C++ 原子变量与内存序:从 std::atomic 到 release/acquire
一、先理解原子变量解决了什么
1. 原子变量保证"操作不可分割"
多线程程序中,多个线程同时访问同一个共享变量,只要其中至少一个线程会写,就可能产生竞态条件。原子变量的价值就是让一次读、写、加减、交换、CAS 等操作不会执行到一半被其他线程插入,从结果上看,它要么完整发生,要么完全没发生
C++ 标准库用 std::atomic<T> 表示原子变量,比如 std::atomic<int> z;、std::atomic<bool> x, y;。它不只是"给变量加锁"的替代品,更重要的是提供了一组能精确控制并发语义的接口,例如 store 写入、load 读取、exchange 交换、compare_exchange_weak/strong 比较并交换、fetch_add/fetch_sub/fetch_or/fetch_xor 等读改写操作
2. 原子变量不等于天然有序
下面是一个非常适合入门的例子:两个线程同时对同一个原子变量 x 写入,一个写正数,一个写负数,最后主线程读取 x 的值
cpp
std::atomic<int> x{0};
void thread_func1()
{
for (int i = 0; i < 100000; ++i)
x.store(i, std::memory_order_relaxed);
}
void thread_func2()
{
for (int i = 0; i < 100000; ++i)
x.store(-i, std::memory_order_relaxed);
}
int main()
{
std::thread t1(thread_func1);
std::thread t2(thread_func2);
t1.join();
t2.join();
std::cout << "Final value of x = " << x.load(std::memory_order_relaxed) << std::endl;
return 0;
}这个例子说明两件事:第一,x 是原子变量,所以不会出现"写了一半的 int"这种撕裂读写问题;第二,memory_order_relaxed 不承诺两个线程谁的写入最后被观察到,所以最终值可能来自线程 1,也可能来自线程 2。也就是说,原子性解决的是"操作是否完整",内存序解决的是"操作之间是否有顺序和可见性关系"
3. 常用原子接口可以分成三类
原子变量的接口大致可以按使用场景理解:普通读写用 store 和 load,例如 x.store(true, order) 与 x.load(order);交换和 CAS 用于实现无锁结构,例如 exchange 会替换旧值并返回旧值,compare_exchange_weak/strong 会在当前值等于期望值时写入新值;计数类操作用 fetch_add、fetch_sub,位运算类操作用 fetch_or、fetch_xor
需要注意的是,compare_exchange_weak 在某些平台上可能出现"明明值相等也失败"的弱失败,所以它通常放在循环里重试;compare_exchange_strong 语义更强,更适合不想处理弱失败的场景。is_lock_free() 则用于判断某个原子对象在当前平台上是否真的可以无锁实现
二、内存序到底在约束什么
1. 内存序约束的是"别人能按什么顺序看见操作"
CPU 和编译器为了提升性能,可能会对指令进行重排;多核 CPU 又有各自的缓存,某个核心先写入的数据,不一定会立刻以同样的顺序被另一个核心看见。C++11 的内存模型把这些底层细节抽象成一组 memory_order,程序员不用直接写内存屏障,只需要在原子操作上选择合适的内存序
