前言
还记得我们上次聊的DDPG吗?它解决了DQN无法处理连续动作的问题,让AI学会了控制机器人、开车甚至跑步。但如果你真的动手实现过DDPG,一定会被它折磨得怀疑人生:
- 稍微调错一个超参数,训练直接崩溃
- 好不容易训练好了,跑着跑着突然性能断崖式下跌
- 评论家网络总是高估Q值,导致演员学会了各种奇怪的"骚操作"
我曾经用DDPG训练一个机械臂抓杯子,训练了整整三天,结果它学会了把杯子用力扔出去------因为评论家严重高估了"扔杯子"这个动作的价值,认为这样能获得更高的奖励。
2018年,来自麦吉尔大学和阿姆斯特丹大学的研究人员发表了一篇里程碑式的论文,彻底解决了DDPG的这些顽疾。他们提出的双延迟深度确定性策略梯度算法(TD3),通过三个简单而巧妙的改进,让连续控制算法的稳定性和性能提升了一个档次。在所有测试的环境上,TD3都碾压了当时的SOTA算法,包括DDPG、PPO、TRPO和ACKTR。
论文信息
- 标题:Addressing Function Approximation Error in Actor-Critic Methods
- 会议:ICML 2018
- 单位:麦吉尔大学、阿姆斯特丹大学
- 代码:github.com/sfujim/TD3
- 论文:https://arxiv.org/pdf/1802.09477.pdf
1 问题根源:DDPG的"自欺欺人"
DDPG的问题本质上是函数近似误差导致的。简单来说,神经网络不是万能的,它对价值函数的估计总会有误差。而在强化学习中,这些误差会通过贝尔曼方程不断累积,最终导致灾难性的后果。
1.1 什么是过估计偏差?
在Q学习中,我们总是选择使Q值最大的动作。如果Q值估计有噪声,那么最大值操作会倾向于选择被高估的动作,从而导致整体的Q值估计系统性地偏高------这就是著名的过估计偏差。
通俗解释:这就像你找工作,有10个公司给你发了offer,每个公司的薪资都有一点误差(有的报高了,有的报低了)。你肯定会选薪资最高的那个,但这个最高薪资大概率是被高估的。
在离散动作的DQN中,这个问题已经被Double DQN解决了。但在连续动作的演员-评论家框架下,Double DQN的方法却失效了。为什么呢?因为在演员-评论家算法中,策略是缓慢变化的,当前网络和目标网络的参数非常相似,无法提供独立的估计。
1.2 DDPG确实存在过估计偏差
作者们通过实验证明了DDPG存在严重的过估计偏差。他们在Hopper和Walker2d环境上训练DDPG,然后比较了评论家估计的Q值和实际测试中得到的真实回报。
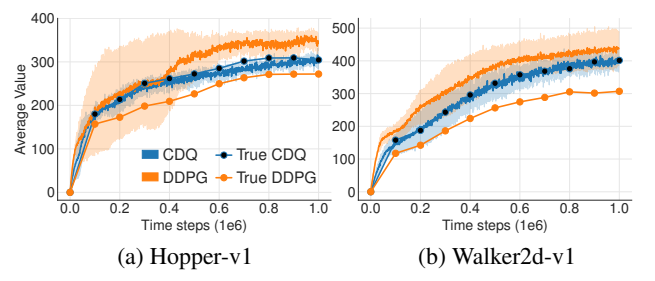
【图片1 DDPG与裁剪双Q学习的过估计对比,出处:论文原文图1】
从图中可以清晰地看到:
- DDPG的Q值估计(蓝色线)远远高于真实值(黑色线)
- 随着训练的进行,过估计偏差越来越大
- 而作者提出的裁剪双Q学习(CDQ,绿色线)几乎没有过估计偏差
这种过估计偏差会形成一个恶性循环:
- 评论家高估了某些动作的价值
- 演员根据这些高估的价值更新自己的策略,倾向于选择这些被高估的动作
- 评论家又会根据演员的新策略进一步高估这些动作的价值
- 最终,整个系统完全崩溃,学到一个毫无用处的策略
2 TD3的三大核心改进:对症下药
TD3的全称是Twin Delayed Deep Deterministic policy gradient algorithm,也就是"双延迟深度确定性策略梯度算法"。从名字就能看出,它有三个核心改进:
- Twin:双评论家网络,取最小值作为目标
- Delayed:延迟策略更新,评论家比演员更新得更频繁
- Policy Smoothing:目标策略平滑正则化,防止过拟合
这三个改进环环相扣,完美解决了DDPG的过估计和不稳定问题。
2.1 改进一:裁剪双Q学习(Clipped Double Q-Learning)
既然一个评论家容易自欺欺人,那我们就用两个独立的评论家网络,让它们互相监督。
TD3维护两个完全独立的评论家网络Qθ1Q_{\theta_1}Qθ1和Qθ2Q_{\theta_2}Qθ2,以及对应的两个目标评论家网络Qθ1′Q_{\theta_1'}Qθ1′和Qθ2′Q_{\theta_2'}Qθ2′。在计算目标Q值时,我们取两个目标评论家输出的最小值 :
y=r+γmini=1,2Qθi′(s′,πϕ′(s′))y = r + \gamma \min_{i=1,2} Q_{\theta_i'}(s', \pi_{\phi'}(s'))y=r+γi=1,2minQθi′(s′,πϕ′(s′))
公式符号全解释:
- yyy:目标Q值,用于更新评论家网络
- rrr:在状态sss采取动作aaa获得的即时奖励
- γ\gammaγ:折扣因子,范围在0,10,10,1,表示未来奖励的重要性
- Qθi′Q_{\theta_i'}Qθi′:第iii个目标评论家网络
- s′s's′:采取动作aaa后转移到的下一个状态
- πϕ′\pi_{\phi'}πϕ′:目标演员网络,用于选择下一个状态的动作
