Claude Code 与 Codex Harness 设计对比:一种加法,一种减法

图 1:两个 CLI agent 的 harness 哲学对照------左边 TS/Bun 把不变量编进类型,右边 Rust/Tokio 把不变量压到内核 syscall。
文章目录
- [Claude Code 与 Codex Harness 设计对比:一种加法,一种减法](#Claude Code 与 Codex Harness 设计对比:一种加法,一种减法)
-
- 一、写在前面:为什么把这两个放一起读
- 二、技术栈与项目布局:第一眼能看出的区别
- [三、维度 1:主循环------状态机 vs 朴素循环](#三、维度 1:主循环——状态机 vs 朴素循环)
-
- [Claude Code:把每条岔路都写进类型](#Claude Code:把每条岔路都写进类型)
- [Codex:朴素 `loop {}` + 4 种退出原因](#Codex:朴素
loop {}+ 4 种退出原因) - 差别在哪
- [四、维度 2:工具系统------metadata 驱动 vs 锁驱动](#四、维度 2:工具系统——metadata 驱动 vs 锁驱动)
-
- [Claude Code:每个工具自带一组元数据](#Claude Code:每个工具自带一组元数据)
- [Codex:parallel 与否就靠一个锁](#Codex:parallel 与否就靠一个锁)
- 差别在哪
- [五、维度 3:上下文压缩------5 层漏斗 vs 单层 LLM 摘要](#五、维度 3:上下文压缩——5 层漏斗 vs 单层 LLM 摘要)
-
- [Claude Code:5 层漏斗 + 250K 次 / 天的熔断](#Claude Code:5 层漏斗 + 250K 次 / 天的熔断)
- [Codex:单层 LLM 摘要 + 三阶段 + Pre/Post Hook](#Codex:单层 LLM 摘要 + 三阶段 + Pre/Post Hook)
- 差别在哪
- [六、维度 4:权限与 Sandbox------AST 解析 vs OS 内核](#六、维度 4:权限与 Sandbox——AST 解析 vs OS 内核)
-
- [Claude Code:用应用层把"危险动作"挡掉](#Claude Code:用应用层把"危险动作"挡掉)
- [Codex:把 fail-closed 压到 OS](#Codex:把 fail-closed 压到 OS)
- 差别在哪
- [七、维度 5:子 Agent------7 种 Task 类型 vs 内核级 spawn_agent](#七、维度 5:子 Agent——7 种 Task 类型 vs 内核级 spawn_agent)
-
- [Claude Code:7 种 Task 类型 + 隔离膜](#Claude Code:7 种 Task 类型 + 隔离膜)
- [Codex:spawn_agent 是一个工具](#Codex:spawn_agent 是一个工具)
- 差别在哪
- [八、维度 6:扩展机制------27 个 Hook + Skills 懒加载 vs MCP 双向](#八、维度 6:扩展机制——27 个 Hook + Skills 懒加载 vs MCP 双向)
- [九、维度 7:跨端 / 多入口------可选回调 vs 单二进制多 mode](#九、维度 7:跨端 / 多入口——可选回调 vs 单二进制多 mode)
- [十、维度 8:成本与可观测性------cache 字段对齐 vs 三种压缩实现](#十、维度 8:成本与可观测性——cache 字段对齐 vs 三种压缩实现)
-
- [Claude Code:把 prompt cache 字段对齐当头号优化](#Claude Code:把 prompt cache 字段对齐当头号优化)
- Codex:把"压缩在哪儿跑"也做成枚举
- 差别在哪
- 十一、要抄哪段?一张选型表
- [十二、5 条可迁移到自家 harness 的设计准则](#十二、5 条可迁移到自家 harness 的设计准则)
- [十三、收束:harness 是产品,不是脚手架](#十三、收束:harness 是产品,不是脚手架)
- 参考
摘要:把 Claude Code v2.1.88 和 OpenAI Codex CLI 两份源码并排放着看,会发现这是同一道题的两种相反答卷------一种用 TS 类型 + AST 解析做加法,一种用 OS sandbox + 几个 enum 做减法。这篇拆给你看。
一、写在前面:为什么把这两个放一起读
grep -r "transition.reason" Claude Code 源码 → 7 个匹配。同样命令打到 OpenAI 的 codex-rs/ 整个 workspace → 0 个匹配。两个 CLI agent 在做几乎相同的产品,但其中一个把"为什么继续"刻进了类型,另一个连这个概念都不存在。
第一遍读这两份代码很容易感慨它们多像,仔细对照之后会发现它们走的根本不是一条路:
- Claude Code v2.1.88 (2026 年 3 月底因 npm sourcemap 泄露而完整可读,约 1900 个
.ts/.tsx文件、512K+ 行;默认对接 Claude Sonnet 4.6,YOLO 旁路用 Haiku 4.5,复杂任务可拉到 Opus 4.7):用 TypeScript 把 harness 写成一个庞大的状态机系统,类型上把每条 recovery 路径都钉死,然后让 Bun 在终端里跑。 - OpenAI Codex CLI (开源、Apache 2.0、
codex-rs/多 crate Rust workspace;默认对接 GPT-5.x 系列):用 Rust 把 agent loop 写成一个朴素的loop {},绝大部分安全保证甩给操作系统的 Landlock/Seatbelt/Seccomp,然后编译成一个二进制跑遍 macOS/Linux/Windows。
两边的 README 都在说 "agent harness",但它们对 harness 这个词的理解几乎是相反的。
Claude Code 的 harness 像一个代模型决策的中央控制层:要不要并发?要不要压缩?要不要重试?10 种 Terminal 怎么映射成生产事故分类?这一切由 harness 替模型答完,模型只负责决策内容。
Codex 的 harness 更像一个给模型递工具、递权限、把 OS 这层栏杆挪到面前的薄壳。它不替模型决策太多,但每个工具调用都被 syscall 级别的 sandbox 框死,错了也跳不出虚拟边界。
这两段判断要看完整本文章 8 个维度的对比才站得住,下面就沿着这 8 个维度对着两边的源码看:技术栈、主循环、工具系统、压缩、权限、子 agent、扩展机制、跨端、最后再把"成本与可观测性"作为第 8 维度收束。每条结论都带文件路径和行号,下次你想验真伪,自己 grep 一下就行。
二、技术栈与项目布局:第一眼能看出的区别

图 2:左 Claude Code 是 Bun 跑的 1900 文件 TS 单仓;右 Codex 是 30+ Rust crate 的 workspace,按职责切成 core/protocol/tui/exec/sandbox/mcp 等独立二进制单元。
Claude Code 的 src/ 顶层是一个相对扁平的前端项目结构:Tool.ts / query.ts / QueryEngine.ts / Task.ts 全是文件级模块,下面再展开 tools/、services/、utils/、bridge/、coordinator/、ink/、memdir/、skills/、plugins/。所有东西都在同一个 npm 包里。
Codex 的 codex-rs/ 是个标准 Rust workspace,每个 crate 都是独立单位:
| crate | 干什么 |
|---|---|
core |
主循环、turn、agent、tool 调度、compact |
protocol |
公共 enum/struct(AskForApproval、SandboxPolicy、SessionSource...) |
tui |
终端 UI |
exec |
非交互执行入口 |
mcp-server / rmcp-client / codex-mcp |
MCP 服务端与客户端 |
linux-sandbox / sandboxing / windows-sandbox-rs |
三平台 sandbox 实现 |
apply-patch / execpolicy / tools |
工具与策略 |
app-server / app-server-daemon |
长驻守护进程 |
sdk/typescript / sdk/python |
语言绑定 |
这种 crate-per-job 的切法暴露了 Codex 的一个产品意图:把 harness 的每一块都做成可复用单元 ,外部 IDE 或服务可以只挑 app-server 或 mcp-server 接进来。Claude Code 没这一层,所有 IDE/Bridge 整合都靠 bridge/ 子目录里的 JWT + workSecret 协议从一个 npm 进程内部分流。
差异背后的折中很明显:
- TS/Bun 的代价是每次都要拉一个 Node 运行时,但好处是改代码不用编译;hook、skill、plugin 都是 markdown 或 TS 文件,热加载非常顺。
- Rust 的代价是修一行代码要编译数十秒,但好处是单二进制可以直接跑在没有 Node 的服务器上,内存安全顺便白送。
这也直接决定了两边的扩展生态长什么样。Claude Code 的 hook + skill + plugin 这套用 Markdown 表达扩展的能力,几乎只有动态语言才能做得这么轻------开发者写一份 frontmatter 加正文就能塞进 skills/ 目录。Rust 这边要做对应能力得编 cdylib 或重启进程,自然不会选这条路。
三、维度 1:主循环------状态机 vs 朴素循环
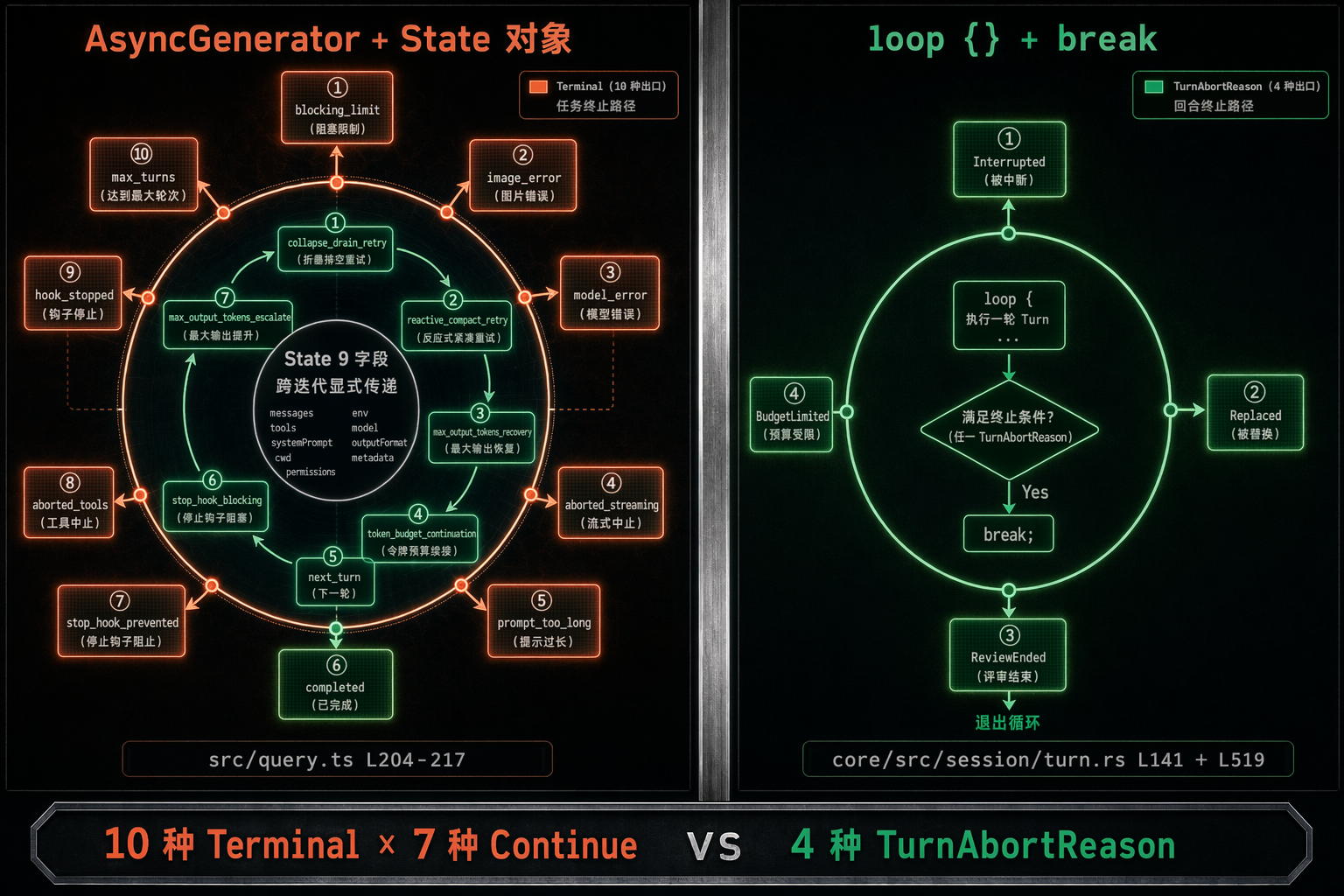
图 3:左 Claude Code 用 AsyncGenerator + State 对象 + 10 种 Terminal + 7 种 Continue 显式枚举每条路径;右 Codex 用 loop {} + break + 4 种 TurnAbortReason 收口。
Claude Code:把每条岔路都写进类型
src/query.ts L219 的签名长这样:
ts
export async function* query(
params: QueryParams,
): AsyncGenerator<
| StreamEvent
| RequestStartEvent
| Message
| TombstoneMessage
| ToolUseSummaryMessage,
Terminal
> {返回值类型是 Terminal------整个主循环结束时必须给出一个具体的退出原因。源码里出现 10 种:
blocking_limit / image_error / model_error / aborted_streaming /
prompt_too_long / completed / stop_hook_prevented / aborted_tools /
