让我们用纯 C++ 和 Eigen 库实现梯度下降算法,享受编程乐趣。
在本文中,我们将介绍梯度下降算法,并通过该算法实现从数据中拟合二维卷积核。我们会使用上一篇文章中介绍的卷积运算与损失函数概念,所有代码均使用现代 C++ 与 Eigen 库实现。
在教程中,我们将学习如何仅使用原生现代 C++,实现深度学习必备核心算法:卷积、反向传播、激活函数、优化器、深度神经网络等。
函数拟合:转化为优化问题
在机器学习中,我们绝大多数工作都是利用数据寻找目标函数的近似函数。

通常通过寻找能最小化损失值的系数 来得到函数近似解。因此,函数拟合问题会被转化为一个优化问题------ 我们的目标是最小化损失函数的取值。
损失函数与梯度下降
损失函数用于计算:用函数 H(X) 近似目标函数 F(X) 时产生的损失值。举个例子,如果 H(X) 是输入 X 与卷积核 k 的卷积运算,那么均方误差(MSE)损失函数定义为:
MSE(k)=N1∑n=1N(H(Xn)−Tn)2
其中 Tn=F(Xn)。
MSE 即均方误差,是我们上一篇文章中介绍的损失函数。
我们的目标是找到卷积核参数 km,使得 MSE(k) 最小化。实现这一目标最基础(同时也最强大)的算法就是梯度下降。
梯度下降利用损失函数的梯度 寻找最小损失值。想要理解梯度是什么,我们先来看损失曲面。
绘制损失曲面
为了方便理解,我们假设卷积核 k 只有两个系数:k00,k01。如果我们绘制出所有 k00,k01 组合对应的 MSE(k) 值,最终会得到一个类似这样的曲面:
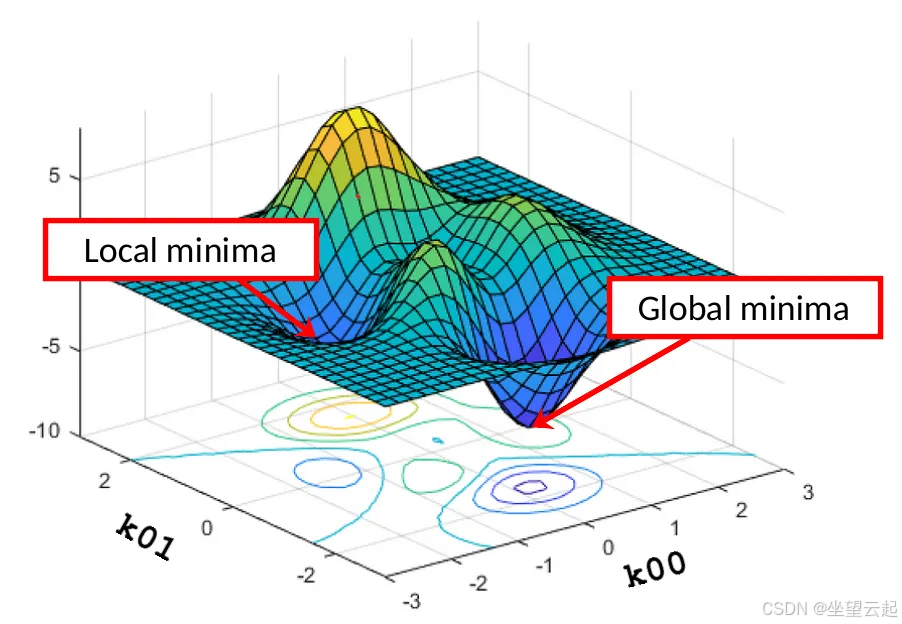
在每一个点 (k00,k01,MSE(k00,k01)) 上,曲面对 k00 轴、k01 轴各有一个倾斜角度:
偏导数
这两个斜率,就是 MSE 曲线分别对 k00 轴、k01 轴的偏导数。在微积分中,我们用符号 ∂ 表示偏导数:
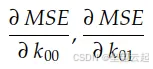
这两个偏导数共同组成了MSE 关于 k00、k01 的梯度。这个梯度将驱动梯度下降算法执行,如下图所示:
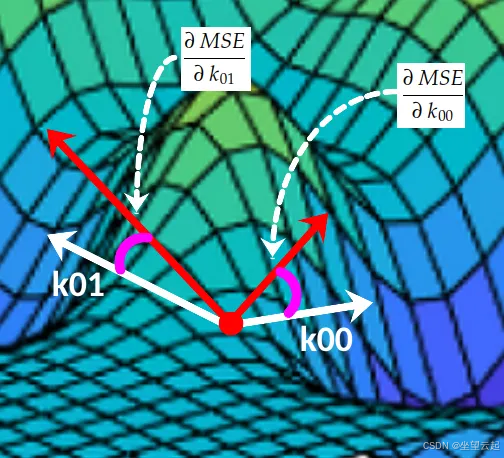
梯度下降运行示意
在损失曲面上完成这种「寻路导航」的算法,就是梯度下降。
梯度下降算法
梯度下降伪代码如下:
梯度下降算法:
初始化卷积核k、学习率、迭代轮数epoch = 1
循环执行:
k = k - 学习率 × 损失函数梯度∇Cost(k)
直到 epoch 达到最大轮数max_epoch
返回k学习率 × ∇Cost(k) 通常被称为参数更新量。我们可以用一句话总结梯度下降的行为:
每一次迭代:
计算参数更新量
