Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

大家好呀,欢迎来到博主新开的《Effective Python 3rd Edition》学习笔记系列,毕竟也读过几百篇 SCI ,这次来试试阅读原版学习是一种怎样的体验。小伙伴们感兴趣的话,请一定要点赞,收藏加关注呀!
第二章 Strings and Slicing
Python 最初作为一种用于编排命令行实用程序和处理输入和输出数据的脚本语言而变得流行。凭借用于字符串和序列处理的内置语法、方法和模块,Python 成为传统 shell 和其他常见脚本语言(例如 Perl)的有力的替代品。 从那时起,Python 不断向邻近领域发展,成为解析文本、生成结构化数据、检查文件格式、分析日志等的理想编程语言。
通过使用 bytes 和 str 类型,Python 程序能够与人类语言文本进行交互、处理底层二进制数据格式、执行输入/输出(I/O)操作并与外部世界进行通信。Python 针对这些字符类型、列表以及其他类型进行了抽象处理,以提供一个通用的接口用于索引、序列化等操作。这些功能极为重要,几乎在所有程序中都能见到它们的踪影。
Item 13: 更喜欢显式字符串连接而不是隐式字符串连接,尤其是在列表中
在早期,Python 直接继承了许多来自 C 语言的特性,包括用于表示数字常量和类似 printf 格式化字符串的符号。自那时起,这门语言已发生了显著演变;例如,八进制数字如今需要加上前缀 0o,而不再仅仅是 0;此外,新的字符串插值语法也更为优越(参见 Item 11:"优先使用插值 F-strings,而非 C 风格格式字符串和 str.format")。然而,Python 中仍保留了一种类似于 C 语言的特性,即隐式字符串连接。这使得相邻的字符串表达式能够被直接拼接在一起,而无需使用中缀加号运算符。因此,这两个赋值操作实际上执行的是同样的事情:
my_test1 = "hello" "world"
my_test2 = "hello" + "world"
assert my_test1 == my_test2
这种隐式连接行为在需要将不同类型且具有不同转义要求的字符串常量进行组合时可能会非常有用,这在进行文本模板化或代码生成的程序中是一种常见的需要。例如,这里我隐式地合并了一个原始字符串、一个 f 字符串以及一个单引号字符串:
x = 1
my_test1 = (
r"first \ part is here with escapes\n, "
f"string interpolation {x} in here, "
'this has "double quotes" inside'
)
print(my_test1)
>>>
first \ part is here with escapes\n, string interpolation 1 in here, this has "double quotes" inside
将每种类型的字符串常量分别放在各自独立的行中,使得这段代码更易阅读;同时,缺少运算符也减少了视觉上的杂乱。相比之下,当隐式连接发生在同一行时,如果不格外留意,就难以预测代码的执行结果:
y = 2
my_test2 = r"fir\st" f"{y}" '"third"'
print(my_test2)
>>>
fir\st2"third"
像这样隐式的连接方式也很容易出错。如果你不小心在相邻的字符串之间插入了逗号字符,那么代码的含义将完全改变(请参阅 Item 6:"始终用括号包围单元素元组" 中的类似问题)
my_test3 = r"fir\st", f"{y}" '"third"'
