小罗碎碎念
2024-06-13|文献精析:机器学习在医学领域中的应用
为了系统性地和大家梳理一下机器学习在医学领域中的应用,我特意去找了一篇文献,把其中有价值的信息筛选出来了。但是我没选的内容不代表不重要,感兴趣的可以找到原文自己再去补充哈。

重点关注

一、引言
机器学习(Machine Learning,ML)是一种广泛应用于多个领域(例如医疗领域)的工具、方法和技术的集合。
在医疗领域,ML能够帮助解决不同专业领域的诊断问题,如医学成像、癌症诊断和可穿戴传感器等1。通过分析重要的临床参数,例如提取医学信息和预测疾病及发展阶段,ML有助于规划和支持患者的健康状况。此外,ML还能通过数据分析和在必要时发送智能警告,确保医疗监测的效率2。
在专业医院中,患者的诊断数据被视作病历3。为了执行学习算法,需要对患者信息进行准确的编码。尽管编码是一个简单的步骤,但为了确保ML的顺利启动,需要自动分析信息并将其与之前解决的类似问题相匹配。这样可以帮助医生对新病例进行准确、简便和快速的诊断。非专业人员和学生在诊断患者时也可以使用ML。
本综述旨在提供ML方法、技术和工具的概览。文章收集了支持ML在医疗领域应用的方法和理论。后续部分将讨论通过ML技术进行医学诊断、ML在医疗应用中的角色以及如何在医疗背景下利用ML方法。
本文的结构安排如图1所示。
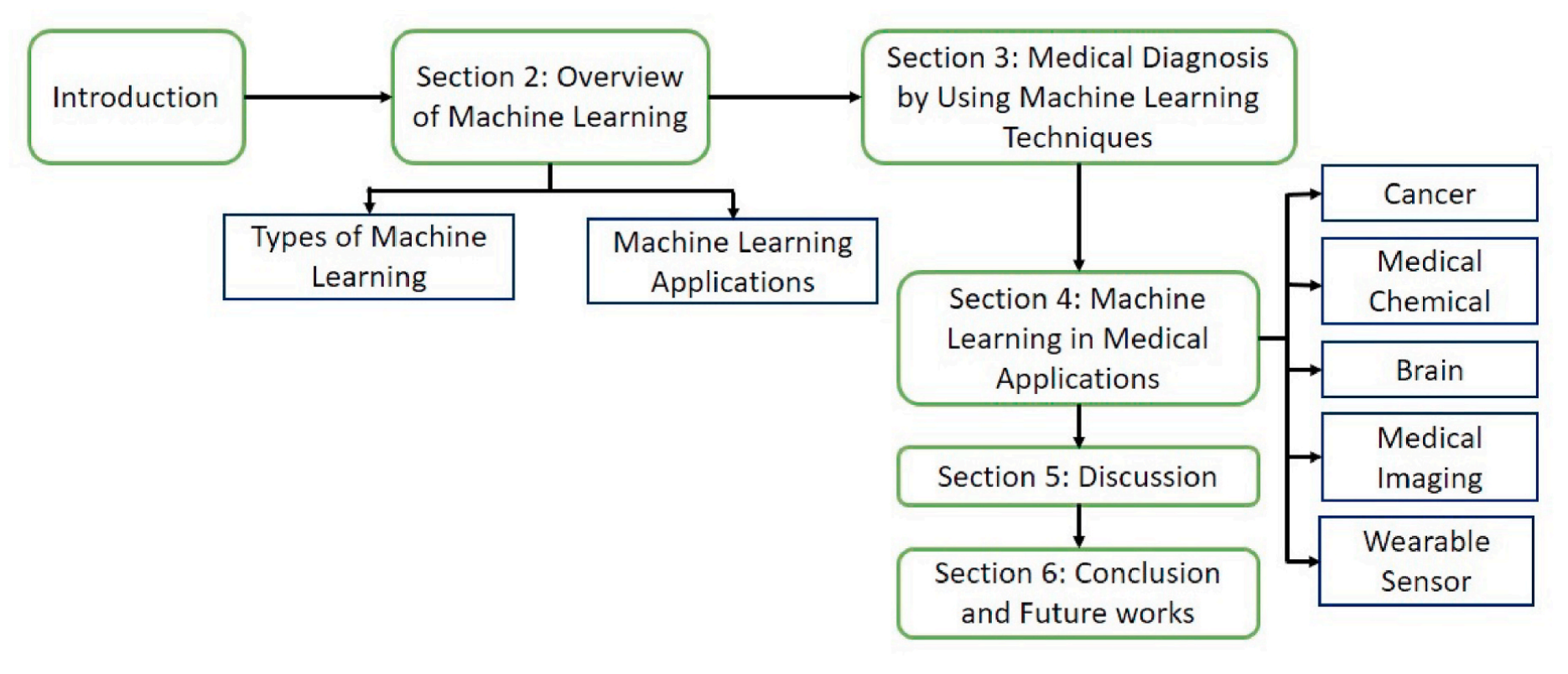
二、机器学习概述
本节介绍机器学习(ML)的类型、方法和技术的背景,并随后讨论ML在医疗领域的应用。
2-1:机器学习类型
Table 1 提供了机器学习(Machine Learning, ML)中不同类型、方法、技术以及它们的描述和应用的概览。
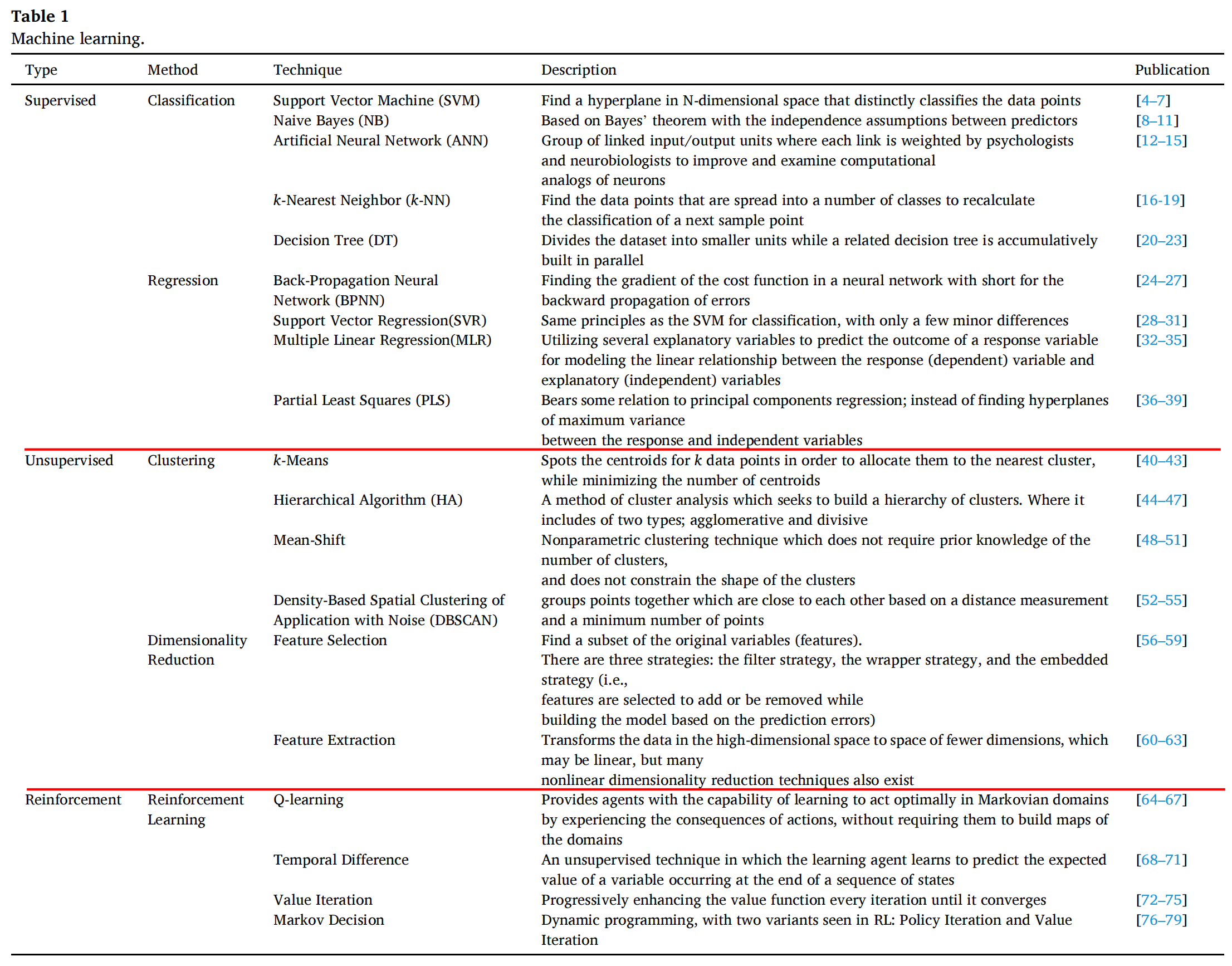
以下是对表中内容的分析:
- 类型(Type) :表中将机器学习分为
监督学习(Supervised)、无监督学习(Unsupervised)和强化学习(Reinforcement Learning)三大类。 - 方法(Method) :每种类型下面列出了具体的方法,例如:
监督学习中的方法包括支持向量机(Support Vector Machine, SVM)、朴素贝叶斯(Naive Bayes, NB)、人工神经网络(Artificial Neural Network, ANN)等。无监督学习中的方法包括k-均值聚类(k-Means)、层次聚类算法(Hierarchical Algorithm, HA)、均值漂移(Mean-Shift)等。强化学习中的方法包括Q学习(Q-learning)、时间差分(Temporal Difference)等。
- 技术(Technique) :每种方法下进一步细分了具体的技术,例如:
- 在SVM方法下,技术可能包括不同的核函数选择。
- 在ANN方法下,技术可能包括不同类型的神经网络架构,如前馈神经网络、卷积神经网络等。
- 描述(Description) :表中对每种方法和技术提供了简要的描述,说明了它们的工作原理和主要用途。例如:
- SVM旨在N维空间中找到一个超平面,以区分数据点。
- NB基于贝叶斯定理,假设预测变量之间相互独立。
- ANN通过连接输入/输出单元,并通过权重调整来模拟神经元的计算过程。
2-2:机器学习类型、方法和技巧之间的详细关系
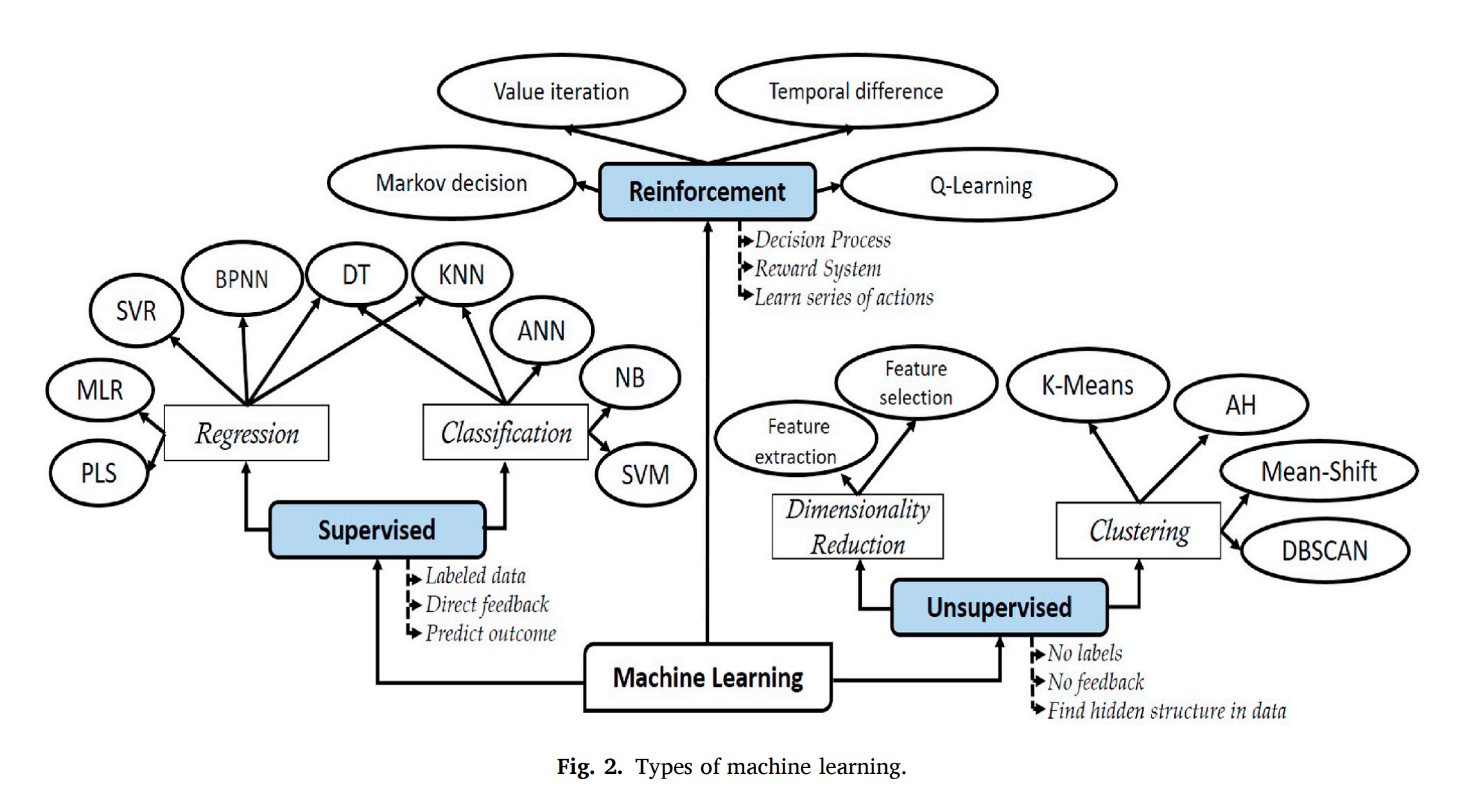
监督学习(Supervised Learning)------分类(Classification)
分类(Classification)是机器学习算法的主要任务之一,其目的是预测数据集中每个实例的类别标签。
以下是对提到的几种监督学习分类方法的解释:
- 支持向量机(Support Vector Machine, SVM) :
- SVM是一种强大的分类算法,它通过在N维空间中找到一个超平面来区分不同的类别。
- 这个超平面尽可能地远离每个类别的数据点,以最大化边界,从而提高分类的准确性和泛化能力。
- 朴素贝叶斯(Naive Bayes, NB) :
- NB是一种基于贝叶斯定理的分类算法,它假设特征之间相互独立。
- 即使在实际应用中特征可能并不完全独立,NB仍然因其简单性和效率而在许多情况下表现良好。
- 人工神经网络(Artificial Neural Network, ANN) :
- ANN是由输入/输出单元组成的网络,每个单元之间通过权重连接。
- ANN能够学习和模拟复杂的非线性关系,适用于许多分类任务。
- k-最近邻(k-Nearest Neighbor, k-NN) :
- k-NN是一种基于实例的学习方法,它根据测试数据点与训练集中数据点的距离来预测标签。
- 它选择最近的k个邻居(即k个最近的数据点),并根据这些邻居的已知类别来确定测试点的类别。
- 决策树(Decision Tree, DT) :
- DT是一种模型决策过程的树形结构,它通过一系列的问题将数据集划分成更小的单元。
- 这些问题基于特征的值,并且每个问题都对应于树中的一个节点。
- 决策树的构建是递增的,意味着随着每个问题的回答,树会逐渐生长,直到达到叶节点,代表最终的决策或分类。
这些方法各有优势和局限性,选择哪一种取决于具体问题的特性和数据集的特点。监督学习算法通过从标记的训练数据中学习,能够对新的、未见过的数据进行准确的分类预测。
监督学习(Supervised Learning)------回归(Regression)
回归(Regression)任务的目标是预测一个连续的数值变量,而不是像分类任务那样预测离散的类别标签。