从参数k中减去该更新量顾名思义,Cost(k) 是参数配置为 k 时的损失函数。梯度下降的目标是找到让 Cost(k) 最小的 k 值。
学习率(learning_rate) 通常是一个标量,例如 0.1、0.01、0.001 等,用于控制优化过程中的步长大小。
算法会循环执行 max_epoch 次。在实际应用中,如果损失值 Cost(k) 已经足够小,即使未达到最大轮数,我们也会提前停止算法。
我们通常将 学习率、最大迭代轮数 这类参数称为超参数。
实现梯度下降的最后一个知识点:如何计算损失函数 C(k) 的梯度。幸运的是,对于 MSE 损失函数,计算梯度 ∇Cost(k) 非常简单,我们会在下文详细说明。
计算 MSE 梯度
到目前为止我们知道:梯度的每个分量,就是损失曲面对每个坐标轴 kij 的斜率。MSE 损失函数对卷积核 k 中每个 (i,j) 位置系数的梯度定义为:
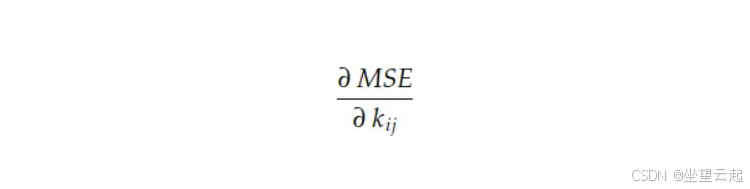
回顾 MSE 的定义:
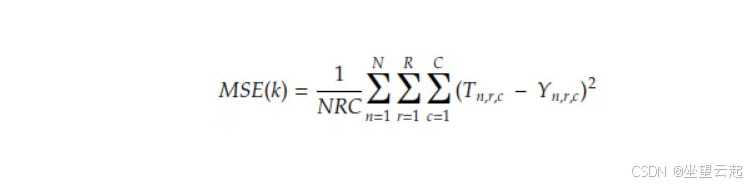
其中:
- n:每一组 (Yn,Tn) 样本的索引
- Tn:真实值
- Yn:预测值
- 、:输出矩阵的行列索引
输出矩阵结构
利用链式法则 和线性组合法则,我们可以推导出 MSE 梯度:
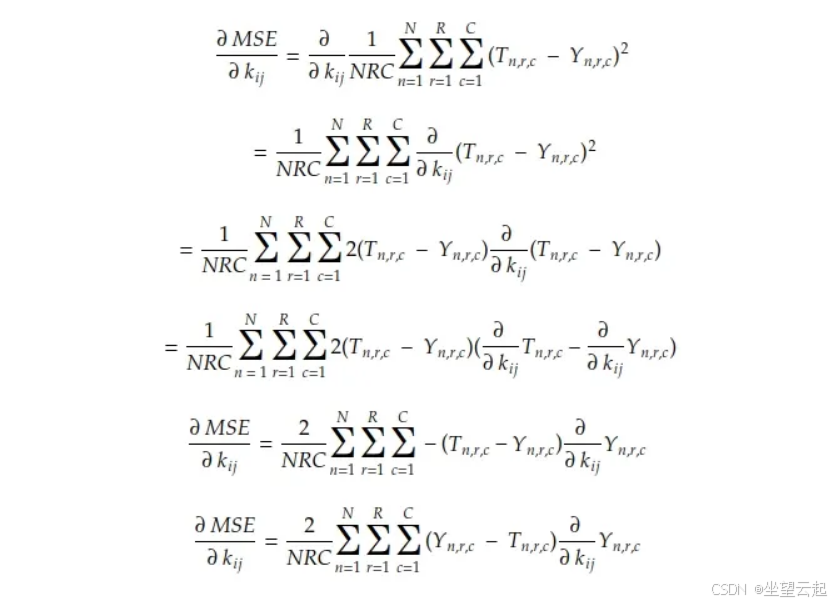
已知 、、、、 的值,我们只需要计算:Tn 中每个系数对卷积核系数 kij 的偏导数。对于带填充 P 的卷积运算,该偏导数为:
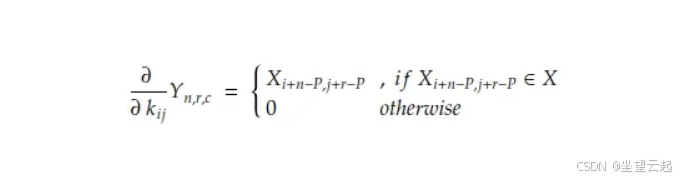
如果我们展开对r和c的求和,可以发现梯度可以简单表示为:

以下代码实现了梯度计算:
auto gradient = [](const std::vector<Matrix> &xs, std::vector<Matrix> &ys, std::vector<Matrix> &ts, const int padding)
{
const int N = xs.size();
const int R = xs[0].rows();
const int C = xs[0].cols();
const int result_rows = xs[0].rows() - ys[0].rows() + 2 * padding + 1;
const int result_cols = xs[0].cols() - ys[0].cols() + 2 * padding + 1;
Matrix result = Matrix::Zero(result_rows, result_cols);
for (int n = 0; n < N; ++n) {
const auto &X = xs[n];
