本文致力于提供一种解决图论中所有(或绝大部分)有向图、无向图、非负加权图的单源最短路径问题的通用程序模板,本文提供的模板并不是简单的可行模板,而是经过深入分析解释的一个较高质量和性能的通用程序模版。在每个关键变量存储的数据结构选择上都进行了深入的思考和解释,使得该方面基础较差的小伙伴,依然可以轻松的看懂。最核心的寻路部分封装成函数方便调用。
记:我之前写的路径规划相关的程序基本上都是基于连续空间或者栅格地图的,没有对基于拓扑结构图的寻路算法的实现进行过深入分析,正好借助本文,动手从零开始边实现边分析,实现拓扑结构图下单源最短路径的通用模板设计。
一、解决有向图、无向图、非负加权图单源最短路径问题的通用模板程序
1、读取给定输入数据,并构建搜索图grid
一般来说给定数据的第一行是图的顶点个数n和边数m,对应的顶点编号为1~n,如果默认起点为编号为1,终点编号为n,那么接下来一般会再给定m行,对于非加权图,边的权重一般默认为1,每行仅包含两个数据即每条边的两个顶点,对于加权图,每行一般有3个数据,前两个是边的两个顶点,第三个是边的权重。对于指定起点和目标点的题目,一般在m行边后面,还会给出一行数据,即给定指定的起点和目标点。
思考1:那么选择什么数据结构来存储给定的拓扑图?
在图论的应用中,C++中常用的图表示方法主要有邻接矩阵(Adjacency Matrix)和邻接表(Adjacency List)。它们各有优缺点,适用于不同的场景。下面对它们展开介绍并对比:
(1)邻接矩阵(Adjacency Matrix)
邻接矩阵是一种使用二维数组表示图的方法。对于一个有 n个顶点的图,需要建立一个n x n的矩阵,例如矩阵A。矩阵中的元素表示顶点之间的连接关系:
如果顶点 ( i ) 和顶点 ( j ) 之间有边存在,对于有向图而言,则矩阵元素 ( Aij ) 的值为 1,对于无向图而言,则矩阵元素 ( Aij )和( Aji )的值都为 1(对于无向图),对于加权图而言,只需要将1改为相应的权重值即可; 如果顶点 ( i ) 和顶点 ( j ) 之间没有边存在,则值一般为 0。下图是一个简单的有向加权图的示例:

优点: 邻接矩阵的优点是实现和理解起来比较简单,并且可以快速的访问判断两个顶点是否相邻,时间复杂度为 ( O ( 1 ) O(1) O(1) )。适用于较为密集的图,当图中的边数接近顶点数的平方时,邻接矩阵的存储效率较高。
缺点: 邻接矩阵的空间复杂度高:需要 ( O ( n 2 ) O(n^2 ) O(n2) ) 的存储空间,对于稀疏图而言,显得非常浪费。且邻接矩阵的遍历效率低,在寻找当前顶点的邻接点时需要遍历一遍所有的顶点,时间复杂度为 ( O ( n ) O(n) O(n) ) 。
(2)邻接表(Adjacency List)
邻接表是一种使用链表或动态数组(如 C++ 中的 vector)表示图的方法。对于每个顶点,建立一个链表或动态数组,链表中的元素表示与该顶点相邻的顶点,当然,对于加权图还需要存储边的权重。
优点:采用邻接表可以节省空间,对于稀疏图,只存储实际存在的边,空间复杂度为 ( O(n + e) ),其中 ( e ) 是图中的边数。这种优势使得邻接表的适应范围更广,鲁棒性更好。此外,邻接表的遍历效率高,遍历一个顶点的所有邻接点只需要 ( O ( degree ( v ) ) O(\text{degree}(v)) O(degree(v)) ) 的时间复杂度,其中 ( degree ( v ) \text{degree}(v) degree(v) ) 是顶点的度数,或者说是邻接点的个数。
缺点:邻接表的缺点是访问效率低,即判断两个顶点是否相邻的时间复杂度为 O ( degree ( v ) ) O(\text{degree}(v)) O(degree(v)) ) ,即需要遍历一遍当前顶点的所有邻接点来判断是否与某个顶点相邻。此外,相比于使用数组的邻接矩阵,邻接表实现起来相对复杂。
☆ 注:邻接表的构建示例和示意图将在下文中思考2部分进行介绍 ↓↓↓
--
(3)邻接矩阵与邻接表的对比总结
--
| 特性 | 邻接矩阵 | 邻接表 |
|---|---|---|
| 存储空间 | O ( n 2 ) O(n^2) O(n2) | O ( n + e ) O(n + e) O(n+e) |
| 邻接性查询 | O ( 1 ) O(1) O(1) | O ( degree ( v ) ) O(\text{degree}(v)) O(degree(v)) |
| 遍历顶点邻接点 | O ( n ) O(n) O(n) | O ( degree ( v ) ) O(\text{degree}(v)) O(degree(v)) |
| 适用场景 | 边较密集的图 | 边较稀疏的图、各种特殊结构图 |
| 实现复杂度 | 简单 | 相对复杂 |
有了以上基础,现在我们回到思考1,选择邻接矩阵还是邻接表来存储图? 其实都可以,可以根据实际情况进行选择,本文致力于提供一种解决图论中所有(或绝大部分)有向图、无向图、加权图的单源最短路径问题的通用程序模板,因此,在本文中将选取适应范围更广,适应性更强的邻接表来存储给定的图。
思考2:用什么实现邻接表?