以下是对提到的几种监督学习回归方法的解释:
-
反向传播神经网络(Back-Propagation Neural Network, BPNN):
- BPNN是一种多层前馈人工神经网络,它使用反向传播算法来调整网络中的权重。
- 它通过计算损失函数(cost function)的梯度来找到最小化误差的权重,这个过程称为反向传播(backpropagation of errors)。
- 通过这种方式,BPNN可以学习输入数据和连续输出值之间的复杂非线性关系。
-
支持向量回归(Support Vector Regression, SVR):
- SVR基于支持向量机(SVM)的原理,但用于回归任务而不是分类。
- 它通过找到数据中的支持向量来构建一个回归超平面,这些支持向量决定了回归函数的形态。
- SVR在本质上与SVM相同,但在目标函数和损失函数的定义上有一些细微的差别。
-
多元线性回归(Multiple Linear Regression, MLR):
- MLR是一种统计方法,它使用多个解释变量(explanatory variables)来预测一个响应变量(response variable)的值。
- 它假设响应变量和解释变量之间存在线性关系,并通过最小化预测误差来估计这些变量的系数。
-
偏最小二乘回归(Partial Least Squares, PLS):
- PLS是一种多变量数据分析技术,它与主成分回归(principal components regression)有关。
- 与寻找最大方差超平面不同,PLS旨在找到数据中能够解释响应变量和解释变量之间最大相关性的新变量空间。
- 这些新变量称为PLS分量,它们通过最大化响应变量和解释变量之间的相关性来构建。
这些回归方法在处理不同类型的数据集和预测任务时各有优势。BPNN适用于捕捉复杂的非线性关系,而SVR在小样本情况下表现良好。MLR是一种简单直观的方法,适用于线性关系,而PLS在变量之间存在多重共线性时特别有用。选择合适的回归方法通常取决于数据的特性、问题的复杂性以及预测精度的需求。
无监督学习(Unsupervised Learning)------聚类(Clustering)
在无监督学习(Unsupervised Learning)中,聚类(Clustering)是一种将数据集中的样本分组的技术,目的是使得同一组内的样本相似度高,而不同组之间的样本相似度低。
以下是对提到的几种无监督学习聚类方法的解释:
-
k-均值聚类(k-Means Clustering):
- k-均值聚类是一种流行的聚类算法,它将数据点划分为k个簇。
- 算法的目标是找到k个中心点(质心),每个中心点代表一个簇,并且使得每个数据点与其最近的中心点之间的距离之和最小。
- 这个过程涉及到迭代地重新分配数据点到最近的簇,以及重新计算每个簇的中心点,直到满足停止条件。