通俗解释:这就像你找工作时,同时问两个独立的猎头同一个职位的薪资。如果一个猎头说这个职位年薪100万,另一个说年薪50万,你应该相信50万那个------因为高估薪资对猎头有好处,而低估的可能性很小。
为什么取最小值而不是平均值?因为我们宁愿低估Q值,也不要高估它。低估的动作会被演员自然地避开,不会对学习造成太大影响;而高估的动作会被演员优先选择,最终导致灾难性的后果。
2.2 改进二:延迟策略更新(Delayed Policy Updates)
在演员-评论家算法中,演员的更新完全依赖于评论家的评价。如果评论家还没学好,演员的更新方向就是错的。
TD3提出了一个非常简单但极其有效的解决方案:让评论家更新得比演员更频繁 。具体来说,我们每更新ddd次评论家网络,才更新一次演员网络和所有目标网络。论文中推荐d=2d=2d=2,也就是评论家每更新2次,演员更新1次。
通俗解释:这就像老师教学生。如果老师自己还没把知识搞懂,就急着教学生,学生肯定学不好。正确的做法是:老师先把知识学扎实了(多更新几次评论家),再教学生(更新一次演员)。
这个改进还有一个额外的好处:它减少了演员的更新次数,大大加快了训练速度。在论文的实验中,TD3的训练速度比DDPG快了将近一倍。
2.3 改进三:目标策略平滑正则化(Target Policy Smoothing)
确定性策略有一个天生的缺点:它容易过拟合到价值函数的尖峰。也就是说,如果价值函数在某个动作处有一个很高的尖峰,演员会不顾一切地选择这个动作,哪怕稍微偏离一点,价值就会暴跌。
为了解决这个问题,TD3引入了目标策略平滑正则化 。我们给目标演员输出的动作加一点小噪声,然后再输入到目标评论家网络中:
y=r+γmini=1,2Qθi′(s′,πϕ′(s′)+ϵ)ϵ∼clip(N(0,σ),−c,c)\begin{aligned} y &= r + \gamma \min_{i=1,2} Q_{\theta_i'}(s', \pi_{\phi'}(s') + \epsilon) \\ \epsilon &\sim \text{clip}(\mathcal{N}(0, \sigma), -c, c) \end{aligned}yϵ=r+γi=1,2minQθi′(s′,πϕ′(s′)+ϵ)∼clip(N(0,σ),−c,c)
公式符号全解释:
- ϵ\epsilonϵ:添加到目标动作上的噪声
- N(0,σ)\mathcal{N}(0, \sigma)N(0,σ):均值为0、标准差为σ\sigmaσ的高斯分布
- clip\text{clip}clip:截断函数,将噪声限制在−c,c-c, c−c,c范围内,防止动作偏离太远
论文中推荐的参数是σ=0.2\sigma=0.2σ=0.2,c=0.5c=0.5c=0.5。
通俗解释:这就像你开车时,不要总是死死地盯着方向盘,保持一点灵活性。给动作加一点小扰动,让演员学会在目标动作附近也能获得较高的价值,这样策略会更加鲁棒。
这个改进本质上是在平滑价值函数,让它在最优动作附近更加平坦,从而防止过拟合。它类似于强化学习中的Expected SARSA算法,能让学到的策略更加安全和稳定。
3 TD3算法完整流程
下面是TD3算法的完整伪代码,对应论文中的Algorithm 1:
1. 随机初始化两个评论家网络Qθ₁, Qθ₂和一个演员网络πφ
2. 初始化对应的目标网络:θ₁' ← θ₁, θ₂' ← θ₂, φ' ← φ
3. 初始化经验回放缓冲区B
4. 对于每个时间步t从1到T:
a. 根据当前策略和探索噪声选择动作:a = πφ(s) + ε, ε ~ N(0, σ_explore)
b. 执行动作a,观察奖励r和下一个状态s'
c. 将转移元组(s, a, r, s')存入经验回放缓冲区B
d. 从B中随机采样一个小批量的N个转移
e. 计算带噪声的目标动作:ã = πφ'(s') + ε, ε ~ clip(N(0, σ_target), -c, c)
f. 计算目标Q值:y = r + γ * min(Qθ₁'(s', ã), Qθ₂'(s', ã))
g. 更新两个评论家网络,最小化均方误差损失:
L(θᵢ) = (1/N) Σ (y - Qθᵢ(s, a))², i=1,2
h. 如果t是d的倍数:
i. 更新演员网络,最大化Qθ₁(s, πφ(s)):
∇φ J ≈ (1/N) Σ ∇a Qθ₁(s, a)|a=πφ(s) ∇φ πφ(s)
ii. 软更新所有目标网络:
θᵢ' ← τθᵢ + (1-τ)θᵢ', i=1,2
φ' ← τφ + (1-τ)φ'4 实验结果:碾压所有SOTA算法
作者们在7个标准的MuJoCo连续控制环境上测试了TD3的性能,包括HalfCheetah、Hopper、Walker2d、Ant等。
【图片2 TD3测试的MuJoCo环境示例,出处:论文原文图4】
从左到右依次是:HalfCheetah-v1、Hopper-v1、Walker2d-v1和Ant-v1。这些环境都是连续控制领域的标准测试基准,难度从易到难。
4.1 与其他算法的对比