从工程角度看,内存序要解决的问题不是"这一行代码在源码里写在前面",而是"其他线程是否必须按这个顺序观察到它"。如果只要求变量本身读写安全,可以用 relaxed;如果要先写数据再发布通知,通常用 release/acquire;如果希望所有相关原子操作都放进一个全局顺序,可以用 seq_cst
2. memory_order_relaxed:只保证原子性,不保证跨变量顺序
memory_order_relaxed 是最弱的内存序,它只保证对单个原子对象的操作是原子的,不保证不同原子变量之间的先后关系,也不建立线程之间的同步关系
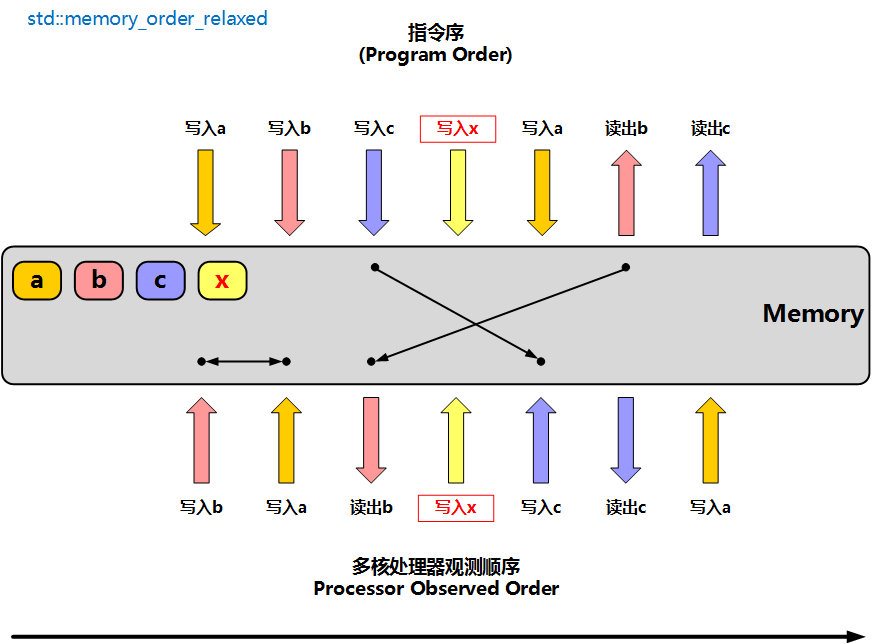
看下面例子,先写 x,再写 y,读线程先等到 y == true,然后再去读 x。从源码顺序看,好像只要读线程看见了 y == true,就应该也能看见 x == true,但由于两次操作都是 relaxed,这个推理并不成立
cpp
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true, std::memory_order_relaxed); // 1
y.store(true, std::memory_order_relaxed); // 2
}
void read_y_then_x()
{
while (!y.load(std::memory_order_relaxed)); // 3
if (x.load(std::memory_order_relaxed)) // 4
++z;
}
int main()
{
int cnt=0;
for (int i=0; i < 10000; i++) {
x=false;
y=false;
z=0;
std::thread b(read_y_then_x);
std::thread a(write_x_then_y);
b.join();
a.join();
int v = z.load(std::memory_order_relaxed);
if (v != 1) cnt++;
}
std::cout<<cnt<<std::endl;
return 0;
}这个例子中,x.store 和 y.store 都是原子的,但没有同步关系把 "1 一定先于 2 被另一个线程观察到" 这个语义建立起来。因此从 C++ 标准的角度看,读线程可能已经看到了 y == true,却仍然没有看到 x == true,于是 z 不一定等于 1。注意这类结果在 x86 等强内存序平台上不一定容易复现,但标准语义允许它发生,写可移植并发代码时不能依赖"这台机器刚好没出问题"
3. memory_order_release:发布之前的写入
memory_order_release 常用于写线程的"发布点"。它的核心限制是:当前线程中 release 操作之前的读写,不能被重排到 release 操作之后;如果另一个线程用 acquire 读取到了这个 release 写入的值,那么 release 之前的写入对 acquire 之后的代码可见
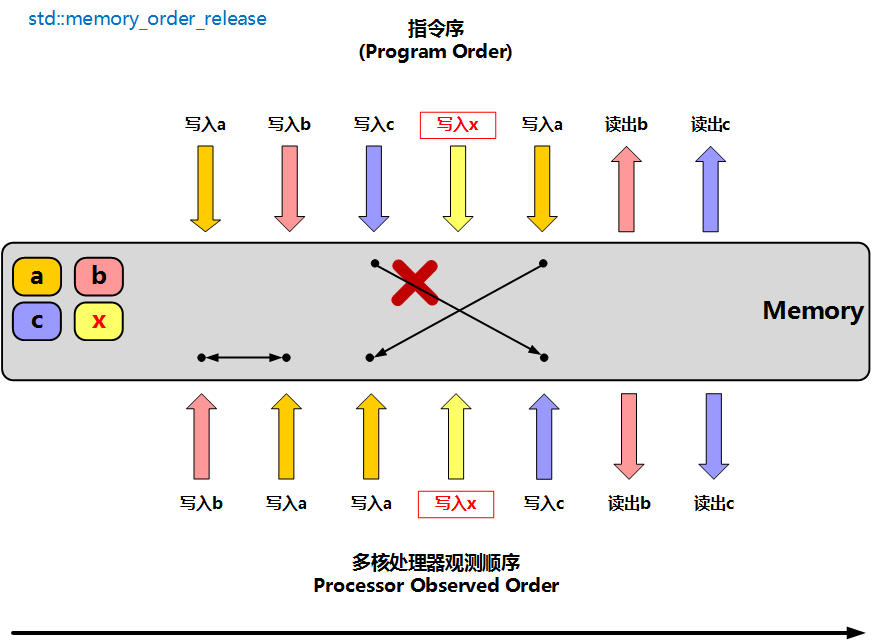
下面例子就是在 relaxed 例子上做了关键修复:写线程仍然先用 relaxed 写 x,但再用 release 写 y;读线程用 acquire 等待 y 变成 true,随后再用 relaxed 读取 x
cpp
