作者:来自 Elastic Sunile Manjee

在检索增强生成 (RAG) 领域,一个持续存在的挑战是找到输入大型语言模型 (LLM) 的最佳数据量。数据太少会导致响应不足或不准确,而数据太多会导致答案模糊。这种微妙的平衡启发我开发了一个专注于智能分块和利用 Elasticsearch 向量数据库的 notebook。
动机
构建此 notebook 的主要动机是通过解决数据分块的挑战来展示一种改进的 RAG 方法。传统方法通常无法动态调整输入到 LLM 的数据大小,要么因过多上下文而使模型不堪重负,要么因太少而使其不足。此笔记本旨在达到适当的平衡,为 LLM 提供足够的信息以生成精确且与上下文相关的响应。但是,必须注意的是,没有一刀切的解决方案。
此方法特别适用于内容在较长部分或章节中流动的书籍和类似文本。但是,它可能需要适应结构化为较短、不同部分的文本,例如研究论文或文章,其中每个部分可能涵盖不同的主题。在这种情况下,可能需要额外的策略来有效地分块和检索相关内容。
方法
获取周围块
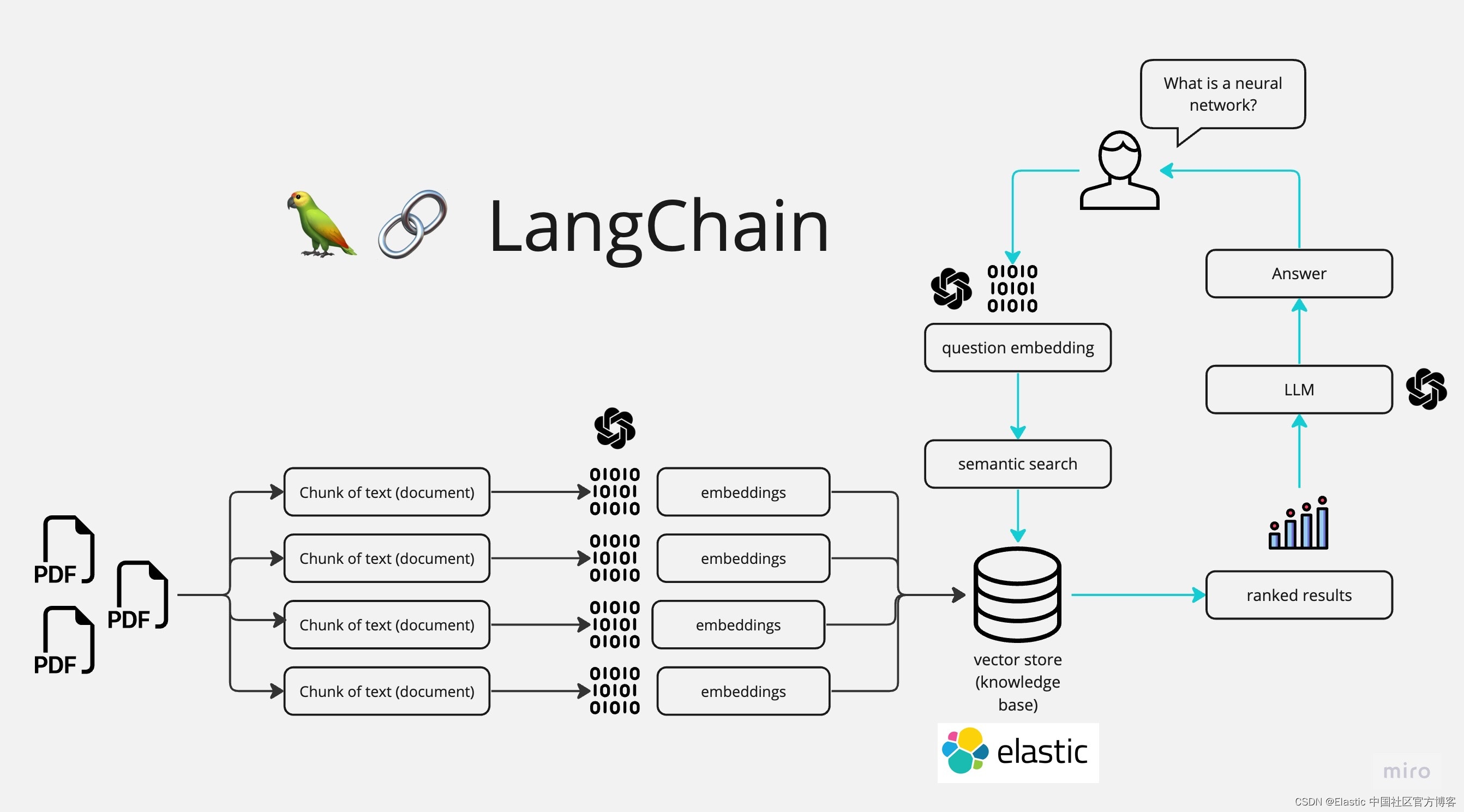
核心思想是将源文本划分为可管理的块,确保每个块包含适量的信息。为了进行演示,我使用了《哈利波特与魔法石》中的文本。文本被划分为章节,每个章节进一步划分为更小的块。这些块及其密集和稀疏 (ELSER) 向量表示都被编入 Elasticsearch 向量数据库的索引中。

