
前言:
《C语言从入门到进阶》这本书可是作者呕心沥血之作,建议零售价1元,当然这里开个玩笑。
本篇博客可是作者之前写的所有C语言笔记博客的集结,本篇博客不止有知识点,还有一部分代码练习。 有人可能会问,作者不会是cv战士 吧!作者在这里回答大家,有cv战士的成分,但不完全是。我是将之前博客冗余的部分删除。有句话叫取其精华,去其糟粕当嘛!当然作者除了删除冗余部分还会修改一小部分,因为之前写博客的技术还不太成熟,当然现在也不太成熟。所以还是要靠大家的支持作者才有十分的动力去创作,所以在这里要感谢大家的支持,也感谢每一位能进来看一下的读者。那么废话不多说,我们现在就开始。
**注:**右下角也有目录,可以通过右下角的目录跳到对应的知识点。
目录:
目录
[4.1 头文件详解](#4.1 头文件详解)
[12.1 空语句](#12.1 空语句)
[12.2 表达式语句](#12.2 表达式语句)
[12.3 函数调用语句](#12.3 函数调用语句)
[12.4 复合语句](#12.4 复合语句)
[12.5 控制语句](#12.5 控制语句)
[1.1 字符类型](#1.1 字符类型)
[1.2 整型](#1.2 整型)
[1.3 浮点型](#1.3 浮点型)
[1.4 布尔类型](#1.4 布尔类型)
[4.1 变量的创建](#4.1 变量的创建)
[4.2 变量的分类](#4.2 变量的分类)
[5.1 + 和 -](#5.1 + 和 -)
[5.2 * 和 /](#5.2 * 和 /)
[5.3 %操作符](#5.3 %操作符)
[6.1 连续赋值](#6.1 连续赋值)
[6.3 复合赋值](#6.3 复合赋值)
[7.2 +和-](#7.2 +和-)
[9、scanf 和 printf](#9、scanf 和 printf)
[9.1 printf](#9.1 printf)
[9.1.1 基本用法](#9.1.1 基本用法)
[9.1.2 占位符](#9.1.2 占位符)
[9.1.3 占位符列举](#9.1.3 占位符列举)
[9.1.4 输出格式](#9.1.4 输出格式)
[9.2 scanf](#9.2 scanf)
[9.2.1 基本用法](#9.2.1 基本用法)
[2.1 if](#2.1 if)
[2.2 else](#2.2 else)
[2.3 分支中的多条语句](#2.3 分支中的多条语句)
[2.4 嵌套if](#2.4 嵌套if)
[2.5 练习:打印出年龄阶段](#2.5 练习:打印出年龄阶段)
[2.6 悬空else问题](#2.6 悬空else问题)
[3、逻辑操作符&&,| |,!](#3、逻辑操作符&&,| |,!)
[3.1 逻辑取反操作符!](#3.1 逻辑取反操作符!)
[3.2 与操作符&&](#3.2 与操作符&&)
[3.3 或操作符| |](#3.3 或操作符| |)
[3.4 练习:闰年的判断](#3.4 练习:闰年的判断)
[3.5 短路](#3.5 短路)
[4.1 switch](#4.1 switch)
[4.2 switch中的break](#4.2 switch中的break)
[4.3 练习:打印对应日期](#4.3 练习:打印对应日期)
[4.4 switch中的default](#4.4 switch中的default)
[5.1 if 和while的对比](#5.1 if 和while的对比)
[5.2 while的执行流程](#5.2 while的执行流程)
[5.3 while循环的实践](#5.3 while循环的实践)
[5.4 练习:打印值的每一位](#5.4 练习:打印值的每一位)
[6.1 语法形式](#6.1 语法形式)
[6.2 for循环的执行流程](#6.2 for循环的执行流程)
[6.3 for循环的实践](#6.3 for循环的实践)
[6.4 while循环和for循环的对比](#6.4 while循环和for循环的对比)
[6.5 练习](#6.5 练习)
[7.1 语法形式](#7.1 语法形式)
[7.2 do while循环流程](#7.2 do while循环流程)
[7.3 练习](#7.3 练习)
[8.1 break](#8.1 break)
[8.2 continue](#8.2 continue)
[9.2 练习2:打印乘法口诀表](#9.2 练习2:打印乘法口诀表)
[11.1 随机数生成](#11.1 随机数生成)
[11.1.1 rand](#11.1.1 rand)
[11.1.2 srand](#11.1.2 srand)
[11.1.3 time](#11.1.3 time)
[11.1.4 设置随机数的范围](#11.1.4 设置随机数的范围)
[11.2 猜数字游戏的实现](#11.2 猜数字游戏的实现)
[2.1 数组创建](#2.1 数组创建)
[2.2 数组初始化](#2.2 数组初始化)
[2.3 数组的类型](#2.3 数组的类型)
[3.1 数组的下标](#3.1 数组的下标)
[3.2 数组的输入](#3.2 数组的输入)
[6.1 二维数组的概念](#6.1 二维数组的概念)
[6.2 二维数组的创建](#6.2 二维数组的创建)
[7.1 不完全初始化](#7.1 不完全初始化)
[7.2 完全初始化](#7.2 完全初始化)
[7.3 按照行初始化](#7.3 按照行初始化)
[7.4 初始化省略行,但是不能省略列](#7.4 初始化省略行,但是不能省略列)
[8.1 二维数组的下标](#8.1 二维数组的下标)
[8.2 二维数组的输入输出](#8.2 二维数组的输入输出)
[2.1 标准库和头文件](#2.1 标准库和头文件)
[2.2 库函数的使用方法](#2.2 库函数的使用方法)
[2.2.1 功能](#2.2.1 功能)
[2.2.2 头文件包含](#2.2.2 头文件包含)
[2.2.3 实践](#2.2.3 实践)
[2.2.4 库函数文档一般格式](#2.2.4 库函数文档一般格式)
[3.1 函数的语法形式](#3.1 函数的语法形式)
[3.2 函数举例](#3.2 函数举例)
[4.1 实参](#4.1 实参)
[4.2 形参](#4.2 形参)
[4.3 形参和实参的关系](#4.3 形参和实参的关系)
[7.1 传值调用](#7.1 传值调用)
[7.2 传址调用](#7.2 传址调用)
[8.1 嵌套调用](#8.1 嵌套调用)
[8.2 链式访问](#8.2 链式访问)
[9.1 单个文件的函数声明和定义](#9.1 单个文件的函数声明和定义)
[9.2 多个文件的函数声明和定义](#9.2 多个文件的函数声明和定义)
[10.1 extern外部声明](#10.1 extern外部声明)
[10.2 static静态修饰](#10.2 static静态修饰)
[10.2.1 static修饰局部变量](#10.2.1 static修饰局部变量)
[10.2.2 static修饰全局变量](#10.2.2 static修饰全局变量)
[10.2.3 static修饰函数](#10.2.3 static修饰函数)
[3.1 举例1:求n的阶乘](#3.1 举例1:求n的阶乘)
[3.1.1 分析和代码实现](#3.1.1 分析和代码实现)
[3.1.2 运行结果:](#3.1.2 运行结果:)
[3.2 举例2:顺序打印一个整数的每一位](#3.2 举例2:顺序打印一个整数的每一位)
[3.2.1 分析和代码实现](#3.2.1 分析和代码实现)
[3.2.2 画图推演](#3.2.2 画图推演)
[1.1 2进制转10进制](#1.1 2进制转10进制)
[1.2 10进制转2进制](#1.2 10进制转2进制)
[1.4 2进制转8进制](#1.4 2进制转8进制)
[1.4 2进制转16进制](#1.4 2进制转16进制)
[3.1 左移操作符](#3.1 左移操作符)
[3.2 右移操作符](#3.2 右移操作符)
[按位取反操作符 ~](#按位取反操作符 ~)
[6、下标访问 、函数调用()](#6、下标访问[ ]、函数调用())
[6.1 下表访问 ](#6.1 下表访问[ ])
[6.2 函数调用()](#6.2 函数调用())
[7.1 优先级](#7.1 优先级)
[7.2 结合性](#7.2 结合性)
[8.1 整形提升](#8.1 整形提升)
[8.2 算数转换](#8.2 算数转换)
[1.1 内存](#1.1 内存)
[1.2 如何理解编址](#1.2 如何理解编址)
[2.1 取地址操作符(&)](#2.1 取地址操作符(&))
[2.2 指针变量和解引用操作符(*)](#2.2 指针变量和解引用操作符(*))
[2.3 指针变量的大小](#2.3 指针变量的大小)
[3.1 指针的解引用](#3.1 指针的解引用)
[3.2 指针+-整数](#3.2 指针+-整数)
[4.1 const修饰变量](#4.1 const修饰变量)
[5.1 指针+-整数](#5.1 指针+-整数)
[5.2 指针-指针](#5.2 指针-指针)
[5.3 指针的关系运算](#5.3 指针的关系运算)
[6.1 野指针成因](#6.1 野指针成因)
[6.2 如何规避野指针](#6.2 如何规避野指针)
[6.2.1 指针初始化](#6.2.1 指针初始化)
[6.2.2 小心指针越界访问](#6.2.2 小心指针越界访问)
[6.2.3 指针变量不再使用时,及时置为NULL,指针使用之前检查有效性](#6.2.3 指针变量不再使用时,及时置为NULL,指针使用之前检查有效性)
[6.2.4 避免返回局部变量的地址](#6.2.4 避免返回局部变量的地址)
[8.1 传址调用](#8.1 传址调用)
[8.2 strlen的模拟实现](#8.2 strlen的模拟实现)
[4.1 函数指针变量的创建](#4.1 函数指针变量的创建)
[4.2 函数指针变量的使用](#4.2 函数指针变量的使用)
[4.3 两端有趣的代码](#4.3 两端有趣的代码)
[4.3.1 typedef关键字](#4.3.1 typedef关键字)
[11.1 冒泡排序](#11.1 冒泡排序)
[11.2 模拟实现](#11.2 模拟实现)
7、桃园三结义:长度受限制函数strncpy、strncat、strncmp
[2.1 什么是大小端?](#2.1 什么是大小端?)
[2.2 为什么有大小端?](#2.2 为什么有大小端?)
[2.3 练习](#2.3 练习)
[3.1 练习](#3.1 练习)
[3.2 浮点数的存储](#3.2 浮点数的存储)
[3.2.1 浮点数存储过程](#3.2.1 浮点数存储过程)
[3.2.2 浮点数取出过程](#3.2.2 浮点数取出过程)
[1.1 结构的创建](#1.1 结构的创建)
[1.1.1 结构的声明](#1.1.1 结构的声明)
[1.1.2 结构体类型的变量](#1.1.2 结构体类型的变量)
[1.1.3 结构的初始化](#1.1.3 结构的初始化)
[1.2 结构的特殊声明](#1.2 结构的特殊声明)
[1.3 结构的自引用](#1.3 结构的自引用)
[1.3.1 typedef类型重命名](#1.3.1 typedef类型重命名)
[2.1 对齐规则](#2.1 对齐规则)
[2.2 为什么存在内存对齐](#2.2 为什么存在内存对齐)
[2.3 修改默认对齐数](#2.3 修改默认对齐数)
[4.1 什么是位段](#4.1 什么是位段)
[4.2 位段的内存分配](#4.2 位段的内存分配)
[4.3 位段的跨平台问题](#4.3 位段的跨平台问题)
[4.5 位段使用的注意事项](#4.5 位段使用的注意事项)
[第十三章:自定义类型(联合union 、枚举enum)](#第十三章:自定义类型(联合union 、枚举enum))
[1.1 联合体类型的声明](#1.1 联合体类型的声明)
[1.2 联合体的特点](#1.2 联合体的特点)
[1.3 相同成员的结构体和联合体对比](#1.3 相同成员的结构体和联合体对比)
[1.4 联合体大小的计算](#1.4 联合体大小的计算)
[1.5 联合体的应用场景](#1.5 联合体的应用场景)
[2.1 枚举类型的声明](#2.1 枚举类型的声明)
[2.2 枚举类型的优点](#2.2 枚举类型的优点)
[2.3 枚举类型的使用](#2.3 枚举类型的使用)
[2.1 malloc](#2.1 malloc)
[2.2 free](#2.2 free)
[3.1 calloc](#3.1 calloc)
[3.2 realloc](#3.2 realloc)
[4.1 对NULL指针的解引用操作](#4.1 对NULL指针的解引用操作)
[4.2 对动态开辟的空间越界访问](#4.2 对动态开辟的空间越界访问)
[4.3 对非动态开辟内存使用free释放](#4.3 对非动态开辟内存使用free释放)
[4.4 使用free释放一块动态开辟内存的一部分](#4.4 使用free释放一块动态开辟内存的一部分)
[4.5 对同一块动态内存多次释放](#4.5 对同一块动态内存多次释放)
[4.6 动态开辟内存忘记释放(内存泄漏)](#4.6 动态开辟内存忘记释放(内存泄漏))
[5.1 柔性数组的特点:](#5.1 柔性数组的特点:)
[5.2 柔性数组的使用](#5.2 柔性数组的使用)
[2.1 程序文件](#2.1 程序文件)
[2.2 数据文件](#2.2 数据文件)
[2.3 文件名](#2.3 文件名)
[4.1 流和标准流](#4.1 流和标准流)
[4.1.1 流](#4.1.1 流)
[4.1.2 标准流](#4.1.2 标准流)
[4.2 文件指针](#4.2 文件指针)
[4.3 文件的打开和关闭](#4.3 文件的打开和关闭)
[4.4 文件指针的概念](#4.4 文件指针的概念)
[5.1 顺序读写函数介绍](#5.1 顺序读写函数介绍)
[5.1.1 fputc的使用](#5.1.1 fputc的使用)
[5.1.2 fgetc的使用](#5.1.2 fgetc的使用)
[5.1.3 fputs的使用](#5.1.3 fputs的使用)
[5.1.4 fgets的使用](#5.1.4 fgets的使用)
[5.1.5 fprintf的使用](#5.1.5 fprintf的使用)
[5.1.6 fscanf的使用](#5.1.6 fscanf的使用)
[5.1.7 fwrite的使用](#5.1.7 fwrite的使用)
[5.1.8 fread的使用](#5.1.8 fread的使用)
[5.2 对比一组函数:](#5.2 对比一组函数:)
[6.1 fseek](#6.1 fseek)
[6.2 ftell](#6.2 ftell)
[6.3 rewind](#6.3 rewind)
[7.1 被错误使用的feof](#7.1 被错误使用的feof)
[7.2 ferror](#7.2 ferror)
[2.1 预处理(预编译)](#2.1 预处理(预编译))
[2.2 编译](#2.2 编译)
[2.2.1 词法分析](#2.2.1 词法分析)
[2.2.2 语法分析](#2.2.2 语法分析)
[2.2.3 语义分析](#2.2.3 语义分析)
[2.3 汇编](#2.3 汇编)
[2.4 链接](#2.4 链接)
[2、#define 定义常量](#define 定义常量)
[7.2 ## 运算符](## 运算符)
[11.1 条件编译](#11.1 条件编译)
[11.2 多分支条件编译](#11.2 多分支条件编译)
[11.3 判断是否被定义](#11.3 判断是否被定义)
[12.1 头文件被包含方式](#12.1 头文件被包含方式)
[12.1.1 本地文件包含](#12.1.1 本地文件包含)
[12.1.2 库文件包含](#12.1.2 库文件包含)
[12.2 嵌套文件包含](#12.2 嵌套文件包含)
第一章:初识C语言
1、C语言是什么?
人与人交流用的是自然语言,例如:汉语、英语、日语。
那人与计算机之间该怎么交流呢?使用计算机语言。
计算机语言有上千种,例如:c / c++ / Java / Python / Go 等等... 其中就包括我们熟知的C语言。
计算机语言和自然语言一样拥有多种不同的语言,我们可以使用各种语言与其他人交流,计算机语言也一样。
所以C语言是众多计算机语言中的其中之一种语言。
2、第一个C语言程序
cpp
#include <stdio.h> //头文件
int main()
{
printf("hello world\n");
return 0;
}在VS2022上运行代码的快捷键:ctrl+F5 (直接将代码编译和链接生成可执行程序并把结果输出在屏幕上,简称为运行)
3、main函数
每个C语言程序不管有多少行代码,都是从main函数开始执行的,main函数是程序的入口,所以main被称为:主函数,main前面的int表示main函数执行结束时需要返回一个整形类型的值。所以main函数最后写return 0; 前后呼应。
- main函数是程序的入口
- main函数有且只有一个
- 一个项目里不管有多少.c文件,但是main函数只能有一个(main函数是程序的入口)
4、库函数
库函数就是标准库的函数,由编译器厂商实现。
4.1 头文件详解
printf是个库函数,库函数需要包含相应的头文件
cpp
#include<stdio.h>头文件解析:
头文件的#include是预处理,是用来包含头文件的。这个"<>"括号里的的stdio.h是头文件的文件名,.h后缀代表该文件是头文件,stdio是英文 (standard(标准) input(输入) output(输出)) 的缩写,全名"standard input output(标准输入输出)",所以每个被调用的标准输入输出函数都会通过该头文件里对应的函数声明到标准库中找到函数的定义并使用。#include<stdio.h>里的"<>"表示是标准库的头文件。#include"stdio.h"表示本地头文件,就是个人创建的头文件。如果调用一个函数会先到本地路径去找头文件,如果未找到,便会自己到标准库里去找。
标准库头文件不止#include<stdio.h>这一个,还有多个类型的库函数需要包含的头文件,比如math.h ,该头文件里定义的是所有关于math(数学)函数的声明。关于输入输出的函数会声明在一个头文件中,关于数学的函数会声明在另一个头文件中。所以想调用一个库函数,必须包含对应的头文件,才能在对应函数的头文件找到该函数的声明并调用。
4.2 什么是库函数?库函数是怎么来的呢?
库函数是由C语言标准规定的一些函数,是由不同的编译器厂商提供的库函数。比如printf就是库函数。C语言规定一些函数的标准,例如需要什么函数,函数的功能是什么。所以C语言本身是不提供函数只提供函数的实现标准的,我们所使用的的那些库函数都是由C语言的编译器厂商根据C语言所提供的标准实现的。
比如我们熟知的VS,它的库函数是由微软提供的。Xcode是由苹果提供的。他们就是根据C语言规定的函数标准去实现这些函数放在编译器中供用户使用。
这些函数比较多,所以这些函数会集成在一起,被称为标准库,这些函数就是库函数(这些函数在其他编译器不一定支持)。
虽然每个编译器的厂商他们的函数实现的功能和使用方式一模一样,但是函数的实现细节可能略有差异。
5、关键字介绍
关键字是C语言中一批保留的名字的符号,比如:int、if、return,这些符号被称为保留字 或者关键字。
- 关键字都有特殊的意义,是保留给C语言使用的。
- 程序员自己创建标识符(定义变量名时和#define定义名称时)的时候是不能和关键字重复的。
- 关键字也是不能自己创建的
例如:
cpp
#define goto 200 //#define定义时使用关键字作为名称
int main()
{
int const = 0; //变量名是关键字
return 0;
}
//这些都是不被允许的C语言32个关键字如下:
auto break case char const continue default do double else enum extern float for goto if int long register return short signed sizeof struct switch typedef union unsigned void volatile while
以上32个关键字是使用次数较多的常用关键字
注:在C99标准中加入里inline、restrict、_Boot、_Comploex、_Imaginary等关键字。
6、字符和ASCII编码
键盘中可以敲出各种符号,例如:' a '、' A '、' # '、' @ '、' 4 ' 等这些被称为字符。每个字符都有一个ASCIi编码。那为什么要有ASCII编码这个概念?
大家都知道字符是以二进制的形式存入内存中,我自己给每个字符创建了一个编码(每一个字符都设计一个二进制序列,这个叫做编码,例如:0001-' a '、0002-' b ') 我可以通过我设计的编码来使用字符,但是有一个缺陷就是这个编码对应的字符只有我自己知道,别人也有一套自己给字符设计的编码,在于别人通信时造成了信息不对等,为了解决这个问题,后来美国国际标准学会(ANSI) 出台了一个标准ASCII编码,C语言中的字符就遵循了ASCII编码的方式。
ASCII里的字符都是以0--127的十进制的数字表示,也叫编号。以编号的二进制存入内存中叫做编码,共128个字符。
ASCII码表:

如果细心观察就会发现ASCII码表里的字符都是英文字符,这是因为ASCII码表是美国人发明的,所以都是英文字符。所以当C语言适用于亚洲和欧洲时,发现一些语言符号不能简单的用ASCII编码的0-127来表示,所以后来人们又在ASCII码表的基础上又扩展了128个字符,ASCII码表后面还有一个扩展表,扩展表中规定了亚洲地区的字号编码128--255,共有256个字符。
但是C语言又在亚洲各个地区开放导致256个字符编码都不够用,后来又衍生出了各种各样的编码,比如国内汉语用的比较多的编码是GB2312
我们不需要记住所有的ASCII码表中的数字,使用时差看就可以,不过我们最好能掌握几组特殊数据。
- 字符A-Z的ASCII码值范围65-90
- 字符a-z的ASCII码值范围97-122
- 对应的大小写字母(a和A)的ASCII码值的差值是32
- 数字字符0-9的ASCII码值范围48-57
- 换行 '\n' 的ASCII码值是:10
打印ASCII里所有字符的代码
cpp
#include <stdio.h>
int main()
{
int i = 0;
for(i=32;i<=127;i++) //循环范围是32-127
{
if(i%16==0) //判断i此时是不是16的整数倍
printf("\n");
printf("%c ",i); //将数字以%c(字符)形式打印
//会将数字所对应ASCII码值的字符放进去打印
}
return 0;
}结果:
前32个ASCII码值之所以不打印是因为它们是类似 ' \n '的字符,无法靠打印显示出来
7、字符串和 ' \0 '
字符串介绍:
单引号括起来的叫做字符,例如:' a ' , ' 1 ' , ' & ' 这些 由单引号括起来的叫做字符。那字符串又是什么? "hello world"这种由双引号括起来的多个字符被称为字符串。字符串可以理解为多种字符串成了一串,就叫字符串。
' \0 '介绍:
' \0 '是字符串的结束标志。
每个字符串的内容不止表面的几个字符,例如 "hello",它实际上存储了6个字符,为什么?
这是因为每创建一个的字符串结尾都有一个结束标志 ' \0 ',因为程序在内存中读取字符串时,是从前往后一个一个读取的,所以最后需要额外存储一个结束标志,程序读取到最后读到结束标志' \0 '就会停止往内存后面继续读取,因为后面的内存不属于字符串的开辟的内存范围了,往后继续读取读到的只是乱码。
注:' \0 ' 只是作为结束标志存储在字符串中的,所以不会显现出来,所以我们看不到结束标志,但是在创建字符串时需要额外开辟一个字节的空间用来存储' \0 '。
cpp
#include <stdio.h>
int main()
{
char str1[] = "hello"; //创建字符数组
char str2[] = {'h','e','l','l','o'};
printf("%s\n",str1);
printf("%s\n",str2);
return 0;
}字符数组可以存储多个字符和字符串,以上代码说明字符数组可以使用这两种方式存储字符,但是打印的结果是不是一样的?答案是不一样。因为在创建str1时初始化的是字符串,字符串是结尾自带结束标志。而创建str2时初始化的是字符,是一个一个存储,字符是没有结束标志的,所以str1会打印出" hello ",str2会打印出" hello烫烫烫"(后面打印的是乱码),str2在打印时程序会一直向后读取字符,字符' o '读取结束后程序并未发现结束标志,所以会继续向后读取直到找到' \0 '为止,字符' o '后面的空间不属于str2开辟的,所以向后读取出的就是乱码。

所以str1和str2的区别就是一个有' \0 ',一个没有。
%s是用来打印字符串的,str2里的字符也是连续存放的,所以也可以使用%s打印。
那如果想让str1和str2打印的结果一样,就给str2数组多初始化一个' \0 ',如以下代码
cpp
#include <stdio.h>
int main()
{
char str1[] = "hello";
char str2[] = {'h','e','l','l','o','\0'};
printf("%s\n",str1);
printf("%s\n",str2);
return 0;
}总结:字符串是有双引号括起来的"多个字符"组成的,结尾会有结束标志'\0'。
8、转义字符
什么是转义字符?比如刚学过的' \n '或者' \0 '这种就叫做转义字符。
转义字符顾名思义就是转变意义的符号,比如我有一个数字字符' 0 ',但是当我给这个字符前面加上右斜杠' \ '后,就是' \0 ',意思就从字符' 0 ' 转变为' \0 '字符串结束标志,这种就叫做转义字符。
 看上面的两种代码打印的结果是不是不同,这是因为转义字符,仔细观察会发现一个字符串中是字符' n ',将字符' n '打印在了屏幕上。而另一个字符串中是' \n '转义字符,此时字符' n '变成了' \n '换行,所以可以看到两段代码输出结果各不相同。
看上面的两种代码打印的结果是不是不同,这是因为转义字符,仔细观察会发现一个字符串中是字符' n ',将字符' n '打印在了屏幕上。而另一个字符串中是' \n '转义字符,此时字符' n '变成了' \n '换行,所以可以看到两段代码输出结果各不相同。
转义字符列表
- \?:在书写连续多个问号时使用,防止他们被解析成三字母词,在新的编译器上无法验证
三字母词就是??)--转换-->],??(--转换-->[
- \':用于表示字符常量'
- \":用于表示字符串内部的双引号
- \\:用于表示反斜杠,防止字符被解释为转义字符
- \a:警报(蜂鸣)
- \b:退格键,光标回退一个字符,但不删除字符
- \f:换页符,光标移到下一页,在现代系统上,这已经反应不出来了,行为改成类似于\v
- \n:换行符
- \r:回车符,光标移到同一行的开头
- \t:制表符,光标移到下一个水平制表位,通常是下一个8的倍数
- \v:垂直分隔符,光标移到下一个垂直制表位,通常是下一行的同一列。
下面两种转义可以理解为:字符的8进制或16进制的形式
- \ddd:ddd表示1---3个八进制的数字。 如:\130 表示字符X
- \xdd:dd表示2个十六禁止的数字。 如:\x30 表示字符0
strlen库函数介绍
先给大家介绍一下strlen 库函数,strlen全名string length(字符串长度),顾名思义这个库函数就是求字符串长度的库函数,需要包含对应的头文件**#include <string.h>**,比如我有一串字符串"abcdef",让strlen求一下这个字符串长度。
cpp
#include <stdio.h>
#include <string.h>
int main()
{
int len = strlen("abcdef"); //创建整型变量len,来接收strlen返回的字符长度
printf("%d\n",len); //打印结果为6
return 0;
}strlen函数的原理就是遇到一个字符就+1,直到遇到 '\0'结束标志为止,所以只会计入' \0 '之前的字符个数。
strlen库函数的返回类型是size_t(无符号整型) ,因为strlen不可能接收到一个长度为负数的字符串,所以返回类型是绝对的,也就是size_t。严格意义上来讲用int(整型)类型的变量len来接收size_t类型的值是不准确的,我也可以用size_t类型的变量来接收strlen的返回值,例如:size_t len = strlen("abcdef"); 但是也可以用int类型变量来接收strlen的返回值。
下面给一段代码,来算字符长度:
cpp
#include <stdio.h>
#include <string.h>
int main()
{
int len = strlen("c:\test\class111\123.c");
printf("%d\n",len); //结果是多少
return 0;
}把一个文件路径当做字符串放进去,求一下这个文件路径的长度,这个字符串长度结果为17。为什么是17呢?里面不是共有22字符吗?这是因为\与字符发生了转义,变为了转义字符。比如上面' \ '与' t '发生了转义,变为了' \t ',它此时就变为了转义字符,被算作一个字符。里面的' \ ' 和' c '结合后虽然不是转义字符,但是会被strlen识别为转义字符,所以会变成' \c ',不是转义字符所以\去除,最后就是' c '(所以如果想让' \ '作为一个普通存入字符串中,就需要' \\ ',注意,这不是注释,而是转义字符,作用就是让' \ '变为一个普通的字符)。后面的'\123'是转义字符,后面是三个八进制位数,它会转换成ASCII码表中对应这个八进制的字符,首先将八进制123转换为十进制数就是83,83作为ASCII码值对应的字符就是' S ',所以'\123'会被替换成' S '。最后的结果也就是17。
以上就是关于strlen的介绍和转义字符功能讲解。
9、语句和语句分类
C语言代码是一条一条的语句构成的,C语言的语句可以分为五类:
- 空语句
- 复合语句
- 表达式语句
- 函数调用语句
- 控制语句
12.1 空语句
空语句是最简单的,一个分号就是一条语句,是空语句
cpp
#include <stdio.h>
int main()
{
;//空语句
return 0;
}空语句一般出现的地方是:这里需要一条语句,但是这个语句不需要做任何事,都可以写一个空语句。
12.2 表达式语句
表达式语句就是在表达式后面加个分号。如下所示:
cpp
#include <stdio.h>
int main()
{
int a = 20;
int b = 0;
b = a + 5; //表达式语句
return 0;
}12.3 函数调用语句
函数调用的时候,也会加上分号,就是函数调用语句。
cpp
#include <stdio.h>
int Add(int x,int y) //自定义函数
{
return x + y;
}
int main()
{
printf("haha\n");//库函数调用也属于函数调用语句
int ret = Add(10,20);//函数调用语句
return 0;
}12.4复合语句
一个括号内有多条语句就是复合语句。
cpp
#include <stdio.h>
int print(int arr[],int sz) //自定义函数的大括号中的代码也构成符合语句
{
int i = 0;
for(i=0;i<sz;i++)
{
printf("%d ",arr[i]);
}
}
int main()
{
int i = 0;
int arr[10] = {0};
for(i=0;i<10;i++) //for循环的循环体的大括号中就是复合语句
{
arr[i] = 10-i;
printf("%d\n",arr[i]);
}
return 0;
}12.5 控制语句
控制语句用于控制程序的执行流程,以实现程序的各种结构方式 (C语言支持三种结构:顺序结构、选择结构、循环结构),他们由特定的语句定义符组成,C语言由九种控制语句。
1.条件判断句(分支语句):if语句、Switch语句;
2.循环执行语句:do while语句、while语句、for语句;
3.转向语句:break语句、goto语句、continue语句、return语句;
13、注释是什么?为什么写注释?
注释是对代码的说明,编译器会忽略注释,也即是说,注释对实际代码么有影响。
注释是给自己看的,也是给别人看的。
好的注释可以帮我们更好的理解代码,但是不要过度注释,不要写没必要的注释。
当然不写注释可能会让后期阅读的人抓狂。
写注释一定程度上反应了程序坐着的素质,建议大家写必要的注释,在找工作时,写代码留下必要的注释也会给面试官留下更好的印象。
13.1注释的2种形式
C语言的注释有两种表示方法。
第一种/*注释*/,可以注释里面的内容。
缺点:不能嵌套注释
第二种//注释,可以注释后面的文字,支持多行注释,推荐使用。
13.2注释会被替换
编译时,注释会被替换为空格,例如hello/*注释*/world,会被分开一个空格hello world。
第二章:数据类型和变量
1、数据类型的介绍
在日常生活当中有非常多的数据,比如一个人的名字或体重、一本书的版号、一件商品的价格这些在计算机上都可以称为数据,而C语言的类型是用来表示生活中的各种数据。使用整形类型来表示整数,使用字符类型来表示字符,使用浮点类型来表示小数,就是相似的数据所拥有的共同特征,编译器只有知道了数据的类型,才知道怎么操作数据。
- 3 , 47 , 100为整数,也被称为整型数据
- 'a' , 'c' , ' l ' 为字符,也被称为字符类型数据
- 3.14,25.6为小数,也被称为浮点型数据
为什么小数被称为浮点型?
这是因为小数点是可以浮动的:
例如:3.14 ,我可以用0.314*10^1 来表示,也可以用31.4*10^-1来表示,小数点可以在各个位置浮动所以小数在C语言中被称为浮点数。
在C语言中数据类型也被分为两大类,分别是:内置类型、自定义类型。
内置类型:就是刚才讲过的字符类型、整型和浮点型,这些C语言本身就具有的类型被称为内置类型。
自定义类型:顾名思义就是自己定义的类型,例如数组、结构体-struct、枚举-enum和联合体-union,这些自定义类型可能是一些内置类型组成的。(这些自定义类型会在后期C语言笔记中介绍)

本篇主要探讨内置数据类型,自定义类型后期笔记会讲解。
1.1 字符类型
字符类型被分为三类:
cpp
char
[signed] char
unsigned char1.2 整型
cpp
//短整型
short [int]
[signed] short [int]
unsigned short [int]
//整型
int
[signed] int
unsigned int
//长整型
long [int]
[signed] long [int]
unsigned long [int]
//更长的整型
//C99中引入的类型
long long [int]
[signed] long long [int]
unsigned long long [int]1.3 浮点型
cpp
float //单精度浮点数
double //双精度浮点数
long double以上就是关于C语言的所有数据类型的表示,也可以直接理解为数据的类型。
注:signed表示有符号,unsigned表示无符号。以上所有类型旁边" "括号括起来的内容是该类型本身就自带的属性,真正使用这个类型时表面上是看不到的,所以不用太在意。
1.4 布尔类型
cpp
_Bool //布尔类型布尔类型也是C99标准中引入的一种类型。
想要使用布尔类型得包含头文件**#include <stdbool.h>**
注:头文件可不只是可以定义函数的声明,头文件还可以定义那些自定义类型的声明
首先先要了解在C语言中表示真假的方式,比如0表示假,非0表示真。不管是正数还是负数都是非0,都表示真,所以只有0表示假。(后面笔记也会慢慢讲解为什么会有真假的概念及如何使用真假来判断) 但是这种判断表示法是C语言最早期的用来判断的,而在C99标准中引入的_Bool类型专门表示真假,_Bool类型的变量取值是:true真 或者 flase假。
cpp
#define bool _Bool
#define false 0
#define true 1使用_Bool类型代码
cpp
#include <stdbool.h>
#include <stdio.h>
int main()
{
_Bool flag = true; //创建变量
if(flag) //判断
{
printf("hello world\n");
}
return 0;
}当布尔类型的变量flag的值为 true真 时,if判断为真就可以执行括号内的语句,最后就能够成功打印"hello world"; 如果flag = flase;if判断为假,就不会执行括号内的语句了,如果想让这段代码有两条不同判断的路径,看一下代码。
cpp
#include <stdbool.h>
#include <stdio.h>
int main()
{
_Bool flag = true; //创建变量
if(flag) //判断
{
printf("hello world\n");
}
else
{
printf("haha");
}
return 0;
}简单介绍一下这里所使用的就是if语句,也被称为分支语句。
如果if判断后为假,就不执行 if 括号内的语句,程序直接结束。但是如果有一条else情况就不一样了,如果if没通过,就执行else里的语句,如果if判断为真通过了,执行if里的语句,执行完后就不会再去else那里了,总之就是不管真还是假,就只运行一条分支的语句。if判断过了就执行if分支语句,if判断不过就执行else分支语句。
2、signed和unsigned
C语言使用signed 和unsigned 关键字修饰字符型 和整型类型的。
- signed关键字,表示一个类型带有正负号,包含赋值。
- unsigned关键字,表示该类型不带有正负号,只能表示零和正整数。
有时候我可以用signed int有符号整型来表示温度(温度有正负数),用无符号整型来表示身高(身高只有正数)。
注:整型类型本身就是signed有符号整型,比如:int类型,实际上它是signed int,只是signed不在表面显示,如果想创建一个不带负数的类型就可以用unsigned int,unsigned int无符号整型是需要自己加上unsigned关键字修饰的。所以int等价于signed int。
cpp
int main()
{
int temp = 30; //这种的变量类型int本身就是signed int有符号整型
int temp = -30; //所以signed可以省略不加
//int temp 等价于 signed int temp
return 0;
}整型变量声明为unsigned的好处是,同样长度的内存能够表示的最大整数值,增大了一倍。
比如,16位的signed short int 的取值范围是:-32768-32767,最大的值为32767,而unsigned short int的取值范围是:0-65535,最大值增大到了65535,。32位的signed int 的取值范围可以参看limits.h中相关定义。
下
面的定义是VS2022环境中,limits.h中相关定义。
cpp
#define SHRT_MIN (-32768) //有符号16位整型的最小值
#define SHRT_MAX 32767 //有符号16位整型的最大值
#define USHRT_MAX 0xffff //无符号16位整型的最大值
#define INT_MIN (-2147483647 - 1) //有符号整型的最小值
#define INT_MAX 2147483647 //有符号整型的最大值unsigned int 里面的int也是可以省略,所以上面的变量声明也可以写成下面这样。
cpp
unsigned a;如果仔细观察有符号整型和无符号整型的的数值范围是相同的,但是所表示的最小值和最大值是不同的,这是因为有符号整型和无符号整型的符号位不同,有符号整型的符号位只能表示符号,表示正数和负数。而无符号数的符号位可以用来表示更大的2^32数值。如果无符号数和有符号数没有符号位表示的数值的范围是相同的,而加上符号位范围相同但大小值不同是因为有符号数的正数的最大值到0的范围+负数最小值到0的范围 和无符号数从0到达那个最大值范围是相同的。
字符类型char也可以设置signed 和 unsigned。
cpp
signed char c; //范围为-128到127
unsigned char c; //范围为0到2553、数据类型的取值范围
上述的数据类型很多,尤其数整型类型就有short、int、long、long long四种,为什么呢?
其实每一种数据类型都有自己的取值范围,也就是存储数字的最大值和最小值的区间,有了丰富的类型,我们就可以在适当的场景下去选择适合的类型。如果要查看当前系统上不同数据类型多的极限值:
limits.h文件中说明了整型类型的取值范围。
float.h文件中说明浮点型类型的取值范围。
为了代码的可移植性,需要知道某种整数类型的极限值时,应该尽量使用这些常量。
- SCHAR_MIN,SCHAR_MAX:signed char 的最小值和最大值。
- SHRT_MIN,SHRT_MAX: short的最小值和最大值。
- INT_MIN,INT_MAX: int的最小值和最大值。
- LONG_MIN,LONG_MAX: long的最小值和最大值。
- LLONG_MIN,LLONG_MAX:long long 的最小值和最大值。
- UCHAR_MAX: unsigned char的最大值。
- USHRT_MAX: unsigned short的最大值。
- UINT_MAX: unsigned int的最大值。
- ULONG_MAX:unsigned long的最大值。
- ULLONG_MAX:unsigned long long 的最大值。
以上就是每个类型的取值范围,知道了类型的取值范围,那每个类型在内存中所占空间大小是多少,这就要用到一个sizeof ,sizeof是一个操作符而不是库函数,这个操作符就是计算并返回变量或类型的在内存所占大小,单位是字节。
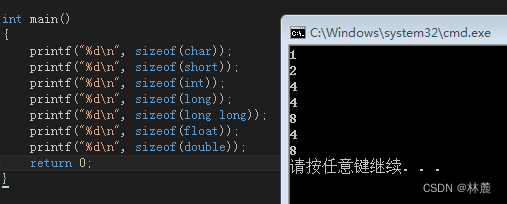
计算机中常见单位:byte(字节) ,bit(比特)
- 1Byte = 8bit
- 1KB = 1024Byte
- 1MB = 1024KB
- 1GB = 1024MB
- 1TB = 1024GB
- 1PB = 1024TB
所以类型的大小是这样:
- char大小为1 byte -> 8 bit
- short大小为2 byte -> 16 bit
- int大小为4 byte -> 32 bit
- long大小为4 byte -> 32 bit
- long long大小为8 byte -> 64 bit
- float大小为4 byte -> 32 bit
- double大小为8 byte -> 64 bit
因为每个类型在内存所占字节大小不同,所以取值范围也会各不相同。每个字节是8个bit位,每个bit位代表一个二进制位,一个二进制位有两种状态,一种是1,一种是0。二进制位越多代表的数值范围就越广。
4、变量
4.1 变量的创建
了解清楚了类型,我们使用类型做什么呢?类型是用来创建变量的。
什么是变量?C语言中经常变化的值称为变量,不变的值称为常量。
比如:身高、体重这些数值就是变量,圆周率这种就是常量。
变量创建语法形式是这样的:
cpp
data_type name;
| |
//数据类型 //变量名比如:
cpp
char str;
int num;
double dub;
//这种前面是类型后面是变量名就称为变量如果在创建变量的同时给变量一个初识值,就称为变量初始化,例如:
cpp
char str = 'a'; //初始化
int num = 100;
double dub = 3.14;先创建一个变量,后面再给变量一个值的过程叫做个变量赋值(变量名可以简称为变量)。
cpp
int a;
a = 100;//赋值如果double类型的值初始化给float类型变量是会报错,这个值可能发生截断。如果想让这个值成功初始化给这个float类型的变量就在这个值的后面加上一个f,例如:
cpp
float scort = 98.51; //会报错,数据可能会发生截断
float scort = 98.51f; //这样才能将double类型的值存入float类型变量中4.2 变量的分类
- **全局变量:**在大括号外部创建的变量就是全局变量
全局变量的使用范围更广,整个工程中想使用,都是有办法的,所以安全性不高
- **局部变量:**在大括号内部创建的变量就是局部变量
局部变量的使用范围是比较局限,只能在自己所在局部范围内使用
cpp
#incude <stdio.h>
int a = 10; //全局变量
int main()
{
int a = 20; //局部变量
printf("%d\n",a); //打印结果是多少
return 0;
}看上面的代码,打印的结果是10还是20?答案是:20。为什么?
上面两个变量名相同的变量a,除了名称相同,所开辟空间和地址都是各不相同的。
注:全局变量和局部变量名称如果一样的话局部变量优先,但是不建议起一样的变量名,以免造成混乱。
cpp
int main()
{
int a = 0;
{
int b = 10;
printf("%d\n",b); //打印:10
}
printf("%d\n",b);//会报错
return 0;
}因为变量b是在大括号内部创建的,所以局部范围暂时可以使用变量b,但是出了大括号变量b的空间就销毁(返还给操作系统)了,再去调用就会报错,所以局部变量只能在局部范围使用。
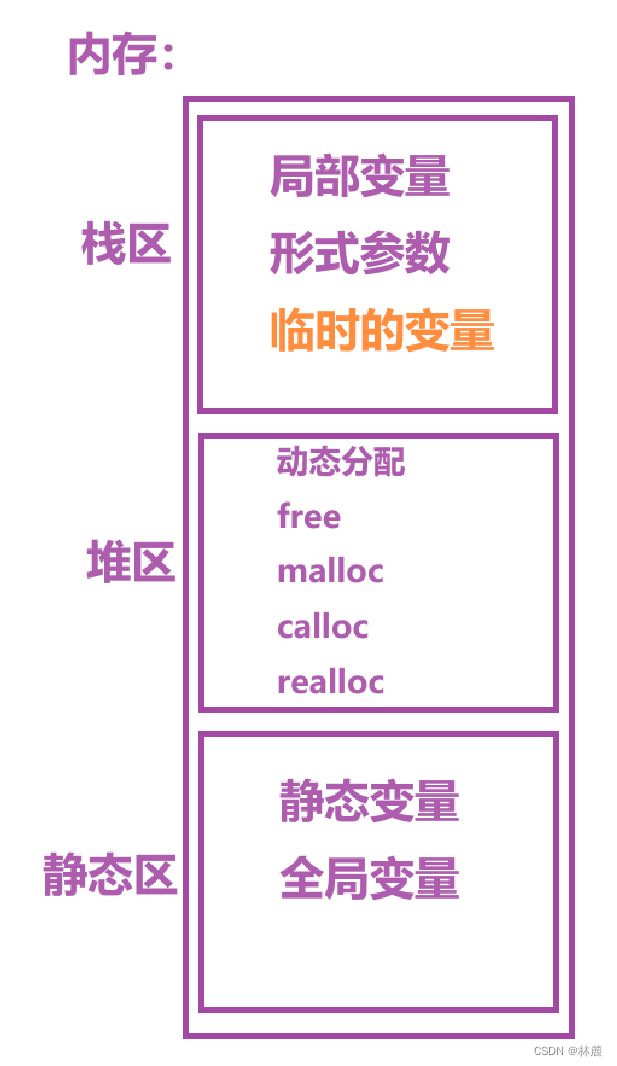
全局变量和局部变量在内存中存储在哪里呢?
一般我们在学习C/C++语言的时候我们会关注内存中的三个区域:栈区、堆区、静态区
- 局部变量是放在内存的栈区
- 全局变量是放在内存的静态区
- 堆区是用来动态内存管理的(malloc、calloc、realloc后期会介绍)
5、算术操作符:+、-、*、/、%
在写代码的时候,一定会涉及到计算。
C语言为了方便运算,提供了一系列操作符,其中一组操作符叫:算术操作符。分别是:+、-、*、/、%,并且都是双目操作符。
双目操作符就是两端拥有两个操作数,可以进行运算就叫做双目操作符。
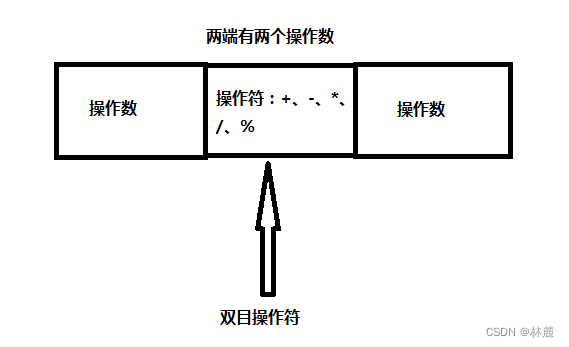
注:操作符也被叫做:运算符,是不同的翻译,意思是一样的。
5.1 + 和 -
+和-用来完成加法和减法的运算
cpp
#include <stdio.h>
int main()
{
int x = 10+20;
int y = 20-10;
printf("%d\n",x);
printf("%d\n",y);
return 0;
}5.2 * 和 /
/操作符两端其中至少要有一个操作数是小数,结果也就为小数。比如printf("%lf",3/2);结果为1,如果想让它的打印出小数,就要printf("%lf\n",3/2.0);一端操作数为小数结果就可以是小数。
cpp
#include <stdio.h>
int main()
{
int a = 2*10;
double b = 7/2.0;
printf("%d\n",a); 结果20
printf("%d\n",7/2);结果为3
printf("%lf\n",b); 结果3.5
return 0;
}5.3 %操作符
%符是取模的意思,取的是两个数相除后的余数,比如printf("%d\n",30%7);因为30整除7商4余2,取余数,结果就是2。也就是两个数的余数。需要注意的是,%操作符两端的操作数必须都是整数
cpp
#include <stdio.h>
int main()
{
int a = 30%7;
printf("%d\n",a); //结果为2
return 0;
}负数取模的规则是,结果的正负号有第一个运算数的正负号决定。
cpp
#include <stdio.h>
int main()
{
printf("%d\n",11%-5); //1
printf("%d\n",-11%-5); //-1
printf("%d\n",-11%5); //-1
return 0;
}上面示例中,第一个运算数(11或-11)决定结果是正数还是负数
6、赋值操作符:=和复合赋值
在变量创建时给变量了一个初始值叫做初始化,而赋值是在创建好变量后,再给变量了一个值,这叫赋值。
cpp
int a = 100;//初始化
a = 200;//赋值赋值操作符=是随时可以给变量赋值的操作符。
6.1 连续赋值
赋值操作符也可以连续赋值:
cpp
int a = 10;
int b = 20;
int c = 30;
c = a = b+20;//连续赋值,从右向左依次赋值C语言虽然支持连续赋值,但是写出的代码不好观察,建议是还是拆开来写,这样方便代码观察细节,例如:
cpp
#include <stdio.h>
int main()
{
int a = 10;
int b = 20;
int c = 30;
a = b+20;
c = a;
return 0;
}这样写在代码调试时方便我们观察。
6.3 复合赋值
一般变量可以通过自加或自减来进行运算,例如:
cpp
int main()
{
int a = 10;
a = a+10; //自加
a = a-10; //自减
return 0;
}但是我们还可以用更简单方便的方式让变量自加或自减,就是复合赋值:
cpp
int main()
{
int a = 10;
a += 10; //复合赋值自加
a -= 10; //复合赋值自减
return 0;
}这样来看你们觉得a=a+10;和a+=10哪个更方便?当然复合操作符不止+=、-=这两种。例如:
cpp
+= -=
*= /= %=
>>= <<=
&= |= ^=7、单目操作符
前面介绍了双目操作符,有两个操作数。现在介绍单目操作符,也就是只有一个操作数的操作符。
单目操作符都有:++、--、+(正)、-(负),这些操作符都有什么作用呢?
7.1++和--
++是一种自增操作符,而--是一种自减操作符,这两种操作符也分为前置和后置
前置++,就是先自增后使用,例如:
cpp
#include <stdio.h>
int main()
{
int a = 10;
int b = ++a;
printf("%d %d\n",a,b);//结果11 11
return 0;
}给b赋值++a时由于是前置++所以先自增为11后再将11赋值给b,b为11,那a为什么也是11呢?这就要说到这种自增或自减的操作符,也有副作用,就是将一个变量++或--后,变量本身的值也是会随着++或--而改变,++不单单只有通过赋值改变变量,也可以通过自增++和自减--操作符改变++。
后置++,如果给一个变量赋值另一个变量的后置++,就记住先使用,后++:
cpp
#include <stdio.h>
int main()
{
int a = 10;
int b = a++;
printf("%d %d\n",a,b); //结果11 10
return 0;
}可以看到,当给变量b赋值变量a++时,是先将a此时的值赋值给b,b为10,a再自增,最后a为11,b为10。
到了这里相信大家就能看懂什么是自增,还有前置和后置的区别了,前置自减和后置自减跟自增基本上都是同等道理。
7.2 +和-
这里的+和-不是上面的双目操作符,而是用来表示正负数的,也被称为单目操作符。
cpp
int main()
{
int a = +10; //单目操作符
int b = -20;
}8、强制类型转换
什么是强制类型转换?用处是什么?
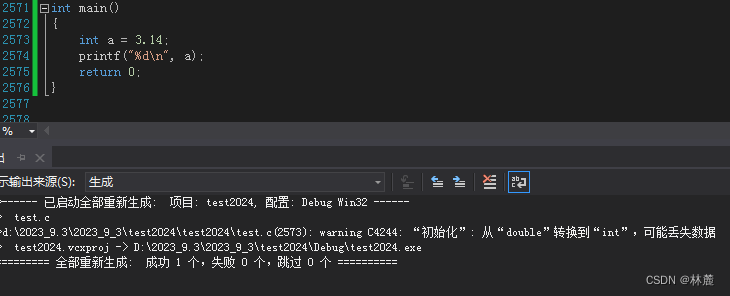
看上图,我创建了一个变量a并给它一个初始值3.14,可是系统会认为该数值为double类型的数据,存入int类型变量中会报错,但是你就想给这个3.14存入变量a当中,就可以用强制类型转换,将3.14强转成int就可以存入变量a中,系统也不会报错了。
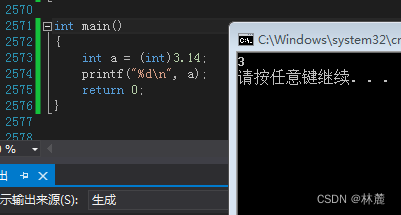
(类型)这种括号括起来的就叫做强制类型转换,如上图,将3.14强转为int后就是3。
俗话说,强扭的瓜不甜。不在必要使用强制转换的时候能不使用就不使用。
9、scanf 和 printf
printf就是将一个值转换成文本格式输出到设备上(打印到屏幕)简称输出函数,与之相对应的就是输入函数scanf ,scanf 也属于库函数所包含头文件和printf一样都是**#include <stdio.h>。**
scanf的功能简介:
scanf的功能与printf相反,printf是将值转换成文本格式打印那scanf就是将用户输入到设备(屏幕)上的文本字符串以对应的类型的格式转换成那个类型通过参数的地址找到变量并将转换后的值存放在变量所开辟的空间。
9.1 printf
cpp
printf("hello world\n");代码中使用了printf函数,可以在屏幕上进行打印。
printf分为print(打印)和format(格式),所以printf是按照格式打印数据。
这里简单的来介绍一下printf函数,printf是一个库函数 ,对应的头文件是**#include<stdio.h>**,它的功能是在标准输出设备(一般指屏幕)上进行信息打印。上面使用printf函数打印了一串字符串。只要想打印一串字符就将它放进双引号内并传递给printf函数,printf函数可以将这串字符串打印到屏幕上
注:每个库函数的定义都是在库文件上实现的。
printf函数也可以用来打印其他类型
cpp
int a = 10;
printf("%d\n",a); //打印整形
printf("%c\n",'z'); //打印字符
printf("%lf\n",3.14); //打印浮点型上面代码中的%d、%c、%lf 是占位符,想要printf在屏幕上打印不同类型的值,就需要对应的占位符。例如:%d是以整形的形式进行打印,%c是以字符的形式进行打印,%lf是以浮点(小数点)的形式进行打印。可以理解为给后面的值占个位值,后面的值可以替换它。(占位符后面会记)
9.1.1 基本用法
printf库函数的作用就是将参数文本输出到屏幕。它名字里的f表示format(格式化),表示可以定制输出文本的格式。(这个格式是由占位符决定的,占位符就是将对应类型的值转换成对应的文本格式,让这个值以文本的形式输出到屏幕上):
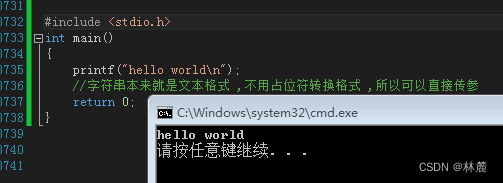
上面这段代码运行时在屏幕上输出了"hello world",'\n'为转义字符,当程序遇到'\n'时会将光标移动到下一行,下一次再打印信息就会在光标所处的位置进行打印,所以'\n'就是换行符。
注意printf打印完后不会自动换行,所以想要换行需要手动添加'\n'将它放在要换行的位置如上图代码,'\n'可以放在任意想要换行的位置,例如:

printf库函数是在标准库的头文件stdio.h定义的。使用这个函数之前,必须在源码文件头部引入这个头文件,标准库头文件是存放库函数声明的文件,通过函数声明可以在库文件中找到函数的定义。
9.1.2 占位符
占位符是输入输出函数所使用的,可以处理对应类型的值并将其转换成文本格式输出到屏幕上:

简单理解就是替后面的值占个位置,然后被后面的值也被称为代入值替换,替换成什么格式就由占位符对应的什么类型决定,例如:

创建一个整型变量a,在printf函数两次输出后的结果不同,可以发现原因是占位符不同,所以打印的文本格式就不同,比如a就是76,%d是以整型的形式进行打印,然后程序就直接取出76转换成对应%d类型格式的文本,最后整数76被程序转换为' 7 '和' 6 '替换占位符%d,最后传输给printf函数进行打印,结果就是76,所以我才说打印的值都是文本也就是字符串。
程序将76转换为%c的格式为' L '是因为%c是以字符形式进行打印,程序看%c对应的值是76,就会自动将它识别为ASCII码值将对应的字符取出来将占位符替换掉,所以ASCII码值76就是字符' L '。
所以占位符就是告诉程序要让后面的值转换成占位符对应的格式替换掉占位符,占位符传达信息,程序来执行这些操作,所以我们敲得每一行代码都叫做计算机指令(也叫做程序)。
输出对应类型的值时一定要使用对应的占位符,比如我想输出整数,那占位符就要是%d。%d也只能处理整型的值,所以占位符一定要用对。
占位符前面的首字符一定是' % ',后面的字符就表示占位符所对应的替换文本。
常用的占位符出了%d还有%s,字符串替换文本:

输出的文本中也可以有多个占位符:

占位符在文本中的顺序对应的就是代入值的所在顺序,占位符的个数与代入值的个数也是一 一对应的。
9.1.3 占位符列举
printf函数我们最常使用的占位符:
%c 字符格式输出
%d 整型格式输出
%ld 长整型格式输出
%f 单精度浮点型格式输出
%lf 双精度浮点型格式输出
%s 字符串格式输出
%x 十六进制格式输出
%o 八进制格式输出
9.1.4 输出格式
限定宽度
printf()允许限定占位符的最小宽度。

可以看出直接打印和限定占位符最小宽度后打印的结果有什么区别。%5d的意思是我要打印5位代入值,后面的代入值替换占位符打印时只能打印5个字符宽度,如果代入值不满这所分配的宽度,就会拿空格来填充,输出的值会默认向右对齐, 如果希望输出的值改为左对齐,在输出内容后面添加空格,或者是在占位符的%后面插入一个 - 号,让5变成-5**。**
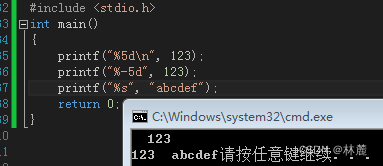
如果所打印的代入值的字符宽度超过限定占位符的最小宽度就会如实打印,限定宽度的占位符并未起到作用:

显示正负号
正整数在打印时是默认为正数,所以不会打印出+号,但是负数前面的-号是必不可少的,有没有什么办法让正数在打印时也可以显示符号,比如:

%+d在%后面加上+好打印正数时可以打印出正数前面的符号,但是用%+d打印负数不会影响到负数,因为负数本身就有符号,所以+对它来说是多余的,不会打印。
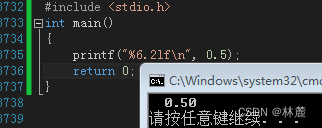
限定小数位
对于小数也是可以加上限定符的,比如:

在C语言中浮点数打印时小数点后面的小数默认为6位,如果不够自动补0,但是如果你打印浮点数只想打印小数点后面的两位就可以用到属于浮点数的限定符,比如%.2lf,.2的意思就是我只想打印小数点后面的两位。
限定宽度占位符和限定小数位占位符可以结合:
最小宽度的小数位这两个限定值可以用*代替,通过printf参数传入
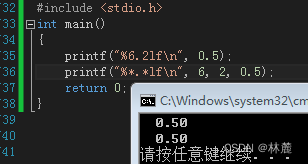
限定字符串输出长度占位符
在%s占位符输出字符串默认是全部输出的,但是也有限定输出长度的占位符,比如%.ms,里面的m就表示输出字符串的限制长度。
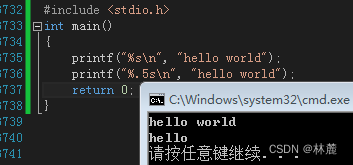
可以看出%.5s是限制输出五个字符。
9.2 scanf
当我们有了变量,我们需要给变量输入值可以使用scanf函数,如果需要将变量的值输出到屏幕上的时候可以使用printf函数,下面看一个例子:

我将一个100以文本的形式输入到屏幕上,scanf将我输入的值以%d的形式转换成整型再通过参数里变量地址找到变量并存入变量,最后再使用printf打印这个变量。
注:如果scanf的参数是变量而不是变量的地址就会报错,&变量名是取变量的地址。
这里插入一个知识点:
cpp#pragma warning(disable:4996)这是一个预处理指令,#pragma warning 就是处理警告指令,disable:4996 是让这个4996这个编号对应的警告失效(每个警报都有编码),所以**#pragma waring(disable:4996)**就是让一个警报失效
9.2.1 基本用法
scanf函数用于读取用户键盘输入
程序运行到这条语句时,会停下来,等待用户从键盘输入。
用户输入数据、按下回车后,scanf()就会处理用户的输入(处理过程前面说过),将其存入变量。
cpp
scanf("%d",&i);它的第一个参数是格式字符串,里面会放置占位符,告诉编译器如何解读用户的输入,需要提取的数据是什么类型。
在C语言中任何数据都是有类型的,你需要通过占位符来告诉编译器要提取什么类型的数据。
scanf也是可以连续输入的。

在输入数据的过程中输入完一个数据必须加上一个空格,表示这是一个数据,然后就可以输入下一个数据。
scanf处理数值占位符时,会自动过滤掉空白字符,包括空格、制表符、换行符。
scanf处理用户输入的原理是,用户的输入先放入缓存,等到按下回车键后,按照占位符对缓存进行解读,如果不想让scanf继续往后解读,按一下ctrl+z就可以停止解读。
scanf的返回值是成功输入变量的个数,如果没有读取任何项,或者匹配失败,则返回0。如果成功读取任何数据之前,发生了读取错误或者遇到读取到文件结尾,则返回常量EOF(end of file),EOF表示-1。
scanf常用占位符如下,与printf的占位符基本一致:
%c: 字符
%d: 整数
%f: float类型浮点数
%lf: double类型浮点数
%Lf: long double类型浮点数
%s: 字符串
% : 在方括号中指定一组匹配的字符(比如%0-9),遇到不在集合指针的字符,匹配将会停止。
注意: 上面所有占位符中,除了%c以外,都会自动忽略起首的空白字符。%c不会忽略空白字符,会将空白字符也返回给变量,如果想让scanf读取%c数据时避免返回空白字符可以在scanf之前加上一个getchar();它可以接收一个字符包括空白字符,或者在%c前面加上一个空格表示跳过零个或多个字符:
cpp
scanf(" %c",&i);还要注意的是%s并不等同于字符串,%s的读取规则是从第一个字符开始读取,遇到空白字符就读取结束,也就是说%s不能打印英文语句,比如:"hello world",只能读取到hello,遇到空白字符就停止读取了。
scanf()将字符串读入字符数组是,是不会检测输入字符串长度是否超出了要存放数组的空间范围,很可能因为输入的字符串超出字符数组所能存储的空间,超出数组边界,导致预想不到的结果,为了防止这种情况,使用%s占位符时,应该指定读入字符串的最长长度,即写成**%ms,**其中m是一个整数,表示读取字符串的最大长度,后面的字符将被丢弃。
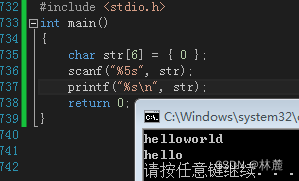
注:不是所有scanf中的变量都需要地取址,如果有些变量本身就是地址或者是指针直接传变量名就可以了,不需要&取地址,例如数组名,因为数组名就是首元素地址。
赋值忽略符
什么是忽略符?忽略符就是每个占位符需要读取的数据中间那个需要省略的符号,有了省略符占位符在读取输入的值时读到省略符就结束,然后省略该符号跳过就该下一个占位符读取值了。
在scanf中默认每个占位符中间以空白字符为读取输入文本的空隔叫忽略符,但是我们可以设置占位符中间的忽略符,比如:
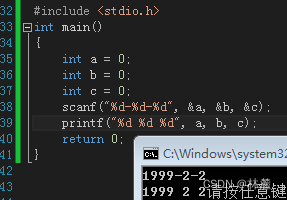
但是这个忽略符设置好,固定就是这样,输入时1999-2-2。但是我们想让\也成为忽略符,比如:1999\2\2怎么办?所以就有了赋值忽略符,比如每个占位符中间加上**%*c**,会接收我想要输入的忽略符

可以看到既可以使用/作为忽略符,也可以用-作为忽略符,%c是表示字符,*表示拿到字符就可以忽略掉,所以**%*c**为赋值忽略符。
第三章:分支和循环
1、C语言的三种结构
C语言是结构化的程序语言,因为C语言支持3种结构:顺序结构 、 选择结构 、 循环结构。生活中也同样是这三种顺序、选择、循环。
举个例子:
**顺序:**我们生活中会制定各种计划,比如今天吃什么,明天去哪儿玩。我们顺序的完成这些计划就是顺序结构。
**选择:**我们有时需要作出一些选择,我要买一件衣服,这种衣服款式好看,那种也不错,我到底是要这种还是那种,需要作出选择就是选择结构。
**循环:**重复循环每天去上学,上课,下课吃饭回宿舍。每天重复这些事情也可以看做循环。
2、if语句
2.1 if
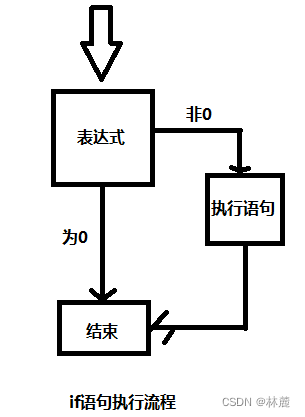
if语句的语法如下:
cpp
if(表达式)//判断表达式结果非0为真,0为假
语句if判断括号内的表达式结果是0为假,非0为真,为假if语句不执行,为真便执行。
下面就给一段代码,来让大家更加清楚地认识到if语句:
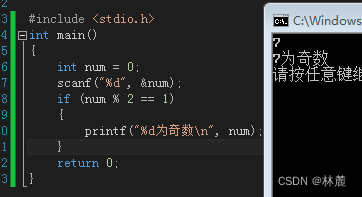
上面代码就是先创建一个变量num,然后使用scanf函数给num输入一个值,下面就继续执行if语句,先判断if语句括号内的表达式,num%2==1意思是如果num这个值:7%2余1,然后判断1==1,判断结果正确返回1,1为真,为真就执行if里面的语句。然后就打印7为奇数。
if语句下面如果只有一条语句可以不扩大括号,比如:

就算if语句不扩大括号,if语句下面的第一条语句也属于if语句的范围,可以理解为绑定。
2.2 else
else语句的语法如下:
cpp
if(表达式)
语句1
else
语句2else语句和if语句是配套的,可以理解为有两条回家的路,如果大路施工就可以走小路,小路堵塞就可以走大路。总要有一种方法能够解决事情。这就是if else语句。if判断为假,就直接执行else语句。if判断为真,就走if语句,结束后就不用走else语句了,这就是else语句的存在,比如下面再给一段代码:

是奇数就走if语句,不是奇数就只有偶数这一种可能了,就走else。

2.3 分支中的多条语句
注:不管是if还是else默认只能控制一条语句,如果一个分支要有多条语句就用大括号括起来。

有时分支不仅仅只有两个,也可能会有有多个分支。
2.4 嵌套if
在if else语句中,else可以与另一个if语句连用,构成多重判断。
比如:要输入一个整数,判断它是正数、负数还是0,就需要用到嵌套if
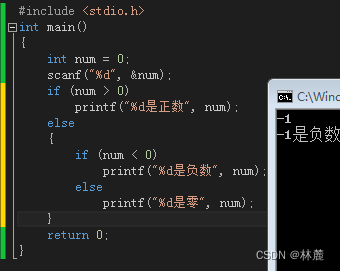
if不通过就走else,然后继续在else里判断剩下的两个分支,但是有没有更简洁的写法呢?当然有,看下面代码。

以上两种嵌套if只是两种书写方式,但是功能和性质还是一模一样的。
将else里嵌套if直接写成else if(表达式)去判断,也可以将else if看作另一个分支的本体,不影响,但需要了解他们之前是嵌套关系。
除了上面的嵌套if,if else语句还可以这样嵌套:
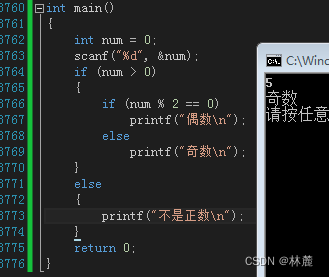
2.5 练习:打印出年龄阶段
例如:输入:22
输出:成年
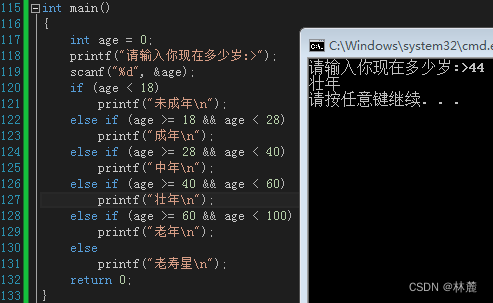
2.6 悬空else问题
来看一下下面这段代码,你们猜它打印"hehe"还是"haha"?

答案是什么都不打印,为什么?首先第一条if语句判断a==1吗?a为0,0 !=1所以为假,为假不是应该走else语句打印"haha"吗?首先,不要看到else 与 if第一条if语句对齐了就以为它们是一对的。else语句规则只与相邻最近的if锁定为一对,因为第一条if语句里的if语句是另一条判断,而且并没有括号括起来来隔绝与外界的联系,所以第二个if和else锁定了,第一个if语句为假,根本就不可能进行下面的判断,所以什么都不打印。

这样看就知道为什么会什么结果都不打印了吧?
如果想要解决这个问题用括号括起来就行:
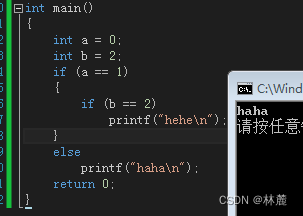
2、关系操作符
C语言用于比较表达式,称为"关系表达式"(relational expression) ,里面使用的运算符称为"关系运算符"(relational operator),主要有下面6个。
- >大于运算符
- <小于运算符
- >=大于等于运算符
- <=小于等于运算符
- ==相等运算符
- !=不等运算符
例子:
cpp
a > b
a < b
a >= b
a <= b
a == b
a != b关系表达式通常返回0或1,表示真假。
C语言中,0表示假,所有非零值表示真。比如,20>12返回1,12>20返回假。
常在if语句 或while循环判断真假的语句中使用。
比如:

a如果小于b返回1,判断为真,就执行if语句。
注:"=="是相等运算符,在生活中,我们使用=来判断这个数等不等于另一个数,但是在C语言中=号为赋值操作符,为了能够分清楚赋值和判断,C语言规定==为判断。
关于关系操作符的使用需要避免的那些错误:
注意,在使用相等运算符==时,建议将常量例如整数3放到前面,将变量放到后面进行判断,3==a;为什么?如果将变量放到a放到前面,常量3放到后面进行比较并不会有什么问题,a==3;但是如果哪一次不小心将相等运算符写成赋值运算符时a=3进行判断,a被赋值成了3,3为真就进入语句,a不仅被赋值为3,关键是这样编译器也不会报错,认为你这就是正常的给变量赋值再进行判断

如果想要解决这个问题就将常量写在前面进行判断,就算不小心将==写成赋值=,也会报错,因为编译器会认为你是在给常量赋值,常量3就是一个整数,怎么能够给整数赋值呢?这不荒唐嘛。

另一个需要避免的错误是:多个关系操作符不宜连用
cpp
a < b < c因为在判断关系表达式时是从左到右进行判断的,比如先判断a是否小于b,为真返回1,为假返回0,最后和c进行判断的要么就是1要么就是0。
cpp
(a < b)< c
比如上面这段代码,是先判断a<b,15<20为真返回1,1和c进行判断,1<18,为真最后返回1打印"hehe"。上面代码中的b并不会和a进行判断后就继续于b进行判断了,而是与a进行判断后返回的1或0再与c进行判断。
但是如果就是想连用让b>a,并且b<c,怎么办?这是就要用到&&或||两个操作符。
cpp
a<b && b<c
那这个操作符是什么呢?又有什么作用?
3、逻辑操作符&&,| |,!
逻辑操作符提供逻辑判断功能,用于构建更复杂的表达式,主要有下面三个操作符。
- !:逻辑反操作符 (改变单个表达式真假)
- &&:与操作符,是并且的意思 (两侧表达式都为真则返回1,一侧为假就返回0)
- | |:或操作符,是或者的意思 (只要有一侧表达式为真就返回1,两侧表达式都为假才返回0)
3.1 逻辑取反操作符!
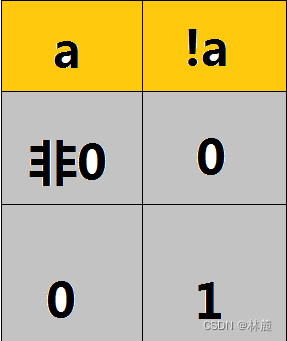
什么是逻辑取反操作符?可以参照以上示图,当a返回非0为真时,!a就取反0为假。当a返回0为假时,!a就取反1为真,这就是!逻辑取反操作符的功能介绍。
来两段代码来让我们更加清楚直观的了解逻辑取反操作符:


可以看到a为非0,a进行if语句判断和!a进行判断的结果不同,这就是!逻辑取反操作符,当a为非0时!a就为0,当a为0时!a就为1。
3.2 与操作符&&
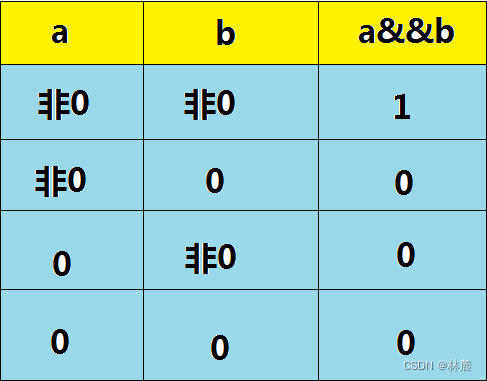
看上图当两个变量或表达式返回的值都为非0,&&就会返回1,但是只要有一个为0那&&后就返回0,全都是0的话就更不用说了。举个简单的例子:比如有一个老师要叫两个比较strong的学生来搬桌子 ,说张三与李四一起过来搬,这张桌子就能搬得动。如果只有李四来了,李四说这个桌子太沉搬不了,如果都不来桌子还是没人能搬。
给一段代码来了解一下&&:

可以看到给month输入3、4、5都可以通过month>=3&&month<=5,因为它们都符合这两个表达式的条件,所以返回值都为1,就通过。给month输入6就不行了,虽然可以通过month>=3这个关系表达式,返回一个1,但是并不能通过month<=5,所以返回0,&&操作符的判断条件就是两边表达式必须都为1,否则就返回0,不通过就执行else语句。
3.3 或操作符| |

| |与操作符两边只要有一个是非0就返回1,除非两个都是0就返回0。举个例子:又是一张桌子,这次的桌子一个人就可以搬得动,老师说张三或者李四来搬一下桌子,一个人就可以搬。如果两个都来了也可以搬,如果两个人都不来那就没法搬。
像上面的代码可以用&&来固定一个数的范围,这个数只要在这个范围就可以执行,比如a>=1&&a<=100,只要是1-100之间的数都可以通过,那如果我想表示冬季的月份呢?12月、1月、2月,就不能用范围来判断了,怎么办?这时就可以用到与操作符。

只要是12、1、2这三个数的一个就可以通过,3不属于规定的这三个数,执行else。或操作符只要有一个为真就返回1,都为0才返回0。
3.4 练习:闰年的判断
输入一个年份year,判断year是否是闰年
闰年的判断规则:
- 能被4整除并且不能被100整除是闰年
- 能被400整除是闰年

代码解析:如果第一个判断(year%4==0&&year%100 !=0)不通过返回0, 0 | |(year%400==0),就判断第二个,如果都没通过那当前输入的整数就不是闰年。
3.5 短路
C语言逻辑运算符还有一个特点,它总是先对左侧的表达式求值,再对右边的表达式求值,这个顺序是保证的。如果左边的表达式满足逻辑运算符的条件,就不再对右边的表达式求值。这种情况称为 "短路"。
比如前面的代码:
cpp
if(month>=3 && month<=5)如果因为是先从左边表达式开始运行的,先判断左边表达式,如果左边表达式为真,就继续判断右边的表达式。如果左边表达式为假就不会再继续判断有边的表达式了,因为如果有一个表达式为0就返回0,因为左边表达式已经是0了,所以计算机就会偷个懒不再判断右边的表达式,这就被称之为短路。
那对于| |运算符是怎么样的呢?结合前面的代码:
cpp
if(month==12 || month==1 || month==2)判断month==12为假就继续向后执行判断,如果为真就不会继续向右判断。
对于| |操作符来说左操作数为真时,右操作数也就不会执行了。
对于这种仅仅根据左操作数的结果就能知道整个表达式的结果,不在对右操作符进行计算的运算符称为短路求值。
4、switch语句
除了if语句外,C语言还提供了一种分支语句叫做switch。这个语句的拼写给人的第一印象就是任天堂的Switch。

,所以要想记住这个语句并不难,只需要记住任天堂Switch拼写和这个语句是一模一样的就可以了。
switch是一种特殊的if ..else结构,用于判断条件有多个结果的情况。它把多重else if改成更易用、可读性更好的形式。
cpp
switch(expression){
case value1: statement
case value2: statement
default: statement
}- switch后的expression必须是整型表达式
- case后的值必须是整形常量表达式
4.1 switch
switch 中文被称为转换,就是通过变量或表达式的值来转换成对应的分支,例如:
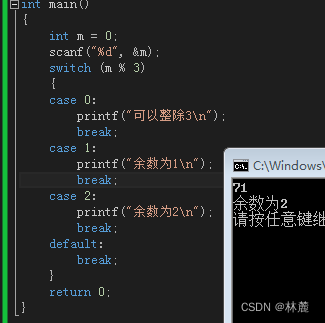
这就是分支转换,就是根据switch括号里变量或表达式求得的值转换到对应路径,并执行。如果括号里最后的值为0,进去就走case 0:分支,如果为1就走case 1:分支,像上面代码中的m%3,77%3的余数为2,进去就直接走case 2:分支,并执行了这条路径的语句,如果找不到对应的分支就执行default分支。
简单理解就是你给switch的值是多少,switch便会转换成你所给的值对应的那个入口。就好比如,你有一张门票2,你给了检票员switch,switch就会给你开放区域2的大门,你就可以进入区域2,如果你的门票数字没有这里对应的区域,就会进入default,就当做出口吧。
4.2 switch中的break
以上所使用的break 是永久退出关键字,适用于分支语句和循环语句,为什么每个分支下都要使用一个break来退出呢?这是因为当switch的一条分支执行结束后并不会自动退出当前switch所属区域,而是自动的向下继续执行其他分支,所以开头对应的值找到对应的分支只是让程序找到这个分支的入口,前面的几个分支程序路过了但是不是对应分支所以没有执行,直到找到这个分支的入口,就执行里面的语句,执行完后可以顺着下面的分支继续执行。由此可见switch的分支是和if else分支是有差异的。
解决方法:为了避免以上的情况请在使用switch分支时让每一条分支结尾都是用break永久退出来跳出switch语句。

4.3 练习:打印对应日期
输入一个1-7的数字,打印出对应的星期几

如果编程题目需求发生改变例如:
- 输入:1-5 输入:6-7
- 输出:工作日 输出:休息日
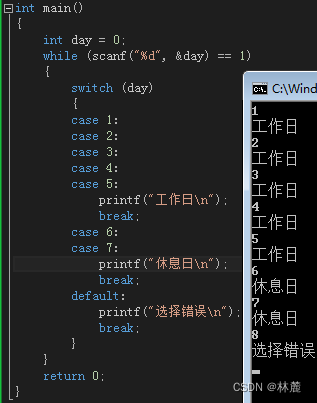
代码解析:这段代码就是利用switch执行完一个分支会继续执行下一个分支这种特性,来达成编程题目的要求。
4.4 switch中的default
在使用switch语句时我们会遇到一种情况,就是传进去的值没有能够与之对应的switch中的case 语句,如果遇到以上情况要么就不处理,直接跳过switch语句,要么就在switch语句最后加上default是子句,上面的代码基本上都用到了default语句。
注:case语句和default语句的顺序规则,default并不一定就只能在最后定义,可以在开头定义,也可以在中间定义。只不过加在最后让代码有更加好的阅读性。
5、while循环
C语言提供了三种循环分别是:while 、for 和do while,接下来介绍一下while循环。
5.1 if 和while的对比
首先来看一下while循环和if语句的对比:
cpp
if(表达式)
语句;
while(表达式)
语句;可以看到while类似if语句,因为while也需要进行判断,但是它们的区别在于if语句判断后只执行一次,while判断后就可以循环多次。
注:while循环每次执行结束就需要再进行一次判断,为真则继续执行。
5.2 while的执行流程
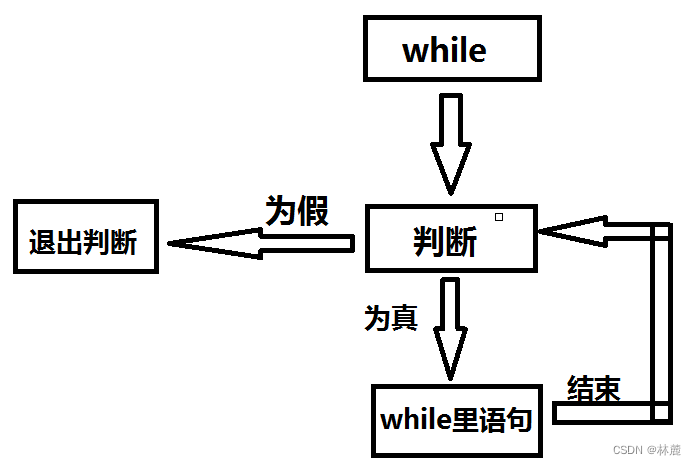
但是while可能会受到break或continue的影响,break可以永久退出,如果遇到break是会直接跳出循环。
5.3 while循环的实践
练习:在屏幕上打印1-10的值

注意:需要一个随时变化的循环变量,比如上面的变量i,就是while的循环变量,如果i<=10(等价于i<11)就循环,但是也不能一直循环,所以在while语句里需要 i 不停的变化,每循环一次i 就+1,直到大于10循环结束。
5.4 练习:打印值的每一位
将一个数值里的每一位进行打印
例如:
输入:1234,输出:4 3 2 1
输入:521,输出:1 2 5


代码解析:以 val 作为判断条件,每循环一次取出val当前数值的个位进行打印并除以10,直到 / 成0,循环结束。
6、for循环
for循环是三个循环中最常使用的一种循环。
6.1 语法形式
cpp
for(表达式1;表达式2;表达式3)
语句;
- 表达式1 用于循环变量的初始化
- 表达式2 用于循环结束条件判断
- 表达式3用于循环变量的调整
6.2 for循环的执行流程
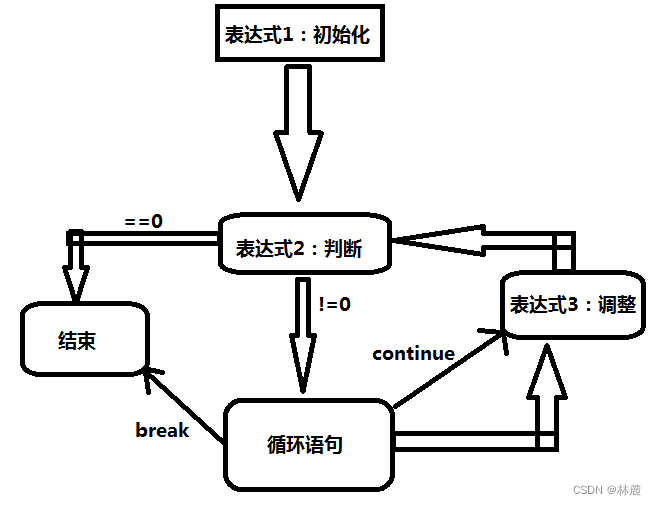
首先执行表达式1,负责给循环变量进行初始化,紧接着执行表达式2用循环变量进行判断,如果==0就直接结束,如果!=0则继续执行里面的循环语句,执行完语句就执行表达式3调整循环变量,然后再判断,==0结束,!=0则继续执行,循环往复,直到判断为==0时则结束循环。也可以中途利用break来跳出循环。
整个循环过程中,表达式1初始化只被执行一次,表达式2和表达式3跟着循环而执行。
6.3 for循环的实践
练习:在屏幕上打印1-10的值

6.4 while循环和for循环的对比


for和while都是拥有初始化、判断、调整这三个部分,可以看出for循环是将三个表达式集成一体的循环,便于代码维护,而如果代码较多的时候while循环的三个部分就比较分散,所以从形式上for循环要更优一些。
6.5 练习
练习:计算1-100之间3的倍数的数字之和

7、do-while循环
7.1 语法形式
在循环语句中do while语句使用的最少,它的语法如下:
cpp
do{
语句;
}while(表达式)while和for是先判断后循环,而do while是先进入循环体,语句执行结束后再判断,这也是do while语句的特点。
7.2 do while循环流程
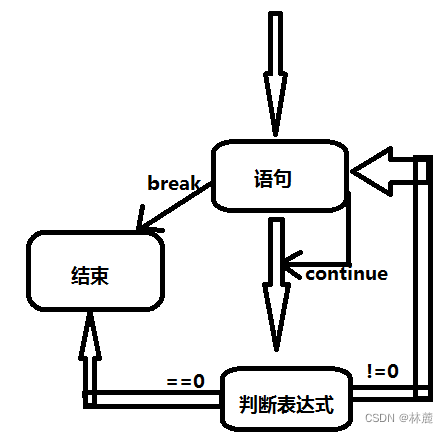
进入do while首先执行语句,执行完后进行判断,==0结束循环,!=0则继续执行下一次语句,中途如果遇到break也可以直接结束循环。
do while循环体至少是要执行一次的,因为是先执行后判断,这是do while比较特殊的地方。
7.3 练习
输入一个正整数,计算这个整数是几位数?
例如:
输入:1234 输出:4
输入:12 输出:2
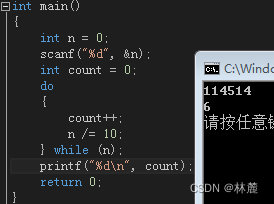
这里并不一定非要使用do while,只是如果输入的值为0,0也是一位数,但是判断时不能通过,所以这种情况可以使用do while,因为是先执行后判断,所以至少循环一次。
8、break和continue语句
在循环执行的过程中,如果某些状况发生时需要提前终止循环,这是非常常见的现象。C语言中提供了break和continue两个关键字,就是应用到循环中的。
- break的作用是永久的终止循环,只要break被执行,就会直接跳出循环。
- continue的作用是跳过本次循环后面的代码,在for循环和while循环中是有差异的。
8.1 break

可以看到当i判断是否等于5为真时,就终止了循环,只打印了1-4的数值。
8.2 continue

当i==5是执行continue,continue就跳过本次循环后面的代码,所以除了5其他数值都打印了。
9、循环的嵌套
前面学习了三种循环:while、for、do while,有时候这三种循环嵌套在一起才能更好的解决问题,就是我们所说的:循环嵌套,这里我们就看一个例子。
9.1 练习1: 找出100-200之间的素数
找出100-200之间的素数
注:素数又被称之为质数,只能被1和本身整除的数字

以上代码用到了一个新的库函数叫做sqrt开平放,听名字就知道是数学函数所以所包含头文件就是**#include <math.h>**,比如:sqrt(36)就是求出36的开平方6并返回
以上代码所使用的就是循环嵌套。
9.2 练习2:打印乘法口诀表
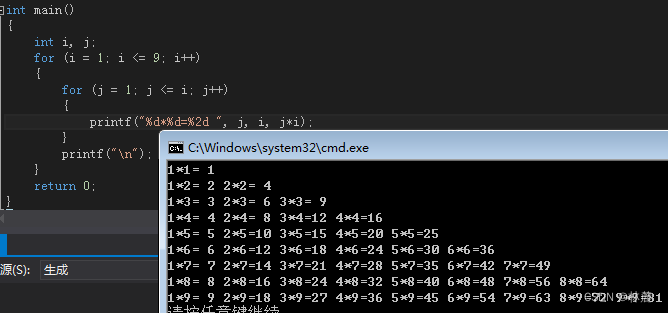
10、goto语句
C语言提供了一种非常特别的语法,即使goto语句和跳转标号,goto语句可以实现同一个函数内跳转到设置好的标号处。
goto的用法:

因为break终止循环仅限于当前循环,当遇到嵌套循环时没有办法一次性跳出所有循环,黄色闪光波风goto说:"这些对我来说都是小case(小问题)。"直接扔出一个飞雷神(again标号),一下子就瞬移到了循环外面。

讲到这里相信大家对goto语句也有了清晰的认知
11、猜数字游戏
写一个猜数字游戏
游戏要求:
- 电脑自动生成1-100之间的随机数
- 玩家猜数字,猜数字的过程中,根据猜测数据的大小给出大了还是小了的反馈,直到猜对,游戏结束
11.1 随机数生成
要想完成猜数字游戏就,首先得产生随机数,那怎么产生随机数呢?
11.1.1 rand
C语言提供了一个函数叫rand,这函数是可以生成随机数的,函数原型如下所示:
cpp
int rand(void);rand函数会返回一个伪随机数,这个随机数的范围是0-RAND_MAX之间,这个RAND_MAX的大小是依赖编译器上实现的,大部分编译器上的是32767。
rand函数的使用需要包含一个头文件是:stdlib.h
那我们就测试一下rand函数,这里多调用几次,产生5个随机数:
cpp
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("%d\n", rand());
printf("%d\n", rand());
printf("%d\n", rand());
printf("%d\n", rand());
printf("%d\n", rand());
return 0;
}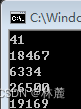

我们可以看到虽然一次运行中产生的5个数字是相对随机的,但是下一次运行程序生成的结果和上一次一模一样,这就说明有点问题。
其实rand生成的随机数是伪随机数,伪随机数并不是真正的随机数,是通过某种算法生成的随机数。真正的随机数是无法预测下一个值是多少的。而rand是对一个叫"种子"的基准值进行运算生成的随机数。
之所以前面每次运行的程序产生的随机数序列是一样的,那是因为rand函数生成的随机数的默认种子是1。如果要生成不同的随机数,就要让种子是变化的。
11.1.2 srand
C语言又提供了一个函数叫srand,用来初始化随机数的生成器(种子)的,srand的原型如下:
cpp
void srand(unsigned int seed);程序在调用rand函数之前先调用srand函数,通过srand函数的参数seed来设置rand函数生成随机数时的种子(因为srand就是对一个默认种子1进行运算生成随机数的,如果要生成不同的随机数,就要让种子是变化的,而srand函数就是用来设置种子的,所以当使用srand改变种子(基准值)后,rand才能生成真正意义上的随机数)。只要种子在变化,每次生成的随机数序列也就在变化。
那也就是说给srand的种子如果是随机的,rand就能生成随机数;在生成随机数的时候有需要一个随机数,这就矛盾了。
不一定非要给srand一个随机数才能让rand生成随机数,给srand一个随时变化的值也可以使rand生成随机数。
11.1.3 time
在程序中我们一般使用程序运行的时间作为种子的,因为时间在时刻的发生变化。
在C语言中有一个函数叫time,就可以获得这个时间,需要的包含为#include <time.h>,time函数原型如下:
cpp
time_t time(time_t* timer);time函数的返回值是计算机的起始时间1970年1月1日0分0秒与程序此时运行的时间之间的差值,单位是秒,这个差值迄今为止已经有17亿这么庞大的数值,而且这个差值是每一秒都在变化的,所以这个差值也被称为时间戳。返回的类型是time_t类型的,time_t类型本质上其实就是32位或者64位的整型类型。
time函数的参数:
time函数的参数timer如果是非NULL指针的话,函数也会将这个返回的差值放在指向的内存中带回去。如果timer是NULL,就只返回这个时间的差值。
cpp
time(NULL);知道了上面的srand可以修改种子,但是又需要一个随时变化的数。time函数刚好就是返回时间差,我们可以将time函数返回的值作为参数传给srand修改种子(基准值)。
cpp
srand((unsigned int)time(NULL));这样成功修改了种子后,使用rand生成的随机数序列也就是真正的随机数了。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main()
{
srand((unsigned int)time(NULL));
printf("%d\n", rand());
printf("%d\n", rand());
printf("%d\n", rand());
printf("%d\n", rand());
printf("%d\n", rand());
return 0;
}
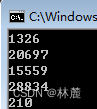
可以看到两次运行的rand随机数序列各不相同,就是因为种子是变化的,生成的随机数也在变化。
11.1.4 设置随机数的范围
如果我们要生成0-99之间的随机数,方法如下:
cpp
rand()%100;//因为rand当前生成的随机数%100的余数就是0-99之间如果想要生成1-100之间的随机数,方法如下:
cpp
rand()%100+1;//如果rand%100余0加1就是1,如果%100余99加1就是100如果想要生成100-200之间的随机数,方法如下:
cpp
100+rand()%(200-100+1);按理说200-100+1直接写成100+1不是更好吗?为什么要写成200-100+1呢?因为这可以看作一个公式,如果想要求数值a到数值b之间的范围就可以使用这个公式。
cpp
a+rand()%(b-a+1);
100+rand()%(1000-100+1); //1-1000范围内的随机数11.2 猜数字游戏的实现
cpp
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void menu()
{
printf("******************\n");
printf("***** 1.play *****\n");
printf("***** 0.exit *****\n");
printf("******************\n");
}
void game()
{
//1.生成随机数
int randata = rand() % 100 + 1;
int data = 0;
//2.猜数字
while (1)//死循环
{
printf("请猜数字:>");
scanf("%d", &data);
if (data < randata){
printf("猜小了\n");
}
else if (data > randata){
printf("猜大了\n");
}
else{
printf("恭喜你,猜对了\n");
break;
}
}
}
int main()
{
srand((unsigned int)time(NULL));
int input = 0;
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
game();
break;
case 0:
printf("退出游戏\n");
break;
default:
printf("选择错误,请重新选择\n");
break;
}
} while (input);
return 0;
}运行结果:

第四章:数组
1、数组的概念
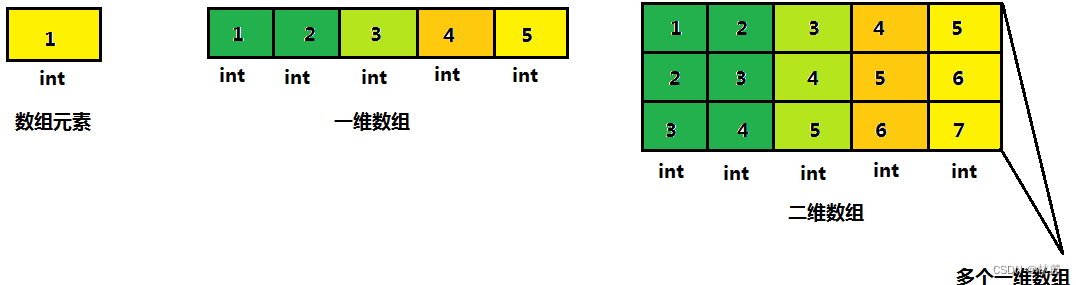
数组是一组相同类型元素的集合;从中我们可以得知两点:
- 数组中存放着1个或者多个数据,但是数组元素个数不能为0。
- 数组存放这多个数据,类型是相同的。
数组分为一维数组和多维数组,多维数组中最常使用的就是二维数组。
2、一维数组的创建和初始化
2.1 数组创建
一维数组创建的基本语法如下:
cpp
type arr_name[常量值];存放在数组的值被称为数组的元素 ,数组在创建的时候可以指定数组的大小 和数组的元素类型。
- type表示数组中存放数据的类型,可以是char、short、int、double等...
- arr_name表示数组名
- 中的常量值是用来指定数组的大小的,这个数组的大小是根据实际需求指定就行
cpp
int arr;//整型类型变量
int arr[10];//整型类型数组比如:我们现在想存储某个班级20个同学的数学成绩,我们就可以创建一个数组,如下:
cpp
int math[20];当然我们也可以根据需要创建其他类型和大小的数组:
cpp
char ch[8];
double score[10];2.2 数组初始化
有时候,数组在创建的时候我们要给数组一个初始值,这就称为数组的初始化。
那数组是如何初始化的呢?数组的初始化一般使用大括号,将数据放在大括号中。
cpp
//完全初始化
int arr[5] = {1,2,3,4,5};
//不完全初始化
int arr[5] = {1,2,3};//剩余的元素默认初始化为0
//错误的初始化
int arr[3] = {1,2,3,4};//初始化元素个数大于所分配空间个数注意还有一种初始化,也是最为常用的初始化方式,如下:
cpp
int arr[] = {1,2,3,4,5};
//数组的大小,是编译器根据初始化的内容(元素个数)确定的。这种初始化方式的空间是系统自动开辟的,不需要我们手动输入来让数组开辟空间,不需要在
内填写任何值来开辟空间大小,编译器可以根据你初始化有几个元素自动开辟对应的空间大小来存放你给的初始值。但是这种方式仅限于初始化,如果只是想先创建一个数组,不给它初始值,就需要在 内填写常量,来表示你要给这个数组开辟多少元素的空间,后期才可以使用此数组。
重点:在刚创建一个数组不给初始值时,要给数组手动输入需要开辟元素的空间个数。如果只是创建数组不给初始值也不在 内输入要开辟的元素个数,那这个数组基本上就不能为我么使用,解引用赋值不能再赋值,并且数组名不是指针,只是一个地址,也不能直接给数组名赋值一块空间的地址。比如有一个int a; 用来取地址&a,并且给&a赋值可以吗?那肯定是不行啊,地址就是地址,而不是一块空间。
注:数组名是首元素的地址
所以建议创建数组时要么初始化,要么给他输入一个元素大小让编译器开辟空间,既不给数组初始化有不说要创建多大空间的数组这种数组就没有办法去使用了。
2.3 数组的类型
数组也是有类型的,数组算是一种自定义类型,去掉数组名留下的就是数组的类型。
如下:
cpp
char ch[10]; //数组类型:char [10];
int arr[12]; //数组类型:int [12];
double score[5];//数组类型:double [5];为什么数组是自定义类型呢?比如char ch10 的类型是char 10 ,如果我将char ch10的 括号内的值改为11,此时数组ch类型就是char 11; char 10和char 11就是两种不同的类型,所以数组可以被称为自定义类型。
注:上面的是数组的类型,那数组类型前面的char、int、double就是数组元素的类型。
3、一维数组的使用
知道了一维数组的基本语法,一维数组可以存放数据,存放数据的目的是对数据的操作,那我们如何使用一维数组呢?
3.1 数组的下标
C语言规定数组是有下标的,下标是从0开始的,每个下标对应一个元素,下标相当于每个元素的编号,如下:
cpp
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
注:数组就是通过下标去访问对应的元素的
在C语言中数组的访问提供了一个操作符 ,这个操作符叫:下标引用操作符。
有了下标引用操作符,我们就可以轻松地访问到数组的元素了,比如我们访问下标为7的元素,我们就可以使用arr7(注意这里是下标的访问,而不是元素的个数) 来访问下标7对应数组中的元素8,也就是说arr7 == 8; 可以使用arr3来访问数组中下标为3的元素4,**arr3 == 4;**如下代码:
cpp
#include <stdio.h>
int main()
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}输出结果:

3.2 数组的输入
明白了数组的访问,我们可以给数组输入想要的数据。
cpp
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0;
for (i = 0; i < 10; i++)
{
scanf("%d", &arr[i]);
}
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}输出结果:

我们除了通过下标访问输出数据,我们也可以通过下标访问输入数据,通过下标访问输入的数据会替换数组下标原来的值。
4、一维数组在内存中的存储
有了前面的知识,我们使用数组就基本上没有什么障碍了,如果我们要深入了解数组,我们最好也能了解一下数组在内存中是如何存储的。
cpp
int main()
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int i = 0;
for (i = 0; i < 10; i++)
{
printf("arr[%d]=%p\n", i, &arr[i]);
}
return 0;
}输出结果:


- 在内存中,&数组元素或是&变量是取该元素或是变量所占的内存空间范围内最接近低地址的那块内存块的地址来表示它的地址
- 连续存放的数组元素类型大小是多少,在内存中需要占用的内存块就是多少。
- 每个字节的内存都有地址,每个地址指向的是一个字节的内存块。
- 数组的元素在内存中连续存储的。
- 随着下标的增长,地址也是由低到高的。
5、sizeof计算数组元素个数
在遍历数组的时候,我们经常想知道数组的元素个数,那C语言中有办法计算数组元素的个数吗?
答案是有的,可以使用sizeof。
sizeof在C语言中是一个关键字,是可以计算类型或者变量大小的,其实sizeof也可以计算数组的大小。
比如:
cpp
#include <stdio.h>
int main()
{
int arr[10];
int sz = sizeof(arr);
printf("%d\n",sz);//结果为40
return 0;
}sizeof返回结果是size_t类型的,size_t是无符号整型。
如果数组元素个数变化时,该怎么精准计算到数组的元素个数呢?
cpp
#include <stdio.h>
int main()
{
int arr[] = {1,2,3,4,5,6,7,8,9,10};
int sz = sizeof(arr)/sizeof(arr[0]);//计算数组元素个数
int i = 0;
for (i = 0; i < sz; i++)
{
scanf("%d", &arr[i]);
}
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}先使用sizeof算出整个数组的大小,再用sizeof算出数组中一个元素的大小,整个数组的大小除以一个元素大小就是数组元素个数。
6、二维数组的创建
6.1 二维数组的概念
前面学习的数组叫做一维数组,数组的元素都是内置类型的,如果我们把一维数组作为数组元素,就是二维数组 ,二维数组作为数组元素就是三维数组 ,二维数组以上都可以称之为多维数组。
注:存放一维数组的数组叫做二维数组,二维数组的每个元素就是一维数组
6.2 二维数组的创建
那我们如何定义二维数组呢?语法如下:
cpp
type arr_name[常量值1][常量值2];
例如:
int arr[3][5]; //第一个[]内表示行,第二个[]内的值表示列,表示此数组有3行5列,也可以理解为3个元素个数为5的一维数组
double data[2][8];//2行8列,可以理解为2个元素个数为8的一维数组解释:上述代码中出现的信息
- 3表示数组有3行
- 5表示数组有5列
- int表示每个元素是int类型
- arr是数组名,可以根据自己的需求指定名字
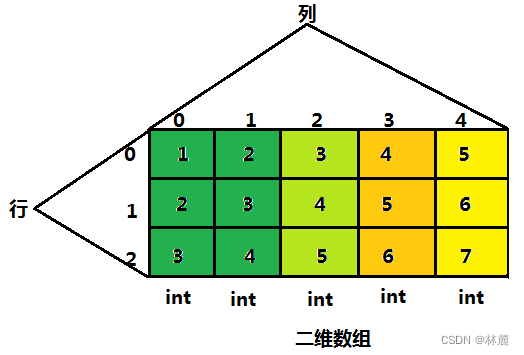
7、二维数组的初始化
首先看一下这三种二维数组初始化的语法:
cpp
int main()
{
int arr1[3][5] = { 1, 2, 3, 4, 5, 6, 7 };//不完全初始化
int arr3[3][5] = { { 1, 2, 3, 4, 5 }, { 2, 3, 4, 5, 6 }, { 3, 4, 5, 6, 7 } };//完全初始化
int arr2[2][4] = { { 1, 2 }, { 2, 3 } };//按照行初始化
return 0;
}7.1 不完全初始化
arr1的不完全初始化里数组的结果
cpp
int arr1[3][5] = { 1, 2, 3, 4, 5, 6, 7 };//不完全初始化
7.2 完全初始化
arr3的完全初始化数组的结果
cpp
int arr3[3][5] = { { 1, 2, 3, 4, 5 }, { 2, 3, 4, 5, 6 }, { 3, 4, 5, 6, 7 } };//完全初始化
7.3 按照行初始化
arr2的按照行初始化数组的结果
cpp
int arr2[2][4] = { { 1, 2 }, { 2, 3 } };//按照行初始化
7.4 初始化省略行,但是不能省略列
cpp
int arr1[][4] = {1,2,3}; //一行1,2,3,0,0
int arr2[][5] = {1,2,3,4,5,6,7}; //两行,第一行:1,2,3,4,5 第二行:6,7,0,0,0
int arr3[][5] = {{1,2},{3,4},{5,6}};//三行,第一行:1,2,0,0,0 第二行:3,4,0,0,0 第三行:5,6,0,0,0可以将列看做一个一维数组,列的个数就是这个一维数组的元素个数。行的个数则代表有多少个元素个数为列个数的一维数组。初始化时行是可以省略的,但是列不能。
8、二维数组的使用
8.1 二维数组的下标
我们掌握了二维数组的创建和初始化,那我们怎么使用二维数组呢?
其实二维数组访问也是使用下标形式的,二维数组是有行和列的,只要锁定了行和列就能唯一锁定数组中的一个元素。
C语言规定,二维数组的行是从0开始的,列也是从0开始的,如下所示:
cpp
int arr[3][5] = {{1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7}};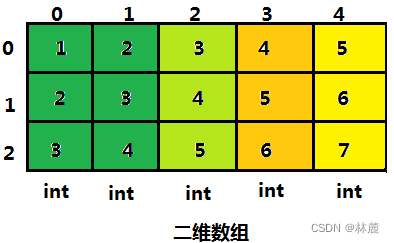
比如我要随机找一个元素5,那就可以通过行和列来锁定,通过下标先找到第二个数组元素arr1,此时二维数组arr拿到了第二个元素,arr1就是一个一维数组,再通过当前的一维数组找到5,就使用列的下标再访问一次数组元素也就是arr13,arr13此时就是元素5。
注:每一行列的下标,都是从0开始的
8.2 二维数组的输入输出
cpp
#include <stdio.h>
int main()
{
int arr[3][5] = { { 1, 2, 3, 4, 5 }, { 2, 3, 4, 5, 6 }, { 3, 4, 5, 6, 7 } };
int i, j;
for (i = 0; i < 3; i++) //表示行
{
for (j = 0; j < 5; j++) //表示列
{
scanf("%d", &arr[i][j]); //通过行和列找到当前空间的地址并输入值
}
}
for (i = 0; i < 3; i++)
{
for (j = 0; j < 5; j++)
{
printf("%d ", arr[i][j]);//通过行和列找到元素进行打印
}
printf("\n");
}
return 0;
}输出结果:

9、二维数组在内存中存储
那二维数组在内存中是怎么存储的呢?看下面代码:
cpp
#include <stdio.h>
int main()
{
int arr[3][5] = { { 1, 2, 3, 4, 5 }, { 2, 3, 4, 5, 6 }, { 3, 4, 5, 6, 7 } };
int i, j;
for (i = 0; i < 3; i++)
{
for (j = 0; j < 5; j++)
{
printf("arr[%d][%d] = %p\n", i, j, &arr[i][j]);
}
}
return 0;
}输出结果:

我们可以看出和一维数组一样,二维数组中的所有元素也是由低到高依次存储的,是连续的存储,地址也在下标的增长中由低到高的变化。

二维数组每一行都是一个一维数组名,arr0、arr1、arr2可以理解为三个一维数组的数组名,再通过这个数组名下标引用就可以找到一维数组的元素,例如:arr03。
二维数组解析:
数组名是首元素地址,二维数组的数组名也是,二维数组的数组元素是一维数组,所以二维数组数组名表示的是一维数组整个数组的地址,+1就跳过一维数组大小的字节地址,解引用二维数组的数组名后变成一维数组的数组名,此时+1就跳过一个一维数组元素大小的字节地址,再解引用就可以拿到值**(后期指针讲解)。**
了解清楚二维数组在内存中的布局,有利于我们后期使用指针来访问学习。
10、变长数组
C99标准之前创建数组的方式,数组大小是使用常量、常量表达式指定的
cpp
int arr1[10];
int arr2[3 + 5];
int arr3[] = { 1, 2, 3, 4 };这样的语法限制,让我们创建数组就不够灵活,有时候数组大了就浪费空间,数组小了不够用。
在C99中,引入了**变长数组(variable-length array,简称VLA)**的新特性,允许数组的大小是变量
请看下面代码:
cpp
int main()
{
//C99中,引入了变长数组的概念,允许数组的大小是变量
int n = 0;
scanf("%d", &n);
int arr[n];
return 0;
}上面示例中,数组arr就是变长数组,因为它的长度取决于变量n的值,编译器没法事先确定,只有运行时才能知道n是多少。
注:变长数组的根本特性,就是数组长度只有运行时才能确定,所以变长数组不能初始化。
11、数组代码练习
练习1:两边字符向中间汇聚
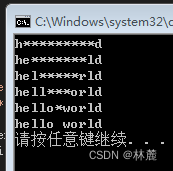
cpp
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
int main()
{
char str1[] = "hello world";
char str2[] = "***********";
int left = 0;
int right = strlen(str1)-1;
while (left <= right)
{
str2[left] = str1[left];
str2[right] = str1[right];
printf("%s", str2);
Sleep(1000); //睡眠时间(1秒循环一次)
system("cls");//执行系统屏幕清理指令
left++;
right--;
}
printf("%s\n", str2);
return 0;
}运行时打印流程:
库函数介绍:
上面又使用两个库函数分别是system 和Sleep ,system 是指令库函数,是执行系统命令的,可以用来输入控制台指令,比如"cls"就是清理屏幕指令,该库函数所包含头文件是**#include<stdlib.h>** 。Sleep是windows所提供的库函数,是睡眠多少时间,参数1000为1秒,该库函数所包含头文件是**#include<windows.h>**
练习2:二分查找 (折半查找)
小明买了一双鞋,说在100-200元之间,让你猜一下,你从100、101、102一个一个往后问就很慢了,如果先猜150,小明说小了,再猜175,小明说大了,然后162这样不停的找中间值,不停的折半,最后很快就找到了要找的数。
cpp
#include <stdio.h>
int main()
{
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int sz = sizeof(arr) / sizeof(arr[0]);
int k = 7;
int left = 0;
int right = sz - 1;
while (left <= right)
{
int z = left + (right - left) / 2;//把right多出left的数求出来折个半加给left是更准确的中间值
if (arr[z] < k)
left = z + 1;
else if (arr[z]>k)
right = z - 1;
else
{
printf("找到了,下标为:>%d\n", z);
break;
}
}
if (left > right)
{
printf("找不到\n");
}
return 0;
}输出结果:

第五章:函数
1、函数的概念
数学中我们就见过函数的概念,比如:一次函数y=kx+b,k和b都是常量,给一个任意的x,就得到一个y值。
在C语言中也引入了函数(function) 的概念,有些翻译为:子程序,子程序这种翻译更加准确一些。C语言中的函数就是一个完成某种特定任务的一小段代码。这段代码是有特殊的写法和调用方法的。C语言程序就是由无数个小的函数组合而成,也就是说:一个计算任务可以分解成若干个较小的函数(对应较小的任务)完成,这些函数各自完成所对应较小的任务。同时一个函数如果能完成某种特定任务的话,这个函数是可以复用的,提升了开发软件的效率。
在C语言中我们一般会见到两类函数:库函数、自定义函数。
2、库函数
库函数是编译器厂商提供的现成的函数,我们直接调用就可以
2.1 标准库和头文件
C语言中规定了C语言的各种语法规则,C语言并不提供库函数;C语言的国际标准ANSI C规定了一些常用的函数标准,被称为标准库,那不同的编译器厂商根据ANSI C提供的库函数标准去实现这一系列函数,这些函数就被称为库函数。
我们前面内容学到的printf、scanf都是库函数,库函数也是函数,不过这些函数已经是现成的,我们只要学会怎么使用就可以了。有了库函数,一些常见的功能就不需要程序员自己实现了,一定程度提升了效率;同时库函数的质量和执行效率上都更有保证。
各种编译器的标准库中提供了一系列的库函数,这些库函数根据功能的划分,都在不同的头文件中进行了声明。有数学相关的,有字符相关的,有日期相关的等,每个头文件中都包含了相关的函数和类型等信息。
2.2 库函数的使用方法
举例:sqrt
cpp
double sqrt(double x);
//sqrt是函数名
//x是函数的参数,表示调用sqrt函数需要传递一个double类型的值
//double是返回值类型-表示函数计算的结果是double类型的值2.2.1 功能
compute square root 计算平方根
Returns the square root of x. (返回平方根)
2.2.2 头文件包含
库函数是在标准库中对应的头文件中生命的,所以库函数的使用,务必包含对应的头文件,不包含可能会出现一些问题的。
2.2.3 实践
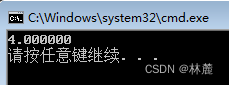
cpp
#include <stdio.h>
#include <math.h>
int main()
{
double d = 16.0;
double r = sqrt(d);
printf("%lf\n", r);
return 0;
}运行结果:
2.2.4 库函数文档一般格式
- 函数原型
- 函数功能介绍
- 参数和返回类型说明
- 代码举例
- 代码输出
- 相关知识链接
3、自定义函数
了解了库函数,我们关注度应该聚焦在自定义函数上,自定义函数其实更加重要,也能给程序员写代码更多的创造性。
3.1 函数的语法形式
其实自定义函数和库函数是一样的,形式如下:
cpp
ret_type fun_name(形式参数)
{
}- ret_type是函数返回类型
- fun_name是函数名
- 括号中放的是形式参数
- {}括起来的是函数体
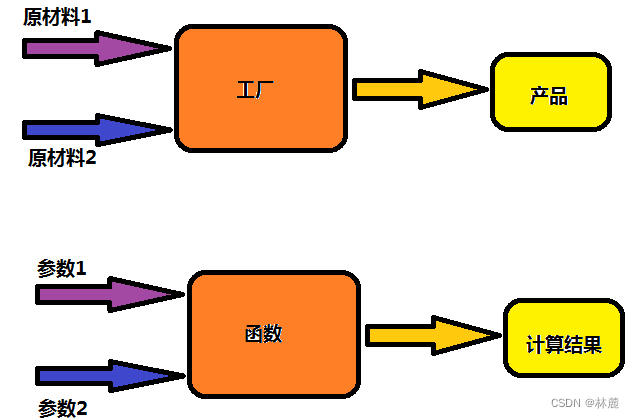
我们可以把函数想象成一个小型的加工厂,工厂得输入原材料,经过工厂加工才能生产处产品,那函数也是一样的,函数一般会输入一些值(可以是0个,也可以是多个),经过函数内的计算,得出结果。
- ret_type 是用来表示函数计算结果的类型,有时候返回类型可以是void,表示什么都不返回。
- fun_name 是为了方便使用函数;就像人的名字一样,有了名字方便称呼,函数有了名字方便调用,所以函数名尽量要根据函数的功能起的有意义。
- 函数参数就相当于工厂中送进去的原材料,函数的参数也可以使void,明确表示函数没有参数。如果有参数,要交代清楚参数的类型和名字,以及参数个数。
- {}括起来的部分被称为函数体,函数体就是完成计算的过程。
注:自定义函数需要注意的是,在自定义函数内部创建的变量空间在函数结束时是会返还给操作系统的。
3.2 函数举例
自定义函数完成加法运算:
cpp
#include <stdio.h>
int Add(int x, int y)
{
int z = 0;
z = x + y;
return z;
}
int main()
{
int a = 0;
int b = 0;
scanf("%d%d", &a, &b);
int ret = Add(a, b);
printf("%d\n", ret);
return 0;
}运行结果:

4、实参和形参
先看下面代码:
cpp
#include <stdio.h>
int Add(int x, int y)//括号内部的参数叫做形式参数,简称形参,用来接收实参传过来的值
{
return x+y;
}
int main()
{
int a = 0;
int b = 0;
scanf("%d%d", &a, &b);
int ret = Add(a, b);//这里的函数调用时传的值就是实际参数,简称实参
printf("%d\n", ret);
return 0;
}4.1 实参
在上面代码中,调用Add函数时传的参数a,b称为实际参数 ,简称实参。
实际参数就是真实传递给函数的参数。
4.2 形参
在上面代码中,函数名Add后括号中的x和y,称为形式参数 ,简称形参。
为什么叫形式参数呢?实际上,如果只是定义了Add函数,而不去调用的话,Add函数的参数x和y只是形式上存在的,不会向内存申请空间,不会真实存在,所以叫做形式参数。形式参数只有在函数被调用的过程中为了存放实参传递过来的值,才向内存申请空间,这个过程就是形参的实例化。
4.3 形参和实参的关系
形参只是在调用时申请一块空间用来存放实参的值,但是形参和实参之间的地址各不相同,对形参的改变不会影响到实参,也可以理解为形参只是实参的一份临时拷贝。
5、return语句
- 在函数设计中,函数中经常会出现return语句,这里讲一下return语句的注意事项。
- return 后边可以是一个数值,也可以是一个表达式,如果是表达式则先执行表达式,再返回表达式的结果。
- return 后边也可以什么都没有,直接写return; 这种写法适合返回函数返回类型是void的情况。
- return 返回的值和函数返回类型不一致,系统会自动将返回的值隐式转换为函数的返回类型。
- return 语句执行后,函数就彻底返回,后边的代码不再执行。
- 如果函数中存在if语句等分支的语句,则要保证每种情况下都有return返回,否则会出现编译错误。
6、数组做函数参数
在使用函数解决问题的时候,难免会将数组作为参数传递给函数,在函数内部对数组进行操作。
比如:写一个函数将一个整形数组的内容全部置为-1,再写一个函数打印数组的内容。
简单思考一下,基本的形式是这样的:
cpp
#include <stdio.h>
int main()
{
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int sz = sizeof(arr)/sizeof(arr[0]);
set_arr(arr,sz);//设置数组内容为-1
print_arr(arr,sz);//打印数组的内容
return 0;
}set_arr函数的实现:
cpp
void set_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
arr[i] = -1;
}
}print_arr函数的实现:
cpp
void print_arr(int arr[],int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}输出结果:

我们需要知道的几个重要知识点:
- 函数的形式参数要和函数的实参个数匹配
- 函数的实参是数组,形参也是可以写成数组形式的
- 形参如果是一维数组,数组大小可以省略不写
- 形参如果是二维数组,行可以省略,但是列不能省略
- 数组传参,形参是不会创建新的数组的
- 形参操作的数组和实参的数组是同一个数组
重点:数组传的是地址,形参里接收数组时可以使用对应的数组类型说明我接收的地址是这个类型,注意不是额外申请空间来接收地址,而是说明函数接收的数组地址是什么类型。这里的形参就是实参的值,不是临时拷贝。
但是用指针来接收数组地址就不一样了,使用指针来接收就是额外申请一块指针空间来存放数组地址,函数可以通过这个指针访问数组,可以给这个指针变量直接赋值。
7、传值调用和传址调用
传值调用 顾名思义就是传递当前的值函数的形参接收这个值并使用,传址调用就是将当前值的地址传递过去函数形参接收到地址调用
7.1 传值调用
传值调用就只是将当前的实参传递给函数,函数通过形参来接收这个值,但是改变形参的变量不会影响到实参的变量,实参只是将变量空间里的值进行了传递,形参变量接收这个值,改变形参变量不会影响到实参变量(上面代码除了数组传参其他的都是传值调用)。
7.2 传址调用
传址调用就是将实参变量的地址作为函数参数传递给函数,函数用指针类型的变量作为形参来接收该地址,形参此时是指针,指针接收了实参的地址,所以形参变量指向了实参变量的空间,可以通过解引用这个地址改变实参空间里存储的值,所以传址调用是形参与实参之间联系了起来,改变形参就可以改变实参。
一般传址调用的作用在想通过函数的运算改变实参,举个简单的栗子,我想通过函数互换两个变量的值:
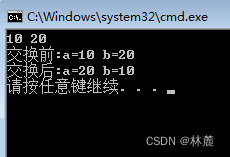
cpp
#include <stdio.h>
void Swap(int* x, int* y)
{
//调换过程
int z = *x;
*x = *y;
*y = z;
}
int main()
{
int a = 0;
int b = 0;
scanf("%d%d", &a, &b);
printf("交换前:a=%d b=%d\n", a, b);
Swap(&a, &b);//将a和b的变量地址取出传递给函数
printf("交换后:a=%d b=%d\n", a, b);
return 0;
}运行结果:
这下相信大家了解了传值调用和传址调用的区别与使用范围了吧。
8、嵌套调用和链式访问
8.1 嵌套调用
嵌套调用就是函数之间的互相调用,每个函数就像一个乐高零件,正式因为多个乐高零件互相配合才能搭出精美的模型,也正是因为函数之间有效的互相调用,最后写出来了相对大型的程序。
假设我们计算某年某月有多少天?如果要函数实现可以设计2个函数:
- is_leap_year():根据年份确定是否是闰年
- get_days_of_month():调用is_leap_year确定是否是闰年后,再根据月计算这个月的天数
cpp
//判断是否是闰年,是闰年返回1,不是返回0
int is_leap_year(int y)
{
if ((y % 4 == 0 && y % 100 != 0) || (y % 400 == 0))
return 1;
else
return 0;
}
//获取某年某月的天数
int get_days_of_month(int y, int m)
{
int days[] = { 0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };
int d = days[m];
if (is_leap_year(y) && m == 2)
{
d += 1;
}
return d;
}
int main()
{
int y = 0;
int m = 0;
scanf("%d%d", &y, &m);
int ret = get_days_of_month(y, m);
printf("%d\n", ret);
return 0;
}运行结果:

以上代码的函数内部调用了另一个函数这就叫做嵌套调用。
这一段代码,完成了独立的功能。代码中反映了不少的嵌套调用:
- main 函数调用 scanf、printf、get_days_of_month
- get_days_of_month 函数调用 is_leap_year
未来稍微大一些的代码都是函数之间的嵌套调用,但是函数是不能嵌套定义的。
8.2 链式访问
所谓的链式访问就是将一个函数的返回值作为另外一个函数的参数,像链条一样将函数穿起来就是函数的链式访问。
比如:
cpp
#include <stdio.h>
#include <strlen.h>
int main()
{
printf("%d\n", strlen("abc"));
return 0;
}再看一个有趣的代码,下面代码执行的结果是什么?
cpp
#include <stdio.h>
int main()
{
printf("%d", printf("%d", printf("%d", 43)));
return 0;
}答案是:

因为printf函数返回值是字符个数,所以依此类推就打印了:4321;
9、函数的声明和定义
函数必须满足先声明后使用这个规则,如果一个函数的定义在调用该函数位置的下面或者其他文件就需要函数声明,给编译器声明一下有这类函数,当编译器扫描到函数调用时知道有这个函数然后往后找或是在其他文件里找就可以找到该函数的定义。
函数定义也是一种特殊的声明,函数的定义在前面就相当于声明了这个函数定义,后期调用就知道了有这个函数,所以不需要函数声明。
9.1 单个文件的函数声明和定义
cpp
//函数的声明
int is_leap_year(int y);
int main()
{
int year = 0;
scanf("%d", &year);
if (is_leap_year(year))
{
printf("是闰年\n");
}
else
{
printf("不是闰年");
}
return 0;
}
//函数的定义
int is_leap_year(int y)
{
if ((y % 4 == 0 && y % 100 != 0) || (y % 400 == 0))
return 1;
else
return 0;
}函数的定义一定要满足先声明后使用;
函数的定义也是一种特殊的声明,所以函数放在调用之前也是可以的。
9.2 多个文件的函数声明和定义
一般在企业中我们写代码的时候,代码可能比较多,不会将所有的代码都放在一个文件中;我们往往会根据程序的功能,将代码拆分成多个模块放在多个文件中。
一般情况下,函数的声明、类型的声明放在头文件(.h)中,函数的实现是放在源文件(.c)中。
如下:
add.c:
cpp
//函数的定义
int Add(int x,int y)
{
return x + y;
}add.h:
cpp
//函数的声明
int Add(int x,int y);test.c:
cpp
#include "add.h" //包含本地头文件
#include <stdio.h>
//函数的调用
int main()
{
int a,b;
scanf("%d%d",&a,&b);
int c = Add(a,b);
printf("%d\n",c);
return 0;
}包含我们自己的头文件时需要用双引号来包含**#include "add.h",库函数头文件时尖括号包含#include<stdio.h>**。
10、static和extern
static和extern 都是C语言中的关键字。
static是静态的的意思,可以用来:
- 修饰局部变量
- 修饰全局变量
- 修饰函数
extern是用来声明外部符号的。
在讲解static和extern之前再了解一下:作用域和生命周期。
**作用域(scope)**是程序设计概念,通常来说,一段程序代码中所用到的名字并不总是有效(可用)的,而限定这个名字的可用性的代码范围就是这个名字的作用域。
1.局部变量的作用域是变量所在的局部范围。
2.全局变量的作用域是整个工程。
生命周期指的是变量的创建(申请内存)到变量的销毁(收回内存)之间的一个时间段。
1.局部变量的生命周期是:进入作用域生命周期开始,出作用域生命周期结束。
2.全局变量的生命周期是:整个程序的生命周期。
10.1 extern外部声明
假如一个源文件想调用另一个源文件里的变量,没有头文件,怎么办?这时就可以使用extern外部声明,每个创建的全局变量默认是外部链接属性的,什么意思呢?就是哪个文件都可以使用它。那怎么使用呢?

输出结果:

extern就是声明外部符号的,格式:
cpp
extern int g_val;//就是变量声明10.2 static静态修饰
static是静态修饰,就是将变量或是函数修饰成静态,也就是将它们的存储类型从栈区改为静态区,当局部变量被static修饰后生命周期就是整个程序的生命周期,但是作用域还是所在局部范围,就是只能在局部范围使用该变量,但是出了局部范围并不销毁,下一次进来可以继续调用。
10.2.1 static修饰局部变量
先来看下面代码:
cpp
#include <stdio.h>
void function()
{
int a = 0;
a++;
printf("%d ", a);
}
int main()
{
int i = 0;
for (i = 0; i < 5; i++)
{
function();
}
return 0;
}输出结果:
static修饰局部变量后的代码:
cpp
#include <stdio.h>
void function()
{
static int a = 0;
a++;
printf("%d ", a);
}
int main()
{
int i = 0;
for (i = 0; i < 5; i++)
{
function();
}
return 0;
}运行结果:

对比static修饰前的代码和static修饰后的代码,运行结果简直就是天壤之别,为什么会这样呢?
结论:因为被static修饰过的局部变量出了函数(作用域)但是不会被销毁,下一次调用还是这个变量。static是将它修饰过的变量的存储类型改为了静态区,静态区开辟的空间一般只有在程序结束后才会销毁,但是该局部变量的作用域还是那个局部范围。简单理解为局部变量被static修饰过后生命周期变长了,和全局变量的生命周期平起平坐了。
使用建议:未来一个变量出了函数但是我们还想保留它的值,就可以使用static修饰它。
10.2.2 static修饰全局变量
当static修饰全局变量后全局变量会有什么变化呢?
static修饰全局变量并不是修改它的存储类型改变全局变量的生命周期,因为全局变量本身就是开辟在静态区的,那为什么还要使用static修饰全局变量呢?这不是多此一举吗?其实static还有另一个作用,就是改变属性,能改变什么属性,就是外部链接属性,一个全局变量在创建时默认就是外部链接属性,不管是哪个文件都可以使用或更改它,这就使得全局变量的安全性不够高,怎么办?使用static修饰后将外部链接属性改为内部链接属性,内部链接属性的全局变量只有当前源文件可以使用,其他文件就不能随意使用了。
使用建议:当创建好了一个全局变量时,指向当前文件可以使用,就可以使用estatic修饰改变它的属性。
10.2.3 static修饰函数
static修饰函数和修饰全局变量是一样的效果,就是为了改变它们的链接属性,函数和全局变量一样,在创建时默认是外部链接属性,如果想让它只能在当前文件调用就可以使用static修饰更改链接属性。
结论:static的两种使用方法
- 将变量的存储类型改为静态区,增加它的生命周期。
- 改变全局变量或者是函数的链接属性,被static修饰过的会变成内部链接属性,只可在当前文件调用
第六章:函数递归
1、递归是什么?
递归是学习C语言函数绕不开的一个话题,那什么是递归呢?
递归其实是一种解决问题的方法,在C语言中,递归就是函数自己调用自己。
写一个史上最简单的C语言递归代码:
cpp
#include <stdio.h>
int main()
{
printf("hehe\n");
main();//main函数中又调用了main函数
return 0;
}上述就是一个简单的递归程序,只不过上面的递归只是为了演示递归的基本形式,不是为了解决问题,代码最终也会陷入死循环,导致栈溢出。
递归的思想:
把一个大型复杂问题层层转化为一个与原问题相似,但规模较小的子问题来求解;直到子问题不能再被拆解,递归就结束了。所以递归的思考方式就是把大事化小的过程。
递归中的递是递推 的意思,归就是回归的意思。
注:所以使用递归需要限制条件,达到递归限制条件,就返回,避免死递归,导致栈溢出。
2、递归的限制条件
递归在书写的时候,有2个必要条件:
- 递归存在限制条件,当满足这个限制条件的时候,递归便不再继续。
- 每次递归调用之后越来越接近这个限制条件。
在下面的例子中,我们逐步体会这2个限制条件。
3、递归举例
3.1 举例1:求n的阶乘
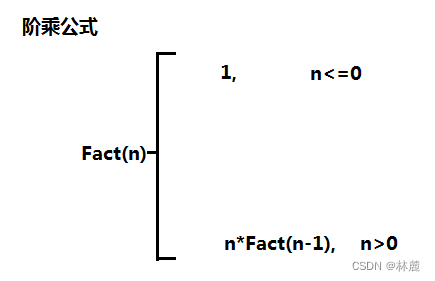
计算n的阶乘(不考虑移除),n的阶乘就是1-n的数字累积相乘.
3.1.1 分析和代码实现
我们知道n的阶乘的公式:n! = n*(n - 1)!
cpp
举例:
5! = 5 * 4!(4*3*2*1)
4! = 4 * 3!(3*2*1)
3! = 3 * 2!(2*1)
2! = 2 * 1!(1)
1! = 1
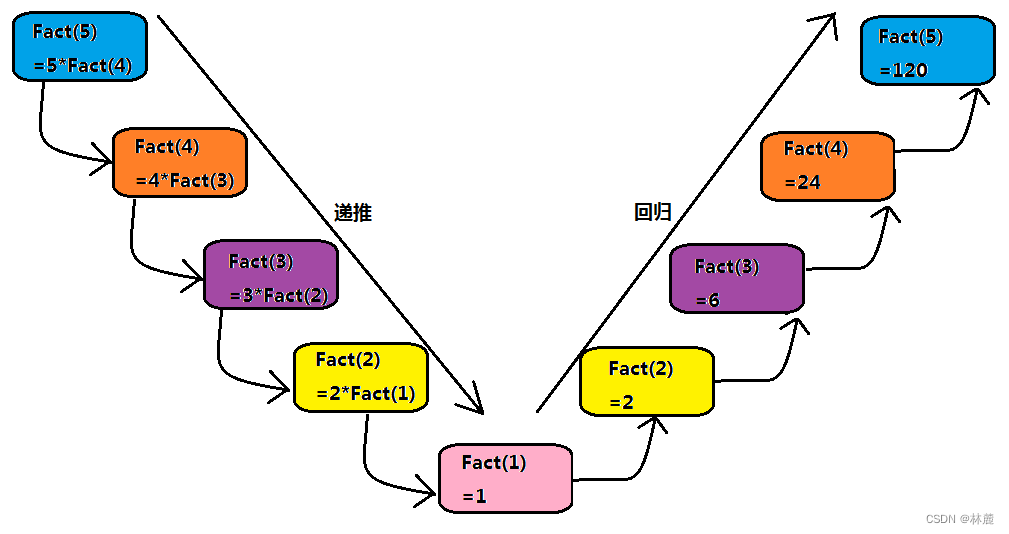
所以:5! = 5 * 4!这样的思路就是把一个较大的问题,转换为一个与原问题相似,但规模较小的问题来求解
n!---->n * (n-1)!
直到n是1或者0时,不再拆解。
所以可以使用递归的方式求n的阶乘:
cpp
#include <stdio.h>
int Fact(int n)
{
if (n <= 1)
return 1;
else
return n*Fat(n - 1);
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = Fact(n);
printf("%d\n", ret);
return 0;
}3.1.2 运行结果:

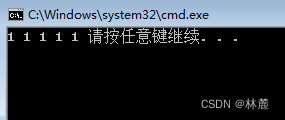
这个阶乘就是递归实现,每次进入函数先判断,如果n大于1就递归,每次递推就需要这个变量n不停的接近这个判断条件。如果等于或小于则作为结束递推的条件结束递推,接下来就是不停的回归。
画图推演
3.2 举例2:顺序打印一个整数的每一位
题目:输入一个整数,打印它的每一位。
例如:输入1234 输出1 2 3 4
输入520 输出5 2 0
3.2.1 分析和代码实现
思路是每次%它的个位数,再让这个数/10,除去原来个位的位数。但是输入1234打印的却是4 3 2 1,因为这个是先%最后一位,在找前面几位,打印结果和我们想要输出的结果相反,怎么办?那如果我们将4 3 2 1 整合成一个值再取位数拿到1 2 3 4不就行了吗?虽然可行但是效率确极低。这时候就可以使用到递归。
递归思路:先不停递推找到第一位数,取模后在不停回归取模当前个位数然后就可以输出正确顺序的每一位了。
cpp
print(1234)
==>print(123) +printf(4)
==>print(12) +printf(3)
==>print(1) +printf(2)
==>printf(1)函数递归实现:
cpp
#include <stdio.h>
void print(int n)
{
if (n > 9)
print(n / 10);
printf("%d ", n % 10);
}
int main()
{
int n = 0;
scanf("%d", &n);
print(n);
return 0;
}运行结果:
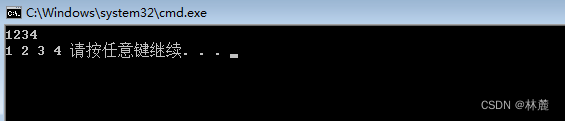
3.2.2 画图推演
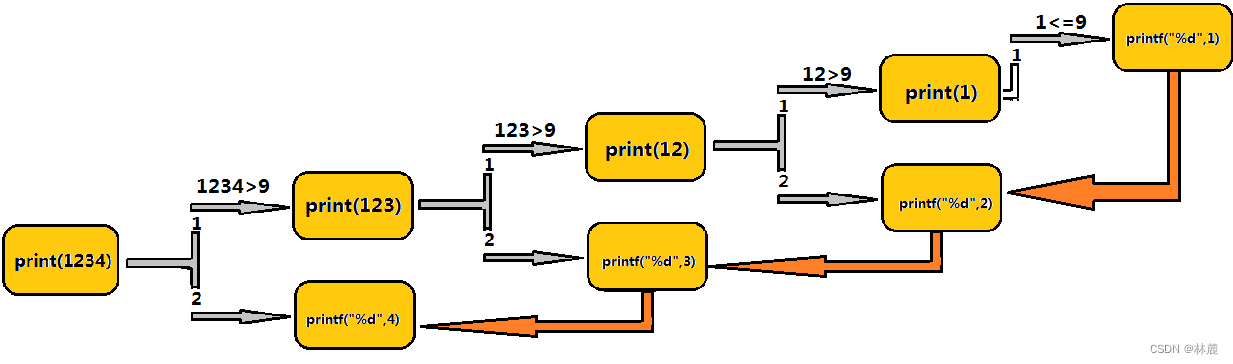
4、递归与迭代
递归是一种很好的编程技巧,但是很多技巧一样,也可能是被误用的,就像举例1一样,看到推导公式,很容易就被写成递归的形式
cpp
int Fact(int n)
{
if(n <= 0)
return 1;
else
return n*Fact(n-1);
}Fact函数是可以产生正确的结果,但是在递归函数调用的过程中涉及一些运行时开销。
在C语言中每一次函数调用,都需要为本次函数调用在栈区上申请一块内存空间来保存函数调用期间的各种局部变量的值,这块空间被称为运行时堆栈 ,或者函数栈帧。
函数不返回,函数对应的栈帧空间就一直占用,所以如果函数调用中存在递归调用的话,每一次递归函数调用都会开辟属于自己的栈帧空间,直到函数递归不再继续,开始回归,才逐层释放栈帧空间。
所以如果采用函数递归的方式完成代码,递归层次太深,就会浪费太多的栈帧空间, 也可能引起栈溢出 (stack over flow) 的问题。
如果不想使用递归就得想其他的办法,通常就是迭代的方式(通常就是循环的方式)。
比如:计算n的阶乘,也是可以产生1-n的数字累积乘在一起的:
cpp
int Fart(int n)
{
int i = 0;
int ret = 1;
for(i = 1;i <= n;i++)
{
ret *= i;
}
return ret;
}上述代码是能够完成任务,并且效率是比递归的方式更好的。
事实上,我们看到的许多问题是以递归的形式进行解释的,这只是因为它比非递归的形式更加清晰,但是这些问题的迭代实现往往比递归实现效率更高。
当一个问题非常复杂,难以使用迭代的方式实现时,此时递归的简洁性便可以补偿它所带来的运行时开销。
举例3:求第n个斐波那契数
我们也能举出更加极端的例子,就像计算第n个斐波那契数,是不适合使用递归求解的,但是斐波那契数的问题通过是使用递归的形式描述的,如下:
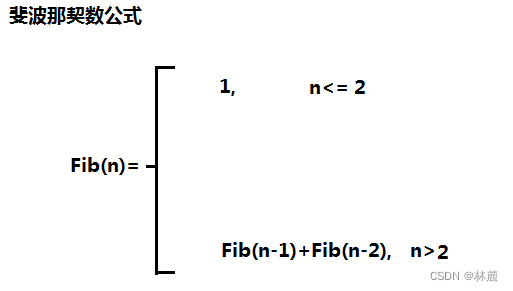
看到这公式,很容易诱导我们将代码写成递归的形式,如下所示:
cpp
#include <stdio.h>
int Fib(int n)
{
if (n <= 2)
return 1;
else
return Fib(n - 1) + Fib(n - 2);
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = Fib(n);
printf("%d\n", ret);
return 0;
}运行结果:
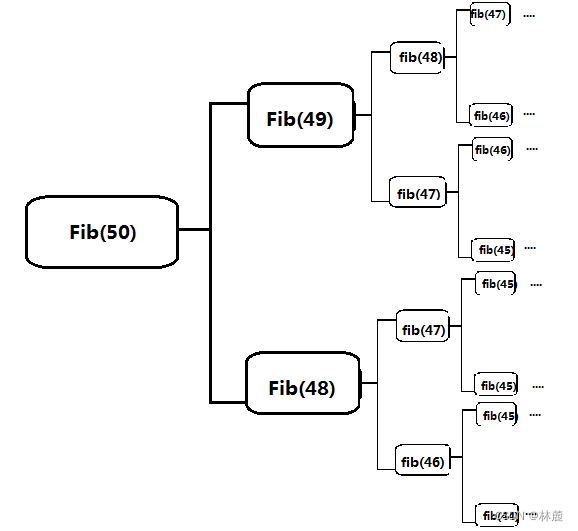
结果看来虽然是对的,如果将数值输入50,那就不能输出正确的斐波那契数值了,这个数庞大到超过千亿甚至更多,这么庞大的数字在C语言中没有任何一个类型变量可以接收这么大的值,这么庞大的数顶多只能用字符来表示,但是这不是最主要的,因为需要不停的递归运算,需要递归不知多少亿次,计算机、CPU再牛也不可能一下就运算出来,又是运算又是开辟空间需要一段时间,不仅效率低下给出的值显示出来的也不正确。如果是迭代,就算输入100也能在1秒内给你输入出一个值,虽然也不对,但是可以得知迭代运行效率确实比递归高,所以想让程序运行效率高时用迭代,遇到迭代难以实现的复杂代码时,递归的简洁性就弥补了运行时开销带来的效率低下问题。
迭代实现斐波那契数:
cpp
#include <stdio.h>
int Fib(int n)
{
int a = 1;
int b = 1;
int c = 1;
while (n > 2)
{
c = a + b;
a = b;
b = c;
n--;
}
return c;
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = Fib(n);
printf("%d\n", ret);
return 0;
}迭代实现第n个斐波那契数的运行效率效率就要高出很多。
那什么时候使用递归法什么时候使用迭代法呢?
1、如果一个问题使用递归方式去写代码,是非常方便的,简单的写出的代码是没有明显缺陷的,这个时候使用递归就可以
2、如果使用递归写的代码是存在明显缺陷的
比如:栈溢出、效率低下等
这时候考虑其他方式,比如:迭代
有时候,递归虽好,但是也是会引入一些问题,所以我们一定不要迷恋递归,适可而止就好。
第七章:操作符
1、二进制
其实我们经常能听到2进制、8进制、10进制、16进制这样的讲法,那是什么意思呢?、其实2进制、8进制、10进制、16进制是数值的不同表示形式而已。
比如:数值15的各种进制的表示形式:
- 15的二进制:1111
- 15的8进制:17
- 15的10进制:15
- 16的16进制:F
我们重点介绍一下二进制:
首先我们还是得从10进制讲起,其实10进制是我们生活中经常用的,我们已经形成了很多尝试:
- 10进制中满10进1
- 10进制的数字每一位都是0-9组成
其实二进制也是一样的:
- 二进制中满2进1
- 二进制数字每一位都是0-1组成
1.1 2进制转10进制
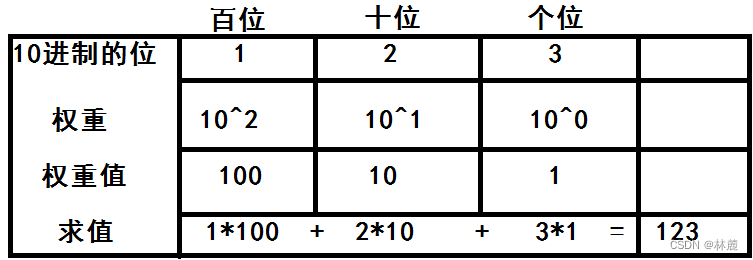
其实10进制123表示的值是一百二十三,为什么是这个值呢?其实10进制的每一位是权重的,10进制的数字从右向左是个位、十位、百位...,分别是10^0,10^1,10^2...
如下图:
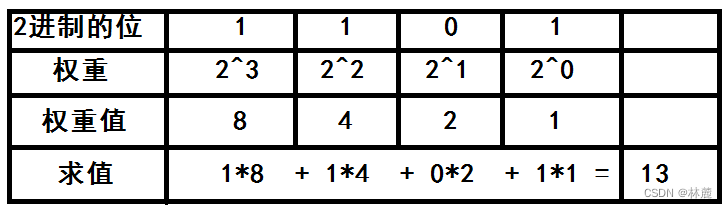
2进制和10进制是类似的,只不过2进制的每一位的权重,从右向左是:2^0,2^1,2^2...
如果是2进制的1101,该怎么理解呢?
1.2 10进制转2进制
怎么转换呢?很简单,看下图:

1.4 2进制转8进制
8进制数字的每一位是0-7的数字,各自写成2进制,有3个二进制位表示就足够了,因为8进制最高位数7只需要2^0,2^1,2^2(1+2+4)表示,需要三个2进制位,所以我们只需将8进制的每一位都转换成1-3个2进制位就可以了。
在C语言中一个数值前面加上一个0就会被识别为8进制数字,比如0153,这里就会被当做8进制。
例如:

1.4 2进制转16进制
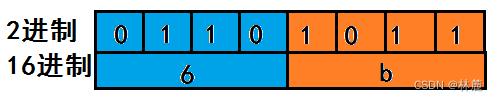
16进制的数字每一位是0-9,a-f的(前面0-9是数字表示,后面的10-15由于是2位数,但是想要表示16进制的1位数肯定是不行的,所以就用a-f来替代10-15的表示形式),每一位写成2进制,最多需要4为2进制位表示。比如16进制的最高位f二进制表示就是1111,每一位不管有没有表示满4个二进制位都要用0填充,才能开始结合相邻位的二进制。
16进制前的0x表示是16进制的,比如0x6b,所以16进制表示的时候前面加上0x。
2、原码、反码、补码
整数的2进制表示的方法有三种,即原码、反码和补码,不涉及小数(浮点数)
三种表示方法均有符号位 和数值位两部分组成,符号位都是用0表示 "正",用1表示 "负",而数值位最高的一位是被当做符号位,剩余的都是数值位。
注:符号位是不能用来存储数据的,所以有符号数的最大值比无符号的最大值小,但是表示的数值范围是相同的。因为有符号数和无符号数的无符号数和有符号数的最大值的差值范围正好是0到最小值负数的范围。
正整数的原、反、补码都相同(也可以理解为正整数没有反码和补码的概念,就只是一个原码二进制位表示)。
负整数的三种表示方式各不相同。
**原码:**直接将数值按照正负数的形式翻译成二进制得到的就是原码。
**反码:**将原码的符号位不变,其他位依次按位取反就可以得到反码。
**补码:**反码+1就得到补码。
反码的存在就是介于原码和补码之间转换的 "转换器"。
比如有一个整型变量,将它存储的值转换成二进制:
cpp
[signed]int a = -5;
//整型占用4个字节-32bit因为整型类型大小为4个字节,所以它的大小是32个bit位。
整数-5的二进制:
原码:10000000 00000000 00000000 00000101
反码:11111111 11111111 11111111 1111010 符号位不变,数值位按位取反
补码:11111111 11111111 11111111 1111011 反码+1
橙色:符号位 蓝色:数值位
对于整数来说:数据在内存中是以补码的形式进行存储的。
为什么呢?
在计算机系统中,数值一律用补码的形式表示存储,原因在于,使用补码,可以将符号位和数值域统一处理;(因为负数的补码是正补数的原码,其原、反、补码的运算就是为了求出补码也就是正补数的原码,正补数不存在符号位,所以符号位就算是1也是表示数值的)
同时,加法和减法也是可以统一处理(CPU只有加法器) 此外,补码和原码相互转换,其运算过程是相同的,不需要额外的硬件电路。(补码就是正补数的原码,正补数和另一个正整数相加正好可以求出负整数和正整数的运算结果,从而实现了加法和减法的统一处理)
怎么简单理解上面的意思呢?CPU只有加法运算器为什么也能处理减法呢?不要着急,接下来就由我来为大家一 一讲解。
其实补码就是专门为了负整数而发明的,原因是CPU只有加法运算器,如果处理两个数相减的减法运算,不知道该怎么处理。那我们可以将减法运算看作一个正整数加上负整数(1+(-1))就可以了呗。但是两个数的原码相加后发现算出的结果根本不对。
怎么办呢?然后就有人发明除了原、反、补码,这个发明者简直就是个天才,为什么这么说?如果你将负整数的原码转换成补码,补码转换为十进制的值可能是一个很庞大的正补数 (可以理解为这个正补数的原码就是这个负数的补码 ),正补数原码的符号位和数值域都可以用来存放数值,也就是实现了符号位和数值域统一处理 。然后正整数可以和正补数相加从而实现了减法和加法的统一处理,经过相加后得到的二进制位如果多出1位直接抛弃最后取出的32个二进制位就是正确结果,经过正补数运算得出的结果的二进制就是原码,不需要额外转换了。
关于负整数或减法运算就是将负数经过原、反、补码的运算求出正补数的原码,然后让正补数替负数执行加法运算得出的就是正确结果,你说秀不秀。
3、移位操作符
<< 左移操作符
>> 右移操作符
注:移位操作符的操作数只能是整数
3.1 左移操作符
移位规则:左边抛弃、右边补0
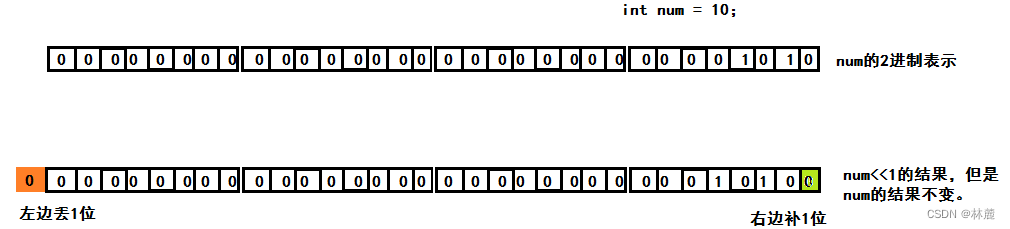
注:左移操作符操作负数移的是负数的补码也就是正补数的原码。
3.2 右移操作符
移位规则:首先右移运算分两种:
- 逻辑右移:左边补0,右边丢弃。
- 算术右移:左边用原符号位填充,右边丢弃。
注:右移操作符具体采用逻辑右移还是算术右移是不确定的,这个取决于编译器,但是大部分的编译器采用的是算术右移的。
警告:对于移位操作符,不要移动负数位,这个是标准为定义的。
例如:
cpp
int num = 10;
num>>-1 //error4、位操作符:&、|、^、~
位操作符有:
- & 按位与
- | 按位或
- ^ 按位异或
- 注:它们的操作数必须是整数
看下面代码:
cpp
#include <stdio.h>
int main()
{
int a = 5;
int b = -6;
int c = a & b;
printf("%d\n", c);
return 0;
}运行结果:

a&b按位与后的结果给变量c,打印变量c的结果为什么是0,来看一下&按位与 的规则。
假设给两个整数变量,a为5,b为-6
它们的二进制表示分别是:
5的二进制:00000000 00000000 00000000 00000101
-6的二进制:
原码:10000000 00000000 00000000 00000110
反码:11111111 11111111 11111111 11111001
补码:11111111 11111111 11111111 11111010
由于负数在内存中存储的是补码,所以任何有关负数的操作都是补码来操作。
&按位与规则:两个相同位数整数的二进制,对应的每一位都有对比,如果两个整数在二进制中当前数位为有一个是0,&结果就是0,如果两个都是1,&结果就为1。
5:00000000 00000000 00000000 00000101
-6:11111111 11111111 11111111 11111010
&按位与后
结果为0:00000000 00000000 00000000 00000000
仔细观察就会发现这两个整数二进制位正好都不相同,所以&按位与后全部为0。
再把上面的代码拿下来,改成两个数|按位或那结果会是什么:
cpp
#include <stdio.h>
int main()
{
int a = 5;
int b = -6;
int c = a | b;
printf("%d\n", c);
return 0;
}运行结果:

如果说&按位与是一个为0就是0,两个位都是1才为1的话,那|按位或就恰恰和它相反,|按位或是一个为1就是1,两个都是0才为0。
|按位或规则:两个相同位数整数的二进制,对应的每一位都要对比,如果两个整数在二进制中当前数位为有一个是1,|结果就是1,如果两个都是0,|结果才为0。
5:00000000 00000000 00000000 00000101
-6:11111111 11111111 11111111 11111010
|按位或后
结果为-1: 11111111 11111111 11111111 11111111
正好每一位都不相同并且每一位都有一个位数1
^按位异或则比较特殊,就是不管二进制位上相同的是位数0还是位数1。两个二进制位比较相同为0,相异为1。
还是上面的代码:
cpp
#include <stdio.h>
int main()
{
int a = 5;
int b = -6;
int c = a ^ b;
printf("%d\n", c);
return 0;
}运行结果:
为什么还是-1?看下面讲解:
^按位异或规则:两个相同位数整数的二进制,对应的每一位都要对比,如果两个整数在二进制中的位数对比相同为0,相异为1。
5:00000000 00000000 00000000 00000101
-6:11111111 11111111 11111111 11111010
^按位异或后
结果为-1: 11111111 11111111 11111111 11111111
因为5和-6的二进制正好每一位都不相同
一道变态的面试题:
不创建第3个变量交换第2个变量的值:
方法1:
cpp
#include <stdio.h>
int main()
{
int a = 10;
int b = 20;
a = a + b;//a == 30
b = a - b;//b = 30-20 = 10
a = a - b;//a = 30-10 = 20
printf("a=%d b=%d\n",a,b);
return 0;
}运行结果:

方法1有个明显的缺陷,就是当两个数字特别大,大到相加以后变量存不下的时候,就会发生错误答案。
方法2:
cpp
#include <stdio.h>
int main()
{
int a = 10;
int b = 20;
a = a ^ b;//先取它们之间^后的操作数
b = a ^ b;//此时a为操作数,操作数^20拿到10的值
a = a ^ b;//此时a还是操作数,b存放10,操作数^10的值后拿到20的值
printf("a=%d b=%d\n",a,b);
return 0;
}运行结果:
但是这种异或操作是有局限性的:
- 只作用于整数交换
- 代码可读性差
- 代码执行的效率也是低于创建第三个变量的交换方法的
练习:求出一个整数的二进制里有多少位是1
例如:输入15 输出:4
**方法1:**整数取模法
cpp
int main()
{
int n = 0;
scanf("%d", &n);
int count = 0;//用来计数
while (n)
{
if (n % 2 == 1)//判断,如果当前整数取模2等于1,那整数此时的最后一位就是1
{
count++;
}
n /= 2;//除去整数二进制的最后一位
}
printf("count = %d\n", n);
return 0;
}输出结果:

**方法2:**位移按位与
cpp
int main()
{
int n = 0;
scanf("%d", &n);
int count = 0;
int i = 0;
for (i = 0; i < 32; i++)
{
if ((n >> i) & 1)//每次让整数n向右移动i位并&1,计算当前移动的位数是不是1
{
count++;
}
}
printf("count=%d\n", count);
return 0;
}代码解析:方法2就是利用&按位与的特性,如果一个位为0 &后就为0,两个都是1才为1,所以让整数n的每一位与1的二进制最后1位&按位与,如果n最后一位是1就为1,count就加1,如果n是0&按位与后就是0,count不变。
**方法3:**奇妙的n&n-1法
cpp
int main()
{
int n = 0;
scanf("%d", &n);
int count = 0;
while (n)
{
n = n & (n - 1);
count++;
}
printf("count=%d\n", count);
return 0;
}代码解析:为什么不断地让给n赋值n&(n-1)最后能够计算出二进制里有多少个1,举个例子:

仔细观察不难发现没当n&n-1时拿到的就是n的二进制最后面的1去除的二进制。也就是说每次n&n-1也就是每次让n的二进制位去除一个1,n每次-1就是将n的最后面1的那一位置为0,后面的二进制位就全置为1。从而导致n与n-1二进制里n最后面的1的那一位向后开始基本上都不能与n-1相同,所以按位与后就将那个位置到后面的二进制位全部置为0,也就是n的二进制去除一个1。
有了上面的方法,那我们可不可以这样呢?
练习3:判断当前整数是不是2^n
cpp
int main()
{
int n = 0;
while (scanf("%d", &n) == 1)
{
if (n & (n - 1) == 0)
{
printf("yes\n");
}
else
{
printf("no\n");
}
}
return 0;
}输出结果:

如果好好想一想,二进制的每一位都是2^n,所以2^n整数在二进制中只有1位,不可能再有第二位,所以我们就可以用n&(n-1)公式将我输入的数的二进制判断一次,如果一次判断为就0,那绝对就是2^n,因为只有一位1,输出yes。但是如果判断结果不是0就输出no。
按位取反操作符 ~
~是按位取反操作符,是将一个整数二进制中的每一位都取反,如果是1就取反为0,如果是0就取反为1。
取反操作符有什么用处呢?
练习:改变整数二进制中的位数
cpp
int main()
{
int n = 15;
n = n | (1 << 4);
printf("n=%d\n", n);
n = n & ~(1 << 4);
printf("n=%d\n", n);
return 0;
}运行结果:

代码解析:如果我想将n的倒数第5位置为1,就需要让1<<4后1此时来到了第5位,n|(1<<4)就可以将第5位置为1,因为按位或只要有一位是1结果就是1,n此时二进制为:11111,就是31。如果想将当前位数置为0,就让1继续向左移动4位,并取反~,取反后倒数第5位数就是0,其他位就是1,让第5位的0与n第5位的1再&按位与后就成功的将这一位置为0,结果就还是15。
5、逗号表达式
逗号操作符 - 优先级是最低的
逗号表达式,就是用逗号隔开的多个表达式。
逗号表达式,从左向右依次执行。整个表达式的结果是最后一个表达式的结果。
例如:
cpp
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int c = (a>b,a=10+b,b=a+1);
printf("%d\n",c);//c的答案是多少
return 0;
}运算结果:

注:逗号表达式前面的表达式可能会影响到后面的表达式结果,请谨慎使用
那逗号表达式该怎么使用呢?
如果我写了一段代码:
cpp
a = get_val();
count_val(a);
while(a > 0)
{
//业务处理
a = get_val();
count_val(a);
}如果是这样写代码会显得非常的冗余,因为是同一段代码却写了两次,那有什么改进的方法呢?
cpp
while (a = get_val(), count_val(a), a > 0)
{
//业务处理
}这样用逗号表达式将它们结合起来看起来就相对好一些。
6、下标访问 、函数调用()
6.1 下表访问
下标访问操作符就是专门针对数组的,作用是访问数组当前下标对应的元素,例如:
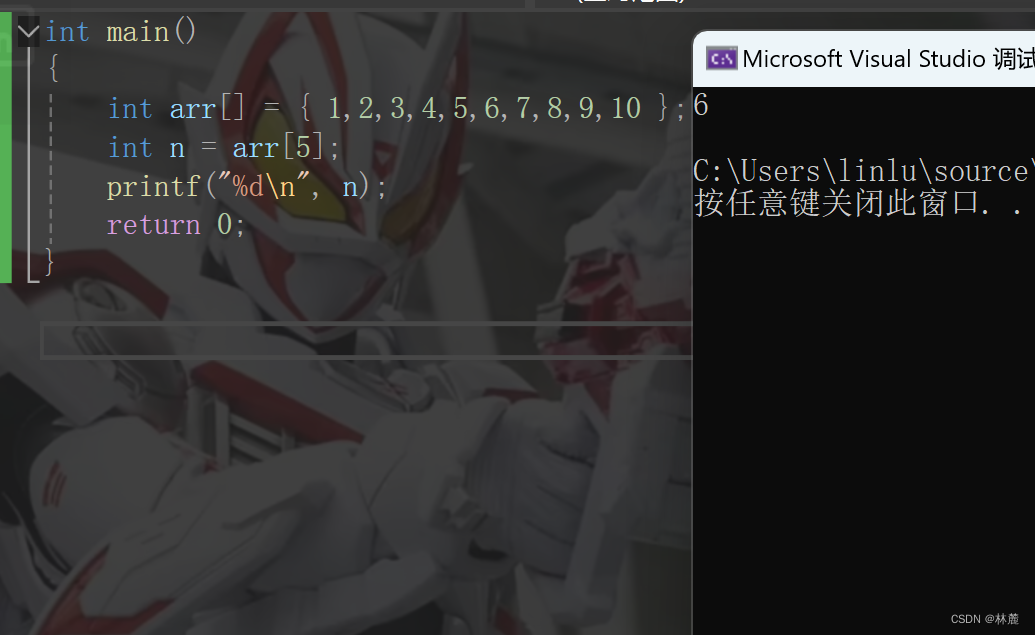
这里的arr5就是下标访问操作符的使用方式,可以看到arr5访问了数组下标5对应的元素6,这里的操作符 的操作数是arr、5。
6.2 函数调用()
函数调用操作符是专门针对函数的,作用是函数传参。

