文章目录
- [1. 数据集与框架介绍](#1. 数据集与框架介绍)
- [2. 任务详情](#2. 任务详情)
- [3. Cascade R-CNN简介](#3. Cascade R-CNN简介)
- [4. 数据分析](#4. 数据分析)
- [5. 相关配置](#5. 相关配置)
-
- 数据增强
- 数据集路径和评估指标
- 学习率和优化器配置
- [预训练CascadeRCNN 的配置](#预训练CascadeRCNN 的配置)
- 日志记录
- [6. 训练预测](#6. 训练预测)
- [7. 参考链接](#7. 参考链接)
1. 数据集与框架介绍
印刷电路板(PCB)瑕疵数据集:PCB疵数据集,是一个公共的合成PCB数据集,由北京大学发布,其中包含1386张图像以及6种缺陷(缺失孔,鼠咬伤,开路,短路,杂散,伪铜),用于检测、分类和配准任务。我们选取了其中适用于检测任务的693张图像,随机选择593张图像作为训练集,100张图像作为验证集。
PaddleDetection:飞桨推出的PaddleDetection是端到端目标检测开发套件,旨在帮助开发者更快更好地完成检测模型的训练、精度速度优化到部署全流程。该框架中提供了丰富的数据增强、网络组件、损失函数等模块,集成了模型压缩和跨平台高性能部署能力。
2. 任务详情
利用 Cascade R-CNN算法完成印刷电路板瑕疵检测。评估方法采用COCO数据集评分指标
3. Cascade R-CNN简介
R-CNN 和其变体通常用于需要高精度目标检测的应用,如自动驾驶、视频监控、图像识别等。
项目中使用的Cascade R-CNN算法 是在 Faster R-CNN 的基础上的进一步改进,它采用了级联结构。
级联结构由多个 R-CNN 检测器组成,每个检测器逐步细化候选区域和边界框。
每个检测器的输出作为下一个检测器的输入,这样可以提高检测精度,尤其是在小目标和复杂场景中。
Cascade R-CNN、R-CNN、Faster R-CNN和Fast R-CNN的主要特点和差异:
| 特征/算法 | R-CNN | Fast R-CNN | Faster R-CNN | Cascade R-CNN |
|---|---|---|---|---|
| 基础架构 | 选择性搜索 + CNN | 选择性搜索 + CNN + ROI池化 | RPN + CNN + ROI池化 | 级联的R-CNN/Fast R-CNN/Faster R-CNN |
| 候选区域生成 | 选择性搜索算法 | 选择性搜索算法 | 内置的RPN | 级联的候选区域细化 |
| 特征提取 | 对每个区域独立提取 | 对整个图像提取一次,共享特征 | 对整个图像提取一次,共享特征 | 多阶段特征提取和细化 |
| 分类器 | SVM | Softmax | Softmax | 级联的分类器 |
| 边界框回归 | 有 | 有 | 有 | 级联的边界框细化 |
| 速度 | 慢 | 较快 | 非常快 | 较慢(由于级联结构) |
| 精度 | 中等 | 高 | 高 | 最高(特别是对于小目标) |
| 计算资源 | 高 | 中等 | 中等 | 高(由于级联检测) |
| 适用场景 | 通用目标检测 | 通用目标检测 | 通用目标检测,实时应用 | 小目标检测,复杂场景 |
| 主要贡献 | 引入基于区域的CNN | 通过ROI池化提高速度 | 通过RPN实现端到端训练 | 通过级联结构提高检测精度 |
4. 数据分析
各类别样本的数量
python
import json
from collections import defaultdict
import matplotlib.pyplot as plt
%matplotlib inline
with open("/home/aistudio/work/PCB_DATASET/Annotations/train.json") as f:
data = json.load(f)
imgs = {}
for img in data['images']:
imgs[img['id']] = {
'h': img['height'],
'w': img['width'],
'area': img['height'] * img['width'],
}
hw_ratios = []
area_ratios = []
label_count = defaultdict(int)
for anno in data['annotations']:
hw_ratios.append(anno['bbox'][3]/anno['bbox'][2])
area_ratios.append(anno['area']/imgs[anno['image_id']]['area'])
label_count[anno['category_id']] += 1
label_count, len(data['annotations']) / len(data['images'])- 从标签来看,总共6个类别。
- 各类别之间的框数量相对较平均,不需要调整默认的损失函数。(如果类别之间相差较大,建议调整损失函数,如BalancedL1Loss)
- 平均每张图的框数量在4个左右,属于比较稀疏的检测,使用默认的keep_top_k即可。
真实框的宽高比
python
plt.hist(hw_ratios, bins=100, range=[0, 2])
plt.show()
目标框长宽比分布
可以看到大部分集中在1.0左右,但也有部分在0.5~1之间, 少部分在1.25~2.0之间。虽说anchor会进行回归得到更加准确的框,但是一开始给定一个相对靠近的anchor宽高比会让回归更加轻松
