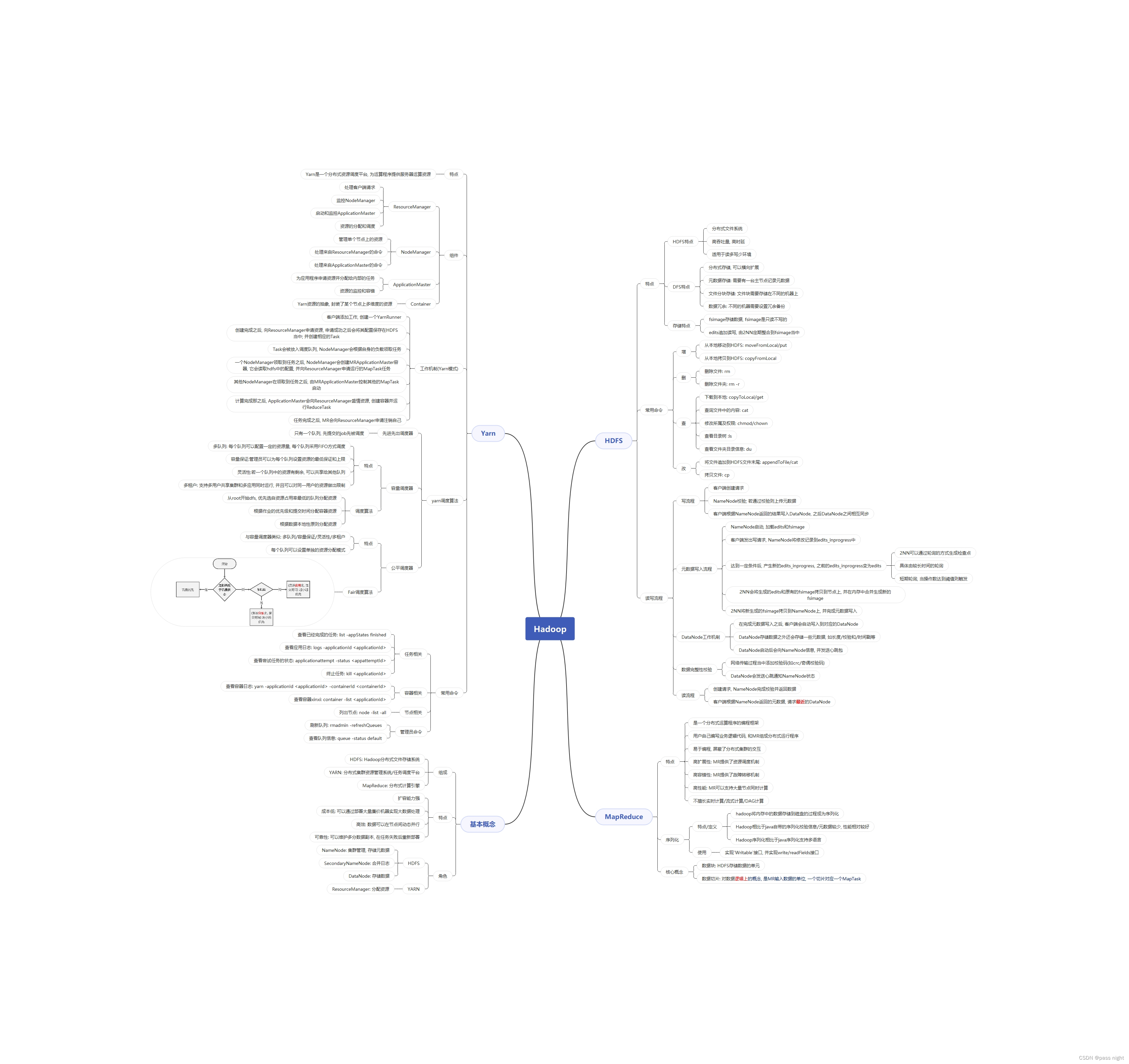
基本概念
- Hadoop组成
- HDFS: Hadoop分布式文件存储系统, 在Haddop中处于底层/核心地位
- YARN: 分布式通用的集群资源管理系统和任务调度平台, 支撑各种计算引擎执行
- MapReduce: 第一代分布式计算引擎, 但因为部分原因, 许多企业都不直接使用MapReduce, 但许多底层软件仍然在使用MapReduce
- Hadoop特点
- 扩容能力: Hadoop可以轻易地扩展到数千个节点, 并行地完成任务
- 低成本: Hadoop集群允许通过大量的廉价机组成集群来处理大数据
- 高效率: 通过并发数据, Hadoop可以在节点之间动态并行地移动数据, 使得速度非常快
- 可靠性: 能够自动维护数据的多份复制, 并在任务失败后能够重新部署计算任务
基本使用
-
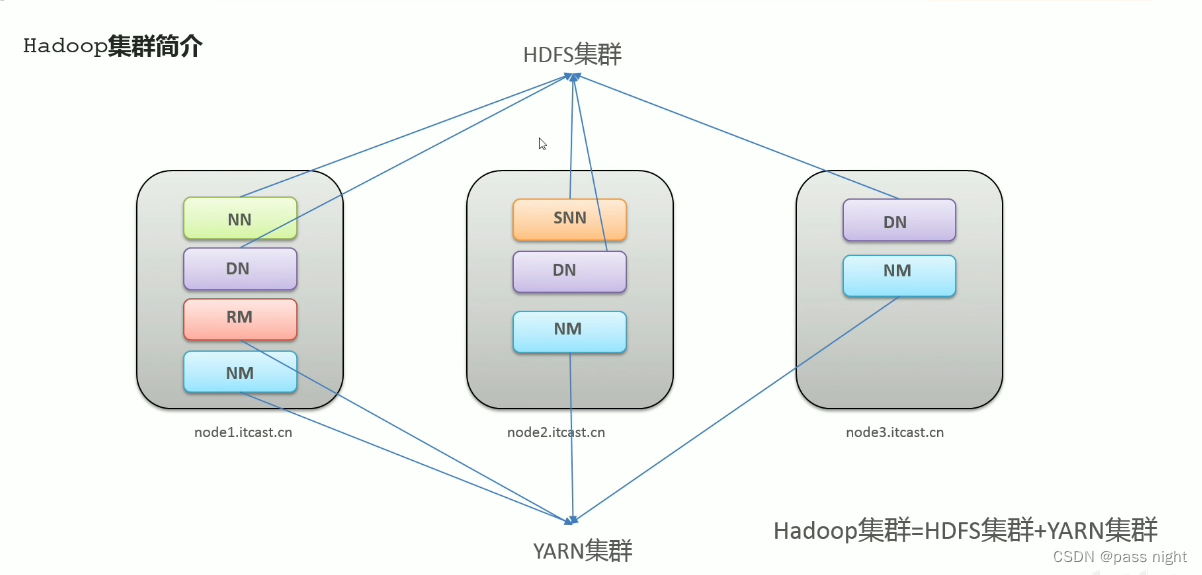
基本架构: 有两个集群组成, HDFS 集群和YARN集群
-
-
HDFS集群:
- 主角色: NameNode, 集群管理, 存储元数据
- 从角色: DataNode, 存储真实数据
- 主角色辅助角色: SecondaryNameNode, 合并日志
-
YARN集群
- 主角色: ResourceManager, 主节点, 分配资源
- 从角色: NodeManager, 从节点, 执行任务
部署
Docker集群部署[1](#Docker集群部署12345)[2](#Docker集群部署12345)[3](#Docker集群部署12345)[4](#Docker集群部署12345)[5](#Docker集群部署12345)
| 节点 | 组件 |
|---|---|
| passnight-s600 | namenode/datanode/resource manager/node manager |
| pasnight-acepc | data node/node manager |
| passnight-centerm | secondary name node/datanode/nodemanager |
passnight-s600对应的docker-compose.yml为
yml
version: "2.1"
services:
namenode:
network_mode: "host"
container_name: hadoop-namenode
hostname: server.passnight.local
image: apache/hadoop:3.3.6
command: ["hdfs", "namenode"]
restart: always
volumes:
- /opt/docker/hadoop/namenode/data:/tmp/hadoop
environment:
# Common Part
HADOOP_HOME: /opt/hadoop
CORE-SITE.XML_fs.defaultFS: hdfs://server.passnight.local
CORE-SITE.XML_io.file.buffer.size: 131072
CORE-SITE.XML_hadoop.tmp.dir: /tmp/hadoop # A base for other temporary directories.
# Configuration for namenode
# HDFS-SITE.XML_dfs.namenode.name.dir: file://${hadoop.tmp.dir}/dfs/name # Path on the local filesystem where the NameNode stores the namespace and transactions logs persistently.
HDFS-SITE.XML_dfs.namenode.secondary.http-address: "replica.passnight.local:50090" # The secondary namenode http server address and port.
HDFS-SITE.XML_dfs.permissions: "false"
ENSURE_NAMENODE_DIR: "/tmp/hadoop/dfs/name" # 没有这个NameNode启动报错
CORE-SITE.XML_hadoop.http.staticuser.user: root
datanode:
network_mode: "host"
container_name: hadoop-datanode
hostname: server.passnight.local
image: apache/hadoop:3.3.6
command: ["hdfs", "datanode"]
restart: always
volumes:
- /opt/docker/hadoop/datanode/data:/tmp/hadoop
environment:
# Common Part
HADOOP_HOME: /opt/hadoop
CORE-SITE.XML_fs.defaultFS: hdfs://server.passnight.local
CORE-SITE.XML_io.file.buffer.size: 131072
CORE-SITE.XML_hadoop.tmp.dir: /tmp/hadoop # A base for other temporary directories.
# Configuration for datanode
# HDFS-SITE.XML_dfs.datanode.data.dir: file://${hadoop.tmp.dir}/dfs/data # Comma separated list of paths on the local filesystem of a DataNode where it should store its blocks.
# CORE-SITE.XML_hadoop.http.staticuser.user: root
resourcemanager:
network_mode: "host"
container_name: hadoop-resourcemanager
hostname: server.passnight.local
image: apache/hadoop:3.3.6
command: ["yarn", "resourcemanager"]
volumes:
- /opt/docker/hadoop/resourcemanager/data:/tmp/hadoop
restart: always
environment:
# Common Part
HADOOP_HOME: /opt/hadoop
CORE-SITE.XML_fs.defaultFS: hdfs://server.passnight.local
CORE-SITE.XML_io.file.buffer.size: 131072
CORE-SITE.XML_hadoop.tmp.dir: /tmp/hadoop # A base for other temporary directories.
# Configuration for both ResourceManager and NodeManager
YARN-SITE.XML_yarn.resourcemanager.hostname: server.passnight.local # The address of the applications manager interface in the RM.
# Configurations for ResourceManager
YARN-SITE.XML_yarn.resourcemanager.address: server.passnight.local:8032 # ResourceManager host:port for clients to submit jobs.