const auto &Y = ys[n];
const auto &T = ts[n];
Matrix delta = Y - T;
Matrix update = Convolution2D(X, delta, padding);
result = result + update;
}
result *= 2.0/(R * C);
return result;
};现在我们已经掌握了梯度计算方法,接下来实现梯度下降算法。
C++ 实现梯度下降
最终,梯度下降的完整代码如下:
auto gradient_descent = [](Matrix &kernel, Dataset &dataset, const double learning_rate, const int MAX_EPOCHS)
{
std::vector<double> losses; losses.reserve(MAX_EPOCHS);
const int padding = kernel.rows() / 2;
const int N = dataset.size();
std::vector<Matrix> xs; xs.reserve(N);
std::vector<Matrix> ys; ys.reserve(N);
std::vector<Matrix> ts; ts.reserve(N);
int epoch = 0;
while (epoch < MAX_EPOCHS)
{
xs.clear(); ys.clear(); ts.clear();
for (auto &instance : dataset) {
const auto & X = instance.first;
const auto & T = instance.second;
const auto Y = Convolution2D(X, kernel, padding);
xs.push_back(X);
ts.push_back(T);
ys.push_back(Y);
}
losses.push_back(MSE(ys, ts));
auto grad = gradient(xs, ys, ts, padding);
auto update = grad * learning_rate;
kernel -= update;
epoch++;
}
return losses;
};这是基础版本代码,我们可以通过多种方式优化它,例如:
- 用单个样本的损失更新卷积核 → 随机梯度下降(SGD),在实际场景中非常实用
- 将样本分组为批次,每批次更新一次卷积核 → 小批量梯度下降(Minibatch)
- 使用学习率调度策略,随迭代轮数降低学习率
- 在