真实框在原图的大小比例
python
plt.hist(area_ratios, bins=100, range=[0, 0.005])
plt.show()这是真实框在原图的大小比例,可以看到大部分框只占到了原图的0.1%,甚至更小,因此基本都是很小的目标,这个也可以直接看一下原图和真实框就能发现。所以在初始的anchor_size设计时需要考虑到这一点,我这里anchor_size是从8开始的,也可以考虑从4开始,应该都可以的。
比如anchor_sizes可设置为:anchor_sizes: \[8,16,32, 64, 128]
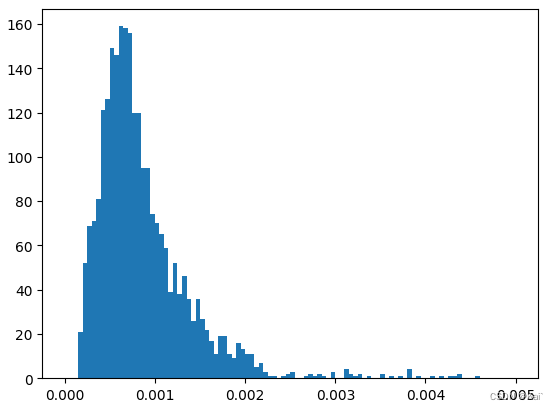
目标框占原图面积分布
5. 相关配置
数据增强
增强方式:RandomResize、RandomFlip、NormalizeImage
python
worker_num: 2 # 定义工作进程数,用于数据加载和处理
TrainReader: # 训练数据读取器配置
sample_transforms: # 数据样本转换操作列表
- Decode: {} # 解码图像
- RandomResize: # 随机调整图像大小
{target_size: [[640, 1333], [672, 1333], [704, 1333], [736, 1333], [768, 1333], [800, 1333]], interp: 2, keep_ratio: True}
- RandomFlip: {prob: 0.5} # 随机翻转图像,概率为0.5
- NormalizeImage: # 归一化图像
{is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {} # 调整数据维度顺序
batch_transforms: # 批量数据转换操作列表
- PadBatch: {pad_to_stride: 32} # 填充批次以满足特定stride
batch_size: 1 # 定义每个批次的样本数
shuffle: true # 是否在每个epoch开始时打乱数据
drop_last: true # 是否丢弃最后一个不完整的批次
collate_batch: false # 是否合并批次数据
EvalReader: # 评估数据读取器配置,与训练配置类似但通常不打乱数据
# 配置项与TrainReader相同,不再赘述
TestReader: # 测试数据读取器配置,通常用于模型推断
# 配置项与TrainReader相似,但可能不涉及数据增强操作,不再赘述数据集路径和评估指标
python
metric: COCO # 使用COCO数据集的评估指标进行模型性能评估
num_classes: 7 # 数据集中目标类别的总数
TrainDataset: # 训练数据集配置
!COCODataSet # 使用COCO数据集格式
image_dir: images # 训练图像存放的文件夹
anno_path: Annotations/train.json # 训练数据的注释文件路径
dataset_dir: /home/aistudio/work/PCB_DATASET # 数据集所在的根目录
data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd'] # 数据集中包含的字段列表
EvalDataset: # 评估数据集配置,使用COCO数据集格式
!COCODataSet
image_dir: images # 评估图像存放的文件夹
anno_path: Annotations/val.json # 评估数据的注释文件路径
dataset_dir: /home/aistudio/work/PCB_DATASET # 评估数据集所在的根目录
TestDataset: # 测试数据集配置
!ImageFolder # 使用ImageFolder数据集格式,适用于通用图像文件夹
anno_path: /home/aistudio/work/PCB_DATASET/Annotations/val.json # 测试数据的注释文件路径学习率和优化器配置
python
epoch: 12 # 训练过程中要执行的完整数据集遍历次数,即总的epoch数为12
LearningRate: # 学习率相关配置
base_lr: 0.01 # 初始学习率设置为0.01
schedulers: # 学习率调度器的配置列表,用于在训练过程中调整学习率
- !PiecewiseDecay # 使用分段衰减策略
gamma: 0.1 # 每次衰减因子为0.1
milestones: [8, 11] # 在epoch索引8和11处衰减学习率
- !LinearWarmup # 使用线性预热策略
start_factor: 0.001 # 预热开始时的学习率因子为0.001
steps: 1000 # 预热期的步数为1000
OptimizerBuilder: # 优化器构建器配置
optimizer: # 优化器的配置
momentum: 0.9 # 动量优化器的动量参数设置为0.9
type: Momentum # 优化器类型为Momentum(动量优化器)
regularizer: # 正则化器的配置
factor: 0.0001 # L2正则化因子设置为0.0001
type: L2 # 正则化类型为L2(欧几里得范数)预训练CascadeRCNN 的配置
python
architecture: CascadeRCNN # 模型的架构,这里是Cascade R-CNN