在上面思考1的邻接表部分中,我们提到了可以采用链表或者动态数组来实现邻接表,同样,我们先简单介绍一下这两种结构
(4)动态数组(Dynamic Array)
动态数组在内存中占据一块连续的内存区域。由于其连续存储特性,可以通过索引快速访问任意元素,时间复杂度为 ( O ( 1 ) O(1) O(1) )。当数组容量不足时,会分配更大的内存块并将元素复制到新的内存块中,这个过程的时间复杂度为 ( O ( n ) O(n) O(n) ),但摊销后的插入时间复杂度仍为 ( O ( 1 ) O(1) O(1) )。动态数组的插入和删除效率较低,例如在中间位置插入或删除元素时,需要移动大量元素,时间复杂度为 ( O ( n ) O(n) O(n) )。
(5)链表(Linked List)
链表常采用非连续内存存储,链表中的每个元素称为节点,每个节点包含数据和指向下一个节点的指针。节点在内存中可以是非连续的。由于链表节点的非连续性,访问任意节点都行需要从头开始遍历,时间复杂度为 ( O ( n ) O(n) O(n) )。链表可以进行高效的插入和删除,在已知位置的插入和删除操作不需要移动其他元素,只需调整指针,时间复杂度为 ( O ( 1 ) O(1) O(1) )。此外,与动态数组相比,链表的内存开销大,每个节点除了存储数据外,还需要存储指针,因此内存开销比动态数组大。
(6)动态数组和链表的对比总结
--
| 特性 | 动态数组(Dynamic Array) | 链表(Linked List) |
|---|---|---|
| 内存布局 | 连续 | 非连续 |
| 随机访问 | 快速, O ( 1 ) O(1) O(1) | 慢, O ( n ) O(n) O(n) |
| 插入和删除 | 慢, O ( n ) O(n) O(n) | 快, O ( 1 ) O(1) O(1) |
| 内存开销 | 较小 | 较大 |
| 适用场景 | 需要频繁随机访问的场景 | 需要频繁插入和删除的场景 |
--
有了以上基础,现在我们回到思考2,先考虑最外层的数据结构用什么,即1-n个节点用链表还是用动态数组来存储?,为了方便的通过索引来直接的访问每个节点,很显然动态数组更加合适,例如vector容器,数据个数n是确定的,且不会发生改变,完全不必担心频繁修改的情况下性能较差的问题。
内层的数据结构用什么? 我们在读取边的数据的过程中是无法确定每个节点对应的边有多少的,也就无法为每个顶点预先分配存储其邻接点的空间大小,如果使用动态数组,如vector,必然涉及到动态扩展大小的问题。那是否要采用链表呢, 其实也不一定要用链表,因为虽然采用动态数组,如vector,在构建图的时候效率不如链表list,但是在后续对图进行访问来寻找路径的时候,效率是高于链表的。这里原则上,用动态数组或者链表都行,如采用如下的两种结构都行
cpp
vector<vector<pair<int, int>>> //外层和内层用动态数组vector
vector<list<pair<int, int>>> //外层用动态数组vector,内层使用链表list至于到底选哪个,就看具体情况和个人感觉了,我的想法是如果给定的图是静态的,即在寻找路径的过程中图不会发生改变,那么可以简单的认为频繁的访问图时高效的优势,远高于构建图过程中的劣势,内层依然选择动态数组。如果给定的图是动态的,即在寻找路径的过程中图会频繁的发生改变,那么此时内层选择链表更合适一些。
鉴于大部分题目给定的图都是静态的,因此,本文选择vector<vector<pair<int, int>>>来实现邻接表,至于,为什么内层vector存储的是pair<int, int>,而不是int,是因为本文致力于提供一种解决图论中所有(或绝大部分)有向图、无向图、加权图的单源最短路径问题的通用程序模板,对于加权图而言,除了存储邻居节点,还需要存储权值,即用pair<int, int>的第一个元素来存储邻居节点索引,第二个元素来存储权值,对于非加权图,第二个元素存储1即可。下图给出了一个加权有向图的示例

--
到这里,第1步读取给定输入数据,并构建搜索图grid的相关内容基本上就介绍完了,考虑到大家对C++算法与数据结构的了解程度可能差异较大,我花了大量的篇幅来详细的介绍和解释本文部分内容,现在给出对应的C++程序示例。
第1部分 C++程序示例
示例(1):有向加权图,默认起点为顶点1,终点为顶点n
示例真题链接:https://kamacoder.com/problempage.php?pid=1047
输入示例:
cpp
7 9
1 2 1
1 3 4
2 3 2
2 4 5
3 4 2
4 5 3
2 6 4
5 7 4
6 7 9读取给定输入数据,并构建搜索图grid的程序:
cpp
// 读取输入数据,并构建搜索图grid
int n, m, p1, p2, val;
cin >> n >> m;
vector<vector<pair<int, int>>> grid(n + 1);
for (int i = 0; i < m; i++) {
cin >> p1 >> p2 >> val;
grid[p1].push_back({ p2,val });
}示例(2):无向非加权图,起点终点由输入给定
示例真题链接:https://kamacoder.com/problempage.php?pid=1179
输入示例:
cpp
5 4
1 2
1 3
2 4
3 4
1 4读取给定输入数据,并构建搜索图grid的程序:
cpp
// 读取输入数据,并构建搜索图grid
int n, m, p1, p2, val,si,ei;
cin >> n >> m;
vector<vector<pair<int, int>>> grid(n + 1);
for (int i = 0; i < m; i++) {
cin >> p1 >> p2;
grid[p1].push_back({ p2,1 });
grid[p2].push_back({ p1,1 });
}
cin>>si>>ei; // 读取起点和终点第1部分读取给定输入数据,并构建搜索图grid的程序需要根据题目给定的数据形式和图的类型来进行细微的调整,总的来说,有向图只需要通过gridp1.push_back({ p2,val });添加从p1指向p2的边即可,而无向图则需要通过gridp1.push_back({ p2,val }); gridp2.push_back({ p1,val });同时添加p1指向p2的边和p2指向p1的边,加权图则权值val通过读入的参数获取,非加权图则根据题目描述直接设定(一般为1),默认起点为1,终点为n的不需要读取起点终点信息,通过输入指定的,需要读取和存储起点和终点信息。一般来说也就这几种变数,都很简单。灵活的对上面两个程序示例进行细微调节就行。
2、选取寻路算法,寻找最短路径