YARN-SITE.XML_yarn.resourcemanager.scheduler.address: server.passnight.local:8030 # ResourceManager host:port for ApplicationMasters to talk to Scheduler to obtain resources.
YARN-SITE.XML_yarn.resourcemanager.resource-tracker.address: server.passnight.local:8031 # ResourceManager host:port for NodeManagers.
YARN-SITE.XML_yarn.resourcemanager.admin.address: server.passnight.local:8033 # ResourceManager host:port for administrative commands.
YARN-SITE.XML_yarn.resourcemanager.webapp.address: server.passnight.local:8088 # ResourceManager web-ui host:port.
# Configuration for map reduce
MAPRED-SITE.XML_mapreduce.framework.name: yarn
MAPRED-SITE.XML_yarn.app.mapreduce.am.env: HADOOP_MAPRED_HOME=/opt/hadoop
MAPRED-SITE.XML_mapreduce.map.env: HADOOP_MAPRED_HOME=/opt/hadoop
MAPRED-SITE.XML_mapreduce.reduce.env: HADOOP_MAPRED_HOME=/opt/hadoop
WORKERS: |
server.passnight.local
replica.passnight.local
follower.passnight.local
nodemanager:
network_mode: "host"
container_name: hadoop-nodemanager
hostname: server.passnight.local
image: apache/hadoop:3.3.6
command: ["yarn", "nodemanager"]
volumes:
- /opt/docker/hadoop/nodemanager/data:/tmp/hadoop
restart: always
environment:
# Common Part
HADOOP_HOME: /opt/hadoop
CORE-SITE.XML_fs.defaultFS: hdfs://server.passnight.local
CORE-SITE.XML_io.file.buffer.size: 131072
CORE-SITE.XML_hadoop.tmp.dir: /tmp/hadoop # A base for other temporary directories.
# Configuration for both ResourceManager and NodeManager
YARN-SITE.XML_yarn.resourcemanager.hostname: server.passnight.local # The address of the applications manager interface in the RM.
# Configurations for NodeManager
YARN-SITE.XML_yarn.nodemanager.aux-services: mapreduce_shuffle # Shuffle service that needs to be set for Map Reduce applications.
YARN-SITE.XML_yarn.nodemanager.auxservices.mapreduce.shuffle.class: org.apache.hadoop.mapred.ShuffleHandler
WORKERS: | # Helper scripts (described below) will use the etc/hadoop/workers file to run commands on many hosts at once.
server.passnight.local
replica.passnight.local
follower.passnight.localpassnight-centerm对应的docker-compose.yml为
yml
version: "2.1"
services:
datanode:
network_mode: "host"
container_name: hadoop-datanode
hostname: follower.passnight.local
image: apache/hadoop:3.3.6
command: ["hdfs", "datanode"]
restart: always
volumes:
- /opt/docker/hadoop/datanode/data:/tmp/hadoop
environment:
# Common Part
HADOOP_HOME: /opt/hadoop
CORE-SITE.XML_fs.defaultFS: hdfs://server.passnight.local
CORE-SITE.XML_io.file.buffer.size: 131072
CORE-SITE.XML_hadoop.tmp.dir: /tmp/hadoop # A base for other temporary directories.
# Configuration for datanode
# HDFS-SITE.XML_dfs.datanode.data.dir: file://${hadoop.tmp.dir}/dfs/data # Comma separated list of paths on the local filesystem of a DataNode where it should store its blocks.
# CORE-SITE.XML_hadoop.http.staticuser.user: root
nodemanager:
network_mode: "host"
container_name: hadoop-nodemanager
hostname: follower.passnight.local
image: apache/hadoop:3.3.6
command: ["yarn", "nodemanager"]
volumes:
- /opt/docker/hadoop/nodemanager/data:/tmp/hadoop
restart: always
environment:
# Common Part
HADOOP_HOME: /opt/hadoop
CORE-SITE.XML_fs.defaultFS: hdfs://server.passnight.local
CORE-SITE.XML_io.file.buffer.size: 131072
CORE-SITE.XML_hadoop.tmp.dir: /tmp/hadoop # A base for other temporary directories.
# Configuration for both ResourceManager and NodeManager
YARN-SITE.XML_yarn.resourcemanager.hostname: server.passnight.local # The address of the applications manager interface in the RM.
# Configurations for NodeManager
YARN-SITE.XML_yarn.nodemanager.aux-services: mapreduce_shuffle # Shuffle service that needs to be set for Map Reduce applications.
YARN-SITE.XML_yarn.nodemanager.auxservices.mapreduce.shuffle.class: org.apache.hadoop.mapred.ShuffleHandler
WORKERS: | # Helper scripts (described below) will use the etc/hadoop/workers file to run commands on many hosts at once.
server.passnight.local
replica.passnight.local
follower.passnight.localpassnight-acepc对应的docke-compose.yml为
yml
version: "2.1"
services:
secondarynamenode:
network_mode: "host"
container_name: hadoop-secondarynamenode
hostname: replica.passnight.local
image: apache/hadoop:3
command: ["hdfs", "secondarynamenode"]
restart: always
volumes:
- /opt/docker/hadoop/secondarynamenode/data:/tmp/hadoop
environment:
# Common Part
HADOOP_HOME: /opt/hadoop
CORE-SITE.XML_fs.defaultFS: hdfs://server.passnight.local
CORE-SITE.XML_io.file.buffer.size: 131072
CORE-SITE.XML_hadoop.tmp.dir: /tmp/hadoop # A base for other temporary directories.
datanode:
network_mode: "host"
container_name: hadoop-datanode
hostname: replica.passnight.local
image: apache/hadoop:3.3.6
command: ["hdfs", "datanode"]
# restart: always
volumes:
- /opt/docker/hadoop/datanode/data:/tmp/hadoop
environment:
# Common Part
HADOOP_HOME: /opt/hadoop
CORE-SITE.XML_fs.defaultFS: hdfs://server.passnight.local
CORE-SITE.XML_io.file.buffer.size: 131072
CORE-SITE.XML_hadoop.tmp.dir: /tmp/hadoop # A base for other temporary directories.
# Configuration for datanode
# HDFS-SITE.XML_dfs.datanode.data.dir: file://${hadoop.tmp.dir}/dfs/data # Comma separated list of paths on the local filesystem of a DataNode where it should store its blocks.
# CORE-SITE.XML_hadoop.http.staticuser.user: root
nodemanager:
network_mode: "host"
container_name: hadoop-nodemanager
hostname: replica.passnight.local
image: apache/hadoop:3.3.6
command: ["yarn", "nodemanager"]
volumes:
- /opt/docker/hadoop/nodemanager/data:/tmp/hadoop
# restart: always
environment:
# Common Part
HADOOP_HOME: /opt/hadoop
CORE-SITE.XML_fs.defaultFS: hdfs://server.passnight.local
CORE-SITE.XML_io.file.buffer.size: 131072
CORE-SITE.XML_hadoop.tmp.dir: /tmp/hadoop # A base for other temporary directories.
# Configuration for both ResourceManager and NodeManager
YARN-SITE.XML_yarn.resourcemanager.hostname: server.passnight.local # The address of the applications manager interface in the RM.
# Configurations for NodeManager
YARN-SITE.XML_yarn.nodemanager.aux-services: mapreduce_shuffle # Shuffle service that needs to be set for Map Reduce applications.
YARN-SITE.XML_yarn.nodemanager.auxservices.mapreduce.shuffle.class: org.apache.hadoop.mapred.ShuffleHandler
WORKERS: | # Helper scripts (described below) will use the etc/hadoop/workers file to run commands on many hosts at once.
server.passnight.local
replica.passnight.local
follower.passnight.local 注意:
-
因为Ubuntu默认hostname指向的是
127.0.1.1, 而hadoop默认监听的端口是127.0.0.1, 这样会导致yarn调度无法实现ipc, 进而导致任务无法正常执行, 所以需要在docker中手动配置hostname[6](#6); 报错信息如下:bashContainer launch failed for container_1710772060978_0008_01_000002 : java.net.ConnectException: Call From passnight-minit8/127.0.1.1 to localhost:44933 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused -
在测试环境不需要多于的权限系统, 这会导致许多任务执行失败, 而一个个单独配置权限又过于麻烦;
-
当权限不足会报错:
bashorg.apache.hadoop.security.AccessControlException: Permission denied: user=passnight, access=WRITE, inode="/user":hadoop:supergroup:drwxr-xr-x -
此时可以通过在name node中配置
HDFS-SITE.XML_dfs.permissions: "false"实现
-
配置Client
-
因为集群是部署在docker容器当中的, 为了方便使用, 可以在宿主机当中配置客户端
-
客户端的部署类似于Hadoop单机的安装, 但不启动daemon服务; 我们只需要
hadoop,yarn等客户端即可 -
本地安装的步骤大致包括下载/解压/配置对应的可执行文件到环境变量当中
-
之外, 还需要进行部分配置才能正常连接到远程服务
-
首先是HDFS连接相关的配置, 在
core-site.xml中添加以下内容xml<property> <name>fs.defaultFS</name> <value>hdfs://server.passnight.local</value> <description>hdfs默认地址与端口</description> </property> -
其次是yarn相关的配置, 在
yarn-site.xml中添加以下内容xml<property> <name>yarn.resourcemanager.hostname</name> <value>server.passnight.local</value> </property> -
最后是map reduce相关的配置, 需要配置yarn容器的环境变量, 以及设置集群模式 在不显示指定会默认以local模式执行 ; 在
mapred-site.xml中配置xml<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/opt/hadoop</value> <description> User added environment variables for the MR App Master processes, specified as a comma separated list. </description> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/opt/hadoop</value> <description> User added environment variables for the MR App Master processes, specified as a comma separated list. </description> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/opt/hadoop</value> <description> User added environment variables for the MR App Master processes, specified as a comma separated list. </description> </property>
Hadoop基本使用
bash
passnight@passnight-s600:~$ docker exec -it hadoop-namenode bash
# ls命令
bash-4.2$ hadoop fs -ls /
# mkdir 命令
bash-4.2$ hadoop fs -mkdir /test
bash-4.2$ hadoop fs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2023-10-05 09:00 /test
# 文件上传命令: put
bash-4.2$ hadoop fs -put NOTICE.txt /test
# 使用Hadoop计算圆周率
bash-4.2$ pwd
/opt/hadoop/share/hadoop/mapreduce
bash-4.2$ hadoop jar hadoop-mapreduce-examples-3.3.1.jar pi 2 2
# 使用hadoop统计单词词频
bash-4.2$ hadoop jar hadoop-mapreduce-examples-3.3.1.jar wordcount /test/NOTICE.txt /test/output单机模式下的基本使用
安装Hadoop ^[7](#安装Hadoop 78)^^[8](#安装Hadoop 78)^
bash
passnight@passnight-s600:/tmp$ wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
passnight@passnight-s600:/tmp$ tar -xvf hadoop-3.3.6.tar.gz
passnight@passnight-s600:/tmp$ sudo mv hadoop-3.3.6 /usr/local/hadoop
passnight@passnight-s600:/usr/local$ sudo mkdir -p /var/lib/hadoop/name # 创建NameNode的文件目录
passnight@passnight-s600:/usr/local$ sudo mkdir -p /var/lib/hadoop/data # 创建DataNode的文件目录
passnight@passnight-s600:/usr/local/hadoop$ vim etc/hadoop/hdfs-site.xml # 配置文件在<configuration>下添加以下内容
xml
<property>
<name>dfs.replication</name>
<value>1</value>
<description>表示数据块的备份数量,不能大于DataNode的数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/lib/hadoop/name</value>
<description>表示 NameNode 需要存储数据的文件目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/lib/hadoop/data</value>
<description>表示 DataNode 需要存放数据的文件目录</description>
</property>再配置hadoop
bash
passnight@passnight-s600:/usr/local/hadoop/etc/hadoop$ vim core-site.xml 添加如下配置
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://server.passnight.local:20011</value>
<description>表示HDFS的基本路径</description>
</property>
</configuration>将Hadoop添加到环境变量中
bash
# passnight@passnight-s600:/usr/local/hadoop/etc/hadoop$ vim /etc/bash.bashrc
export HADOOP_HOME="/usr/local/hadoop"
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# :wq 保存
passnight@passnight-s600:/usr/local/hadoop/etc/hadoop$ source /etc/bash.bashrc # 使配置文件生效修改Hadoop环境变量配置文件hadoop.env.sh
bash
passnight@passnight-s600:/usr/local/hadoop/etc/hadoop$ vim hadoop-env.sh
# 添加下面内容
export JAVA_HOME="/usr/lib/jvm/java-1.11.0-openjdk-amd64/"
# :wq 保存尝试运行:
bash
passnight@passnight-s600:/usr/local/hadoop/etc/hadoop$ hdfs
Usage: hdfs [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
OPTIONS is none or any of:
--buildpaths attempt to add class files from build tree
--config dir Hadoop config directory
--daemon (start|status|stop) operate on a daemon
--debug turn on shell script debug mode
--help usage information
--hostnames list[,of,host,names] hosts to use in worker mode
--hosts filename list of hosts to use in worker mode
--loglevel level set the log4j level for this command
--workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
cacheadmin configure the HDFS cache
crypto configure HDFS encryption zones
debug run a Debug Admin to execute HDFS debug commands
dfsadmin run a DFS admin client
dfsrouteradmin manage Router-based federation
ec run a HDFS ErasureCoding CLI
fsck run a DFS filesystem checking utility
haadmin run a DFS HA admin client
jmxget get JMX exported values from NameNode or DataNode.
