文章目录
-
- [OpenAI 访问权限和 API 密钥](#OpenAI 访问权限和 API 密钥)
- [Hello World 示例程序](#Hello World 示例程序)
- [使用 GPT-4 和 ChatGPT](#使用 GPT-4 和 ChatGPT)
- [ChatCompletion 端点的输入选项](#ChatCompletion 端点的输入选项)
- [ChatCompletion 端点的输出格式](#ChatCompletion 端点的输出格式)
OpenAI 将 GPT-4 和 ChatGPT 作为服务提供。这意味着用户无法直接访问模型代码,也无法在自己的服务器上运行这些模型。OpenAI 负责部署和运行其模型,只要用户拥有 OpenAI 账户和 API 密钥,就可以调用这些模型。在执行以下步骤之前,请确保你已登录 OpenAI 账户。
OpenAI 访问权限和 API 密钥
OpenAI 要求你必须拥有 API 密钥才能使用其服务。此密钥有两个用途:它赋予你调用 API 方法的权利;它将你的 API 调用与你的账户关联,用于计费。你必须拥有此密钥才能在应用程序中调用 OpenAI 服务。要获取密钥,请访问 OpenAI 的平台页面。单击页面右上角的账户名,然后选择"View API keys"(查看 API 密钥),如上图所示。
 在 OpenAI 菜单中选择查看 API 密钥
在 OpenAI 菜单中选择查看 API 密钥
进⼊ API 密钥页面后,请单击"Create new secret key"(创建新密钥)并复制密钥。该密钥是以 sk- 开头的⼀⻓串字符。请妥善保管密钥,因为它直接与你的账户相关联。如果密钥丢失,可能会导致不必要的费用。⼀旦获得了密钥,最好将其导出为环境变量。这样⼀来,你的应用程序就能够在不直接将密钥写如代码的情况下使用它。以下说明具体如何做。对于 Linux 或 macOS:
bash
# 设置当前会话的环境变量 OPENAI_API_KEY
export OPENAI_API_KEY=sk-(...)
# 检查是否设置了环境变量
echo $OPENAI_API_KEY对于 Windows:
bash
# 设置当前会话的环境变量 OPENAI_API_KEY
set OPENAI_API_KEY=sk-(...)
# 检查是否设置了环境变量
echo %OPENAI_API_KEY%以上代码片段将设置⼀个环境变量,并使密钥对从同⼀ shell 会话启动的其他进程可用。Linux 用户还可以直接将这段代码添加到 .bashrc 文件中。这将允许在所有的 shell 会话中访问该环境变量。当然,请勿在要推送到公共代码仓库的代码中包含这些命令行。要在 Windows 11 中永久添加或更改环境变量,请同时按下 Windows 键和 R键,以打开运行窗口。在此窗口中,键入 sysdm.cpl 以打开"系统属性"面板。单击"高级"选项卡,接着单击"环境变量"按钮。在出现的窗口中,你可以使用 OpenAI 密钥添加⼀个新的环境变量。OpenAI 提供了关于 API 密钥安全的详细页面,详见其网站上的"Best Practices for API Key Safety"。现在你已经有了密钥,是时候用 OpenAI API 编写第⼀个 Hello World 示例程序了。
Hello World 示例程序
本节展示如何使用 OpenAI Python 库开始编写代码。我们从经典的 HelloWorld 示例程序开始,以了解 OpenAI 如何提供服务。使用 pip 安装 Python 库:
bash
pip install openai接下来,在 Python 中访问 OpenAI API:
bash
import openai
# 调用 OpenAI 的 ChatCompletion 端点
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Hello World!"}],
)
# 提取响应
print(response["choices"][0]["message"]["content"])你将看到以下输出:
bash
Hello there! How may I assist you today?恭喜!你刚刚使用 OpenAI Python 库编写了第⼀个程序。让我们来详细了解如何使用这个库。OpenAI Python 库还提供了⼀个命令行实用程序。在终端中运行以下代码的效果与执行之前的 Hello World 示例程序相同:
bash
openai api chat_completions.create -m gpt-3.5-turbo -g user "Hello world"还可以通过 HTTP 请求或官方的 Node.js 库与 OpenAI API 进行交互。此外,还有⼀些由 OpenAI 社区维护的库可用。你可能已经注意到,以上代码片段并没有明确提到 OpenAI API 密钥。这是因为,OpenAI Python 库会自动查找名为 OPENAI_API_KEY 的环境变量。或者,你可以使用以下代码将 openai 模块指向包含密钥的文件:
bash
# 从文件加载 API 密钥
openai.api_key_path = <PATH>你还可以使用以下方法在代码中⼿动设置 API 密钥:
bash
# 加载 API 密钥
openai.api_key = os.getenv("OPENAI_API_KEY")建议遵循环境变量使用惯例:将密钥存储在⼀个 .env 文件中,并在.gitignore 文件中将其从源代码控制中移除。在 Python 中,你可以运行load_dotenv 函数来加载环境变量并导入 openai 库:
bash
from dotenv import load_dotenv
load_dotenv()
import openai在加载 .env 文件后声明导入 openai 库,这样做很重要,不然无法正确应用OpenAI 的设置。
使用 GPT-4 和 ChatGPT
GPT-3.5 Turbo 是最便宜且功能最多的模型。因此,它也是⼤多数用例的最佳选择 。截至 2023 年 11 月下旬,OpenAI 已经推出了 GPT-4 Turbo 和 GPT-4 Vision。前者的上下文窗口大小是 GPT-3.5 Turbo 的 30 倍以上,并下调了整体价格,后者新增了图像理解能力。请根据具体用例需求选择合适的模型。以下是使用示例:
bash
import openai
# 对 GPT-3.5 Turbo 来说,端点是 ChatCompletion
openai.ChatCompletion.create(
# 对 GPT-3.5 Turbo 来说,模型是 gpt-3.5-turbo
model="gpt-3.5-turbo",
# 消息列表形式的对话
messages=[
{"role": "system", "content": "You are a helpful teacher."},
{"role": "user","content": "Are there other measures than time complexity for an algorithm?",
},
{"role": "assistant","content": "Yes, there are other measures besides time complexity for an algorithm, such as space complexity.",
},
{"role": "user", "content": "What is it?"},
],
)在前面的例子中,我们使用了最少数量的参数,即用于预测的 LLM 和输入消息。正如你所见,输入消息中的对话格式允许模型进行多轮对话。请注意,API 不会在其上下文中存储先前的消息。问题"What is it?"问的是先前的回答,这只有在模型知道答案的情况下才有意义。每次模拟聊天会话时,都必须发送整段对话。GPT-3.5 Turbo 模型和 GPT-4 模型针对聊天会话进行了优化,但这并非强制要求。这两个模型可用于多轮对话和单轮任务。如果你在提示词中请求模型补全文本,那么它们也可以很好地完成传统的文本补全任务。GPT-4 和 ChatGPT 都使用端点 openai.ChatCompletion。开发人员可以通过更改模型 ID 来在 GPT-3.5 Turbo 和 GPT-4 之间切换,而无须修改其他代码。
ChatCompletion 端点的输入选项
让我们更详细地看⼀下如何使用 ChatCompletion 端点及其 create 方法。create 方法让用户能够调用 OpenAI 的模型。当然,还有其他方法可用,但它们对与模型的交互没有帮助。你可以在 OpenAI Python库的 GitHub 代码仓库中查看代码。ChatCompletion 端点及其 create 方法有多个输入参数,但只有两个是必需的,如下表所示。对话以可选的系统消息开始,然后是交替出现的用户消息和助⼿消息。系统消息帮助设置助⼿的行为。用户消息相当于是用户在 ChatGPT 网页界面中键入的问题或句子。它既可以由应用程序的用户生成,也可以作为指令设置。
 必需的输入参数
必需的输入参数
助⼿消息有两个作用:要么存储先前的回复以继续对话,要么设置为指令,以提供所需行为的示例。由于模型没有任何关于历史请求的"记忆",因此存储先前的消息对于给出对话上下文和提供所有相关信息是必要的。如前所述,对话的总长度与标记的总数相关。这将影响以下方面。成本:定价基于标记计算。时间:标记越多,响应所需的时间就越长------最长可能需要几分钟。模型是否工作:标记总数必须小于模型的上限。所以有必要小心控制对话的长度。你可以通过管理消息的长度来控制输入标记的数量,并通过 max_tokens 参数来控制输出标记的数量。OpenAI 提供了⼀个名为 tiktoken 的库,让开发人员能够计算文本字符串中的标记数。所以强烈建议在调用端点之前使用此库来估算成本。OpenAI 提供了其他几个选项来微调用户与库的交互方式。如下表所示:
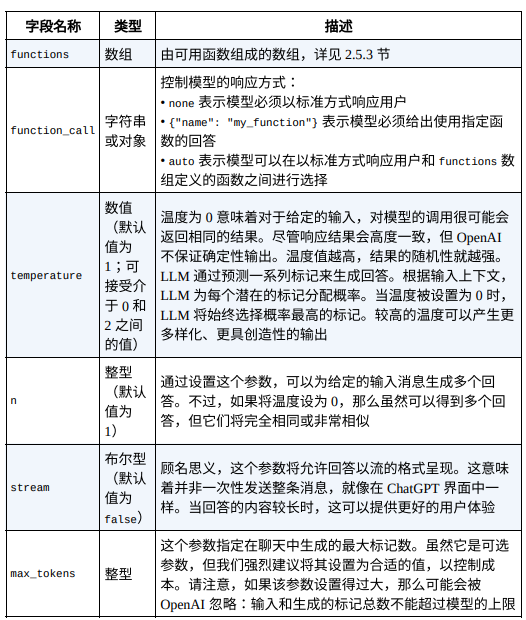 ⼀些可选参数
⼀些可选参数
可以在 OpenAI 的文档中找到更多详细信息。截至 2023 年 11 月下旬,ChatCompletion 的可用模型包括 gpt-3.5-turbo、gpt-3.5-turbo-0301、gpt-3.5-turbo-0613、gpt-3.5-turbo-1106、gpt-3.5-turbo-16k、gpt-3.5-turbo-16k-0613。截至 2023 年 11 月下旬,ChatCompletion 可选参数已更新,其中 functions 和function_call 已被弃用;新增了 tools、response_format、seed 等参数。请以最新的OpenAI 文档为准。
ChatCompletion 端点的输出格式
以下是 Hello World 示例程序的完整响应:
bash
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "Hello there! How may I assist you today?",