-
层次聚类算法(Hierarchical Algorithm, HA):
- 层次聚类是一种创建数据点层次结构的聚类方法,它可以形成树状的簇结构,称为树状图(dendrogram)。
- 层次聚类分为两种类型:聚合的(agglomerative)和分裂的(divisive)。
- 聚合的层次聚类从每个数据点作为单独的簇开始,逐步合并最接近的簇对;分裂的层次聚类从所有数据点作为一个大簇开始,逐步分裂成更小的簇。
-
均值漂移(Mean-Shift):
- 均值漂移是一种非参数聚类技术,它不需要事先知道簇的数量。
- 算法通过寻找密度函数的局部极大值点来确定簇的中心,这些中心点代表了簇的质心。
- 均值漂移不对簇的形状施加任何限制,可以发现任意形状的簇。
-
基于密度的聚类算法与噪声(Density-Based Spatial Clustering of Application with Noise, DBSCAN):
- DBSCAN是一种基于密度的聚类算法,它可以发现任意形状的簇,并且能够很好地处理噪声数据。
- 算法通过基于距离度量和最小点数的准则来将紧密相连的点分组在一起。
- 如果一个点的邻域内有足够的点(由参数指定),则该点被认为是"核心点",可以开始形成一个新的簇。
这些聚类方法各有特点,适用于不同的数据集和应用场景。
- k-均值聚类简单高效,但需要事先指定簇的数量;
- 层次聚类可以提供数据点之间关系的直观表示;
- 均值漂移适用于簇数量和形状未知的情况;
- DBSCAN能够识别噪声和发现不规则形状的簇。
选择合适的聚类方法需要考虑数据的特性和分析的目标。
无监督学习------降维(Dimensionality Reduction)
在无监督学习中,降维(Dimensionality Reduction)是减少数据集中变量数量 的技术,旨在发现数据的潜在结构,同时尽可能保留原始数据的重要信息。
以下是对提到的无监督学习降维方法的解释:
-
特征选择(Feature Selection):
- 特征选择是从原始数据集中选择一个变量(特征)子集的过程。
- 它不创建新特征,而是从已有特征中选择最相关的子集,以提高模型的性能和可解释性。
- 特征选择有三种策略:
- 过滤策略(Filter Strategy):根据统计测试(如相关性、互信息等)预先评估特征的重要性,选择最有信息量的特征。
- 包装策略(Wrapper Strategy):将特征子集的选择看作搜索问题,使用模型的预测性能作为指标来评估特征子集的好坏。
- 嵌入式策略(Embedded Strategy):在模型构建过程中进行特征选择,根据模型的预测误差来添加或移除特征。
-
特征提取(Feature Extraction):