oev apply the offline edits viewer to an edits file
oiv apply the offline fsimage viewer to an fsimage
oiv_legacy apply the offline fsimage viewer to a legacy fsimage
storagepolicies list/get/set/satisfyStoragePolicy block storage policies
Client Commands:
classpath prints the class path needed to get the hadoop jar and the required libraries
dfs run a filesystem command on the file system
envvars display computed Hadoop environment variables
fetchdt fetch a delegation token from the NameNode
getconf get config values from configuration
groups get the groups which users belong to
lsSnapshottableDir list all snapshottable dirs owned by the current user
snapshotDiff diff two snapshots of a directory or diff the current directory contents with a snapshot
version print the version
Daemon Commands:
balancer run a cluster balancing utility
datanode run a DFS datanode
dfsrouter run the DFS router
diskbalancer Distributes data evenly among disks on a given node
httpfs run HttpFS server, the HDFS HTTP Gateway
journalnode run the DFS journalnode
mover run a utility to move block replicas across storage types
namenode run the DFS namenode
nfs3 run an NFS version 3 gateway
portmap run a portmap service
secondarynamenode run the DFS secondary namenode
sps run external storagepolicysatisfier
zkfc run the ZK Failover Controller daemon
SUBCOMMAND may print help when invoked w/o parameters or with -h.修改数据存储位置的权限
bash
passnight@passnight-s600:/usr/local/hadoop/etc/hadoop$ sudo chown passnight:passnight /var/lib/hadoop/
passnight@passnight-s600:/var/lib/hadoop$ hdfs namenode -format ## 格式化 HDFS 集群的 namenode尝试启动
bash
passnight@passnight-s600:/usr/local/hadoop/etc/hadoop$ start-dfs.sh
Starting namenodes on [passnight-s600]
passnight-s600: passnight@passnight-s600: Permission denied (publickey,password).
Starting datanodes
localhost: passnight@localhost: Permission denied (publickey,password).
Starting secondary namenodes [passnight-s600]
passnight-s600: passnight@passnight-s600: Permission denied (publickey,password).将自身公钥添加到允许访问的公钥中
bash
passnight@passnight-s600:/usr/local/hadoop/etc/hadoop$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys再次尝试启动 以特权模式
bash
passnight@passnight-s600:/usr/local/hadoop$ sudo sbin/start-dfs.sh
Starting namenodes on [server.passnight.local]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [passnight-s600]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.将相关环境变量添加到hadoop.env.sh中[9](#9)
bash
# passnight@passnight-s600:/usr/local/hadoop$ vim etc/hadoop/hadoop-env.sh
export HDFS_NAMENODE_USER=passnight
export HDFS_DATANODE_USER=passnight
export HDFS_SECONDARYNAMENODE_USER=passnight
export YARN_RESOURCEMANAGER_USER=passnight
export YARN_NODEMANAGER_USER=passnight
# :wa再次尝试启动
bash
passnight@passnight-s600:/usr/local/hadoop$ start-dfs.sh
Starting namenodes on [server.passnight.local]
Starting datanodes
Starting secondary namenodes [passnight-s600]javapom依赖
Java依赖
xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.4.1</version>
</dependency>
</dependencies>第一个Hadoop应用
在HAFS中创建一个文件
bash
# 显示根目录 / 下的文件和子目录,绝对路径
passnight@passnight-s600:~$ hadoop fs -ls /
# 新建文件夹,绝对路径
passnight@passnight-s600:~$ hadoop fs -mkdir /hello
# 上传文件
passnight@passnight-s600:~/tmp$ echo "hello world" > hello.txt
passnight@passnight-s600:~/tmp$ hadoop fs -put hello.txt /hello/
# 下载文件
passnight@passnight-s600:~/tmp$ rm hello.txt
passnight@passnight-s600:~/tmp$ hadoop fs -get /hello/hello.txt
passnight@passnight-s600:~/tmp$ cat hello.txt
hello world
# 输出文件内容
passnight@passnight-s600:~/tmp$ hadoop fs -cat /hello/hello.txt或是使用java完成文件上传
java
package com.passnight.bigdata.hadoop;
import lombok.extern.log4j.Log4j2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.jupiter.api.Test;
import java.io.IOException;
@Log4j2
public class WordCountTest {
@Test
public void writeHDFS() throws IOException {
System.setProperty("hadoop.home.dir", "/usr/local/hadoop");
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://server.passnight.local:20011");
FileSystem fs = FileSystem.get(conf);
fs.copyFromLocalFile(new Path("src/test/resources/word list.txt"), new Path("/hello/word list.txt"));
}
}使用java程序操作
java
package com.passnight.bigdata.first;
import lombok.SneakyThrows;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSManipulate {
@SneakyThrows
public static void main(String[] args) {
System.setProperty("hadoop.home.dir", "/usr/local/hadoop");
// 配置连接地址
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://server.passnight.local:20011");
FileSystem fs = FileSystem.get(conf);
// 打开文件并读取输出
Path hello = new Path("/hello/hello.txt");
FSDataInputStream ins = fs.open(hello);
System.out.println("-".repeat(100));
System.out.println(new String(ins.readAllBytes()));
System.out.println("-".repeat(100));
}
}输出:
bash
----------------------------------------------------------------------------------------------------
21:27:25.328 [main] DEBUG org.apache.hadoop.hdfs.DFSClient - Connecting to datanode 192.168.100.3:9866
21:27:25.334 [main] DEBUG org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
21:27:25.334 [IPC Parameter Sending Thread #0] DEBUG org.apache.hadoop.ipc.Client - IPC Client (2030538903) connection to server.passnight.local/192.168.100.3:20011 from passnight sending #1 org.apache.hadoop.hdfs.protocol.ClientProtocol.getServerDefaults
21:27:25.335 [IPC Client (2030538903) connection to server.passnight.local/192.168.100.3:20011 from passnight] DEBUG org.apache.hadoop.ipc.Client - IPC Client (2030538903) connection to server.passnight.local/192.168.100.3:20011 from passnight got value #1
21:27:25.335 [main] DEBUG org.apache.hadoop.ipc.ProtobufRpcEngine2 - Call: getServerDefaults took 1ms
21:27:25.338 [main] DEBUG org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient - SASL client skipping handshake in unsecured configuration for addr = /192.168.100.3, datanodeId = DatanodeInfoWithStorage[192.168.100.3:9866,DS-dcd3a633-c853-40e8-b2aa-62b93434f7db,DISK]
hello world
----------------------------------------------------------------------------------------------------使用Hadoop实现WordCount[10](#使用Hadoop实现WordCount10)
java
package com.passnight.bigdata.first;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
System.setProperty("hadoop.home.dir", "/usr/local/hadoop");
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("bigdata/src/main/resources/word list.txt"));
FileOutputFormat.setOutputPath(job, new Path("bigdata/src/main/resources/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}该程序使用的是本地文件系统而非hdfs, 直接使用cat命令查看结果:
bash
passnight@passnight-s600:~/project/note/spring$ cat bigdata/src/main/resources/output/part-r-00000
I 4
hadoop 2
like 2
love 2
runoob 2HDFS基本概念
分布式文件系统
- 重要概念
- 数据: 存储的内容本身
- 元数据: 记录数据的数据 如文件大小/最后修改时间/底层存储位置等
- 单机文件系统的特点:
- 带有抽象的目录树结构
- 树节点可以分为两类: 目录和文件
- 从根目录开始, 节点路径具有唯一性
- 海量数据存在的问题
- 高成本: 传统的存储方式达到一定阈值之后, 扩容成本极大
- 传统的数据和程序的分布结构无法支撑高性能的计算和分析
- 性能低: 单节点的IO瓶颈无法逾越, 难以支撑高并发高吞吐的场景
- 可扩展性差: 无法实现部署和弹性扩展/动态扩缩容的成本高, 技术实现难度大
- 分布式存储系统的核心属性
- 分布式存储: 存储横向扩展, 理论上可以无限扩展
- 元数据存储: 分布在不同机器上的元数据不同于寻找, 因此需要将部分机器用于元数据记录
- 文件分块存储: 过大的文件分块存储在不同的机器, 可以针对各个块并行操作以提升效率 这个时候元数据需要记录分块信息
- 数据冗余: 硬件的故障难以避免, 不同的机器设置备份, 冗余存储, 保障数据安全
HDFS的特点
- HDFS: Hadoop Distributed File System, 意为Hadoop分布式文件系统:
- HSFS主要是解决大数据存储的问问题, 分布式意味着HDFS是横跨多台计算机上的存储系统
- HDFS是一种能够在普通硬件上运行的分布式文件系统, 它具有高度容错的特点, 适用于具有大数据集的应用程序
- HDFS的设计目标
- 故障检测和自动快速恢复: HDFS由成百上千个节点组成, 每个节点都有可能出现故障, 因此需要有故障检测盒恢复的能力
- 吞吐量有限: HDFS上的应用主要是流式读取数据, 被用于批处理, 相比于数据访问的反应时间, 它更注重于吞吐量
- 一次写入多次读取的访问模型: 一个文件一旦创建/写入/关闭后就不需要再修改了 这样能简化数据一致性的问题
- 移动计算的性价比之移动数据的计算代价低: 一个应用请求的计算, 离它操作的数据越近就越高效. 因此将计算移动到数据附近可以极大地提高计算效率
- HDFS应用场景: 大文件/数据流式访问/一次写入多次读取/低成本高性能部署
- 不适用场景: 大量小文件/数据交互式访问/频繁任意修改/低延迟处理
HDFS组成架构
- NameNode: 是集群的Master, 是管理集群的节点
- 管理HDFS的命名空间
- 配置副本策略
- 管理数据块的映射信息
- 处理客户端的读写请求
- DataNode: 是集群的Slave, 即实际执行操作的节点
- 存储实际的数据块
- 执行数据块的读写操作
- Secondary NameNode: Secondary NameNode并非NameNode的热备, 因此当NameNode宕机时, 它不能替代NameNode
- 辅助NameNode, 分担其工作量, 并推送给NameNode
- 在紧急情况下, 可以恢复NameNode
- Client: 即客户端
- 文件气氛: 文件上传HDFS的时候, Client将文件拆分成多个块
- 与NameNode交互, 获取文件的位置信息
- 与DataNode交互, 读取或者写入数据
- Client提供一些命令用于管理HDFS 如NameNode的格式化
- Client可以通过一些命令操作集群, 如对集群的增删查改
常用Shell命令
bash
# 查看帮助
bash-4.2$ hadoop fs -help mkdir
-mkdir [-p] <path> ... :
Create a directory in specified location.