作者们将TD3与当时最先进的连续控制算法进行了对比,包括DDPG、PPO、TRPO、ACKTR和SAC。
【表格1 各算法在MuJoCo环境上的最大平均回报,出处:论文原文表1】
| 环境 | TD3 | DDPG | 我们的DDPG | PPO | TRPO | ACKTR | SAC |
|---|---|---|---|---|---|---|---|
| HalfCheetah | 9636.95 | 3305.60 | 8577.29 | 1795.43 | -15.57 | 1450.46 | 2347.19 |
| Hopper | 3564.07 | 2020.46 | 1860.02 | 2164.70 | 2471.30 | 2428.39 | 2996.66 |
| Walker2d | 4682.82 | 1843.85 | 3098.11 | 3317.69 | 2321.47 | 1216.70 | 1283.67 |
| Ant | 4372.44 | 1005.30 | 888.77 | 1083.20 | -75.85 | 1821.94 | 655.35 |
| Reacher | -3.60 | -6.51 | -4.01 | -6.18 | -111.43 | -4.26 | -4.44 |
| InvPendulum | 1000.00 | 1000.00 | 1000.00 | 1000.00 | 985.40 | 1000.00 | 1000.00 |
| InvDoublePendulum | 9337.47 | 9355.52 | 8369.95 | 8977.94 | 205.85 | 9081.92 | 8487.15 |
结果分析:
- TD3在7个环境中的6个上取得了最好的成绩
- 在HalfCheetah环境上,TD3的得分是原始DDPG的3倍
- 即使是和作者们重新调优过的DDPG相比,TD3也有明显的优势
- 只有在最简单的倒立摆环境上,所有算法都能达到满分
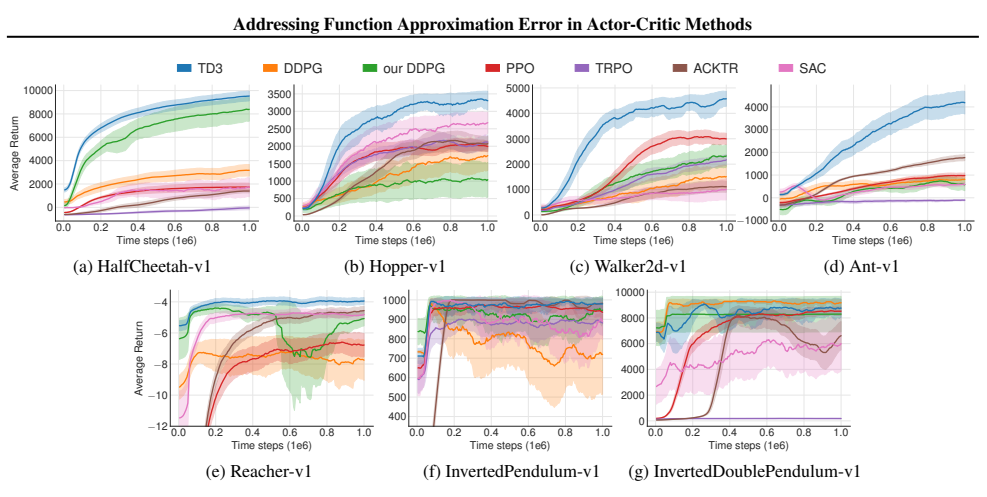
【图片3 各算法的学习曲线对比,出处:论文原文图5】
从学习曲线可以看出:
- TD3不仅最终性能最好,学习速度也是最快的
- DDPG的学习曲线波动很大,经常出现性能断崖式下跌
- PPO和TRPO的学习速度很慢,而且最终性能不如TD3
4.2 消融实验:哪个组件最重要?
为了搞清楚TD3三个核心组件的各自贡献,作者们做了一个详细的消融实验。他们分别去掉了裁剪双Q学习(CDQ)、延迟策略更新(DP)和目标策略平滑(TPS),然后比较了性能。
【表格2 TD3的消融实验结果,出处:论文原文表2】
| 方法 | HalfCheetah | Hopper | Walker2d | Ant |
|---|---|---|---|---|
| TD3 | 9532.99 | 3304.75 | 4565.24 | 4185.06 |
| DDPG | 3162.50 | 1731.94 | 1520.90 | 816.35 |
| TD3 - CDQ | 9792.80 | 1837.32 | 2579.39 | 849.75 |
| TD3 - DP | 9590.65 | 2407.42 | 4695.50 | 3754.26 |
| TD3 - TPS | 8987.69 | 2392.59 | 4033.67 | 4155.24 |
结果分析:
- 裁剪双Q学习是最重要的组件:去掉它之后,TD3的性能在Hopper和Walker2d上几乎降到了DDPG的水平
- 延迟策略更新和目标策略平滑也很重要,去掉它们之后性能有明显下降
- 三个组件结合起来,才能达到最好的效果
5 核心代码:完整的PyTorch实现
下面是一个严格按照论文实现的TD3代码,包含了所有核心组件。
python
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from collections import deque
import random
# 论文中的超参数设置
GAMMA = 0.99
TAU = 0.005
ACTOR_LR = 1e-3
CRITIC_LR = 1e-3
BUFFER_SIZE = int(1e6)
BATCH_SIZE = 100
POLICY_DELAY = 2 # d=2,每更新2次评论家,更新1次演员
EXPLORATION_NOISE = 0.1
TARGET_NOISE = 0.2
NOISE_CLIP = 0.5
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 经验回放缓冲区
class ReplayBuffer:
def __init__(self, buffer_size=BUFFER_SIZE, batch_size=BATCH_SIZE):
self.buffer = deque(maxlen=buffer_size)
self.batch_size = batch_size