- 特征提取是将高维数据转换到低维空间 的过程,通常会产生新的特征,这些特征是原始特征的某种组合或变换。
- 这个过程可以是线性的,例如
主成分分析(PCA),它通过线性变换找到数据的主要方向;也可以是非线性的,例如t-分布随机邻域嵌入(t-SNE)或自编码器(Autoencoders)。 - 特征提取的目的是通过降低数据的维度来简化模型,同时尽可能保留数据的原始结构和重要特征。
特征选择和特征提取都是处理高维数据集的重要技术,它们有助于解决维数灾难(curse of dimensionality),提高学习算法的性能,减少计算资源的需求,并可能揭示数据的内在模式。选择哪种方法取决于数据的特性、分析的目标以及所采用的模型类型。
强化学习
在强化学习(Reinforcement Learning, RL)中,智能体(agent)通过与环境的交互来学习如何采取行动以最大化某种累积奖励。
以下是对提到的几种强化学习方法的解释:
-
Q-学习(Q-learning):
- Q-学习是一种无模型的强化学习算法,它允许智能体学习在给定状态下采取特定行动的预期效用。
- 它基于贝尔曼方程,通过探索(exploration)和利用(exploitation)的平衡来估计状态-行动对(state-action pairs)的价值,即Q值。
- Q-学习不需要对环境进行建模,智能体通过实际经验来学习最优策略。
-
时间差分学习(Temporal Difference, TD):
- 时间差分学习是一种
无监督的强化学习方法,智能体学习预测序列状态结束时某个变量的期望值。 - 它通过比较当前估计值和新获得的样本值(即实际奖励和下一个状态的值)来更新预测。
- 时间差分学习可以用于预测未来奖励的总和,即回报(return)。
- 时间差分学习是一种
-
值迭代(Value Iteration):
- 值迭代是一种动态规划方法,它通过迭代地改进价值函数(value function)直到收敛来找到最优策略。
- 在每次迭代中,智能体更新每个状态的价值估计,直到所有状态的价值估计达到稳定。
- 值迭代通常用于小到中等规模的问题,它可以保证找到最优策略。
-
马尔可夫决策过程(Markov Decision Process, MDP):
- 马尔可夫决策过程是强化学习的基础框架,它描述了智能体在环境中的决策过程。
- MDP包括状态空间、行动空间、转移概率和奖励函数。
- 在MDP中,有两种主要的动态规划变体:
- 策略迭代(Policy Iteration):通过迭代改进策略评估和策略改进步骤来找到最优策略。
- 值迭代:如上所述,通过迭代改进价值函数直到收敛。
这些强化学习方法使智能体能够在不确定性环境中做出决策,学习如何采取行动以实现长期目标。Q-学习和时间差分学习特别适合在线学习,而值迭代和策略迭代则更适用于可以完全访问环境模型的情况。强化学习在游戏、机器人控制、资源管理和许多其他领域都有广泛的应用。