-p Do not fail if the directory already exists
# 创建文件夹
bash-4.2$ hadoop fs -mkdir /test上传命令
bash
################上传###################################
# 从本地移动到HDFS
bash-4.2$ echo "hello world" > hello.txt
bash-4.2$ hadoop fs -moveFromLocal hello.txt /test
bash-4.2$ ls | grep hello
bash-4.2$ hadoop fs -ls /test
Found 1 items
-rw-r--r-- 3 hadoop supergroup 12 2023-10-07 13:53 /test/hello.txt
# 从本地拷贝到HDFS, 还有一个别名为`put`
bash-4.2$ echo "copyed hello" > chello.txt
bash-4.2$ hadoop fs -copyFromLocal chello.txt /test
bash-4.2$ hadoop fs -ls /test | grep chello
-rw-r--r-- 3 hadoop supergroup 13 2023-10-07 13:54 /test/chello.txt
bash-4.2$ ls | grep chello
chello.txt
# 从本地拷贝到HDFS, 同`copyFromLocal`
bash-4.2$ echo "p hello world" > phello.txt
bash-4.2$ hadoop fs -put phello.txt /test
bash-4.2$ hadoop fs -ls /test | grep phello
-rw-r--r-- 3 hadoop supergroup 14 2023-10-07 13:55 /test/phello.txt
bash-4.2$ ls | grep phello
phello.txt
# 将一个文件追加到一个文件的末尾
bash-4.2$ hadoop fs -put ahello.text /test/ahello.text
bash-4.2$ hadoop fs -appendToFile ahello.text /test/ahello.text
bash-4.2$ hadoop fs -cat /test/ahello.text
hello again
hello again
hello again下载命令
bash
#################################下载命令
# 从hdfs下载文件, 同`get`
bash-4.2$ rm ahello.text
bash-4.2$ hadoop fs -copyToLocal /test/ahello.text ./
bash-4.2$ cat ahello.text
hello again
hello again
# 从hdfs下载文件, 同`copyFromLocal`
bash-4.2$ rm ahello.text
bash-4.2$ hadoop fs -get /test/ahello.text ./
bash-4.2$ cat ahello.text
hello again
hello again查询修改操作
bash
##########################查询命令
# 查看目录中的文件
bash-4.2$ hadoop fs -ls /test
Found 5 items
-rw-r--r-- 3 hadoop supergroup 24 2023-10-07 13:59 /test/ahello.text
-rw-r--r-- 3 hadoop supergroup 13 2023-10-07 13:54 /test/chello.txt
-rw-r--r-- 3 hadoop supergroup 36 2023-10-07 13:58 /test/hello.text
-rw-r--r-- 3 hadoop supergroup 12 2023-10-07 13:53 /test/hello.txt
-rw-r--r-- 3 hadoop supergroup 14 2023-10-07 13:55 /test/phello.txt
# 查看文件中的内容
bash-4.2$ hadoop fs -cat /test/hello.txt
hello world
# 修改文件归属及权限
bash-4.2$ hadoop fs -chown passnight:passnight /test/hello.txt
bash-4.2$ hadoop fs -chmod 666 /test/hello.txt
bash-4.2$ hadoop fs -ls /test | grep test/hello.txt
-rw-rw-rw- 3 passnight passnight 12 2023-10-07 13:53 /test/hello.txt
# 拷贝文件
bash-4.2$ hadoop fs -mkdir /test/another
bash-4.2$ hadoop fs -cp /test/hello.txt /test/another/hello.txt
bash-4.2$ hadoop fs -ls /test | grep /test/hello.txt
-rw-rw-rw- 3 passnight passnight 12 2023-10-07 13:53 /test/hello.txt
bash-4.2$ hadoop fs -ls /test | grep /test/another/hello.txt
bash-4.2$ hadoop fs -ls /test/another | grep /hello.txt
-rw-r--r-- 3 hadoop supergroup 12 2023-10-07 14:08 /test/another/hello.txt
# 移动文件
bash-4.2$ hadoop fs -mv /test/hello.text /test/another
bash-4.2$ hadoop fs -ls /test | grep test/hello.text
bash-4.2$ hadoop fs -ls /test/another | grep hello.text
-rw-r--r-- 3 hadoop supergroup 36 2023-10-07 13:58 /test/another/hello.text
# 查看文件头尾1kb的数据
bash-4.2$ hadoop fs -tail /test/chello.txt
copyed hello
bash-4.2$ hadoop fs -head /test/chello.txt
copyed hello
# 删除文件
bash-4.2$ hadoop fs -rm /test/ahello.text
Deleted /test/ahello.text
bash-4.2$ hadoop fs -ls /test | grep /test/ahello.text
bash-4.2$ hadoop fs -rm -r /test/another
Deleted /test/another
bash-4.2$ hadoop fs -ls /test | grep another
# 统计文件夹的大小信息
bash-4.2$ hadoop fs -du /test
13 39 /test/chello.txt
12 36 /test/hello.txt
14 42 /test/phello.txt
bash-4.2$ hadoop fs -du -s -h /test
39 117 /test
# 修改副本数量, 注意副本数量不会超过机器数量
bash-4.2$ hadoop fs -setrep 2 /test/phello.txt
Replication 2 set: /test/phello.txt
bash-4.2$ hadoop fs -ls /test | grep phello
-rw-r--r-- 2 hadoop supergroup 14 2023-10-07 13:55 /test/phello.txt
bash-4.2$ hadoop fs -setrep 20 /test/phello.txt
Replication 20 set: /test/phello.txt
bash-4.2$ hadoop fs -ls /test | grep phello
-rw-r--r-- 20 hadoop supergroup 14 2023-10-07 13:55 /test/phello.txtHDFS读写流程
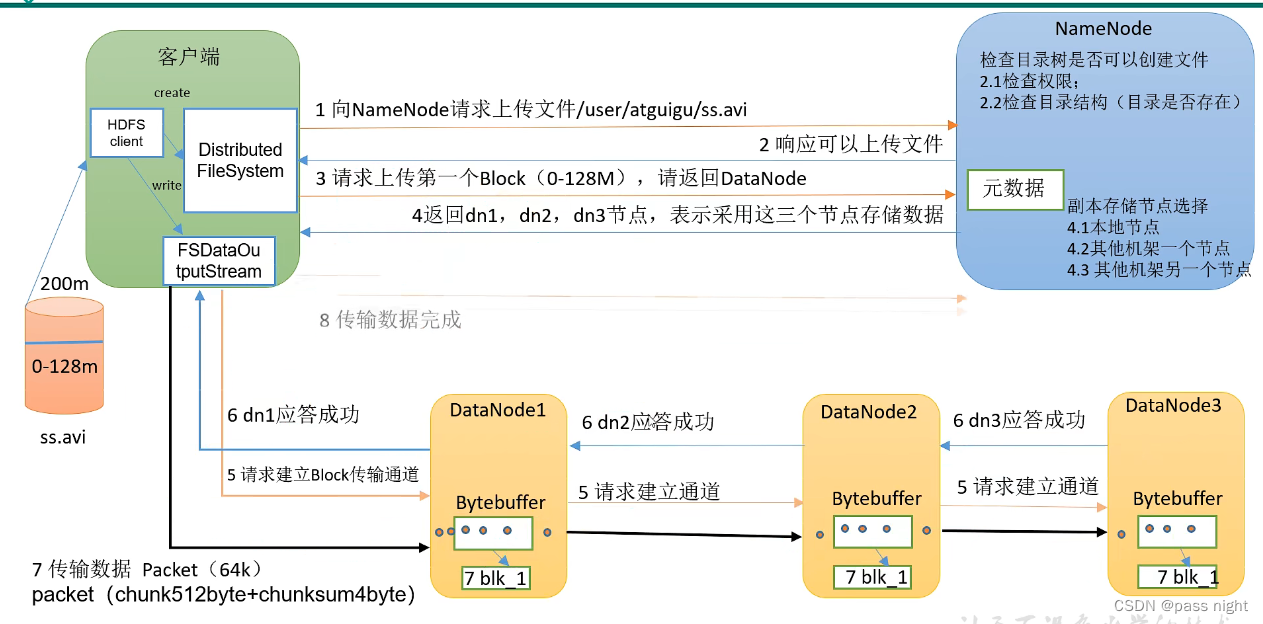
注意:这是文件的写入流程, 并不包括元数据的写入流程
-
写流程:
-
-
客户端创建一个分布式文件系统对象, 由该对象完成文件读写请求
-
向NameNode发送请求, NameNode进行校验; 校验完成后返回结果 如文件是否已经存在/是否由权限等
-
若通过校验, 则上传第一个block的元数据到NameNode, NameNode在返回存储数据的策略
-
客户端创建输出流, 并根据NameNode的存储策略写文件; 该过程只需要写一个DataNode, 剩下的节点与与客户端交互的节点相同步
-
-
节点距离计算: 最近公共祖先到二者的距离和
-
读流程
-
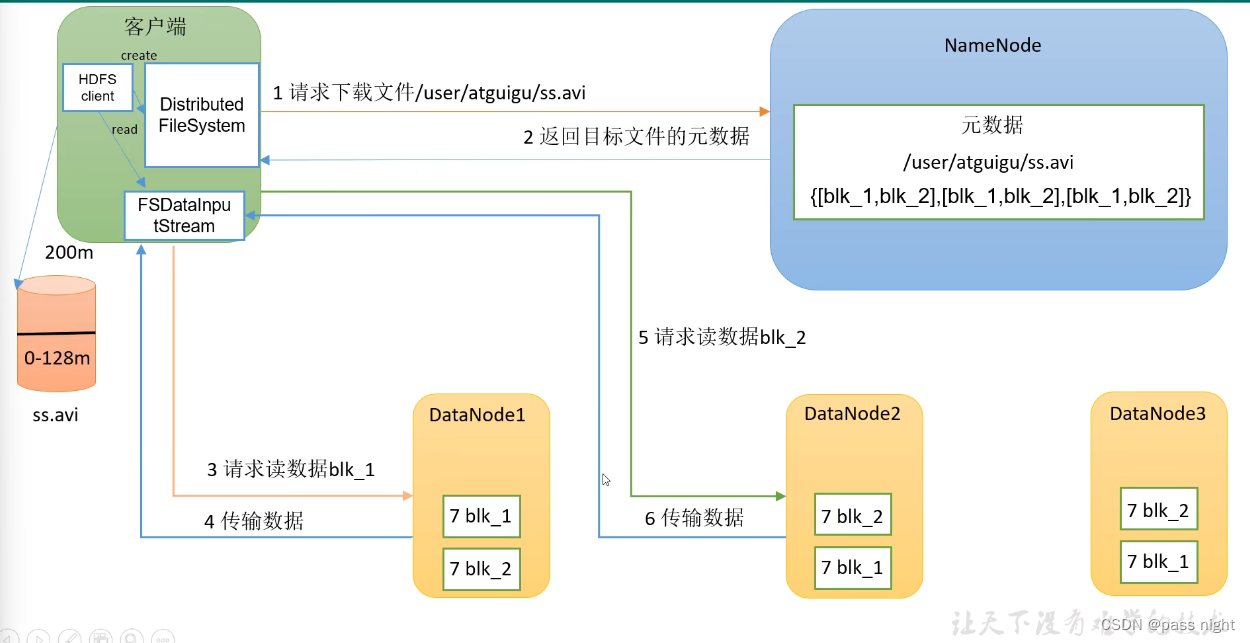
-
客户端创建一个分布式文件系统对象, 由该对象完成文件的读写请求
-
向NameNode发送请求, NameNode先进行校验如权限等, 检验完成后返回文件的元数据
-