这里的Add(x,y)就是将两个变量传参,传递给函数。这里的操作符()的操作数是Add、x、y。
函数调用操作符的操作数至少要有一个函数名。
7、操作符的属性:优先级、结合性
C语言的操作符有2个重要的属性:优先级、结合性,这两个属性一定程度上决定了表达式求值的计算顺序。
7.1 优先级
cpp
int a = 3 + 4 * 5;看上面的表达式,先执行哪个操作符呢?那肯定是先*,得20再+3结果就是23,这就是操作符的优先级。
注:相邻操作符才讨论优先级
7.2 结合性
如果两个相邻的操作符的优先级相同,优先级没办法决定先计算哪个了,这个时候就可以看结合性了,则根据运算符是左结合还是右结合,决定执行顺序。大部分运算符是左结合(从左到右执行),少数运算符是右结合(从右到左执行),比如赋值运算符(=),先执行右边的表达式,再执行左边的进行赋值。
cpp
int a = 5 * 6 / 2; 上面示例中,*和/的优先级相同,它们都是左结合运算符,所以从左到右执行,先计算5 * 6,再计算6 / 2。
运算符的优先级顺序很多,下面是部分运算符的优先级顺序(按照优先级从高到低排序),建议大概记住这些操作符的优先级就行,其他操作符再使用的时候查看C语言官网的优先级表格就可以了。
- 圆括号(())
- 自增运算符(++),自减运算符(--)
- 单目运算符(+)和(-)
- 乘法(*),除法(/)
- 加法(+),减法(-)
- 关系运算符(<、>等)
- 赋值运算符(=)
由于圆括号优先级最高,可以使用它改变其他运算符的优先级。
注:需要记住赋值操作符的优先级最低,因为需要等表达式运算出结果再赋值。
8、表达式求值
表达式求值之前要进行 类型转换,当表达式中的值转换到适当的类型,才开始计算。
类型转换分为两种:
- 整形提升
- 算术转换
8.1 整形提升
C语言中整型算术运算总是至少以**缺省整型(int)**类型的精度来进行的。
为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这种转换称为整型提升。
整型提升的意义:
表达式的整型运算要在CPU的相应运算器件内执行,CPU内整型运算器(ALU)的操作数的字节长度一般就是int字节长度,同时也是CPU通用寄存器的长度。
因此,即使两个char类型相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长度。
通用CPU(general-purpose CPU)是难以直接实现两个8比特字节直接相加运算(虽然机器指令中可能有这种字节相加指令)。所以,表达式中各种长度可能小于int长度的整型值,都必须先转换为int或unsigned int,然后才能送入CPU去执行运算。
cpp
//实例1
char a,b,c;
...
a = b + c;b和c的值被提升为普通整型,然后再执行加法运算。
加法运算完成之后,结果将被截断,然后再存储于a中。
如何整型提升呢?
- 有符号整数提升是按照变量的数据类型的符号位来提升的。
- 无符号整数提升,高位补0。
cpp
1 //负数的整型提升
2 char c1 = -1;
3 变量c1的二进制(补码)中只有8个比特位:
4 11111111
5 因为char 为有符号的 char
6 整型提升时高位补符号位,即为1
7 提升之后的结果是:
8 11111111 11111111 11111111 11111111
9 unsigned char c2 = 1;
10 变量c2的二进制中只有8个比特位:
11 00000001
13 因为unsigned char 为无符号的 char
14 整型提升时高位补0
15 提升之后的结果
16 00000000 00000000 00000000 00000001但是如果是下面的整型提升的代码:

可以发现c打印出来的结果并不正确,不是应该是132的吗?为什么是-124呢?这是因为有符号类型的最高位是符号位,signed char的取值范围是-128~127,所以当127+5时,char类型的最高位(符号位)就是1,%d整型形式打印时也是需要整型提升的,所以高位补1,最后将补码转换成原码结果为-124。

解决方法:使用unsigned char(无符号字符型)的变量c来接收最高位为1的值,整型提升时高位就补0.
8.2 算数转换
如果某个操作符的各个操作数属于不同类型,那么除非其中一个操作数的转换为另一个操作数的类型,否则操作就无法进行。下面的层次体系称为寻常算数转换。
cpp
1 long double
2 double
3 float
4 unsigned long int
5 long int
6 unsigned int
7 int如果某个操作数的类型在上面这个列表中排名靠后,那么首先要转换为另一个操作数的类型后执行运算。
比如:

第八章:深入理解指针
深入理解指针(1)
1、内存和地址
1.1 内存
在讲内存和地址之前需要知道它们之间有什么关系。
**举个例子:**在生活中,你住在一个公寓,这个公寓很高,有几十层的高度。每一层有二十多个房间。如果你的朋友想来找你那该怎么找?一个一个的找效率太低了,你就给它一个这个房间的门牌号,比如:101、310、402... 你的朋友可以通过这个房间号直接锁定了第几楼第几个房间的位置并找到你。
通过以上例子大概就能知道了内存和指针的关系。比如:你的朋友要找你玩,你可以把门牌号(地址)给你的朋友,然后你的朋友通过地址,找到这个房间(内存单元),。

如果把上面的例子对照到计算机中,又是怎样?
我们知道计算机上CPU(中央处理器)在处理数据的时候,需要的数据是在内存中读取的,处理后的数据也会放回内存中,电脑上的内存是8GB/16GB/32GB等,那这些内存高效的管理呢?
其实也是把内存划分为一个个的内存单元,每个内存单元的大小为1字节,每个字节的内存单元都有一个地址编号。
就像一个高楼大厦,那怎么合理分配这么大的空间,就是划分为多个小的房间,每个房间都有门牌号。
关于计算机单位:
**计算机常见单位:**bit(比特)、byte(字节)、KB、MB、GB、TB、PB
计算机单位之间的换算:
1bit --x8--> 1byte(字节) --x1024--> 1KB --x1024--> 1MB --x1024--> 1GB --x1024-->1TB --x1024--> 1PB
1个bit位可以存放1个二进制位(1 / 0),1个byte(字节)是8个bit位也就是说可以存储8个二进制位。这8个二进制位至少可以表示一个char类型的数据,一个内存单元正好可以存储一个char类型的数据。
也可以将每个内存单元简单理解为一个宿舍,有8个学生,每个学生就是1个bit位。
总结:数据在内存中是以二进制的形式存储,方便CPU拿取内存中的二进制指令进行运算,因为计算机只能识别二进制指令。
 生活中我们把门牌号叫地址,在计算机中我们把内存单元编号也称为地址。C语言中给地址起了新的名字叫:指针 。所以我们可以理解为:内存单元编号==地址==指针
生活中我们把门牌号叫地址,在计算机中我们把内存单元编号也称为地址。C语言中给地址起了新的名字叫:指针 。所以我们可以理解为:内存单元编号==地址==指针
总结:
- 在计算机中为了方便管理内存,内存会被划分为以字节为单位的内存空间,也就是说一个内存单元的大小是一个字节
- 为了方便找到这个内存单元,会给每个内存单元一个编号,就像生活中每个房间的门牌号
- 有了内存单元的编号,就可以快速的找到内存单元
1.2 如何理解编址
CPU访问内存中某个字节空间,必须知道这个字节空间在内存中的什么位置,而因为内存中的字节很多,所以需要给内存进行编址(就如同宿舍很多,需要给宿舍编号一样)
计算机中的编址,并不是把每个字节的地址记录下来,而是通过硬件设计完成的。
钢琴、吉他上面没有写 "都瑞咪发嗦啦" 这样的信息,但是演奏者照样能够准确的找到每个琴弦上音调的位置,这是为何?因为制造商已经在乐器硬件层面设计好了,并且所有的演奏者都知道。本质是一种约定出来的共识!
总结:简单理解就是每个内存单元都有一个地址编号,但是内存单元编号本身并不是也开辟一块内存空间存储起来的,内存单元编号它本身就是某块内存空间的地址,是绑定的,约定好的,所以并不需要额外的内存单元来存储另一个单元的地址信息。
注:内存和CPU之间有三种联系方式,分别是:地址总线、数据总线和控制总线。
首先,必须理解,计算机内是有很多硬件单元,而硬件单元是要互相协同工作的。所谓的协同,至少相互之间要能够进行数据传递。
但是硬件和硬件之间是相互独立的,那么如何通信呢?答案很简单,用 "线" 连起来。
而CPU和内存之间也是有大量的数据交互的,所以,两者必须用线连接起来,我们现在需要了解一种线,叫地址总线。
我们简单理解,32位机器有32根地址总线,每根线只有两种状态,表示0,1【电脉冲有无】,那么一根线就能表示2种含义,2根线能表示4种含义,依次类推。32根地址总线就能表示2^32种含义,每一种含义都代表一个地址。
地址信息被下达给内存,在内存上,就可以找到该地址对应的数据,将数据通过数据总线传入CPU内寄存器
总结:CPU通过地址总线传输的一个地址信息给内存,在内存上,找到该地址对应的数据。再通过数据总线将内存单元里的数据传输给CPU中的寄存器,该寄存器保存数据,所以相反,CPU也可以通过地址总线传输地址让计算机在内存中找到这个地址并将数据通过数据总线写入这个地址。
控制总线:就是控制CPU是从内存中读取数据还是将数据写入内存。
以上就是CPU和内存之间怎样联系的具体步骤。
通过以上知识点,我们需要知道每个地址也是有单位的 ,虽然内存单元地址刚开始不用内存单元来存储,但如果我们想要获取这个地址,通过这个地址访问对应的内存单元时就需要创建指针变量(后面会讲) 。这个指针变量就是在内存中开辟了一块4个字节的空间来存储这个地址。所以可以得知内存单元的编号(地址)是4个字节的。但是也不一定是固定4个字节的,如果是64位机器地址大小就是8字节,但是我们平常用的都是32位机器,所以地址是4字节。
总结:每个地址单位是4个字节,每个地址所关联的内存单元是1个字节。
2、指针变量和地址
2.1 取地址操作符(&)
理解了内存和地址的关系,我们再回到C语言,在C语言中创建变量其实就是向内存申请空间,比如:
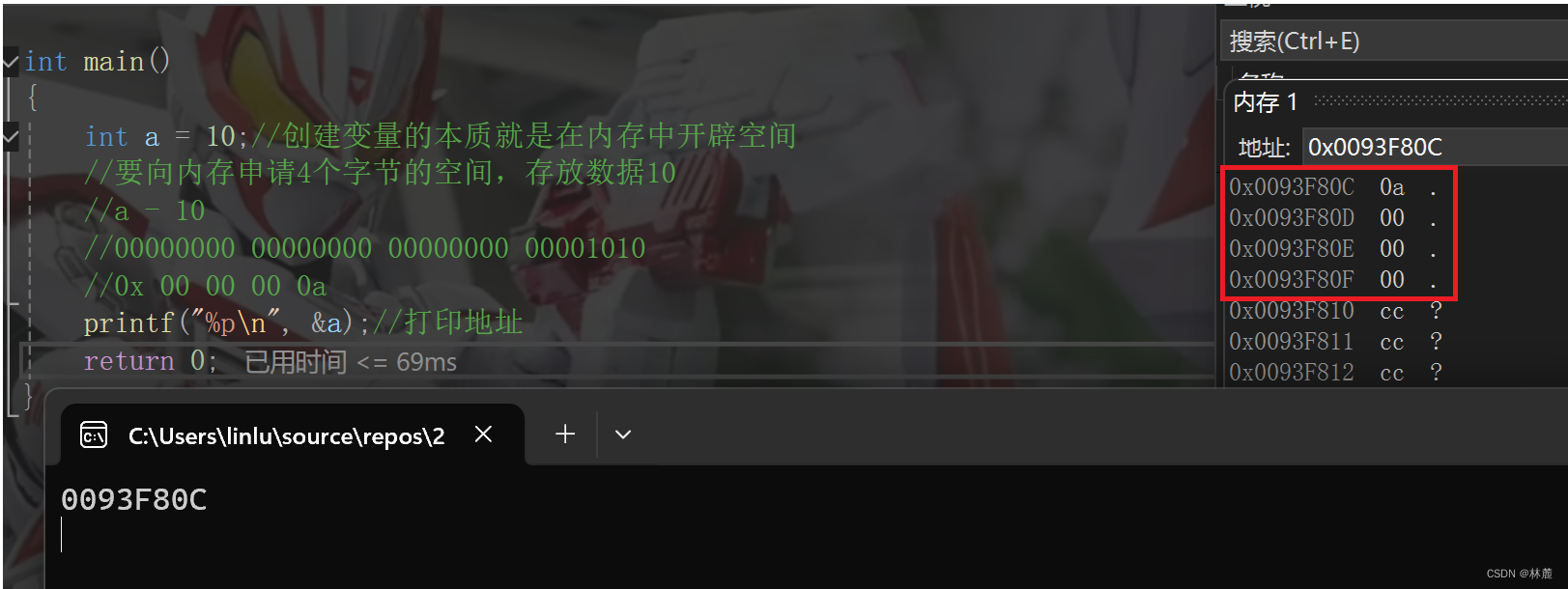
看上图,变量a是int类型需要向内存申请4个字节空间的地址来存储数据10,数据10的被拆分为4个字节存储到内存中,变量a的地址是从4个字节地址中选择较小的那个字节的地址来表示变量a的地址,拿数据时CPU可以通过这个地址向后再访问3个字节的内存单元就可以取出数据10。
比如,在上述代码就是创建了整型变量a,内存中申请4个字节,用于存放整数10,其中每个字节都有地址,上图4个字节的地址从低到高分别是
cpp1 0x0093F80C 2 0x0093F80D 3 0x0093F80E 4 0x0093F80F表示变量a的地址就是最低的地址:0x0093F80C
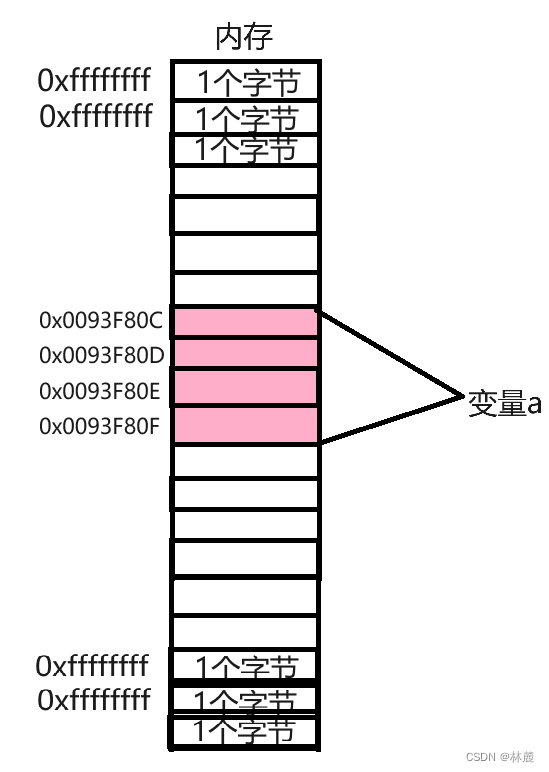
看到这里可能有人疑问了,就是内存中每个内存单元存储的不是二进制形式的数据吗?为什么上图的内存中存储的是16进制。在这里声明一下,在内存中数据是以2进制的形式存储的,但是显示时是16进制显示的,方便观察。
总结 :当一个变量需要开辟的内存单元多于一个字节时,就取这些开辟好的内存单元的地址中的低地址来表示变量的地址,也就是属于这个变量内存空间的最低地址。
2.2 指针变量和解引用操作符(*)
注:指针变量才是学习指针最重要的核心。
通过上面的代码中打印&a取出的地址可以发现地址也是一个值,如果地址是一个值那是不是就可以创建一个变量来存储这个地址呢?答案是可以的,我们可以通过指针变量来存储这个地址,指针变量就可以通过这个地址找到这个地址的内存单元并读取或修改这块空间里的值,比如:

通过上图代码可以得知创建一个指针变量pa来接收&a取出的地址,pa和&a是等价的,这就是指针变量。认真的来讲:pa的类型是int* ,int说明这个指针变量所指向对象是int类型的,*说明这个pa是指针变量。

这个就是最基础的指针变量,整型指针变量,可以简称为整型指针。pa因为是存放指针的变量,所以叫做指针变量。
重点:我们看到的地址都是int类型的值表示的,当你对一个变量a取地址时编译器会根据变量a的类型来决定&a地址的指针类型。在指针空间中就是将这个int*类型的地址拆分开放在每个字节的内存空间。但是当你拥有一个int类型的地址时,比如:0x0012ff40时,你想直接访问这个地址指向的内存空间。就可以将它强制类型转换为指针类型。就可以根据指针的类型访问多大的空间。
假如此时我有一个变量:
cpp
1 char ch = 'w';
2 //接收&ch的指针变量是什么?接收&ch的指针变量是什么,看上面的指针变量有定义:int说明这个指针变量所指向对象是int类型的,*说明这个pa是指针变量。*可以证明这个变量是指针变量,所以*必不可少,那就剩类型需要更改了,这个&ch地址所指向的对象是char类型的,所以对应的指针变量就是:
cpp
1 char ch = 'w';
2 char* pc = &ch;//指针变量这个是指向字符的指针变量,简称字符指针。
看到这里是不是就明白当面对不同类型的变量时,该用什么指针类型变量来接收这个地址了吧。
比如遇到double类型的变量时,就用double*类型的指针来接收double类型变量的地址。
例如:
cpp
1 double d;
2 double* pd = &d;总结:指针变量就是用来存放地址的,存放在指针变量中的值,都会被当成地址使用。
但是用指针变量拿到地址有什么用呢?比如我在一个宿舍,我将宿舍的门牌号告诉好兄弟,我的好兄弟可以通过这个门牌号找到我给我送点东西,或是来找我玩。相同的,指针也是这个道理,如果想改变这个空间的值或访问这个空间的值,就给指针变量这个空间的地址,指针就可以通过这个地址找到这个空间并修改这个空间所存储的值。
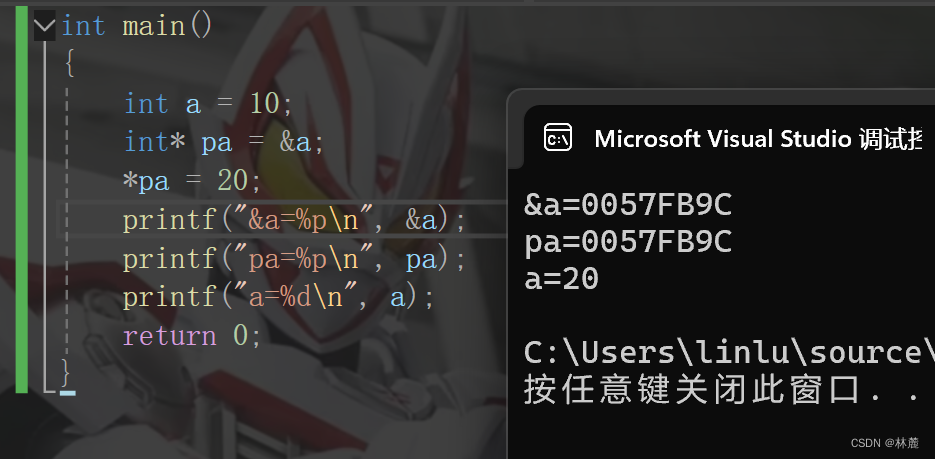
这里的*是解引用操作符或者叫间接访问操作符,*pa可以直接通过pa中的地址找到地址指向的变量a的内存空间,给*pa赋值20变量等价于变量a赋值了20,所以说*pa等价于变量a。*pa是直接通过地址找到的变量a的内存空间。
cpp
1 *pa == a;
2 (*pa = 20) == (a = 20);但是可能就有人会想,解引用*pa改变a那不是多此一举吗?其实指针访问变量空间的应用场景并不是这里,而是函数传参,想一想,函数传参形参是实参的一份临时拷贝,改变形参不会影响实参。如果我想写一个函数,交换两个变量的值,怎么办?答案是传地址,通过地址可以直接访问到变量的空间并修改:
cpp
#include <stdio.h>
void swap(int* x, int* y)
{
int s = *x;
*x = *y;
*y = s;
}
int main()
{
int x = 0;
int y = 0;
scanf("%d%d", &x, &y);
printf("交换前:x=%d y=%d\n", x, y);
swap(&x, &y);
printf("交换后:x=%d y=%d\n", x, y);
return 0;
}运行结果:
可以看到确实通过函数交换了两个变量的值,函数调用时实参传递地址,形参由指针接收这个地址,指针形参通过这个地址可以访问到变量的空间,相当于让实参和形参有了连接,而不是拷贝。这就是传址调用。
2.3 指针变量的大小
指针变量并不会因为类型而决定它的大小,比如int*类型的指针变量是4个字节,那char*类型的指针变量是1个字节吗?double* 类型的指针变量是8个字节吗?当然不是,指针变量说白了就是开辟一块空间存储地址,地址固定大小就是4/8个字节,是根据环境来指定的,地址一般是由32个或64个0/1组成的二进制序列组成的地址。指针变量就是开辟地址大小的空间来存放地址,所以指针变量要么是4个字节,要么就是8个字节。32位机器(x64)就是4字节,64位机器(x86)就是8字节:
注:一个指针变量存放的地址就是CPU通过地址线将某变量的地址存放在指针变量所在内存空间不同环境地址总线数量不同,所以地址大小也就不同。
32位机器(x86)环境运行:
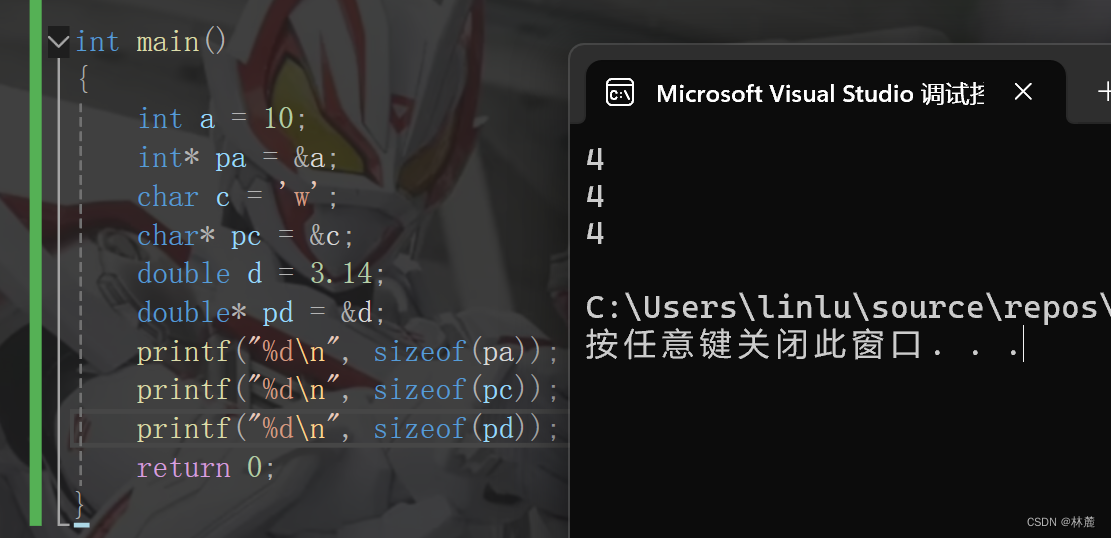
64位机器(x64)环境运行:
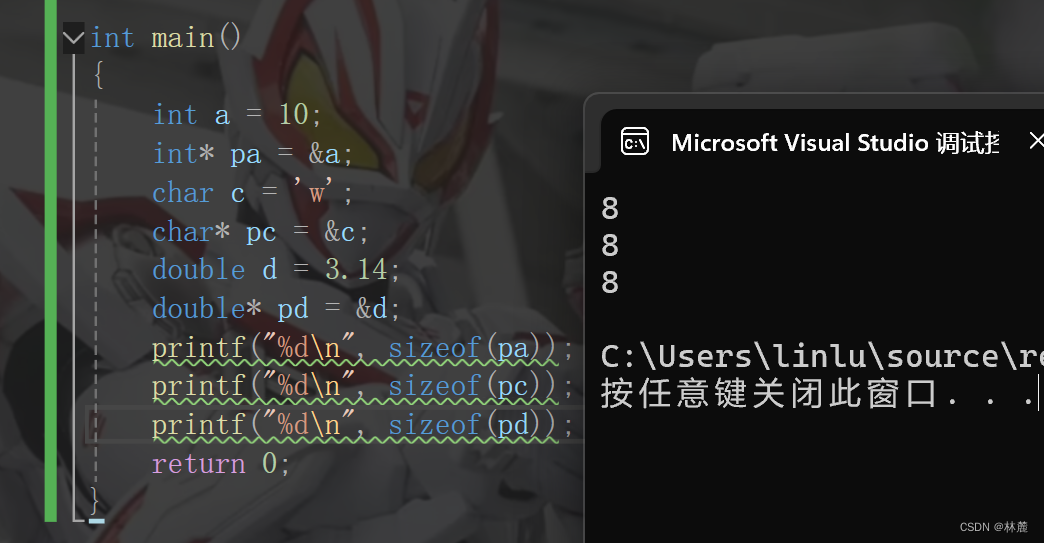
32位机器(32位平台)下的地址总线是32根,地址线上传输过来的电信号转换成数字信号后,得到32个0/1组成的二进制序列就是地址(64位机器就是64根地址线,地址线数量不同,表示地址二进制序列的大小也就不同)。
有句俗话就是:不要在门缝里看人,把人看扁了。这句话在当前场景就是不要在门缝里看指针,把指针看扁了。什么意思?就是不要看一个指针变量是int*,大小是4个字节。就以为另一个char*指针变量的大小就是1个字节。不管指针变量的类型一不一样,指针大小就是取决于地址的大小,和类型无关。
总结:
- 32位平台下地址是32个bit位,指针变量大小是4个字节。
- 64位平台下地址是64个bit位,指针变量大小是8个字节。
- 注意指针变量的大小和类型是无关的,只要指针类型的变量,在相同的平台下,大小都是相同的。
3、指针变量类型的意义
指针变量的大小是取决于地址在当前平台的大小,而不是取决于指针类型的。那指针类型真的只是简单的表示指针变量所指向的数据是什么什么类型的吗?有没有其他特殊的意义呢?答案是有的。
3.1 指针的解引用
先看下面两段代码在内存中调试的结果:
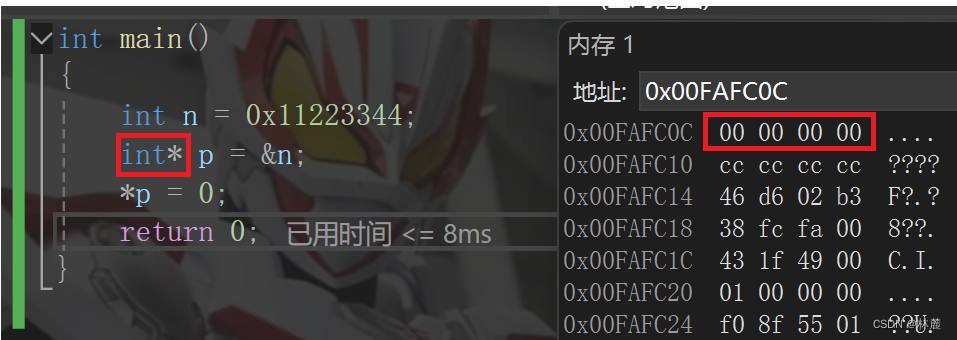

可以看到指针类型的不同导致了解引用时访问的内存单元大小不同,int*指针变量解引用时访问了4个字节的内存空间并将4个空间存储的值都修改为0。而char*指针变量解引用时只访问了低地址的那一个字节,解引用赋值时也只改动了一个字节。可以得知指针类型决定指针变量解引用时访问几个内存单元。
指针类型的里的类型int、char、double本来是表示指针变量指向的空间存储的什么类型的数据。所以解引用时访问多大内存空间也是类型决定的。类型的大小就决定了解引用访问空间的大小。
指针类型存储的是一个类型的地址,地址始终是指向一个字节的内存单元,如果是int*的指针变量,解引用时的访问权限是4个字节也就是4个内存单元,是会从当前的地址再向后访问几个地址的空间拿到4个内存单元大小的空间。
注意:指针的访问权限还是我们自己给的,如果把一个整型变量的地址给一个char*类型的指针变量,这个指针变量解引用只能访问到一个字节。所以我们在写程序时应该尽量使用对应类型的指针变量来接收该类型的地址。
3.2 指针+-整数
先看下面代码:
cpp
#include <stdio.h>
1 int main()
2 {
3 int n = 0x11223344;
4 int* p = &n;
5 char* pc = &n;
6 //指针p和p+1的地址
7 printf("p = %p\n", p);
8 printf("p+1 = %p\n", p + 1);
9 //指针pc和pc+1的地址
10 printf("pc = %p\n", pc);
11 printf("pc+1 = %p\n", pc + 1);
12 return 0;
13 }运行结果:
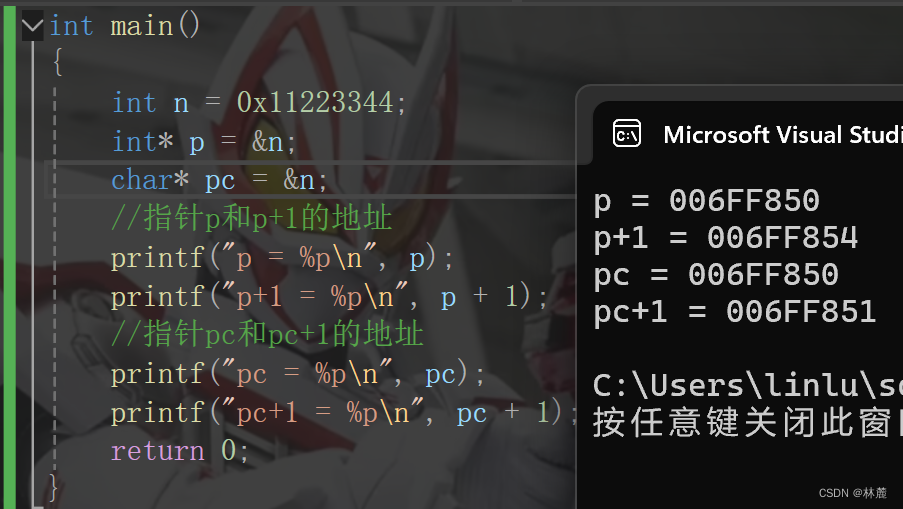
可以看到int*指针类型的p+1后地址+4,也就是跳过了4个内存单元的地址,char*指针pc+1后地址就+1,地址只跳过了1个内存单元的地址。指针类型变量指向的数据类型多大+1或-1跳过的空间大小就有多大。
指针类型除了决定解引用时访问内存单元大小,还可以决定指针变量+1跳过几个字节的空间。比如char*类型的指针变量+1拿到一个字节后的地址。int*类型的指针变量+1拿到跳过4个字节空间的地址。因为不同类型的指针变量需要跳过当前类型指针指向数据所占的空间去到下一个存储数据的地址。
指针类型的设计:
为什么这样设计指针类型?就是根据数据的类型大小,取出存储数据空间的地址用对应的数据类型解引用或+1、-1的操作能够刚好访问到这个大小的空间,或跳过这个数据所占内存的空间,如果当前指针指向的是double类型的数据,所占内存8个字节,那指针+1只能跳过一个字节需要+8次,不是很麻烦吗?为了方便+1能够刚好跳过这个指针指向数据的内存大小来到下一个元素的地址访问下一个元素,就给指针类型设计了指针类型+1或-1跳过内存空间的大小正好是指针指向数据类型的大小,double*类型的指针变量只需要+1就可以跳过double类型大小的8个字节的空间。
结论:
- 指针类型是有意义的。
- 指针类型决定了指针在解引用操作时的访问权限,也就是一次解引用访问几个字节的内存单元空间。
- 比如:char*类型的指针解引用时访问1个字节,int*类型的指针解引用时访问4个字节
- 指针类型决定了指针在+1/-1操作的时候,一次跳过几个字节(指针的步长)
可以发现指针类型决定的解引用正好拿取指针所
指向的数据类型大小,不多拿也不少拿。只要访问到指针指向的那个数据所占内存大小就可以了。+1/-1操作也能刚好跳过类型大小的字节空间的地址。
还需要注意的是,地址的访问权限不一定都是创建指针变量时给的。
比如有一个int类型的变量a,&a的地址本身就是int*类型的,&a+1也是跳过4个字节的,既然你取的是int变量的地址,那地址的类型自然就是int*的类型,不需要再额外定义int*的指针变量去给它int*类型的访问权限。
学到了上面的指针,知道了指针类型的作用,那怎么使用呢?
如果有一个整型数组arr,你想访问它里面的元素,该怎么访问呢?
方法一 :数组下标的访问,例如:
cppint arr[] = {1,2,3,4,5,6,7,8,9,10}; arr[6]、arr[3]、arr[9]方法二 :指针访问,例如:
cppint arr[] = {1,2,3,4,5,6,7,8,9,10}; int* parr = arr;//使用int*指针来接收 *(parr+6)、*(parr+3)、*(parr+9)*(parr+6)等价于arr6的,所以指针可以通过指针类型的特性去访问数组中的每个元素,在函数调用时传数组名时形参可以创建一个指针变量来接收数组名。
因为数组名是首元素的地址,本身就是地址,所以可以直接使用指针变量来接收该地址。
这里就需要给大家讲一下数组名本身就是首元素的地址,数组名是地址,所以是不能直接给数组名赋值的,只能改变这个地址所指向的空间的元素。
cppint arr1[] = {1,2,3,4,5,6,7,8,9,10}; int arr2[] = {1,2,3,4,5}; arr1 = arr2;//错误的,地址不能被赋值 arr1[0] = arr2[0];//正确的,可以通过解引用该地址访问空间并赋值 arr1==&arr1[0];//数组名是等价于首元素地址的
4、const修饰指针
4.1 const修饰变量
const是C语言中的一个关键字,也叫保留字。const的作用是将const修饰的变量改为常量属性,下次给这个变量赋值但是因为是常量属性所以不能改,改了就会报错。
给一个代码:
cpp
#include <stdio.h>
int main()
{
const int n = 10;
n = 20;
printf("%d\n", n);
return 0;
}运行后:

确实将变量n改变成了常量属性,无法直接赋值。
但是当你把这个const修饰过的变量的地址给一个指针,通过指针改变它可以发现真的能够改变:
cpp
#include <stdio.h>
int main()
{
const int n = 10;
int* p = &n;
*p = 20;
printf("n = %d\n", n);
return 0;
}运行结果:

我已经把n修饰为常量属性了,n不能改了,但是指针还可以改,相当于饶了一圈又将变量改了,指针并不在const的修饰范围。
举个例子: 前一年很火的电视剧狂飙,里面的高启强心狠手辣,是个黑恶势力,经常
人,并且不是他亲自动手。比如变量n就是高启强,他想

如果不想让限制这个变量不想被任何方法修改,怎么办?可以把指针也用const修饰。让老默也受到公安局的监视不就可以了
cpp
#include <stdio.h>
int main()
{
const int n = 10;
const int* p = &n;
*p = 20;
printf("n = %d\n", n);
return 0;
}运行后:

将指针也修饰const后,指针也不能修改这个变量了,只能访问,不能修改。
const修饰指针其实有两种修饰方法,一种是const放在*左边,另一种是const放在*右边。
假设有两个变量和一个指针变量:
cpp
int n = 10;
int m = 20;
int* p = &n;1.const放在*左边:
cpp
const int* p = &n;
*p = 30;//会报错
p = &m;//不会报错如果const放在*左边修饰的就是*p,指针指向的内容不能被修改了,但是指针变量本身是可以修改的。
cpp
int const *p = &n;等价于 const int* p = &n;2.const放在*右边:
cpp
int* const p = &n;
*p = 30;//不会报错
p = &m;//会报错const放在*右边直接修饰的是变量p,限制着指针变量本身。所以改变指针变量p地址指向是会报错的,但是可以修改指针指向的内容。
如果既不想让指针变量p改变地址指向,也不想让指针变量p改变p所指向的空间里存储的值,就左右各修饰一个const:
cpp
const int* const p = &n;
*p = 30;//会报错
p = &m;//会报错5、指针运算
指针的基本运算有三种,分别是:
- 指针+-整数
- 指针-指针
- 指针的关系运算
5.1 指针+-整数
因为数组在内存中是连续存放的,只要知道第一个元素的地址,顺藤摸瓜就能找到后面的所有元素
cpp
1 int arr[10] = {1,2,3,4,5,6,7,8,9,10};
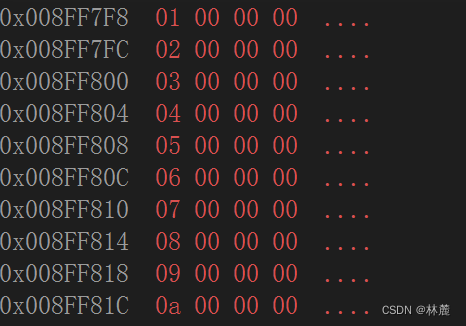
可以看到数组在内存中是连续存放的,是由低到高依次存储,大家观察一下,每个元素的地址与下一个元素的地址相差4个字节,这是因为数组的每个元素需要4个字节的内存单元来存储元素,所以每个元素的地址相差4个字节。
从这里我们得知了数组在内存中确实是连续存放的,我们是不是可以用指针访问整个数组的所有元素呢?答案是可以的:
cpp
#include <stdio.h>
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);//求出数组元素个数
int* p = arr;//等价于int* p = &arr[0];
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));//遍历访问数组的每个元素
}
return 0;
}运行结果:
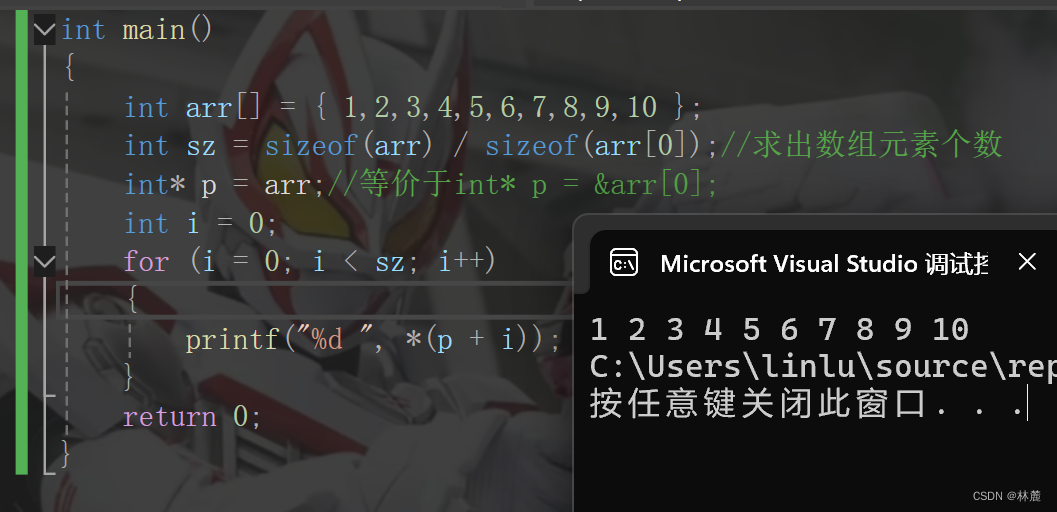
注意:使用指针遍历的前提是元素必须是连续存放的。
5.2 指针-指针
指针减去指针就是两个地址相减,得到的就是两个地址之间的元素的个数,如果是int*的指针,是以4个字节为一个元素单位计算的,如果是char*类型的指针是以1个字节为一个元素单位计算的。

指针-指针 (地址-地址) 的前提是两个指针指向同一块开辟好的数组空间,这就是语法规则。
所以不能这样:

运行结果是错误的,所以一定要遵循语法规则。
可以用指针减去指针做什么呢?
练习:指针-指针来模拟strlen库函数,求出字符串的长度:
cpp
#include <stdio.h>
int my_strlen(char* str)
{
char* str1 = str;//创建一个新的指针来接收这个地址
while (*str1 != '\0')//用新指针不停的遍历找到'\0'
{
str1++;
}
return str1 - str;//新指针('\0'的地址)减去形参指针(第一个字符的地址)
}
int main()
{
char str[] = "hello world";
int len = my_strlen(str);
printf("%d\n", len);
return 0;
}运行结果:
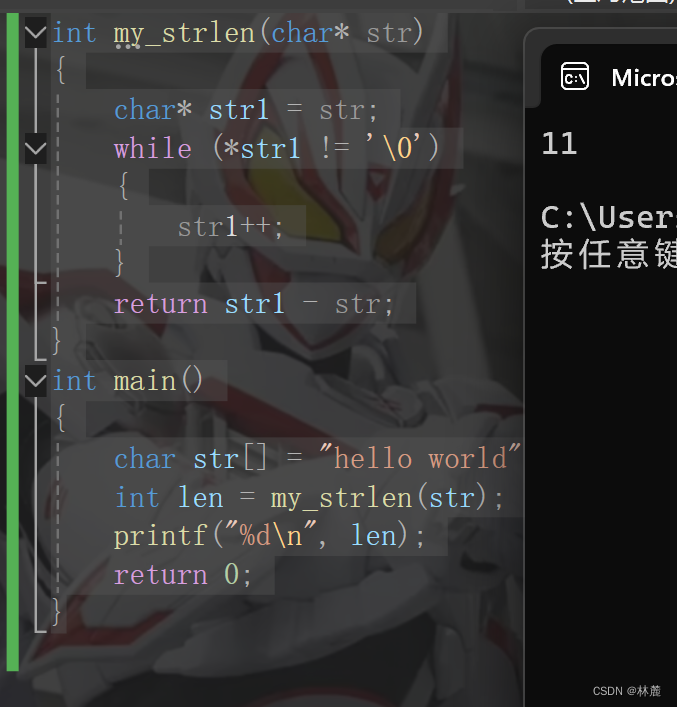
总结:
指针-指针必须指向同一块空间,可以相互运算。因为如果是&arr0+9就是&arr9,arr9-arr0就是9了,指针减指针也是看两个指针的类型求出它们之间的元素个数。
准确来说指针-指针求出的是以元素大小为单位的绝对值
指针-指针不能是两个不同变量空间的地址相减,1.如果类型不同不确定是用哪个类型来表示元素个数的元素。2.就算类型一样两个地址相减也没有什么意义,答案也不对,因为两块不同的空间中间会有未开辟的内存空间隔开,谁知道未开辟的内存空间里有多少元素个数。
5.3 指针的关系运算
所谓的指针关系运算,就是指针和指针(地址和地址)之间比较大小。高地址比低地址大,低地址比高地址小。
可以使用指针关系运算,判断一个指针是否小于另一个指针,如果小于则打印这个指针对应的数组元素。前提是要找到数组最后一个元素地址的下一个地址,再不停的进行比较,如果小于这个地址就访问地址指向的空间打印空间里的数据。
cpp
#include <stdio.h>
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);//求出元素个数
int* p = arr;//获取首元素地址
while (p < arr + sz)
{
printf("&数组元素:%d==", *p);
printf("%p < %p\n", p, arr + sz);
p++;
}
printf("%p == %p", p, arr + sz);
return 0;
}运行结果:
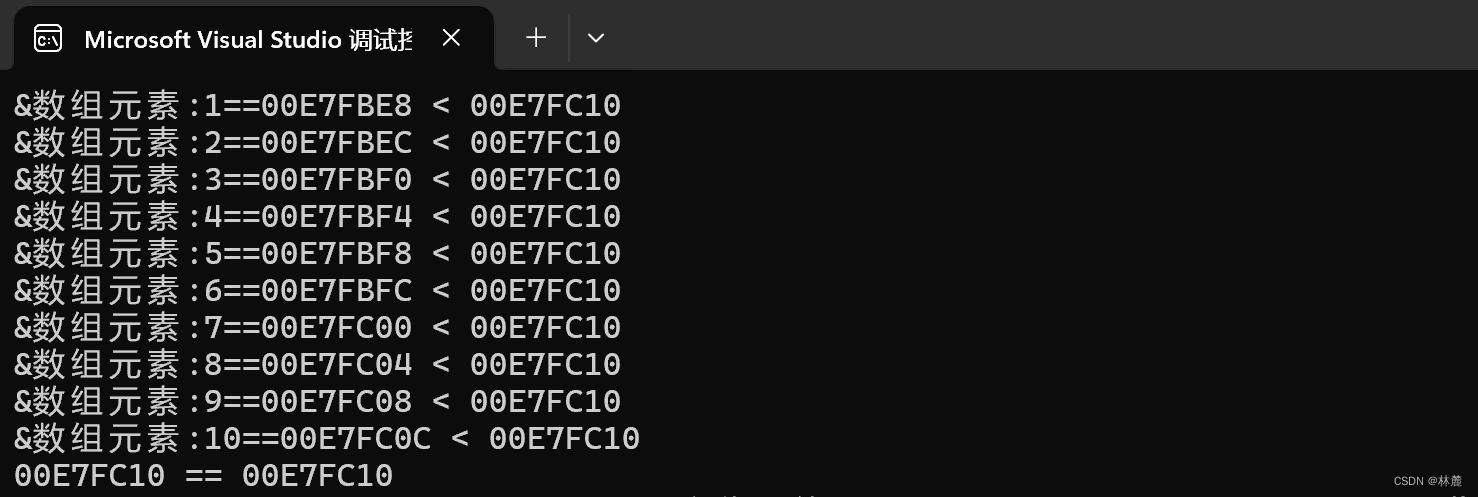
6、野指针
概念:野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)
6.1 野指针成因
1.指针未初始化
cpp
int main()
{
int* p;//局部变量,在创建的时候内存中存储的是随机值
*p = 20;//这时候给p随机值当做地址访问就是非法访问
return 0;
}在内存中的一块空间,你需要申请才能使用。像上面的未初始化的野指针,局部变量自动赋值为随机数,把随机数当成地址,这个地址指向的这块空间还未申请开辟,不属于当前的程序的内存空间。通过这个随机数地址访问指向的空间并赋值就是非法访问。
2.越界访问
cpp
int main()
{
int arr[10] = {0};
int* p = &arr[0];
int i = 0;
for(i=0;i<=11;i++)//判断表达式的判断已经超出了数组元素个数
{
*(p++) = i;
}
return 0;
}运行后:

编译器报错,因为越界访问了。
3. 指针指向的空间被释放了
cpp
int* test()
{
int n = 100;
return &n;
}
int main()
{
int* p = test();
*p = 20;
return 0;
}出了局部范围局部变量就会销毁,但是在出函数结束之前返回了一个局部变量n的地址给指针p,因为局部变量n的空间已经返还给操作系统了,所以p就是野指针了,再解引用访问就是非法访问。
6.2 如何规避野指针
6.2.1 指针初始化
如果创建了一个指针已经明确要让这个指针指向哪里就直接初始化那个地址。如果创建指针时还不知道指针明确要指向哪里时就先初始化为NULL,让这个指针指向一个NULL,也就是空指针。NULL是C语言中的一个标识符常量,值是0, 0也是地址,这个地址是无法使用的,读写该地址会报错。(使用时需要包含头文件**#include <stdio.h>**)
NULL标识符定义:
cpp
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void*)0)
#endif以上代码可以看到NULL的本质就是0,在cplusplus也就是C++上NULL是0,其他语言的NULL是把0强制类型转换成一个地址,但是也是一个空指针。所以NULL本质就是0。NULL本质是0那可不可以给指针直接初始化为0呢?
cpp
int* p = 0;当然可以直接初始化为0, 0和NULL是一样的。但是你给一个0就还要看一下变量是否是整型的变量。但是初始化NULL就可以知道我是给指针初始化为空指针的。就知道了是为指针初始化的。整型初始化可以用0,指针初始化尽量不用0,用NULL。这样代码可读性更高。
cpp
int* p = 0; 等价于 int* p = NULL;
指针初始化建议用int* p = NULL;6.2.2 小心指针越界访问
一个程序向内存申请了多大空间,通过指针就只能访问这个申请过的空间,不能超出范围访问,超出了就是越界访问。
6.2.3 指针变量不再使用时,及时置为NULL,指针使用之前检查有效性
在创建指针时暂时不想使用时就初始化为空指针。接下来在使用这个指针之前先判断这个指针是否为NULL,不为NULL就可以解引用访问。
cpp
int main()
{
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int* ptr1 = arr;
int* ptr2 = NULL;
if(ptr1!=NULL)//使用之前进行判断
{
//使用ptr1
}
if(ptr2!=NULL)
{
//使用ptr2
}
return 0;
}6.2.4 避免返回局部变量的地址
不要返回局部变量的地址,因为出了局部变量的局部范围局部变量的空间就会自动销毁并返还给操作系统,再对这块空间访问就是非法访问。
7、assert断言
assert.h头文件定义了宏assert(),用于在运行时确保程序符合指定条件,如果不符合,就会报错终止运行。这个宏常常被称为 "断言"。
cpp
assert(p != NULL);上面代码在程序运行到这一行语句是,验证变量p是否等于NULL。如果确实不等于NULL,程序继续执行,否则就会终止运行,并且报错误信息提示。
assert和if一样是可以进行判断的,如果为真返回非0,如果为假则返回0。虽然都可以判断,但是它们有一点还是不一样的。就是如果判断为假后的区别反应。
assert和if的判断区别:
如果是if判断为假就走else或者继续执行下一条语句,只是不进入if语句内执行。
如果是assert判断为假会终止程序的运行并在标准错误流stderr中写入一条错误信息,显示没有通过的表达式,以及包含这个表达式的文件名和行号。
以上就是两种判断的区别,如果需要调用的指针不能为空指针时就可以使用assert。
assert()的使用对程序是非常友好的,使用assert有几个好处:它不仅能自动标识文件和出问题的行号,还有一种无需更改代码就能开启或关闭assert()的机制。如果已经确认程序没有问题,不需要再做断言,就在**#include <assert.h>** 语句的前面,定义一个宏NDEBUG。
cpp
#define NDEBUG
#include <assert.h>然后重新编译程序,编译器就会禁用文件中所有的assert()语句。如果程序又出现问题,可以移除这条#define NDEBUG 指令,再次编译,这样就重新启用了assert()语句。
缺点:assert()的缺点是,因为引入了额外的检查,增加了程序的运行时间。
8、指针的使用和传址调用
学习了指针的知识,那指针该怎么使用呢?
8.1 传址调用
我们平常使用指针时一般在同一个局部范围创建指针接收变量的地址修改变量,我们最常使用指针的地方就是函数传参,因为直接将变量作为实参传递给函数,函数的形参接收到的只是实参的一份临时拷贝,形参的修改并不会影响到实参。但是如果我们需要一个函数来交换两个变量的值该怎么办?我们最先想到的方法是:
cpp
void Swap(int x,int y)
{
int z = 0;
z = x;
x = y;
y = z;
}
int main()
{
int a = 10;
int b = 20;
printf("交换前:a=%d b=%d\n",a,b);
Swap(a,b);
printf("交换后:a=%d b=%d\n",a,b);
}运行结果:

直接传参由形参接收,但是因为形参是实参的一份临时拷贝,形参里的修改不会影响到实参。实参不会改变,怎么办?我们可以使用传址调用。就是将变量的地址作为实参传递给函数,函数的形参为指针,用指针来接收这个地址。在函数中可以使用形参访问这块地址并修改,相当于有了远程连接:
cpp
void Swap(int* x,int* y)
{
int z = 0;
z = *x;
*x = *y;
*y = z;
}
int main()
{
int a = 10;
int b = 20;
printf("交换前:a=%d b=%d\n",a,b);
Swap(&a,&b);
printf("交换后:a=%d b=%d\n",a,b);
}运行结果:
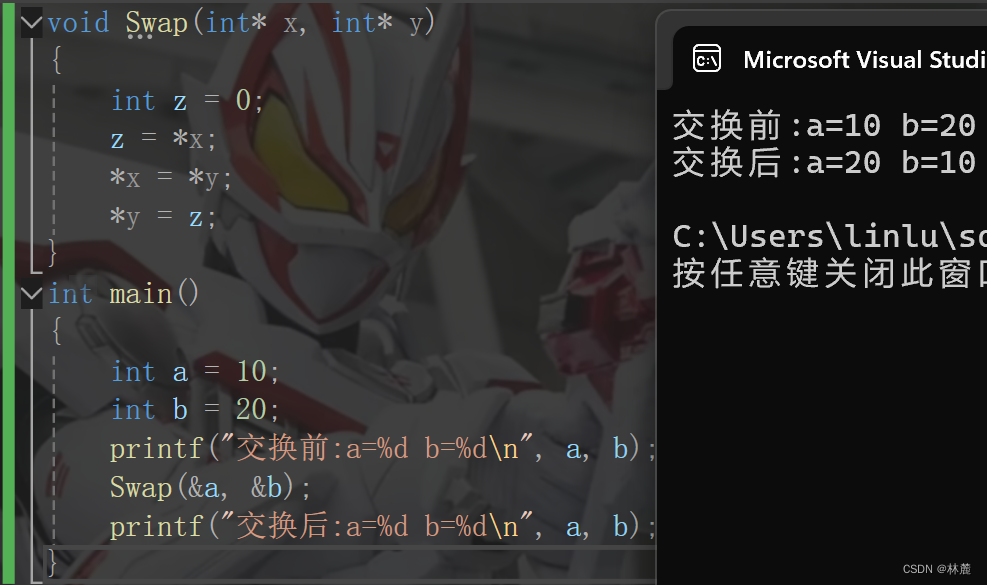
函数传参有两种:传址调用、传值调用
传值调用:就是直接将变量传递给函数,函数接收它的临时拷贝,就叫传值调用。
传址调用:就是将地址作为参数传递给函数,函数接收它的地址,可以通过这个地址直接访问它,就叫传址调用。
8.2 strlen的模拟实现
cpp
#include <stdio.h>
size_t my_strlen(const char* str)
{
assert(str != NULL);//确保了指针的有效性
size_t count = 0;
while (*str != '\0')
{
count++;
str++;
}
return count;
}
int main()
{
char arr[] = "hello world";
size_t len = my_strlen(arr);
printf("%zd\n", len);
return 0;
}size_t 是无符号整型,是专门为sizeof发明的类型。因为sizeof计算一个变量或类型的空间不可能返回一个负数大小的空间,所以返回类型为size_t。但是strlen和sizeof一样,计算字符串长度是不可能返回负数,最少也是0,所以strlen的返回值也是无符号数,用size_t来作为strlen的返回类型。
深入理解指针(2)
**1、**数组名的理解
cpp
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int* p = &arr[0];这里我们使用的&arr0的方式拿到了数组第一个元素的地址,但是数组名本来就是地址,而且是数组首元素的地址,给一段代码:
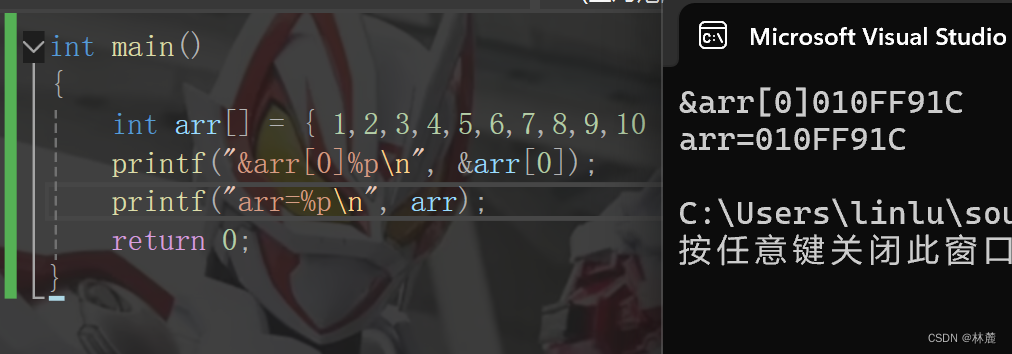
可以看到数组名就是首元素的地址。但是有2个例外:
- **sizeof(arr)**这里的数组名表示的是整个数组,所以sizeof(数组名)计算的是整个数组的大小,单位是4个字节。
- &arr这里的数组名表示的是整个数组,取出的是整个数组的地址,+1或-1可以跳过整个数组
除此之外遇到所有的数组名都是首元素地址。