print(my_test3)
>>>
('fir\\st', '2"third"')
如果你反其道而行之,不小心删除了逗号而非添加了逗号,那么另一个问题也可能随之出现。例如,假设我想要创建一个用于输出的字符串列表,每一行对应一个元素:
my_test4 = [
"first line\n",
"second line\n",
"third line\n",
]
print(my_test4)
>>>
['first line\n', 'second line\n', 'third line\n']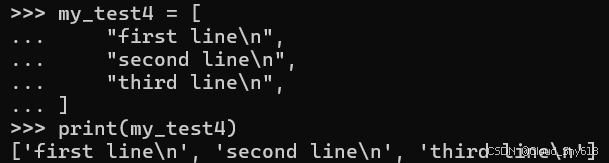
如果删除中间的那个逗号,所得数据将具有类似的结构,但最后两行将悄无声息地合并到一起。
my_test5 = [
"first line\n",
"second line\n" # Comma removed
"third line\n",
]
print(my_test5)
>>>
['first line\n', 'second line\nthird line\n']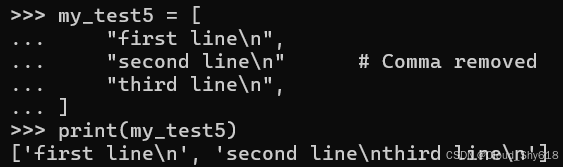
但即便你确实注意到了这种隐式的连接操作正在发生,目前尚不清楚这是有意为之还是偶然所致。因此,我的建议是始终使用显式的加号运算符来组合列表或元组中的字符串,以消除因隐式连接造成的任何歧义:
my_test6 = [
"first line\n",
"second line\n" + # Explicit
"third line\n",
]
assert my_test5 == my_test6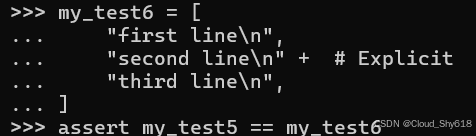
当存在加号运算符时,自动格式化工具或许仍会改变换行方式,但处于这种状态时,至少可以明确了解代码作者最初的意图:
my_test6 =[
"first line\n",
"second line\n" + "third line\n",
]另一种可能因隐式字符串连接而产生问题的场景出现在函数调用参数列表中。有时在调用过程中使用隐式拼接看似并无不妥,例如在调用 print 函数时:
print("this is my long message "
"that should be printed out")
>>>
this is my long message that should be printed out
当您在单个位置参数之后提供附加关键字参数时,隐式串联甚至可以被读取:
import sys
print("this is my long message "
"that should be printed out",
end="",
file=sys.stderr)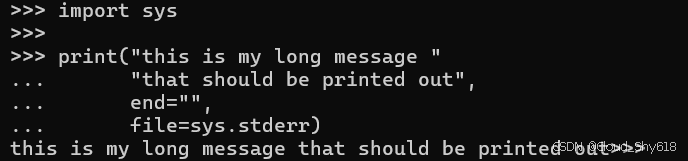
然而,当一项调用需要多个位置参数时,隐式字符串连接可能会造成混淆并增加出错的可能性,正如它对列表和元组字面量的影响一样。例如,这里创建了一个类的实例,并在初始化参数列表的中间使用了隐式连接------你能很快发现这一点吗?
import sys
first_value = ...
second_value = ...
class MyData:
...
value = MyData(123,
first_value,
f"my format string {x}"
f"another value {y}",
"and here is more text",
second_value,
stream=sys.stderr)将字符串连接操作改为显式处理可使这段代码更易阅读:
value2 = MyData(123,