客户端创建一个输入流, 客户端会根据节点距离和节点负载选择节点, 并读取数据 这里的读是串行地读, 而非并发读
-
HDFS Java Api
基本操作
Hadoop的基本操作包括: 文件上传/文件下载/创建文件/删除文件这四个操作
java
package com.passnight.bigdata.hadoop;
import lombok.SneakyThrows;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.net.URI;
import java.util.Arrays;
public class HDFSManipulate {
@SneakyThrows
public static FileSystem connect() {
System.setProperty("hadoop.home.dir", "/usr/local/hadoop");
// 配置连接地址
Configuration conf = new Configuration();
// 连接NameNode; 注意用户权限
return FileSystem.get(new URI("hdfs://server.passnight.local:8020"), conf, "hadoop");
}
@SneakyThrows
public static void mkdir() {
FileSystem fs = connect();
fs.mkdirs(new Path("/test"));
fs.close();
}
// 上传文件
@SneakyThrows
public static void put() {
FileSystem fs = connect();
/*
* @param delSrc 是否删除源文件
* @param overwrite 是否覆写已存在的文件, 若为`true`, 目标路径不为空会抛异常; 否则覆写
* @param srcs 源文件
* @param dst 目标文件
* @throws IOException IO failure
*/
fs.copyFromLocalFile(false, true, new Path("bigdata/src/main/resources/word list.txt"), new Path("/test/word list.txt"));
fs.close();
}
// 下载文件
@SneakyThrows
public static void get() {
FileSystem fs = connect();
/*
* @param delSrc: 是否删除源文件
* @param src: 源文件路径
* @param dst: 目标地址路径
* @param useRawLocalFileSystem: 设置为`true`关闭本地校验
*/
fs.copyToLocalFile(false, new Path("/test/word list.txt"), new Path("bigdata/src/main/resources/word list from hdfs.txt"), true);
fs.close();
}
// 删除文件
@SneakyThrows
public static void rm() {
FileSystem fs = connect();
/*
* @param f 要删除的路径
* @param recursive 是否要递归删除; 为false时能够删除文件和空目录
*/
fs.delete(new Path("/test/word list.txt"), false);
fs.close();
}
@SneakyThrows
public static void read() {
FileSystem fs = connect();
// 打开文件并读取输出
Path hello = new Path("/test/word list.txt");
FSDataInputStream ins = fs.open(hello);
System.out.println("-".repeat(100));
System.out.println(new String(ins.readAllBytes()));
System.out.println("-".repeat(100));
fs.close();
}
// 移动文件
@SneakyThrows
public static void mv() {
FileSystem fs = connect();
// 若rename文件的路径, 则会对文件进行移动
fs.rename(new Path("/test/word list.txt"), new Path("/test/word list.new.txt"));
fs.close();
}
// 获取文件详细信息
@SneakyThrows
public static void describe() {
FileSystem fs = connect();
// 若rename文件的路径, 则会对文件进行移动
RemoteIterator<LocatedFileStatus> it = fs.listFiles(new Path("/"), true);
while (it.hasNext()) {
LocatedFileStatus fileStatus = it.next();
System.out.printf("=".repeat(100) + "%n%s%n", fileStatus);
System.out.println(Arrays.toString(fileStatus.getBlockLocations()));
// 也可以使用`listStatus`命令来查看状态
// System.out.println(Arrays.toString(fs.listStatus(fileStatus.getPath())));
}
System.out.println("=".repeat(100));
fs.close();
}
public static void main(String[] args) {
describe();
}
}HDFS架构
基本概念
- 存储介质的特点
- 内存:
- 优点
- 计算快
- 缺点
- 可靠性低
- 优点
- 磁盘
- 优点
- 可靠性高
- 缺点
- 性能低
- 优点
- 磁盘+内存
- 实现方式
- fsImage存储数据
- edits追加数据 因为HDFS对随机读写支持较差, 因此采用这种方式实现文件变更追踪
- 2NN定期将edits中的数据合并到fsimage中
- 实现方式
- 内存:
- HDFS中涉及到的概念
- edits: 存放HDFS文件系统所有跟新操作的路径, 文件系统的所有写操作都会先记录到Edits文件中
- fsimage: HDFS文件系统元数据的一个永久检查点 , 包含HDFS文件系统的所有目录和文件inode的序列化信息
- block: 实际存储数据的存储块
为了能够兼具磁盘的持久化和内存的高性能, Hadoop采用了磁盘+内存的实现方式
HDFS元数据写入流程
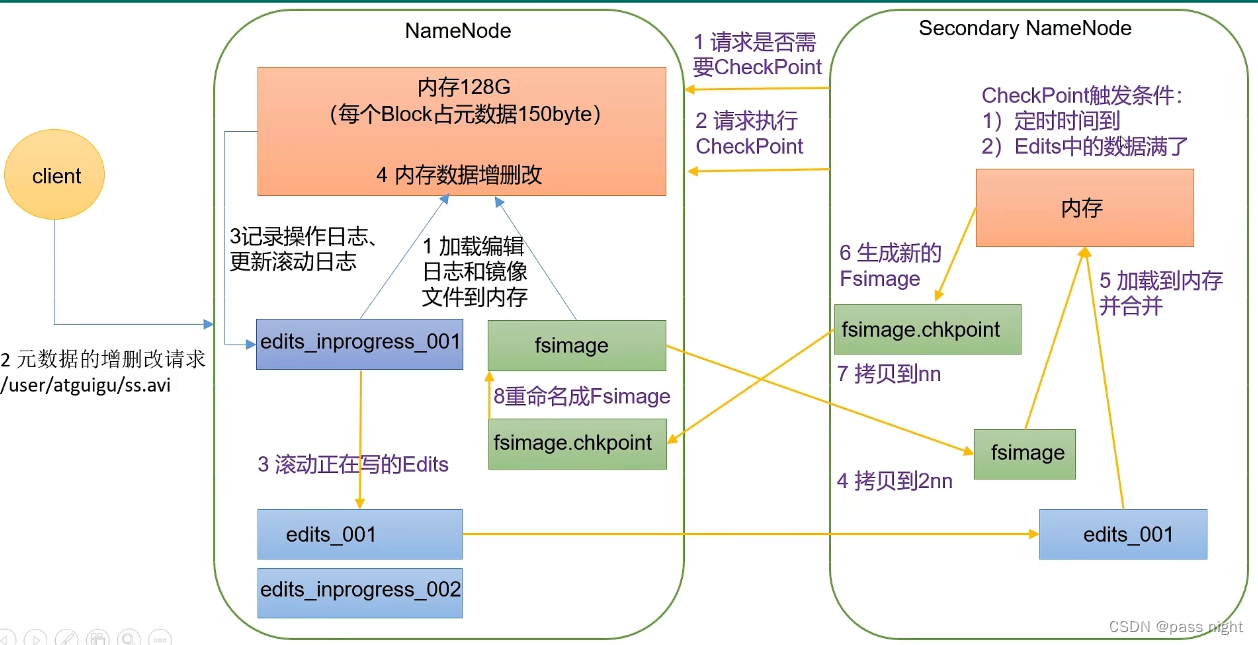
- NameNode启动, 加载edits和fsimage
- 加载完数据后, client就可以对数据进行访问; 即对数据的增删查改
- 若需要修改数据, NameNode会将修改的数据记录到
edits_inprogress中 edits_inprogress中的数据达到一定条件时, 会滚动生成新的edits_inprogress接受新请求, 并将其变为edits该条件由2nn负责, 当2nn生成一个CheckPoint, 则会出发当前操作; 对应上图生成一个新的edits_inprogress用以接受新请求以及一个edits用于生成镜像- 当
edits生成后, 2nn会将fsimage和edits都拷贝过来, 并在内存中合并; 生成新的Fsimage 这就是CheckPoint, - 之后将
fsimage.checkpoint拷贝到NameNode; 覆盖 原来的fsimage
Secondary NameNode工作机制
- 有上文可知, 2nn负责文件上传中实际写入到fsimage /生成check point 的工作主要通过定时轮询
- 每
dfs.namenode.checkpoint.period=3600s执行一次 - 每
dfs.namenode.checkpoint.check.period=60s检查一次, 操作数是否达到dfs.namenode.checkpoint.txns=1000000次, 达到则写入
- 每
Fsimage和edits
-
NameNode格式化之后, 会生成
fsimage; 它是HDFS文件系统元数据的永久检查点, 包括HDFS文件系统中所有的目录和文件inode的序列化信息- 可以通过
hdfs oiv查看, 它有三个参数-p 文件类型,-i 镜像文件,-o 输出路径 - 例如
hdfs oiv -p XML -i fsimage_001 -o output.xml, 之后就可以通过cat output.xml查看xml格式的文件元数据 例如文件的相对路径
- 可以通过
-
edits文件: 是存放HDFS文件系统中所有更新操作的路径, 文件系统客户端执行的所有写操作首先会被记录到edits文件中
- 可以通过
hdfs oev查看; 类似fsimage一样, 例如对文件的增删查改/rename等操作
- 可以通过
-
seen_txid文件保存的是一个数字, 即最后一个edits对应的数字
-
前两个文件都是二进制文件 , 但可以通过
hdfs导出为可阅读的格式
DataNode工作机制
当元数据完成写入后, 便可以正式开始数据写入
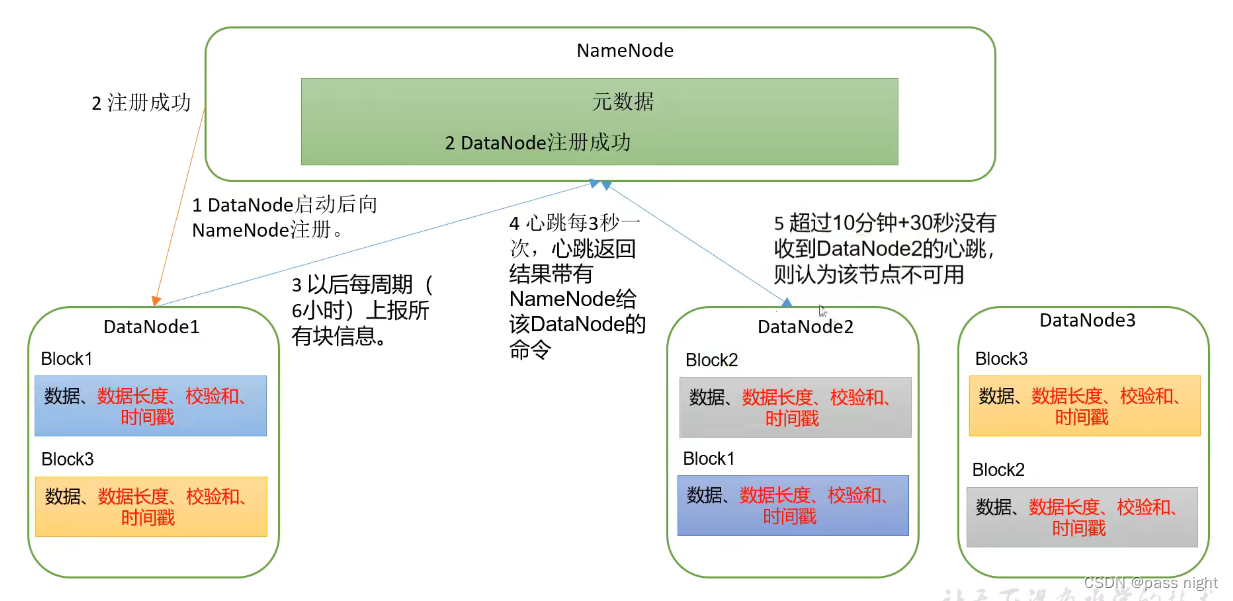
- DataNode在存储数据之外, 还会存储数据的元数据 如长度, 校验和, 时间戳等