hook_stopped / max_turns每一种都对应一个生产事故分类,可以直接进 dashboard 做饼图。
State 对象是 9 个字段,跨迭代显式传递(src/query.ts L204-217):
ts
type State = {
messages: Message[]
toolUseContext: ToolUseContext
autoCompactTracking: AutoCompactTrackingState | undefined
maxOutputTokensRecoveryCount: number
hasAttemptedReactiveCompact: boolean
maxOutputTokensOverride: number | undefined
pendingToolUseSummary: Promise<ToolUseSummaryMessage | null> | undefined
stopHookActive: boolean | undefined
turnCount: number
transition: Continue | undefined
}注意最后那个 transition 字段。每次循环要 continue 都写一次它,告诉下一轮"刚刚是因为什么原因再来一遍"。源码里所有 transition.reason 加起来一共 7 种:
collapse_drain_retry / reactive_compact_retry / max_output_tokens_escalate /
max_output_tokens_recovery / stop_hook_blocking / token_budget_continuation /
next_turn这玩意儿乍一看像是工程洁癖,实际上解决的是任何写过 agent loop 的人都遇到过的痛点:这一轮到底是因为什么继续的 ?没有 transition.reason 你就只能去翻消息内容自己反推。有了它,测试可以直接 assert(state.transition.reason === 'reactive_compact_retry'),监控可以按 reason 画分布。
最值得拎出来看的是 L1293-1297 那段保护:
ts
// Preserve the reactive compact guard --- if compact already ran and
// couldn't recover from prompt-too-long, retrying after a stop-hook
// blocking error will produce the same result. Resetting to false
// here caused an infinite loop: compact → still too long → error →
// stop hook blocking → compact → ... burning thousands of API calls.
hasAttemptedReactiveCompact,注释说人话:"曾经把这个标志位 reset 成 false,结果触发了几千次 API 调用的死循环。"这种先把人类语言写进注释、再用一个布尔位扛起来的代码,是生产环境踩坑的化石样本。
Codex:朴素 loop {} + 4 种退出原因
Codex 这边在 codex-rs/core/src/session/turn.rs L141 的 run_turn 函数里直接 loop {},每轮:
- 排空 pending_input(用户插话)
- 构建 sampling_request_input
- 调用
run_sampling_request - 检查
needs_follow_up和 token limit
退出条件是 L519 一行:
rust
if !needs_follow_up {
last_agent_message = sampling_request_last_agent_message;
// ... run stop hooks ...
break;
}中断/取消统一收到 TurnAbortReason(protocol/src/protocol.rs L3707):
rust
pub enum TurnAbortReason {
Interrupted, Replaced, ReviewEnded, BudgetLimited,
}注意这里 TurnAbortReason 只有 4 种,比 Claude Code 的 10 种 Terminal 粗很多。再加上 AgentStatus(L1680)的 7 种状态(PendingInit / Running / Interrupted / Completed / Errored / Shutdown / NotFound),Codex 一个 turn 总的 lifecycle 状态空间也就十几个枚举值。
这种粗粒度不是偷懒------Codex 的恢复策略是"指数退避重试 + transport fallback",逻辑上简单一些就够。run_sampling_request L1106-1119 处的 fallback:WebSocket 跑挂了,自动降级到 HTTPS 再来一次。粗暴有效。
差别在哪
两条主循环映射的是两种不同的"生产可观测性"哲学:
- Claude Code 的态度是先把每条恢复路径命名,让运维和测试能直接对枚举值断言。代价是 query.ts 一个文件 1500+ 行,新增一种恢复原因要改 5 处枚举/类型/状态机。
- Codex 的态度是先简单跑通,只把外层中断原因(4 种)和异步状态机的 7 种 lifecycle 区分清楚。代价是中间出错时你只能从日志里往回翻。
如果是自己写 agent loop,建议先抄 Codex 的朴素结构,等踩到具体的死循环或诡异恢复,再把 transition.reason 这种字段加上去。Claude Code 的 7 种 continue reason 不是凭空设计的,每一种背后都至少有一次生产事故。
Takeaway:能用 enum 表达的退出/继续原因就别用字符串日志。当你想加第 8 种 reason 时,类型系统会强迫你把 5 处分支都更新一遍------这是好事不是坏事。
四、维度 2:工具系统------metadata 驱动 vs 锁驱动

图 4:Claude Code 把每个工具的 isConcurrencySafe / isReadOnly / isDestructive 写成 per-input 函数,连续 safe 的打成并发批;Codex 用一个 RwLock,supports_parallel 拿读锁,不 parallel 拿写锁。
Claude Code:每个工具自带一组元数据
src/Tool.ts L402-406 定义 Tool 接口的几个判定方法:
ts
isConcurrencySafe(input: z.infer<Input>): boolean
isEnabled(): boolean
isReadOnly(input: z.infer<Input>): boolean
/** Defaults to false. Only set when the tool performs irreversible
operations (delete, overwrite, send). */
isDestructive?(input: z.infer<Input>): boolean注意这里所有判定方法都接收 input 参数。同一个 BashTool 跑 ls 和跑 rm -rf 都会被分别判断------是 per-input 而不是 per-tool 的判定。这就把"工具元数据"从静态变成了根据 input 动态推断的东西。
更耐看的是 L748-769 的默认值:
ts
const TOOL_DEFAULTS = {
isEnabled: () => true,
isConcurrencySafe: (_input?: unknown) => false,
isReadOnly: (_input?: unknown) => false,
isDestructive: (_input?: unknown) => false,
checkPermissions: (input, _ctx?) =>
Promise.resolve({ behavior: 'allow', updatedInput: input }),
}除了 isEnabled 和 checkPermissions,所有元数据默认全部选保守的那一侧。新工具忘了声明 metadata 不会让系统更激进,只会让它更保守。这是非常工业化的 fail-closed 默认值------很多团队会把它做反,导致 prod 上线后才发现自己默认放行了一类危险操作。
调度逻辑在 src/services/tools/toolOrchestration.ts L91-116:
ts
function partitionToolCalls(toolUseMessages, toolUseContext): Batch[] {
return toolUseMessages.reduce((acc, toolUse) => {
const tool = findToolByName(toolUseContext.options.tools, toolUse.name)
const parsedInput = tool?.inputSchema.safeParse(toolUse.input)
const isConcurrencySafe = parsedInput?.success
? (() => { try { return Boolean(tool?.isConcurrencySafe(parsedInput.data)) }
catch { return false } })()
: false
...
}, [])
}13 行讲清楚了 Claude Code 的并发哲学:连续 isConcurrencySafe = true 打成一个并行批次,只要插一个不安全的工具就切回串行。safeParse 失败时默认不并发,回调抛异常时也默认不并发------两层 fail-closed。
并发上限在 L8-11,默认 10:
ts
function getMaxToolUseConcurrency(): number {
return parseInt(process.env.CLAUDE_CODE_MAX_TOOL_USE_CONCURRENCY || '', 10) || 10
}还有一个值得单独拎出来看的优化:StreamingToolExecutor(src/services/tools/StreamingToolExecutor.ts L48-60)。模型还在流式输出 tool_use block 时,executor 已经开始执行:
ts
// Child of toolUseContext.abortController. Fires when a Bash tool errors
// so sibling subprocesses die immediately instead of running to completion.
