idx, metric in enumerate(metrics):
axes[idx].bar(results_df['模型'], results_df[metric],
color=['blue', 'green', 'orange', 'red'])
axes[idx].set_title(metric)
axes[idx].set_xlabel('模型')
axes[idx].grid(True, alpha=0.3)
if metric == 'R²':
axes[idx].set_ylim(0, 1)
plt.suptitle('各模型性能对比', fontsize=14)
plt.tight_layout()
plt.show()============================================================
模型性能对比
============================================================
模型 MSE MAE R²
LSTM 6702.376120 62.038002 0.638010
Stacked LSTM 9973.605210 80.296352 0.461334
SimpleRNN 5274.071087 55.594104 0.715152
MLP 15639.891096 100.225106 0.155302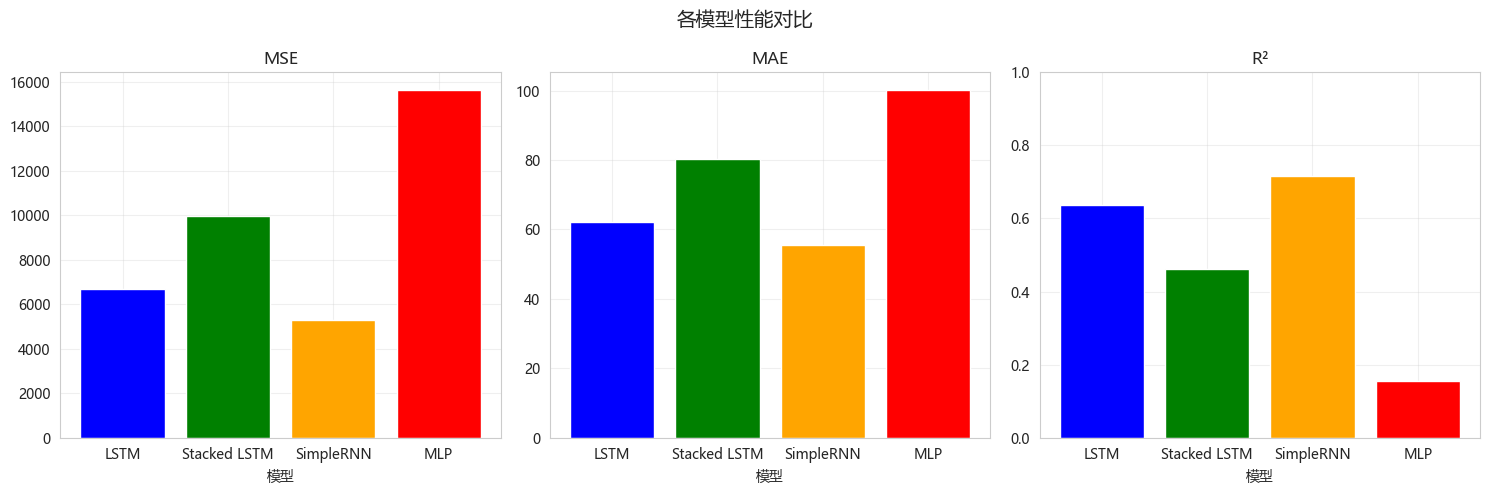
10. 预测误差分析
python
# 计算各模型误差
errors = {}
for name, (model, X_tr, X_te) in models.items():
y_pred = model.predict(X_te, verbose=0)
y_pred_orig = scaler.inverse_transform(y_pred)
errors[name] = y_test_original.flatten() - y_pred_orig.flatten()
# 误差分布
plt.figure(figsize=(12, 6))
for name, error in errors.items():
plt.hist(error, bins=50, alpha=0.5, label=name, density=True)
plt.xlabel('预测误差')
plt.ylabel('密度')
plt.title('各模型预测误差分布')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 误差统计
print("\n误差统计(均值 ± 标准差):")
for name, error in errors.items():
print(f" {name}: {error.mean():.4f} ± {error.std():.4f}")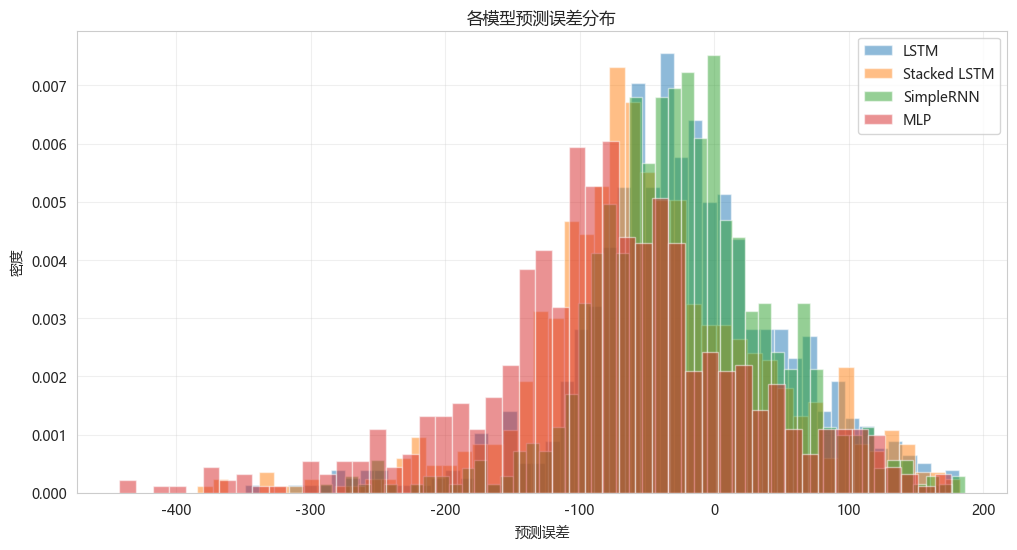
误差统计(均值 ± 标准差):
LSTM: -23.8619 ± 78.3134
Stacked LSTM: -48.5615 ± 87.2662
SimpleRNN: -22.4557 ± 69.0638
MLP: -77.1468 ± 98.429011. 多步预测
python
def multi_step_predict(model, last_sequence, n_steps=10):
"""使用模型进行多步预测
Args:
model: 训练好的模型
last_sequence: 最后已知的序列 (seq_length, 1)