有些题目是只需要判断节点A和B之间是否存在可行路径,返回bool类型的结果即可,而有的题目,若存在可行路径,则需要返回节点A和B之间的最短路径。本文致力于提供一种解决图论中所有(或绝大部分)有向图、无向图、加权图的单源最短路径问题的通用程序模板,因此,我们直接选取寻找最短路径的算法。
寻找最短路径的算法其实有多种,其中,A * 算法是路径规划领域最经典,也是应用最广泛的算法之一,但是由于启发式函数的存在,A * 算法并不能保证一定找到最短路径。因此,本文采用无启发式函数的类A * 算法(或者说将启发式函数的权重系数设置为0)来作为寻路算法。
【选做、非必要】 对A*算法的感兴趣的可以看一下以下资料,资料1的第一部分有我写的对 A * 算法的基本原理简介和算法流程简介,想要深入了解的,可以看一下资料2,应该算是我看过的A * 算法最全的介绍了,资料3和4是我之前写的A * 算法的源码解读和详细的基本原理介绍和算法流程概括总结 。
资料1:JPS(Jump Point Search)跳点搜索路径规划算法回顾
资料3:zhm_real/MotionPlanning运动规划库中A*算法源码详细解读
资料4:详细介绍用MATLAB实现基于A*算法的路径规划(附完整的代码,代码逐行进行解释)
之前对A * 算法完全没有了解的小伙伴,不用慌,上面我特意标注了 【选做、非必要】 标识,即使你对于A * 算法是完全陌生的,也不影响你掌握本文接下来要介绍的寻找最短路径的策略,只需要记住以下算法流程和几个概念就可以了。
必备概念
① 节点代价值:节点A的代价值是指从起点到节点A所需的累计代价,即从起点到节点A的路径经过的所有边的权重累加值,该值在寻路过程中可能会发生变化,例如发现一条从起点到节点A的更优路径时,其值会被更新为更优路径的代价值。
② 节点的父节点:节点A的父节点,即扩展出节点A的那个节点,例如已知路径 ①->②->A->④->⑤,则节点A的父节点,即为②
③ 节点扩展: 所谓的对节点A进行扩展可以理解为,当前已经得到了从起点到节点A的路径和累计代价,通过遍历节点A的邻接点和从节点A到达该邻接点的代价,就可以进一步得到从起点到节点A的所有邻接点的路径和累计代价,从而实现路径的扩展和延伸。
④ 节点状态:寻找最短路径的过程中,每个节点都有三种状态:【未被访问过的节点】,【被访问过,等待扩展的节点】,【被访问过,且已经扩展过的节点】
⑤ 两个容器:openlist容器存储被访问过,等待扩展的点,closelist容器存储,被访问过,且已经扩展过的节点
⑥ 路径回溯:每个节点都记录了其父节点,一但发现了终点,则通过终点记录的父节点,就可以得到终点前面的那个点,以此类推,直至回溯到起点,即可获得完整的路径。
算法流程
① 将起点放入到openlist中完成算法初始化。
② 检查当前openlist是否为空。如果为空,则搜索失败,停止循环,不存在从起点到目标点的可行路径。若不为空,则继续循环。
③从openlist中取出代价值最小的节点作为当前扩展点current,并将其加入到closelist中。
④ 判断当前扩展点current是否为要找的终点,则说明已经找到了从起点到终点的最短路径,结束循环,若不是,则继续循环。
⑤ 对当前节点current进行扩展,即遍历其当所有的邻接点,生成一组子节点。对于每一个邻接点:
如果该节点在closelist中,则说明该节点已经扩展过了,无需任何处理
如果该节点在openlist中,则说明该节点之前已经被访问过,且添加到openlist中等待被扩展,检查其通过当前节点计算得到的代价值是否比其现在存储的代价值更小,如果更小,则说明我们找到了到节点的一条更优的路径,则更新其代价值,并将其父节点设置为当前节点。
如果该节点不在openlist中,则说明该节点之前没有被访问过,将其加入到openlist列表,并计算代价值,设置其父节点为当前节点。
⑥ 本轮迭代结束, 转到第②步,循环进行下一轮迭代和扩展。直至openlist为空,在第②步中退出循环,或者找到最短路径,在第④步中退出循环。
思考3:那么选择什么容器来构造openlist和closelist?
从上面的必备概念和算法流程可知,在寻路过程中,除了我们已知的用于路径搜素的图grid,我们还需要记录每个节点的状态、代价值、父节点等信息。在寻路过程中,需要频繁对openlist执行访问、插入、删除等操作,对closelist执行访问和插入操作(对closelist的访问在路径回溯阶段)。且openlist和closelist中数据的存储可以是无序的。至此,基本上答案已经呼之欲出了------ unordered_map
(1)unordered_map 简介和特点
简介:unordered_map 是一个哈希表实现的关联容器,用于存储键值对。它提供了高效的插入、删除和查找操作,平均时间复杂度为 ( O(1) )。【高效的插入、删除和查找能力简直是充当openlist和closelist容器的绝配】unordered_map 具有以下的特点:
① 哈希表实现:内部使用哈希表实现,键值对的存储位置由键的哈希值决定。
② 无序:元素存储顺序不是按照插入顺序或键的顺序,而是根据哈希值。
③ 快速查找:平均查找时间复杂度为 ( O(1) ),最坏情况为 ( O(n) )(当发生大量哈希冲突时)。
④ 自动扩展 :当元素数量增加时,哈希表会自动扩展,重新哈希,保持高效的查找性能。【这里的自动扩展能力使得我们对openlist和closelist执行插入操作时变得非常非常方便】
(2)unordered_map 与其他容器的对比
--
| 特性 | unordered_map |
map |
vector |
list |
|---|---|---|---|---|
| 内部实现 | 哈希表 | 红黑树 | 动态数组 | 双向链表 |
| 元素顺序 | 无序 | 按键排序 | 按插入顺序 | 按插入顺序 |
| 查找时间复杂度 | 平均 O ( 1 ) O(1) O(1),最坏 O ( n ) O(n) O(n) | O ( log n ) O(\log n) O(logn) | O ( n ) O(n) O(n) | O ( n ) O(n) O(n) |
| 插入/删除时间复杂度 | 平均 O ( 1 ) O(1) O(1),最坏 O ( n ) O(n) O(n) | O ( log n ) O(\log n) O(logn) | 插入末尾 O ( 1 ) O(1) O(1),删除 O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) |
| 适用场景 | 需要快速查找 ( 同时需要频繁插入删除) , 无需顺序 | 需要有序存储和快速查找 | 需要高效随机访问和批量操作 | 需要频繁插入和删除 |
--
有了以上基础,现在我们回到思考3,很显然unordered_map 高效的插入、删除和查找能力简直是充当openlist和closelist容器的绝配
--
思考4:是否可以选择优先级队列priority_queue来构造openlist和closelist?