来看三个数组名的地址和+1后跳过的多大一块空间:

可以看到虽然&arr是整个数组的地址,但是不代表整个数组需要的空间有独立地址。所以整个数组的地址依然是首元素的地址,只不过+1跳过多大空间的权限为整个数组的大小。&arr0和arr都是int*类型的地址,+1跳过4个字节。但是&arr是什么类型的地址?&arr是数组指针类型的地址,int(*)10就是&arr的指针类型。(数组指针后期会讲解)
为了让大家更加深刻的理解数组名,下面给一段代码:
cpp
#include <stdio.h>
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}我们除了使用arri遍历访问整个数组元素,我们还可以使用什么方法访问数组呢?
cpp
printf("%d ",*(arr+i));这样也可以访问每个元素,arr本身是数组首元素地址,地址+i再解引用就访问到了对应的元素。所以:
cpp
arr[i]==等价于==*(arr+i)arri只是一种形式,在编译阶段arri会被编译为*(arr+i),所以可以证明 只是操作符。
既然arri等价于*(arr+i),arri的原型就是*(arr+i),加法又是支持交换律的。那我可以将*(arr+i)写成*(i+arr),那是不是也可以写成iarr格式呢?
cpp
printf("%d ",*(i+arr));
printf("%d ",i[arr]);答案是可以的:
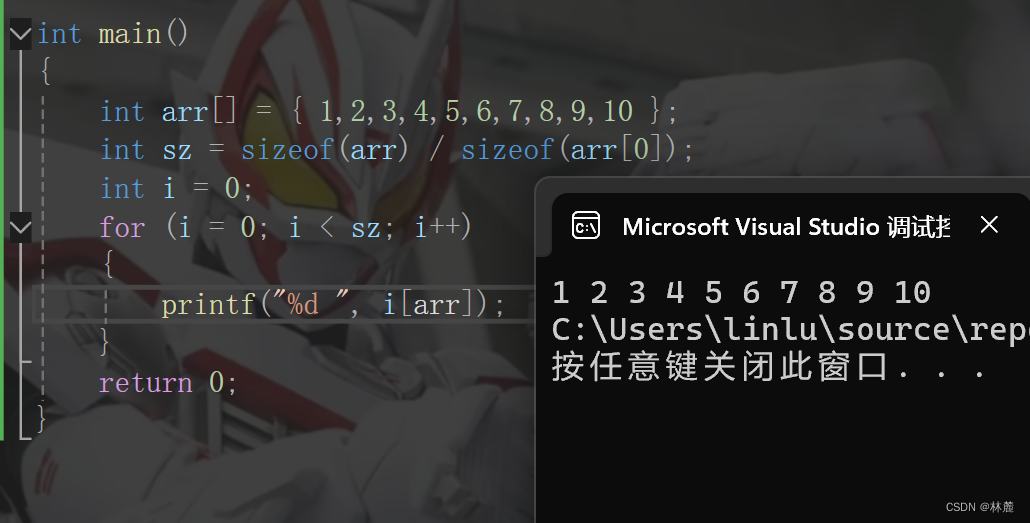
这更加说明了arri或iarr只是一种形式,并不是固定的格式必须arri。arri只是一种形式,真正的运算还要转换成*(arr+i)进行运算。但是这里讲iarr只是让大家对数组名有更深刻的理解,只是不让大家的思维局限于arri,但是写代码时最好不要写成iarr这种形式,虽然可以访问,但是很难理解,可读性差。
2、数组传参的本质
先看下面的代码:
cpp
#include <stdio.h>
void print(int arr[])
{
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for(i=0;i<sz;i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
print(arr);
return 0;
}运行结果:
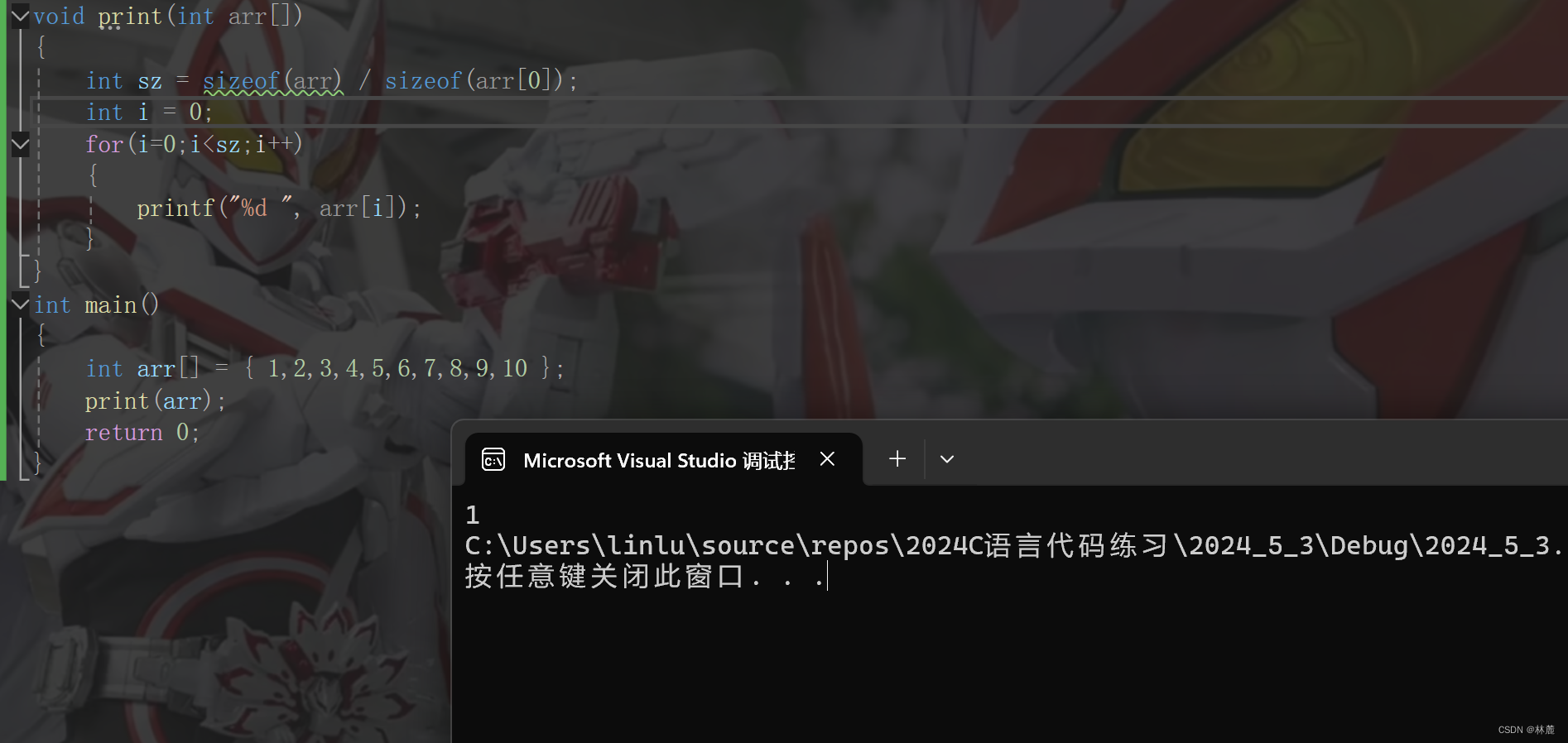
不是应该从1-10依次打印吗?怎么会只打印了1。这就要关系到数组传参的本质了。数组名传参就是将数组名首元素的地址传给函数。既然是地址,sizeof(arr)就是求地址的大小/sizeof(arr0)元素大小,因为是x86环境所以是4/4,sz=1。所以只打印了一次。
但是有人觉得奇怪了,为什么在main函数里创建的数组的数组名也是首元素地址,但是sizeof(数组名)里的数组是整个数组。为什么传参后就不是了。这是因为在传参之前的数组名不仅仅是作为数组首元素地址而存在的,此时的数组名身上可是还有多种buff加身的。但是传参时传的仅仅只是首元素地址,而不是数组名本身。可以理解为实参数组名拷贝了一份首元素地址信息传给函数。所以函数拿到的只是一个地址。能代表整个数组的是数组名,而不是首元素地址。
所以不要被上面代码中传递实参用数组接收就以为是还是个数组,这里数组名传参传的既不是整个数组又不是数组名,本质上数组传参传递的是组首元素的地址。
cpp
#include <stdio.h>
void print(int* arr)
{
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for(i=0;i<sz;i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
print(arr);
return 0;
}如果将形参的类型改变为指针就可以看懂了吧,其实就是用指针接收首元素地址。sizeof(地址)得到的就是地址的大小,上面之所以可以用int arr 数组的形式接收是因为传的本来就是数组地址,所以可以使用这种格式来表示,但是不代表这里的arr就是数组。
所以就不要在函数内部求形参数组的大小了,函数形参的数组只是一个首元素地址。也就是指针。
那有什么解决方法,在函数内部遍历整个数组呢?
cpp
#include <stdio.h>
void print(int* arr, int sz)
{
int i = 0;
for(i=0;i<sz;i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
print(arr, sz);
return 0;
}运行结果:
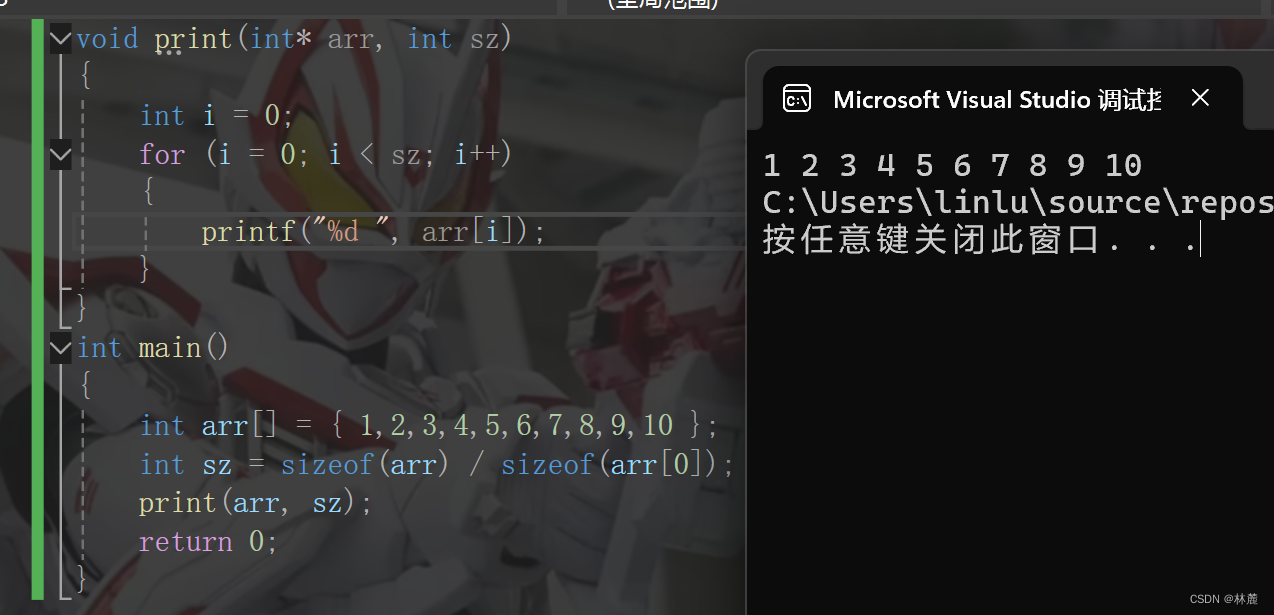
在传参之前算出数组元素个数,然后将算出的元素个数也通过传参传过去。
总结:一维数组传参,形参的部分可以写成数组的形式,也可以写成指针的形式。
3、冒泡排序
冒泡排序是一种数组排序的算法,这种排序就像汽水里的气泡一样不停的从下往上面冒泡,所以名为冒泡排序(bubble sort)。
冒泡排序的算法思想就是需要排序n-1趟,每一趟排出最大的数在位置最后。因为这种方法最多n-1趟就可以将数组排序完毕。因为每次筛选最大值排在最后,有n个数,n-1个数筛选完后最后一个数必定是在第一个,也就是最小值。经过第一趟排序需要n-1次判断两个相邻的数,如果前面大于后面的就调换。算上排最大值本身,与其他的值经过筛选判断也只需要n-1次判断排出最大值。每一趟排出最大数下一趟排序的n-1需要再减去前面已经排过的趟数。因为每一趟都排出最大值下一趟就不需要对最大数也进行判断,只需要判断已排序最大值前面的那些值就可以了。

既然知道了冒泡排序算法的思想,那接下来就实现冒泡排序算法:
cpp
int main()
{
int arr[] = { 10,9,8,7,6,5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);
int i, j;
for (i = 0; i < sz - 1; i++)//循环排序n-1趟
{
int flag = 1;//假设顺序是正确的
for (j = 0; j < sz - 1 - i; j++)//循环n-1-i次判断并调换找出最大值
{
if (arr[j] > arr[j + 1])
{
int s = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = s;
flag = 0;//设置为需要排序
}
}
if (flag == 1)//假设一趟下来没有任何排序的值,说明已经不再需要排序,跳出循环排序
{
break;
}
}
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}运行结果:
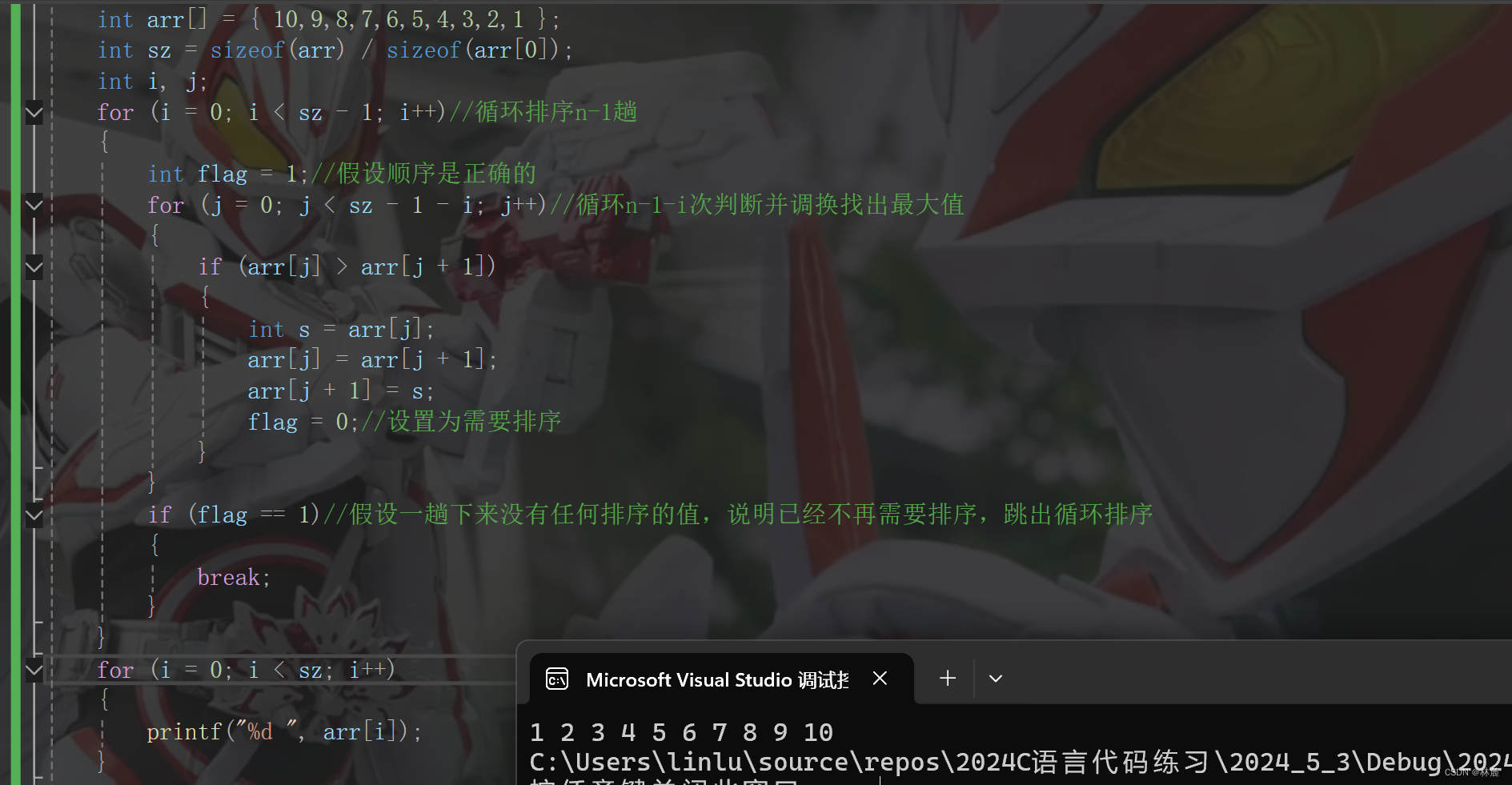
4、二级指针
什么是二级指针?它的作用是什么?
cpp
int a = 10;
int* p = &a;a是一个int类型的变量,它有4个字节的空间,这块空间也有地址。取出a的地址初识化给一个指针变量p,p需要创建4/8个字节的空间来存放这块地址。但是这块空间有没有地址呢?答案是有的。我们将指针变量p空间的地址取出来(注意,不是这块空间里存储的变量a的空间,而是存储这个地址的空间的地址),指针变量p的地址需要创建二级指针来接收。那什么是二级指针呢?
cpp
int a = 10;
int* p = &a;
int** pp = &p;int**是二级指针,那int*就是一级指针,指针的级数是通过地址的层级来决定的。
看上面这段代码pp就是二级指针,它是用来接收一级指针地址的,将int**拆分开来看是这样的:
cpp
int a = 10; int说明a存储的整型变量的值
int * p = &a; 这里的*说明p是指针变量,int说明p指向的是int类型
int* * pp = &p; 这里的*说明pp是指针变量,int*说明pp指向的是int*类型其实一级指针p和二级指针pp都是指针变量,都是开辟了4/8个字节存储的地址,不同的是指向的类型不同。一级指针是指向类型变量的,存储的是普通类型变量的地址。二级指针是指向一级指针的,存储的是一级指针的地址。
所以有二级指针就有更高级别的指针,例如三级指针就是存储二级指针空间的地址:
cpp
int a = 10;
int* p = &a;
int** pp = &p;
int** * ppp = &pp; *说明ppp是指针变量,int**说明ppp指向的是二级指针
既然二级指针指向一级指针,一级指针又指向变量。那是不是可以用二级指针直接访问变量的空间?当然是可以的:
二级指针pp解引用两次访问到了变量a的空间,*pp第一次解引用通过一级指针空间的地址访问到一级指针的空间,然后再**pp解引用一次通过一级指针空间里存储的地址访问到变量的空间。
简单理解多级指针之间的关系:
5、指针数组
什么是指针数组呢?
我们可以类比一下:
- 整型数组 - 存放整型的数组 int arr10;
- 字符数组 - 存放字符的数组 char str10;
那指针数组就是存放指针的数组,指针数组的元素类型可就多了:int* char* double*的都有。
比如:int* parr5;就是指针数组的创建,这是一个数组,是存放多个整型指针的数组。
数组的每个元素是数组的类型:
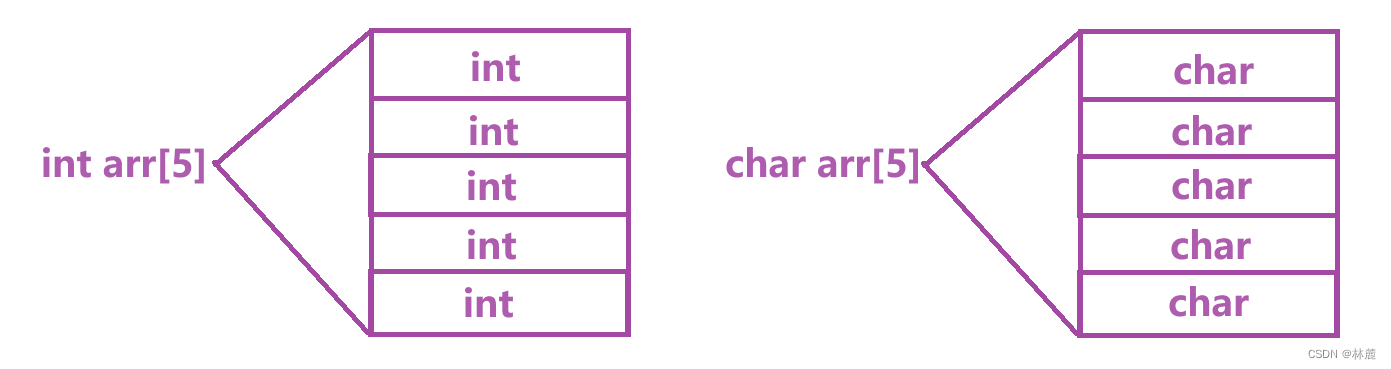
指针数组的每个元素都是用来存放地址(指针)的。
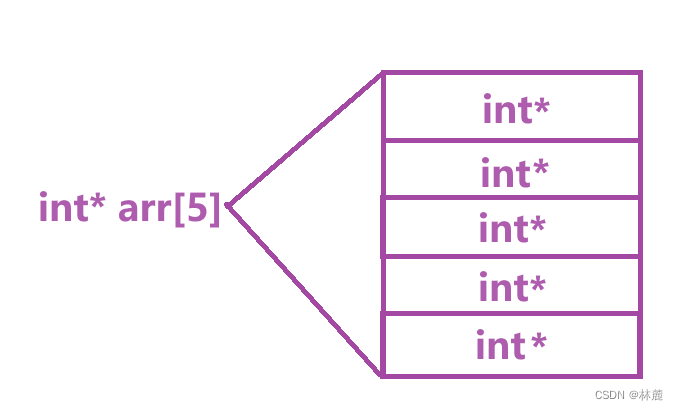
数组指针的每个元素是地址,又可以指向一块区域。
那有人会问既然数组指针是存放指针的,那是不是就可以这样使用:

能用是能用,但是很少会这样去使用指针数组的,如果只是为了打印12345直接创建个数组遍历不就好了吗?
看上面的代码,parr通过下标访问到元素时元素还是一个地址,需要再一次解引用才能访问到变量。这里的下标访问也是一次解引用,那两次解引用就可以证明这里的数组名的类型是一个二级指针,我也可以使用二级指针来接收parr首元素地址。就比如int类型的数组名arr,它是首元素的地址,指向int类型。它是一个指向int类型的地址那这个地址的类型就是int*,arr首元素的类型就是int*指针。
cppint* p = arr; int** pparr = parr;
如果指针数组不是这样使用的,那该怎么使用呢?
6、指针数组模拟二维数组
指针数组一般使用方式就是类似模拟二维数组,就是有多个数组,指针数组可以将每个数组的数组名(首元素地址)作为指针数组的元素,每次解引用访问到该首元素地址就可以继续锁定这个数组其他元素的地址找到元素地址并访问:
cpp
#include <stdio.h>
int main()
{
int arr1[5] = { 1,2,3,4,5 };
int arr2[5] = { 2,3,4,5,6 };
int arr3[5] = { 3,4,5,6,7 };
int* parr[3] = { arr1,arr2,arr3 };
int i, j;
for (i = 0; i < 3; i++)
{
for (j = 0; j < 5; j++)
{
printf("%d ", parr[i][j]);
}
printf("\n");
}
return 0;
}运行结果:
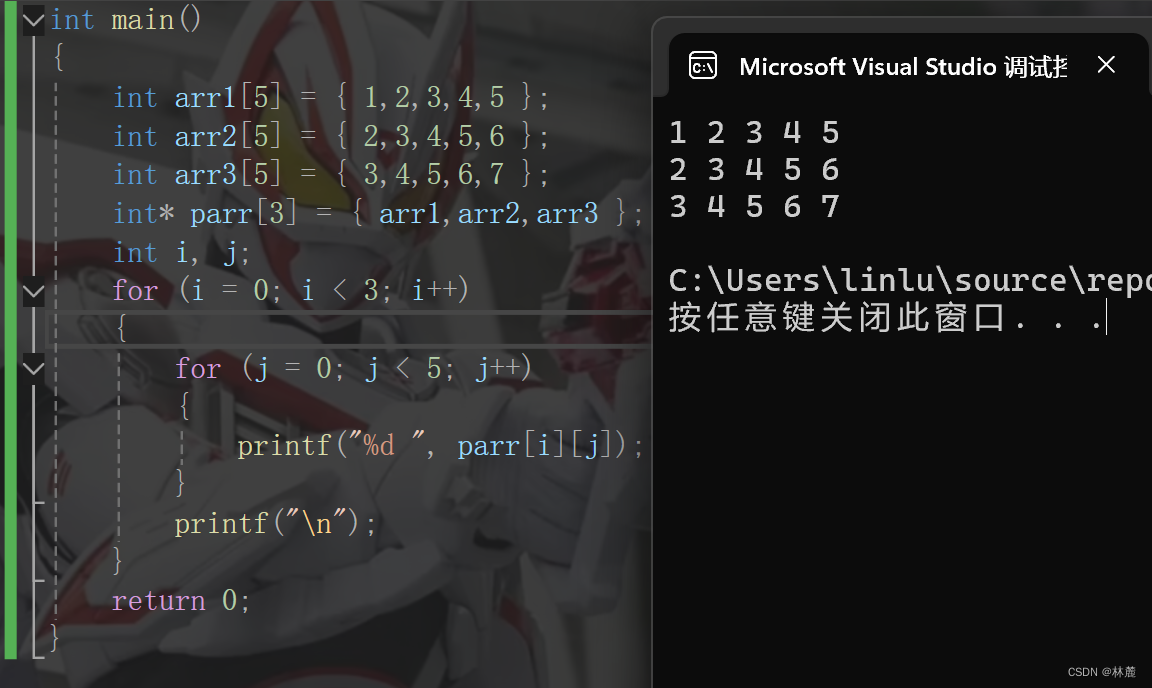
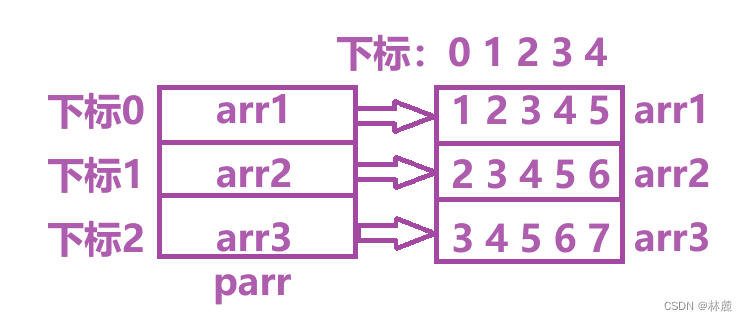
深入理解指针(3)
1、字符指针
字符指针的使用方法是什么?
cpp
char ch = 'a';
char* pc = &ch;一般是使用字符指针接收一个字符型的变量的地址。其实字符指针还可以这样使用:
cpp
char* p = "hello world";这个字符串有11个字节的大小,这么大的字符串怎么能初识化给字符指针呢?如果好好想一想其实字符串也是有首元素地址的。将 "hello world\0" 初始化给字符指针p,并不是表面上把一整个字符串存放在指针p的空间中,而是将字符串的首元素地址初始化给指针p,p拿到的就是首元素地址。p可以通过这个地址继续访问后面的元素。
其实表达式都是有2个属性的:值属性、类型属性
比如b = 2+3;
2+3 值是5(值属性)
2+3类型是int(类型属性)
那上面的字符串 "hello world\0"也是有值属性和类型属性的,它的值属性就是首字符 'h' 的地址,它的类型属性就是char*。所以上面代码中的字符串只是将首元素地址传递给了字符指针p。

注意:直接给字符指针初始化的字符串是常量字符串,是不能被修改的。
就好像你对一个常量3修改为常量5,3=5这样是不行的,常量是不能够被修改的。
如果修改了程序就会崩掉:

解决方法:在p的左边加一个const,不能对地址指向的空间进行修改。
给一道经典的笔试题,让大家更深刻的了解字符指针初始化字符串:
cpp
#include <stdio.h>
int main()
{
char str1[] = "hello world";
char str2[] = "hello world";
char* str3 = "hello world";
char* str4 = "hello world";
if (str1 == str2)
{
printf("str1 and str2 are same\n");
}
else
{
printf("str1 and str2 are not same\n");
}
if (str3 == str4)
{
printf("str3 and str4 are same\n");
}
else
{
printf("str3 and str4 are not same\n");
}
return 0;
}这段代码给了两个字符数组和两个字符指针,并且都是初始化为 "hello world",所以都是首字符地址。然后判断两个字符数组的地址是否相同。再判断两个字符指针的地址是否相同。来猜一猜结果
答案是:

两个字符数组地址各不相同,两个字符指针地址相同。为什么?
首先两个字符数组地址肯定是不想同的,虽然字符串相同,但是两个数组是各自开辟了一块空间来存放字符串,所以地址不相同。两个指针存放的是常量字符串的首元素地址,为什么相同呢?因为在给指针初始化字符串时是常量字符串,常量字符串是不能修改的,所以没有必要保存两份。所以两个指针所指向的常量字符串是共用一个,可以使用,但是都不能修改。
所以像这种常量字符串,在内存中只保留一份。

2、数组指针变量
首先要认识到,之前的指针数组是数组,是存放指针的数组。
接下来学习的:数组指针
类比:
字符指针 - 指向字符的指针,存放的是字符的地址 char ch = 'w'; char* pc = &ch;
整型指针 - 指向整型的指针,存放的是整型的地址 int n = 100; int* p = &n;
数组指针 - 指向数组的指针。存放的是数组的地址 int arr10; int(*p)10 = &arr;
cppint arr[10]; int (*p)[10] = &arr;注:这里说指向数组的指针不是存储数组首元素地址的指针,而是存储指向整个数组的地址的指针。
cppint arr[6]; int* p = arr; 数组首元素的地址 int (*p)[6] = &arr; 数组的地址(*p)两边的括号是不能省略的:
cppint (*p)[10];//数组指针 int *p[10];//指针数组如果是指针数组的话,p10说明p是个数组,元素类型是int*。
但如果是数组指针的话用(*p)将p和10分开,*表示p是指针变量,指向的是int10整型数组,数组有10个元素。
注意:数组指针的 10 里面的10也是不能省略的,因为数组指针需要明确知道它指向的数组有几个元素的大小,才能给数组指针变量p多大的访问权限。比如:p+1就能跳过40个字节的空间。这就是10的作用,10就是整个数组的大小。可以理解为数组指针p能够跳过arr数组大小的空间。所以 坚决不能为空,10就是要明确指针数组p所指向的arr数组的大小,也决定了这个指针数组的权限。
这里数组指针p的类型是:
cpp
int (*)[10]如果创建了一个char*类型的指针数组,该怎么用数组指针接收地址:
cpp
char* ch[8];
char* (*ch)[8] = &ch;*说明ch是指针,指向的是char*8类型的数组。
之前提到过&arr的的指针类型:
cpp
int arr[10] = {0};
arr; 数组首元素的地址 - int*
&arr; 数组的地址 - int (*)[10]这里的arr指针类型是int*,权限为4个字节,arr+1就跳过4个字节。&arr的指针类型是int(*)10,权限为40个字节,因为10个元素,每个元素是int类型也就是4个字节。所以&arr+1就跳过40个字节。
知道了数组指针是不是就可以这样写代码:
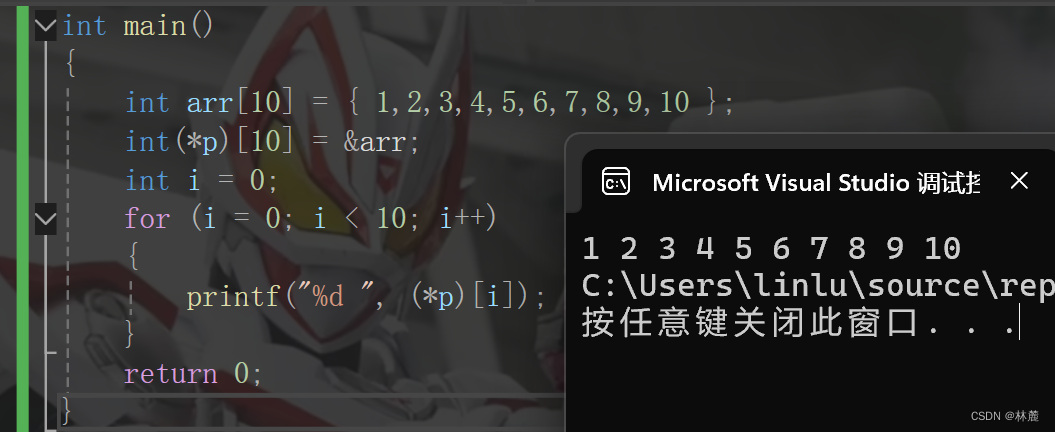
虽然可以这样写,但是大家会不会感到别扭。就是为什么要取出整个数组的地址在解引用得到arr再遍历访问,这样不是多此一举吗?
那数组指针有没有适用场景呢?答案是:有的。
3、二维数组传参的本质
如果清楚了二维数组传参的本质,那数组指针的使用场景也就清楚了。
二维数组传参:
cpp
#include <stdio.h>
void print(int parr[3][5], int r, int c)
{
int i, j;
for (i = 0; i < r; i++)
{
for (j = 0; j < c; j++)
{
printf("%d ", parr[i][j]);
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} };
print(arr, 3, 5);
return 0;
}用int arr35作为形参的传参方式,但是除了这个,还有哪些二维数组传参方式呢?
还可以使用数组指针作为形参来接收二维数组arr的首元素地址。
例如:
cpp
#include <stdio.h>
void print(int(*parr)[5], int r, int c)
{
int i, j;
for (i = 0; i < r; i++)
{
for (j = 0; j < c; j++)
{
printf("%d ", *(*(parr+i)+j));
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} };
print(arr, 3, 5);
return 0;
}
cpp
*(parr+i)等价于parr[i] 访问行(一维数组)
*(*(parr+i)+j)等价于parr[i][j] 访问列(一维数组元素)因为二维数组的每一行是一个一维数组。这一个一维数组可以看做是二维数组的一个元素。所以二维数组是一维数组的数组。二维数组数组名也表示首元素的地址,也就是一维数组的地址。一维数组的地址是数组指针类型的,所以传参时可以使用数组指针来接收。
简单概括:二维数组的每个元素就是一维数组,二维数组的数组名也表示数组首元素的地址,就是第一行(一维数组)整个数组的地址。
总结:一维数组int arr5的每个元素是int类型的值,&每个元素所在的地址是int*类型的。二维数组int arr35的每个元素都是一个一维数组。&每个元素取出整行(一维数组) 的地址是int(*)5类型的。5里的5是列的个数。
arr是二维数组的数组名,*arr就是第一行(一维数组)的数组名。
值得了解的是,二维数组数组名本身就是元素的地址,可以通过+-整数拿到每个元素的地址。当解引用时拿到的就是一维数组的数组名,也就是一维数组的首元素地址。再经过+-整数可以访问一维数组也就是一行里所有的元素。这就是二维数组需要两次解引用。所以二维数组数组名+-整数的地址就是一行(一维数组)的地址也就是int(*)5数组指针类型。但是需要知道二维数组并不是上面的指针数组模拟二维数组。将多个不同也就是不相连的一块一维数组空间的地址作为指针数组的元素,+1来到下一个元素的地址但是这个地址和上一个元素的地址不相连。但是二维数组不同,它里面所存储的每一个元素都是由低到高依次存储的,是一块完整相连的二维数组空间。那为什么二维数组数组名+1能跳过一行(一维数组)里5列元素。那是因为它的地址访问权限就是这个大小。解引用时访问权限就是一维数组的元素类型的大小。
不管是二维数组名首元素地址还是解引用后访问到二维数组的元素一维数组的首元素地址,都是同一块空间的地址,并不是把每一行放在不同的空间。访问权限不同只不过是当前地址类型不同罢了。有时候二维数组名arr是首元素的地址0x12ff40,解引用数组名*arr的一维数组首元素地址也是0x12ff40。虽然是同一个地址,但是+-整数的访问权限不同。二维数组数组名是为了访问每个元素一维数组的,访问权限是一个一维数组的大小。*arr是一维数组,+-整数是访问一维数组里每个int类型的元素,所以访问权限就是4个字节。

4、函数指针变量
数组指针 - 是指向数组的指针 - 是存放数组地址的指针
函数指针 - 是指向函数的指针 - 是存放函数地址的指针
那函数的地址是不是对函数名&呢?

4.1 函数指针变量的创建
可以看到&Add的地址和Add的地址一模一样,说明Add函数名本身就是函数的地址。
知道了函数的地址,那函数指针又是什么格式的呢?
函数指针的写法和数组指针十分有九分的相似:
cpp
int Add(int x,int y);
int (*pf)(int x ,int y) = &Add;*说明p是指针,(int x,int y)是指向函数的参数,int是指向函数的返回类型。整体就是函数指针。
但是因为Add本身就是函数的地址,所以不用再额外的&地址,而且这个函数指针还可以改造:
cpp
int Add(int x,int y);
int (*pf)(int ,int) = Add其实函数指针()里只需要填指针指向函数形参的类型,只需知道指针指向函数的参数是什么类型的就可以,变量名字不用填写。
4.2 函数指针变量的使用
通过函数指针调用指针指向的函数:
cpp
#include <stdio.h>
int Add(int x, int y)
{
return x + y;
}
int main()
{
int (*pf)(int, int) = Add;
int ret = (*pf)(10, 20);
printf("%d\n", ret);
return 0;
}运行结果:

可以看到通过函数指针变量可以找到函数并调用。但是前面我们知道Add函数名它本身就是地址,我们每次调用函数时是**函数名(实参)**的方式调用,这里说明不用解引用地址就可以直接通过地址调用函数。既然函数指针pf已经被赋值了Add函数的地址,那我使用pf时是不是就不用解引用再调用,可以直接拿着这个地址调用:
cpp
int (*pf)(int, int) = Add;
int ret = pf(10, 20);运行结果:

这里可以证明每次调用函数时都是直接通过函数名也就是函数地址调用函数,不用解引用。
4.3 两端有趣的代码
代码1:
cpp(*(void (*)()) 0 )();首先需要知道地址本身就是一个int类型的值,假设我有一个int类型的变量a,我&这个变量a的地址时会将它的地址自动转换成对应的指针类型。但是如果我直接拥有一个int类型的地址:0x0012ff40,我想调用它指向的int类型的空间,但是它是int类型无法直接解引用。那我可以将它强制类型转换成int*类型(int*),0x0012ff40此时就是有4个字节的访问权限的地址。解引用就会找到这个地址指向的那4个字节的空间。
注:这里可以说明我们是可以将一个整型的值强转成指针类型的地址并访问。
所以上面的代码里的0就可以看作int类型的0x00000000,就是将0x00000000强制转换成函数指针类型地址,变为地址就可以调用这个地址处的函数。
代码2:
cppvoid (* signal(int , void (*)(int) ) )(int);先把看signal(int , void (*)(int))可以看出是一个函数,参数是整型int和函数指针void(*)(int),但是函数参数肯定不可能只有类型没有变量名,所以可以看出这是一次函数声明,就是声明signal这个函数,函数声明时可以不用填写变量名,明确有什么类型就可以了。但是函数声明得有类型,那这次函数声明的函数的返回类型是什么?如果将signal(int , void (*)(int))拿出来剩下的就是函数指针void(*)(int),说明函数的返回类型是函数指针。最后再看上面代码是返回值类型为函数指针类型的函数的声明。
4.3.1 typedef关键字
typedef 是用来类型重命名的,可以将复杂的类型,简单化。
比如,你觉得unsigned int 写起来不方便,如果能写出uint 就方便多了,那么我们可以使用:
cpp
typedef unsigned int uint;
//将unsigned int 重命名为 uint
我也可以将指针变量重命名,比如:
cpp
typedef int* ptr_t;
//将int* 重命名为 ptr_t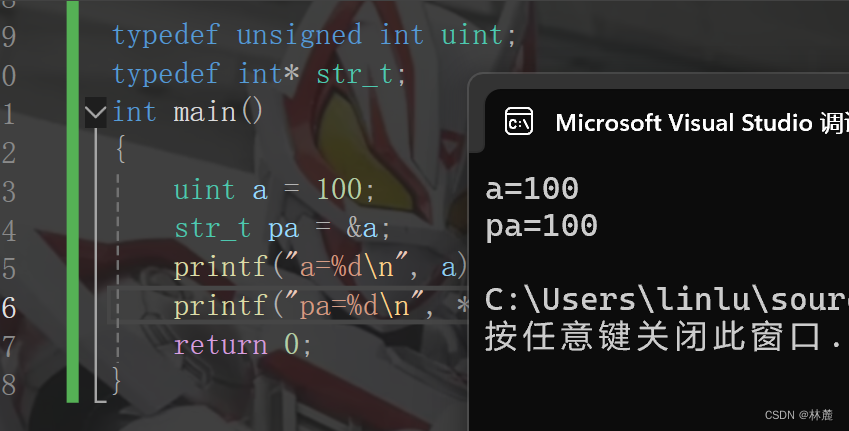
既然指针能够重命名,那我是不是也可以将上面的代码中函数指针类型也改的简短一点:
cpp
typedef void(*pf_t)(int);
//将void(*)(int) 重命名为 pf_t然后就可以来看有没有更加方便:
cpp
typedef void(*pf_t)(int);
void (* signal(int , void (*)(int) ) )(int);
pf_t signal(int , void (*)(int));5、函数指针数组
整型指针数组 - 存储整型指针的数组
函数指针数组 - 存储函数指针的数组
如果我实现了4个函数,需要函数指针来调用,难道需要连续创建4个函数指针来接收4个函数吗?
cpp
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
int main()
{
int (*pf1)(int, int) = Add;
int (*pf2)(int, int) = Sub;
int (*pf3)(int, int) = Mul;
int (*pf4)(int, int) = Div;
return 0;
}这样会不会太麻烦了,如果有多个函数就要有多个函数指针来接收吗?有没有什么办法可以将函数集成起来吗?我们可以使用函数指针数组来接收:
cpp
int main()
{
int (*arr[4])(int ,int) = {Add,Sub,Mul,Div};
return 0;
}这就是函数指针数组,还可以理解为存储函数指针的数组。arr4说明arr是个数组,数组的元素类型是int(*)(int,int)的函数指针。
注意:使用函数指针数组的前提是函数指针数组的每个元素返回类型、参数个数和参数类型都必须形同,才能在集成到一个数组中。
6、转移表
函数指针数组的用途:转移表
用函数指针模拟计算器:
cpp
#include <stdio.h>
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("************************\n");
printf("**** 1. Add 2. Sub ****\n");
printf("**** 3. Mul 4. Div ****\n");
printf("**** 0. exit ***********\n");
printf("************************\n");
}
int main()
{
int input = 0;
int x, y;
//根据输入的值作为数组下标访问到的函数中间就像转移一样,所以函数指针数组就叫转移表
//转移表
int (*pfArr[])(int, int) = { 0,Add,Sub,Mul,Div };
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
if (input >= 1 && input <= 4)
{
printf("请输入两个操作数:>");
scanf("%d%d", &x, &y);
int ret = pfArr[input](x, y);
printf("%d\n", ret);
}
else if (input == 0)
{
printf("退出计算器\n");
}
else
{
printf("选择错误,请重新选择\n");
}
} while (input);
return 0;
}根据输入的值作为函数指针数组下标访问到的函数中间就像转移一样,所以函数指针数组就叫转移表
转移表虽然精妙,但是还是有一定的局限性存在的,就是转移表的方法需要函数指针数组,而函数指针数组里的元素的返回类型和参数的类型必须相同。比如函数指针数组(int,int)里的int,int,就必须要整型的才可以。但是如果我想进行float类型的运算呢?这个转移表就明显解决不了,需要知道就算是这么巧妙的代码也有局限性的。
还有一种方法,可以完成计算器的计算:
cpp
#include <stdio.h>
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("************************\n");
printf("**** 1. Add 2. Sub ****\n");
printf("**** 3. Mul 4. Div ****\n");
printf("**** 0. exit ***********\n");
printf("************************\n");
}
void calc(int(*pf)(int, int))//接收使用函数指针函数地址
{
int x, y;
printf("请输入两个操作数:>");
scanf("%d%d", &x, &y);
int ret = pf(x, y);//通过函数指针来调用传过来的函数
printf("%d\n", ret);
}
int main()
{
int input = 0;
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
calc(Add);//给自定义函数calc传递函数地址
break;
case 2:
calc(Sub);
break;
case 3:
calc(Mul);
break;
case 4:
calc(Div);
break;
case 0:
printf("退出计算器\n");
break;
default:
printf("选择错误,请重新选择\n");
}
} while (input);
return 0;
}上面代码只是个引子,就是为了让大家更方便理解回调函数。
7、回调函数
通过函数指针调用的函数就是回调函数。就像上面的代码,通过函数指针pf调用的Add、Sub、Mul、Div这些函数都被称为回调函数。
如果你把函数的指针 (地址) 作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,被调用的函数就是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
既然讲到了回调函数,那么就需要qsort函数和qsort的模拟实现来引入回调函数的概念。
8、什么是qsort函数
qsort函数的功能是数组排序,给定任意类型的数组,再给定数组元素的信息便可以排序。不管是char数组 、int数组 还是自定义结构体数组都是可以排序的。所以qsort函数就是数组排序的函数。
9、qsort的函数声明和头文件包含
qsort函数是包含在stdlib.h头文件中的,如果我们想调用qsort函数就需要包含对应头文件
cpp
#include <stdlib.h>调用qsort函数时我们需要传递4个参数,如下qsort的函数声明:
cpp
void qsort(void* base,数组的首元素地址
int size, 数组的元素个数
int width, 数组中每个元素的大小
int (*con)(const void*,const void*) 函数指针
)void* base参数是因为qsort可以排序各种类型的数组,所以要用void*的指针来接收各个类型的数组首元素地址。因为void*可以接收各个类型的数据,相当于一个万能的存储空间。但是不能解引用,因为void*只是个没有类型的地址,没有访问权限。
int size参数是数组中元素个数,在给数组排序时需要得知数组有多少个元素。方便找到这个范围内的元素循环并排序。
int width参数是数组中每个元素的大小,因为传进来的地址是void类型,并不知道这个数组的每个元素有多大空间的访问权限,所以需要有一个元素大小的信息方便交换这么大的元素。
**int (*con)(const void*,const void*)**参数是函数指针,这个函数指针用来接收我们传递的函数,而这个函数需要我们自己去定义实现并传参,后面会讲到该函数的作用。
10、qsort函数的调用
知道了qsort的功能和参数。那就开始尝试调用一下qsort函数。
cpp
#include <stdlib.h>
int con(const void* e1, const void* e2)//该函数是自己实现的,要排序什么类型数组,就将地址强转成什么类型
{
return *(int*)e1 - *(int*)e2;//qsort内部判断该函数返回值如果大于0就交换,如果等于或小于则不交换
}//如果e1大于e2,e1-e2一定返回大于0的数字,e1大于e2就交换
void print_f(int* arr, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[] = { 10,9,8,7,6,5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);//求数组元素个数
qsort(arr, sz, sizeof(arr[0]), con);//数组排序
print_f(arr, sz);//数组打印
return 0;
}运行结果:
我们传递的函数con是qsort达到某种特定条件回调这个函数进行判断的,判断两个元素的大小。满足条件就交换。所以具体如何判断还是要自己实现。
既然知道了qsort如何调用那我们可以模拟实现qsort函数,看一看qsort函数的底层原理。
11、qsort函数的模拟实现
如果我们要模拟qsort函数就需要得知排序方法。我们知道的排序方法有很多种,但是我们要使用最常用的排序也就是冒泡排序bubble_sort来模拟实现qsort函数。

那什么是冒泡排序呢?
11.1 冒泡排序
冒泡排序是一种数组排序的算法,这种排序就像汽水里的气泡一样不停的从下往上面冒泡,所以名为冒泡排序(bubble sort)。

冒泡排序的算法思想就是需要排序n-1趟,每一趟排出最大的数在位置最后。因为这种方法最多n-1趟就可以将数组排序完毕。因为每次筛选最大值排在最后,有n个数,n-1个数筛选完后最后一个数必定是在第一个,也就是最小值。经过第一趟排序需要n-1次判断两个相邻的数,如果前面大于后面的就调换。算上排最大值本身,与其他的值经过筛选判断也只需要n-1次判断排出最大值。每一趟排出最大数下一趟排序的n-1需要再减去前面已经排过的趟数。因为每一趟都排出最大值下一趟就不需要对最大数也进行判断,只需要判断已排序最大值前面的那些值就可以了。
既然知道了冒泡排序算法的思想,那接下来就实现冒泡排序算法:
cpp
int main()
{
int arr[] = { 10,9,8,7,6,5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);
int i, j;
for (i = 0; i < sz - 1; i++)//循环排序n-1趟
{
int flag = 1;//假设顺序是正确的
for (j = 0; j < sz - 1 - i; j++)//循环n-1-i次判断并调换找出最大值
{
if (arr[j] > arr[j + 1])
{
int s = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = s;
flag = 0;//设置为需要排序
}
}
if (flag == 1)//假设一趟下来没有任何排序的值,说明已经不再需要排序,跳出循环排序
{
break;
}
}
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}运行结果:
11.2 模拟实现
了解了冒泡排序后我们就可以以冒泡排序来实现qsort函数了,我们自定义模拟实现的qsort函数就以bubble_sort为函数名,接下来就是bubble_sort自定义函数的实现:
cpp
void reverse(char* buf1, char* buf2, int width)
{
int i = 0;
for (i = 0; i < width; i++)//交换元素大小个字节的元素刚好是交换数组的两个元素
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
void bubble_sort(void* base, int size, int width, int(*con)(const void*, const void*))
{
int i, j;
for (i = 0; i < size - 1; i++)
{
int flag = 1;
for (j = 0; j < size - 1 - i; j++)
{
if (con((char*)base + j * width, (char*)base + (j + 1) * width))//达到某种特定条件调用该函数,这就是回调函数
{
reverse((char*)base + j * width, (char*)base + (j + 1) * width, width);//通过char*有一个字节的权限,再配合元素的大小+j刚好跳过这个元素大小的整数倍
flag = 0;
}
}
if (flag == 1)
{
break;
}
}
}达到某种特定条件回调我们传参的函数,就是回调函数,以上con就是回调函数。
但是该函数最精巧的不是回调函数,而是**(char*)base+j*width和(char*)base+(j+1)*width**,因为该函数的特点就是可以排序每个类型的数组,既然是这样,必须要用void*的指针base来接收地址。再将地址强转成char*类型,每次+j*width刚好跳过这些元素的大小来到某个元素的位置并调换。这就是void*指针和每个元素的大小在该函数中的作用。
然后我们就调用我们模拟实现的函数并打印:
cpp
int con(const void* e1, const void* e2)//该函数是自己实现的,要排序什么类型数组,就将地址强转成什么类型
{
return *(int*)e1 - *(int*)e2;//qsort内部判断该函数返回值如果大于0就交换,如果等于或小于则不交换
}//如果e1大于e2,e1-e2一定返回大于0的数字,e1大于e2就交换
void print_f(int* arr, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[] = { 10,9,8,7,6,5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);//求数组元素个数
bubble_sort(arr, sz, sizeof(arr[0]), con);//数组排序
print_f(arr, sz);//数组打印
return 0;
}打印结果:
第九章:字符函数和字符串函数
在编程的过程中,我们经常要处理字符和字符串,为了方便操作字符和字符串,C语言标准库中提供了一系列库函数,接下来我们就学习一下这些函数。

