本文整理自B站「AI专业知识科普:啥是LLM(大语言模型)」,通过AI音视频总结工具 Ai好记 转文字+截取PPT整理,以下为精炼整理后的内容。
LLM(Large Language Model,大语言模型)是这两年 AI 领域最火的关键词。ChatGPT、DeepSeek、Kimi、豆包,背后都是 LLM 在撑场子。
但 LLM 到底是怎么工作的,很多人其实是模糊的。这篇从最底层的原理开始聊,不搞玄学公式,争取用大白话讲清楚。
LLM 的本质:不是思考,是接龙
先说最核心的一件事:大语言模型并不真正"理解"你说的话,它只是在做一件事------根据你前面说的内容,猜下一个字最可能是什么。
像玩词语接龙。你开头说"今天天气真",它根据学过的数万亿字语料,算出"好"的概率是87%,"不"是8%,"热"是3%。
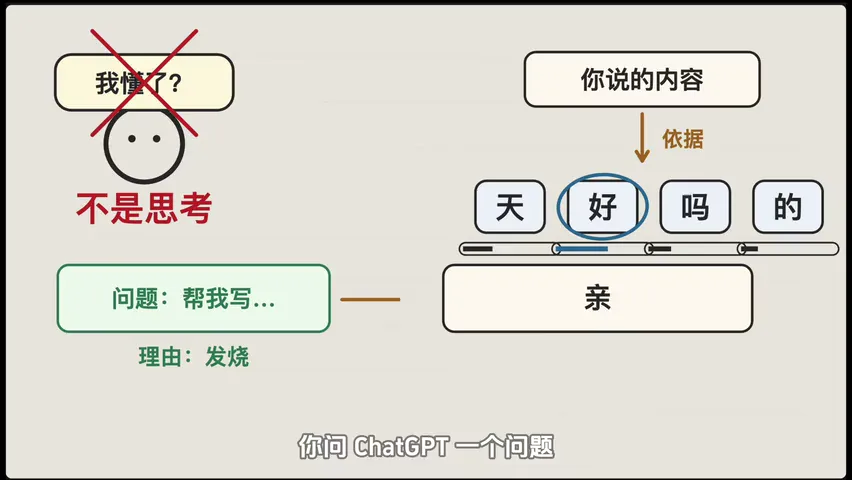
选了"好",然后继续猜下一个字。ChatGPT 输出的每一段回答,都是一个字一个字这么接龙接出来的。
这个认知很重要------LLM 没有懂,只有猜。 但当接龙做得足够准的时候,就足够模拟出 AI 真的很懂的样子了。
训练三阶段:从读到精再到对齐
一个 LLM 从"什么都不会"到"能用",要经过三个阶段。
预训练------全世界互联网上能找到的所有文字,网页、书籍、维基百科、新闻、论坛,几十万亿的字,全拿过来。
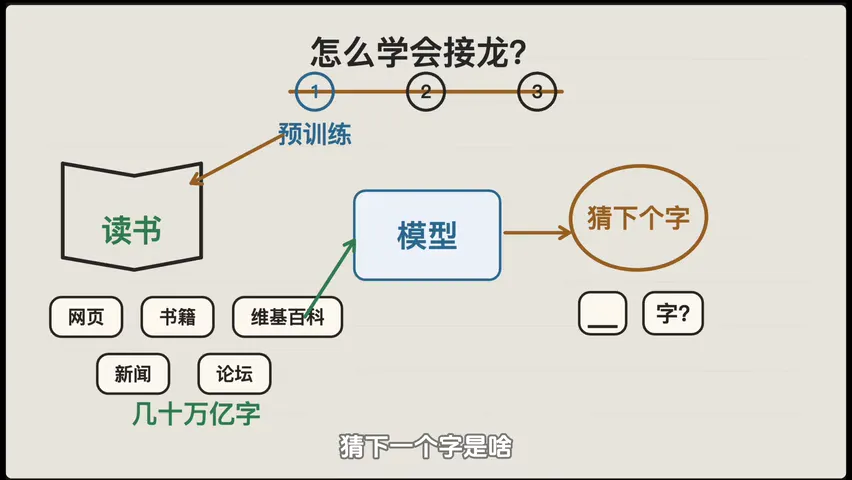