2-3:机器学习应用
如上所述,机器学习被认为是人工智能中的一种流行应用,其中设备、软件和计算机通过认知(即,非常接近人脑原理)来执行任务。
最近,几乎所有的领域都至少包含一种机器学习方法,例如我们每天都在不知不觉中处理的电子邮件垃圾邮件和恶意软件过滤。
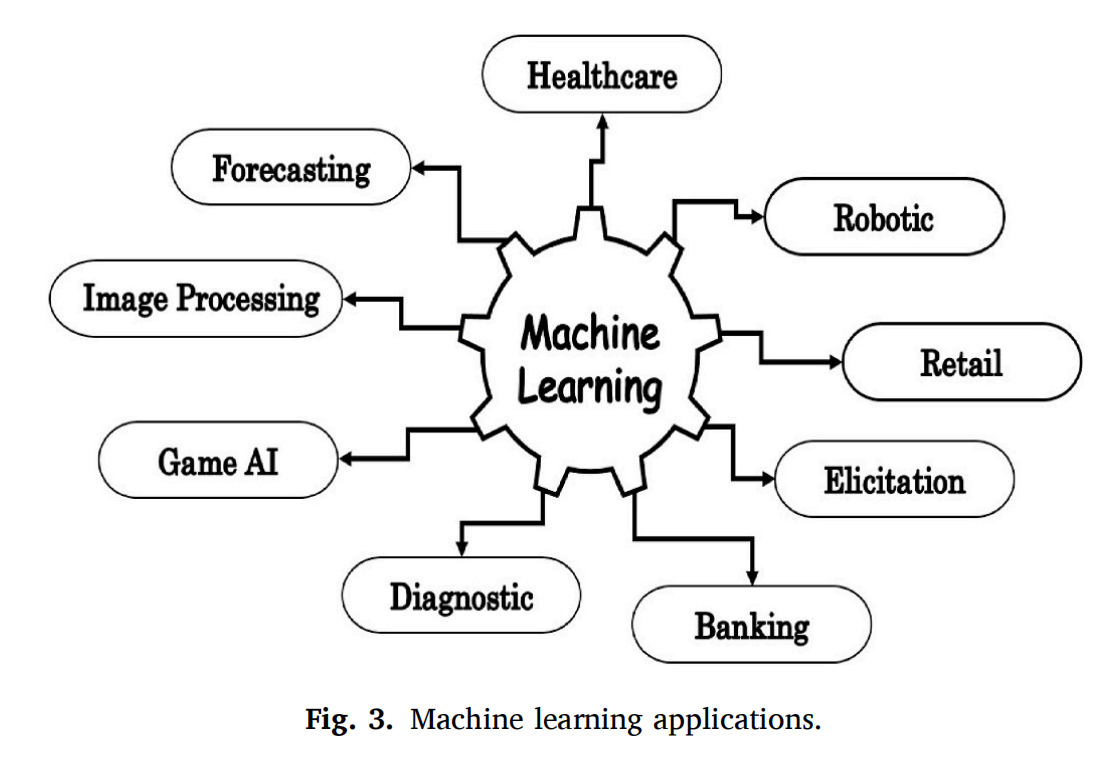
本综述讨论了机器学习在医疗领域的应用,包括医疗保健、图像处理和诊断。
关于机器学习在医疗领域应用的论文已经广泛发表,图4展示了从2000年到2021年12月期间发表的文章数量。
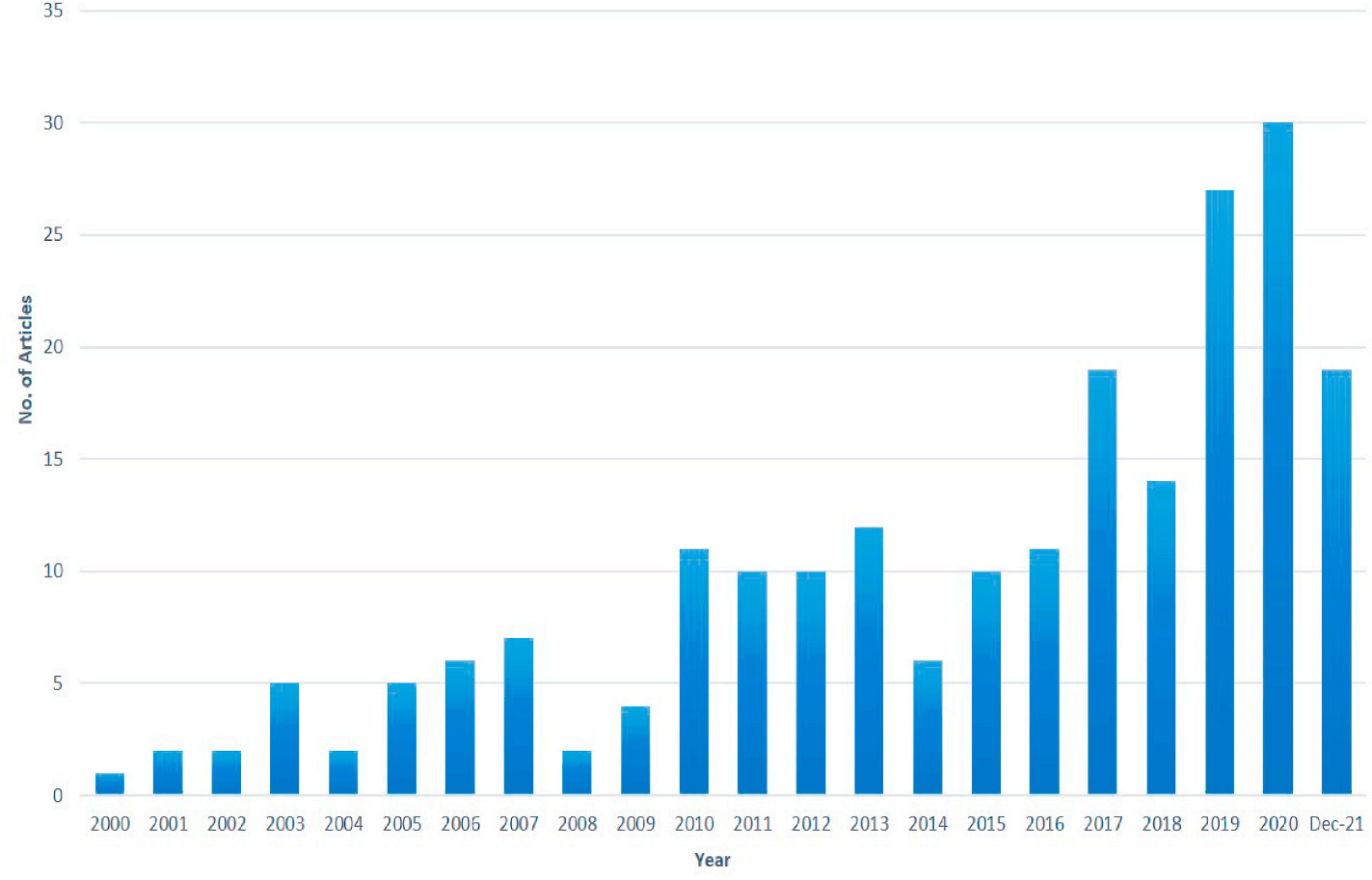
这些材料是根据关键词"机器学习在医疗领域"的应用收集的。首先,从Springer、Elsevier、IEEE以及其他一些通过Google Scholar搜索的知名出版商那里收集了已发表的文章。其次,将搜索结果按出版日期分类,以展示机器学习在医疗领域使用量的增长。
三、机器学习在医疗行业中的应用
3-1:用于预测癌症的ML技术
Table 2 概括了使用机器学习(ML)技术进行癌症预测的不同研究和所使用的技术。
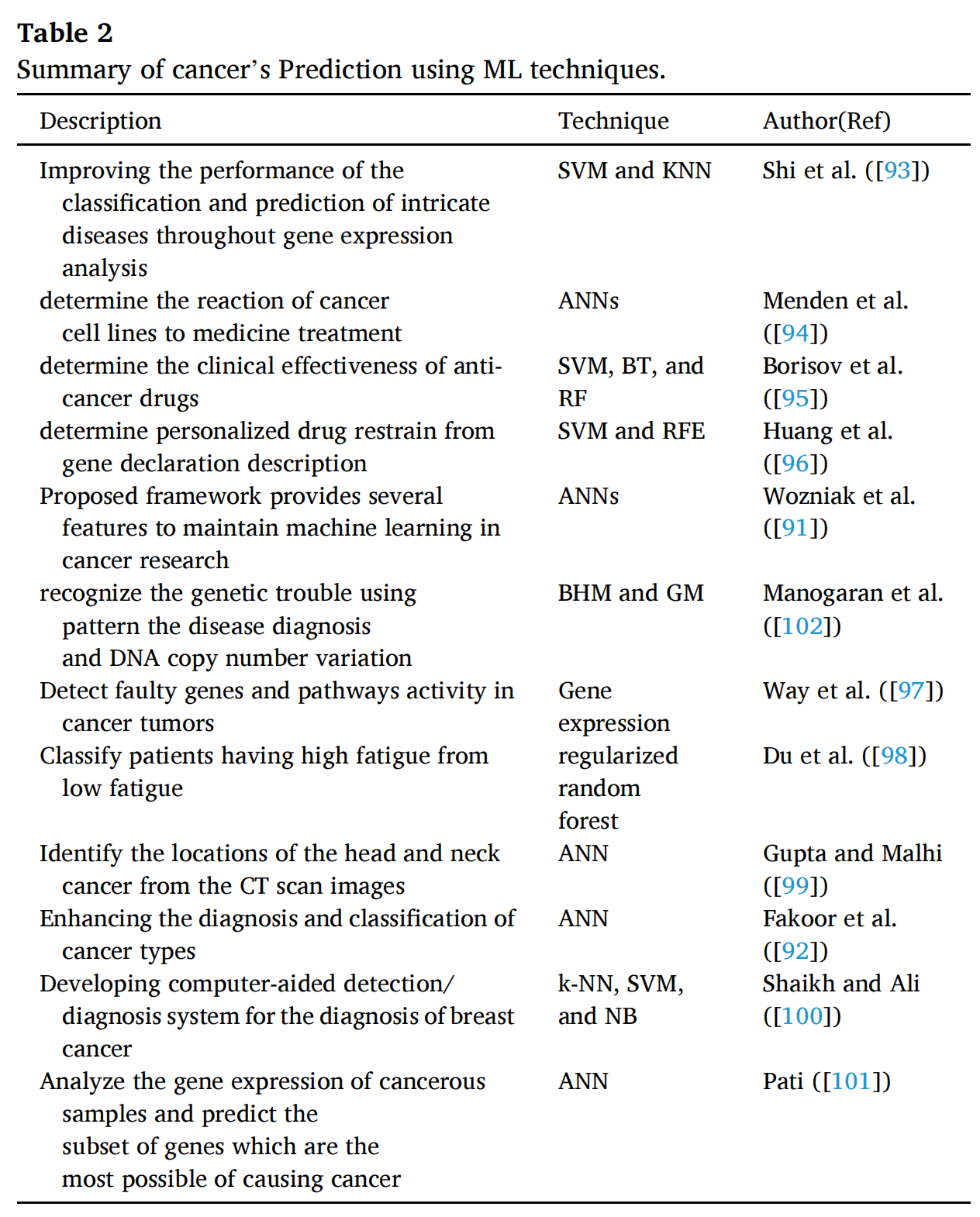
以下是对表中内容的逐项分析:
-
提高基因表达分析中复杂疾病分类和预测的性能:
- 技术:SVM(支持向量机)和KNN(k-最近邻)
- 作者和参考文献:Shi et al. (93)
-
确定癌细胞系对药物治疗的反应:
- 技术:ANNs(人工神经网络)
- 作者和参考文献:Menden et al. (94)
-
确定抗癌药物的临床效果:
- 技术:SVM(支持向量机)、BT(二叉树)、RF(随机森林)
- 作者和参考文献:Borisov et al. (95)
-
从基因表达描述中确定个性化药物抑制:
- 技术:SVM(支持向量机)和RFE(递归特征消除)
- 作者和参考文献:Huang et al. (96)
-
提出的框架为维持癌症研究中的机器学习提供多种特性:
- 技术:ANNs(人工神经网络)
- 作者和参考文献:Wozniak et al. (91)
-
使用模式识别疾病诊断和DNA拷贝数变异的遗传问题:
- 技术:BHM(贝叶斯层次模型)和GM(高斯混合模型)
- 作者和参考文献:Manogaran et al. (102)
-
在癌症肿瘤中检测故障基因和途径活性:
- 技术:基因表达分析
- 作者和参考文献:Way et al. (97)
-
对高疲劳和低疲劳患者进行分类:
- 技术:正则化随机森林
- 作者和参考文献:Du et al. (98)
-
从CT扫描图像中确定头颈癌的位置:
- 技术:ANN(人工神经网络)
- 作者和参考文献:Gupta and Malhi (99)
-
提高癌症类型的诊断和分类:
- 技术:ANN(人工神经网络)
- 作者和参考文献:Fakoor et al. (92)
-
开发用于乳腺癌诊断的计算机辅助检测/诊断系统:
- 技术:k-NN(k-最近邻)、SVM(支持向量机)、NB(朴素贝叶斯)
- 作者和参考文献:Shaikh and Ali (100)
-
分析癌症样本的基因表达并预测最可能导致癌症的基因子集:
- 技术:ANN(人工神经网络)
- 作者和参考文献:Pati (101)
表中的每一项都指出了ML技术在癌症预测中的一个具体应用,并提供了相关研究的作者和引用信息。这表明了ML技术在癌症研究中的多样性和广泛性,从基因表达分析到图像识别,再到个性化治疗的预测。
这些研究为癌症的早期诊断、治疗反应的预测以及个性化医疗提供了有价值的工具和方法。
3-2:机器学习在常见癌症中的应用
肺癌
肺癌是世界上已知的新病例(约每年0.13例)和死亡率(接近0.2例死亡)最多的癌症之一。
肺癌样本错误或致命生长判断的错误会导致手术无效,因为抗癌方法取决于肿瘤形态。在一项评估ML方法在肺癌分析与分类中的性能的研究中,使用了四个公开可访问的数据集(即来自丹娜-法伯癌症研究所、密歇根大学、多伦多大学和布里格姆和妇女医院的数据集,分别包括203、96、39和181个单位)103。
在一项针对立体定向框架放疗(SBRT)后肺炎诊断的大数据工具研究中,提出了一个用于临床决策的算法105。共有201例SBRT后的病例报告了61个特征,其中8例(4.0%)出现了播散性肺炎(RP)。
乳腺癌
乳腺癌是世界上最常见的癌症类型,也是女性癌症死亡的主要原因【106】【107】。
乳腺癌(BDC)在女性癌症死亡中排名第二,但如果早期诊断,它也是最短暂的癌症类型之一【109】。
研究表明,SVM在乳腺癌诊断方面具有众多准确的诊断经验【110】。本研究提出了一种基于SVM和特征选择技术的乳腺癌分析方法。在不同的常见数据集上进行了实验,包括威斯康辛乳腺癌数据集(WBCD)。使用特异性、敏感性、分类性能、阳性预测值、阴性预测值、接收者操作特征混淆矩阵和曲线 来评估所提出算法的有效性。结果显示,包含五个选定特征的SVM模型的分类准确率最高可达99.5%,这比之前发表的算法更令人鼓舞【111】。
前列腺癌
Nguyen等人提出了一种自动化Gleason评分系统,用于诊断前列腺癌。该方法结合了定量相位成像(QPI)技术来报告未标记的样本,并利用ML方法对组织进行分类和诊断组织活检【124】。
Gu等人旨在利用ML方法的能力,及时在前列腺切除术后诊断前列腺癌【125】。
Zhu等人提出了一种在线自适应放射治疗工具,用于评估自适应强度调制放射治疗(IMRT)的能力。他们提出的方法旨在确定前列腺自适应IMRT的质量标准和需求【126】。