- 当DataNode启动后, 会向NameNode注册, 并通知NameNode它存储的相关信息
- DataNode在启动之后, 会定期*
dfs.blockreport.intervalMsec=6h*, 会向NameNode上报所有块信息 - DataNode每一段时间后默认是3s , 会向NameNode发送心跳, 之后超过10分钟+30s后没有收到心跳才会认为该节点不可用
数据完整性
- 为了保证数据的完整性, Hadoop存在以下机制
- 传输/存储过程中添加校验位 如网络传输过程中添加奇偶/crc校验
- 为了保证系统的一致性, Hadoop会定期检测存活的节点
- NameNode没有接收到心跳的时候, 并不会马上判定节点死亡, 而是等待
TimeOut2*dfs.namenode.heartbeat.recheck-interval+10*dfs.heartbeat.interval=10min+30s后才将节点判定为死亡
- NameNode没有接收到心跳的时候, 并不会马上判定节点死亡, 而是等待
MapReduce
概述
- 定义:
- MapReduce是一个分布式运算程序 的编程框架, 是用户开发基于Hadoop的数据分析应用的核心框架
- MapReduce核心功能是将用户编写的业务逻辑代码 和自带默认组件 组合成一个完整的分布式运算程序, 并运行在一个Hadoop集群上
- 优点
- 易于编程: 用户无需再关系集群中的交互
- 良好的扩展性: MapReduce框架已经考虑了计算资源动态变化的情况
- 高容错性: 某台机器宕机, Hadoop会自动将任务转移到其他节点
- 高性能: 适合海量数据的计算
- 缺点
- 不擅长实时计算 即无法快速完成少量数据的计算
- 不擅长流式计算
- 不擅长DAG计算 即某个任务输出会作为后续任务的输入, 并形成DAG的情况
WordCount

- MapReduce分为三个部分:
Mapper: 用户定义的Mapper需要继承基类Mapper, 其输入/输出 数据时KV对形式; 每个mapper会被调用一次Reducer: 用户定义的Reducer也要继承基类Reducer, 其输入类型是Mapper的输出类型, 其形式也是KV对; ReduceTask会对每一组相同的k的<k,v>组调用一次reduce()方法 这样所有相同的token就会调用相同的reduceDriver: 启动类
下面是一个例子
java
package com.passnight.bigdata.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
/*
* Mapper 有四个泛型参数, 分别为
* KEYIN: LongWritable, 这里不关注, 因此为Object
* VALUEIN: Text, 输入value为文本, 即Text
* KEYOUT: IntWritable; Map阶段则会输出<文本, 1>这样的键值对, 即Key为IntWritable
* VALUEOUT: Text, Value为Text
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
// 为了优化性能, 将word提升到类作用域
private final Text word = new Text();
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString(); // 获取行
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) { // 使用`StringTokenizer`对分词
word.set(itr.nextToken());
context.write(word, one);
}
}
/*
* Reducer 也有四个泛型参数, 分别为
* KEYIN: 对应mapper的key输出
* VALUEIN: 对应mapper的value输出
* KEYOUT: 对应实际的输出, 这里是分词类型, 即Text
* VALUEOUT: 对应实际输出, 这里是词频, 即Long
*/
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, LongWritable> {
private final LongWritable result = new LongWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static class WordCountDriver {
public static void main(String[] args) throws Exception {
System.setProperty("hadoop.home.dir", "/usr/local/hadoop");
// 创建job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
// 设置jar包, 这里是通过设置jar包中的类反射获得jar包
job.setJarByClass(WordCount.class);
// 设置mapper
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入路径和输出路径
FileInputFormat.addInputPath(job, new Path("bigdata/src/main/resources/word list.txt"));
FileOutputFormat.setOutputPath(job, new Path("bigdata/src/main/resources/output"));
// 提交任务
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
}
}对于输入
txt
I love passnight
I like passnight
I love hadoop
I like hadoop会输出
txt
I 4
hadoop 2
like 2
love 2
passnight 2
Hadoop序列化
-
序列化: 将内存中的数据序列化到磁盘, 然后再进行传输
-
Hadoop的序列化相比于Java自带的序列化有以下好处:
- 校验信息/元数据较少, 因此消耗空间小, 传输速率快
- 支持多语言的互操作性
-
Hadoop中的序列化接口:
javapublic interface Writable { /** * Serialize the fields of this object to <code>out</code>. * * @param out <code>DataOuput</code> to serialize this object into. * @throws IOException */ void write(DataOutput out) throws IOException; /** * Deserialize the fields of this object from <code>in</code>. * * <p>For efficiency, implementations should attempt to re-use storage in the * existing object where possible.</p> * * @param in <code>DataInput</code> to deseriablize this object from. * @throws IOException */ void readFields(DataInput in) throws IOException; } -
添加自定义数据类型的方法:
- 实现
Writable接口 - 框架会调用无参构造函数, 因此一定要提供无参构造函数
- 注意: 序列化的顺序一定要和反序列化的顺序一致 即write(a), write(b); 则一定要对应read(a), read(b)
- 注意: 若要将结果显示在文件中, 需要重写
toString() - 倘若要将自定义的对象放在
key中传输, 还需要实现Comparable接口, 因为在mr框架中的Shuffle过程中会对key排序
- 实现
统计流量
对于输入格式为文本类型, 数据使用\t进行划分的数据, Hadoop不能直接读取, 而需要自定义序列化方法才能序列化, 这里会将其序列化为一FlowBean
部分数据为:
txt
14591430480 206.175.250.82 web-49.28.cn 6652 4853 200
14576404331 110.11.174.29 lt-91.duxu.cn 3691 9180 200
14582487728 21.234.130.14 desktop-19.13.cn 2797 1428 200下面用split对数据进行分隔, 然后使用parse序列化为java内置类型; 最后再set到对象中
为了可以更直观地看到输出的内容, 需要重写toString方法, 这里使用lombok所带的@Data自动生成因为total相关的setter无需传入参数, 因此自己定义一个覆盖lombok的实现
java
package com.passnight.bigdata.hadoop;
import lombok.Data;
import lombok.SneakyThrows;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Arrays;
/**
* 流量对应的java实体类
* 需要实现`Writable接口`
* 包含一个空参构造
* 并且还要重写`toString`; 以便观察输出
*/
@Data
class FlowBean implements Writable {
/**
* 上行流量