def add(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self):
batch = random.sample(self.buffer, self.batch_size)
states = torch.tensor(np.array([b[0] for b in batch]), dtype=torch.float32).to(device)
actions = torch.tensor(np.array([b[1] for b in batch]), dtype=torch.float32).to(device)
rewards = torch.tensor(np.array([b[2] for b in batch]), dtype=torch.float32).to(device)
next_states = torch.tensor(np.array([b[3] for b in batch]), dtype=torch.float32).to(device)
dones = torch.tensor(np.array([b[4] for b in batch]), dtype=torch.float32).to(device)
return states, actions, rewards, next_states, dones
def __len__(self):
return len(self.buffer)
# 演员网络
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, action_scale):
super(Actor, self).__init__()
self.action_scale = torch.tensor(action_scale, dtype=torch.float32).to(device)
self.fc1 = nn.Linear(state_dim, 400)
self.fc2 = nn.Linear(400, 300)
self.fc3 = nn.Linear(300, action_dim)
# 初始化最后一层
nn.init.uniform_(self.fc3.weight, -3e-3, 3e-3)
nn.init.uniform_(self.fc3.bias, -3e-3, 3e-3)
def forward(self, state):
x = torch.relu(self.fc1(state))
x = torch.relu(self.fc2(x))
x = torch.tanh(self.fc3(x)) # tanh将输出限制在[-1,1]
return x * self.action_scale
# 评论家网络(双评论家)
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
# 第一个评论家
self.fc1_q1 = nn.Linear(state_dim + action_dim, 400)
self.fc2_q1 = nn.Linear(400, 300)
self.fc3_q1 = nn.Linear(300, 1)
# 第二个评论家
self.fc1_q2 = nn.Linear(state_dim + action_dim, 400)
self.fc2_q2 = nn.Linear(400, 300)
self.fc3_q2 = nn.Linear(300, 1)
# 初始化最后一层
nn.init.uniform_(self.fc3_q1.weight, -3e-4, 3e-4)
nn.init.uniform_(self.fc3_q1.bias, -3e-4, 3e-4)
nn.init.uniform_(self.fc3_q2.weight, -3e-4, 3e-4)
nn.init.uniform_(self.fc3_q2.bias, -3e-4, 3e-4)
def forward(self, state, action):
sa = torch.cat([state, action], dim=1)
# 第一个评论家的前向传播
q1 = torch.relu(self.fc1_q1(sa))
q1 = torch.relu(self.fc2_q1(q1))
q1 = self.fc3_q1(q1)
# 第二个评论家的前向传播
q2 = torch.relu(self.fc1_q2(sa))
q2 = torch.relu(self.fc2_q2(q2))
q2 = self.fc3_q2(q2)
return q1, q2
def Q1(self, state, action):
sa = torch.cat([state, action], dim=1)
q1 = torch.relu(self.fc1_q1(sa))
q1 = torch.relu(self.fc2_q1(q1))
q1 = self.fc3_q1(q1)
return q1