// Aborting this does NOT abort the parent --- query.ts won't end the turn.
private siblingAbortController: AbortController注释解释得很清楚:siblingAbortController 是父 abortController 的子,一个 Bash 工具失败时它一刀砍掉所有兄弟工具,但不会让外层 turn 直接终止。这种只爆一层、不会把整个 session 拖死的精细 abort 链,是任何写过 supervisor 的人都该抄的。
Codex:parallel 与否就靠一个锁
Codex 的工具定义在 codex-rs/tools/src/tool_definition.rs 简单到只有 5 个字段:
rust
pub struct ToolDefinition {
pub name: String,
pub description: String,
pub input_schema: JsonSchema,
pub output_schema: Option<JsonValue>,
pub defer_loading: bool,
}这里没有 is_concurrency_safe / is_read_only / is_destructive 这些元数据。Codex 走的是另一条路 :让工具自己声明 supports_parallel,剩下交给一个共享 RwLock 来串。
codex-rs/core/src/tools/parallel.rs L84-129:
rust
let _guard = if supports_parallel {
Either::Left(lock.read().await) // 并行:读锁
} else {
Either::Right(lock.write().await) // 串行:写锁
};一个 RwLock,supports_parallel 拿读锁,不 parallel 拿写锁。读锁不互斥,所以并行的工具可以一起跑;写锁互斥,所以串行的工具自然进队列。极简。
Codex 的工具有十几种,全在 codex-rs/core/src/tools/handlers/:shell/、apply_patch.rs、multi_agents.rs、multi_agents_v2/、mcp.rs、request_permissions.rs、request_user_input.rs、view_image.rs、tool_search.rs(动态发现)、plan.rs、goal/。注意有个 tool_search.rs------Codex 默认不会把所有工具都塞给模型,模型可以反过来通过 tool_search 工具按 schema 查找当前能用什么。这是一种相反方向的"懒加载"。
ToolName 还多了个 namespace 字段(protocol/src/tool_name.rs L9):
rust
pub struct ToolName {
pub name: String,
pub namespace: Option<String>,
}这是给 MCP 工具用的------同名工具来自不同 MCP server 时靠 namespace 区分,避免和内置工具撞车。
而工具流式执行 Codex 也有,在 turn.rs L1840 与 L2018:
rust
let mut stream = client_session.stream(prompt, ...).await??;
let mut in_flight: FuturesOrdered<BoxFuture<'static, CodexResult<ResponseInputItem>>> =
FuturesOrdered::new();
// 收到 OutputItemDone(FunctionCall) 立即 spawn 工具 future
if let Some(tool_future) = output_result.tool_future {
in_flight.push_back(tool_future);
}FuturesOrdered 保证按收到顺序的 future 完成顺序执行后续 step------这和 Claude Code 的 siblingAbortController 处理"半成品状态"的思路不同:Codex 选择让 future 自然完成或被 cancel token 中断,不主动一刀切兄弟。
如果你做的是分钟级长跑后台 agent,Claude Code 的精细 abort 链更稳------一个 Bash 卡死你不希望另外几个并行的 grep 全部干等到 timeout;如果是秒级短任务,Codex 的"future 自然完成"策略反而省心,少一层错误传播。
差别在哪
两套工具系统对应两种安全模型:
- Claude Code 把工具元数据写在 TS 类型里,由 harness 在调度前根据 input 动态推断。模型不需要懂"哪些工具能并发",harness 替它判断。
- Codex 把工具元数据简化成一个 supports_parallel 布尔,靠 RwLock 把并发约束物化成锁竞争。模型需要懂"自己能调几个工具",但 OS sandbox 兜底。
哪种更好?要看场景信不信 OS。如果目标用户是开发者本地用,OS sandbox 完全可信,那 Codex 的极简法更省心。如果是 SaaS 或 web 服务,OS 不一定可控的情况下,更倾向 Claude Code 这种应用层细粒度元数据------多一道纸糊的墙也好过没墙。
Takeaway:fail-closed 默认值不只是写漂亮代码,是踩过坑之后的剩余物。新增一类工具时如果默认值倾向"激进允许",迟早会有一个早晨醒来发现昨夜烧了 25 万次 API 调用。
五、维度 3:上下文压缩------5 层漏斗 vs 单层 LLM 摘要
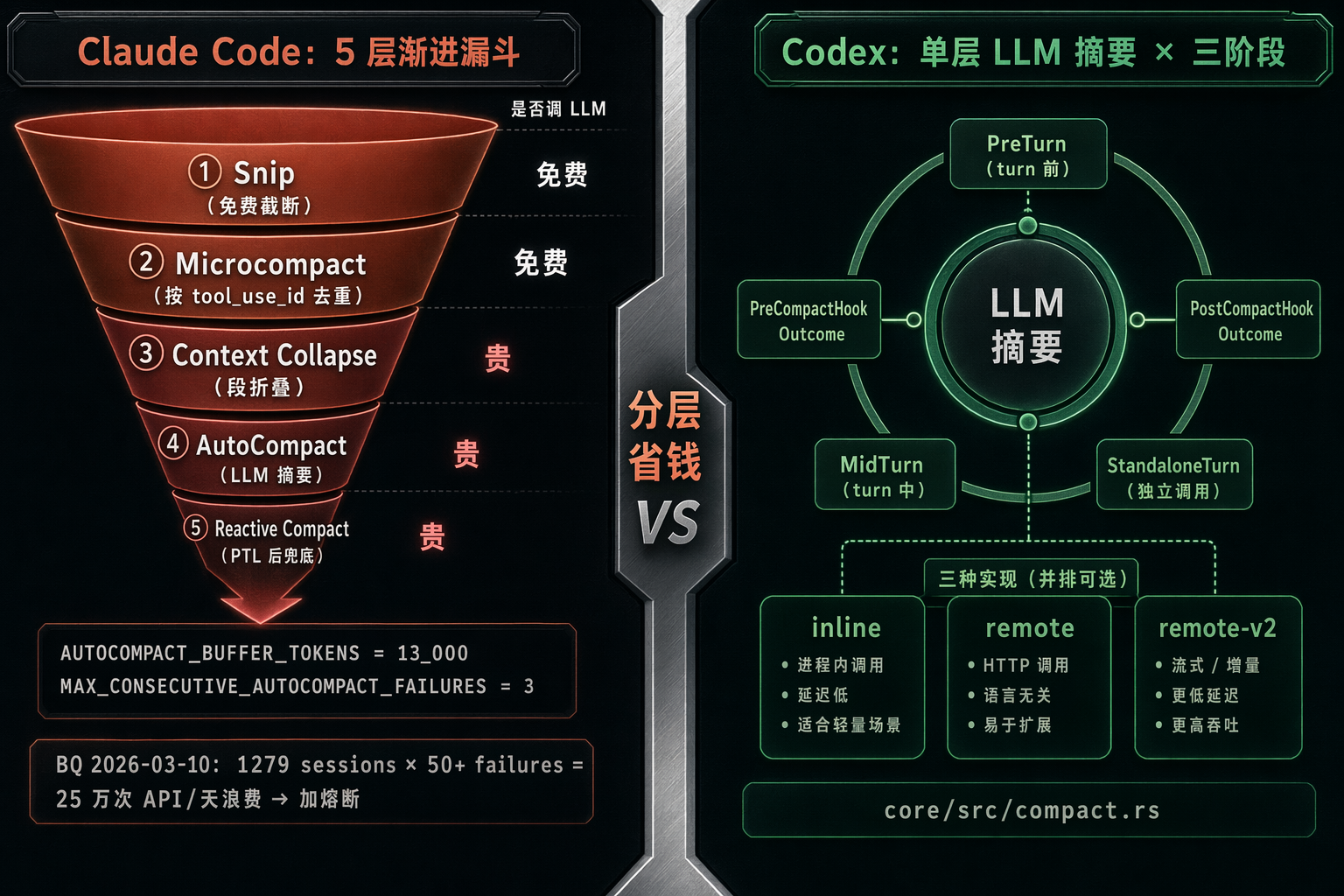
图 5:Claude Code 的 5 层渐进漏斗------免费的 Snip / Microcompact 在前,最贵的 AutoCompact 在后;Codex 是单层 LLM 摘要,但区分 PreTurn / MidTurn / Standalone 三种触发阶段,并配 Pre/Post hook 生命周期。
这是两边差异最大的一块,也是 take-away 最多的一部分。
Claude Code:5 层漏斗 + 250K 次 / 天的熔断
Claude Code 把上下文压缩拆成 5 层,按"从最便宜到最贵"的顺序逐级回退(按 query.ts L401 / L414 / L440 / L454 顺序触发):
- Snip :直接丢老的 round(feature gate
HISTORY_SNIP,services/compact/snipCompact.ts),不调 LLM。 - Microcompact :按 tool_use_id 去重工具结果(
services/compact/microCompact.ts,缓存编辑模式叫CACHED_MICROCOMPACT),仍然不调 LLM。 - Context Collapse :把老段折叠成 summary(feature gate
CONTEXT_COLLAPSE),可 projection 回放。 - AutoCompact :调 LLM 生成整体摘要(
services/compact/autoCompact.ts)。 - Reactive Compact :在
prompt_too_long错误发生后才按需触发,作为最后一道墙。
阈值常量在 autoCompact.ts L62-70:
ts
export const AUTOCOMPACT_BUFFER_TOKENS = 13_000
export const WARNING_THRESHOLD_BUFFER_TOKENS = 20_000
export const ERROR_THRESHOLD_BUFFER_TOKENS = 20_000
export const MANUAL_COMPACT_BUFFER_TOKENS = 3_000
// BQ 2026-03-10: 1,279 sessions had 50+ consecutive failures (up to 3,272)
// in a single session, wasting ~250K API calls/day globally.
const MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3最后那个常量值得单独拎出来。注释直接写:2026 年 3 月 10 号统计到 1279 个 session 出现过 50+ 连续 autocompact 失败,最严重一个 session 跑了 3272 次,全 fleet 一天浪费约 25 万次 API 调用。然后他们加了 MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3:连续失败 3 次熔断,停止重试。
这就是生产经验的化石------你看不到事故复盘报告,但事故的疤痕被一行常量永远固定在源码里。
post-compact 还有一组保留预算(compact.ts L122-131):
ts
export const POST_COMPACT_MAX_FILES_TO_RESTORE = 5
export const POST_COMPACT_TOKEN_BUDGET = 50_000
export const POST_COMPACT_MAX_TOKENS_PER_FILE = 5_000
export const POST_COMPACT_MAX_TOKENS_PER_SKILL = 5_000
export const POST_COMPACT_SKILLS_TOKEN_BUDGET = 25_000意思是:压缩完不是"光秃秃留个摘要",而是再补 5 个最近文件、每文件 5K 内、最近调用过的 skills 共计 25K------避免压缩后立刻又去读同一批文件造成 thrashing。
Codex:单层 LLM 摘要 + 三阶段 + Pre/Post Hook
Codex 走的是另一种思路:只做一种压缩动作 (LLM 摘要),但区分触发阶段 和执行位置。
codex-rs/core/src/compact.rs 的核心常量:
rust
pub const SUMMARIZATION_PROMPT: &str = include_str!("../templates/compact/prompt.md");
pub const SUMMARY_PREFIX: &str = include_str!("../templates/compact/summary_prefix.md");
const COMPACT_USER_MESSAGE_MAX_TOKENS: usize = 20_000;注意 prompt 是从 markdown 文件 include_str! 进来的------可以单独 review,可以让产品经理修改而不需要改 Rust。
触发阈值通过 model_auto_compact_token_limit(config/mod.rs L527)配置,turn loop L480 判断:
rust
let token_limit_reached = total_usage_tokens >= auto_compact_limit;
if token_limit_reached && needs_follow_up {
run_auto_compact(..., CompactionReason::ContextLimit, CompactionPhase::MidTurn).await;
}CompactionPhase 枚举三种:PreTurn / MidTurn / StandaloneTurn。意思是同一段压缩逻辑会被三个不同时机调用------在新 turn 开始前预先压(preventive)、在当前 turn 中间被打断时压(reactive)、或者作为单独的 standalone turn 被用户触发。
执行位置上 Codex 还有三种实现:
run_inline_auto_compact_task ------ 本地 inline
run_inline_remote_auto_compact_task ------ 远程
run_inline_remote_auto_compact_task_v2 ------ 远程 v2(迭代版)更有意思的是 Codex 给 compact 配了 hook 生命周期:PreCompactHookOutcome 和 PostCompactHookOutcome。开发者可以在压缩前后插入自己的逻辑,比如审计、备份、metric 上报。Claude Code 的 PreCompact / PostCompact 在 27 个 hook 事件里也有,但触发点的可定制粒度上 Codex 显式做成了 outcome enum 而非 string event。
InitialContextInjection(compact.rs L59)这个枚举也很有意思:
rust
pub(crate) enum InitialContextInjection {
BeforeLastUserMessage,
DoNotInject,
}压缩完之后要不要把"前情提要"重新塞回最后一条 user message 之前?两个选项,二选一。这种把决策维度写成最小封闭枚举的味道贯穿 Codex 全栈。
差别在哪
Claude Code 的 5 层漏斗背后是一种"省钱第一"的产品观:免费手段(截断 / 去重)在前,贵的 LLM 调用在后;每层都有自己的熔断;甚至 compact 调用本身也走父 prompt cache 共享,fleet 累计节省的 compute 折到周维度也是 Gtok 数量级(同一段 runAgent.ts L385-410 注释里 "~5-15 Gtok/week" 那一组数字)。
Codex 的单层摘要 + 三阶段背后是"分清楚层次"的工程观:压缩只有一种实质动作,但触发时机、执行位置、生命周期 hook 各自正交。开发者要扩展时,不用动核心算法,挑一个 phase 或 hook 插进去。
哪种更好?比较站得住的判断是:5 层漏斗只有 fleet-scale 才划算。Claude Code 那 5 层每加一层都需要踩一个具体坑------HISTORY_SNIP 是一个 feature gate,CONTEXT_COLLAPSE 是另一个 feature gate,它们都不是从 day 1 设计的,都是"线上某场景太贵了,加一层免费的"演化出来的。如果你是个起步项目,先抄 Codex 单层摘要,等用户量上来发现钱烧得太凶了,再把免费层往前加。
Takeaway:压缩策略最容易踩的坑不是"算法不对",而是"没有熔断"。
MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3这种常量看上去不起眼,没有它你的服务有概率把自己烧穿。
六、维度 4:权限与 Sandbox------AST 解析 vs OS 内核
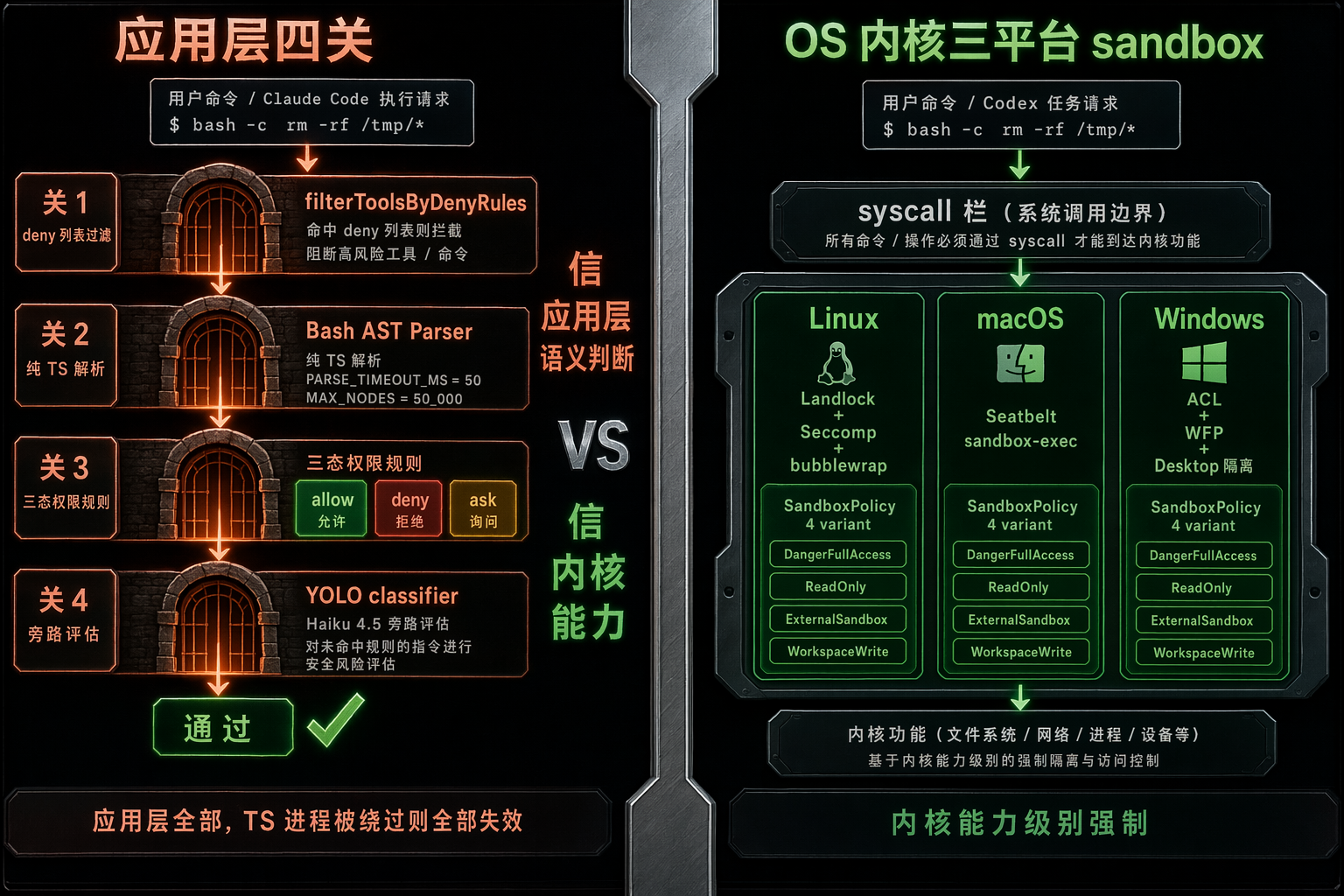
图 6:Claude Code 把 fail-closed 压在 TS 类型 + Bash AST 解析 + 三态权限规则上;Codex 把 fail-closed 压在 Linux Landlock+Seccomp+bubblewrap / macOS Seatbelt / Windows ACL+WFP 这些 OS 内核能力上。
这是两边哲学差异最显眼的一块。
Claude Code:用应用层把"危险动作"挡掉
Claude Code 没有 OS-level sandbox。它的安全完全压在应用层的几道关卡上:
第一关:deny rules 过滤工具集 。filterToolsByDenyRules 在 system prompt 构建前就把 deny 列表里的工具滤掉,模型根本看不到。
第二关:Bash AST parser 。src/utils/bash/bashParser.ts L1-30 有这么一段非常野的注释:
ts
/**
* Pure-TypeScript bash parser producing tree-sitter-bash-compatible ASTs.
* Validated against a 3449-input golden corpus generated from the WASM parser.
*/
const PARSE_TIMEOUT_MS = 50
const MAX_NODES = 50_0003449 条 golden corpus 是从原来的 WASM tree-sitter parser 生成的------也就是说他们先用 WASM 跑过几千条真实命令拿到正确 AST,再把这些 case 当测试集,然后从头写了一份纯 TS 的 parser 来匹配。50ms 解析超时 + 50K 节点上限是给对抗输入留的逃生口。
为什么不继续用 WASM?纯 TS 启动更快、bundle 更小、不依赖外部 .wasm 文件。代价是写一个 bash parser 从零开始,golden corpus 验证 3449 条------这个工程量光听描述就肝疼。
第三关:三态权限规则 (src/Tool.ts L123-138):
ts
export type ToolPermissionContext = DeepImmutable<{
mode: PermissionMode
alwaysAllowRules: ToolPermissionRulesBySource
alwaysDenyRules: ToolPermissionRulesBySource
alwaysAskRules: ToolPermissionRulesBySource
...