为区块分配编号
章节中的每个区块都被分配了一个连续的整数,使我们能够识别其位置。当找到匹配的区块时,章节编号和区块编号用于检索周围的区块,为 LLM 提供额外的上下文。
Elasticsearch 中的向量数据库
这些块及其向量表示被提取到 Elasticsearch Cloud 实例中。Elasticsearch 强大的向量搜索功能使其成为托管这些块的理想选择,允许根据用户查询的语义内容或文本匹配高效地检索最相关的块。
AI 搜索
为了检索相关块,我采用了一种混合搜索策略,同时使用密集向量比较、稀疏向量比较和文本搜索。这种多方面的方法可确保搜索结果在语义上丰富且在上下文上准确。发出查询以查找匹配的块,该查询返回块编号和章节。然后根据匹配的块获取该章节的周围块。
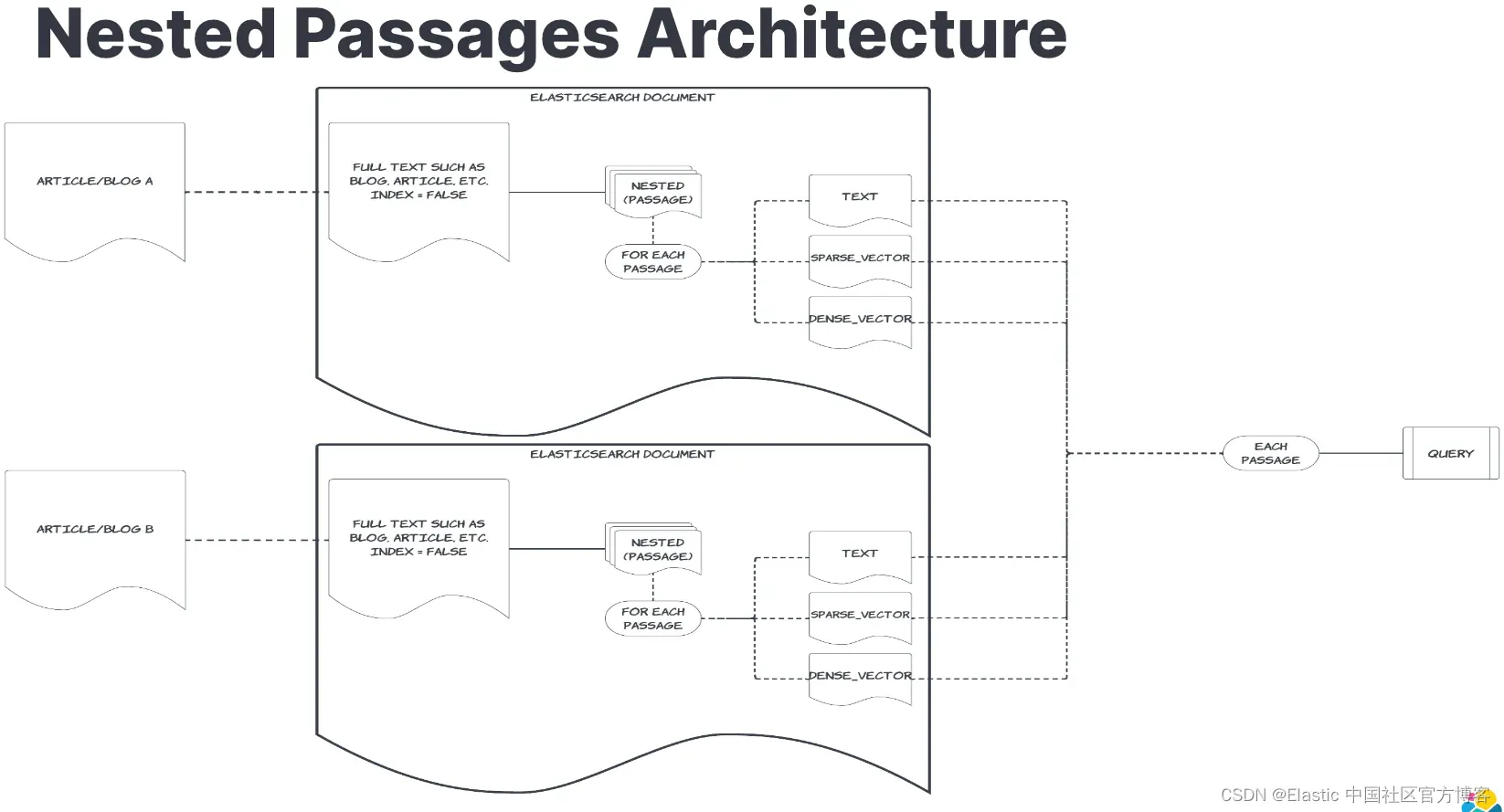
RAG 模式
当进行查询时,搜索流程执行以下步骤:
- 查询分析:将用户的查询转换为密集和稀疏向量,以从 Elasticsearch 索引中检索最相关的块。
- 块检索:使用 AI 搜索策略,系统检索最相关的块。