(3)priority_queue简介与特点
简介:priority_queue 是一个基于堆实现的容器适配器,用于存储一组元素,并提供快速访问和移除最大或最小元素的功能。priority_queue 具有以下特点:
① 堆实现:通常使用最大堆(或最小堆)实现,保证队列中的最大(或最小)元素总是位于队首。
② 无序存储:元素的存储顺序不保证,只有最大(或最小)元素的位置是确定的。
③ 快速访问最大/最小元素 :访问最大(或最小)元素的时间复杂度为 ( O(1) ),插入和删除操作的时间复杂度为 ( O ( log n ) O(\log n) O(logn) )。
--
(4)priority_queue维持最大/小堆的时间复杂度
--
在 priority_queue 中插入或删除一个元素后,维持堆顶元素最大或最小的时间复杂度是 ( O ( log n ) O(\log n) O(logn) )。这里,n 是 priority_queue 中的元素数量。具体来说:
① 插入元素的时间复杂度:
当向 priority_queue 中插入一个元素时,元素会首先被添加到堆的末尾,然后通过上浮操作(heapify up)将其移动到正确的位置,以维持堆的性质。这个过程的时间复杂度为( O ( log n ) O(\log n) O(logn) ),因为堆是一个完全二叉树,插入操作最多需要调整树的高度次,而高度为 ( log n \log n logn )。
② 删除堆顶元素的时间复杂度:
当从 priority_queue 中删除堆顶元素时,堆顶元素会被移除,并用堆的最后一个元素替换,然后通过下沉操作(heapify down)将这个元素移动到正确的位置,以维持堆的性质。这个过程的时间复杂度同样为( O ( log n ) O(\log n) O(logn) ),因为最多需要调整树的高度次。
所以,总的来说,在 priority_queue 中,无论是插入元素还是删除堆顶元素,都会进行堆的调整操作,以维持堆的性质。这些操作的时间复杂度都是( O ( log n ) O(\log n) O(logn) )。
--
(5)priority_queue与unordered_map 的对比
--
| 特性 | unordered_map |
priority_queue |
|---|---|---|
| 内部实现 | 哈希表 | 堆(最大堆或最小堆) |
| 元素顺序 | 无序 | 无序,只有最大/最小元素位置确定 |
| 插入时间复杂度 | 平均 O ( 1 ) O(1) O(1),最坏 O ( n ) O(n) O(n) | O ( log n ) O(\log n) O(logn) |
| 删除时间复杂度 | 平均 O ( 1 ) O(1) O(1),最坏 O ( n ) O(n) O(n) | O ( log n ) O(\log n) O(logn) |
| 查找时间复杂度 | 平均 O ( 1 ) O(1) O(1),最坏 O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) 仅访问最大/最小元素 |
| 适用场景 | 快速查找、插入和删除键值对 | 快速访问和移除最大/最小元素 |
| 常见用途 | 字典、频率统计、关联数组 | 优先级队列、任务调度 |
| 内存使用 | 需要额外的哈希桶和节点指针 | 需要额外的堆结构 |
| 是否支持随机访问 | 是(通过键访问任意元素) | 否(仅能访问堆顶元素) |
--
有了以上基础,现在我们回到思考4,有些小伙伴可能注意到算法流程第③步中,在每轮循环迭代中,我们都需要从openlist中获取代价值最小的那个元素,自然而言也就想到了可以自动排序的优先级队列priority_queue。
我们现在分析一下分别使用priority_queue和unordered_map时,算法每轮迭代获取代价值最小的节点所需的时间复杂度。假设当前openlist中存在n个节点,本轮迭代新插入到openlist中的节点个数为m,此外,每轮迭代都会从openlist列表中移除一个节点,在closelist中插入一个节点。priority_queue在插入或删除元素后,会自动维持其最大/小堆特性,堆顶元素即代价值最小的节点,因此,其时间复杂度主要取决于插入和删除次数,近似为 O ( ( m + 2 ) log n ) O((m+2)\log n) O((m+2)logn),unordered_map从openlist中获取代价值最小的点,则需要遍历一遍openlist中的所有节点,删除插入的时间复杂度都是 O ( 1 ) O(1) O(1) ,因此,所以其时间复杂度近似为 O ( n + m + 2 ) O(n+m+2) O(n+m+2) ,当n远大于m时,priority_queue的时间复杂度更低,那是不是用priority_queue更好?
答案是否定的,priority_queue存在一个致命的问题,其不支持随机访问,即只能访问堆顶的元素,而在前面介绍的算法流程的步骤⑤中,对当前节点进行扩展时,若该邻接点已经存在于openlist中,我们需要从openlist中访问并读取该邻接点现有的代价值,且若新的代价值更优,还需对openlist中存储的该邻接点的相关数据进行修改。如果使用priority_queue,则必然需要很多复杂的额外操作来实现以上需求。且上面算时间复杂度的时候,并没有考虑每轮迭代中大量的节点访问的时间复杂度,这方面unordered_map具有绝对的优势。因此,综合来看,使用priority_queue来实现openlist和closelist并不合适。
注: unordered_map :可以通过将顶点索引值作为键,来通过键访问任意元素。因此,可以认为 unordered_map 支持随机访问,但这种访问是基于键而非位置索引的。
思考5:算法所需的节点索引、父节点索引、代价值、状态值等变量应该如何存储?
上面的思考4中,我们已经提到了将节点的索引作为unordered_map的键,来方便的通过节点索引来访问openlist和closelist中的任意元素,每个节点的父节点、代价值、状态值应该是与节点绑定的数据,那么是不是可以将他们打包在一起作为unordered_map的值呢?