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true, std::memory_order_relaxed); // 1
y.store(true, std::memory_order_release); // 2
}
void read_y_then_x()
{
while (!y.load(std::memory_order_acquire)); // 3
if (x.load(std::memory_order_relaxed)) // 4
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
std::cout << z.load(std::memory_order_relaxed) << std::endl;
return 0;
}这里 y 扮演的是"发布完成"的标志位。写线程在 y.store(true, release) 之前做了 x.store(true, relaxed);读线程一旦通过 y.load(acquire) 读到这个 true,就和写线程的 release 建立同步关系。于是 1 发生在 4 之前,读线程再读 x 时就应该能看到 x == true,所以这个例子里的 z 会稳定变成 1
4. memory_order_acquire:获取发布出来的结果
memory_order_acquire 常用于读线程的"获取点"。它的核心限制是:当前线程中 acquire 操作之后的读写,不能被重排到 acquire 操作之前。换句话说,先确认发布标志,再读取发布的数据,这个顺序不能反过来
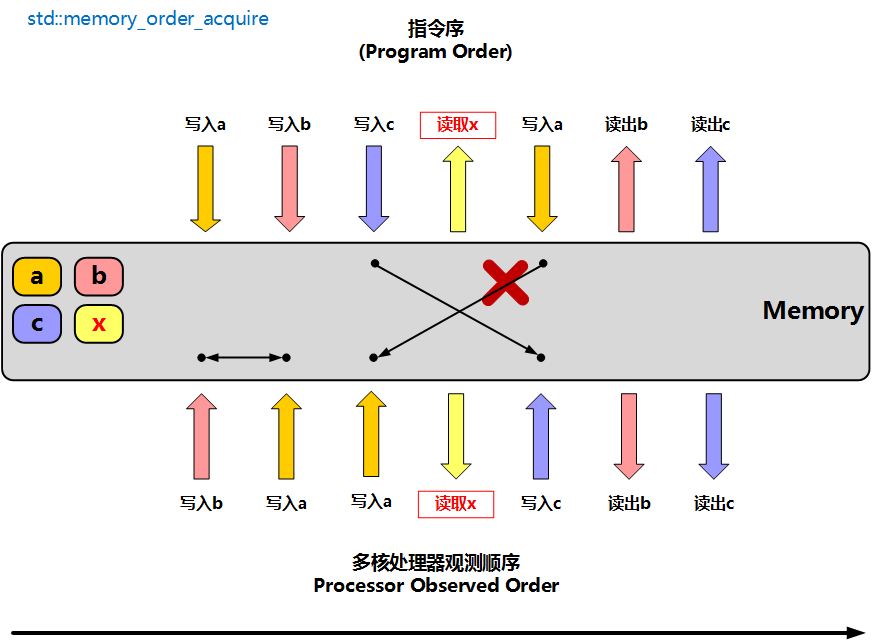
release 和 acquire 必须落在同一个原子变量上才能配对。上面的例子中,release 是 y.store(true, release),acquire 是 y.load(acquire),二者都作用在 y 上,所以 y 成了两个线程之间的同步桥梁。x 本身虽然仍然用 relaxed 访问,但它被放在 release/acquire 建立的 happens-before 关系里,因此读线程可以安全读取到发布前写好的 x
一个常见写法可以这样记:普通数据或其他原子数据先准备好,然后 release 写入 flag;另一个线程 acquire 读取 flag 成功后,再读取真正的数据。flag 本身不一定是业务数据,它更像是一面"数据已经准备好"的同步旗子
5. memory_order_seq_cst:所有操作进入一个全局顺序
memory_order_seq_cst 是默认内存序,也是最容易理解但通常成本最高的内存序。它对读操作相当于 acquire,对写操作相当于 release,对读改写操作相当于 acquire-release,并且所有 seq_cst 原子操作会被放进同一个全局顺序中,所有线程观察到的顺序保持一致
下面有两个写线程分别写 x 和 y,两个读线程分别等待 x 或 y,再去检查另一个变量
cpp
void write_x() { x.store(true, std::memory_order_seq_cst); }
void write_y() { y.store(true, std::memory_order_seq_cst); }
void read_x_then_y()
{
while (!x.load(std::memory_order_seq_cst));
if (y.load(std::memory_order_seq_cst))
++z;