一、字符函数
1、字符分类函数
C语言中有一系列的函数是专门做字符分类的,也就是一个字符是属于什么类型的字符的。这些函数的使用都需要包含一个头文件是ctype.h
|--------------|----------------------------------|
| 函数 | 如果他的参数符合下列条件就返回真 |
| iscntrl | 任何控制字符 |
| isspace | 空白字符:空格、换页、换行、回车、制表符 |
| isdigit | 十进制数字0-9 |
| isxdigit | 十六进制数字,包含所有十进制数组,小写字母a-f,大写字母A-F |
| islower | 小写字母a-z |
| isupper | 大写字母A-Z |
| isalpha | 字母a-z或A-Z |
| isalnum | 字母或数字,a-z,A-Z,0-9 |
| ispunct | 标点符号,任何不属于数字或者字母的圆形字符(可打印) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
给一段代码让大家清楚的看到字符分类函数的用法和返回值,以islower为例:
cpp
#include <ctype.h>
int main()
{
int ret = islower('a');
printf("%d\n", ret);
ret = islower('A');
printf("%d\n", ret);
return 0;
}打印结果:

islower是分类小写字母的函数,当我们给它传一个小写字母时返回非0的值,传一个大写字母判断不是小写字母则返回0。
其他的函数和此函数的使用形式是一模一样的,可以根据以上例子进行使用。
代码练习:将字符串中的小写字母转大写,其他字符不变
cpp
#include <ctype.h>
#include <string.h>
#include <stdio.h>
int main()
{
char str[] = "i Like Beijing!";
size_t len = strlen(str);
size_t i = 0;
for (i = 0; i < len; i++)
{
if (islower(str[i]))//遍历判断是否小写
{
str[i] -= 32;//转换大写
}
}
printf("%s\n", str);
return 0;
}2、字符转换函数
C语言提供了2个字符转换函数:
cpp
int tolower(int c);//将参数传进去的大写字母转小写
int toupper(int c);//将参数传进去的小写字母转大写有了这个函数我们就可以将上面的代码更新一下,不需要+、-32来改变大小写字母,直接使用转换字符函数即可:
cpp
#include <ctype.h>
#include <string.h>
#include <stdio.h>
int main()
{
char str[] = "i Like Beijing!";
size_t len = strlen(str);
size_t i = 0;
for (i = 0; i < len; i++)
{
//不用再额外判断字母是不是小写,tolower判断该字符是小写就转换大写,不是就不改
str[i] = toupper(str[i]);//如果是小写字母就转换为大写
//前提是转换结果需要用一块整型空间来接收,因为传值调用,并不能在函数直接内部修改
}
printf("%s\n", str);
return 0;
}二、字符串函数
3、strlen的使用和模拟实现
strlen库函数功能:求字符串长度,统计的是结束标志\0之前出现的字符个数
strlen库函数的声明:
cpp
size_t strlen(const char* str);strlen函数的调用:
cpp
#include <stdio.h>
#include <string.h>
int main()
{
char str[] = "abcdef";
size_t len = strlen(str);//调用strlen函数,返回值用size_t的变量来接收
printf("%zd\n", len);//打印size_t类型的返回值(字符串长度)
return 0;
}strlen注意事项:
1、strlen所计算的字符串结尾必须有结束标志 ' \0 '。
2、必须给strlen传递字符串地址,strlen需要通过地址向后访问找到 ' \0 ' 为止,只传递字符会报错。
strlen函数的模拟实现:
仿照strlen的函数参数,返回类型,功能写一个类似的函数
方法1:遍历判断
cpp
#include <stdio.h>
#include <assert.h>
size_t my_strlen(const char* str)
{
assert(str != NULL);
size_t count = 0;//计数器,统计字符串的长度
while (*str++ != '\0')//后置++,先使用,当解引用以后str++指向下一个元素
{
count++;//不是'\0'就让计数器++一次
}
return count;
}
int main()
{
char str[] = "hello world";
size_t len = my_strlen(str);
printf("%zd\n", len);
return 0;
}方法2:指针 - 指针
cpp
#include <stdio.h>
#include <assert.h>
size_t my_strlen(const char* str)
{
assert(str != NULL);
char* start = str;
while (*start != '\0')
{
start++;
}
return start - str;//\0的地址 - 首字符的地址得到地址直接的元素个数
}
int main()
{
char str[] = "hello world";
size_t len = my_strlen(str);
printf("%zd\n", len);
return 0;
}方法3:函数递归
cpp
#include <stdio.h>
#incldue <assert.h>
size_t my_strlen(const char* str)
{
assert(str != NULL);
if (*str != '\0')
return 1 + my_strlen(str + 1);
else
return 0;
}
int main()
{
char str[] = "hello world";
size_t len = my_strlen(str);
printf("%zd\n", len);
return 0;
}4、strcpy的使用和模拟实现
strcpy库函数功能:将一个字符串拷贝另一个数组
strcpy函数的声明:
cpp
char* strcpy(char* destination, const char* source);strcpy函数的调用:
cpp
#include <string.h>
#include <stdio.h>
int main()
{
char arr1[] = "hello world";
char arr2[20] = { 0 };
strcpy(arr2, arr1);
printf("%s\n", arr2);
return 0;
}strcpy注意事项:
1、strcpy里源字符串必须包含 ' \0 ',因为 ' \0 ' 也会被拷贝到目标空间。
2、strcpy里目标空间必须要有足够大的空间来存储这个拷贝过来的数据。
strcpy函数的模拟实现:
仿照strcpy的函数参数,功能写一个类似的函数
cpp
#include <stdio.h>
char* my_strcpy(char* dest, const char* src)
{
char* ret = dest;
assert(dest && src);
while (*dest++ = *src++)//边判断,边赋值
{
;
}
return ret;
}
int main()
{
char arr1[] = "hello world";
char arr2[20] = { 0 };
my_strcpy(arr2, arr1);
printf("%s\n", arr2);
return 0;
}5、strcat的使用和模拟实现
strcat库函数功能:字符串追加,就是在目标空间的末尾追加上一串源字符串
strcat函数的声明:
cpp
char* strcat(char* destination, const char* source);strcat函数的调用:
cpp
#include <string.h>
#include <stdio.h>
int main()
{
char arr1[20] = "hello";
char arr2[] = "world";
strcat(arr1, arr2);
printf("%s\n", arr2);
return 0;
}从arr1末尾的 ' \0 ' 开始,拷贝源字符串arr2,将arr1的末尾追加上arr2
strcat注意事项:
1、目标空间必须有足够大的空间进行追加。
2、目标空间结尾和源字符串结尾都必须有 ' \0 '。
strcat函数的模拟实现:
仿照strcat的函数参数,功能写一个类似的函数
cpp
#include <stdio.h>
char* my_strcat(char* dest, const char* src)
{
assert(dest && src);
char* ret = dest;
while (*dest != '\0')//先找到目标空间的'\0',方便追加
{
dest++;
}
while (*dest++ = *src++)//从dest的'\0'位置开始追加
{
;
}
return ret;
}
int main()
{
char arr1[20] = "hello ";
char arr2[] = "world";
my_strcat(arr1, arr2);
printf("%s\n", arr1);
return 0;
}6、strcmp的使用和模拟实现
strcmp库函数功能:用来比较两个字符串的大小关系
strcmp的函数声明:
cpp
int strcmp(const char* str1, const char* str2);注意strcmp比较的不是两个字符串的长度的,而是比较两个字符串中对应位置上的字符,按照字典序比较。
标准规定:
- 第一个字符串大于第二个字符串,则返回大于0的数字
- 第一个字符串等于第二个字符串,则返回0
- 第一个字符串小于第二个字符串,则返回小于0的数字
- 那么如何判断两个字符串?比较两个字符串中对应位置字符的ASCII码值的大小
strcmp函数的调用:
cpp
#include <stdio.h>
#include <string.h>
int main()
{
int ret1 = strcmp("abcdef", "abq");
int ret2 = strcmp("abcdef", "abcdef");
int ret3 = strcmp("abq", "abcdef");
printf("%d %d %d", ret1, ret2, ret3);//打印-1 0 1
return 0;
}strcmp函数的模拟实现:
cpp
#include <stdio.h>
int my_strcmp(const char* str1, const char* str2)
{
assert(str1 && str2);
while (*str1 == *str2)
{
if (*str1 == '\0')
return 0;
str1++;
str2++;
}
return *str1 - *str2;
}
int main()
{
int ret = my_strcmp("abcdef", "abc");
printf("%d", ret);
return 0;
}7、桃园三结义:长度受限制函数strncpy、strncat、strncmp
前面的三个函数strcpy、strcat、strcmp是长度不受限制的字符串函数,他们仨还有长度受限制的函数,分别是:strncpy、strncat、strncmp,和前面的strcpy、strcat、strcmp的功能是相同的,参数上多了一个值,这个值就是限制字符串函数的执行功能长度限制,表面上不同的是str后面多了一个n,干了这碗wine ( 酒 )后我们仨就正式结拜为兄弟。

比如我要拷贝"hello world"到一个空间,但是只想拷贝 "hello" 这6个字符,就可以考虑用长度受限制的字符串拷贝函数strncpy。
strncpy函数的声明:
cpp
char* strncpy(char* destination, const char* source, size_t num);strncat函数的声明:
cpp
char* strncat(char* destination, const char* source, size_t num);strncmp函数的声明:
cpp
char* strncmp(char* destination, const char* source, size_t num);它们的功能大概就是:
strncpy:限制拷贝字符个数
strncat:限制字符追加个数
strncmp:限制字符串比较字符个数
所以具体函数调用就不再一一介绍了,知道是什么功能限制什么就可以了
8、strstr的使用和模拟实现
strstr库函数功能:在一个字符串中查找另一个字符串,简单概述就是判断第二个字符串是不是第一个字符串的子字符串
strstr的函数声明:
cpp
char* strstr(const char* str1, const char* str2);strstr函数返回str2在str1中第一次出现的位置
如果str2在str1中没有出现,就返回NULL
strstr函数的调用:
cpp
#include <stdio.h>
#include <string.h>
int main()
{
char str1[] = "abbcde";
char str2[] = "bc";
char* s = strstr(str1, str2);
if (s == NULL)
{
printf("str2不是str1的子串\n");
}
else
{
printf("%s\n", s);
}
return 0;
}strstr函数的模拟实现:
仿照strlen的函数参数,返回类型,功能写一个类似的函数
方法1:暴力求解
cpp
#include <stdio.h>
#include <string.h>
#include <assert.h>
const char* my_strstr(const char* str1, const char* str2)
{
assert(str1 && str2);
const char* s1 = NULL;
const char* s2 = NULL;
const char* start = s1;
if(*str2=='\0')
return str1;
while (*start)
{
s1 = start;//重置位置
s2 = str2;//重置位置
while (*s1==*s2 && *s1!='\0')//如果相等就++继续判断下一个
{
s1++;
s2++;
}
if (*s2 == '\0')//结束循环后判断是不是因为*s2为\0结束的
{
return start;//返回刚开始的判断位置
}
start++;//下一个位置继续对比判断
}
return NULL;
}
int main()
{
char str1[] = "abbbcde";
char str2[] = "bbc";
const char* s = my_strstr(str1, str2);
if (s == NULL)
{
printf("str2不是str1的子串\n");
}
else
{
printf("%s\n", s);
}
return 0;
}方法2:KMP算法-效率高,但是难度大,难以理解
有兴趣可以自己去了解一下。
9、strtok的使用
以后学习计算机网络时,会学到点分十进制表示的IP地址,例如:192.168.101.25,由点分开的十进制就叫点分十进制,IP地址本质是一个整数,不好记,所以才有了点分十进制表示方法
既然IP地址是用 ' . ' 隔开的,那可以将每个隔开的段拿出来吗?
比如:192,168,101,25这四个由 ' . ' 隔开的段。
当然可以。这里就要是用到strtok函数。该函数可以通过分隔符将一个字符串的每个分割段拿出来。
strtok函数的声明:
cpp
char* strtok(char* str, const char* sep);strtok函数功能:
- sep参数指向一个字符串,定义了用作分隔符的字符集合
- 第一个参数指定一个字符串,它包含了0个或者多个有sep字符串中一个或多个分隔符分割的标记
- strtok函数找到str中的下一个标记,并将其用 ' \0 ' 结尾,返回指向这个标记的指针。(注:strtok分割字符串时是会改变传参过来的字符串的,如果不想改变就拷贝一个传参)
- strtok函数的第一个参数不为NULL,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置
- strtok函数的第一个参数为NULL,函数将在同一个字符串中被保存的位置开始,查找下一个标记
- 如果字符串中不存在更多的标记,则返回NULL指针
简单来说就是第一次调用strtok函数时需要传参传一个需要分割的字符串,他会分隔符位置置为 '\0' 返回已经分割的第一段。但是它一直停留在 ' \0 '的位置,所以下一次调用直接传递NULL就可以继续沿着' \0 '的位置继续向后找分隔符分割成段并返回,直到没有可以分割的段时返回NULL。
注:如果第一次分割字符串后,想继续分割该字符串,调用时可以直接传NULL,因为出了函数不会销毁这个分割后的字符串,一直保存着这个字符串,下一次调用时可以直接传NULL便可继续使用该字符串,是因为该字符串可能被static修饰过,出了作用域不会被销毁。
如果想分割其他字符串,不想分割该字符串。就传其他字符串,不再传递NULL。然后strtok会以刚传的其他字符串为开头,下一次调用传NULL便可继续分割其他的字符串。
strtok函数的调用
cpp
#include <stdio.h>
#include <string.h>
int main()
{
char arr[] = "linlu1024@yeah.net";
char buf[30] = { 0 };
strcpy(buf, arr);
char* p = "@.";
char* s = NULL;
for (s = strtok(buf, p); s != NULL; s = strtok(NULL, p))//根据strtok的特性去遍历
{
printf("%s\n", s);//遍历打印字符串的分段
}
return 0;
}10、strerror的使用
strerror库函数功能:返回一个错误信息字符串的起始地址,简单概述就是返回一个错误码所对应的错误信息字符串的起始地址,这个错误码就是我们调用时传递的实参。
strerror函数的声明:
cpp
char* strerror(int errnum);strerror函数的调用:
cpp
#incldue <stdio.h>
#include <string.h>
int main()
{
int i = 0;
for (i = 0; i <= 10; i++)
{
printf("%s\n", strerror(i));
}
return 0;
}
那我们一般什么情况下使用该函数呢?
errno的介绍
首先要知道当库函数调用失败的时候,会将错误码记录到errno这个变量中,errno是记录最后一次错误码的。代码是一个int类型的值,在errno.h中定义,所以使用时需要包含errno.h头文件
errno是C语言规定的一个全局变量,用来存储错误码
然后先暂时了解一下文件操作函数,fopen是用来开辟文件信息区将文件信息放入信息区并返回该文件信息区的函数,然后我们就可以通过FILE*类型的指针接收这个fopen返回的文件信息区的地址。
所以当我们调用fopen函数失败时,此时打开文件失败的错误信息的错误码会记录在errno变量中,我们就可以通过这个strerror将这个错误码对应的错误信息打印出来:
cpp
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main()
{
FILE* pf = fopen("add.txt", "r");//文件不存在,打开失败返回NULL
if (pf == NULL)
{
printf("打开文件失败,失败原因: %s\n", strerror(errno));//打印错误信息
return 1;
}
else
{
printf("打开文件成功\n");
}
return 0;
}perror库函数的介绍:
还有一个库函数叫perror,和上面的strerror一样,也是打印错误信息的,唯一不同的区别就是返回类型。
perror和strerror的区别:
- strerror接收到错误码是找到对应的错误信息的地址并返回,我们想打印就打印,不想打印就暂时存起来。
- perror做的就有点绝,它不返回错误信息的起始地址,而是接收到错误码后直接在函数内部打印错误信息。
- 注:perror不需要传参,是可以直接获取errno的错误码打印出错误信息。
这就是strerror和perror的区别。
第十章:内存函数
1、memcpy的使用和模拟实现
memcpy库函数的功能:任意类型数组的拷贝
memcpy的函数声明:
cpp
void* memcpy(void* destination, const void* source, size_t num);destination是目标空间,source是源,size_t num是拷贝字节的个数。
为什么还有输入拷贝字节个数呢?
因为memcpy可以拷贝任意类型的数组,可以是字符,可以是int,也可以是struct自定义类型的,但是前提是要输入要拷贝的字节个数,因为传过去的地址被void类型的指针接收,所以不能得知元素大小。
memcpy函数的调用:
cpp
#include <stdlib.h>
#include <stdio.h>
int main()
{
int arr1[10] = { 0 };
int arr2[] = { 1,2,3,4,5,6,7,8,9,10 };
memcpy(arr1, arr2, 20);//向拷贝20个字节也就是5个int类型大小的arr2元素到arr1数组中
int i = 0;
for (i = 0; i < 5; i++)
{
printf("%d ", arr1[i]);
}
return 0;
}memcpy函数的模拟实现:
cpp
#include <stdio.h>
#include <assert.h>
void* my_memcpy(void* dest, const void* source, size_t num)
{
assert(dest && source);
void* ret = dest;
while (num--)
{
*(char*)dest = *(char*)source;
dest = (char*)dest + 1;
source = (char*)source + 1;
}
return ret;
}
int main()
{
int arr1[10] = { 0 };
int arr2[] = { 1,2,3,4,5,6,7,8,9,10 };
my_memcpy(arr1, arr2, 20);//向拷贝20个字节也就是5个int类型大小的arr2元素到arr1数组中
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr1[i]);
}
return 0;
}但是这个函数有一个缺点,就是不能重叠内存拷贝,什么意思呢?就是不能在同一个数组中拷贝,会导致打印信息不正确,例如:
cpp
#include <stdio.h>
#include <assert.h>
void* my_memcpy(void* dest, const void* source, size_t num)
{
assert(dest && source);
void* ret = dest;
while (num--)
{
*(char*)dest = *(char*)source;
dest = (char*)dest + 1;
source = (char*)source + 1;
}
return ret;
}
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
my_memcpy(arr+2, arr, 20);更改位置
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr1[i]);
}
return 0;
}我想将arr+2也就是第3个元素的位置开始,拷贝1-5,我们想象的答案是1 2 1 2 3 4 5 8 9 10, 但是实际上的答案是1 2 1 2 1 2 1 8 9 10,因为是从前往后开始拷贝,拷贝信息和拷贝的位置重叠了,导致拷贝时更改了拷贝信息,打印出的结果有所差异。
那怎么办?其实还有memmove函数,他和memcpy的拷贝一样,任意类型都可以拷贝,不同的是memmove可以处理重叠内存拷贝。
2、memmove的使用和模拟实现
memmove库函数功能:拷贝任意类型的数组,也可以处理重叠内存拷贝问题
memmove函数的声明:
cpp
void* memmove(void* destination, const void* source, size_t num);可以看到memmove和memcpy的返回类型和参数一模一样,唯一不同的只是memmove函数的实现细节
memmove函数的调用:
cpp
#include <stdlib.h>
#include <stdio.h>
int main()
{
int arr1[10] = { 0 };
int arr2[] = { 1,2,3,4,5,6,7,8,9,10 };
memmove(arr1, arr2, 20);//向拷贝20个字节也就是5个int类型大小的arr2元素到arr1数组中
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr1[i]);
}
return 0;
}memmove究竟是如何处理拷贝重叠的的呢?请继续往下看
memmove函数的模拟实现:
cpp
#include <stdio.h>
#include <assert.h>
void* my_memmove(void* dest, const void* source, size_t num)
{
assert(dest && source);
void* ret = dest;
if (dest < source)//如果拷贝的地址小于拷贝信息的地址就可以从前向后拷贝
{
while (num--)
{
*(char*)dest = *(char*)source;//从前向后拷贝
dest = (char*)dest + 1;
source = (char*)source + 1;
}
}
else//如果拷贝的地址大于或等于拷贝信息的地址就从后向前拷贝
{
while (num--)
{
*((char*)dest + num) = *((char*)source + num);//从后向前拷贝
}
}
return ret;
}
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
my_memmove(arr + 2, arr, 20);
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}memmove模拟实现逻辑:
我们可以使用地址于地址之间的关系运算,简单概述就是两个地址之间比较大小。因为该函数是排序数组的,数组又是连续存放的,所以可以比较两个地址。如果目标空间地址比源地址大,就从后往前拷贝。如果目标空间地址比源地址小,就可以从前往后拷贝。
3、memset的使用和模拟实现
memory- 记忆(内存),set - 设置。memset就是内存设置的意思。
memset库函数功能:将参数ptr的前num个字节设置成指定的value值。
memset的函数声明:
cpp
void* memset(void* ptr, int value, size_t num);比如我有一个字符数组,字符串是 " hello world " ,我想把它改成 " hello xxxxx",那我们就可以使用memset函数。
memset函数的调用:
cpp
#include <stdio.h>
#include <stdlib.h>
int main()
{
char str[] = "hello world";
memset(str + 6, 'x', 5);
//参数1:字符数组下标6的位置 参数2:需替换的的源值 参数3:字节为单位,向后拷贝的字节大小
printf("%s\n", str);//打印 "hello xxxxx"
return 0;
}打印结果确实是 " hello xxxxx ",但是我们也可以用它来改变整型数组:
cpp
#include <stdio.h>
#include <stdlib.h>
int main()
{
int arr[] = {1,2,3,4,5,6,7,8,9,10};
memset(arr, 1, 20);
int sz = sizeof(arr)/sizeof(arr[0]);
int i = 0;
for(i=0;i<sz;i++)
{
printf("%d ",arr[i]);
}
return 0;
}我们想象的是改变前20个字节也就是前5个整型元素,打印为:1,1,1,1,1,6,7,8,9,10,但实际上却却是以每个字节更改为01,并不是我们想象的改为五个1,如下图:
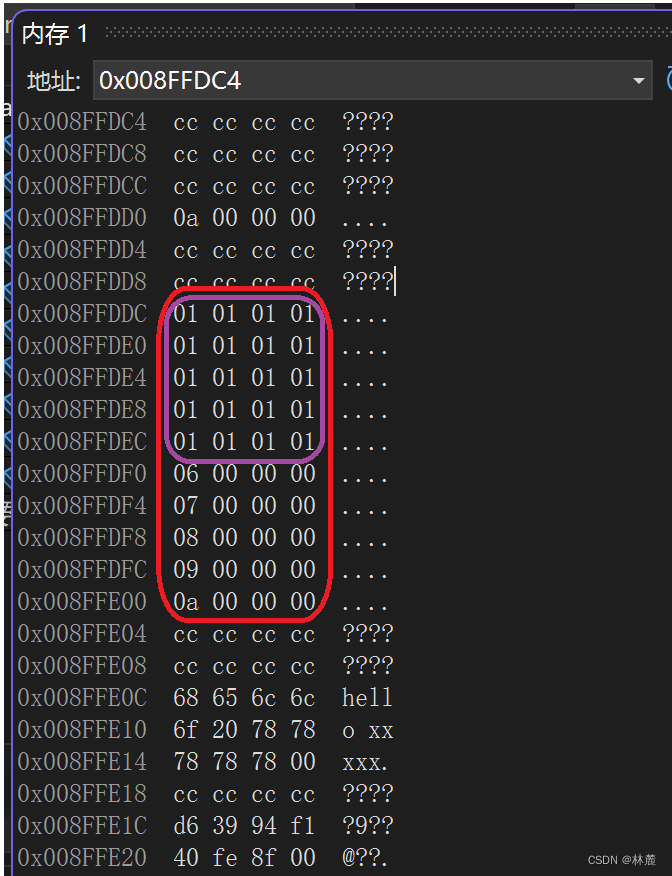
所以你想让它的每个字节都是1是可以做的到的,但是你想让它每个整型都是1这个是做不到的,memset本身就是以字节为单位进行设置的。前面的memcpy和memmove虽然也是以字节为单位来拷贝的,但是它们两边都是在变化着拷贝的,所以能够拷贝正确答案。而这个需拷贝的源始终都是一个值,这个值是不会变化的,每次拷贝一个字节都从这里面的一个字节拷贝到另一个空间。
memset的模拟实现:
cpp
#include <stdio.h>
#include <stdlib.h>
void my_memset(void* str, int value, size_t num)
{
assert(str != NULL);
void* ret = str;
while (num--)
{
*(char*)str = (char)value;
str = (char*)str + 1;
}
return ret;
}
int main()
{
char str[] = "hello world";
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
my_memset(str+6, 'x', 5);
my_memset(arr, 1, 20);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
printf("%s\n", str);
return 0;
}4、memcmp的使用和模拟实现
memcmp库函数的功能:和strncmp的功能一样,strncmp是比较两个字符串的,memcmp是比较两个数组内存的
memcmp函数的声明:
cpp
int memcmp(void* ptr1, void* ptr2, size_t num);memcmp返回值:如果ptr1比ptr2大就返回大于0的数字,如果ptr1比ptr2小就返回小于0的数字,如果相等就返回0
memcmp函数的调用:
cpp
#include <stdio.h>
#include <stdlib.h>
int main()
{
int arr1[] = { 1,4,3,4,5 };
int arr2[] = { 1,3,5,7,9 };
int ret = memcmp(arr1, arr2, 5);
printf("%d\n", ret);
return 0;
}memcmp函数的模拟实现:
cpp
#include <stdio.h>
#include <stdlib.h>
int my_memcmp(void* ptr1, void* ptr2, size_t num)
{
assert(ptr1 && ptr2);
while (num--)
{
if (*(char*)ptr1 != *(char*)ptr2)
{
return *(char*)ptr1 - *(char*)ptr2;
}
ptr1 = (char*)ptr1 + 1;
ptr2 = (char*)ptr2 + 1;
}
return 0;
}
int main()
{
int arr1[] = { 1,3,3,4,5 };
int arr2[] = { 1,4,5,7,9 };
int ret = my_memcmp(arr1, arr2, 5);
printf("%d\n", ret);
return 0;
}第十一章:数据在内存中存储
1、整数在内存中的存储
在讲解操作符的时候,我们就讲过了下面的内容:
整数的2进制表示方法有三种,即原码 、反码 和补码
三种表示方法均有符号位 和数值位两部分,符号位都是0表示"正",用1表示"负",而数值位最高位的一位是被当做符号位,剩余的都是数值位。
以上仅限于有符号整数。
正数的原、反、补码都相同。
负整数的三种表示方法各不相同。
**原码:**直接将数值按照正负数的形式翻译成二进制得到的就是原码
**反码:**原码的符号位不变,其他位按位取反得到的就是反码
**补码:**反码+1就是补码
对于整数来说,数据在内存中是以补码的形式进行存储的。
为什么呢?
在计算机系统中,数值一律用补码的形式表示存储,原因在于,使用补码,可以将符号位和数值域统一处理;(因为负数的补码是正补数的原码,其原、反、补码的运算就是为了求出补码也就是正补数的原码,正补数不存在符号位,所以符号位就算是1也是表示数值的)
同时,加法和减法也是可以统一处理(CPU只有加法器) 此外,补码和原码相互转换,其运算过程是相同的,不需要额外的硬件电路。(补码就是正补数的原码,正补数和另一个正整数相加正好可以求出负整数和正整数的运算结果,从而实现了加法和减法的统一处理)
怎么简单理解上面的意思呢?CPU只有加法运算器为什么也能处理减法呢?不要着急,接下来就由我来为大家一 一讲解。
其实补码就是专门为了负整数而发明的,原因是CPU只有加法运算器,如果处理两个数相减的减法运算,不知道该怎么处理。那我们可以将减法运算看作一个正整数加上负整数(1+(-1))就可以了呗。但是两个数的原码相加后发现算出的结果根本不对。
怎么办呢?然后就有人发明除了原、反、补码,这个发明者简直就是个天才,为什么这么说?如果你将负整数的原码转换成补码,补码转换为十进制的值可能是一个很庞大的正补数 (可以理解为这个正补数的原码就是这个负数的补码 ),正补数原码的符号位和数值域都可以用来存放数值,也就是实现了符号位和数值域统一处理 。然后正整数可以和正补数相加从而实现了减法和加法的统一处理,经过相加后得到的二进制位如果多出1位直接抛弃最后取出的32个二进制位就是正确结果,经过正补数运算得出的结果的二进制就是原码,不需要额外转换了。
关于负整数或减法运算就是将负数经过原、反、补码的运算求出正补数的原码,然后让正补数替负数执行加法运算得出的就是正确结果,你说秀不秀。
2、大小端字节序和字节序判断
2.1 什么是大小端?
大端字节序和小端字节序是什么呢?首先根据字节序得知就是字节的顺序,大端的字节顺序和小端的字节顺序有所差异。那字节顺序指的是内存中数据存储的字节顺序。
首先我们先给一个代码:
cpp
int main()
{
int a = 0x11223344;//将16进制放进变量a中,就是该16进制表示的10进制的数
return 0;
}变量a是int类型的,有4个字节,我们可以调试一下看内存中变量a的每个字节所存储的顺序:
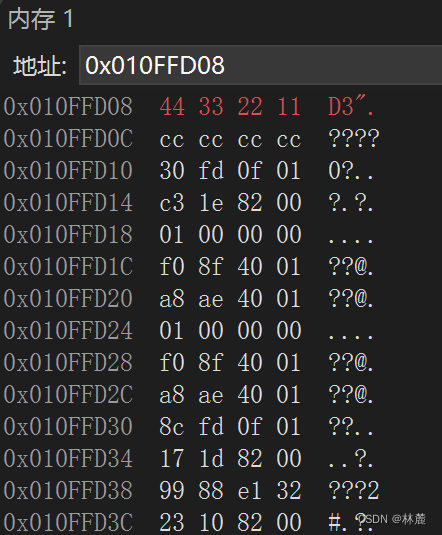
可以看到数据是倒着存放的,44是数据的最低位,如果仔细观察可以发现内存中数据的地位放在相对较低的地址,高位11放在相对较高的地址,这就是小端字节序。
大端和小端名字的由来:格列佛游记中的一个故事,两个国家因为一件事情没谈拢,这件事情就是鸡蛋应该从大头向小头剥还是从小头向大头剥,没谈拢两个国家就打了一架。
**小端字节序:**低位字节序存储到低地址,高位字节序存储到高地址
**大端字节序:**低位字节序存储到高地址,高位字节序存储到低地址


2.2 为什么有大小端?
为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit位,但是C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题,因此导致了大端存储模式和小端存储模式。
2.3 练习
练习1:
请概述大端字节序和小端字节序的概念,设计程序来判断当前机器的字节序
cpp
int check_sys()
{
int a = 1;
return *(char*)&a;//小端返回1,大端返回0
}
int main()
{
int ret = check_sys();
if (ret == 1)
{
printf("小端\n");
printf("%d\n", ret);
}
else
{
printf("大端\n");
printf("%d\n", ret);
}
return 0;
}一个整型类型的a是4个字节,a等于1,将这个a的地址强转成char*类型,解引用访问1个字节,首先需要了解变量的地址是所在空间的低地址。解引用根据变量的类型向高地址访问几个字节,所以解引用当前的a访问的是低地址,如果是大端,低地址内存存储的是00,解引用拿到的就是0,如果是小端就是1.
注:每个变量的地址都是所占内存的多个字节空间地址中低地址内存的地址,解引用时是由低到高访问的。
练习2:
cpp
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d,b=%d,c=%d", a, b, c);
return 0;
}答案解析:
答案是:-1,-1,255
因为有符号char和char是一样的,答案都是-1,unsignedchar char -1的符号位是1,就是负数,但是是unsigned char无符号字符型,所以符号位也能用来表示数据,所以没有负号就是255.
练习3:
cpp
int main()
{
char a = -128;
printf("%u\n", a);
return 0;
}答案解析:
答案:4294967168
char类型的取值范围是-128-127,-128的补码是10000000,%u打印时需要整型提升,整型提升看值的类型,是signed char有符号字符就需要提升符号位,符号位是1所以结果就是11111111 11111111 11111111 10000000,最后被当做无符号整型打印就是42亿的数值。
练习4:
cpp
int main()
{
char a[1000];
int i = 0;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d\n", strlen(a));
return 0;
}答案解析:
答案:255
不对啊,明明循环了1000次赋值了1000个元素那为什么字符长度还是255呢?这是因为字符char就是一个轮回,比如ASCII码值从1一直+1,+到127时如果是有符号的char再次+1就变为-128,然后再+1变为-127,依次类推,那字符串的结束标志 ' \0 '的ASCII就是0,所以当存储到0的时候之前已经存储了255个字符,虽然a存储了1000个字符,但是strlen遇到 ' \0 '还是会停下,所以结果为255
3、浮点数在内存中的存储
常见的浮点数:3.1459、1E10等,浮点数家族包括:float、double、long double类型。
浮点数表示的取值范围:float.h中定义
3.1 练习
cpp
#include <stdio.h>
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值为: %d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
*pFloat = 9.0;
printf("n的值为: %d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
return 0;
}答案解析:
**第一次打印:**9,0.000000,因为第一次打印之前只是将变量n的地址强转成float*类型赋值给pFloat指针,打印时变量n还是9。但是pFloat虽然接收到n的地址,可以解引用访问,但是当它通过该地址找到这块空间发现里面存放的不是浮点型,但是%f要打印浮点型,由于这块空间存放着整型,不是浮点型。因为浮点型不能和整型之间进行转换。所以干脆就给打印0.000000
**第二次打印:**1091567616,9.000000,因为第二次打印之前通过*pFloat解引用找到这块空间并将这块地址赋值为9.000000,打印变量n时就通过浮点数二进制打印整数,结果为1091567616,是关于浮点数的二进制。当*pFloat解引用时由于就是浮点数所以可以打印浮点数9.000000。
3.2 浮点数的存储
上面的代码中,num和*pFloat在内存中明明是同一个数,为什么浮点数和整数的解读结果差别那么大?要理解这个结果,一定要搞懂浮点数在计算机内部的表示方法。
根据国际标准 IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
V = (-1)^S * M * 2^E
- (-1)^S 表示符号位,当S=0,V为正数;当S=1,V为负数
- M 表示有效数字,M是大于等于1,小于2的
- 2^E 表示指数位
每个十进制浮点数要先转换成表示方法V,然后再将表示方法V里面符号位S、有效数字M和指数E三部分信息存入内存,下一次使用该浮点数就可以通过内存中的这三个信息得到对应浮点数来操作。
相信绝大多数的人刚看到这个V的表示形式有些懵,但是不要着急,接下来我举个例子,来让大家清晰的理解该表示形式。
如何将十进制浮点数转换成表示方法V:
比如我有一个浮点数5.5,V=5.5,我如果要取出它的二进制首先要转换出小数点前面的5的二进制,5的二进制:101,然后再换算小数点后面的小数,注意:不要以为后面的小数是5就也按照正常权重二进制形式转换,并不是101.101,小数的二进制权重,看下图:
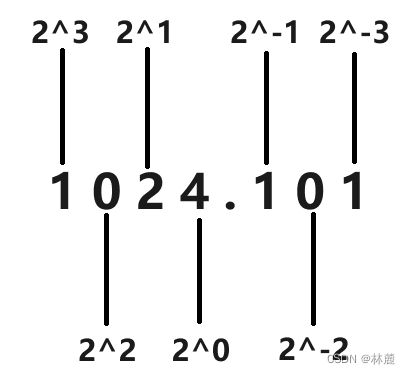
所以2^-1就是1 / 2^1,也就是0.5,2^-2就是1 / 2^-2也就是0.25。所以小数点后面的就是.1,所以算出的5和0.5的二进制是101.1,但是并不是到了这里就完了,在内存中存储浮点数并不只是存储101.1的。
来看一下十进制浮点数123.45是不是也可以表示成1.2345 * 10^2,1.2345 * 10^2 = 123.45,因为是十进制所以需要10^?来移动浮点。所以二进制浮点数需要2^?来移动浮点:101.1也可以表示成1.011 * 2^2,因为小数点向右边移两位就是101.1了,和十进制方法相同。5.5是正数,所以最终5.5的表示方法V就是 V = (-1)^0 * 1.011 * 2^2。
**V = (-1)^s * M * 2^E,上面的0对标的就是s,1.011对标的就是M,2对标的就是E,**所以浮点数在内存中存储的就是S 、M、E三部分。它们之间是相互作用的。
十进制浮点数5.5的表示方法V:
V = (-1)^0 * 1.011 * 2^2
V = (-1)^S * M * 2^E
- S = 0
- M = 1.011
- E = 2
再举一个例子:比如十进制浮点数9.0,将它换算成二进制就是1001.0,然后将这个二进制1001.0换算成有效数字M就是1.001,因为1.001 * 2^3就是1001.0,所以指数E就是3,由于9.0是正数,所以(-1)^0就是正数,符号位S就是0.
十进制浮点数9.0的表示方法V:
V = (-1)^0 * 1.001 * 2^3
V = (-1)^S * M * 2^E
- S = 0
- M = 1.001
- E = 3
知道了V的表示形式和转换,那怎么将符号位S、有效数字M 和 指数E存放进内存中的呢?
IEEE 754规定:
对于32位浮点数,最高的1位存储符号位S,接着的8位存储指数E,剩下的23位存储有效数字M
对于64位浮点数,最高的1位存储符号位S,接着的11位存储指数E,剩下的52位存储有效数字M

3.2.1 浮点数存储过程
IEEE 754对有效数字M和指数E,还有一些特别规定。
前面说过,1 <= M < 2,也就是说,M可以写成1.xxxxxx的形式,其中xxxxxx表示小数部分。
IEEE 754 规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分。比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字,以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以24位有效数字。
至于指数E,情况就比较复杂。
首先E为一个无符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0 - 255,如果E为11位,它的取值范围为0 - 2047。但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数是127,对于11位的E,这个中间数就是1023。比如,2^10的 E 是10,所以保存32位浮点数时,必须保存10+127 = 137,即10001001
那什么情况下E为负数呢?
比如0.5的二进制位0.1,将它转换成有效数字M需要向右移动一位,所以指数E为-1
十进制浮点数0.5的表示方法V:
V = (-1)^0 * 1.0 * 2^-1
V = (-1)^S * M * 2^E
- S = 0
- M = 1.0
- E = -1
E也是有可能为负数的,如上面所示。如果不加中间值,直接将负数E以无符号的整数存入内存取出就会认为是一个无符号整数,所以需要加上中间值当作无符号数存入,取出时减去这个中间值得到的就是负数。
注:指数E的真实值+中间值就是为了防止出现负数,+中间数是为了中和掉负数。
符号位S有效数字M指数E
32位浮点数:5.5在内存中存储的是:0 10000001 01100000000000000000000
32位浮点数:9.0在内存中存储的是:0 10000010 00100000000000000000000
3.2.2 浮点数取出过程
指数E从内存中取出还可以分为三种情况:
E不全为0或全为1:
这时,浮点数就采用下面的规则表示,则指数E的计算值减去127(或1023),得到真实值,再将有效数字M前面加上第一位的1.
E全为0:
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,有效数字M不再加上第一位的1,而是还原0.xxxxxx的小数。这样做是为了表示+-0,以及接近于0很小的数字。
E全为1:
这时,如果有效数字M全为0,表示+-无穷大(正负取决于符号位s)
关于浮点数的表示规则,就说到这里。

根据上图得出一点:给变量赋值得到的值是什么类型的取决于变量类型,比如上面的整型变量a,将浮点型变量b赋值给a,编译器会根据变量a的类型来处理这个值,将浮点型的9.0转换为整型的9赋值给变量a,但是如果将a的地址传给float*指针变量pFloat,通过解引用该变量*pFloat赋值会根据当前访问的类型来赋值,所以将浮点数9.0表示方法的二进制赋值给这块空间,打印变量a是会将这个二进制当作一个整型的二进制打印,所以给某空间存放什么类型的值取决于类型。
第十二章:自定义类型(结构体)
1、结构体类型的声明
为什么要有自定义的结构类型呢?
这是因为稍微复杂的类型,直接使用内置类型是不行的!比如:描述一个人或 一本书的价格、版号等信息。
1.1 结构的创建
结构体是一些值的集合,这些值称为成员变量,结构的每个成员可以是不同类型的变量。
1.1.1 结构的声明
cpp
struct tag
{
member-list;//成员列表,可以有多个成员
}variable-list;//变量列表,可以使用该类型创建多个变量例如描述一个学生:
cpp
struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
};因为struct student是一个结构体类型声明,并不是函数,所以旁边不用加()。但是结构体后的分号是不可省略的,因为不管是函数声明还是自定义类型声明结尾都是必须有分号的。
1.1.2 结构体类型的变量
结构体类型变量有两种创建方式:
方法1:
cppstruct Stu { char name[20];//名字 int age;//年龄 char sex[5];//性别 char id[20];//学号 }; int main() { struct student s1, s2, s3; return 0; }结构体声明好后,直接使用该自定义类型创建变量
方法2:
cppstruct Stu { char name[20];//名字 int age;//年龄 char sex[5];//性别 char id[20];//学号 }s3,s4,s5;声明结构体的同时创建变量
注:结构体声明就像绘制建筑图纸,当建筑的图纸绘制好后。我可以通过这个图纸建造n个建筑(变量)。自定义类型的声明可以比作建筑图纸,而使用这个类型创建变量就可以看作照着建筑图纸搭建一个建筑。
1.1.3 结构的初始化
我们通过函数的声明创建好变量后可以给变量初始化,那如何给结构初始化呢?
cpp
struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
};
int main()
{
struct Stu s1 = { "zhangsan",20,"nan","12345" };
struct Stu s2 = {"lisi",21,"nan","54321"};
return 0;
}结构体变量的初始化是按照顺序来初始化的,你在声明结构类型时里面的成员是什么顺序的创建好变量后初始化就必须是什么顺序的,不能不按顺序乱初始化。
但是有没有什么办法可以不按照顺序初始化呢?答案是有的:
cpp
struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
};
int main()
{
struct Stu s1 = { "zhangsan",20,"nan","12345" };
struct Stu s2 = {"lisi",21,"nan","54321"};
struct Stu s3 = { .sex = "nan",.age = 18,.name = "wangwu",.id = "13579" };
return 0;
}这种方式相当于在初始化过程中访问该变量s3的每个成员并赋值,赋值可以不按照顺序,因为是在s3内部通过 ' . ' 来访问的,所以默认为s3.age访问。
cpp
以下两种方法是等价的:
struct Stu s3 = { .sex = "nan",.age = 18,.name = "wangwu",.id = "13579" };
struct Stu s3 = {0};
s3.sex = "nan";
s3.age = 18;
s3.name = "wangwu";
s3.id = "13579";这里需要了解到 ' . '是结构体的访问操作符,比如我想访问变量s3里的成员age,我就可以使用 ' . '
s3.age,既然能访问也就可以通过这种方式来给成员赋值,s3.age = 30。
那我们如何打印结构体类型呢?比如:
cpp
#include <stdio.h>
struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
};
int main()
{
struct Stu s1 = { "zhangsan",20,"nan","12345" };
printf("%s %d %s %s", s1.name, s1.age, s1.sex, s1.id);
return 0;
}看上面代码就是通过 ' . '操作符访问该结构的每个成员并打印,这就是结构体的打印方式。
1.2 结构的特殊声明
在声明结构的时候,可以不完全的声明。
比如:
cpp
//匿名结构体类型
struct
{
int a;
char b;
float c;
}x;
struct
{
int a;
char b;
float c;
}a[20],*p;匿名结构体是不能声明好结构类型后再创建变量,这样会报错,比如:
cpp
struct
{
int a;
char b;
float c;
};
int main()
{
struct x = {0};//会报错
return 0;
}匿名结构体的变量应该在声明的时候就创建,然后就可以直接使用该变量:
cpp
#include <stdio.h>
struct
{
int a;
char b;
float c;
}x;
int main()
{
x.a = 10;
x.b = 'a';
x.c = 3.14f;
printf("%d %c %f\n",x.a,x.b,x.c);
return 0;
}注:匿名结构体只能使用一次,就是在声明的时候创建变量,声明好后就不能创建变量了。
那匿名结构体可以这样使用吗?
cpp
struct
{
int a;
char b;
float c;
}s = {0};
struct
{
int a;
char b;
float c;
}* ps;
int main()
{
ps = &s;//err
return 0;
}警告:
答案是不能,因为运行时会报错:指针ps和&s的类型不兼容。别看两个匿名结构类型的成员一模一样,但是编译器依然认为它们是两个不同的指针类型,所以不能相互赋值。
解决方法:定义结果体不要使用匿名结构体
1.3 结构的自引用
在结构中包含一个类型为该结构本身的成员是否可以呢?
比如,定义一个链表的节点:
cpp
struct Node
{
int data;
struct Node next;
};上述代码正确吗?如果正确,那sizeof(struct Node)是多少?
仔细分析,其实是不行的,因为一个结构体中再包含一个同类型的结构体变量,这样结构体变量的大小会无穷大,是不合理的。
正确的自引用方式:
cpp
struct Node
{
int data;
struct Node* next;
};因为指针就是用来存储地址的,地址的大小是4/8个字节,所以大小可以固定。
1.3.1 typedef类型重命名
typedef是C语言的关键字,作用是类型重命名
比如:如果觉得struct Node太长太麻烦,就使用类型重命名:
cpp
typedef struct Node
{
int data;
Node* next;//将struct Node改名为Node可以在内部使用吗?
}Node;//类型声明时使用typedef改名时是在这个位置,这里是要更改的名字,不是变量将struct Node改名为Node后可以在内部使用吗?
答案是不能,因为是先声明后改名,在声明阶段还未改名,就用上Node来表示自引用类型,编译器不认识就会报错,typedef改名后是在后来想创建该类型变量时可以使用改名后的Node来创建,在之前是不能使用的,所以还是应该这样使用:
cpp
typedef struct Node
{
int data;
struct Node* next;
}Node;
int main()
{
Node* n1 = NULL;等价于 struct Node* n1 = NULL;
return 0;
}**2、**结构体内存对齐
我们已经掌握了结构体的基本使用了。
现在我们深入讨论一个问题:计算结构体的大小
这也是一个特别热门的考点:结构体内存对齐
注:结构体类型的大小是由结构体内存对齐来决定的。
看下面代码:
cpp
#include <stdio.h>
struct S1
{
char c1;
char c2;
int a;
};
struct S2
{
char c1;
int a;
char c2;
};
int main()
{
int ret1 = sizeof(struct S1);
int ret2 = sizeof(struct S2);
printf("%d\n%d\n", ret1, ret2);
return 0;
}运行结果:

结果不一样,为什么?虽然是不同的结构类型,但是每个结构类型的成员都是一模一样的,不同点就是顺序有所差异,为什么最后类型的大小不一样?
这就要谈到结构体的对齐规则了,如果结构体的成员顺序有所差异,也会导致对齐规则开辟的空间大小不相同。
2.1 对齐规则
首先得掌握结构体的对齐规则:
结构体的第一个成员对齐到和结构体变量起始位置偏移量为0的地址处
其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处
对齐数 = 编译器默认的一个对齐数 与 该成员变量大小的较小值
- VS中默认的值为8
- Linux中gcc没有默认对齐数,对齐数就是成员自身的大小
结构体总大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍
如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己成员中最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍
知道了上面的规则了,那我们就可以通过例子来更加清晰的认识到对齐规则。
例1:
我们先来看结构体struct S1是如何在内存中对齐的:
cpp
struct S1
{
char c1;
char c2;
int c3;
};首先就是第一条规则:结构体的第一个成员对齐到和结构体变量起始位置偏移量为0的地址处

其他的成员就是第二条规则:其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处
对齐数 = 编译器默认的一个对齐数 与 该成员变量大小的较小值
- VS中默认的值为8
- Linux中没有默认对齐数,对齐数就是成员自身的大小
c2是char类型,大小是1字节,和默认对齐数8对比1最小,1的整数倍是任何数

还是第二规则,c3是int类型,大小4字节,默认对齐数是8字节,所以要对齐到4的整数倍的偏移量的位置

最后就是第三规则:结构体总大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍。
注意:这里的整数倍不是看偏移量,是看已占内存空间大小是不是整数倍

例2:
然后再来看struct S2的对齐过程:
cpp
struct S2
{
char c1;
int a;
char c2;
};还是第一条规则:让第一个成员对齐到偏移量为0的地址处

然后第二条规则:对比默认对齐数,选出最小对齐数对齐到该对齐数的整数倍

还是第二条规则,对齐到char类型对齐数的整数倍

最后就是第三条规则:结构体最终大小是最大对齐数的整数倍,该结构体最大对齐数是4

那可能有人问了,中间不是还空着内存空间吗?为什么不用呢?这样放在一起不是更节省空间吗?为什么要浪费呢?
虽然在内存开辟那么大的空间,但是对齐后中间可能会有开辟的空间但未使用,这是因为对齐规则就是这样,是以空间换取效率的开辟方式,也是为了平台的移植性。
如果使用结构体时想要知道某个成员的偏移量,难道我们要自己算出来吗?当然不是,我们可以使用C语言里的一种宏,叫offsetof,offsetof需要两个参数:
cpp
offsetof(type,member);
类型 成员使用offsetof只需要传一个结构体类型,再将结构体类型成员传过去,他会返回size_t类型的一个值,这个值就是它计算出的偏移量。
如果想要使用必须包含头文件**#include <stddef.h>**
cpp
#include <stdio.h>
#include <stddef.h>
struct S1
{
char c1;
char c2;
int a;
};
int main()
{
printf("%zd\n",offsetof(struct S1,c1));
printf("%zd\n",offsetof(struct S1,c2));
printf("%zd\n",offsetof(struct S1,a));
return 0;
}2.2 为什么存在内存对齐
大部分的参考资料都是这样说的:
- 平台原因(移植原因)
不是所有的硬件平台都能访问任意类型地址上任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因
数据结构(尤其是栈)应该尽可能地在自然边界上对齐,原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存仅需一次访问。假设一个处理器总是从内存中取8个字节,则地址必须是8的倍数。如果我们能保证将所有double类型的数据的地址都对齐成8的倍数,那么就可以用一个内存操作来读或写值了。否则,我们可能需要执行两次内存访问,因为对象可能被分放在两个8字节内存块中。
总体来说 :结构体的内存对齐是拿空间 来换取时间的做法。
那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到:
让占用空间小的成员尽量集中在一起:
cpp
//例如
struct S1
{
char c1;
int a;
char c2;
};//占用了12个字节
struct S2
{
char c1;
char c2;
int a;
};//占用了8个字节S1和S2类型的成员一模一样,但是S1和S2所占空间大小有一定的区别
2.3 修改默认对齐数
#pragma 这个预处理指令,可以改变编译器的默认对齐数。
cpp
#include <stdio.h>
#pragma pack(1)//设置默认对齐数为1
struct S
{
char c1;
int a;
char c2;
};
#pragma pack()//取消设置的默认对齐数,还原默认对齐数
int main()
{
printf("%d\n", sizeof(struct S));
return 0;
}结构体在对齐方式不合适的时候,我们可以自己更改默认对齐数
3、结构体传参
函数调用时,结构体传参尽量传地址过去,因为结构体可能是一个非常大的空间,在传参时是需要压栈来存储传过来的实参的,所以我们将地址传参过去,可以提高程序效率。
两种结构体传参方式:
方法1:传值调用
cpp
#include <stdio.h>
struct S
{
int data[10];
int num;
};
void print1(struct S s)
{
int sz = sizeof(s.data) / sizeof(s.data[0]);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", s.data[i]);
}
printf("\n%d\n", s.num);
}
int main()
{
struct S s = { {1,2,3,4,5,6,7,8,9,10},20 };
print1(s);//传递结构体变量
return 0;
}方法2:传址调用
cpp
#include <stdio.h>
struct S
{
int data[10];
int num;
};
void print2(const struct S* s)//不希望指针修改该空间就修饰const
{
int sz = sizeof(s->data) / sizeof(s->data[0]);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", s->data[i]);
}
printf("\n%d\n", s->num);
}
int main()
{
struct S s = { {1,2,3,4,5,6,7,8,9,10},20 };
print2(&s);//传递结构体变量的地址
return 0;
}'->'是结构体指针解引用操作符,正常结构体使用 ' . ' 来访问成员,而结构体指针可以直接使用 '->'来访问成员
cpp
stu->num ==等价于== *(stu).num上面两种传参方式哪种更好?
答案是:首选传址调用。
原因:
1. 函数传参的时候,参数是需要压栈的,会有时间和空间上的系统开销。
**2.**如果传递一个结构体对象的时候,结构体过大,参数压栈的系统开销比较大,所以会导致性能下。
**结论:**结构体传参的时候,要传结构体的地址。
4、位段
结构体讲完就得讲讲结构体实现 位段 的能力。
**注:**位段是基于结构体,位段的出现是为了节省空间
4.1 什么是位段
位段的声明和结构是类似的,有两个不同:
1. 位段的成员必须是 int、unsigned int、或 signed int,在C99 中位段成员的类型也可以选择其他类型。
**2.**位段的成员名后边有一个冒号和一个数字
比如:
cpp
struct A
{
int _a:2;
int _b:5;
int _c:10;
int _d:30;
};那冒号 ' : ' 后面的数字是什么意思呢?其实冒号后面的数字是给该成员分配的空间大小,单位是二进制位,比如成员_a后面是:2意思是我给该成员分配2个二进制位来存放数据,1个二进制位是1bit,所以可以简单理解为后面的数字的单位就是bit。
所以成员变量_a:2就是2个bit位,_b:5就是5个bit位,_c:10就是10个bit位,_d:30就是30个bit位。
注:结构体位段不会内存对齐
知道了位段信息,我们就可以根据该信息算出上面的结构体A的大小,最后算出一共是47个bit位,大概是6个字节。如果不使用位段4个整型的变量也是16个字节。但是结果真的是6个字节吗?我们可以使用sizeof运算一下。
cpp
#include <stdio.h>
struct A
{
int _a:2;
int _b:5;
int _c:10;
int _d:30;
};
int main()
{
printf("%d\n",sizeof(struct A));
return 0;
}运算结果:

我们算出的位段总共加起来差不多6个字节,那为什么结果是8个字节呢?
这就要看位段的内存分配方式了,经过第一个成员位段在开辟空间时首先不管成员位段后面的空间,而是看成员的类型,是int类型就先开辟一个4个字节,32个二进制位的空间。开辟好后就开始看第一个成员变量_a位段的数字,首先是2bit,可以存放。接下来是看_b和_c后面的数字,还是可以在所开辟的空间范围之内申请空间。此时已经占用了17个bit位了,但是_d是30,剩下的空间不够申请30个bit了,所以又要开辟一块空间,怎么开辟呢?就是要看_d的类型,是整型所以又开辟了32个bit,又开辟了4个字节,最后分配给_d30个bit。所以最后结果是8个字节。可以看到位段可能会浪费一些空间,但是相对结构体位段的空间节省较好一些。

注意:位段后面分配的位数大小是不能超出自身类型的大小的,比如char类型的变量不能分配9个bit,int类型不能分配33个bit。
4.2 位段的内存分配
1. 位段成员可以是int、unsigned int、signed int 或是 char等类型。
2. 位段的空间是按照需要以4个字节(int)或者1个字节(char)的方式来开辟的。
3. 位段涉及很多不确定因素,位段是不跨平台的,注意可移植的程序应该避免使用位段。
为了大家能够更深刻的理解位段,特举了下面代码例子:
cpp
struct S
{
char a:3;
char b:4;
char c:5;
char d:4;
};
int main()
{
struct S s = {0};
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
printf("%d\n",sizeof(s));
return 0;
}该位段大小为3个字节,为什么是三个字节呢?那这些值在内存中如何存储的呢?可以根据下图来分析。


4.3 位段的跨平台问题
1. int 位段被当成有符号数还是无符号数是不确定的。
**2.**位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32,写成27,在16位机器会出问题)。
3. 位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
**4.**当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位是,是舍弃剩余的位还是利用,这是不确定的。
**总结:**跟结构相比,位段可以达到同样的效果,并且可以很好地节省空间,但是有跨平台的问题存在。
4.5 位段使用的注意事项
位段的几个成员共有同一个字节,这样有些成员的起始位置并不是某个字节的起始位置,那么这些位置处是没有地址的,内存中每个字节分配一个地址。一个字节内部的bit位是没有地址的。
所以不能对位段的成员使用&操作符,这样不能使用scanf直接给位段的成员输入值,只能是先输入放在一个变量中,然后赋值给位段成员。
第十三章:自定义类型(联合union 、枚举enum)
1、联合体
1.1 联合体类型的声明
像结构体一样,联合体也是由一个或多个成员构成,这些成员可以是不同的类型。
但是编译器只为最大的成员分配足够的内存空间,联合体的特点是所有成员共用一块内存空间,所以联合体也叫:共用体
struct 是结构体类型前缀,union是联合体类型前缀。
和结构体一样,联合体类型的声明也是这样的:
cpp
#include <stdio.h>
union U
{
char c;
int i;
};
int main()
{
union U u = {0};
printf("%d\n",sizeof(u));
return 0;
}结果为4个字节;不对啊!一个int类型成员是4字节,还有一个char类型的成员,加起来怎么说也得有5个字节,为什么只有4个字节呢?这就是联合体的特点。
看下面的代码:
cpp
#include <stdio.h>
union U
{
char c;
int i;
};
int main()
{
union U u = { 0 };
printf("%p\n", &u);
printf("%p\n", &(u.i));
printf("%p\n", &(u.c));
return 0;
}运行结果:
三个地址还是一样,我们可以来分析一下为什么。如果三个地址一样可以说明这个联合体变量只有一块4个字节的空间,所以联合体变量本身的地址就是这块空间的首字节地址,然后就是2个成员,2个成员的地址相同说明什么,说明它们共用一块空间,这就是联合体的特点。
1.2 联合体的特点
联合的成员是共用同一块内存空间的,这样一个联合变量的大小,至少是最大成员的大小(因为联合至少得有能力保存最大的那个成员)
知道了联合体的特点,那来看一下以下代码会打印什么:
cpp
#include <stdio.h>
union U
{
char c;
int i;
};
int main()
{
union U u = { 0 };
u.i = 0x11223344;
u.c = 0x55;
printf("%#x\n", u.i);
return 0;
}运行结果:
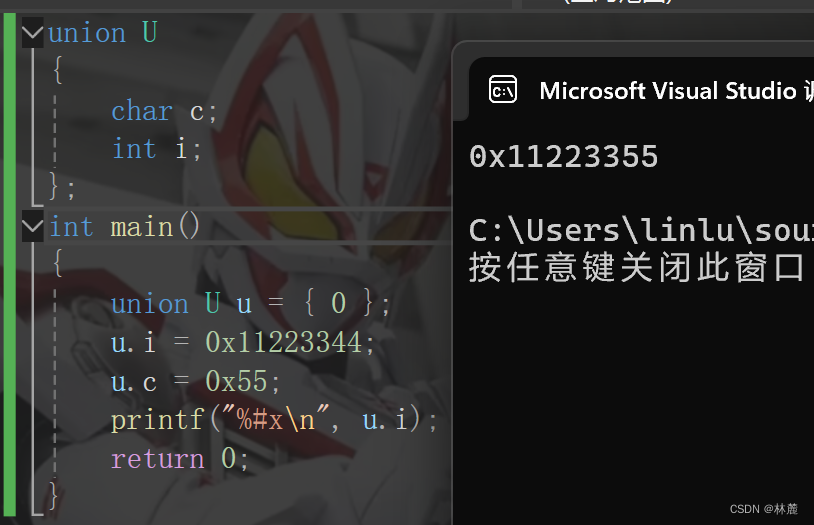
1.3 相同成员的结构体和联合体对比
我们再对比一下相同成员的结构体和联合体的内存布局情况。
cpp
struct S
{
char c;
int i;
};
struct S s = {0};
cpp
union Un
{
char c;
int i;
};
union Un un = {0};
1.4 联合体大小的计算
联合体的大小至少是最大成员的大小。
当最大成员的大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍。
联合体的最终大小也是要对齐到最大对齐数的整数倍的,既然知道了联合体大小的计算,那来计算一下这个代码的结果:
cpp
#include <stdio.h>
union Un1
{
char c[5];
int i;
};
union Un2
{
short c[7];
int i;
};
int main()
{
printf("%d\n", sizeof(union Un1));
printf("%d\n", sizeof(union Un2));
return 0;
}运算结果:
最大对齐数还是4,因为成员i是最大对齐数,千万不要以为数组的整体大小才算对齐数,其实数组的对齐数就是数组每个成员类型的大小。
1.5 联合体的应用场景
知道了联合体是什么,什么特点以及怎么使用,那联合体的应用场景是什么?
先举个例子:比如我想写一个游戏,需要有一个架构来保存角色的不同职业信息。那有人可能会写出这样的代码:
cpp
struct Game
{
//角色基础信息
char name[20];//名字
char sex[5];//性别
enum color c;//角色头发颜色
//剑士
int l1;//攻击
struct K k;//剑士技能
//刺客
int j1;//机敏
struct C c;//刺客技能
};当我选择剑士时,只使用给剑士数据开辟的空间,当我选择刺客时,只使用给刺客数据开辟的空间。虽然只选择一个职业时,只给一个职业的内存存入数据。由于是结构体,另一个未选择的职业也是有开辟空间的。这就导致了开辟了多余的空间但却空着不使用,从而造成了空间浪费。这时候联合体union就派上了用处,如果只想给架构中一部分变量的内存存入数据,并保证另一部分不占用空余的空间就使用联合体。相当于两个不同角色职业的数据可以存储在同一个内存空间,但并不是两个一块存储,而是有一方需要存入数据时保证另一方不占用多余空间,而使用另一方存入数据时保证这一方不会占用多余的空间,这就是联合体的作用
cpp
struct Game
{
//角色基础信息
char name[20];//名字
char sex[5];//性别
enum color;//角色头发颜色
//职业数据
union{ //如果在内部创建只使用一次,创建一次内部可以无限调用,所以可以在结构体内部创建匿名联合体或结构体
//剑士
struct{
int l1;//攻击
struct K Sdm;//剑士技能
}Swordsman;
//刺客
struct{
int j1;//机敏
struct C Asin;//刺客技能
}assassin;
}un;
};这下应该知道union联合体的作用了吧!
**union联合体的应用场景:**当有两个或多个相同类型的数据需要一个结构来集成在一起,但是每次使用只使用一个类型的空间,我们可以将这多个类型的全部集成一个联合体,每个类型的地址都是一块空间,相当于共用一块,使用一个类型也保证了其他类型不额外占用多余空间。
联合体练习:
我们也可以通过联合体来判断当前场景为大端还是小端:
cpp
#include <stdio.h>
union Un
{
int i;
char c;
};//因为是共用4个字节,并且两个成员的地址都是首字节低地址处
int main()
{
union Un un = { 0 };
un.i = 1;//将里面的i赋值为1,小端会将1的低位字节放在低地址处,大端会将低位字节放在高地址处
if (un.c == 1)//成员c本身就是这块空间的低地址,只需要判断低地址处的是1还是0
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}2、枚举类型
2.1 枚举类型的声明
没枚举顾名思义就是一一列举。
把可能的取值一一列举。
比如我们现实生活中:
一周的星期一到星期日是有限的7天,可以一一列举
性别有:男、女、保密,也可以一一列举
月份有12月,也可以一一列举
三原色,也是可以一一列举
这些数据的表示就可以使用枚举了。
cpp
enum Day//星期
{
Mon,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
enum Sex//性别
{
MALE,
FAMALE,
SECRET
};
enum color//颜色
{
RED,
GREEN,
BLUE
};这里枚举里的常量都是列出的枚举类型的可能取值
这些列出的可能取值被称为:枚举常量
每个枚举里的常量,从第一个默认都是0,依次向下增长的常量集合。
cpp
#include <stdio.h>
enum Day//星期
{
Mon,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
int main()
{
printf("%d %d %d %d %d %d %d\n", Mon, Tues, Wed, Thur, Fri, Sat, Sun);
return 0;
}运行结果:
从这里我们可以看出,枚举和(联合、结构体)的格式是不相同的,枚举里的不是成员,而是标识符常量,定义了这些标识符我们就可以直接使用该标识符来打印对应的常量,不用再额外创建该枚举类型变量再访问该标识符。所以简单来说枚举类型就是一堆标识符常量的集合类型。
如果不想默认从0开始打印我们就可以更改第一个标识符赋值一个值,后面的标识符的值则是该值依次增长所得到的值。
cpp
#include <stdio.h>
enum Day//星期
{
Mon=5,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
int main()
{
printf("%d %d %d %d %d %d %d\n", Mon, Tues, Wed, Thur, Fri, Sat, Sun);
return 0;
}运行结果:
注意:只有在声明枚举常量时里面的标识符可以被赋予一个初始值,但是声明好后在去给枚举里的标识符常量赋值是会报错的,原因是该标识符是常量,不能被更改。
cpp
enum Day//星期
{
Mon=5,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
int main()
{
Mon = 10;//error
return 0;
}2.2 枚举类型的优点
为什么使用枚举呢?
我们可以使用#define定义常量,为什么非要使用枚举?
枚举的优点:
**1.**增加代码的可读性和可维护性
2. 和#define定义的标识符比较枚举有类型检查,更加严谨
**3.**便于调试,预处理阶段会删除#define定义的符号
**4.**使用方便,一次可以定义多个常量
**5.**枚举常量是遵循作用域规则的,枚举声明在函数内,只能在函数内使用
2.3 枚举类型的使用
cpp
enum Color
{
RED = 1,
GREEN = 2,
BLUE = 3
};
enum Color clr = GREEN;//使用枚举常量给枚举变量赋值那是否可以拿整数给枚举变量赋值呢?在C语言中是可以的,但是在C++是不行的,C++的类型检查比较严格。
第十四章:动态内存管理
1、为什么要有动态内存分配
我们已经掌握的内存开辟方式有:
cpp
创建变量
char c = 0;
int a = 0;
int arr[10] = {0};但是上述的开辟空间的方式有两个特点:
- 空间开辟大小是固定的
- 数组在声明的时候,必须指定数组的长度,数组空间一旦确定了大小不能调整
但是对于空间的需求,不仅仅是上述的情况。有时候我们需要的空间大小在程序运行的时候才知道,那数组的编译时开辟空间的方式就不能满足了
当数组创建好后空间大小是不能调整的,一旦创建好数组后数组空间的大小就是固定的,所以才引入了动态内存分配,刚开始可以分配10个整型元素的空间,当这10个空间不够用了,我们就可以继续申请扩容空间容量,继续使用。
C语言引入了动态内存开辟,让程序员自己可以申请和释放空间,就比较灵活了。
2、malloc和free
malloc是用来申请内存的 ,动态内存开辟的方式有些特殊,开辟的内存空间并不是栈区的空间,而是堆区的空间,所以程序结束时并不会自动销毁并回收该空间,所以就有了free,每次用完该空间就记得使用free将该空间释放掉。不然它将一直占用内存空间。
调用动态内存开辟 函数时需要包含头文件**#include <stdlib.h>**
2.1 malloc
malloc函数的声明:
cpp
void* malloc(size_t size);这个函数向内存申请一块连续可用的空间,并返回指向这块空间的指针。
- 如果开辟成功,则返回一个指向开辟好空间的指针
- 如果开辟失败,则返回一个NULL指针,因此malloc的返回值一定要做检查
- 返回值的类型是void*,所以malloc函数并不知道开辟空间的类型,具体在使用的时候由使用者自己来决定
- 如果参数size为0,malloc的行为是标准还是未定义的,取决于编译器
malloc函数的使用:
cpp
#include <stdlib.h>
int main()
{
//申请10个整型的空间 - 40个字节
int* p = (int*)malloc(10 * sizeof(int));
if (p == NULL)//判断
{
perror("malloc");
return 1;
}
int i = 0;
for (i = 0; i < 10; i++)
{
p[i] = i;
}
for (i = 0; i < 10; i++)
{
printf("%d ", p[i]);
}
return 0;
}既然可以申请到空间并且使用,那还需要释放掉该空间,那怎么释放呢?
malloc申请的空间怎么回收呢?
1. free回收
**2.**自己不释放的时候,程序结束后,也会由操作系统回收
注:动态内存开辟的函数开辟空间都是在堆区上开辟的,内存是分为三个区域:栈区、堆区、静态区
2.2 free
free的函数声明:
cpp
void free(void* ptr);free是用来释放动态开辟的空间的,只需要将这块空间的起始位置的指针传递给free,free可以通过该地址向后释放这块空间。
free函数就是用来释放动态开辟的内存。
- 如果参数ptr指向的不是动态开辟的,那free函数的行为是未定义的。
- 如果参数ptr是NULL指针,则函数什么事都不做
注意:free释放的空间仅限于动态内存开辟的空间,必须是堆区的空间
free函数的使用:
cpp
#include <stdlib.h>
#include <stdio.h>
int main()
{
//申请10个整型的空间 - 40个字节
int* p = (int*)malloc(10 * sizeof(int));
if (p == NULL)//判断
{
perror("malloc");
return 1;
}
int i = 0;
for (i = 0; i < 10; i++)
{
p[i] = i;
}
for (i = 0; i < 10; i++)
{
printf("%d ", p[i]);
}
free(p);//使用完该空间调用free释放掉该空间
p = NULL;//当free掉p指向的空间后这块空间就不能使用了,记得让指针改变指向
return 0;
}给free一个指向开辟好的堆区的指针,就可以通过这个指针释放空间。最后不要忘了将指向free释放掉的空间的指针指向NULL,因为它指向的空间已经被free释放,再解引用就是非法访问了,所以要置为NULL。
3、calloc和realloc
3.1 calloc
C语言还提供了一个函数叫calloc,calloc函数也用来动态内存分配,原型如下:
cpp
void* calloc(size_t num,size_t size)calloc函数的注意事项:
- 如果开辟成功,则返回一个指向开辟好空间的指针
- 如果开辟失败,则返回一个NULL指针,因此calloc的返回值一定要做检查
- 返回值的类型是void*,所以calloc函数并不知道开辟空间的类型,具体在使用的时候由使用者自己来决定
可以看见calloc的参数比malloc的参数多了一个,calloc和malloc一样,都是动态内存开辟的,那这多出的一个参数有什么不同呢?calloc和malloc的区别又是什么。
malloc和calloc的区别:
1. **参数区别:**malloc的参数size是需要动态开辟的字节大小,calloc的参数1 num是需要开辟的元素个数,参数二 size是每个元素的大小。
**2.****功能区别:**malloc开辟好空间后什么也不管并直接返回该空间的初始地址,而calloc开辟好空间会将空间里全部初始化为0并返回初始地址。
所以它们除了上面不同外,其他地方基本相同:
cpp
这两种开辟方式基本上都相同:
int* p = (int*)malloc(10*sizeof(int));
int* p = (int*)calloc(10,sizeof(int));我们可以打印一下试试calloc开辟的空间是否初始化为全0:
cpp
#include <stdio.h>
#include <stdlib.h>
int main()
{
int* p = (int)calloc(10, sizeof(int));
if (p == NULL)
{
perror("calloc");
return 1;
}
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", p[i]);
}
return 0;
}运行结果:

3.2 realloc
- realloc函数的出现让动态内存管理更加灵活
- 有时我们会发现过去申请的空间太小了,有时我们又会觉得申请的空间过大了,那为了合理的使用内存,我们一定会对内存的大小做灵活的调整。那realloc函数就可以对动态开辟内存进行扩容
函数原型如下:
cpp
void* realloc(void* ptr,size_t size);- ptr是需要调整的内存地址
- size调整之后新的大小
- 返回值为调整之后的内存起始位置
- 这个函数调整原内存空间大小的基础上,还会将原来内存中的数据移动到新的空间
假设malloc开辟的空间不够用了,那就可以使用realloc在原有的空间大小开辟出新的空间大小:
cpp
#include <stdio.h>
#include <stdlib.h>
int main()
{
int* ptr = (int)malloc(20);
if (ptr != NULL)
{
int* tmp = (int*)realloc(ptr, 40);//注意realloc开辟空间需要新的指针来接收,不要用原来的指针来接收
}
return 0;
}realloc在调整内存空间存在两种情况:
**1.**原有空间之后有足够大的空间
2. 原有空间之后没有足够大的空间
如果是情况1,后面未分配的空间足够需要开辟的大小,就会在原有的空间的基础上增加开辟空间的大小。
但如果是情况2,后面未分配的空间不够需要开辟的大小,编译器找一个新的空间并会将之前开辟空间里面存储的数据存放进新找到的空间并将原来的空间销毁。
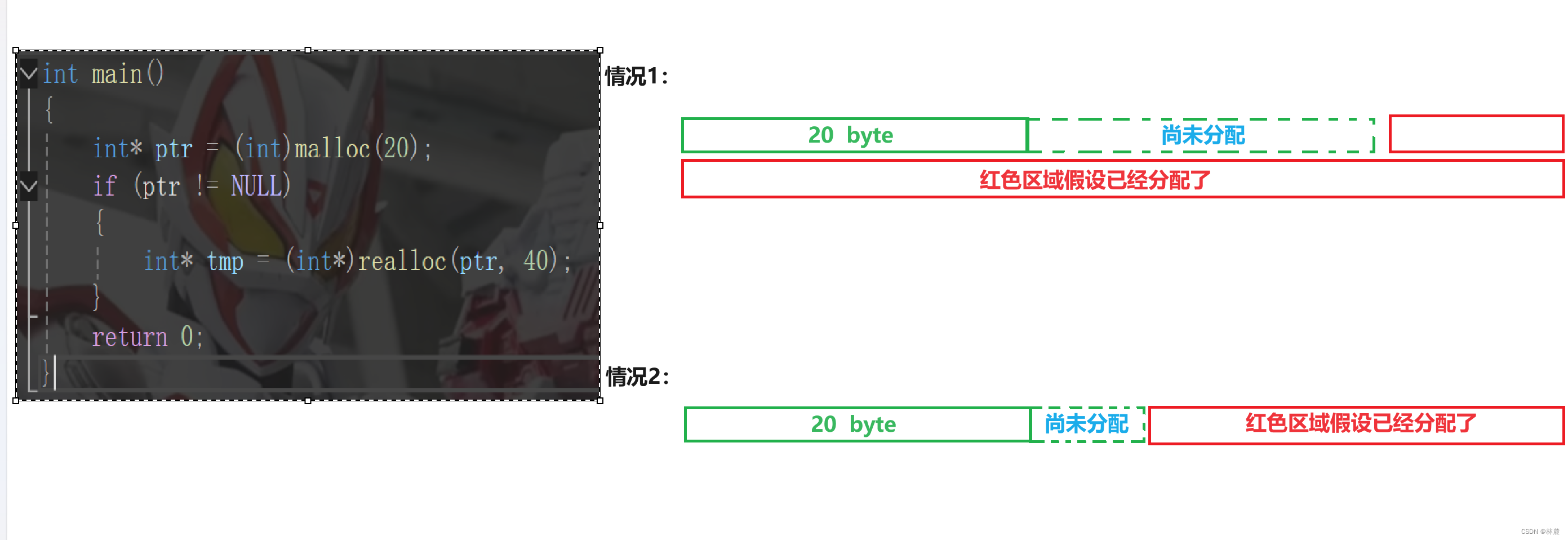
那我们可以用原来接收malloc返回值的指针,来接收realloc新开辟的空间地址吗?
cpp
#include <stdlib.h>
int main()
{
int* p = (int*)malloc(5*sizeof(int));
if(p==NULL)
{
perror("malloc");
return 1;
}
int* p = (int*)realloc(p,10*sizeof(int));
return 0;
}当然不能,如果p来接收新开辟的空间地址,是接收了。但realloc可能也会开辟失败返回NULL,如果用了p来接收,不但没有接收到新开辟空间的地址,而且NULL还弄丢了之前开辟空间的地址。
解决方法: 可以再创建一个指针变量,当指针变量接收realloc的返回值时,判断是否是NULL,不是就说明开辟成功了,可以赋值给p。
cpp
#include <stdlib.h>
int main()
{
int* ptr = (int)malloc(20);
if (ptr == NULL)
{
perror("malloc");
return 1;
}
int* tmp = (int*)realloc(ptr, 40);
if (tmp != NULL)
{
ptr = tmp;
tmp = NULL;
}
else
{
perror("realloc");
return 1;
}
return 0;
}**注:**realloc函数不仅仅是扩容来使用的,也可以将realloc当malloc使用
realloc函数的第一个参数是一块动态开辟内存的地址,然后通过这个地址继续给这块动态开辟的空间来扩容。但是realloc不仅仅是扩容来使用的,也可以将realloc当malloc使用,比如第一个参数什么地址都不传就传递一个空指针NULL 就可以了,realloc函数接收到NULL,就已经不是接收地址在地址指向的空间后面继续开辟,而是会自动在堆区找一块内存空间开辟并返回该空间的地址,大小还是有第二个参数来决定。
cpp
#include <stdlib.h>
int main()
{
int* p = (int*)realloc(NULL,20);
等价于
int* p = (int*)malloc(20);
return 0;
}总结:
**1.**使用malloc 或 realloc 函数开辟的空间不会被初始化为全0,只有使用calloc函数开辟的空间会被初始化为全0。
2.free函数只能释放动态内存开辟的空间,如果传入其他空间的地址会报错。还有当把一个动态内存的地址传给free释放掉这块空间后,要将指向这块空间的指针置为NULL,以免造成非法访问
3. realloc函数一般是用来扩容空间使用的,但是当传递NULL给realloc函数时,此时的realloc和malloc是等价的,都是直接开辟一块动态内存并返回地址
4、常见的动态内存错误
4.1 对NULL指针的解引用操作
不管是malloc、calloc还是realloc这些函数在 开辟 / 调整 空间失败的时候,会返回NULL,而我们并未判断并解引用则会导致NULL指针解引用操作的错误出现
cpp
#include <stdlib.h>
int main()
{
int* p = (int*)malloc(20);//有可能返回空指针
int i = 0;
for (i = 0; i < 5; i++)
{
*(p + i) = i;
}
free(p);
p = NULL;
return 0;
}**解决方法:**每次开辟或调整完空间后判断指针接收到的是不是NULL,提前进行判断并解决
cpp
#include <stdlib.h>
int main()
{
int* p = (int*)malloc(20);
if(p==NULL)//开辟完后进行判断
{
return 1;//提前结束程序
}
int i = 0;
for (i = 0; i < 5; i++)
{
*(p + i) = i;
}
free(p);
p = NULL;
return 0;
}4.2 对动态开辟的空间越界访问
动态开辟的空间也是有使用范围的,和数组一样,当越界访问时就会报错
cpp
#include <stdlib.h>
int main()
{
int* p = (int*)malloc(20);//只申请了5个整型大小的空间
if(p==NULL)
{
return 1;
}
int i = 0;
for (i = 0; i < 20; i++)//解引用访问了20个整型大小的空间,属于越界访问
{
*(p + i) = i;
}
free(p);
p = NULL;
return 0;
}**解决方法:**使用时注意尽量避免越界访问就可以了
4.3 对非动态开辟内存使用free释放
cpp
#include <stdlib.h>
int main()
{
int a = 10;
int* p = &a;
free(p);//error
reutrn 0;
}**解决方法:**使用free时注意只能传动态开辟的地址就可以了
4.4 使用free释放一块动态开辟内存的一部分
cpp
#include <stdlib.h>
int main()
{
int* p = (int*)malloc(20);
if(p==NULL)
{
return 1;
}
p += 1;//拿到跳过一个整型大小的地址
free(p);
p = NULL;
return 0;
}**解决方法:**尽量不要改变p地址的指向,如果要改变,提前创建一个指针指向该块动态内存空间的起始位置就可以了
4.5 对同一块动态内存多次释放
cpp
#include <stdlib.h>
int main()
{
int* p = (int*)malloc(20);
if (p == NULL)
{
return 1;
}
free(p);
free(p);//重复释放
return 0;
}**解决方法:**释放完后给指向这块空间地址的指针置为NULL,下一次free这个指针时什么也不会发生
cpp
#include <stdlib.h>
int main()
{
int* p = (int*)malloc(20);
if (p == NULL)
{
return 1;
}
free(p);
p = NULL;
free(p);
return 0;
}4.6 动态开辟内存忘记释放(内存泄漏)
cpp
#include <stdlib.h>
int main()
{
int* p = (int*)malloc(20);
if(p==NULL)
{
return 1;
}
int i = 0;
for (i = 0; i < 5; i++)
{
*(p + i) = i;
}
return 0;
}**解决方法:**你申请的动态内存当不再使用时记得使用free释放该空间
5、柔性数组
也许你从来没听说过柔型数组(flexible array)这个概念,但是它确实是存在的。
C99中,结构中最后一个元素允许是未知大小的数组,这就叫做【柔性数组】成员。
柔性数组:
**1.**一定在结构体中
**2.**一定是最后一个成员
**3.**一定是未知大小的数组(柔型数组)
注:并且柔性数组是需要配合动态内存管理来使用的
例如:
cpp
typedef struct st_type
{
int i;
int a[];//柔性数组成员
}type_a;5.1 柔性数组的特点:
- 结构中的柔性数组成员前面必须至少要有一个其他成员
- sizeof返回这种结构的大小不包括柔性数组的内存
- 包含柔性数组成员的结构用malloc函数进行内存的动态分配,并且分配的内存应该大于结构的大小,以适应柔型数组的预期大小
例如:
cpp
#include <stdio.h>
struct st_type
{
int i;
int a[];//柔性数组成员
};
int main()
{
printf("%d\n",sizeof(struct st_type));//打印结果为:4
return 0;
}5.2 柔性数组的使用
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct st_type
{
int i;
int a[];
};
int main()
{
struct st_type* p = (struct st_type*)malloc(sizeof(struct st_type) + 10 * sizeof(int));
if (p == NULL)
{
perror("malloc");
return;
}
p->i = 100;
int i = 0;
for (i = 0; i < 10; i++)
{
p->a[i] = i + 1;
}
//我们觉得给柔性数组10个整型空间不够怎么办?我们可以使用realloc增容
struct st_type* ptr = (struct st_type*)realloc(p, sizeof(struct st_type) + 15 * sizeof(int));
if (ptr != NULL)
{
p = ptr;
ptr = NULL;
}
else
{
perror("realloc");
return 1;
}
//使用
// ...
//释放
free(p);
p = NULL;
return 0;
}第十五章:文件操作
1、为什么使用文件?
如果没有文件,我们写的程序的数据是存储在电脑的内存中,如果程序退出,内存回收,数据就丢失了,等再次运行程序,是看不到上次程序的数据的,如果要将数据进行持久化的保存,我们可以使用文件。
2、什么是文件?
磁盘(硬盘)上的文件就是文件。
但是程序设计中,我们一般谈两个文件,分别是程序文件、数据文件(从文件的角度来分类的)。
2.1 程序文件
程序文件包括源程序文件(后缀为.c)、目标文件(windows环境后缀为.obj),可执行文件(windows环境后缀为.exe)。
2.2 数据文件
文件的内容不一定是程序,而是程序运行时读写的数据,比如程序运行需要从中读取数据的文件,或者输出内容的文件。
本章讨论的是数据文件。
在以前各篇笔记所处理数据的输入输出都是以终端为对象的,即从终端的键盘输入数据,运行结果显示到显示器上,其实有时候我们会把信息输出到磁盘上,当需要的时候再从磁盘上把数据读取到内存中使用,这里处理的就是磁盘上的文件。
2.3 文件名
一个文件要有唯一的文件表示,以便用户识别和引用。
文件名包含3部分:文件路径+文件主干+文件后缀
例如:c:\code\test.txt
为了方便起见,文件标识常被称为文件名。
3、二进制文件和文本文件
根据数据的组织形式,数据文件被称为文本文件 或者二进制文件。
数据在内存中以二进制的形式存储,如果不加转换的输出到外存的文件中,就是二进制文件。
如果要求在外出上以ASCII的形式存储,则需要再存储前转换,以ASCII字符的形式存储的文件就是文本文件。
一个数据在文件中是怎么存储的呢?
字符一律以ASCII形式存储,数值型数据既可以用ASCII形式存储,也可以用二进制形式存储。
比如有整数10000,如果以ASCII码的形式输出到磁盘,则磁盘中占用5个字节(每个字符一个字节),而二进制形式输出,则在磁盘上只占4个字节。

代码栗子:
cpp
#include <stdio.h>
int main()
{
int a = 10000;
FILE* pf = fopen("test.txt", "wb");//打开文件
fwrite(&a, 4, 1, pf);//二进制的形式写到文件中
fclose(pf);//关闭文件
pf = NULL;
return 0;
}4、文件的打开和关闭
4.1 流和标准流
4.1.1 流
程序的数据是要输出到各种外部设备,也需要从外部设备获取数据,不同的外部设备的输入输出操作各不相同,为了方便程序员对各种设备进行方便的操作,我们抽象出了流的概念,我们可以把流想象成流淌着字符的河。C程序真的文件、画面、键盘灯的数据输入输出操作都是通过流操作的。
一般情况下,我们要想向流里写数据,或者从流里读数据,都是要打开流,然后操作。
4.1.2 标准流
文件操作时我们需要自己打开文件(流),当操作完后需要自己关闭文件(流),那为什么我们从键盘输入数据,向屏幕上输出数据,并没有打开流呢?
那是因为C语言程序在启动的时候,默认打开了3个流:
- stdin - 标准输入流,大多数的环境中从键盘输入,scanf函数就是从标准输入流中读取数据。
- stdout - 标准输出流,大多数环境中输出值显示器界面,printf函数就是将信息输出到标准输出流中。
- stderr- 标准错误流,大多数环境中输出到显示器界面。
这是默认打开了这三个流,我们使用scanf、printf等函数就可以直接进行输入输出操作的。
stdin、stdout、stderr 三个流的类型是:FILE* ,通常称为文件指针。
C语言中,就是通过**FILE***的文件指针来维护流的各种操作的。
4.2 文件指针
缓冲文件系统中,关键的概念是 "文件类型指针 " ,简称为 "文件指针"。
每个被使用的文件都在内存中开辟了一个相应的文件信息区 ,用来存放文件的相关信息(如文件的名字,文件状态及文件当前的位置等)。这些信息是保存在一个结构体变量中的,该结构体类型是由系统声明的,取名FILE。
例如:VS2013编译环境提供的stdio.h头文件中有以下的文件类型声明:
cpp
struct _iobuf{
char *_ptr;
int _cnt;
char* _base;
int _flag;
int _file;
int _charbuf;
int _bufsiz;
char* tmpfname;
};
typedef struct _ioduf FILE;不同的c编译器的FILE类型包含的内容不完全相同,但是大同小异。
每当打开一个文件的时候,系统会根据文件的情况自动创建一个FILE类型的变量,并填充其中信息,该结构体类型的变量里存放着我们需要打开的文件的信息,因此被称为文件信息区。使用时不必关心细节。开辟好文件信息区后便会返回该信息区的地址,我们需要FILE*类型的指针来接收这个地址,这个FILE*类型指针就是流,属于文件的流。
一般都是通过FILE指针来维护这个FILE结构变量,这样使用更加方便。
cpp
FILE* PF;//文件指针变量定义pf是一个指向FILE类型的指针变量,可以使pf指向某个文件的文件信息区(是一个结构体变量),通过该文件信息区中的信息就能够访问该文件,也就是说,通过文件指针变量能够间接找到与它关联的文件。
比如:

4.3 文件的打开和关闭
文件在读写之前应该先打开文件,在使用结束之后应该关闭文件。
在编写程序的时候,在打开文件的同时,都会返回一个FILE*的指针变量指向该文件,也相当于建立了指针和文件的关系。
ANSI C规定使用fopen来打开文件,fclose来关闭文件。
cpp
//打开文件
FILE* fopen(const char* filename, const char* mode);
//关闭文件
int fclose(FILE* ftream);fopen的函数声明:参数1:filename是所需的文件名,参数2:mode是打开流的形式,是输入还是输出。返回类型:FILE*是一个文件信息区的地址,通过该地址找到文件信息区访问文件。
fclose的函数声明:参数:ftream是我们打开文件时用来接收fopen返回值是创建的变量,将这个变量所存储的地址传参过去就可以回收文件信息区所占用的空间,就是关闭文件
fopen函数的参数2mode的打开形式是什么意思呢?怎么表示打开形式呢?
mode表示文件的打开模式,下面都是文件的打开模式:
|---------------------|----------------------------------------|-------------------|
| 文件使用方式 | 含义 | 如果指定文件不存在 |
| "r"(只读) | 为了输入数据,打开一个已经存在的文本文件 | 出错 |
| "w"(只写) | 为了输出数据,打开一个文本文件 | 建立一个新的文件 |
| "a"(追加) | 向文本文件尾部添加数据 | 建立一个新的文件 |
| "rb"(只读) | 为了输入数据,打开一个二进制文件 | 出错 |
| "wb"(只写) | 为了输入文件,打开一个二进制文件 | 建立一个新文件 |
| "ab"(追加) | 向一个二进制文件尾部添加数据 | 建立一个新的文件 |
| "r+"(读写) | 为了读和写,打开一个文本文件 | 出错 |
| "w+"(读写) | 为了读和写,建立一个新的文本文件 | 建立一个新的文件 |
| "a+"(追加) | 打开一个文本文件,在文件尾部进行读写 | 建立一个新的文件 |
| "rb+"(读写) | 为了读和写,打开一个二进制文件 | 出错 |
| "wb+"(读写) "ab+"(追加) | 为了读和写,建立一个新的二进制文件 打开一个二进制文件,在文件尾部进行读和写 | 建立一个新的文件 建立一个新的文件 |
注:fopen也是会打开失败的,如果打开失败,则返回空指针NULL。打开成功,则返回开辟好后的文件信息区的地址,所以使用前一定要判断一下。
然后就是fclose函数,它是用来关闭文件的,当我们指向文件信息区的FILE*的指针变量pf传进去,关闭好文件后一定要记得将pf置为NULL,因为我们虽然使用fclose函数释放了文件信息区,将文件信息区所占的内存还给操作系统了。但是指针变量pf始终是指向这块内存的,如果解引用访问使用这块内存就是非法访问了,所以当我们关闭文件后就把pf置为NULL。
**注:**如果以只读" w " 或" wb " 的形式打开文件,如果这个文件本身有数据,则会被清空,因为需要从头写入文件,所以要谨慎的使用只读的形式。
文件的打开方式:
文件打开有两种路径,一种是相对路径,一种是绝对路径
相对路径:
' . '表示当前路径,".."表示上一级路径
如果我们要打开的文件和程序所在的文件在一个路径下的话可以直接使用文件名打开,例如:
cpp
FILE* pf = fopen("test.txt","r");因为没有路径表示编译器便会自动在程序文件相同路径的位置找该文件。
如果该程序文件在许多级文件内存储,如果我们要打开的文件也在这个多级文件中,但是在程序文件所在文件的上一级的上一级的位置,我们可以这样访问,例如:
cpp
FILE* pf = fopen(".\\..\\..\\test.txt","r");一个' . '表示当前路径,两个 ".." 表示上一级路径。
还是将test.txt存放在当前数据文件所在的文件的上一级的上一级的位置,只不过我在这个位置又新建了一个文件夹叫hehe,然后我将test.txt放入这个hehe文件夹中,我们有什么方法可以访问呢:
cpp
FILE* pf = fopen(".\\..\\..\\hehe\\test.txt","r");".\\..\\..\\hehe\\test.txt"意思就是在当前路径 ' . ' 的上一级 " .. " 的上一级" .. " 路径下的文件夹"hehe"里的文件"test.txt"。
绝对路径:
必须填写文件对应的路径,通过这个路径来找到对应的文件
但当我们想要打开其他路径的文件比如桌面上的文件时,我们就需要额外的输入路径,让编译器通过该路径找到对应的文件,例如:
cpp
FILE* pf = fopen("C:\\Users\\zpeng\\Desktop\\test.txt","w");
//绝对路径在文件名前面添加一条路径,就可以根据这个路径找到对应文件。
**场景1:**当需要打开的文件和当前程序文件都是一个路径时,比如程序文件的项目是需要创建在一个文件夹中的,如果存在同一个文件夹,则不用填写路径。
**场景2:**当需要打开的文件和程序文件不在同一个文件夹,则需要在文件名前面添加上路径。
总结: 文件路径也分为两个,分别是绝对路径 和相对路径。
**绝对路径:**是在文件和程序文件位置不同时需要填写完整的路径来访问。
**相对路径:**是和程序文件在同一个文件里的,可能不一级文件,但是位置是有关联的,被称为相对路径
4.4 文件指针的概念
这里要说一下文件是有文件指针的,文件指针决定读取或写入的操作时从哪个位置开始的,如果程序开始运行并且使用过一次函数来访问当前文件信息区的文件了,文件指针就会发生改变,因为文件指针需要访问下一个位置的数据。
假设文件信息区的地址由变量pf来接收,那它的文件指针始终都不会重新开始,方便下一次调用文件访问函数可以从当前位置继续向后访问,所以没访问一次,文件指针会自动向后指向。除非是程序结束、使用rewind函数 或者是 又创建了一个文件信息区,否则当前pf关联的文件的文件指针始终都不会重新指向起始位置。
5、文件的顺序读写
5.1 顺序读写函数介绍
|-------------|---------|-------|
| 函数名 | 功能 | 适用于 |
| fgetc | 字符输入函数 | 所有输入流 |
| fputc | 字符输出函数 | 所有输出流 |
| fgets | 文本行输入函数 | 所有输入流 |
| fputs | 文本行输出函数 | 所有输出流 |
| fscanf | 格式化输入函数 | 所有输入流 |
| fprintf | 格式化输出函数 | 所有输出流 |
| fread | 二进制输入 | 文件 |
| fwrite | 二进制输出 | 文件 |
以上第三列表格适用于:所有输入流 、所有输出流 、文件 ,意思是每个对应函数的参数里有一个FILE*类型的指针变量参数,也就是流,所以都要有对应的流。所有输入流包括:标准输入流、文件流,所有输出流包括:标准输出流、文件流,二进制文件读写函数只能传文件流。我们也可以使用以上适用于标准输出流的函数数据通过标准输出流 输出到屏幕上去,也可以使用以上适用于标准输入流的函数将我们从键盘输入的数据通过标准输入流读取出来,所以要记住,这些函数不仅仅是作用于文件的读取和写入。
以上所有函数的声明:
cpp
int fputc(int character, FILE* stream);
int fgetc(FILE* stream);
int fputs(const char* str, FILE* stream);
char* fgets(char* str, int num, FILE* stream);5.1.1 fputc的使用
fputc的声明:
cpp
int fputc(int character, FILE* stream);fputc函数:参数1:character是需要输出的字符。参数2:stream是FILE*类型的指针,可以是标准输出流或者是对应文件的流。
**fputc函数的功能:**通过参数2的指向的文件信息区里的信息访问文件,并将参数1的字符输出到当前文件,一次只能写一个字符。
fputc函数的使用:
cpp
#include <stdio.h>
#include <string.h>
int main()
{
FILE* pf = fopen("test.txt", "w");//打开文件
if (pf == NULL)
{
perror("fopen");
return;
}
char str[] = "hello world";
ine len = strlen(str);
int i = 0;
for(i = 0; i < len; i++)
{
fputc(str[i], pf);//将"hello world"一个一个输出到文件
}
fclose(pf);//关闭文件
pf = NULL;
return 0;
}那我们也可以通过该函数将字符输出到屏幕上,就像printf一样:
cpp
#include <stdio.h>
int main()
{
fputc('a',stdout);经过标准输出流直接将字符'a'输出到屏幕上
return 0;
}所以这里也就证明了FILE*类型的指针变量接收的文件信息区的地址是文件的流,顺序读写函数的参数FILE* stream是流,至于什么的流就看自己想怎么操作。
5.1.2 fgetc的使用
fgetc的声明:
cpp
int fgetc(FILE* stream);fgect函数:**参数:**stream不用说就是流,但仅限于所有输入流,或文件的流,因为fgetc需要从输入流中获取数据。
**fgetc函数的功能:**将对应的输入流传参过去,getc会读取输入流中的字符,标准输入流是需要我们来输入字符,文件流是fgetc自己读取文件中的字符。
fgetc函数的使用:
cpp
#include <stdio.h>
int main()
{
FILE* pf = fopen("test.txt", "r");//打开文件
if (pf == NULL)
{
perror("fopen");
return;
}
char c = 0;
while(c = fgetc(pf) != EOF)//会不断地向文件后读取数据
{
printf("%c",c);
}
fclose(pf);//关闭文件
pf = NULL;
return 0;
}那我们也可以通过该函数读取我们键盘输入的字符,就像scanf一样:
cpp
#include <stdio.h>
int main()
{
char c = fgetc(stdin);
printf("%c\n", c);
return 0;
}
cpp
int c = fgetc(stdin);
等价于
int c = getchar();到这里相信大家也都知道了这些函数可以通过标准输入流来获取我们键盘输入的数据或标准输出流将数据输出到屏幕上,那么下面的函数就不用在举这个例子了。
5.1.3 fputs的使用
fputs的声明:
cpp
int fputs(const char* str, FILE* stream);fputs函数:参数1:str是需要输出的字符串,参数2:stream是FILE*类型的指针,可以是标准输出流或者是对应文件的流。
**fputs函数的功能:**将字符串根据输出流输出到对应的位置
fputs函数的使用:
cpp
#include <stdio.h>
int main()
{
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
perror("fopen");
return;
}
char str[] = "hello world";
fputs(str, pf);
fclose(pf);
pf = NULL;
return 0;
}5.1.4 fgets的使用
fgets的声明:
cpp
char* fgets(char* str, int num, FILE* stream);fgets函数:参数1:str是存储fgets从输入流读取的数据空间的地址,参数2:num是需要拷贝从输入流读取的字符的个数,参数3:stream是FILE*类型的指针,可以是标准输入流或者是对应文件的流。
fgets函数的功能:从参数3的输入流中读取num个字符拷贝到str。
如果fgets读取失败会返回一个空指针NULL,所以我们使用该函数时也可以判断一下有没有读取成功。
fgets的使用:
cpp
#include <stdio.h>
int main()
{
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return;
}
char* str = (char*)malloc(10 * sizeof(char));
fgets(str, 10, pf);
printf("%s\n", str);
fclose(pf);
pf = NULL;
return 0;
}fgets不管读取多少个字符,最后一定会额外拷贝一个结束字符' \0 ' 放入str中。
5.1.5 fprintf的使用
fprintf是格式化函数,printf也是格式化函数
fprintf函数的声明:
cpp
int fprintf(FILE* stream,const char* format,...);fprintf和printf有什么区别,我们再看一下printf函数声明:
cpp
int printf(const char* format,...);我们可以发现printf和fprintf之间就差一个参数stream,stream就是流,我们可以将stream的参数修改为文件流,后面的参数就和printf一样,printf本身的输出流是标准输出流stdout,输出到屏幕上的,所以我们就将文件想象成正常使用printf将数据输出到屏幕,其他参数就和printf一样。
如果这样的话,那fprintf可以做到和printf等价:
cpp
int main()
{
char c = 'a';
int a = 10;
char str[] = "hello world";
printf("%c %d %s",c,a,str);
等价于
fprintf(stdout,"%c %d %s",c,a,str);
return 0;
}fprintf的使用:
cpp
#include <stdio.h>
struct S
{
int n;
float f;
char arr[20];
};
int main()
{
struct S s = { 100, 3.14f, "zhangsan" };
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
perror("fopen");
return;
}
fprintf(pf, "%d %f %s", s.n, s.f, s.arr);
fclose(pf);
pf = NULL;
return 0;
}5.1.6 fscanf的使用
fscanf和scanf的参数也是相似的,就像fprintf和printf一样:
cpp
int fscanf(FILE* stream, const char* format,...);
int scanf(const char* format,...);fscanf的使用:
cpp
#include <stdio.h>
struct S
{
int n;
float f;
char arr[20];
};
int main()
{
struct S c = { 0 };
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return;
}
fscanf(pf, "%d %f %s", &(c.n), &(c.f), c.arr);//输出到变量c中
printf("%d %f %s", c.n, c.f, c.arr);
fclose(pf);
pf = NULL;
return 0;
}5.1.7 fwrite的使用
fwrite函数声明:
cpp
size_t fwrite(const void* ptr, size_t size, size_t count, FILE* stream);**fwrite函数:**参数1:ptr是一个const void* 的指针,是可以处理任意类型的数据的地址,不管是整型、浮点型还是结构体类型的地址都可以接收。参数2:size是类型大小,单位是字节。参数3:count是类型变量的个数。参数4:stream必须是文件的流,不能是其他流。
**fwrite函数功能:**通过参数1的指针将指针指向的count个数量的size类型大小的二进制数据输出到stream流。简单来说就是将数据在内存中的二进制数据传输进流。它的流只能是文件,不能是其他流,例如标准输出流。
cpp
#include <stdio.h>
struct S
{
int n;
float f;
char arr[20];
};
int main()
{
struct S s = { 200, 3.14f, "zhangsan" };
FILE* pf = fopen("C:\\Users\\linlu\\Desktop\\test.txt", "wb");//以二进制写的形式打开文件
if (pf == NULL)
{
perror("fopen");
return;
}
//
//使用
fwrite(&s, sizeof(struct S), 1, pf);//以二进制的形式写入文件
//
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}5.1.8 fread的使用
fread函数声明:
cpp
size_t fread(void* ptr, size_t size, size_t count, FILE* stream);可以看到fread的函数声明和fwrite的函数声明是极其相似的。
**fread函数和fwrite函数的区别:**不同的就是前面那个void*的指针,fwrite是const修饰的,因为只是想读取它指向的空间里的数据并不想更改,所以使用了const。而fread是需要一个指针,通过这个指针指向的空间来接收读取的值,所以不能是const修饰。
**fread函数:**参数1:ptr是一个void* 的指针,是可以处理任意类型的数据的地址,不管是整型、浮点型还是结构体类型的地址都可以接收。参数2:size是类型大小,单位是字节。参数3:count是类型变量的个数。参数4:stream必须是文件的流,不能是其他流。
**fread函数功能:**通过seteam文件流将文件中的count个数量的size类型大小的二进制数据输入到ptr中。简单来说就是将文件中的二进制数据输入到ptr空间。它的流只能是文件,不能是其他流,例如标准输出流。
cpp
#include <stdio.h>
struct S
{
int n;
float f;
char arr[20];
};
int main()
{
struct S s = { 200, 3.14f, "zhangsan" };
FILE* pf = fopen("C:\\Users\\linlu\\Desktop\\test.txt", "rb");//打开文件
if (pf == NULL)
{
perror("fopen");
return;
}
//
//使用
struct S c = { 0 };
fread(&c, sizeof(struct S), 1, pf);//将文件中二进制的数据读取出来
printf("%d %f %s", c.n, c.f, c.arr);
//
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}5.2 对比一组函数:
scanf / fscanf / sscanf
printf / fprintf / sprintf
- scanf - 针对标准输入流(stdin)的格式化输入函数
- printf - 针对标准输出流(stdout)的格式化输出函数
- fscanf - 针对所有输入流的格式化输入函数
- fprintf - 针对所有输出流的格式化输出函数
那sscanf和sprintf两个函数是干什么的呢?
sprintf的函数声明:
cpp
int sprintf(char* str, const char* format,...)可以从参数上发现sprintf就比printf多了一个char*类型的参数,那具体功能是什么?
**sprintf函数功能:**将格式化数据输出到字符串中
sprintf和printf的区别: printf是将格式化数据输出到标准输出流也就是屏幕上,sprintf则是将格式化数据输出到一个字符串里
cpp
#include <stdio.h>
struct S
{
int n;
float f;
char arr[20];
};
int main()
{
struct S s = { 200, 3.14f, "zhangsan" };
char arr[30] = { 0 };
sprintf(arr, "%d %f %s", s.n, s.f, s.arr);//将格式化数据输出到字符串arr
printf("%s\n", arr);//打印arr接收到的格式化数据
return 0;
}既然可以使用sprintf函数将格式化数据输出到字符串中,那我们是否可以使用sscanf函数将字符串中的格式化数据提取出来呢?答案是可以的。
sscanf函数声明:
cpp
int sscanf(char* str, const char* format,...);**sscanf函数功能:**将字符串中的格式化数据读取出来
sscanf和scanf的区别:scanf 是将格式化数据输入到标准输入流也就是屏幕上,sscanf则是将格式化数据从字符串里读取出来。
cpp
#inlcude <stdio.h>
struct S
{
int n;
float f;
char arr[20];
};
int main()
{
//将格式化的数据输出到字符串数组arr中
struct S s = { 200, 3.14f, "zhangsan" };
char arr[30] = { 0 };
sprintf(arr, "%d %.2f %s", s.n, s.f, s.arr);//将格式化数据输出到字符串arr
printf("%s\n", arr);
//从arr这个字符串中读取出格式化的数据
struct S c = { 0 };
sscanf(arr, "%d %f %s", &c.n, &c.f, c.arr);
printf("%d %f %s", c.n, c.f, c.arr);
return 0;
}6、文件的随机读写
什么是文件的随机读写?文件的随机读写就是定位到我们想要的位置开始向后读写,从开头向后读写就是顺序读写。定位位置向后读写就是随机读写。
6.1 fseek
cpp
int fseek(FILE* stream, long int offset, int origin);fseek函数:参数1就是stream文件的流。参数2offset就是偏移量,是某个位置开始的向后的偏移量处的位置开始向后读写。而参数三origin就是决定这某个位置。
参数3:origin有三种位置:
|---------------|-------------------------------------------------|
| Contstant | Reference position |
| SEEK_SET | Beginning of file (文件的起始位置) |
| SEEK_CUR | Current position of the file pointer(文件指针的当前位置) |
| SEEK_END | End of file(从文件的末尾位置向前偏移) |
是从这些位置开始向后计算偏移量的位置,从计算好偏移量的位置开始向后读取。
例子:
cpp
#include <stdio.h>
int main()
{
FILE* pf = fopen("C:\\Users\\linlu\\Desktop\\test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return;
}
//
//使用
fseek(pf, 6, SEEK_SET);//文件指针位置:起始位置向后偏移6个偏移量位置
int ch = fgetc(pf);//读取当前文件指针位置的字符
printf("%c", ch);
fseek(pf, -3, SEEK_END);//文件指针位置:文件末尾向前偏移3个偏移量位置
int ch = fgetc(pf);//读取当前文件指针位置的字符
printf("%c", ch);
fseek(pf, 5, SEEK_CUR);//文件指针位置:当前文件指针位置向后偏移5个偏移量位置
int ch = fgetc(pf);//读取当前文件指针位置的字符
printf("%c", ch);
//
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}文件里是存在文件指针的,正常情况下调用一次后该文件指针会向后指向,下一次调用是从后面继续向后访问。顺序读写函数是这样的。而随机读写函数是可以随机改变文件指针的指向,让文件指针改变位置从而进行读取或写入。
注:
1. 文件指针并不是我们熟知的C语言指针,而是一个表示文件位置的指针。
2. 偏移量为负数是向前偏移,偏移量为整数是向后偏移。
3. 不管文件指针的位置如何改变,文件都是自动的从前向后访问
6.2 ftell
ftell的函数声明:
cpp
long int ftell(FILE* stream);如果我们不知道当前的文件初始位置与文件指针之间的偏移量是多少时我们就可以使用ftell库函数,这个函数会计算好文件指针的偏移量并返回。
例子:
cpp
#include <stdio.h>
int main()
{
FILE* pf = fopen("C:\\Users\\linlu\\Desktop\\test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return;
}
//
fseek(pf, -3, SEEK_END);//文件指针位置:文件末尾向前偏移3个偏移量位置
int ch = fgetc(pf);//读取当前文件指针位置的字符
printf("%c\n", ch);
int ret = stell(pf);//计算当前偏移量
printf("%d\n",ret);
//
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}6.3 rewind
让文件指针的位置回到文件的起始位置
比如我随意用fseek来设置文件指针的位置导致乱了套,这时我们就可以使用rewind来让文件指针回到起始位置,功能比较简单,容易理解。
cpp
void rewind(FILE* stream);例子:
cpp
#include <stdio.h>
int main()
{
FILE* pf = fopen("C:\\Users\\linlu\\Desktop\\test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return;
}
//
fseek(pf, -3, SEEK_END);//文件指针位置:文件末尾向前偏移3个偏移量位置
int ch = fgetc(pf);//读取当前文件指针位置的字符
printf("%c\n", ch);
//不知道当前文件指针的位置就重置
rewind(pf);//重置文件指针位置
int ch = fgetc(pf);//读取起始位置字符
printf("%c\n",ch);
//
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}7、文件读取结束的判定
7.1 被错误使用的feof
牢记:在文件读取过程中,不能用 feof函数的返回值直接来判断文件是否结束。
feof的作用是:当文件读取结束的时候,判断是读取结束的原因是否是:遇到文件尾结束。
文件读取结束有两种原因:
1. 文件遇到末尾了
2. 文件读取错误了
**1.**文本文件读取是否结束,判断返回值是否为EOF(fgetc的错误),或者是NULL(gets的错误)
例如:
- fgetc判断是否为EOF
- fgets判断是否问NULL
**2.**二进制文件的读取结束判断,判断返回值是否小于实际要读的个数。
例如:
- fread判断返回值是否小于实际要读的个数
注:fread的返回值是读取到的元素的个数。
7.2 ferror
feof是判断文件是否是因为读取到文件末尾而结束的,而ferror则是判断是否是因为读取失败而结束的,如果读取失败结束就返回1.
cpp
int ferror(FILE* stream);文本文件读取结束判断:
cpp
#include <stdio.h>
#include <stdlib.h>
int main()
{
int ch = 0;
FILE* pf = fopen("C:\\Users\\linlu\\Desktop\\test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return;
}
//
while (ch = fgetc(pf) != EOF)
{
printf("%c ", ch);
}
printf("\n");
//判断是什么原因结束的
if (ferror(pf))//判断是否是读取失败导致结束的
{
puts("1/0 error when reading");
}
else if (feof(pf))//判断是否是读取到文件末尾结束的
{
printf("End of file reached successfully");
}
//
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}二进制文件的例子:
cpp
#include <stdio.h>
int main()
{
double a[5] = { 1.0, 2.0, 3.0, 4.0, 5.0 };
FILE* pf = fopen("test.bin", "wb");//以输出二进制的形式打开
fwrite(a, sizeof *a, 5, pf);
fclose(pf);
//
double b[5];
pf = fopen("test.bin", "rb");//以读取二进制的形式打开
size_t ret_code = fread(b, sizeof *b, 5, pf);
if (ret_code == 5){
puts("Array read successfully,contents: ");
for (int n = 0; n < 5; n++)
{
printf("%f ", b[n]);
}
putchar('\n');
}
else
{
//判断是什么原因结束的
if (ferror(pf))//判断是否是读取失败导致结束的
{
puts("1/0 error when reading");
}
else if (feof(pf))//判断是否是读取到文件末尾结束的
{
printf("End of file reached successfully");
}
}
//
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}8、文件缓冲区
ANSIC 标准规定采用 "缓冲文件系统" 处理数据文件的,所谓缓冲文件系统是指系统自动地在内存中为程序中每一个正在使用的文件开辟一块 "文件缓冲区" ,从内存中向磁盘输出数据会先送到内存中的缓冲区,装满缓冲区后才一起送到磁盘上,如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的大小根据C编译器系统决定的。