}>allow / deny / ask 三态,规则按来源分(user-config / project-config / managed-policy / built-in),优先级有讲究。
第四关:YOLO classifier 。auto mode 下跑一个 Claude Haiku 旁路评估每条命令的风险等级(src/utils/permissions/yoloClassifier.ts)。System prompt 从 yolo-classifier-prompts/auto_mode_system_prompt.txt 加载。Haiku 成本几乎可以忽略,但能在主模型决定执行前再做一次 LLM-级别的安全过滤。
四道关卡全是应用层。优势是细粒度高、可以做语义判断("这条命令在意图上是不是危险");劣势是只要 Claude Code 的 TS 进程被绕过,sandbox 就没了。
Codex:把 fail-closed 压到 OS
Codex 的安全模型是另一种风格------把内核能力请到台前。
Linux :codex-rs/linux-sandbox/src/landlock.rs 用 Landlock ABI + Seccomp BPF:
rust
pub(crate) fn apply_permission_profile_to_current_thread(
permission_profile: &PermissionProfile,
cwd: &Path,
apply_landlock_fs: bool,
allow_network_for_proxy: bool,
proxy_routed_network: bool,
) -> Result<()> { ... }文件系统访问由 bubblewrap (bwrap) 命名空间隔离,网络由 seccomp 系统调用过滤------子进程在 syscall 层直接被禁止访问限制路径或建 outbound socket,不靠应用层"判断这条命令危不危险"。
macOS :codex-rs/sandboxing/src/seatbelt.rs:
rust
const MACOS_SEATBELT_BASE_POLICY: &str = include_str!("seatbelt_base_policy.sbpl");
pub const MACOS_PATH_TO_SEATBELT_EXECUTABLE: &str = "/usr/bin/sandbox-exec";直接调系统的 /usr/bin/sandbox-exec,policy 写在 .sbpl 文件里。
Windows :codex-rs/windows-sandbox-rs/,含 ACL、WFP(Windows Filtering Platform)、Desktop 隔离、Token 权限降低、进程属性。这是 Codex 仓库里最大的一个 sandbox crate,因为 Windows 的隔离能力本来就比 Unix 系散乱。
Sandbox 的策略走 protocol/src/protocol.rs L994 的 SandboxPolicy:
rust
pub enum SandboxPolicy {
DangerFullAccess,
ReadOnly { network_access: bool },
ExternalSandbox { network_access: NetworkAccess },
WorkspaceWrite { writable_roots, network_access, exclude_tmpdir_env_var, ... },
}四个 variant 把"完全开放 / 只读 / 外部 sandbox / 工作区可写"这四种典型部署形态显式枚举出来。WorkspaceWrite 还能配 writable_roots、exclude_tmpdir_env_var 等细节。
审批策略 AskForApproval(L900):
rust
pub enum AskForApproval {
UnlessTrusted, // 仅只读命令自动通过
OnFailure, // 沙箱失败才问
OnRequest, // 模型决定何时问(默认)
Granular(GranularApprovalConfig),
Never,
}OnFailure 这种命名本身就在表态------日常都让 sandbox 兜,只有当 sandbox 真的拦下来了,才升级到问用户。这个策略名等于在告诉用户:信内核能力,不信应用层判断。
codex-rs/execpolicy/ 还提供命令级 prefix rule 白名单作为补充。
差别在哪
两条思路的根本分歧:
- Claude Code 信应用层语义判断 :Bash AST 解析后能识别
rm -rf /这种语义危险------哪怕 syscall 层是合法的;YOLO classifier 还能在意图层再判一道。代价是凡是 TS 进程内的代码都能绕过。 - Codex 信内核:syscall 在 namespace / Landlock / Seatbelt 层就被拦掉,应用层逻辑被绕过也没用。代价是只能拦"系统能拦的"------对于"语义危险但 syscall 合法"的命令,OS sandbox 帮不了你。
这两条不是对立的。比较稳的做法是:真正生产级的 agent harness 应该两层都有 ------syscall 兜底 + 应用层 AST 做语义判断。Codex 自己也有 execpolicy 做 prefix 白名单------只是它的应用层比较浅。
Takeaway:如果你只能选一种,先选 OS sandbox。AST 解析靠人写黑名单,永远跟不上手段更新。Landlock/Seatbelt 这种 OS 能力是被很多年攻防验证过的。
七、维度 5:子 Agent------7 种 Task 类型 vs 内核级 spawn_agent
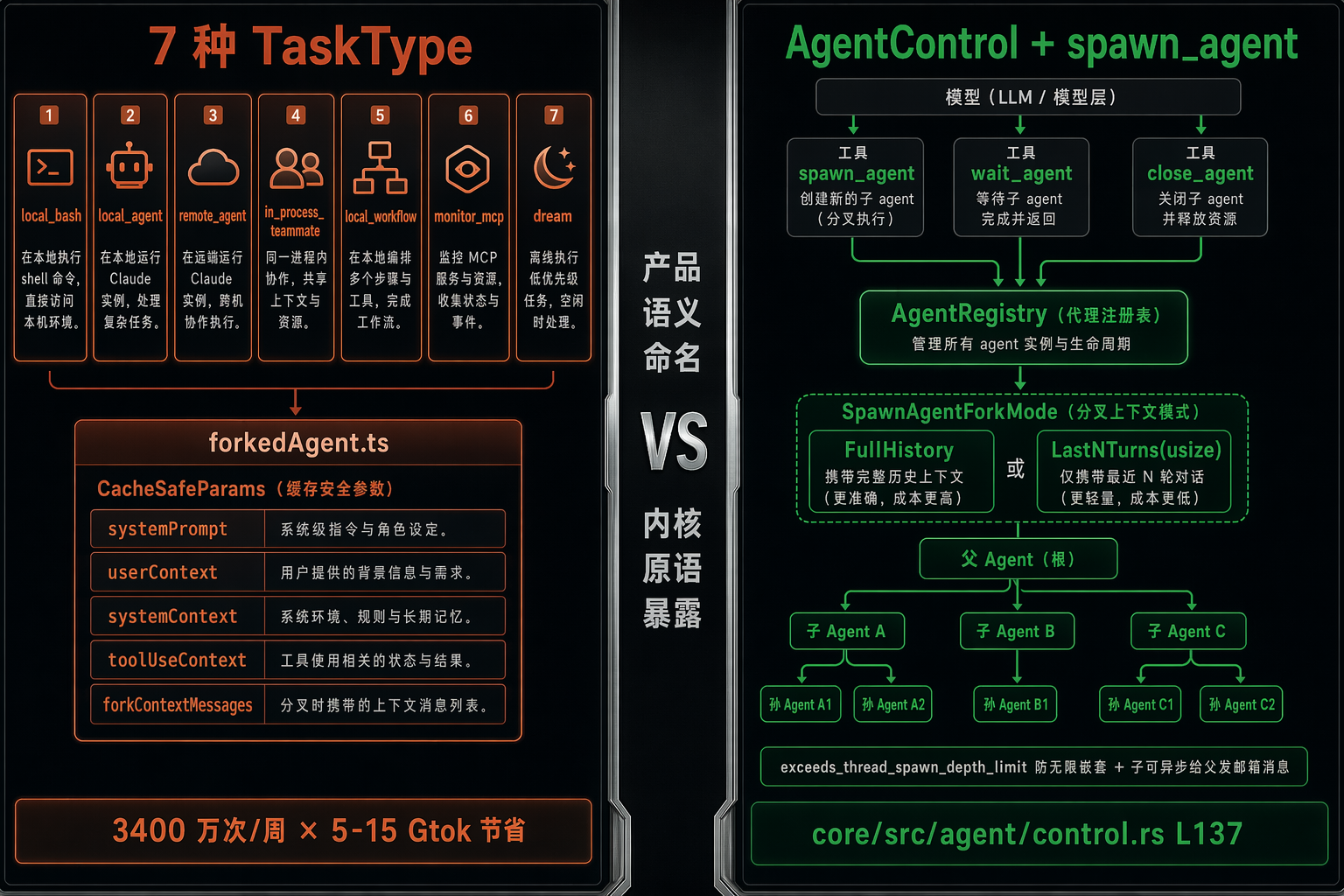
图 7:左 Claude Code 的 7 种 TaskType 各自对应一种执行模式(local_bash / local_agent / remote_agent / in_process_teammate / local_workflow / monitor_mcp / dream),靠 forkedAgent.ts 的 CacheSafeParams 共享父 prompt cache;右 Codex 直接做 AgentControl + AgentRegistry,模型用 spawn_agent / wait_agent 工具显式编排。
一个常见的误解是只有 Claude Code 才有"子 agent"概念。读完 Codex 之后会发现两边都做了,但路径完全不同。
Claude Code:7 种 Task 类型 + 隔离膜
src/Task.ts L6-13:
ts
export type TaskType =
| 'local_bash'
| 'local_agent'
| 'remote_agent'
| 'in_process_teammate'
| 'local_workflow'
| 'monitor_mcp'
| 'dream'7 种类型,各自对应一种生命周期:本地 shell 任务、本地 agent 进程、远端 agent、同进程的 teammate 协作、workflow 编排、MCP 监控、还有一个叫 "dream" 的(猜测是离线/低优先级的任务)。
子 agent 上下文克隆在 src/utils/forkedAgent.ts,关键是 5 个字段必须字节级一致才能命中父的 prompt cache(L57-68):
ts
export type CacheSafeParams = {
systemPrompt: SystemPrompt
userContext: { [k: string]: string }
systemContext: { [k: string]: string }
toolUseContext: ToolUseContext
forkContextMessages: Message[]
}注释里提到 budget_tokens 改一个数字 cache 就全没------thinking config 也是 cache key 的一部分。
更精彩的是 L413-417 那个逃生通道:
ts
// Task registration/kill must always reach the root store, even when
// setAppState is a no-op --- otherwise async agents' background bash tasks
// are never registered and never killed (PPID=1 zombie).
setAppStateForTasks:
parentContext.setAppStateForTasks ?? parentContext.setAppState,子 agent 默认所有 mutable state 都被替换成 no-op(包括 setAppState),但 setAppStateForTasks 单独走逃生通道直连根 store。原因写在注释里:后台 bash 任务必须能注册到根 AppState 才能被正确 kill,不然变 PPID=1 僵尸进程。
这种绝大多数都隔离、只开一个最窄的逃生通道的设计值得停下来体会。这是工程审美。
src/tools/AgentTool/runAgent.ts L385-410 还有一段经验金句:
ts
// Read-only agents (Explore, Plan) don't act on commit/PR/lint rules from
// CLAUDE.md --- the main agent has full context and interprets their output.