first_value,
f"my format string {x}" + # Explicit
f"another value {y}",
"and here is more text",
second_value,
stream=sys.stderr)因此建议,当函数调用采用多个位置参数时,始终使用显式字符串连接,以避免任何混淆(有关类似示例,请参阅 Item 37:"通过仅关键字和仅位置参数增强清晰度")。如果只有一个位置参数(如上面的 print 示例),那么使用隐式字符串连接就可以了。可以使用显式或隐式连接来传递关键字参数(以最大限度提高清晰度为准),因为同级字符串常量不会被误解为 = 字符之后的位置参数。
注意:
- 在 Python 代码中,当两个字符串常量相邻排列时,它们会被合并,就好像中间存在加号运算符一样,这与 C 编程语言中隐式字符串连接的特性颇为相似。
- 避免对列表和元组常量中的元素进行隐式字符串连接,因为这会导致对原作者意图产生歧义。相反,应使用带有加号运算符的显式连接方式。
- 在函数调用中,使用隐式字符串连接结合一个位置参数以及任意数量的关键字参数是可行的,但如遇有多重位置参数的情况,则应采用显式连接方式。
Item 14:了解如何对序列进行切片
Python 提供了用于将序列切分成片段的语法。切分功能使您能够以最小的努力访问序列中的一部分元素。切分的最简单应用对象是内置类型列表、元组、字符串和字节。切分功能还可扩展至任何实现 __getitem__ 和 __setitem__ 特殊方法的 Python 类(参见 Item 57:"为自定义容器类型继承自 collections.abc 类")。
切片语法的基本形式是 someliststart:end,其中 start 包含在内,end 不包含:
a = ["a", "b", "c", "d", "e", "f", "g", "h"]
print("Middle two: ", a[3:5])
print("All but ends:", a[1:7])
>>>
Middle two: ['d', 'e']
All but ends: ['b', 'c', 'd', 'e', 'f', 'g']
当从序列的开头进行切片时,您应该省略零索引以减少视觉噪音:
assert a[:5] == a[0:5]当切片到序列末尾时,您应该省略最终索引,因为它是多余的:
assert a[5:] == a[5:len(a)]使用负数进行切片 有助于相对于序列末尾进行偏移。所有这些形式的切片对于代码的新读者来说都是清晰的:
a[:] # ["a", "b", "c", "d", "e", "f", "g", "h"]
a[:5] # ["a", "b", "c", "d", "e"]
a[:-1] # ["a", "b", "c", "d", "e", "f", "g"]
a[4:] # ["e", "f", "g", "h"]
a[-3:] # ["f", "g", "h"]
a[2:5] # ["c", "d", "e"]
a[2:-1] # ["c", "d", "e", "f", "g"]
a[-3:-1] # ["f", "g"]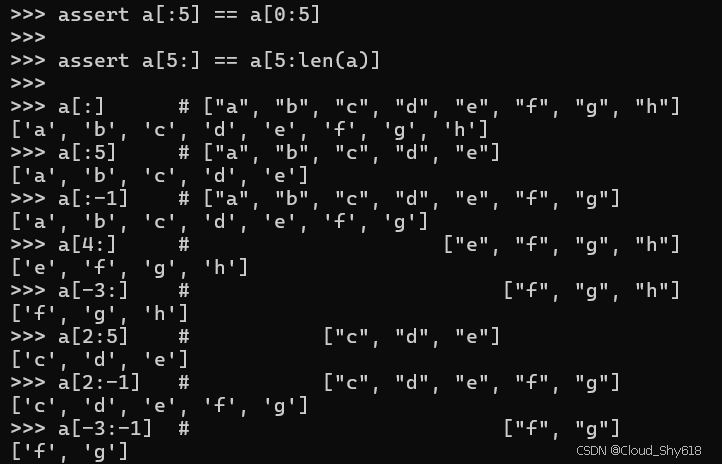
切片通过默默地忽略丢失的项目来正确处理超出列表边界的开始和结束索引。 此行为使您的代码可以轻松确定输入序列要考虑的最大长度:
first_twenty_items = a[:20]
last_twenty_items = a[-20:]相反,直接访问相同的缺失索引会导致异常:
a[20]
>>>
Traceback ...