答案是不可以,我们需要明确那些量是只openlist和closelist中存储的那些节点,openlist中存储的是已经被访问过,且尚未扩展的节点,而closelist中存储的是已经被访问过,且已经扩展过的节点。前面的必备概念中,我们提到节点的状态,除了以上两种,还有未访问过,这个状态,即,我们并没有也不需要设计容器来存储未访问过的节点,且未访问过的节点的父节点和代价值信息是未知的。
若将节点状态值也放closelist中存储,在前面介绍的算法流程的步骤⑤中,对当前节点进行扩展时,若该邻接点之前尚未被扩展过,即其不在openlist中也不在closelist中,此时就无法查询该节点的状态,或者有的小伙伴说可以遍历一遍openlist和closelist,都没找到就说明没访问过。但这种操作是很低效的,我们需要的对每个节点状态的查询都是高效的 O ( 1 ) O(1) O(1)复杂度。因此,节点状态量需要单独的进行存储,节点的数量n是已知的,且不发生改变,直接用一个vector来存储即可实现高效的访问和修改。
对于未访问过的节点的父节点和代价值信息是未知且无意义的,所以每个节点的父节点和代价值则可以打包在一起作为unordered_map的值,存储在openlist或closelist中,就两个数据是否可以直接用pair<int ,int>来打包在一起? 原则上是可以的,但本文致力于提供一种解决图论中所有(或绝大部分)有向图、无向图、加权图的单源最短路径问题的通用程序模板,为了防止有些题目需要存储其他的额外信息,考虑到程序模板良好的可拓展性,这里面我们使用结构体来打包这两个数据,这样如果需要存储其他信息时,只需要在struct中添加即可,无需调整整个unordered_map,即本文设计的openlist和closelist的数据结构如下:
cpp
// 创建节点数据类型,记录节点累计代价值,父节点索引值等信息
struct Node
{
int val_;
int parent_;
Node(int val, int parent) : val_(val), parent_(parent) {}
Node() : val_(INT_MAX), parent_(0){}
};
unordered_map<int, Node> openlist; // 存放待扩展点,int类型的键存储节点索引,自定义的Node类型的值存储其他绑定数据信息
unordered_map<int, Node> closelist; // 存放已经扩展过的节点--
至此,经过大量的分析和对比,我们已经明确了算法中涉及到的所有关键数据的数据存储结构,现在,我们来总结一下,如下所示:
cpp
1、int类型的n,m,si,ei分别存储图的节点数、边数、起点索引、终点索引
2、vector<vector<pair<int, int>>>类型的变量grid(n + 1)存储输入给定的图
3、自定义Node类型的结构体存储与节点绑定的父节点索引、代价值等其他信息
struct Node
{
int val_;
int parent_;
Node(int val, int parent) : val_(val), parent_(parent) {}
Node() : val_(INT_MAX), parent_(0){}
};
4、unordered_map<int, Node>类型的变量openlist和closelist分别存储待扩展点和已经扩展过的节点,
其中int类型的键存储节点索引,自定义的Node类型的值存储其他绑定数据信息
5、vector<int>类型的变量state(n+,1)存储n个节点的状态,初始化为未访问状态1
节点状态对应的值 1:未被访问过 2;在优先级队列中等待扩展 3:已经扩展过了寻找最短路径的程序(核心)
有了上面的基础,再配合前面介绍的算法流程,很容易就可以写出寻找最短路径的程序,我将其封装成了独立的函数方便调用,如下所示,程序里面,我写了很详细的注释,配合前面的算法流程介绍,应该很容易看懂,本文的篇幅已经很长了,后面还有一些内容,这里就不对程序展开详细的介绍了,我把它单独放在一篇博客中了,有兴趣的可以去看一下,链接如下:
拓扑结构图中寻找最短路径的findpath函数【by慕羽】的函数源码、算法流程概括、函数源码解析【点击可跳转】
注:为了方便描述和理解,程序注释中将openlist和closelist描述为了"优先级队列"或"列表",大家知道其实际上是unordered_map即可。
cpp
// 寻找最短路径
// 形参依次为 起点索引start_i,目标点索引end_i,搜索图grid,已经扩展过的节点列表closelist
// 返回值表示是否找到可行路径
bool findpath( const int start_i, const int end_i, const vector<vector<pair<int, int>>>& grid, unordered_map<int, Node>& closelist)
{
closelist.clear(); //清空closelist列表,准备存储规划结果
unordered_map<int, Node> openlist; // 创建哈希表存放待扩展点
vector<int> state(grid.size(),1); // 记录节点状态 1:未被访问过 2;在优先级队列中等待扩展 3:已经扩展过了
Node start(0, -1); //初始化起点,代价值为0,起点无父节点设置为-1
openlist[start_i] = start; //将起点放入openlist列表
state[start_i] = 2; //更新起点状态,完成初始化
while (!openlist.empty())
{
//第一步:从openlist列表中选取代价值val最小的节点current_index
int current_index = -1;
int min_val = INT_MAX;
for (const auto& item : openlist) {
if (item.second.val_ < min_val) {
min_val = item.second.val_;
current_index = item.first;
}
}
//第二步:将节点current_index从带扩展队列openlist中取出,并添加到扩展完成队列closelist
Node current = openlist[current_index];
openlist.erase(current_index);
closelist[current_index] = current;
state[current_index] = 3;
//第三步: 判断是否发现到目标点的最短路径
//若当前扩展点是目标点,说明待扩展点队列中其他点的当前代价均大于目标点的代价,图中所有边为非负数,此时已经找到最短路径
if (current_index == end_i) return true;
//第四步: 扩展当前节点current_index
for (const auto &neig: grid[current_index])
{
if (state[neig.first] == 1) //若该邻居节点未被访问过,则将current_index作为其父节点,并放入队列中
{
Node temp(current.val_ + neig.second,current_index);
openlist[neig.first] = temp;
state[neig.first] = 2;
}
else if (state[neig.first] == 2) //若该邻居节点已经在带扩展队列中了,则判断是否需要更新代价值和父节点
{
if (openlist[neig.first].val_ > (current.val_ + neig.second))
{
openlist[neig.first].val_ = current.val_ + neig.second;
openlist[neig.first].parent_ = current_index;
}
} //若该邻居节点已经在带扩展完成队列中了,则无需任何处理
}
}
return false;
}思考6:为什么当openlist中代价值最小的点是终点时,当前找到的路径就一定是最短路径?