// Dropping claudeMd here saves ~5-15 Gtok/week across 34M+ Explore spawns.
const shouldOmitClaudeMd = agentDefinition.omitClaudeMd && ...每周在 3400 万次 Explore 调用上省 5-15 Gtok。这种优化只有 fleet-scale 才会发现------但思路是任何规模都能抄的:只读 agent 不需要 commit message 规则。
Codex:spawn_agent 是一个工具
Codex 这边,子 agent 不是 7 种类型,而是一个内核能力:AgentControl(codex-rs/core/src/agent/control.rs L137):
rust
pub(crate) struct AgentControl {
session_id: SessionId,
manager: Weak<ThreadManagerState>,
state: Arc<AgentRegistry>,
}spawn_agent_with_metadata(L185):
rust
pub(crate) async fn spawn_agent_with_metadata(
&self,
config: crate::config::Config,
initial_operation: Op,
session_source: Option<SessionSource>,
options: SpawnAgentOptions,
) -> CodexResult<LiveAgent> { ... }模型通过 spawn_agent、wait_agent、close_agent 这些工具调用显式 spawn 子线程。子 agent 继承父的 model/sandbox/approval 配置,可选 role 覆盖。
SpawnAgentForkMode(L48)二选一:
rust
pub(crate) enum SpawnAgentForkMode {
FullHistory,
LastNTurns(usize),
}要么完整传父历史,要么只传最后 N 轮------和 Claude Code 的 forkContextMessages 类似但更显式。
还有 exceeds_thread_spawn_depth_limit 检查避免无限嵌套。
multi_agents.rs 里实现了 inter-agent 邮箱机制------子 agent 可以异步给父 agent 发消息,父 agent 也可以等待子 agent 完成。这就比 Claude Code 的"父只看子的最终输出"强一些。
差别在哪
两条 sub-agent 哲学:
- Claude Code 的 sub-agent 是产品形态:7 种类型按使用场景命名,每种都有 UI 反馈、有 sidechain transcript。模型不用关心 spawn / wait / close 这些原语,只调一次 Task tool 就行。
- Codex 的 sub-agent 是内核能力:模型直接看到 spawn_agent / wait_agent / close_agent 这些原语,自己负责编排。harness 提供机制,不提供策略。
产品形态决定选哪种:
- 如果你做的是面向终端用户的 CLI,Claude Code 那种"7 种命名好的 task 类型"产品感更强,用户能从 UI 看出"这个 task 在跑 Explore 还是 Plan"。
- 如果你做的是给 LLM 操作的内核(比如下游再有个 agent 编排框架),Codex 那种 spawn/wait/close 原语反而更通用------你可以在上面叠任何调度策略。
Takeaway:sub-agent 设计的核心问题不是"要不要支持",而是"暴露给模型的是产品语义还是内核原语"。这两条路都走得通,但中间那种"既不像产品也不像内核"的设计是踩坑陷阱。
八、维度 6:扩展机制------27 个 Hook + Skills 懒加载 vs MCP 双向

图 8:Claude Code 的扩展是 27 种 hook 事件 + Skills 懒加载 + Plugin 打包三层独立结构;Codex 把所有扩展面收到 MCP 这一根 wire 上,靠 mcp-server / rmcp-client 双向 stdio JSON-RPC 完成。
Claude Code 的扩展面积非常大,hook 事件 27 种全部列在 src/entrypoints/sdk/coreTypes.ts L25-53:
ts
export const HOOK_EVENTS = [
'PreToolUse', 'PostToolUse', 'PostToolUseFailure', 'Notification',
'UserPromptSubmit', 'SessionStart', 'SessionEnd', 'Stop', 'StopFailure',
'SubagentStart', 'SubagentStop', 'PreCompact', 'PostCompact',
'PermissionRequest', 'PermissionDenied', 'Setup', 'TeammateIdle',
'TaskCreated', 'TaskCompleted', 'Elicitation', 'ElicitationResult',
'ConfigChange', 'WorktreeCreate', 'WorktreeRemove',
'InstructionsLoaded', 'CwdChanged', 'FileChanged',
] as constPreToolUse 这种 hook 还能改命 ------AggregatedHookResult(src/types/hooks.ts L277-289):
ts
export type AggregatedHookResult = {
preventContinuation?: boolean
permissionBehavior?: PermissionResult['behavior']
additionalContexts?: string[]
updatedInput?: Record<string, unknown>
updatedMCPToolOutput?: unknown
permissionRequestResult?: PermissionRequestResult
retry?: boolean
}返回 preventContinuation: true 阻止工具执行;返回 updatedInput 改写模型的参数;返回 additionalContexts 给后续 turn 注入提示。这是把"harness 代模型决策"做到极致的设计。
还有一个非常细的工程细节,utils/hooks/hookEvents.ts L20 / L57-78 的事件队列:
ts
const MAX_PENDING_EVENTS = 100
const pendingEvents: HookExecutionEvent[] = []
let eventHandler: HookEventHandler | null = null
function emit(event: HookExecutionEvent): void {
if (eventHandler) { eventHandler(event) }
else {
pendingEvents.push(event)
if (pendingEvents.length > MAX_PENDING_EVENTS) { pendingEvents.shift() }
}
}handler 还没注册时事件先进队列,handler 上线时批量 flush。这是"迟到订阅者也能拿到启动事件"的标准做法------对插件和 skill 的动态加载非常关键。
Skill 走的是另一条懒加载路径。src/skills/loadSkillsDir.ts L97-103:
ts
/**
* Estimates token count for a skill based on frontmatter only
* (name, description, whenToUse) since full content is only loaded on invocation.
*/
export function estimateSkillFrontmatterTokens(skill: Command): number {
const frontmatterText = [skill.name, skill.description, skill.whenToUse]
.filter(Boolean).join(' ')启动时只 load frontmatter(约 100 tokens),正文(可能 20K+)只在 SkillTool 调用时才 fetch。50 个 skill 启动成本是 5K 而不是 1M。
LoadedFrom 类型(L67-73)区分了来源:
ts
export type LoadedFrom =
| 'commands_DEPRECATED' | 'skills' | 'plugin' | 'managed' | 'bundled' | 'mcp'isRestrictedToPluginOnly(src/utils/settings/pluginOnlyPolicy.ts)被 7 个文件引用,企业管理员可以强制"只允许官方 plugin 提供 skill / hook / MCP"。
而 Codex 这边------基本上没有 hook这个独立机制。扩展面积主要落在 MCP 上:
codex-rs/mcp-server/让 Codex 暴露 自己作为 MCP server,外部应用可以通过 stdio JSON-RPC 调用codex_tool_runner、exec_approval、patch_approval等。codex-rs/rmcp-client/让 Codex 消费 外部 MCP server 提供的工具(stdio_server_launcher.rs启动外部进程,elicitation_client_service.rs反向 elicit user input)。codex-rs/codex-mcp/管 namespace 路由。
这就是 Codex 的扩展观:所有扩展都走 MCP 这一条 wire。要扩 tool?写 MCP server。要让 Codex 给别的工具用?把 Codex 跑成 MCP server。
Compact 那边 Codex 倒是有 PreCompactHookOutcome / PostCompactHookOutcome,但这是个例不是体系。
差别在哪
- Claude Code 的扩展是面向开发者 :27 种 hook、Skills 懒加载、Plugin 打包,每种扩展形态对应一种使用场景。代价是扩展面积爆炸,企业管控需要
isRestrictedToPluginOnly这种闸门。 - Codex 的扩展是面向系统集成:MCP 双向就是一切,外部系统通过 stdio JSON-RPC 接 Codex,Codex 通过 stdio JSON-RPC 接外部系统。代价是细粒度操控(如 PreToolUse 改命)做不到,只能在 tool 层面拼。
如果你做的是开发者社区生态,Claude Code 的多种扩展形态更顺;如果你做的是企业 IDE 集成,Codex 这种"全走 MCP"反而更省心------一种协议覆盖所有边界。
Takeaway:扩展机制最容易踩的坑是"什么都做"。Claude Code 27 种 hook 的演化是踩坑驱动的,不是 day 1 设计的。Codex 把扩展面收到 MCP 一条 wire 上,是另一种克制。
九、维度 7:跨端 / 多入口------可选回调 vs 单二进制多 mode
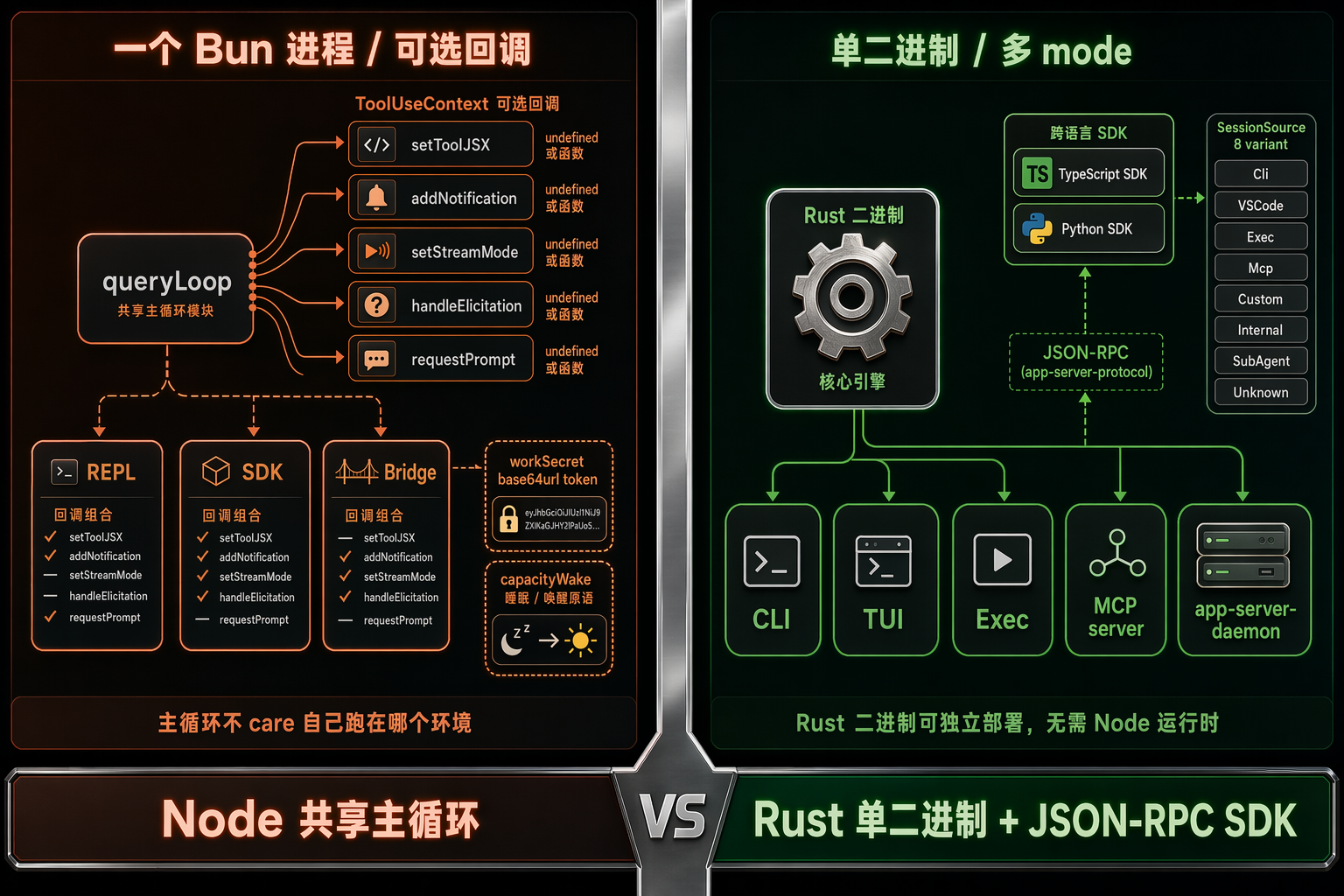
图 9:左 Claude Code 在一个 Bun 进程里靠 ToolUseContext 上的可选回调区分 REPL/SDK/Bridge;右 Codex 是单 Rust 二进制 + 5 种 mode(CLI/TUI/Exec/MCP server/app-server-daemon),加 TS 和 Python SDK。
Claude Code 的多端实现非常巧妙。所有 mode 共享同一个 queryLoop,区分仅靠 ToolUseContext 上的可选回调(来自 Tool.ts 节选):
ts
export type ToolUseContext = {
options: { /* tools, mcpClients, commands, ... */ }
abortController: AbortController
readFileState: FileStateCache
getAppState(): AppState
setAppState(f): void
setToolJSX?: SetToolJSXFn
addNotification?: (...)