kernel -= update;这一行接入动量法、RMSProp、Adam 等优化器(后续文章讲解) - 引入验证集或交叉验证策略
- 用向量化运算替换嵌套循环,提升性能、降低 CPU 占用(上一篇文章已讲解)
- 添加回调函数与钩子,自定义训练循环
我们暂时可以不考虑这些优化。当前核心目标是理解:梯度如何用于更新参数(本文中即卷积核)。这是现代机器学习最核心、最基础的概念,也是学习更高级算法的关键。
接下来,我们通过一个直观的实验,验证这段代码的运行效果。
实战实验:还原 Sobel 边缘检测算子
在上一篇文章中,我们学习了使用 Sobel 算子 Gx 检测垂直边缘:
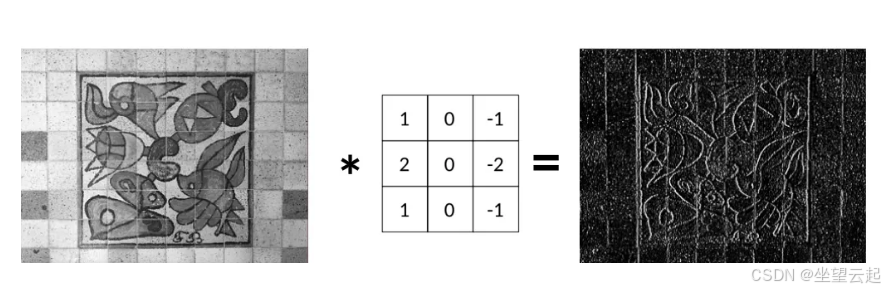
现在问题来了:给定原始图像与边缘检测结果图像,我们能否还原出 Sobel 算子 Gx?

换句话说:仅根据输入 X 和期望输出 Y,我们能否拟合出对应的卷积核?
答案是:可以,我们将用梯度下降算法实现这一目标。
加载与准备数据
首先,我们使用 OpenCV 从文件夹中读取图像,对图像应用 Gx 算子,并将原始图像 - 结果图像成对存入数据集对象:
auto load_dataset = [](std::string data_folder, const int padding) {
Dataset dataset;
std::vector<std::string> files;
for (const auto & entry : fs::directory_iterator(data_folder)) {
Mat image = cv::imread(data_folder + entry.path().c_str(), cv::IMREAD_GRAYSCALE);
Mat formatted_image = resize_image(image, 640, 640);
Matrix X;
cv::cv2eigen(formatted_image, X);
X /= 255.;
auto Y = Convolution2D(X, Sobel.Gx, padding);
auto pair = std::make_pair(X, Y);
dataset.push_back(pair);
}
return dataset;
};
auto dataset = load_dataset("../images/");我们通过工具函数 resize_image,将所有输入图像统一调整为 640×640 尺寸。

如上图所示,resize_image 会将图像居中放置在黑色 640×640 画布中,不会拉伸图像。
我们用 Gx 算子生成了每张图像的真实输出 Y 。接下来我们将 "忘掉" 这个算子,仅依靠数据、梯度下降和二维卷积,重新还原出它。