让模型一遍又一遍地玩"猜下一个字"的游戏。猜错了就内部调整参数,猜对了就保留。这个阶段成本极高,GPT-3 光是一次训练就要花上亿美元。
后训练精修------预训练完的模型虽然能接龙,但回答太生硬,像在抄书。这时候拿高质量对话数据(人工写的问题+标准答案)来精调,让模型学会怎么像一个正常人那样回答问题。
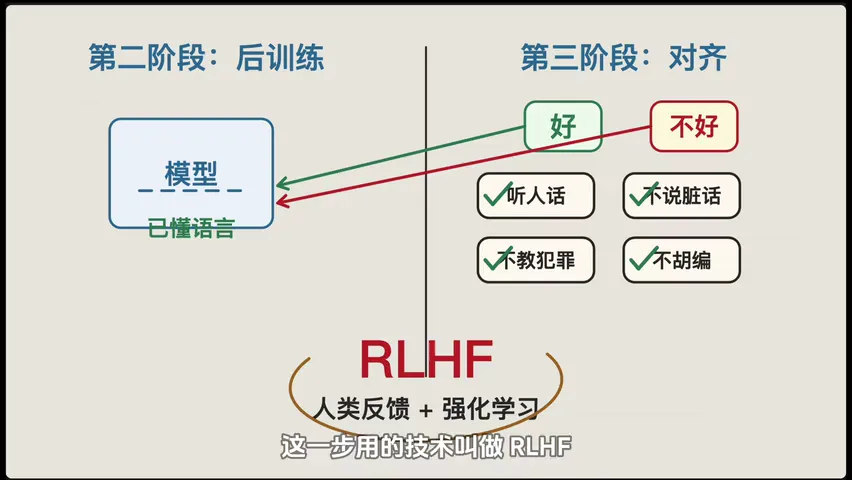
对齐------最后一步,用人类反馈来校准。给模型生成的多个回答排好坏,让它学会什么该说、什么不该说、怎么更有帮助。
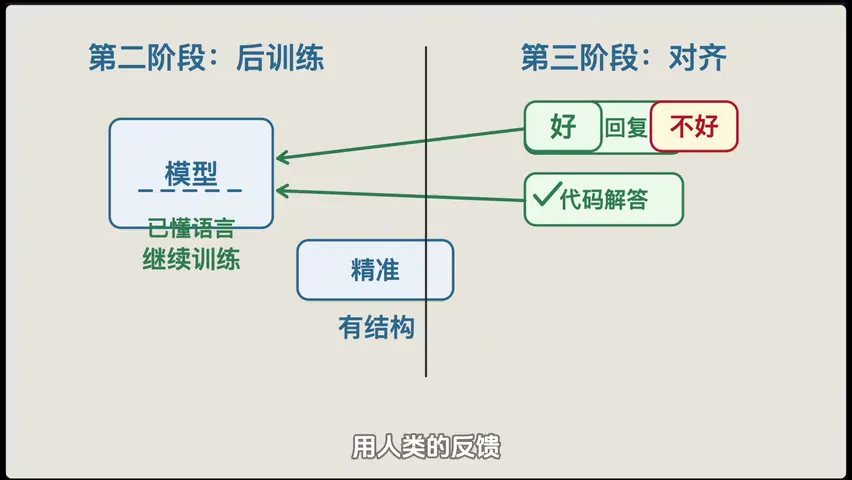
这就是 RLHF(基于人类反馈的强化学习),也是 ChatGPT 当年脱颖而出的关键一步。
核心概念划重点
理解 LLM 需要了解几个关键概念。
参数:相当于模型内部的"小开关"数量。7B(70亿参数)的模型和 671B(6710亿参数,DeepSeek V3)的模型,能力差距就像小学生和博士生的区别。
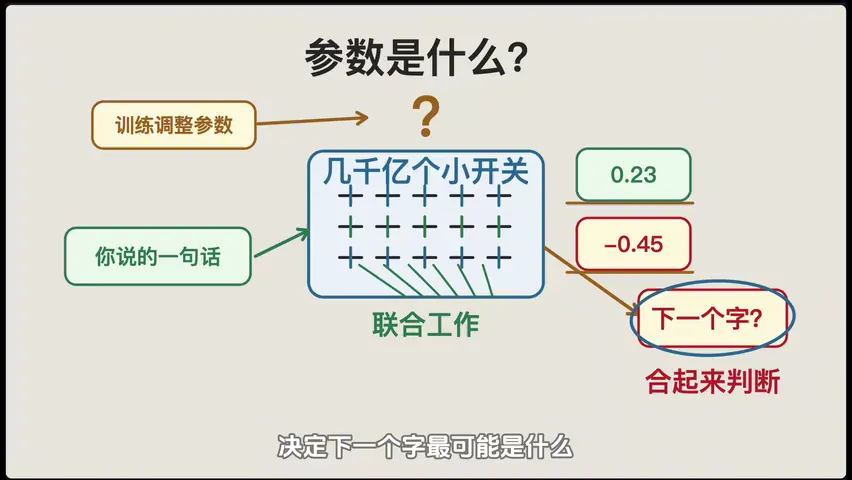
参数越多,模型能记住的语言模式越丰富,但计算成本和部署难度也成倍增加。

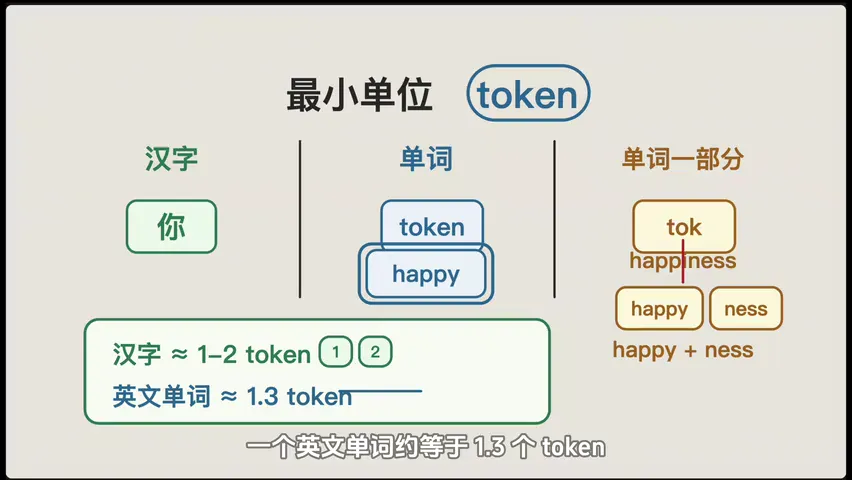
Token:模型内部处理的不是"字",而是 token。一个 token 差不多相当于 0.75 个汉字。你提问的时候,模型不是看你一句话,而是看一堆 token 串在一起。
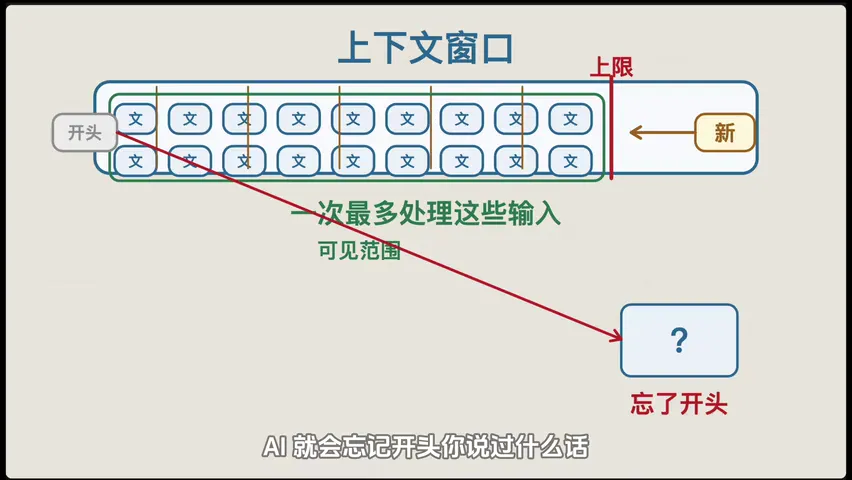