*/
private long up;
/**
* 下行流量
*/
private long down;
/**
* 总流量
*/
private long total;
public void setTotal() {
this.total = up + down;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(up);
dataOutput.writeLong(down);
dataOutput.writeLong(total);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
// 注意序列化的顺序一定要和反序列化的顺序一致
up = dataInput.readLong();
down = dataInput.readLong();
total = dataInput.readLong();
}
}
class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
final private Text phoneNumber = new Text();
final private FlowBean flowBean = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context) throws IOException, InterruptedException {
// 行模板:
// 0 13290352597 199.193.203.21 laptop-66.tang.com 2184 5477 500
String line = value.toString();
String[] split = line.split("\t");
System.out.println((Arrays.toString(split)));
phoneNumber.set(split[1]);
flowBean.setUp(Long.parseLong(split[split.length - 3]));
flowBean.setDown(Long.parseLong(split[split.length - 2]));
flowBean.setTotal();
context.write(new Text(phoneNumber), flowBean);
}
}
class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
final private FlowBean fb = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context) throws IOException, InterruptedException {
long totalUp = 0;
long totalDown = 0;
for (FlowBean flowBean : values) {
totalUp += flowBean.getUp();
totalDown += flowBean.getDown();
}
fb.setUp(totalUp);
fb.setDown(totalDown);
fb.setTotal();
context.write(key, fb);
}
}
public class FlowAnalyzer {
@SneakyThrows
public static void main(String[] args) {
System.setProperty("hadoop.home.dir", "/usr/local/hadoop");
// 创建job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "flow analyzer");
// 设置jar包, 这里是通过设置jar包中的类反射获得jar包
job.setJarByClass(FlowAnalyzer.class);
// 设置mapper
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 设置输入路径和输出路径
FileInputFormat.addInputPath(job, new Path("bigdata/src/main/resources/traffic.txt"));
FileOutputFormat.setOutputPath(job, new Path("bigdata/src/main/resources/output"));
// 提交任务
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}执行主任务, 可以看到数据成功被统计, 输出的格式与toString()所定义的一致; 下面是一个输出片段:
txt
10.60.145.193 FlowBean(up=6262, down=2760, total=9022)
102.158.159.187 FlowBean(up=8356, down=5491, total=13847)核心框架原理
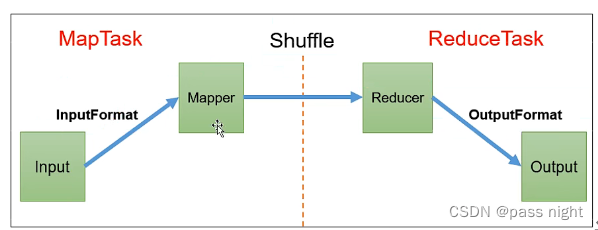
切片与MapTask并行度
-
问题: 任务的并行度与效率的关系 是并行度越高效率越高吗
-
基本概念:
- 数据块: 数据块是HDFS的存储数据的单位
- 数据切片: 数据切片只是逻辑上 对输入进行分片, 并不会在磁盘上将其切分成片进行存储. 数据切片是MapReduce程序输入数据 的单位, 一个切片会启动一个MapTask
- 如下图, 黄线代表了逻辑的数据切片, 而不同矩形代表了在物理机器上实际存储的块:
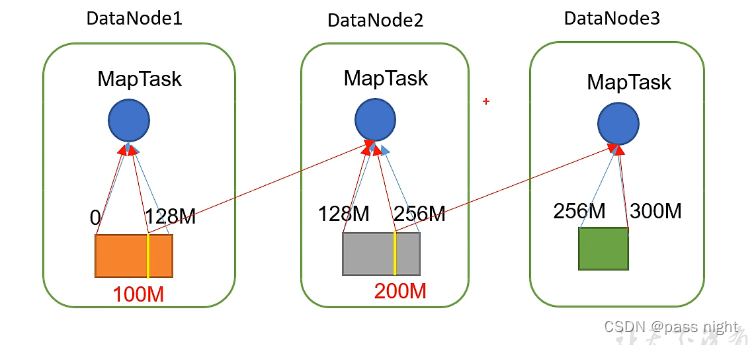
-
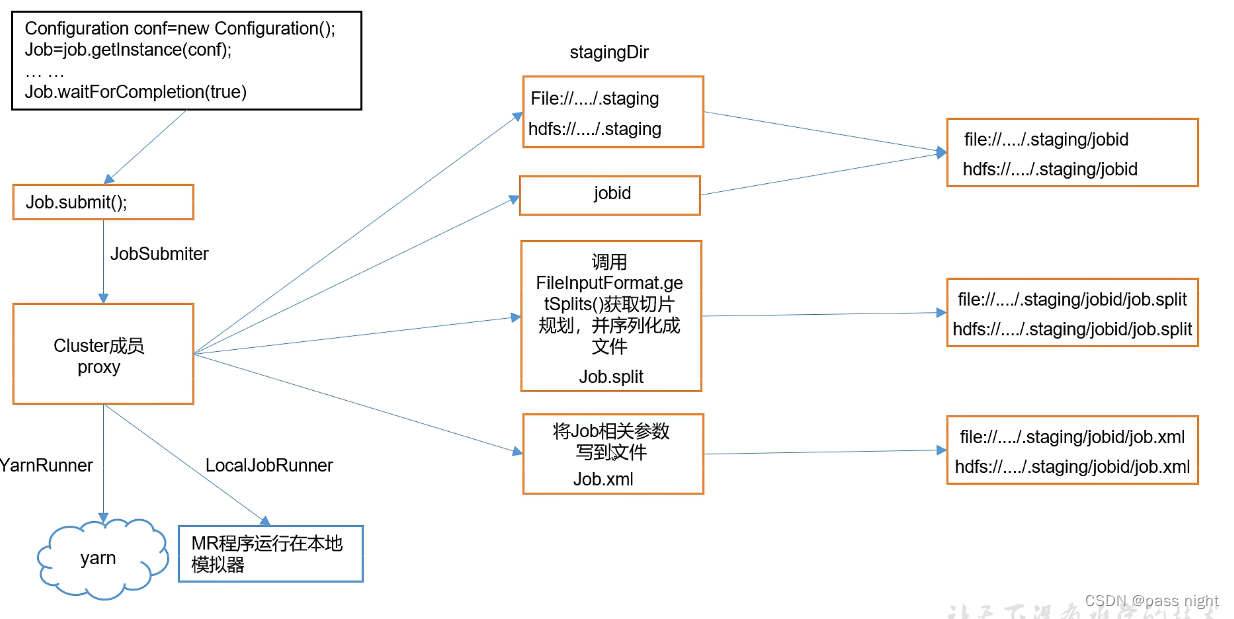
Job提交流程:
yarn
- yarn是一个资源调度平台 , 负责为运算程序提供服务器运算资源, 相当于一个分布式操作系统平带, 而MapReduce等运算程序则相当于运行在该操作系统上的程序
- Yarn包含的组件:
- Resource Mnager:
- 处理客户端请求
- 监控NodeManager
- 启动或监控ApplicationMaster
- 资源的分配和调度
- NodeManager:
- 管理单个节点上的资源
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
- ApplicationMaster
- 为应用程序申请资源并分配给内部的任务
- 任务的监控和容错
- Container
- Container是YARN中的资源抽象, 它封装了某个节点上多维度的资源 如CPU内存等
- Resource Mnager:
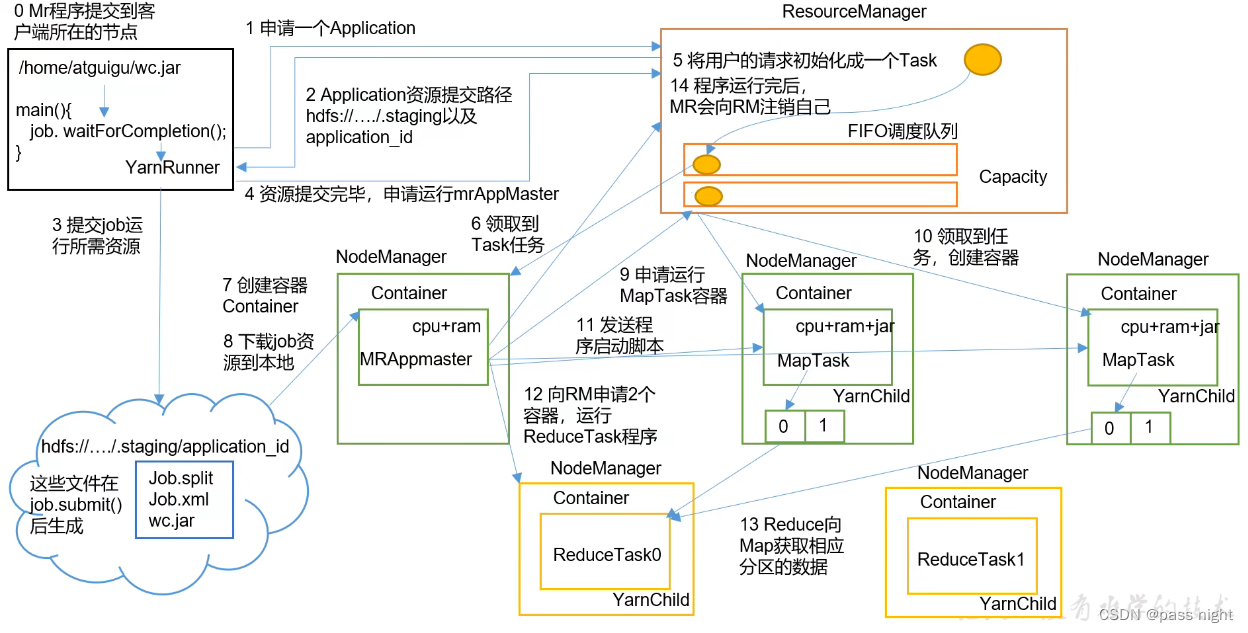
YARN的工作机制
Hadoop job创建流程:
- 客户端提交工作, 若是集群模式, 调用
waitForCompletion时会创建一个YarnRunner - 创建完成之后会向ResourceManager申请资源, 申请成功后会将资源配置保存到HDFS中, 此时ResourceManager会返回成功并创建一个Task
- Task会先被放入调度队列, NodeManager会根据自身的负载领取任务
- 领取到任务之后, NodeManager会创建一个MRAppMaster容器, 该容器会读取HDFS中的配置, 并根据配置向ResourceManager申请运行MapTask的任务
- 其他NodeManager在领取到任务之后, 由MRAppMaster控制其他NodeManager中MapTask的启动
- 计算完成之后, ApplicationMaster会再次向RM申请资源, 并创建容器运行ReduceTask
- 在任务执行完成之后, MR会向RM注销自己
Yarn 常用命令
bash
bash-4.2$ pwd
/opt/hadoop/share/hadoop/mapreduce
# 启动任务
bash-4.2$ hadoop jar hadoop-mapreduce-examples-3.3.1.jar wordcount "/test/word list.txt" /test/output
# 查看运行中的任务
bash-4.2$ yarn application -list
2023-10-30 13:52:54 INFO DefaultNoHARMFailoverProxyProvider:64 - Connecting to ResourceManager at server.passnight.local/192.168.100.3:8032
Total number of applications (application-types: [], states: [SUBMITTED, ACCEPTED, RUNNING] and tags: []):1
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1696500545514_0008 word count MAPREDUCE hadoop default RUNNING UNDEFINED 50% http://passnight-centerm:35377
# 查看已经完成的任务, 可以使用-appStates参数
bash-4.2$ yarn application -list -appStates finished
2023-10-30 13:54:54 INFO DefaultNoHARMFailoverProxyProvider:64 - Connecting to ResourceManager at server.passnight.local/192.168.100.3:8032