- 上下文扩展:还会检索相邻块(n-1 和 n+1),以提供更全面的上下文。如果该块是章节中的最后一块,则获取 n-1 和 n-2;如果它是第一块,则获取 n+1 和 n+2。
- LLM 响应:然后将这些智能选择的块输入到 LLM 中,确保它接收最佳信息量以生成精确且上下文相关的响应。
为什么这很重要
这种方法通过优化输入到 LLM 的输入数据来解决 RAG 的一个关键方面。通过利用智能分块和混合语义搜索,该方法提高了 LLM 生成的响应的准确性和相关性。它展示了一种可以广泛应用于 RAG 领域内各种应用的模式,从客户支持到内容生成等等。
结论
本 notebook 强调了 RAG 框架中智能数据分块的重要性,并演示了如何利用 Elasticsearch 矢量数据库来实现最佳结果。通过确保 LLM 接收到适量的信息,这种方法为更准确、上下文更丰富的响应铺平了道路,从而提高了 RAG 系统的整体效率。
准备好自己尝试了吗?开始免费试用。
希望将 RAG 构建到你的应用程序中?想要尝试使用向量数据库的不同 LLMs?
查看 Github 上针对 LangChain、Cohere 等的示例笔记本,并立即加入 Elasticsearch Relevance Engine 培训。
原文:Intelligent RAG, Fetch Surrounding Chunks --- Elastic Search Labs