上下文窗口:模型一次能"记住"多少 token。GPT-4 是 12.8 万 token,Claude 2.5 达到了 100 万 token。窗口越大,它能处理的长文档就越长。
超出上下文窗口的内容,模型就会"忘记"------这不是 bug,是工作机制决定的。
温度参数:控制模型回答的"随机性"。温度设为 0,模型每次都选概率最高的那个词,回答稳定但不灵活。温度调高,模型会选概率较低但也可能的词,更有创造力但也更容易跑偏。
LLM 的实际工作过程
拿一个日常场景举例。你在 AI 里输入"帮我写一封请假邮件,因为感冒"。
模型先把这句话拆成 token 序列,然后从自己的参数里算出接下去最可能的词。首先输出"亲"------"亲爱的"的概率更高,于是输出"爱"再接"的"。一个接一个,直到"请领导批准"------到这里模型判断已经能组成一封完整的请假邮件了。
这就是 流式输出------你看到 AI 打字的时候,其实它正在实时做逐词预测。所以你会发现有时候它写到一半会"反悔"------删掉前面写的话重新输出,因为在接龙过程中发现了更合理的走向。
AI 家族的层级关系
很多概念容易混,理一下就清楚了。
人工智能(AI) 是最大的概念,图像识别、语音合成、自动驾驶等都算 AI。
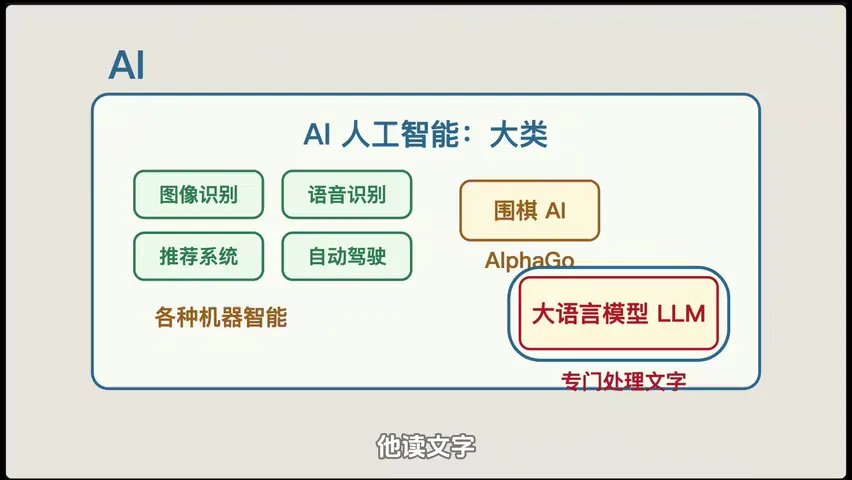
大语言模型(LLM) 是 AI 中专门处理文本的子集。
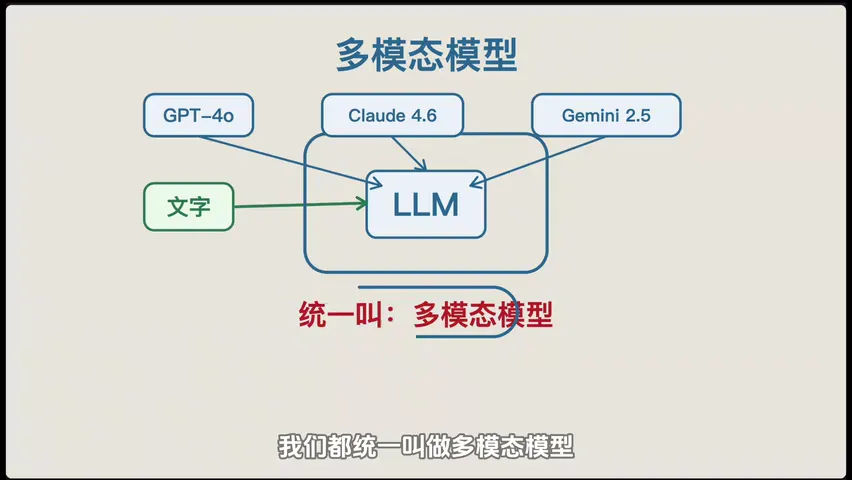