运行实验
整合所有代码,最终训练流程如下:
int main() {
const int padding = 1;
auto dataset = load_dataset("../images/", padding);
const int MAX_EPOCHS = 1000;
const double learning_rate = 0.1;
auto history = gradient_descent(kernel, dataset, learning_rate, MAX_EPOCHS);
std::cout << "Original kernel is:\n\n" << std::fixed << std::setprecision(2) << Sobel.Gx << "\n\n";
std::cout << "Trained kernel is:\n\n" << std::fixed << std::setprecision(2) << kernel << "\n\n";
plot_performance(history);
return 0;
}下图展示了卷积核的拟合过程:

训练初始阶段,卷积核被随机数填充,因此前几轮迭代的输出图像通常是全黑的。
几轮迭代后,梯度下降开始将卷积核向全局最小值方向拟合。
训练末期,模型输出几乎与真实结果完全一致,损失值也渐近收敛到最小值。我们可以查看损失值随迭代轮数的变化曲线:
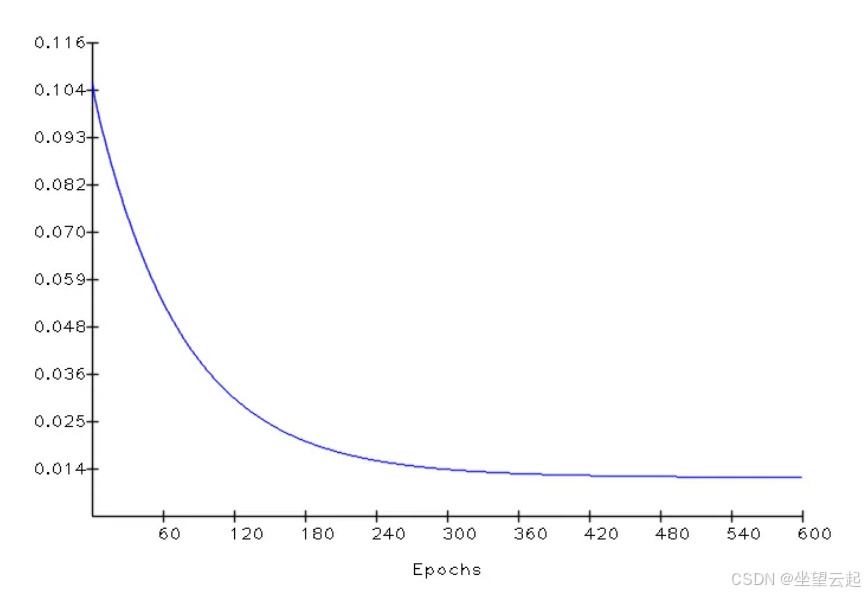
训练性能曲线
在机器学习中,这种损失曲线非常典型:
- 训练初期:参数完全随机,初始损失值很高
- 训练末期:梯度下降完成优化,卷积核拟合到最优值,损失收敛到最小值
下图展示了损失曲面上的算法寻优过程:
现在我们对比学习到的卷积核 与原始 Sobel Gx 算子:
正如预期,两者几乎完全一致。如果增加迭代轮数(并使用更小的学习率),误差还能进一步缩小。
补充:微分与自动微分
本文中,我们使用标准微积分法则推导了 MSE 的偏导数。但在某些场景下,为复杂损失函数推导代数形式的导数非常困难。幸运的是,现代机器学习框架提供了一项强大功能:自动微分(autodiff)。
自动微分会追踪每一个基础算术运算(加、乘等),并应用链式法则计算偏导数。使用自动微分时,我们无需手动推导导数公式,也无需手动实现导数计算。
本文使用的是简单、经典的损失公式,因此不需要自动微分,也无需手动推导复杂微分。
总结与后续计划
在本文中,我们学习了如何利用梯度从数据中拟合卷积核 ,实现了简单、高效、且是反向传播等高级算法基础的梯度下降,并通过实战实验,用梯度下降从数据中还原了 Sobel 算子。
下一篇文章,我们将讲解激活函数:分类、原理、代码实现以及导数实现。