数据和代码获取:请查看主页个人信息!!!
大家好!欢迎来到R语言数据分析视界。今天我来介绍微生物组执行随机森林分类分析的R语言操作方法。微生物组的随机森林分析可以用于研究微生物组的组成和功能与其他因素(如分组情况、疾病状态、环境因素等)之间的关联关系。

microeco包可以轻松实现随机森林分类分析,接下来我们来进行分析和可视化展示,首先载入本次绘图数据:
Step1:数据载入
rm(list=ls())pacman::p_load(tidyverse,microeco,magrittr,data.table,aplot)# 载入数据feature_table <- fread('feature_table.csv') %>% column_to_rownames('ID')sample_table <- fread('sample_table.csv') %>% column_to_rownames('ID')tax_table <- fread('tax_table.csv') %>% column_to_rownames('ID')Step2:创建microeco对象
# 创建microtable对象dataset <- microtable$new(sample_table = sample_table, otu_table = feature_table, tax_table = tax_table)dataset
Step3:执行随机森林分类分析
rf <- trans_diff$new(dataset = dataset, method = "rf", group = "Group", taxa_level = "Genus")rf
这里我们制定分类的变量为"Group",分类水平为"Genus"水平。
Step4:重要分类微生物可视化
# plot the MeanDecreaseGini bar# group_order is designed to sort the groupsg1 <- rf$plot_diff_bar(use_number = 1:20, group_order = c("TW", "CW", "IW"))
# plot the abundance using same taxa in g1g2 <- rf$plot_diff_abund(group_order = c("TW", "CW", "IW"), select_taxa = rf$plot_diff_bar_taxa)
g1 %>% insert_right(g2)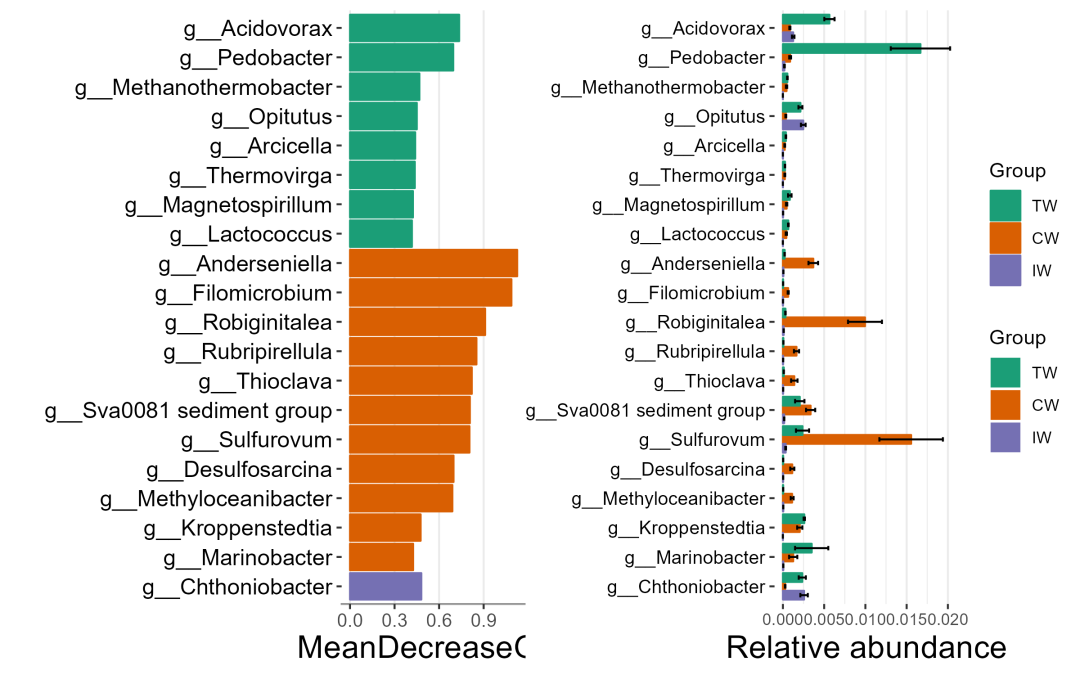
在随机森林中,MeanDecreaseGini表示每个特征对于模型的准确性的贡献程度。通过绘制柱状图,可以直观地展示每个特征的重要性排序,从而帮助识别哪些特征对于预测结果最为关键。同时绘制丰度图可以展示不同分类单位在微生物组中的相对丰度,从而帮助了解微生物组的组成特征。
Step5:差异分析
t1 <- trans_diff$new(dataset = dataset, method = "anova", group = "Group", taxa_level = "Genus", filter_thres = 0.001)t1$plot_diff_abund(use_number = 1:10, add_sig = T, coord_flip = F)ggsave('pic1.png', width = 7, height = 5)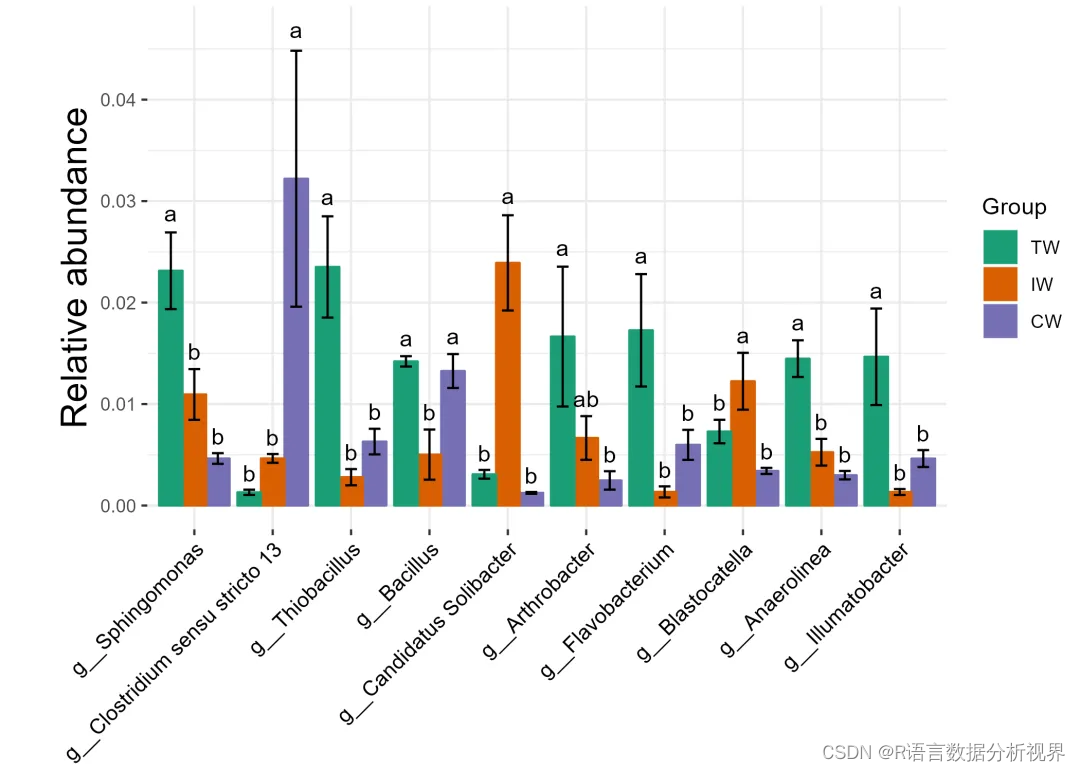
关键词"随机森林" 获得本期代码和数据。