多模态模型 是 LLM 的进化版------不仅能看文字,还能看图、听声音、处理视频。像 GPT-4o 就是典型。
推理模型 是更进一步------LLM 只是逐词预测,推理模型会在内部做多步思考和验证,像 OpenAI 的 o1。

日常说的"DeepSeek V3""GPT-4""Kimi"都是 LLM,"DeepSeek R1""o1"就是推理模型的代表。
参数规模与蒸馏
不同参数规模的模型适用于不同场景。
7B 模型可以在手机上跑,但回答质量有限。70B 模型需要显卡才能跑,回答质量明显提升。671B 模型是顶级水平,但需要多张高性能显卡集群才能部署。
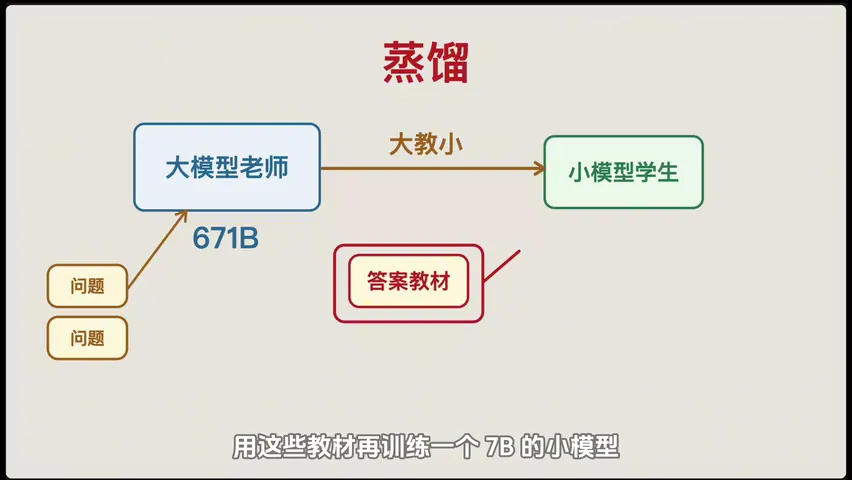
蒸馏 技术解决了这个问题------用大模型(如 671B)的答案作为教材,去训练小模型(如 7B),让小模型以远低于大模型的成本,获得接近大模型的输出能力。这就是很多端侧 AI(手机本地模型)能做好的根本原因。
模型选择建议
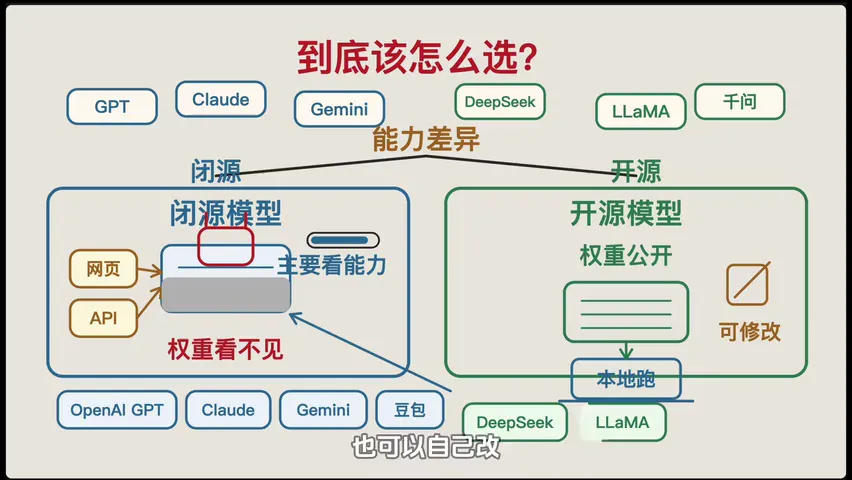
日常聊天用免费网页版就好------豆包、Kimi、DeepSeek Web 都够用,完全免费。
复杂任务推荐用 API 调用------写代码、分析长文档、处理结构化数据,用 DeepSeek API(性价比高)或 Claude API(长上下文强)。
数据敏感场景选开源模型本地部署------不把数据传输到外网,Qwen、DeepSeek 开源版都可以自己部署。