# TD3主类
class TD3:
def __init__(self, state_dim, action_dim, action_scale):
self.actor = Actor(state_dim, action_dim, action_scale).to(device)
self.actor_target = Actor(state_dim, action_dim, action_scale).to(device)
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=ACTOR_LR)
self.critic = Critic(state_dim, action_dim).to(device)
self.critic_target = Critic(state_dim, action_dim).to(device)
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=CRITIC_LR)
# 初始化目标网络参数与主网络相同
self.soft_update(self.actor, self.actor_target, tau=1.0)
self.soft_update(self.critic, self.critic_target, tau=1.0)
self.replay_buffer = ReplayBuffer()
self.total_it = 0
def soft_update(self, source, target, tau=TAU):
for source_param, target_param in zip(source.parameters(), target.parameters()):
target_param.data.copy_(tau * source_param.data + (1.0 - tau) * target_param.data)
def select_action(self, state, add_noise=True):
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(device)
self.actor.eval()
with torch.no_grad():
action = self.actor(state).cpu().data.numpy()[0]
self.actor.train()
if add_noise:
action += np.random.normal(0, EXPLORATION_NOISE, size=action.shape)
# 确保动作在有效范围内
action = np.clip(action, -self.actor.action_scale.cpu().numpy(), self.actor.action_scale.cpu().numpy())
return action
def update(self):
self.total_it += 1
states, actions, rewards, next_states, dones = self.replay_buffer.sample()
# 计算带噪声的目标动作
with torch.no_grad():
noise = torch.randn_like(actions) * TARGET_NOISE
noise = torch.clamp(noise, -NOISE_CLIP, NOISE_CLIP)
next_actions = self.actor_target(next_states) + noise
next_actions = torch.clamp(next_actions, -self.actor.action_scale, self.actor.action_scale)
# 计算两个目标评论家的Q值,取最小值
target_Q1, target_Q2 = self.critic_target(next_states, next_actions)
target_Q = torch.min(target_Q1, target_Q2)
y = rewards + GAMMA * target_Q * (1 - dones)
# 更新两个评论家
current_Q1, current_Q2 = self.critic(states, actions)
critic_loss = nn.MSELoss()(current_Q1, y) + nn.MSELoss()(current_Q2, y)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 延迟更新演员和目标网络
if self.total_it % POLICY_DELAY == 0:
# 更新演员,最大化Q1
actor_loss = -self.critic.Q1(states, self.actor(states)).mean()