cpp
#include <stdio.h>
#include <windows.h>
int main()
{
FILE* pf = fopen("test.txt", "w");
fputs("abcdef", pf);
printf("睡眠10秒-已经写数据了,打开test.txt文件,发现文件没有内容\n");
Sleep(10000);
printf("刷新缓冲区\n");
fflush(pf);//刷新缓冲区的函数,才将输出缓冲区的数据写到文件(磁盘)
//注: fflush 函数在高版本的VS不能使用了
printf("再睡眠10秒-此时再打开test.txt文件,发现文件有内容了\n");
Sleep(10000);
fclose(pf);
//注:fclose关闭文件时,也会刷新缓冲区
pf = NULL;
return 0;
}这里可以得出一个结论:
因为有缓冲区的存在,C语言在操作文件的时候,需要做刷新缓冲区或者在文件操作结束时关闭文件,如果不做,可能导致读写文件问题。
第十六章:编译和链接
1、翻译环境和运行环境
在ANSI C的任何一种实现中,存在两个不同的环境。
第1种是翻译环境,在这个环境中源代码被转换为可执行机器指令(二进制指令)
第2种是执行环境,它用于实际执行代码
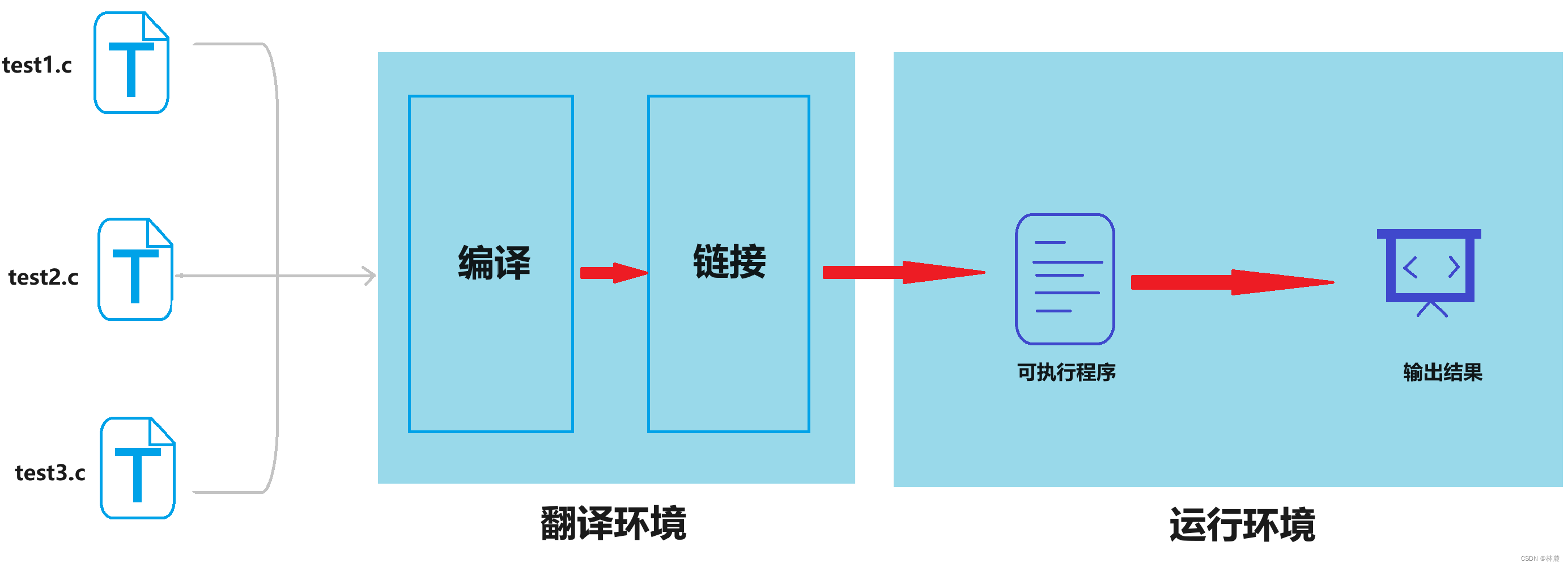
2、翻译环境
那翻译环境是怎么将源代码转换为可执行的机器指令的呢?这里我们就得展开讲解一下翻译环境所做的事情。
其实翻译环境是由编译 和链接 两个大的过程组成的,而编译又可以分解成:预处理(预编译)、编译、汇编三个过程。
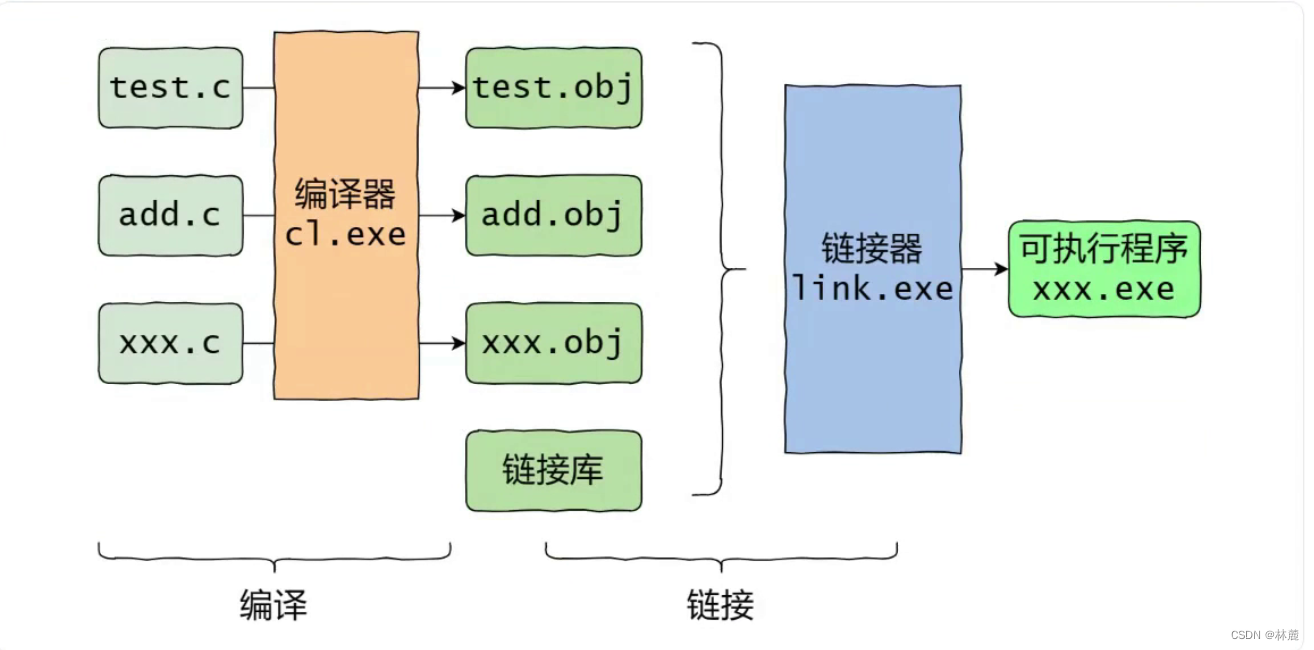
一个C语言的项目中可能有多个.c文件一起构建,那么多个.c文件如何生成可执行程序呢?
- 多个.c文件单独经过编译处理生产对应的目标文件(.obj)
- 注:在Windows环境下的目标文件的后缀是.obj,Linux环境下目标文件的后缀是.o
- 多个目标文件(.obj)和链接库一起经过链接器的处理生成最终的可执行程序
- 链接库是指运行时库(它是支持程序运行的基本函数集合)或者第三方库
什么是链接库?
在学习C语言时我们经常会用到库函数,比如printf、scanf,这些函数肯定不是凭空出现的,像这样的库函数是被编译成一个一个的链接库,这些函数都包含在这个链接库中也就是第三方库,是C编译器厂商自己提供的库来供我们使用。在我们的C程序中会用到库函数,但是必须经过链接器目标文件和链接库一起链接才能调用该库函数。
举个例子:比如有一条河,两个人想见面,一个人(程序)在河的这边,而另一个人(库函数实现)在河的那边,那两人想见面(调用)是不是必须搭一座桥,而这座桥就是链接器。
其实还可以把编译器的编译展开成3个过程,那就变成了下面的过程:
Linux环境下:
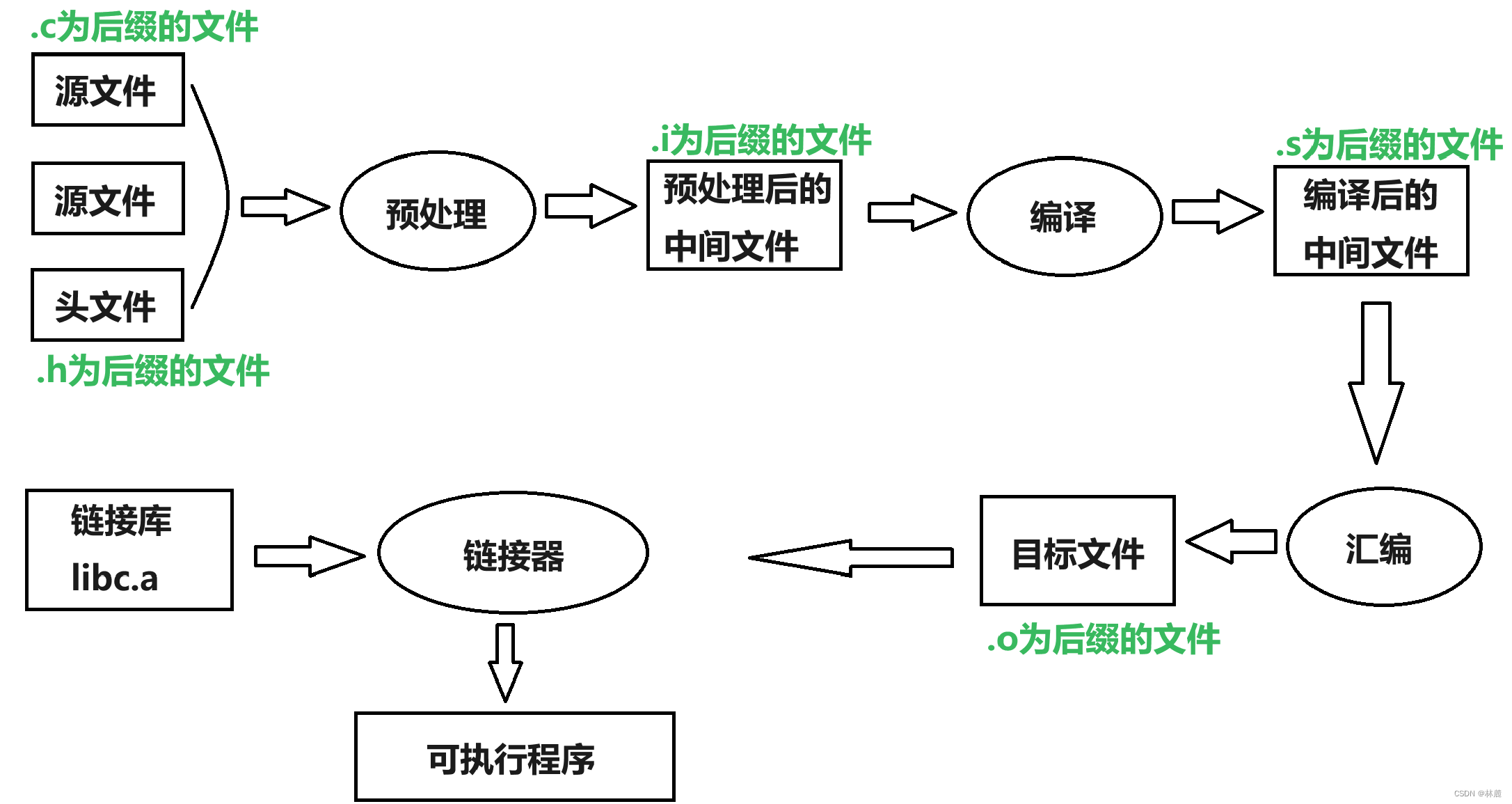
2.1 预处理(预编译)
在预处理阶段,源文件和头文件会被处理成为.i位后缀的文件。
在gcc环境下想观察一下,对test.c文件预处理后的.i文件,命令如下:
cpp
gcc -E test.c -o test.i预处理阶段主要处理那些源文件中#开始的预处理指令,比如:#include,#define 处理规则如下:
- 将所有的#define删除,并展开所有宏定义。
- 处理所有的条件编译指令,如:#if、#ifdef、#elif、#else、#endif。
- 处理#include预处理指令,将包含的头文件的内容插入到该预编译指令的位置。这个过程是递归进行的,也就是说被包含的头文件也可能包含其他文件
- 删除所有注释
- 添加行号和文件名标识,方便后续编译器生成调试信息等。
- 或保留所有的#pragma的编译器指令,编译器后续会使用
经过预处理后的.i文件中不再包含宏定义,因为宏已经被展开。并且包含的头文件都被插入到.i文件中,所以当我们无法知道宏定义或者头文件是否包含正确的时候,可以查看预处理后的.i文件来确认。
2.2 编译
编译过程就是将预处理后的文件进行一系列:词法分析 、语法分析 、**语义分析、符号汇总(链接阶段会讲一下符号汇总有什么用)**及优化,生成相应的汇编指令。简单来说编译过程就是将C语言代码转换成汇编代码。
编译过程的命令如下:
cpp
gcc -S test.i -o test.s对下面代码进行编译的时候,会怎么做呢?假设有下面的代码:
cpp
array[index] = (index + 4) * (2 + 6);2.2.1 词法分析
将源代码程序输入扫描器,扫描器的任务就是简单的进行词法分析,把代码中的字符分割成一系列的记号(关键字、标识符、字面量、特殊字符等)。
上面代码进行词法分析后得到了16个记号:
|--------|--------|
| 记号 | 类型 |
| array | 标识符 |
| | 左方括号 |
| index | 标识符 |
| | 右方括号 |
| = | 赋值 |
| ( | 左圆括号 |
| index | 标识符 |
| + | 加号 |
| 4 | 数字 |
| ) | 右圆括号 |
| * | 乘号 |
| ( | 左圆括号 |
| 2 | 数字 |
| + | 加号 |
| 6 | 数字 |
| ) | 右圆括号 |
2.2.2 语法分析
接下来语法分析器,将对扫描产生的记号进行语法分析,从而产生语法树。这些语法树是以表达式为节点的树

2.2.3 语义分析
由语义分析器来完成语义分析,即对表达是的语法层面分析,编译器所能做的分析是语义的静态分析,静态语义分析通常包括声明和类型匹配,类型的转换等。这个阶段会报告错误的语法信息。
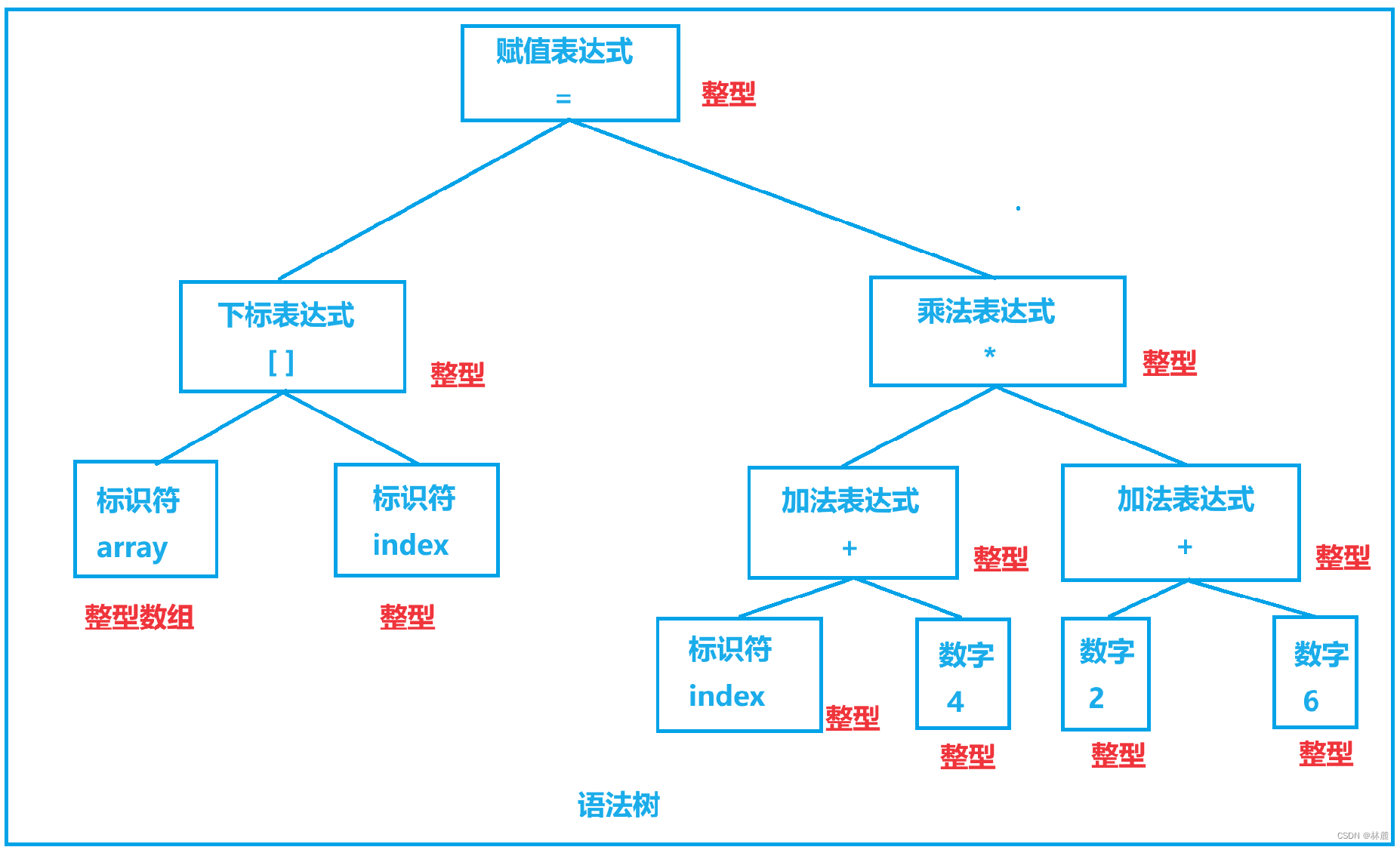
以上步骤完成后,最后就是将代码生成汇编指令,然后编译阶段就完成了。
2.3 汇编
汇编器是将汇编代码转变(翻译)为可执行的二进制指令,每一个汇编语言几乎都对应一条机器指令。就是根据汇编指令和机器指令的对照表一一的进行翻译,也不做指令优化。
注:这个过程还会形成符号表,是根据编译过程的符号汇总生成符号表的。
汇编的命令如下:
cpp
gcc -c test.s -o test.o2.4 链接
链接是一个复杂的过程,链接的时候需要把一堆文件链接在一起才生成可执行程序。
链接过程主要包括:地址和空间分配,符号决议和重定位等这些步骤。
链接解决的是一个项目中多文件、多模块之间互相调用的问题。
链接主要就是处理不同文件之间的相互调用,比如:
add.c
cpp
int g_val = 2023;
int Add(int x, int y)
{
return x + y;
}test.c
cpp
extern int Add(int x,int y);
extern int g_val;
int main()
{
printf("%d\n",g_val);
printf("%d\n",Add(2, 3));
return 0;
}这两个文件直接是如何链接的才可以相互调用的呢?
注意:这两个文件会生产目标文件:add.obj、test.obj,在生产目标文件之前的编译过程中会对两个文件进行符号汇总 ,然后在汇编过程中又会形成符号表。比如add.c文件在编译过程中会进行符号汇总:g_val、Add,test.c在编译过程中进行符号汇总:g_val、Add、main,下一步在汇编过程中每个文件汇总出的符号是会形成符号表的,符号表中每个符号都有对应的地址。
例如:add.obj符号表
|--------|--------|
| 符号 | 地址 |
| g_val | 0x100 |
| Add | 0x200 |
test.obj符号表
|--------|--------------|
| 符号 | 地址 |
| Add | 0x000(无效的地址) |
| g_val | 0x000(无效的地址) |
| main | 0x300 |
注:以上地址是自己填上去的,真正的地址不是这样,只是举个例子使用
test.c里的符号Add和g_val由于是外部声明符号,并不知道符号真实地址,所以形成符号表时就给个无效地址。
链接过程中这些符号表是要进行合并的,多个目标文件都是一个项目的,没必要那么多符号表,所以只需将多个文件的符号表合成一个就够了。
add.obj和test.obj经过链接合并成的符号表:
|--------|--------|
| 符号 | 地址 |
| Add | 0x200 |
| g_val | 0x100 |
| main | 0x300 |
因为合并时找到了符号本身的有效地址,多以合并时将无效地址替换掉了,最终两个文件的符号表合并在了一起,运行时便可以通过该符号表的地址找到对应符号并调用。
而合并符号表过程中将test.obj符号表中Add符号的无效地址或g_val符号的无效地址替换掉就叫做符号的决议和重定位。
总结:
多个文件之间相互调用首先需要在编译阶段进行符号汇总 ,然后汇编阶段将汇总出的符号形成符号表 ,符号表中的每个符号都分配有对应地址。最后在链接阶段将多个目标文件的符号表进行符号表合并,至此多个文件的符号都有了联系,一个文件如果想调用另一个文件的函数就可以通过符号表的地址找到该函数并调用。
3、运行环境
1. 程序必须载入内存中,在有操作系统的环境中,一般这个由操作系统完成,程序的载入必须要手工安排,也可能是通过可执行代码置入只读内存完成。
**2.**程序的指向便开始,接着便调用main函数。
**3.**开始执行程序代码,这个时候程序将使用一个运行时堆栈(stack(函数栈帧)),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留它们的值。
4. 终止程序,正常终止main函数;也有可能是意外终止。
第十七章:预处理
1、预定义符号
C语言设置了一些预定义符号,可以直接使用。预定义符号也是在预处理期间处理的。
cpp
__FILE__ //进行编译的源文件
__LINE__ //文件当前的行号
__DATE__ //文件被编译的日期
__TIME__ //文件被编译的时间
__STDC__ //如果编译器遵循ANSI C,其值为1, 否则未定义举个例子:
cpp
#include <stdio.h>
int main()
{
printf("进行编译的源文件:%s\n", __FILE__);
printf("当前文件的行号:%d\n", __LINE__);
printf("当前文件编译日期:%s\n", __DATE__);
printf("当前文件编译时间:%s\n", __TIME__);
return 0;
}运行:

**STDE**只有在编译器遵循ANSI C时才为1,但是VS使用该标识符是未定义的,说明VS并不支持ANSI C

2、#define 定义常量
基本语法:
cpp
#define name stuff举个例子:
cpp
#define MAX 1000
#define reg register //为register这个关键字,创建一个简短的名字
#define do_forerer for(;;) //定义一个死循环的for,使用这个标识符时会一直死循环
#define CASE break;case //在写case语句的时候启动把break写上
//如果定义的stuff过长,可以分成几行写,除了最后一行外,每行的后面都加一个反斜杠(续航符)
#define DEBUG_PRINT printf("file:%s\tline:%d\t \
date:%s\ttime:%s\n", \
__FILE__, __LINE__, \
__DATE__, __TIME__)思考:在define定义标识符的时候,要不要在最后加上**;**?
比如:
cpp
#define MAX 1000;
#define MAX 1000建议不要加上**;**,这样容易导致问题
比如下面场景:
cpp
if(condition)
max = MAX;
else
max = 0;如果是加上了分号的情况,等替换后,if和else之间就是2条语句,而没有大括号的时候,if后边只能有一条语句。这里会出现语法错误。
cpp
替换后
if(condition)
max = 1000;;
else
max = 0;因为1000后面多出了一个**;** ,而多出的这个**;**会被当做一条空语句,看似一条语句,实则两条语句,所以使用时一定要注意#define定义的标识符后面尽量不加分号。
总结:#define定义标识符的后面的可以是常量、字符、浮点数、字符串、关键字或一段代码等...
3、#define定义宏
define不止可以定义常量,还可以定义宏。
#define机制包括了一个规定,允许把参数替换到文本中,这种实现通常称为宏(macro)或定义宏(define macro)。
下面是宏的申明方式:
cpp
#define name(parament-list) stuff其中的parament-list是一个由逗号隔开的符号表,它们可能出现在stuff中。
注意:
参数列表的左括号必须与name紧邻,如果两者之间有任何空白存在,参数列表就会被解释为stuff的一部分。
那宏怎么使用呢?举个例子:
cpp
#include <stdio.h>
#define SQAURE(X) X*X//假设我要计算一个数的平方而使用define定义一个宏
int main()
{
int a = 5;
printf("%d\n", SQAURE(a));//传一个参数过去当经过预处理阶段时会替换成我们定义的表达式
return 0;
}这样来看是不是感觉宏和函数的使用方式有一些相似。
其实宏的计算和函数有点不一样的是将参数传给宏,并不是在宏里完成表达式计算返回值,而是在预处理阶段将调用宏的地方替换成宏定义的表达式。
例如:
cpp
#include <stdio.h>
int main()
{
int a = 5;
printf("%d\n", a*a);//预处理阶段,展开#define定义并替换
return 0;
}警告:
这个宏存在一个问题:
观察下面的代码段:
cpp
#include <stdio.h>
#define SQAURE(X) X*X//假设我要计算一个数的平方而使用define定义一个宏
int main()
{
int a = 5;
printf("%d\n", SQAURE(a+2));//传一个参数过去当经过预处理阶段时会替换成我们定义的表达式
return 0;
}我们想象的结果是a+2也就是7的开平方49,实际上结果是17,为什么?
因为我们给宏传参传表达式并不是计算完成后在计算宏,而是在预处理阶段直接将我们传参的表达式替换到宏定义的表达式。
例如:
cpp
#include <stdio.h>
int main()
{
int a = 5;
printf("%d\n", 7*7);//我们想象的
printf("%d\n",a+2*a+2);//预处理阶段实际做的
return 0;
}**解决方法:**所以我们使用宏时一定要注意,当定义宏的表达式时一定要用括号将表达式中的参数单个括起来,说不定这个参数本身也是一个表达式。
比如:
cpp
#include <stdio.h>
#define SQAURE(X) ((X)+(X))//宏的整体也括一下
//因为调用宏的位置说不定是在某表达式中调用,因为操作符优先级导致计算顺序并不能达到我们的预期
int main()
{
int a = 5;
printf("%d\n", 2*SQAURE(a+2));
printf("%d\n",2*((a+2)+(a+2)));//预处理阶段替换
return 0;
}记得把宏定义表达式整体也括一下,这样才能保证先运算宏定义的表达式。
4、带有副作用的宏参数
当宏参数在宏的定义中出现超过一次的时候,如果参数带有副作用,那么你在使用这个宏的时候就可能出现危险,导致不可预测的后果。副作用表达式求值的时候出现的永久性效果。
例如:
cpp
x+1; //不带副作用
x++; //带副作用什么是带有副作用的表达式呢?就是我想解决一件问题,但却因此留下了另一个问题。就比如我感冒了,我开了点感冒药。吃完感冒药后感冒是好了但是胃又因此不舒服了,这就是副作用。
例如:
cpp
#include <stdio.h>
int main()
{
int a = 10;
int b = ++a;//我想得到a+1的值11,使用++a是得到了11但是因此a也发生了改变
printf("a=%d b=%d\n", a, b);//结果:11,11
return 0;
}这就是带有副作用的表达式。
那如果宏参数是带有副作用的表达式会发生什么呢?
举个例子:
cpp
#include <stdio.h>
#define MAX(a, b) ((a)>(b)?(a):(b));
int main()
{
int a = 15;
int b = 9;
int m = MAX(a++,b++);
printf("m=%d\n", m);
printf("a=%d b=%d\n", a, b);//再猜一下a和b的值是多少
return 0;
}最后的结果是什么呢?
运行结果:m=16, a=17, b = 10
为什么?看下面解析:
cpp
#include <stdio.h>
int main()
{
int a = 15;
int b = 9;
int m = ((a++)>(b++)?(a++):(b++));//预处理替换后
printf("m=%d\n", m);
printf("a=%d b=%d\n", a, b);
return 0;
}代码解析:首先判断(a++)>(b++),此时是转换成15>9来进行判断的,因为先使用后++,当15>9成立,该表达式就返回a++,此时a是16,因为先使用后++就先返回16,m就拿到了16,所以m=16,然后a++就是17,前后a++了两次,b++了一次,所以a=17, b=10
总结:
1、宏的参数是如果是表达式,不会计算的。和函数相反,函数是先将表达式参数进行运算,将运算结果作为参数传参。
2、宏是直接将参数原封不动的替换到宏定义的表达式中的。
宏的参数是不参与计算的,当我们给宏的参数传递一个表达式时,并不是将表达式计算结果进行计算,而是在预处理阶段直接将表达式参数替换到宏定义的表达式,然后再替换到调用宏的位置。
5、宏的替换规则
在程序中扩展#define定义符号和宏是,需要涉及几个步骤。
-
在调用宏时,首先对参数进行检查,看看是否包含任何由#define定义的符号,如果是,它们首先被替换。
-
替换文本后被插入到程序中原来文本的位置,对于宏,参数名被他们的值所替换。
-
最后,再次对结果文件进行扫描,看看它是否包含任何由#define的符号。如果是,就重复上述处理过程。
注意:
-
宏参数和#define定义中出现其他#define定义的符号。但是对于宏,不能出现递归。
-
当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索。
6、宏和函数的对比
宏通常被应用于执行简单的运算。
比如在两个数中找出较大的一个时,写成下面的宏,更有优势一些。
cpp
#define MAX(a, b) ((a)>(b)?(a):(b))那为什么不用函数来完成这个任务呢?
原因有二:
-
用于调用函数和从函数返回的代码可能比实际指向这个小型计算工作所需要的时间更多。所以宏比函数在程序的规模和所读方面更胜一筹。
-
更为重要的是函数的参数必须声明为特定的类型。所以函数只能在类型合适的表达式上使用。反之这个宏可以适用于整型、长整型、浮点型等可以用于>来比较的类型。宏是类型无关的。
和函数相比宏的劣势:
每次使用宏的时候,一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度。
宏是没法调试的
宏由于类型无关,也就不够严谨。
宏可能会带来运算符优先级的问题,导致容易出现错误。
看到这里感觉函数和宏之间各有千秋,函数有函数的好处,宏有宏的好处,那宏有没有什么事函数做不到的呢?当然有。
宏有时候可以做到函数做不到的事情。比如:宏的参数可以出现类型,但是函数做不到。
cpp
#define MALLOC(num, type) \
(type*)malloc(num * sizeof(type))
...
//使用
int* a = MALLOC(10,int);//类型作为参数
//预处理器替换之后
int* a = (int*)malloc(10 * sizeof(int));宏和函数的一个对比:
|--------------|--------------------------------------------------------------------------|--------------------------------------------------|
| 属性 | #define定义宏 | 函数 |
| 代码长度 | 每次使用时,宏代码都会被插入到程序中。 除非非常小的宏之外,程序的长度会大幅度 增长 | 函数代码只出现于一个地方;每次使用函 数时,都调用那个地方的同一份代码 |
| 执行速度 | 更快 | 存在函数的调用和返回的额外开销,所以 相对慢一些 |
| 操作符优先级 | 宏参数的求值是在所有周围表达式的上下文 环境里,除非加上括号,否则邻近操作符的 优先级可能会产生不可预料的后果,所以建 议宏在书写的时候多写括号 | 函数参数只在函数调用的时候求值一次, 它的结果值传递给函数。表达式的求值 结果更容易预测 |
| 带有副作用的参数 | 参数可能被替换到宏体中的多个为止,如 果宏的参数被多次计算,带有副作用的参数 可能会产生不可预料的结果 | 函数参数只在传参的时候求值一次,结果 更容易控制 |
| 参数类型 | 宏的参数与类型无关,只要对参数的操作是 合法的,他就可以使用任何参数类型 | 函数的参数是与类型有关的,如果参数的 类型不同,就需要不同的函数,即使他们 执行的任务是不同的。 |
| 调试 | 宏是不方便调试的 | 函数是可以逐语句调试的 |
| 递归 | 宏是不可以递归的 | 函数是可以递归的 |
那什么时候该有宏,什么时候该有函数呢?
- 如果计算逻辑比较简单就可以使用宏。
- 如果计算逻辑比较复杂就可以使用函数。
7、#和##
7.1 #运算符
#既不是#include或#define中的#,又不是+、-、*、/中的运算符。#是预处理中的一种运算符。
#运算符将宏的一个参数转换为字符串字面量,它仅允许出现在带参数的宏的替换列表中,#运算符所执行的操作可以理解为**"字符串化"**。
printf的特性:
这里首先要了解一下printf函数还有一个特性,就是当我们给printf传两个或多个字符串时,printf会自动将它们参数合并成一个字符串并输出,举个例子:
可以看到第二次调用printf将"hello" "world\n",分成两个字符串,可是printf自动将这两个字符串合并成一个。

知道了printf的这个特性我们就可以继续向下学习。
知道了#运算符可以在宏体中将宏的参数转换成字符串,我们就可以写下面这样代码:
cpp
#include <stdio.h>
#define Print(n, format)\
printf("the value of " #n " is " format "\n", n)
int main()
{
char c = 'a';
Print(c, "%c");
printf("the value of" "c" "is" "%c" "\n", c);//预处理阶段替换后
int n = 10;
Print(n, "%d");
printf("the value of" "n" "is" "%d" "\n", n);//预处理阶段替换后
float f = 3.14f;
Print(f, "%f");
printf("the value of" "f" "is" "%f" "\n", f);//预处理阶段替换后
return 0;
}运行结果:

因为#运算符修饰的参数本来就是"字符串化",如果n是变量c那#n就"c",如果n是变量a,那#n就是"a",如果n是变量f,那#n就是"f",所以"#n"经过预处理阶段就会替换为" "a" ",所以不需要再"#n"的套一层字符串。
7.2 ## 运算符
可以把位于它两边的符号合成一个符号,它允许宏定义从分离的文本片段创建标识符,## 被称为记号粘合这样的连接必须产生一个合法的标识符,否则器结果就是未定义的。
这里我们想想,写一个函数求2个数的较大值的时候,不同的数据类型就得写不同的函数。
比如:
cpp
int int_max(int x, int y)
{
return x>y?x:y;
}
float float_max(int x, int y)
{
return x>y?x:y;
}但是这样写起来太繁琐了,现在我们这样写代码试试:
cpp
//宏定义
#define GENERIC_MAX(type) \
type type##_max(type x, type y)\
{ \
return (x>y?x:y); \
} \使用宏,定义不同类型
cpp
//预处理前的程序格式
#define GENERIC_MAX(type)\
type type##_max(type x, type y)\
{\
return (x>y?x:y);\
}
//下面两行代码是使用宏定义两个自定义函数
GENERIC_MAX(int)
GENERIC_MAX(float)
int main()
{
int a = 10;
int b = 20;
int ret = int_max(a, b);
printf("%d\n", ret);
float c = 11.1f;
float d = 22.2f;
float fret = float_max(c, d);
printf("%.2f\n", fret);
return 0;
}
//预处理后的程序格式
int int_max(int x, int y)
{
return (x>y?x:y);
}
float float_max(float x, float y)
{
return (x>y?x:y);
}
int main()
{
int a = 10;
int b = 20;
int ret = int_max(a, b);
printf("%d\n", ret);
float c = 11.1f;
float d = 22.2f;
float fret = float_max(c, d);
printf("%.2f\n", fret);
return 0;
}8、命名约定
一般来讲函数和宏的使用语法很相似。所以语言本身没法帮我们区分二者
那我们平时的一个习惯是:
把宏名全部大写
函数名不用全部大写
9、#undef
这条指令又能与移除一个#define的标识符定义或宏定义
cpp
#undef NAME
//如果现存的一个名字需要被重新定义,那么它的就名字首先要被移除#undef的使用:
cpp
#define M 100
int main()
{
int a = M;//a = 100
//当想使用M这个标识符名字重新定义
#undef M
//移除标识符M的定义
#define M 200
int b = M;//b = 200
printf("a=%d b=%d\n", a, b);
return 0;
}10、命令行定义
许多C 的编译器提供了一种能力,允许在命令行中定义符号。用于启动编译过程。
例如:当我们根据同一个源文件要编译出一个程序的不同版本的时候,这个特性有点用处(假设某个程序中声明了一个某个长度的数组,如果机器内存有限,我们需要一个很小的数组,但是另一个机器内存大些,我们需要一个数组能够大些)
注:VS是不支持命令行定义的,只能在gcc下观察。
cpp
#include <stdio.h>
int main()
{
int array[ARRAY_SIZE];//ARRAY_SIZE可以在源文件中定义,也可以在命令行中输入命令来定义
int i = 0;
for (i = 0; i < ARRAY_SIZE; i++)
{
array[i] = i;
}
for (i = 0; i < ARRAY_SIZE; i++)
{
printf("%d ", array[i]);
}
return 0;
}编译指令:
cpp
//Linux 环境演示
gcc -D ARRAY_SIZE 10 programe.c
//-D是定义命令,后面定义一个标识符,再在标识符后面输入一个值
//ARRAY_SIZE是标识符 100是标识符的常量
//programe.c是当前源文件的文件名11、条件编译
在编译一个程序的时候我们如果要将一条语句(一组语句)编译或者放弃是很方便的。因为我们有条件编译指令。
注:条件编译后的只能是常量或常量表达式来进行判断,不能使用变量来进行判断。
比如说:
调试性的代码,删除可惜,保留又碍事,所以我们可以选择性的编译。
满足条件,就编译
不满足条件,就放弃编译
常见的条件编译指令:
cpp
1.条件编译
#if 常量表达式
//...
#endif
//常量表达式由预处理器求值
如:
#define __DEBUG__ 1
#if __DEBUG__
//...
#endif
2.多个分支的条件编译
#if 常量表达式
//...
#elif 常量表达式
//...
#else
//...
#endif
3.判断是否被定义
#if defined(symbol)
#ifdef symbol
#if !defined(symbol)
#ifndef symbol
4.嵌套指令
#if defined(OS_UNIX)
#ifdef OPTION1
unix_version_option1();
#endif
#ifdef OPTION2
unix_version_option2();
#endif
#elif defined(OS_MSDOS)
#ifdef OPTION2
msdos_version_option2();
#endif
#endif11.1 条件编译
那我们是怎么使用的呢?看下面代码:
cpp
#include <stdio.h>
#define flag 1
int main()
{
//flag = 1
#if flag
printf("hello world---1\n");
#endif
//!flag = 0
#if !flag
printf("hello world---2\n");
#endif
return 0;
}运行结果:
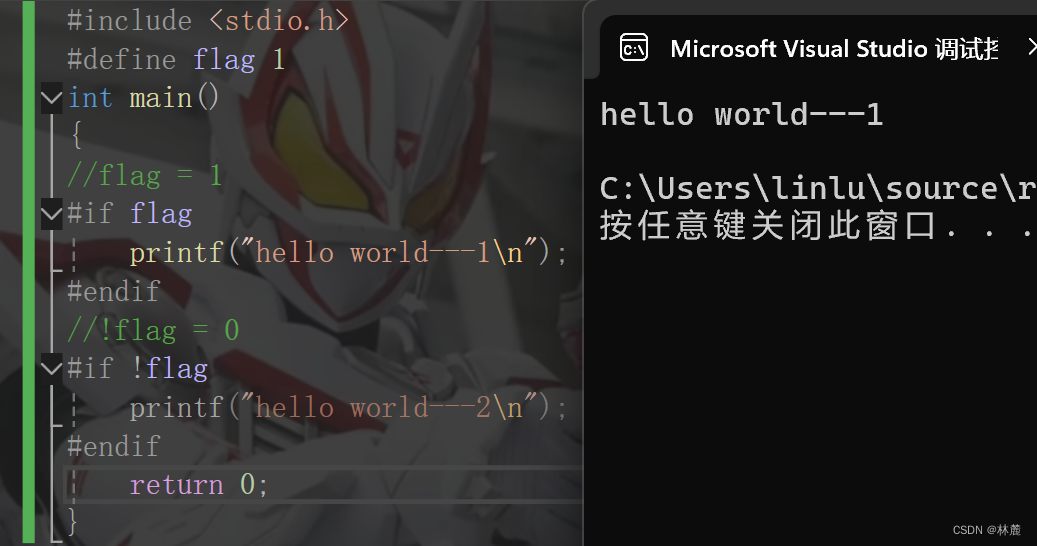
if 和 #if 的区别:
如果if判断为真则执行if中的语句,if为假则不执行if中的语句。
如果#if判断为真预处理阶段就保留#if中的语句,如果为假,则在预处理阶段删除#if中的语句。
所以上面代码经过预处理后是这样的:
cpp
int main()
{
printf("hello world---1\n");
return 0;
}因为只有第一条#if判断为真,所以这条语句被保留了下来,第二条#if判断为假,则删除语句。
注:条件编译完最后记得加上一条#endif来表示条件编译结束。
11.2 多分支条件编译
多分支条件编译不管有多少条编译总归得执行一条,例如:
cpp
#include <stdio.h>
#define flag 17
int main()
{
#if flag%3 == 1
printf("flag取模3的余数为1\n");
#elif flag%3 == 2
printf("flag取模3的余数为2\n");
#else
printf("flag取模3的余数为0\n");
#endif
return 0;
}运行结果:

和if、else if、else的使用方法相似,只是功能不一样。
所以这条代码经过预处理后是这个格式:
cpp
int main()
{
printf("flag取模3的余数为2\n");
return 0;
}11.3 判断是否被定义
#ifdef或#if defined()就是判断该标识符符有没有定义,定义了就保留这条语句,未定义就删除语句。而#ifndef或#if !defined()判断该标识符没有定义就保留语句,定义了就删除语句。
cpp
#include <stdio.h>
#define MAX 100
int main()
{
#ifdef MAX
printf("MAX标识符已定义\n");
#endif
//等价
#if defined(MAX)
printf("MAX标识符已定义\n");
#endif
//.........
#ifndef MAX
printf("MAX标识符未定义\n");
#endif
//等价
#if !defined(MAX)
printf("MAX标识符未定义\n");
#endif
return 0;
}运行结果:

所以这条代码经过预处理后是这个格式:
cpp
int main()
{
printf("MAX标识符已定义\n");
return 0;
}12、头文件的包含
12.1 头文件被包含方式
12.1.1 本地文件包含
cpp
#include "filename.h"查找策略:先在源文件所在目录下查找,如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件。
如果找不到就提示编译错误。
Linux环境的标准头文件路径:
cpp
/usr/includeVS环境的标准头文件路径:
cpp
c:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\include
//这是VS2013的默认路径注意按照自己的安装路径去找。
12.1.2 库文件包含
cpp
#include <filename.h>查找头文件直接去标准路径下去查找,如果找不到就提示编译错误。
那是不是可以说,对于库文件也可以使用" "的形式包含?
cpp
#include "stdio.h"答案是肯定的,可以,但是这样查找的效率就低些,当然这样也不容易区分是库文件还是本地文件了。
12.2 嵌套文件包含
我们已经知道,#include 指令可以使另一个文件被编译。就像它实际出现于#include 指令的地方一样。
这种替换的方式很简单:预处理器先删除这条指令,并用包含文件的内容替换。
一个头文件被包含10次,那就实际被编译10次,如果重复包含,对编译的压力就比较大。
test.c源文件
cpp#include "test.h" #include "test.h" #include "test.h" #include "test.h" #include "test.h" int main() { return 0; }test.h头文件
cppvoid test(); struct stu { int id; char name[20]; };
如果直接这样写,test.c文件中将test.h包含5次,那么test.h文件的内容将会被拷贝5份在test.c中。
如果test.h文件比较大,这样预处理后代码会剧增。如果工程比较大,有公共使用的头文件,大家
都能使用,如何解决头文件被重复引入的问题呢?答案:条件编译
cpp
#ifndef __TEST_H__
#define __TEST_H__
//头文件内容
#endif //__TEST_H__或者
cpp
#pragma once就可以避免头文件的重复引入。
注:
推荐《高质量C/C++编程指南》中附录的考试试卷(很重要).
笔试题:
**1.**头文件中的 ifndef / define /endif是干什么用的?
答:是用来避免重复头文件重复包含的,ifndef判断标识符是否定义,如果未定义就继续向下编译,知道endif为止。中间使用define定义ifndef所判断的标识符,下一次再包含头文件属于重复包含但是因为第一次包含时顺便定义了该标识符,所以第二次包含时不会通过ifndef,ifndef会在预处理阶段将头文件一下内容删除,不会再被编译进包含该头文件的文件里。
2.****#include <filename.h> 和 #include "filename.h"有什么区别?
答:区别是<>所包含的头文件只寻找1次,而" "包含的头文件寻找2次。<>说明包含的头文件是标准库中的头文件,便会直接去标准库中寻找,找不到就编译错误,并不会额外花费时间去本地文件路径找。" "说明包含的头文件是本地文件,会先去本地文件路径下寻找,如果未找到就去标准库找,找了2次。
13、其他预处理指令
cpp
#error
#pragma
#line
...
不做介绍,可以自己去了解
#pragme pack()在结构体部分介绍过了14、offsetof模拟实现
offsetof是宏定义,参数就给它一个结构体类型,然后再给一个成员名它就可以求出该成员在结构体类型中内存对齐的偏移量。偏移量就是结构体的起始地址和内存对齐后变量的地址之间的距离。单位是:字节(byte)。
假设我们把0作为结构体的起始地址,那其他的成员的地址就是偏移量。有了思路我们就可以模拟offsetof了:
cpp
#include <stdio.h>
#define OFFSETOF(type,mem) (size_t)&(((type*)0)->mem)
//假设结构体的地址是0,通过0这个地址->找到成员取地址取出的就是偏移量。
//此时这个取出偏移量还是地址,将这个地址强制类型转换成(size_t)无符号整型。
struct S
{
char c1;
int i;
char c2;
};
int main()
{
printf("%d\n", OFFSETOF(struct S, c1));
printf("%d\n", OFFSETOF(struct S, i));
printf("%d\n", OFFSETOF(struct S, c2));
return 0;
}如果结构体的起始位置从0开始的话,那它成员的位置(地址)刚好就可以表示偏移量。
C99后
引入了一个概念:内联函数(inline)
**内联函数:**具有了函数的特点,也具有了宏的特点
**函数的特点:**参数、返回值
**宏的特点:**和宏一样,在调用内联函数的地方展开
学习C++时可以学到
到这里本篇C语言从入门到进阶博客结束了,欢迎大家在评论区留言,我们下一篇博客再见-