IndexError: list index out of range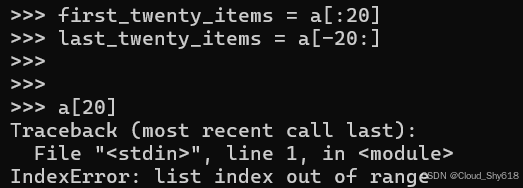
请注意,通过负数变量对列表进行索引是少数可以通过切片获得意外结果的情况之一。例如,当 n 大于零时,表达式 somelist-n: 将正常工作(例如,当 n 为3 时,somelist-3:)。但是,当 n 为零时,表达式 somelist-0: 等效于 somelist:,这会生成原始列表的副本。
切片列表的结果是一个全新的列表。新列表中的每个项目都将引用原始列表中的相应对象。修改切片创建的列表不会影响原始列表的内容:
b = a[3:]
print("Before: ", b)
b[1] = 99
print("After: ", b)
print("No change:", a)
>>>
Before: ['d', 'e', 'f', 'g', 'h']
After: ['d', 99, 'f', 'g', 'h']
No change: ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']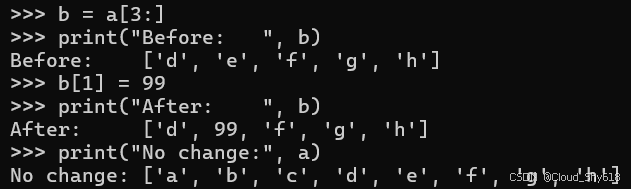
在赋值中使用时,切片会替换原始列表中的指定范围。与解包赋值不同(例如,a, b = c:2;请参阅 Item 5:"优先选择多重赋值解包而不是索引"和 Item 16:"优先选择 Catch-All 解包而不是切片"),切片赋值的长度不需要相同。赋值切片之前和之后的所有值都将被保留,新值将缝合在其间。这里,列表收缩,因为替换列表比指定的切片短:
print("Before ", a)
a[2:7] = [99, 22, 14]
print("After ", a)
>>>
Before ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
After ['a', 'b', 99, 22, 14, 'h']
这里列表会增长,因为赋值的列表比指定的切片长:
print("Before ", a)
a[2:3] = [47, 11]
print("After ", a)
>>>
Before ['a', 'b', 99, 22, 14, 'h']
After ['a', 'b', 47, 11, 22, 14, 'h']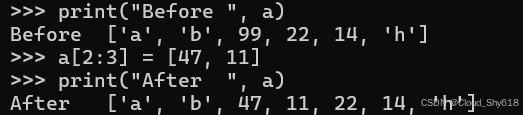
如果在切片时省略开始和结束索引,您最终会得到整个原始列表的副本:
b = a[:]
assert b == a and b is not a如果赋值给没有开始或结束索引的切片,则将列表的整个内容替换为对右侧序列中的项目的引用(而不是赋值新列表):
b = a
print("Before a", a)
print("Before b", b)
a[:] = [101, 102, 103]
assert a is b # Still the same list object
print("After a ", a) # Now has different contents
print("After b ", b) # Same list, so same contents as a
>>>
Before a ['a', 'b', 47, 11, 22, 14, 'h']
Before b ['a', 'b', 47, 11, 22, 14, 'h']
After a [101, 102, 103]
After b [101, 102, 103]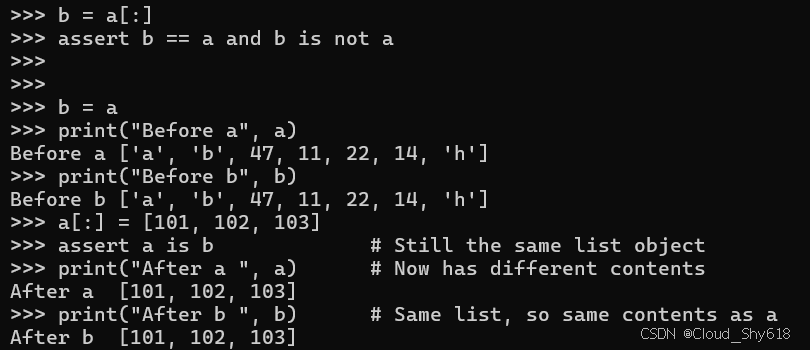
注意:
- 切片时避免冗长:不要为起始索引提供 0 或为结束索引提供序列长度。
- 切片允许超出范围的开始或结束索引,这意味着可以轻松地在序列的前边界或后边界上描述切片(例如,a:20 或 a-20:)。
- 即使长度不同,赋值给列表切片也会将原始序列中的范围替换为引用的范围。
Item 15:避免在单个表达式中跨步和切片
除了基本的切片(参见 Item 14:"了解如何对序列进行切片")之外,Python 还有特殊的切片 stride 语法,格式为 someliststart: end: stride。这使您可以在切片序列时获取每第 n 个项目。例如,stride 步幅可以轻松地按列表中的偶数和奇数序数位置进行分组:
x = ["red", "orange", "yellow", "green", "blue", "purple"]
odds = x[::2] # First, third, fifth
evens = x[1::2] # Second, fourth, sixth
print(odds)
print(evens)
>>>
['red', 'yellow', 'blue']
['orange', 'green', 'purple']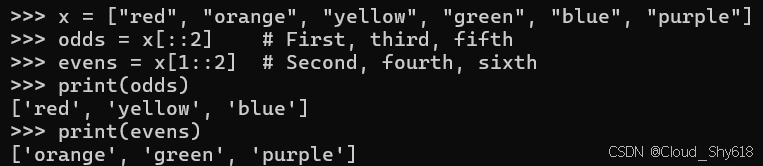
问题在于,stride 语法经常会导致意外行为,从而引入错误。例如,用于反转字节字符串的常见 Python 技巧是以 -1 的步长对字符串进行切片:
x = b"mongoose"
y = x[::-1]
print(y)
>>>
b'esoognom'这也适用于 Unicode 字符串(请参阅 Item 10:"了解 bytes 和 str 之间的区别"):
x = "寿司"
y = x[::-1]
print(y)
>>>
司寿
但当 Unicode 数据被编码为 UTF-8 字节字符串时,它就会崩溃:
w = "寿司"
x = w.encode("utf-8")
y = x[::-1]
z = y.decode("utf-8")
>>>
Traceback ...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb8 in position 0: invalid start byte
除了 -1 之外的负步长还有用吗?考虑以下示例:
x = ["a", "b", "c", "d", "e", "f", "g", "h"]
x[::2] # ["a", "c", "e", "g"]
x[::-2] # ["h", "f", "d", "b"]这里,::2 的意思是 "从头开始选择每隔一个的项目。" 更棘手的是, ::-2 意味着 "选择从末尾开始向后移动的每隔一个项目。"
下面来看看 2::2,-2::-2,-2:2:-2,2:2:-2 都意味着什么?
x[2::2] # ["c", "e", "g"]
x[-2::-2] # ["g", "e", "c", "a"]
x[-2:2:-2] # ["g", "e"]
x[2:2:-2] # []
>>>
['c', 'e', 'g']
['g', 'e', 'c', 'a']
['g', 'e']
[]
关键是切片语法的步幅部分可能非常令人困惑。由于其密度,括号内包含三个数字很难阅读。那么,start 和 end 索引相对于 stride 值何时生效并不明显,尤其是当 stride 为负值时。
为了防止出现问题,建议您避免将步幅与开始和结束索引一起使用。如果必须使用步幅,最好将其设置为正值并省略开始和结束索引。如果必须使用带有开始或结束索引的步幅,请考虑使用一个赋值用于跨步,另一个赋值用于切片
y = x[::2] # ["a", "c", "e", "g"]
z = y[1:-1] # ["c", "e"]跨步然后切片会创建数据的额外浅拷贝。第一个操作应尝试尽可能减小结果切片的大小。如果您的程序无法承担两个步骤所需的时间或内存,请考虑使用 itertools 内置模块的 islice 方法(请参阅 Item 24:"考虑使用 itertools 来使用迭代器和生成器"),该方法读起来更清晰,并且不允许开始、结束或步长为负值。
注意:
- 在单个切片中一起指定开始、结束和步幅可能会非常令人困惑。
- 如果需要跨步,请尝试仅使用不带开始或结束索引的正跨步值;避免负步幅值。
- 如果您需要在单个切片中开始、结束和跨步,请考虑执行两次赋值(一个用于跨步,另一个用于切片)或使用 itertools 内置模块中的 islice。
Item 16:使用 Catch-All 解包更好而不是切片
基本解包的一个限制(参见 Item 5:"优先使用多重赋值解包而不是索引")是您必须提前知道要解包的序列的长度。例如,这里有一个在汽车经销商处交易的汽车使用年数的列表。当我尝试通过基本解包获取列表的前两项时,在运行时会引发异常:
car_ages = [0, 9, 4, 8, 7, 20, 19, 1, 6, 15]
car_ages_descending = sorted(car_ages, reverse=True)
oldest, second_oldest = car_ages_descending
>>>
Traceback ...