}
void read_y_then_x()
{
while (!y.load(std::memory_order_seq_cst));
if (x.load(std::memory_order_seq_cst))
++z;
}
int main() {
for (int i = 0; i < 20; i++) {
x = false;
y = false;
z = 0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
// assert(z.load() != 0); // 5
std::cout << z.load() << std::endl;
}
return 0;
}如果两个读线程都已经分别看到了自己等待的变量为 true,那么在 seq_cst 的全局顺序下,不可能两个线程随后读取另一个变量时都读到 false。换成代码里的结论就是 z 可以是 1 或 2,但不应该是 0。注释里的 assert(z.load() != 0) 正是这个例子的核心判断,只是源文件中暂时把它注释掉了
6. memory_order_consume 与 memory_order_acq_rel
memory_order_consume 类似 acquire,但它只约束依赖于该原子读结果的数据依赖链。比如 s = a + b 中,如果原子读发生在 a 上,那么 s 依赖 a,但 b 不依赖 a。这个模型很难写对,不同编译器实现也比较保守,所以实际工程中通常不建议使用 consume,直接用 acquire 更清晰
memory_order_acq_rel 常用于读改写操作,例如 CAS、fetch_add、exchange。这些操作既读取旧值,又写入新值,所以有时需要同时具备 acquire 和 release 语义:读取别人的发布结果,同时把自己的修改发布出去
三、用例子总结如何选择内存序
1. 只做统计计数,用 relaxed
如果一个原子变量只是用来做计数、打点、统计次数,并且其他线程不依赖这个计数去判断某段数据是否已经准备好,那么 relaxed 通常就够了。例如 counter.fetch_add(1, std::memory_order_relaxed) 可以保证计数本身不会丢失更新,但不额外约束其他内存读写的顺序
2. 先准备数据再通知,用 release/acquire
如果一个线程负责准备数据,另一个线程等待数据准备好再读取,就应该优先考虑 release/acquire。acquire_release.cc 中的 x 和 y 就是典型结构:x 是被发布的数据,y 是发布标志。写线程先写 x,再 release 写 y;读线程 acquire 读到 y 后,再读 x,这比全部使用 seq_cst 更轻量,也比全部使用 relaxed 更安全
3. 不确定怎么选,先用默认 seq_cst
seq_cst 的好处是语义直观:所有使用 seq_cst 的原子操作在全局上有一个一致顺序,推理难度最低。它的缺点是可能更慢,尤其是在高并发、跨核心频繁同步的场景下。对于初学者或正确性优先的代码,可以先使用默认内存序;当性能压测证明它成为瓶颈时,再把局部同步关系改成 release/acquire 或 relaxed
4. 最重要的判断标准
选择内存序时不要只问"这个变量是不是原子的",而要问三个问题:是否只关心这个变量自身的原子读写;是否需要让一个线程在看到标志位后,也看到另一个线程之前写好的数据;是否需要所有线程对多个原子变量的观察顺序完全一致。对应答案分别倾向于 relaxed、release/acquire、seq_cst