pretrain_weights: https://paddledet.bj.bcebos.com/models/pretrained/ResNet50_cos_pretrained.pdparams # 预训练模型权重的URL
CascadeRCNN:
backbone: ResNet # 模型的主干网络,这里是ResNet
neck: FPN # 特征融合网络,这里是FPN
rpn_head: RPNHead # 区域提议网络的头部,用于生成候选区域
bbox_head: CascadeHead # 边界框预测头部,这里是CascadeHead
# post process # 后处理配置的注释说明
bbox_post_process: BBoxPostProcess # 边界框后处理模块
ResNet:
depth: 50 # ResNet网络的深度,这里是50层
norm_type: bn # 归一化类型,这里使用Batch Normalization
freeze_at: 0 # 冻结网络中前N层的权重,这里是0层,即不冻结
return_idx: [0,1,2,3] # 返回的特征层索引
num_stages: 4 # ResNet网络的阶段数
FPN:
out_channel: 256 # FPN输出的特征通道数
RPNHead:
anchor_generator: # 锚点生成器配置
aspect_ratios: [0.5, 1.0, 2.0] # 锚点的纵横比
anchor_sizes: [[32], [64], [128], [256], [512]] # 锚点的大小
strides: [4, 8, 16, 32, 64] # 锚点在不同特征层上的步长
rpn_target_assign: # RPN目标分配配置
batch_size_per_im: 256 # 每个图像上的目标总数
fg_fraction: 0.5 # 正样本占目标总数的比例
negative_overlap: 0.3 # 负样本的IoU阈值
positive_overlap: 0.7 # 正样本的IoU阈值
use_random: True # 是否使用随机采样
train_proposal: # 训练时的候选区域生成配置
min_size: 0.0 # 最小候选区域的大小
nms_thresh: 0.7 # NMS的阈值
pre_nms_top_n: 2000 # NMS前保留的候选区域数量
post_nms_top_n: 2000 # NMS后保留的候选区域数量
topk_after_collect: True # 是否在收集后进行topk操作
test_proposal: # 测试时的候选区域生成配置,类似train_proposal
CascadeHead:
head: CascadeTwoFCHead # CascadeHead使用的头部网络,这里是CascadeTwoFCHead
roi_extractor: # ROI特征提取器配置
resolution: 7 # 特征图的分辨率
sampling_ratio: 0 # 采样比例
aligned: True # 是否对齐采样
bbox_assigner: BBoxAssigner # 边界框分配器
BBoxAssigner:
batch_size_per_im: 512 # 每个图像上的目标总数
bg_thresh: 0.5 # 背景样本的IoU阈值
fg_thresh: 0.5 # 前景样本的IoU阈值
fg_fraction: 0.25 # 前景样本占目标总数的比例
cascade_iou: [0.5, 0.6, 0.7] # Cascade R-CNN中不同阶段的IoU阈值
use_random: True # 是否使用随机采样
CascadeTwoFCHead:
out_channel: 1024 # CascadeTwoFCHead的输出通道数
BBoxPostProcess:
decode: # 边界框解码配置
name: RCNNBox # 解码器名称
prior_box_var: [30.0, 30.0, 15.0, 15.0] # 锚点框的先验方差
nms: # 非极大值抑制配置
name: MultiClassNMS # NMS名称
keep_top_k: 100 # 保留的边界框数量
score_threshold: 0.05 # 边界框的得分阈值
nms_threshold: 0.5 # NMS的阈值日志记录
python
use_gpu: true # 是否使用GPU进行训练,设置为true表示使用GPU
log_iter: 20 # 训练过程中每多少个迭代记录一次日志信息
save_dir: output # 模型保存的目录
snapshot_epoch: 1 # 每多少个epoch保存一次模型快照6. 训练预测
V100 16G训练593张图片40min完毕,最后一轮的效果如下:

模型在IoU阈值为0.50时表现非常好,但在更严格的IoU阈值和大型对象上表现有所下降。模型的召回率随着考虑的检测数增加而提高,但仍然有改进的空间,特别是在只选择一个最佳预测时。
如果在linux系统训练时,可每隔一秒查看gpu使用状况:
watch -n 1 nvidia-smi
最后选择一张PCB图片预测:
python -u ./tools/infer.py -c yaml配置文件 -infer_img=图片路径 -o weights=最好模型路径 use_gpu=true
预测效果:

7. 参考链接
casacde rcnn算法参考文章:
https://segmentfault.com/a/1190000022160962