n_steps: 预测未来步数
Returns:
predictions: 预测序列
"""
predictions = []
current_seq = last_sequence.copy()
for _ in range(n_steps):
# 预测下一步
next_val = model.predict(current_seq.reshape(1, SEQ_LENGTH, 1), verbose=0)
predictions.append(next_val[0, 0])
# 更新序列
current_seq = np.roll(current_seq, -1)
current_seq[-1] = next_val
return np.array(predictions)
future_steps = 30
# 获取最后20天的数据(预留30天数据用于验证)
last_seq = scaled_data[-(SEQ_LENGTH + future_steps):-future_steps].reshape(SEQ_LENGTH, 1)
# 多步预测
future_pred = multi_step_predict(lstm_model, last_seq, future_steps)
# 反标准化
future_pred_original = scaler.inverse_transform(future_pred.reshape(-1, 1))
# 可视化
plt.figure(figsize=(14, 6))
# 历史数据
history_days = 100
plt.plot(range(history_days), scaler.inverse_transform(scaled_data[-history_days:]),
'b-', label='历史数据', linewidth=1.5)
# 预测区间
future_idx = range(history_days - future_steps, history_days)
plt.plot(future_idx, future_pred_original, 'r--', label='LSTM预测', linewidth=2)
plt.xlabel('天数(从测试集末尾往前)')
plt.ylabel('价格')
plt.title('多步预测(未来30天)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()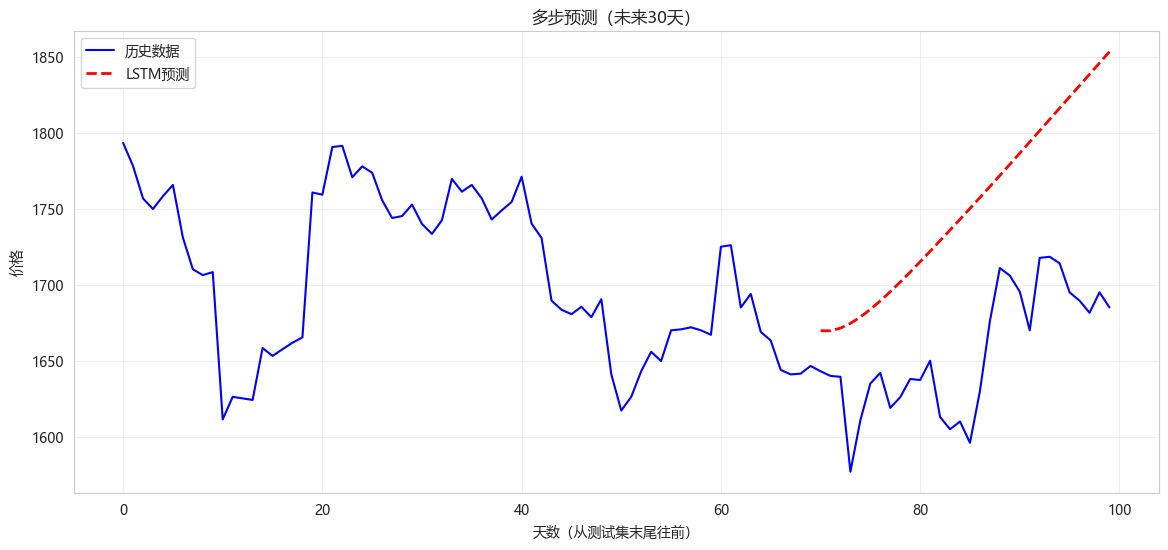
12. 今日总结
-
RNN/LSTM核心概念:
- 循环神经网络适用于序列数据
- 简单RNN存在梯度消失问题
- LSTM通过门控机制解决长期依赖
-
LSTM的门控结构:
- 遗忘门:决定丢弃哪些信息
- 输入门:决定存储哪些新信息
- 输出门:决定输出哪些信息
- 细胞状态:信息高速公路
-
量化应用建议:
- LSTM擅长捕捉时间序列的长期依赖
- 数据标准化是必需步骤
- 使用滑动窗口创建训练样本
- 时间顺序划分防止数据泄露
-
扩展作业
- 作业1:尝试不同的序列长度(10, 20, 30, 50),观察对预测的影响
- 作业2:添加更多特征(成交量、技术指标)进行多变量预测
- 作业3:使用GRU替换LSTM,对比性能
- 作业4:实现序列到序列(Seq2Seq)预测未来多日收盘价
-
量化思考
- LSTM比简单RNN更适合金融时间序列
- 滑动窗口长度是重要超参数
- 始终使用时间顺序划分数据
- 标准化对LSTM训练很重要