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 软更新目标网络
self.soft_update(self.actor, self.actor_target)
self.soft_update(self.critic, self.critic_target)
# 主训练函数
def main():
env = gym.make("HalfCheetah-v4")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
action_scale = env.action_space.high[0]
agent = TD3(state_dim, action_dim, action_scale)
num_episodes = 1000
max_steps = 1000
# 初始随机探索10000步
state, _ = env.reset()
for _ in range(10000):
action = env.action_space.sample()
next_state, reward, done, truncated, _ = env.step(action)
done = done or truncated
agent.replay_buffer.add(state, action, reward, next_state, done)
state = next_state
if done:
state, _ = env.reset()
for episode in range(num_episodes):
state, _ = env.reset()
episode_reward = 0
for step in range(max_steps):
action = agent.select_action(state)
next_state, reward, done, truncated, _ = env.step(action)
done = done or truncated
agent.replay_buffer.add(state, action, reward, next_state, done)
agent.update()
state = next_state
episode_reward += reward
if done:
break
if episode % 10 == 0:
print(f"Episode {episode} | 奖励: {episode_reward:.1f}")
if __name__ == "__main__":
main()代码亮点:
- 严格按照论文中的网络结构和超参数实现
- 包含完整的双评论家网络和目标网络
- 实现了裁剪双Q学习、延迟策略更新和目标策略平滑
- 初始随机探索阶段,提高了训练的稳定性
- 代码结构清晰,易于理解和修改
6 总结与启示
TD3是连续控制领域的一个里程碑式的工作,它通过三个简单而巧妙的改进,彻底解决了DDPG的过估计和不稳定问题。
TD3的核心贡献
- 证明了演员-评论家方法也存在过估计偏差:这是之前被广泛忽视的一个问题
- 提出了裁剪双Q学习:通过两个独立的评论家取最小值,有效限制了过估计
- 提出了延迟策略更新:让评论家先学好,再更新演员,提高了训练稳定性
- 提出了目标策略平滑正则化:平滑价值函数,防止过拟合
TD3的局限性
当然,TD3也不是完美的,它有一些缺点:
- 仍然是确定性策略,探索效率不如随机策略
- 对超参数仍然有一定的敏感度,虽然比DDPG好很多
- 没有解决样本效率低的问题,仍然需要大量的交互数据
这些缺点也催生了后续的改进算法,比如SAC(软演员-评论家),它结合了TD3的双评论家思想和最大熵强化学习,进一步提高了性能和稳定性。
给实践者的建议
如果你想用强化学习解决连续控制问题,TD3是你的首选算法。它比DDPG稳定得多,比PPO快得多,而且实现起来非常简单。
在使用TD3时,一定要注意以下几点:
- 严格按照论文中的超参数设置 :尤其是学习率、软更新系数τ\tauτ和策略延迟ddd
- 一定要用双评论家:这是TD3最重要的组件,没有它性能会大幅下降
- 初始随机探索阶段很重要:先随机探索10000步,再开始训练
- 不要用Ornstein-Uhlenbeck噪声:论文证明简单的高斯噪声效果更好
7 写在最后
TD3的故事告诉我们:有时候,最简单的改进往往是最有效的。
DDPG的问题困扰了研究者们好几年,大家尝试了各种复杂的方法,都没有取得很好的效果。而TD3的三个改进都非常简单:加一个评论家、少更新几次演员、给动作加一点噪声。但就是这三个简单的改进,让连续控制算法的性能提升了一个档次。
这也给我们一个启示:在做研究时,不要总是追求复杂的方法。有时候,深入理解问题的本质,从最简单的地方入手,反而能取得意想不到的效果。
今天,TD3已经成为了连续控制领域的基础算法,几乎所有后续的连续控制算法都借鉴了它的双评论家思想。无论是机器人控制、自动驾驶还是游戏AI,你都能看到TD3的影子。