若当前openlist中代价值最小的点是终点,则说明openlist中存储的其他待扩展点的当前代价vi均大于终点的代价ve,图中所有边ei均为非负数,即从这些点到终点必然需要再累加一个或多个大于0的代价,即vi大于ve,ei大于0,vi+ei也必然大于ve,那么必然不存在到终点的更近路径了,此时已经找到最短路径。
3、通过路径回溯提取最短路径
思考7:closelist为什么要以传引用的形式传入findpath函数,而不是像openlist一样直接在findpath函数中定义? 每个节点为什么要记录其父节点?findpath函数的返回值仅提供了是否存在可行路径信息,如何获得找到的最短路径?
以上三个问题实际上可以看做是一个问题,之所以findpath函数的返回值是bool类型的表示是否找到可行路径的标志,而不是直接返回路径,是因为有些题目仅仅需要输出是否存在可行路径,而不关心具体的路径,有些题目仅需要输出最短路径的代价值是多少,而同样不关心最短路径具体是什么。那么对于需要输出最短路径的题目,我们又如何获取最短路径呢?
答案是通过节点记录的父节点信息进行路径回溯来提取路径,这些路径点储存在哪里呢? 答案是closelist,因为如果一个节点有子节点,那么他一定扩展过了,必然存在于closelist中。所以我们直接从终点开始根据其记录的父节点信息,就可以得到终点的前一个点,根据这个点记录的父节点信息,又可以得到这个点前面的一个点,以此类推,直至回溯到起点。即可得到完整的路径。这也是为什么每个点要记录其父节点信息,以及为什么closelist要以引用的形式传入,并将其返回的原因。
路径回溯,并输出最短路径的程序
由于需要从终点开始向起点进行路径回溯,而在输出的时候一般是输出从起点到终点的顺序来输出路径,所以,我们并不能直接输出路径,而需要先将回溯过程的路径存储起来,考虑到先入后出的特性,自然也就想到了stack,且stack的入栈和出栈操作都是高效的,其时间复杂度为 O ( 1 ) O(1) O(1) ,因此该部分主要分为路径回溯部分和路径打印部分两部分内容,其中路径打印部分的程序需要根据题目要求的格式进行细微的调整,参考程序如下:
cpp
// 输出最短路径的函数
void printPath(const int start_i, const int end_i, unordered_map<int, Node>& closelist) {
stack<int> path; //创建一个空栈存储回溯得到的路径
int current = end_i;
// 从终点向前追溯到起点
while (current != start_i) {
path.push(current);
current = closelist[current].parent_;
}
path.push(start_i); // 将起点加入路径
// 输出路径
while (!path.empty()) {
cout << path.top(); path.pop();
if (!path.empty()) cout << " -> ";
}
cout << endl;
}4、完整的通用模板程序
至此,解决图论中有向图、无向图、非负加权图的单源最短路径问题的通用模板程序就设计和编写完成了,如下所示,无论是是有向图,无向图,加权图、非加权图等,无论是寻找是否存在可行路径,还是寻找最短路径或者代价值。本文提供的程序模板的核心部分也就是findpath函数都无需更改,直接调用即可,程序模板主函数中的读取给定输入数据,并构建搜索图grid部分,根据题目要求和本文第1部分末尾处提供的各种示例进行细微的修改即可,如果需要打印出最短路径,则根据题目要求的输出格式对printPath函数的输出路径部分进行细微的修改即可。
cpp
#include <iostream>
#include <vector>
#include <unordered_map>
#include <limits.h>
#include <stack>
using namespace std;
// 创建节点数据类型,记录节点累计代价值,父节点索引值,节点状态等信息
struct Node
{
int val_;
int parent_;
Node(int val, int parent) : val_(val), parent_(parent) {}
Node() : val_(INT_MAX), parent_(0){}
};
// 寻找最短路径
// 形参依次为 起点索引start_i,目标点索引end_i,搜索图grid,已经扩展过的节点列表closelist
// 返回值表示是否找到可行路径
bool findpath( const int start_i, const int end_i, const vector<vector<pair<int, int>>>& grid, unordered_map<int, Node>& closelist)
{
closelist.clear(); //清空closelist列表,准备存储规划结果
unordered_map<int, Node> openlist; // 创建哈希表存放待扩展点
vector<int> state(grid.size(),1); // 记录节点状态 1:未被访问过 2;在优先级队列中等待扩展 3:已经扩展过了
Node start(0, -1); //初始化起点,代价值为0,起点无父节点设置为-1
openlist[start_i] = start; //将起点放入openlist列表
state[start_i] = 2; //更新起点状态,完成初始化
while (!openlist.empty())
{
//第一步:从openlist列表中选取代价值val最小的节点current_index
int current_index = -1;
int min_val = INT_MAX;
for (const auto& item : openlist) {
if (item.second.val_ < min_val) {
min_val = item.second.val_;
current_index = item.first;
}
}
//第二步:将节点current_index从带扩展队列openlist中取出,并添加到扩展完成队列closelist
Node current = openlist[current_index];
openlist.erase(current_index);
closelist[current_index] = current;
state[current_index] = 3;
//第三步: 判断是否发现到目标点的最短路径
//若当前扩展点是目标点,说明待扩展点队列中其他点的当前代价均大于目标点的代价,图中所有边为非负数,此时已经找到最短路径
if (current_index == end_i) return true;
//第四步: 扩展当前节点current_index
for (const auto &neig: grid[current_index])
{
if (state[neig.first] == 1) //若该邻居节点未被访问过,则将current_index作为其父节点,并放入队列中
{
Node temp(current.val_ + neig.second,current_index);
openlist[neig.first] = temp;
state[neig.first] = 2;
}
else if (state[neig.first] == 2) //若该邻居节点已经在带扩展队列中了,则判断是否需要更新代价值和父节点
{
if (openlist[neig.first].val_ > (current.val_ + neig.second))
{
openlist[neig.first].val_ = current.val_ + neig.second;
openlist[neig.first].parent_ = current_index;
}
} //若该邻居节点已经在带扩展完成队列中了,则无需任何处理
}
}
return false;