ValueError: too many values to unpack (expected 2)
Python 新手经常依赖索引和切片(参见 Item 14:"了解如何对序列进行切片")来处理这种情况。例如,这里我从至少两项的列表中提取最旧的、次旧的和其他使用年数:
oldest = car_ages_descending[0]
second_oldest = car_ages_descending[1]
others = car_ages_descending[2:]
print(oldest, second_oldest, others)
>>>
20 19 [15, 9, 8, 7, 6, 4, 1, 0]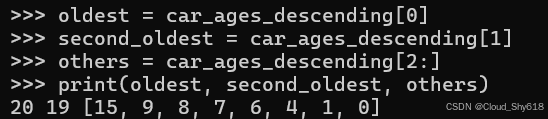
这是可行的,但所有索引和切片在视觉上都很嘈杂。在实际中,以这种方式将序列的成员划分为不同的子集也很容易出错,因为你更有可能出现相差一的错误;例如,您可能更改某一行的边界而忘记更新其他行。
为了更好地处理这种情况,Python 还支持通过星号表达式进行包罗万象的解包。此语法允许解包赋值的一部分接收与解包模式的任何其他部分不匹配的所有值。在这里,我使用带星号的表达式来实现与上面相同的结果,而无需任何索引或切片:
oldest, second_oldest, *others = car_ages_descending
print(oldest, second_oldest, others)
>>>
20 19 [15, 9, 8, 7, 6, 4, 1, 0]
此代码更短,更易于阅读,并且不再具有必须在行之间保持同步的边界索引的容易出错的脆弱性。
带星号的表达式可以出现在任何位置(开始、中间或结束),因此当您需要提取一个可选切片时,您可以随时获得 Catch-All 解包的好处(请参阅 Item 9:"在流程控制中考虑解构的匹配,避免使用 When if 语句足够了",了解另一种有用的情况):
oldest, *others, youngest = car_ages_descending
print(oldest, youngest, others)
*others, second_youngest, youngest = car_ages_descending
print(youngest, second_youngest, others)
>>>
20 0 [19, 15, 9, 8, 7, 6, 4, 1]
0 1 [20, 19, 15, 9, 8, 7, 6, 4]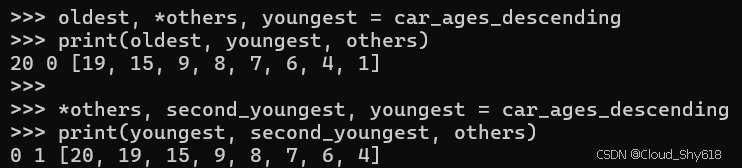
然而,当您在解包赋值中使用带星号的表达式时,您必须至少有一个必需的部分,否则您将收到语法错误。您不能单独使用 Ctach-All 表达式:
*others = car_ages_descending
>>>
Traceback ...
SyntaxError: starred assignment target must be in a list or tuple
您也不能在单个解包模式中使用多个 catch-all 表达式:
first, *middle, *second_middle, last = [1, 2, 3, 4]
>>>
Traceback ...