Hussain等人也提出了一种使用ML技术的另一种前列腺癌诊断方法【127】。他们使用了多种ML技术,如支持向量机(SVM)和贝叶斯方法,以及一些特征提取方法,以进一步提高诊断效率。
Wang等人提出了一种磁共振成像放射组学分析,以提高PI-RADS v2的性能。这项工作的主要目的是测试ML方法在提高检测前列腺癌性能方面的能力【128】。
胰腺癌
循环外泌体包含丰富的蛋白质组学和传递信息,这对癌症诊断非常有利。
胰腺癌是主要的终末癌症之一,在所有癌症相关死亡案例中排名第四。胰腺癌患者预后不佳,5年存活率仅为6%。由于肿瘤特征、治疗方法和患者群体的多样性,预测胰腺癌存活率具有挑战性。某些预测有助于改善个性化治疗和控制。在参考文献130中,测试了ML在预测胰腺癌存活率方面的有效性。
3-3:不同类型的癌症使用机器学习(ML)技术的情况
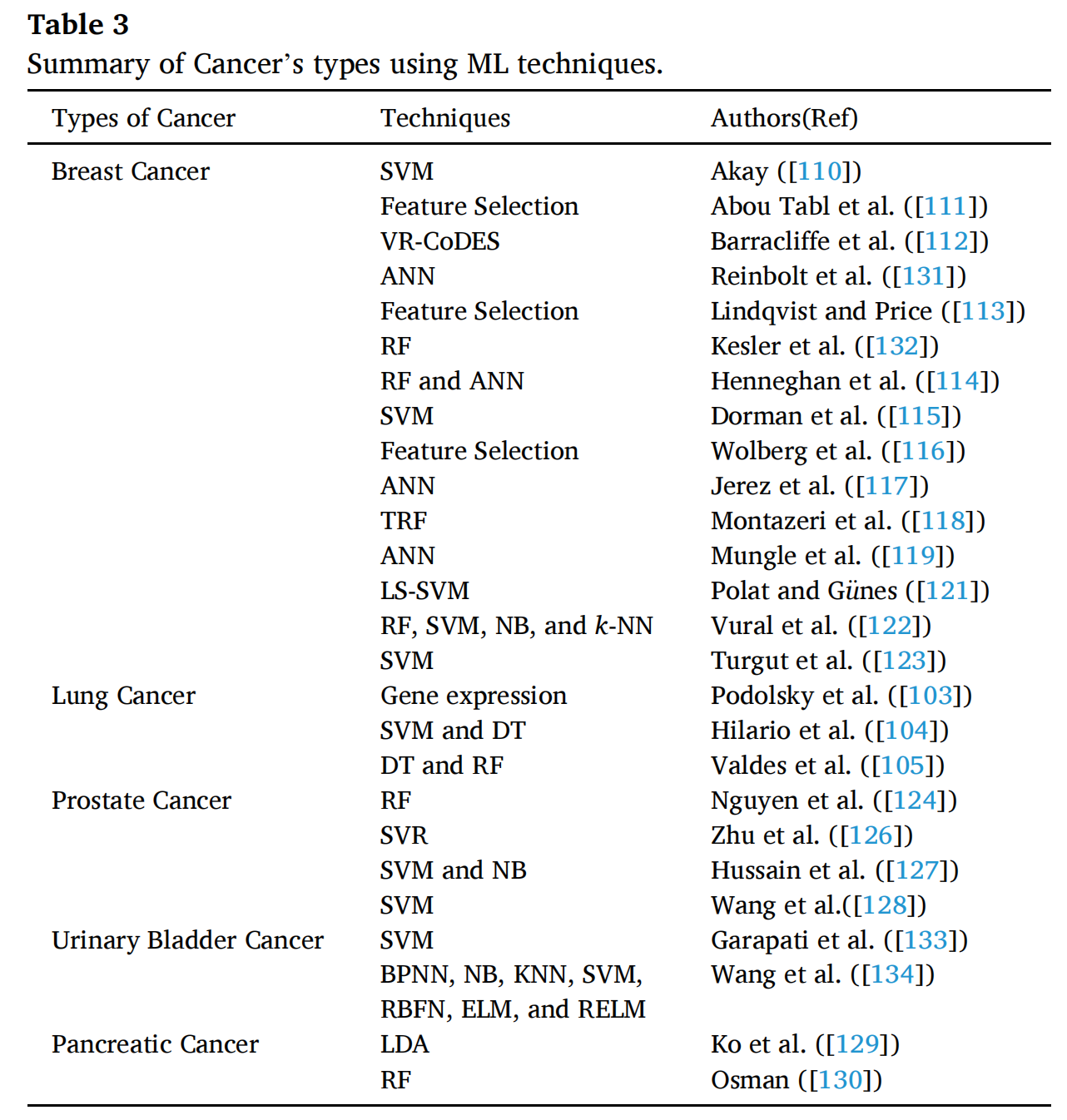
-
乳腺癌(Breast Cancer):
- 使用了多种技术,包括支持向量机(SVM)110、特征选择(Feature Selection)111, 113, 116、人工神经网络(ANN)131, 117, 118, 119、随机森林(RF)132, 114、逻辑斯特回归(TRF)118、最小二乘-SVM(LS-SVM)121、以及多种技术的组合,如RF、SVM、朴素贝叶斯(NB)和k-最近邻(k-NN)122。
-
肺癌(Lung Cancer):
- 技术包括基因表达分析103、SVM与决策树(DT)104、以及DT和RF的结合使用105。
-
前列腺癌(Prostate Cancer):
- 使用了随机森林(RF)124、支持向量回归(SVR)126、SVM与朴素贝叶斯(NB)的组合127,以及SVM128。
-
膀胱癌(Urinary Bladder Cancer):
- 应用了SVM133,以及多种技术的组合,包括反向传播神经网络(BPNN)、NB、k-NN、SVM、径向基函数网络(RBFN)、极限学习机(ELM)和正则化极限学习机(RELM)134。
-
胰腺癌(Pancreatic Cancer):
- 使用了线性判别分析(LDA)129和随机森林(RF)130。
从表中可以看出,每种癌症类型都采用了不同的ML技术,这可能与癌症的生物学特性、数据的可用性和研究者的研究目标有关。一些技术如SVM和ANN在多种癌症类型中都有应用,显示出它们的通用性和有效性。同时,特征选择作为提高模型性能的预处理步骤,在多种癌症研究中都有使用。
此外,表中还反映了ML在癌症研究中的多样性和个性化,不同的癌症可能需要不同的方法来最有效地进行预测和分类。这些研究为未来的癌症诊断、治疗响应预测和个性化医疗提供了有价值的见解和工具。