setStreamMode?: (mode)
handleElicitation?: (serverName, params, signal) => Promise<ElicitResult>
requestPrompt?: (sourceName, summary) => (req) => Promise<PromptResponse>
agentId?: AgentId
}注意那些 ?:------非本环境的回调直接 undefined。主循环代码完全不 care 自己跑在哪个环境,只 care "这个回调在不在"。这是极简的多端接口。
Bridge 那边是另一套机制。src/bridge/workSecret.ts L6-31:
ts
export function decodeWorkSecret(secret: string): WorkSecret {
const json = Buffer.from(secret, 'base64url').toString('utf-8')
...
if (typeof obj.session_ingress_token !== 'string' || ...)
throw new Error('Invalid work secret: missing or empty session_ingress_token')
}workSecret 是 base64url 编码的 JSON,包含 session_ingress_token 和 api_base_url。Bridge 进程靠这个 token 接管 session,把本地状态 pipe 给手机或 IDE。
src/bridge/capacityWake.ts L1-9 的注释把多端协作的核心问题写得很清楚:
ts
/**
* Shared capacity-wake primitive for bridge poll loops.
* Both replBridge.ts and bridgeMain.ts need to sleep while "at capacity"
* but wake early when either (a) the outer loop signal aborts (shutdown),
* or (b) capacity frees up (session done / transport lost).
*/"at capacity 时睡着,shutdown 或 session 完成时立刻醒"------这是任何长连接代理都要解决的问题。
Codex 那边走的是另一条路。codex-rs/cli/src/main.rs 是一个 dispatcher,根据子命令进入不同 mode:
codex_tui::Cli--- TUI 交互codex_exec::Cli--- 非交互执行(headless)- MCP server 模式
app-server/app-server-daemon--- 长驻守护进程(类 LSP protocol)
SessionSource(protocol/src/protocol.rs L2519)枚举了所有来源:
rust
pub enum SessionSource {
Cli,
VSCode,
Exec,
Mcp,
Custom(String),
Internal(InternalSessionSource),
SubAgent(SubAgentSource),
Unknown,
}然后 app-server-protocol 是个 JSON-RPC 协议------VS Code、自家 SDK、其他 IDE 都通过这个协议跟 daemon 通信。sdk/typescript/ 和 sdk/python/ 就是协议的语言绑定。
差别在哪
- Claude Code 用进程内多端共享主循环:一个 Node 进程跑 REPL、跑 SDK 调用、跑 Bridge 远端,区分靠回调有无。代价是必须有 Node runtime,跨语言绑定难------你想给 Java/Go 工具链做嵌入接入会非常别扭。
- Codex 用单二进制多 mode + 跨语言 SDK:Rust 二进制可以独立跑在没 Node 的服务器上,但每个 mode 是独立子命令;多语言 SDK 通过 JSON-RPC 接 daemon,所以 Java/Go/Python 后端都能直接调。
- 共同点:主循环代码完全不 care 自己跑在哪个环境 。Claude Code 用"回调存在与否"实现这一点,Codex 用"SessionSource enum + mode 子命令"实现。两条路都避免了
if mode == 'repl' else if mode == 'sdk'这种到处分叉的反模式。 - 隐含的代价不一样:Claude Code 的可选回调写起来轻,但维护时一旦多端行为不一致,bug 散在调用点;Codex 的 mode 子命令把行为分支显式集中在 main.rs dispatcher,但增加一种 mode 要动整条编译链。
哪种更好?如果目标是"要一个 npx 一行就跑起来的开发工具",Claude Code 的 Node 路线让 hook/skill 这种 markdown 扩展非常顺。如果目标是"要让 Java/Go/Python 后端都能调用这个 agent",Codex 的 Rust + JSON-RPC 路线天然友好。
Takeaway:跨端不是从 day 1 决定的,是被部署形态逼出来的。两边都把"主循环不要 if mode == 'X'"这条原则做到了------一个用可选回调,一个用枚举 SessionSource。
十、维度 8:成本与可观测性------cache 字段对齐 vs 三种压缩实现
前 7 个维度看的是"功能对错"------能不能跑、安不安全、能不能扩。这一个维度看的是"花多少钱、出问题能不能查",是把 agent 推上 fleet 之后真正决定生死的层。
Claude Code:把 prompt cache 字段对齐当头号优化
src/utils/forkedAgent.ts L57-68 的 CacheSafeParams 之前提过,再贴一次:
ts
export type CacheSafeParams = {
systemPrompt: SystemPrompt
userContext: { [k: string]: string }
systemContext: { [k: string]: string }
toolUseContext: ToolUseContext
forkContextMessages: Message[]
}这 5 个字段必须字节级 和父 agent 一致,子 agent 才能命中父的 prompt cache。Anthropic 官方对这个机制的说明是:cache read 通常只要 cache write 的 10% 价格(见参考章 Anthropic Prompt Caching docs)。所以当你 fleet 每周有 3400 万次 Explore agent spawn 的时候(runAgent.ts L385-410 注释里的真实数字),命中或不命中 cache 是几个零的成本差距。
实操上有几个隐藏地雷:
- thinking budget 是 cache key 的一部分 。切个
budget_tokens整个 cache 就失效。所以切模型时 Claude Code 会显式 strip thinking signatures。 - Explore / Plan agent 主动剥离 claudeMd 和 gitStatus (
runAgent.tsL385-410 注释里写"saves ~5-15 Gtok/week")。原因是这两 agent 是只读的,不需要"commit message 要遵循 conventional commits"这种 rule,但每次都喂 30-40K tokens 进去太亏。 - Compact 调用刻意共享父 prompt prefix(同一段注释里)。压缩本身不便宜,但只要 cache 命中,compute 费用比 cache miss 时低一个量级------这是和上一条同等量级的 Gtok/week 节省。
可观测性这边,Claude Code 的事件队列设计精巧。utils/hooks/hookEvents.ts L20 / L57-78 之前提过的 MAX_PENDING_EVENTS = 100 + 早期事件先入队列、handler 上线再 flush------这意味着 hook 系统绝对不会丢启动事件 ,就算你的 plugin 是延迟加载的。Terminal.reason 10 种 + Continue.reason 7 种再加上 27 种 hook event,这套枚举体系直接对接 OpenTelemetry 的 attribute 维度都不需要适配层。
Codex:把"压缩在哪儿跑"也做成枚举
Codex 没有把 prompt cache 抽象成像 CacheSafeParams 这么显式的类型------但它在另一个维度做了取舍:压缩动作的执行位置可枚举 。回看 compact.rs 的三个实现:
run_inline_auto_compact_task ------ 本地 inline
run_inline_remote_auto_compact_task ------ 远程
run_inline_remote_auto_compact_task_v2 ------ 远程 v2为什么搞三种?因为 Codex 的部署形态是"本地二进制 + 远端 daemon + IDE 客户端"三种叠加。压缩有时候在你笔记本里跑(inline),有时候在 daemon 里跑(remote),v2 是后来重做的版本。这三种实现共享同一份 SUMMARIZATION_PROMPT 模板(include_str!("../templates/compact/prompt.md")),但运行环境不同------这是把"成本结构"作为一种 enum 编进代码。
COMPACT_USER_MESSAGE_MAX_TOKENS = 20_000 这个常量看起来很普通,但它定义了"任何一条 user message 超过 20K 都会被预先压"------是一种成本侧的 fail-closed。不是等到 prompt_too_long 再处理,是预防性切。