SyntaxError: multiple starred expressions in assignment
但是,可以在解包赋值语句中使用多个带星号的表达式,只要它们涵盖了要解包的嵌套结构的不同级别。不建议执行以下操作(请参阅 Item 31:"返回专用结果对象而不是要求函数调用者解包三个以上变量" 以获取相关指导),但理解它应该有助于您对如何在解包赋值中使用带星号的表达式培养一种直觉:
car_inventory = {
"Downtown": ("Silver Shadow", "Pinto", "DMC"),
"Airport": ("Skyline", "Viper", "Gremlin", "Nova"),
}
((loc1, (best1, *rest1)),
(loc2, (best2, *rest2))) = car_inventory.items()
print(f"Best at {loc1} is {best1}, {len(rest1)} others")
print(f"Best at {loc2} is {best2}, {len(rest2)} others")
>>>
Best at Downtown is Silver Shadow, 2 others
Best at Airport is Skyline, 3 others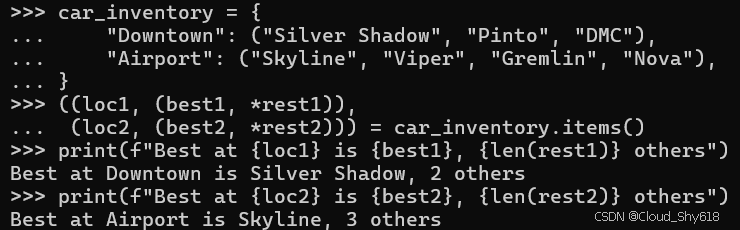
在所有情况下,加星号的表达式都会成为列表实例。如果解包序列中没有剩余项目 ,则 catch-all 部分将是一个空列表。当您处理预先知道至少有 N 个元素的序列时,这尤其有用:
short_list = [1, 2]
first, second, *rest = short_list
print(first, second, rest)
>>>
1 2 []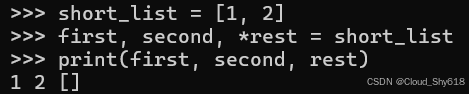
您还可以使用解包语法解包任意迭代器。对于基本的多重赋值语句来说,这没有多大价值。例如,这里通过在长度为 2 的范围内迭代来解压缩值。这似乎没有用,因为只赋值给与解包模式匹配的静态列表(例如,1, 2)会更容易:
it = iter(range(1, 3))
first, second = it
print(f"{first} and {second}")
>>>
1 and 2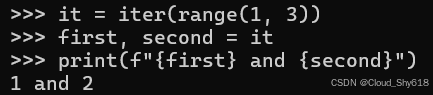
但随着星号表达式的添加,解包迭代器的价值变得清晰起来。 例如,这里有一个生成器,它生成 CSV(逗号分隔值)文件的行,其中包含本周来自经销商的所有汽车订单:
def generate_csv():
yield("Date", "Make", "Model", "Year", "Price")
...使用索引和切片处理该生成器的结果很好,但它需要多行并且视觉上有噪音:
all_csv_rows = list(generate_csv())
header = all_csv_rows[0]
rows = all_csv_rows[1:]
print("CSV Header:", header)
print("Row count: ", len(rows))
>>>
CSV Header: ('Date', 'Make', 'Model', 'Year', 'Price')
Row count: 200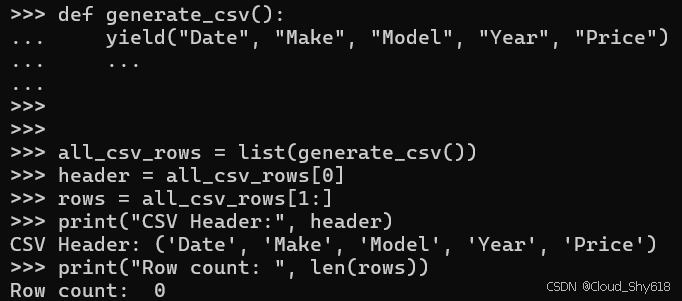
提示:这里输出的结果为 0,是由于在 def generate_csv() 中进行了省略。
使用星号的表达式解包可以轻松处理第一行(标题),与迭代器的其余内容分开。使其更清楚了:
it = generate_csv()
header, *rows = it
print("CSV Header:", header)
print("Row count: ", len(rows))
>>>
CSV Header: ('Date', 'Make', 'Model', 'Year', 'Price')
Row count: 200
但请记住,由于星号表达式始终会转换为列表,因此解包迭代器还会冒耗尽计算机上所有内存并导致程序崩溃的风险(请参阅 Item 115:"使用 tracemalloc 了解内存使用情况和泄漏"了解如何调试此问题)。因此,只有当您有充分的理由相信结果数据将全部适合内存时,才应该对迭代器使用 catch-all 解包(有关另一种方法,请参阅 Item 21:"迭代参数时保持防御性")。
注意:
- 解包分配可能包括一个星号表达式,用于存储未分配给列表中解包模式其他部分的所有值。
- 星号表达式可以出现在解包模式的任何位置。它们将始终成为包含零个或多个值的列表实例。
- 将列表划分为不重叠的部分时,与使用进行切片和索引的单独语句相比,catch-all 解包更不容易出错。