"role": "assistant",
},
}
],
"created": 1681134595,
"id": "chatcmpl-73mC3tbOlMNHGci3gyy9nAxIP2vsU",
"model": "gpt-3.5-turbo",
"object": "chat.completion",
"usage": {"completion_tokens": 10, "prompt_tokens": 11,
"total_tokens": 21},
} 上表列出了生成的输出。截至 2023 年 11 月下旬,ChatCompletion 输出参数已更新,新增了 system_fingerprint等参数。请以最新的 OpenAI 文档为准。
 模型的输出描述
模型的输出描述
如果将参数 n 设置为大于 1,那么你会发现 prompt_tokens 的值不会改变,但 completion_tokens 的值将大致变为原来的 n 倍。
OpenAI 使其模型可以输出⼀个包含函数调用参数的 JSON 对象。模型本身无法调用该函数,但可以将文本输入转换为可由调用者以编程方式执行的输出格式。在 OpenAI API 调用结果需要由代码的其余部分处理时,这个功能特别有用:你可以使用函数定义将自然语言转换为 API 调用或数据库查询,从文本中提取结构化数据,并通过调用外部工具来创建聊天机器人,而无须创建复杂的提示词以确保模型以特定的格式回答可以由代码解析的问题。函数定义需要作为函数对象数组传递。下表列出了函数对象的详细信息。截至 2023 年 11 月下旬,functions 和 function_call 已被弃用,取而代之的是 tools 和tool_choice。关于函数对象的详细参数,请以最新的 OpenAI 文档为准。
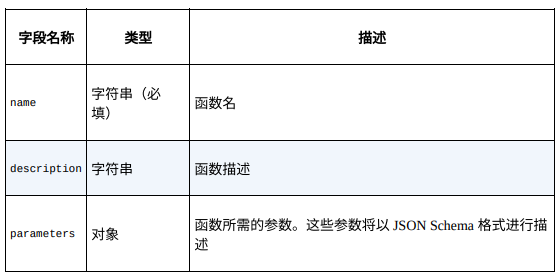 函数对象的详细信息
函数对象的详细信息
看⼀个例子。假设我们有⼀个包含公司产品相关信息的数据库。我们可以定义⼀个函数来执行对这个数据库的搜索:
bash
# ⽰例函数
def find_product(sql_query):
# 执⾏查询
results = [
{"name": "pen", "color": "blue", "price": 1.99},
{"name": "pen", "color": "red", "price": 1.78},
]
return results接下来定义函数的规范:
bash
# 函数定义
functions = [
{
"name": "find_product",
"description": "Get a list of products from a sql query",
"parameters": {
"type": "object",
"properties": {
"sql_query": {
"type": "string",
"description": "A SQL query",
}
},
"required": ["sql_query"],
},
}
]我们可以创建⼀个对话,并调用 ChatCompletion 端点:
bash
# 示例问题
user_question = "I need the top 2 products where the price is less
than 2.00"
messages = [{"role": "user", "content": user_question}]
# 使用函数定义调用 ChatCompletion 端点
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613", messages=messages,
functions=functions
)
response_message = response["choices"][0]["message"]
messages.append(response_message)我们使用该模型创建了⼀个查询。如果打印 function_call 对象,会得到如下结果:
bash
"function_call": {
"name": "find_product",
"arguments": '{\n "sql_query": "SELECT * FROM products WHERE price < 2.00 ORDER BY price ASC LIMIT 2"\n}',
}接下来,我们执行该函数并继续对话:
bash
# 调用函数
function_args = json.loads(
response_message["function_call"]["arguments"]
)
products = find_product(function_args.get("sql_query"))
# 将函数的响应附加到消息中
messages.append(
{
"role": "function",
"name": function_name,
"content": json.dumps(products),
}
)
# 将函数的响应格式化为⾃然语⾔
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=messages,
)最后,提取最终的响应并得到以下内容:
bash
The top 2 products where the price is less than $2.00 are:
1. Pen (Blue) - Price: $1.99
2. Pen (Red) - Price: $1.78