}
// 输出最短路径的函数
void printPath(const int start_i, const int end_i, unordered_map<int, Node>& closelist) {
stack<int> path; //创建一个空栈存储回溯得到的路径
int current = end_i;
// 从终点向前追溯到起点
while (current != start_i) {
path.push(current);
current = closelist[current].parent_;
}
path.push(start_i); // 将起点加入路径
// 输出路径
while (!path.empty()) {
cout << path.top(); path.pop();
if (!path.empty()) cout << " -> ";
}
cout << endl;
}
int main() {
// 读取输入数据,并构建搜索图grid
int n, m, p1, p2, val,si,ei;
cin >> n >> m;
vector<vector<pair<int, int>>> grid(n + 1);
for (int i = 0; i < m; i++) {
cin >> p1 >> p2 >> val;
grid[p1].push_back({ p2,val });
}
si = 1; ei = n; //默认起点为1,终点为n
// 调用findpath函数寻找最短路径
unordered_map<int, Node> closelist;
bool suc = findpath(si, ei, grid, closelist);
// 判断是否成功找到最短路径,并根据需要输出最短路径值、最短路径等信息
if (suc) cout << closelist[ei].val_ << endl;
else cout << -1 << endl;
// 如果成功,则打印路径
if (suc) printPath(si, ei, closelist); //根据题目输出要求决定是否需要输出最短路径,不需要就注释掉该行内容
return 0;
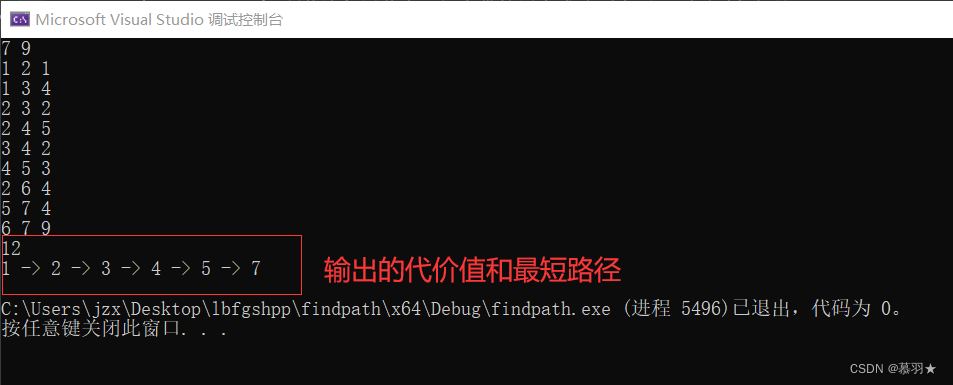
}当输入数据为以下内容时:
cpp
7 9
1 2 1
1 3 4
2 3 2
2 4 5
3 4 2
4 5 3
2 6 4
5 7 4
6 7 9 本文给定的通用模板程序的输出如下所示:
二、真题示例
1、参加科学大会
小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。小明的起点是第一个车站,终点是最后一个车站。然而,途中的各个车站之间的道路状况、交通拥堵程度以及可能的自然因素(如天气变化)等不同,这些因素都会影响每条路径的通行时间。小明希望能选择一条花费时间最少的路线,以确保他能够尽快到达目的地。
输入:第一行包含两个正整数,第一个正整数 N 表示一共有 N 个公共汽车站,第二个正整数 M 表示有 M 条公路。 接下来为 M 行,每行包括三个整数,S、E 和 V,代表了从 S 车站可以单向直达 E 车站,并且需要花费 V 单位的时间。
输出:输出一个整数,代表小明从起点到终点所花费的最小时间。
示例真题链接:https://kamacoder.com/problempage.php?pid=1047
参考程序:
cpp
#include <iostream>
#include <vector>
#include <unordered_map>
#include <limits.h>
#include <stack>
using namespace std;
// 创建节点数据类型,记录节点累计代价值,父节点索引值,节点状态等信息
struct Node
{
int val_;
int parent_;
Node(int val, int parent) : val_(val), parent_(parent) {}
Node() : val_(INT_MAX), parent_(0){}
};
// 寻找最短路径
// 形参依次为 起点索引start_i,目标点索引end_i,搜索图grid,已经扩展过的节点列表closelist
// 返回值表示是否找到可行路径
bool findpath( const int start_i, const int end_i, const vector<vector<pair<int, int>>>& grid, unordered_map<int, Node>& closelist)
{
closelist.clear(); //清空closelist列表,准备存储规划结果
unordered_map<int, Node> openlist; // 创建哈希表存放待扩展点
vector<int> state(grid.size(),1); // 记录节点状态 1:未被访问过 2;在优先级队列中等待扩展 3:已经扩展过了
Node start(0, -1); //初始化起点,代价值为0,起点无父节点设置为-1
openlist[start_i] = start; //将起点放入openlist列表
state[start_i] = 2; //更新起点状态,完成初始化
while (!openlist.empty())
{
//第一步:从openlist列表中选取代价值val最小的节点current_index
int current_index = -1;
int min_val = INT_MAX;
for (const auto& item : openlist) {
if (item.second.val_ < min_val) {
min_val = item.second.val_;
current_index = item.first;
}
}
//第二步:将节点current_index从带扩展队列openlist中取出,并添加到扩展完成队列closelist
Node current = openlist[current_index];
openlist.erase(current_index);
closelist[current_index] = current;
state[current_index] = 3;
//第三步: 判断是否发现到目标点的最短路径
//若当前扩展点是目标点,说明待扩展点队列中其他点的当前代价均大于目标点的代价,图中所有边为非负数,此时已经找到最短路径
if (current_index == end_i) return true;
//第四步: 扩展当前节点current_index
for (const auto &neig: grid[current_index])
{
if (state[neig.first] == 1) //若该邻居节点未被访问过,则将current_index作为其父节点,并放入队列中
{
Node temp(current.val_ + neig.second,current_index);
openlist[neig.first] = temp;
state[neig.first] = 2;
}
else if (state[neig.first] == 2) //若该邻居节点已经在带扩展队列中了,则判断是否需要更新代价值和父节点
{
if (openlist[neig.first].val_ > (current.val_ + neig.second))
{
openlist[neig.first].val_ = current.val_ + neig.second;
openlist[neig.first].parent_ = current_index;
}
} //若该邻居节点已经在带扩展完成队列中了,则无需任何处理
}
}
return false;
}
// 输出最短路径的函数
void printPath(const int start_i, const int end_i, unordered_map<int, Node>& closelist) {