Total number of applications (application-types: [], states: [FINISHED] and tags: []):6
Application-Id Application-Name Application-Type User Queue
State Final-State Progress Tracking-URL
application_1696500545514_0005 word count MAPREDUCE hadoop default
FINISHED FAILED 100% http://passnight-centerm:19888/jobhistory/job/job_1696500545514_0005
# 终止某个任务
bash-4.2$ yarn application -kill application_1696500545514_0008
2023-10-30 13:56:49 INFO DefaultNoHARMFailoverProxyProvider:64 - Connecting to ResourceManager at server.passnight.local/192.168.100.3:8032
Killing application application_1696500545514_0008
2023-10-30 13:56:50 INFO YarnClientImpl:504 - Killed application application_1696500545514_0008
# 查看某个应用程序的日志
bash-4.2$ yarn logs -applicationId application_1696500545514_0008
# 查看Container的日志
bash-4.2$ yarn logs -applicationId application_1696500545514_0010 -containerId container_1696500545514_0010_01_000001
# 查看尝试运行的任务
bash-4.2$ yarn applicationattempt -list application_1696500545514_0010
2023-10-30 14:21:16 INFO DefaultNoHARMFailoverProxyProvider:64 - Connecting to ResourceManager at server.passnight.local/192.168.100.3:8032
Total number of application attempts :1
ApplicationAttempt-Id State AM-Container-Id Tracking-URL
appattempt_1696500545514_0010_000001 RUNNING container_1696500545514_0010_01_000001 http://server.passnight.local:8088/proxy/application_1696500545514_0010/
# 查看尝试任务的状态
bash-4.2$ yarn applicationattempt -status appattempt_1696500545514_0011_000001
2023-10-30 14:24:40 INFO DefaultNoHARMFailoverProxyProvider:64 - Connecting to ResourceManager at server.passnight.local/192.168.100.3:8032
Application Attempt Report :
ApplicationAttempt-Id : appattempt_1696500545514_0011_000001
State : RUNNING
AMContainer : container_1696500545514_0011_01_000001
Tracking-URL : http://server.passnight.local:8088/proxy/application_1696500545514_0011/
RPC Port : 38075
AM Host : passnight-acepc
Diagnostics :
容器相关命令
bash
# 查看容器信息
bash-4.2$ yarn container -list application_1696500545514_0013
2023-10-31 12:48:32 INFO DefaultNoHARMFailoverProxyProvider:64 - Connecting to ResourceManager at server.passnight.local/192.168.100.3:8032节点相关命令
bash
# 查看node节点状态
bash-4.2$ yarn node -list -all
2023-10-31 12:49:50 INFO DefaultNoHARMFailoverProxyProvider:64 - Connecting to ResourceManager at server.passnight.local/192.168.100.3:8032
Total Nodes:3
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
passnight-centerm:38637 RUNNING passnight-centerm:8042 1
localhost:33655 RUNNING localhost:8042 1
passnight-acepc:38149 RUNNING passnight-acepc:8042 0管理员命令
bash
# 刷新队列
bash-4.2$ yarn rmadmin -refreshQueues
2023-10-30 14:27:49 INFO DefaultNoHARMFailoverProxyProvider:64 - Connecting to ResourceManager at server.passnight.local/192.168.100.3:8033
# 查看队列信息
bash-4.2$ yarn queue -status default
2023-10-30 14:28:21 INFO DefaultNoHARMFailoverProxyProvider:64 - Connecting to ResourceManager at server.passnight.local/192.168.100.3:8032
Queue Information :
Queue Name : default
State : RUNNING
Capacity : 100.00%
Current Capacity : .00%
Maximum Capacity : 100.00%
Default Node Label expression : <DEFAULT_PARTITION>
Accessible Node Labels : *
Preemption : disabled
Intra-queue Preemption : disabledYARN调度算法
Hadoop的调度算法主要有三种: FIFO, 容量调度器默认 和公平调度器; 可以通过yarn.resourcemanager.scheduler.class配置
先进先出调度器
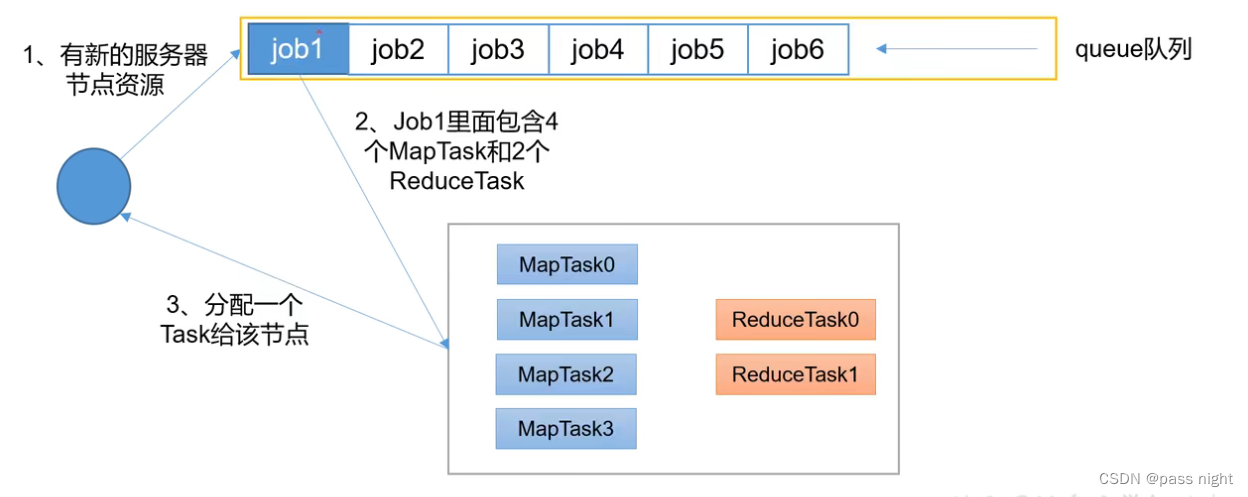
- 只有一个job队列, 调度器根据作业的提交顺序, 先来的先被调度
容量调度器
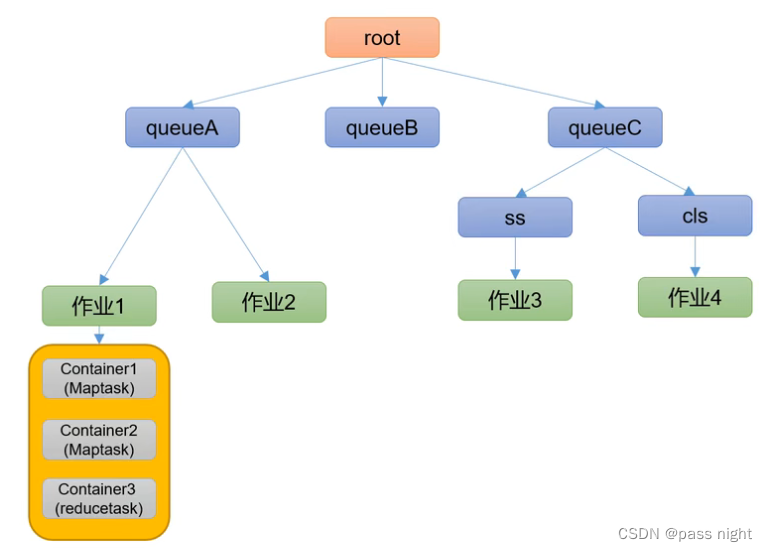
Capacity Scheduler是Yahoo开发的多用户调度器
- 特点
- 多队列: 每个队列可以配置一定的资源量, 每个队列采用FIFO调度策略
- 容量保证: 管理员可以为每个队列设置资源的最低保证和资源使用上限
- 灵活性: 若一个队列中的资源有剩余, 可以暂时共享给其他的队列, 而一旦该队列有任务提交, 则其他队列借调的资源会立即归还给该队列
- 多租户: 支持多用户共享集群和多应用程序同时运行, 为了防止同一个用户的作业独占队列的资源, 调度器会对同一用户提价的作业所占的资源总量进行限制
- 调度算法
- 从root开始dfs, 优先选择资源占用率最低的队列分配资源
- 之后根据作业的优先级 和提价时间分配容器资源
- 容器的资源尽量遵循数据本地性原则, 即任务和数据在同一节点/任务和数据在同一机架等
公平调度器
Fair Scheduler是Facebook开发的多用户调度器
- 特点: 公平调度器和容量调度器的特点非常相似
- 与容量调度器的相似点: 多队列/容量保证/灵活性/多租户
- 每个队列可以单独设置资源分配方式
- Fair调度算法默认算法 :
-
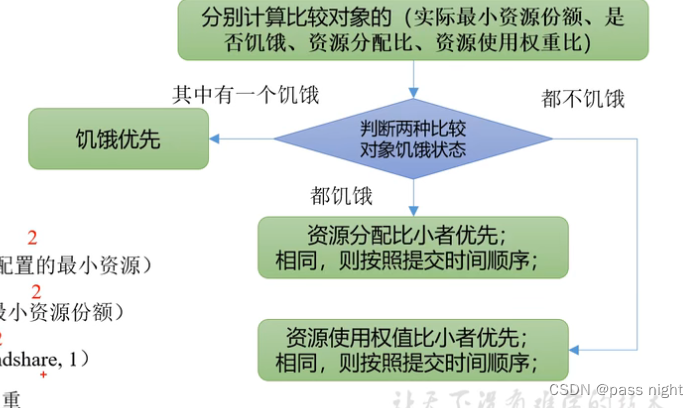
-
采用一种基于最大最小公平算法实现的资源多路复用方式, 一般情况下, 队列中的任务会分配到相同的资源
-
最小资源份额 = min ( 资源需求量 , 配置的最小资源 ) 最小资源份额=\min(资源需求量,配置的最小资源) 最小资源份额=min(资源需求量,配置的最小资源)
-
是否饥饿 = 资源使用量 < 最小资源份额 是否饥饿=资源使用量<最小资源份额 是否饥饿=资源使用量<最小资源份额
-
资源分配比 = 资源使用量 max ( 最小资源份额 , 1 ) 资源分配比=\frac{资源使用量}{\max(最小资源份额, 1)} 资源分配比=max(最小资源份额,1)资源使用量
-
资源使用权重比 = 资源使用量 权重 资源使用权重比=\frac{资源使用量}{权重} 资源使用权重比=权重资源使用量
-