可观测性这边,Codex 的 AgentStatus(7 种 lifecycle)+ TurnAbortReason(4 种)+ SessionSource(8 种)+ CompactionPhase(3 种)合起来同样可以投到 metric 维度上。但相对 Claude Code 那种"每条 transition 都有 reason"的力度就粗一些。
差别在哪
- Claude Code 的成本观是字段对齐:每一处 fork / compact / sub-agent spawn 都在压榨 cache 命中。可观测性是 reason 枚举密集铺,"每条 continue 都能被 dashboard 切片"。
- Codex 的成本观是位置枚举:把 inline / remote / remote-v2 当成不同压缩实现,按部署形态选。可观测性是 lifecycle 枚举,"每个 turn 都能被 status 标记"。
什么场景偏哪种?如果你的 agent 调用密度极高(每用户每分钟几十次 turn),prompt cache 字段对齐这种细颗粒优化非常划算。如果你的 agent 是每个 task 几分钟、人工触发,三种压缩位置反而更重要------你需要选"在哪儿跑"。
Takeaway:成本和可观测性是同一件事的两面。能精确度量的成本才能精确优化,反过来能精确分桶的事件流才能精确归因。Claude Code 选了字段对齐 + reason 密集;Codex 选了位置枚举 + lifecycle 三态。两者都比"反正把日志打到 ELK 里"强一个量级。
十一、要抄哪段?一张选型表
把前面 8 个维度的差异收成一张可执行清单------你在做什么类型的产品,左边一列定位自己,右边一列直接告诉你抄哪边。每一行背后都对应着一种典型的项目场景,不是凭空对仗。
| 你在做的事 | 推荐抄的部分 |
|---|---|
| 个人 / 小团队的 coding 助手 | 抄 Codex 的朴素 loop {} + TurnAbortReason,等坑出来再升 enum |
| 走自托管的企业 agent SaaS | 抄 Claude Code 的 Terminal.reason + transition.reason,从一开始就让运维能按 reason 分桶 |
| 服务端无人值守 agent(无开发者本地 OS) | 抄 Codex 的 OS sandbox 三件套(Landlock / Seatbelt / WFP);只信内核,别信应用层 |
| 桌面 dev tool(开发者自愿安装运行) | 抄 Claude Code 的 Bash AST + 三态权限规则,UX 上能让用户一键 always allow |
| 多 LLM 任务编排框架 | 抄 Codex 的 spawn_agent 内核能力,把策略留给上层 |
| 面向终端用户的产品化 agent | 抄 Claude Code 的 7 种 TaskType + sidechain transcript,让 UI 能呈现"这是 Explore / Plan / Workflow" |
| 上下文压缩第一版 | 抄 Codex 的单层 LLM 摘要 + Pre/Post hook,先把生命周期插槽留好 |
| 上下文压缩 fleet 优化 | 抄 Claude Code 的 5 层漏斗,免费手段优先;务必加 MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES 熔断 |
| 多语言 SDK / IDE 集成 | 抄 Codex 的 app-server-protocol JSON-RPC + Rust 单二进制 |
| 富 markdown 扩展生态(hook/skill/plugin) | 抄 Claude Code 的 27 个 hook + 懒加载 skill + plugin 打包 |
| 双向 MCP 集成 | 抄 Codex 的 mcp-server + rmcp-client 双 crate 拆法 |
十二、5 条可迁移到自家 harness 的设计准则
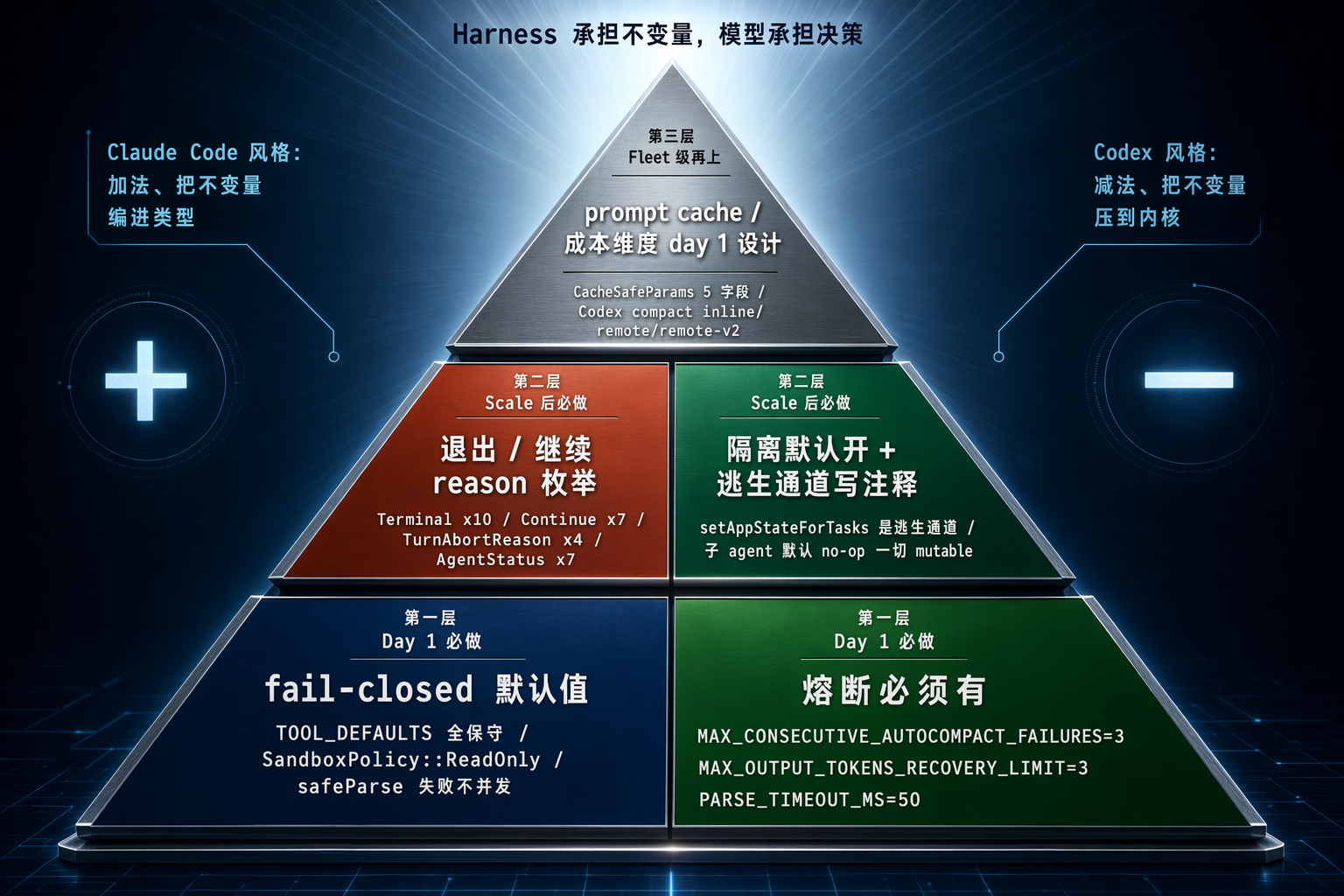
图 10:5 条可迁移准则按"项目阶段"组成的金字塔------地基是 fail-closed 默认值(保守度量),中层是熔断 + 隔离(防爆 + 隔污),顶层是状态机枚举 + cache 对齐(可归因 + 可优化)。三层从下往上做,越上层越是规模红利。
把两份源码的共识层提炼成 5 条,按"项目阶段"排序------day 1 必做的两条最重要,scale 后必做两条,fleet 级别再上最后一条:
【Day 1 必做】1. fail-closed 默认值贯穿一切。
Claude Code 的 TOOL_DEFAULTS 全部默认保守、safeParse 失败默认不并发、callback 抛错默认不并发;Codex 的 SandboxPolicy::ReadOnly { network_access: false }、AskForApproval::OnRequest。新增能力时如果默认偏激进,迟早会有一个早晨醒来发现昨夜烧了几十万次 API 调用。
【Day 1 必做】2. 熔断必须有,不要靠"下次能成"。
MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3、MAX_OUTPUT_TOKENS_RECOVERY_LIMIT = 3、MAX_PENDING_EVENTS = 100、PARSE_TIMEOUT_MS = 50、MAX_NODES = 50_000------每一个常量都是踩坑得来的。任何重试逻辑必须有上限;任何队列必须有 max size;任何解析必须有 timeout。
【Scale 后必做】3. 退出 / 继续原因要做成 enum,不要做成日志字符串。
Claude Code 的 10 种 Terminal + 7 种 Continue、Codex 的 4 种 TurnAbortReason + 7 种 AgentStatus,都是把"为什么停 / 为什么继续"显式枚举。这让运维能按 reason 分桶,让测试能精确断言恢复路径。日志字符串不行------一升级文案 dashboard 就崩。
【Scale 后必做】4. 隔离要默认开,逃生通道要写注释。
Claude Code 的 setAppStateForTasks 是逃生通道但注释明确写"task registration/kill must reach root store"------读代码的人能立刻明白这个例外的意义。所有 mutable 默认 no-op,只显式开必要的窗户。
【Fleet 级再上】5. prompt cache(或等价的成本维度)要从设计阶段就考虑。
Claude Code 的 CacheSafeParams 5 个字段必须字节级一致;Codex 的 compact 走 inline / remote / remote-v2 三套以适配不同部署。如果你跑大 fleet,这是真金白银------runAgent.ts 里那一周 5-15 Gtok 的注释不是 marketing,是优化沉淀。
十三、收束:harness 是产品,不是脚手架
读到这里,回头看会发现:Claude Code 和 Codex 在战术上完全相反,在战略上又惊人地一致。
战术上:
- Claude Code 把 harness 不变量写成 TS 类型 + 元数据 + AST + 三态权限,是 加法。
- Codex 把 harness 不变量压到 OS syscall + 几个紧致 enum 上,是 减法。
战略上:
- 两边都明白 prompt 不是产品力,harness 才是产品力。
- 两边都在每个关键决策点把"为什么"写成枚举或常量,让人类协作者能 grep 到原因。
- 两边都用 fail-closed 默认值兜底,把"忘了显式声明"导向更保守的行为而非更激进的行为。
如果你只能带走一句话:
Harness 承担不变量,模型承担决策。
剩下的所有差异------TS 还是 Rust、5 层漏斗还是单层摘要、27 hook 还是 MCP 双向、应用层 AST 还是 OS syscall------都只是这条原则在不同部署形态下的折中。
两种源码读起来观感完全不同。Claude Code 的源码像一本写满批注的工具书:每一行注释都在告诉读者"这里曾经踩过哪个坑"。Codex 的源码像一本简洁的教科书:每个 enum 的 variant 都齐整地排在一起,没有多余的话。两种风格各有可取之处,背后映射的工程文化也是不同的------前者是 fleet 上跑出来的疤,后者是先把骨架立好的勇气。
如果你打算自己写一套 harness,建议把这两份源码的 Tool.ts / query.ts / core/src/session/turn.rs / core/src/agent/control.rs 都读一遍,然后做一个清单:哪些是你的产品 day 1 就需要的,哪些是 fleet 大了再加的。
差异化的产品力不来自"调哪个 LLM"------这部分谁都能调到。差异化来自 harness 怎么把那个 LLM 卡进自己的工程不变量层。
参考
源码引用:
- Claude Code v2.1.88 src/ 镜像(2026-03-31 npm sourcemap 公开),路径见各章节
- OpenAI Codex
codex-rs/:github.com/openai/codex(Apache 2.0)
公开材料:
- Anthropic, "Effective context engineering for AI agents", 2025-09-29
- Anthropic, "Introducing Claude Opus 4.7", 2026
- Anthropic, "Prompt Caching" API 文档(cache read 价格约为 cache write 的 10%)
- Addy Osmani, "Agent Harness Engineering", 2026
- OpenAI, "Codex CLI" 官方文档(codex-rs/docs/)
(本文所有文件路径、行号、常量值、枚举 variant 均来自上述源码或公开材料,未作自创。)