stack<int> path; //创建一个空栈存储回溯得到的路径
int current = end_i;
// 从终点向前追溯到起点
while (current != start_i) {
path.push(current);
current = closelist[current].parent_;
}
path.push(start_i); // 将起点加入路径
// 输出路径
while (!path.empty()) {
cout << path.top(); path.pop();
if (!path.empty()) cout << " -> ";
}
cout << endl;
}
int main() {
// 读取输入数据,并构建搜索图grid
int n, m, p1, p2, val,si,ei;
cin >> n >> m;
vector<vector<pair<int, int>>> grid(n + 1);
for (int i = 0; i < m; i++) {
cin >> p1 >> p2 >> val;
grid[p1].push_back({ p2,val });
}
si = 1; ei = n; //默认起点为1,终点为n
// 调用findpath函数寻找最短路径
unordered_map<int, Node> closelist;
bool suc = findpath(si, ei, grid, closelist);
// 判断是否成功找到最短路径,并根据需要输出最短路径值、最短路径等信息
if (suc) cout << closelist[n].val_ << endl;
else cout << -1 << endl;
// 如果成功,则打印路径
// if (suc) printPath(si, ei, closelist); //根据题目输出要求决定是否需要输出最短路径
return 0;
}2、寻找存在的路径
给定一个包含 n 个节点的无向图中,节点编号从 1 到 n (含 1 和 n )。你的任务是判断是否有一条从节点 source 出发到节点 destination 的路径存在。
输入:第一行包含两个正整数 N 和 M,N 代表节点的个数,M 代表边的个数。 后续 M 行,每行两个正整数 s 和 t,代表从节点 s 与节点 t 之间有一条边。 最后一行包含两个正整数,代表起始节点 source 和目标节点 destination。
输出:输出一个整数,代表是否存在从节点 source 到节点 destination 的路径。如果存在,输出 1;否则,输出 0。
示例真题链接:https://kamacoder.com/problempage.php?pid=1179
参考程序:
cpp
#include <iostream>
#include <vector>
#include <unordered_map>
#include <limits.h>
using namespace std;
// 创建节点数据类型,记录节点累计代价值,父节点索引值
struct Node
{
int val_;
int parent_;
Node(int val, int parent) : val_(val), parent_(parent) {}
Node() : val_(INT_MAX), parent_(0){}
};
// 寻找最短路径
// 形参依次为 起点索引start_i,目标点索引end_i,搜索图grid,已经扩展过的节点列表closelist
// 返回值表示是否找到可行路径
bool findpath( const int start_i, const int end_i, const vector<vector<pair<int, int>>>& grid, unordered_map<int, Node>& closelist)
{
closelist.clear(); //清空closelist列表,准备存储规划结果
unordered_map<int, Node> openlist; // 创建哈希表存放待扩展点
vector<int> state(grid.size(),1); // 记录节点状态 1:未被访问过 2;在优先级队列中等待扩展 3:已经扩展过了
Node start(0, -1); //初始化起点,代价值为0,起点无父节点设置为-1
openlist[start_i] = start; //将起点放入openlist列表
state[start_i] = 2; //更新起点状态,完成初始化
while (!openlist.empty())
{
//第一步:从openlist列表中选取代价值val最小的节点current_index
int current_index = -1;
int min_val = INT_MAX;
for (const auto& item : openlist) {
if (item.second.val_ < min_val) {
min_val = item.second.val_;
current_index = item.first;
}
}
//第二步:将节点current_index从带扩展队列openlist中取出,并添加到扩展完成队列closelist
Node current = openlist[current_index];
openlist.erase(current_index);
closelist[current_index] = current;
state[current_index] = 3;
//第三步: 判断是否发现到目标点的最短路径
//若当前扩展点是目标点,说明待扩展点队列中其他点的当前代价均大于目标点的代价,图中所有边为非负数,此时已经找到最短路径
if (current_index == end_i) return true;
//第四步: 扩展当前节点current_index
for (const auto &neig: grid[current_index])
{
if (state[neig.first] == 1) //若该邻居节点未被访问过,则将current_index作为其父节点,并放入队列中
{
Node temp(current.val_ + neig.second,current_index);
openlist[neig.first] = temp;
state[neig.first] = 2;
}
else if (state[neig.first] == 2) //若该邻居节点已经在带扩展队列中了,则判断是否需要更新代价值和父节点
{
if (openlist[neig.first].val_ > (current.val_ + neig.second))
{
openlist[neig.first].val_ = current.val_ + neig.second;
openlist[neig.first].parent_ = current_index;
}
} //若该邻居节点已经在带扩展完成队列中了,则无需任何处理
}
}
return false;
}
int main() {
// 读取输入数据,并构建搜索图grid
int n, m, p1, p2, val,si,ei;
cin >> n >> m;
vector<vector<pair<int, int>>> grid(n + 1);
for (int i = 0; i < m; i++) {
cin >> p1 >> p2;
grid[p1].push_back({ p2,1 });
grid[p2].push_back({ p1,1 });
}
cin>>si>>ei;
// 调用findpath函数寻找最短路径
unordered_map<int, Node> closelist;
bool suc = findpath(si, ei, grid, closelist);
// 判断是否成功找到最短路径,并根据需要输出最短路径值、最短路径等信息
if (suc) cout << 1<< endl;
else cout << 0 << endl;
}