总结
LLM 没有我们想象中那么神秘。它的本质就是一个被海量数据训练过的词语接龙高手,一个字一个字地预测输出。当这种接龙做得足够准的时候,就模拟出了"懂"的样子。
理解了这个底层逻辑,选模型、调参数、判断回答质量,都会更有谱。
常见问题
Q:LLM 和 ChatGPT 是什么关系?
A:ChatGPT 是基于 GPT 系列 LLM 开发的应用产品。LLM 是底层的"发动机",ChatGPT 是上面的"车身"。
Q:为什么 AI 有时候会胡说八道?
A:这叫"幻觉"。因为 LLM 的本质是在做概率预测,当它遇到训练数据中没有明确答案的问题,就会根据概率编造一个看起来像样的回答。
Q:参数越大的模型是不是一定更好?
A:通常来说参数越大能力越强,但部署成本也成倍增加。对于日常简单任务,蒸馏后的小模型反而性价比更高,速度和成本都友好。
Q:同样的问题问不同模型,回答不一样是为什么?
A:有两个原因。一是模型训练数据不同,知识库有差异。二是温度参数设置不同,高温度时回答会有一定随机性。
Q:开源 LLM 和闭源 LLM 怎么选?
A:闭源模型(GPT-4、Claude)能力更强,但成本高、受限于供应商服务。开源模型(DeepSeek、Qwen)可以本地部署,数据安全可控,适合对隐私要求高的场景。
以上内容由 Ai好记 转录整理。
支持解析B站、抖音、小宇宙等平台链接及本地/网盘的音视频文件,转写后自动生成精华速览、思维导图和结构化笔记,帮助你把几小时的视频内容变成可搜索、可复习的图文笔记。