在人工智能的浪潮中,大型语言模型(LLMs)已经成为推动自然语言处理技术发展的关键力量。它们在理解、生成语言以及执行复杂任务方面展现出了巨大的潜力。然而,尽管在特定领域内取得了显著进展,现有的开源LLMs在处理多样化和高难度的推理任务时,仍然难以与最前沿的专有模型相媲美。这一差距不仅限制了开源模型的应用范围,也阻碍了整个领域的发展和创新。
推理任务,特别是那些需要综合运用数学知识、编程技能和逻辑分析的挑战,对LLMs提出了更高的要求。为了提升模型的推理能力,研究者们需要开发出新的数据集来训练和优化模型,同时也需要探索更有效的学习方法来提高模型的泛化能力和准确性。
本文正是在这样的背景下,提出了ULTRAINTERACT------一个专为复杂推理任务设计的大规模、高质量的对齐数据集,以及基于此数据集训练的EURUS系列模型。这些模型在多个推理基准测试中取得了突破性的成绩,显著缩小了开源模型与专有模型之间的性能差距。通过深入分析和评估,本文不仅展示了ULTRAINTERACT和EURUS模型的强大能力,也为开源LLMs的进一步发展提供了宝贵的见解和资源。
 EURUS-7B和EURUS-70B模型与其他基线模型在LeetCode编程问题和TheoremQA数学问题基准测试上的比较结果
EURUS-7B和EURUS-70B模型与其他基线模型在LeetCode编程问题和TheoremQA数学问题基准测试上的比较结果
EURUS-7B与比其大10倍的模型相当,而EURUS-70B是唯一一个与GPT-3.5 Turbo性能相当的模型
ULTRAINTERACT
 不同数据集中的示例,说明如何构建偏好树,其中每个指令都作为偏好树的根,每个动作是一个节点
不同数据集中的示例,说明如何构建偏好树,其中每个指令都作为偏好树的根,每个动作是一个节点
Figure 2 描述了三种不同的数据结构和方法,用于构建和管理语言模型中的指令和反馈。这些方法都旨在提高模型在执行任务时的精确性和效率,尤其是在编程和推理任务中。
左侧:
-
CodeActInstruct:这是一种数据结构,用于指导模型执行编程任务。它包含了一系列的指令和行动,模型需要按照这些指令来生成代码或执行相关任务。
-
Code-Feedback:这个结构涉及到在模型生成代码后提供反馈。反馈包括代码的正确性、效率或其他评价标准,用于指导模型学习和改进其代码生成能力。
中间:
- HH-RLHF:这是一个特定的模型或方法,用于提高语言模型在执行任务时的人类一致性(Human-Likeness)。这种方法涉及到对模型的输出进行评估和反馈,以使其更加符合人类的思维方式和行为模式。
右侧:
-
ULTRAINTERACT:每个指令都被构建为一个偏好树(preference tree)。在这种结构中,每个指令都是树的根,而树的每个节点代表一个行动或决策。偏好树允许模型在执行任务时考虑多种可能的行动路径,并根据反馈来优化这些路径。
-
Chosen Action:被选择的行动,即模型根据当前信息和偏好选择的最佳行动。
-
Rejected Action:被拒绝的行动,即模型在评估后认为不是最佳选择的行动。
-
Observation:观察结果,包括环境反馈或其他相关信息,用于评估行动的效果。
-
Critique:批评或评价,来自用户或其他评价系统,提供了对行动的深入分析和改进建议。
-
偏好树的构建允许ULTRAINTERACT数据集在多轮交互中进行偏好学习,模型可以根据每一轮的反馈来调整其行动选择,从而在复杂的推理任务中实现更好的性能。这种方法特别适用于需要逐步解决问题的场景,如编程、数学问题求解或逻辑推理等任务。通过这种方式,ULTRAINTERACT不仅提高了模型的决策质量,还增强了其学习和适应新任务的能力。
ULTRAINTERACT数据集通过精心策划,涵盖了数学、编程和逻辑推理等多种类型的复杂问题。这些问题来源于12个已经建立的数据集,它们不仅在内容上具有多样性,而且在难度和解决问题所需的策略上也表现出丰富性。这种设计使得数据集能够全面地训练和评估LLMs在不同领域的推理能力。
在ULTRAINTERACT中,指令的选择经过了精心策划,以确保它们在复杂性、质量和多样性上的高标准。研究者们专注于三个主要的推理任务:数学问题求解、代码生成和逻辑推理。这些问题不仅具有挑战性,而且拥有确切的解决方案,这有助于提供高质量的反馈信号,从而提高模型的推理性能。
ULTRAINTERACT数据集支持多轮交互,这使得模型能够在解决问题的过程中与环境进行多次交流和学习。在每一轮交互中,模型将问题分解为更小的子问题,并通过生成代码或文本形式的行动来解决这些子问题。这种分解和互动的过程不仅模拟了人类解决问题的方式,而且也使得模型能够逐步优化其解决方案。
 通过一个具体的数学问题解决示例,展示了模型如何在每个回合中生成推理链,并从环境和批评模型获得观察和文本批评
通过一个具体的数学问题解决示例,展示了模型如何在每个回合中生成推理链,并从环境和批评模型获得观察和文本批评
ULTRAINTERACT的创新点偏好树的设计。与开放式对话不同,许多推理任务对于正确的行动路径有着明确的偏好。ULTRAINTERACT通过构建偏好树,为每个指令收集了成对的正确和错误的行动,这些行动以树状结构组织,从而促进了偏好学习。这种设计允许模型在每一轮交互中学习并改进其选择,以更好地符合任务的客观偏好。
偏好树中的每个节点代表一个行动,而树的路径则代表解决特定问题的一系列决策。通过这种方式,ULTRAINTERACT不仅为模型提供了丰富的学习材料,而且通过明确的正确与错误示例,指导模型如何根据反馈进行自我修正和优化,从而在复杂推理任务中实现更好的性能。
 ULTRAINTERACT数据集的详细统计信息,包括不同任务类型的指令数量、每个轨迹的回合数、每个轨迹的标记数等
ULTRAINTERACT数据集的详细统计信息,包括不同任务类型的指令数量、每个轨迹的回合数、每个轨迹的标记数等
ULTRAINTERACT数据集通过其独特的设计,为LLMs提供了一个全面、高质量的训练环境,使其能够在多样化的复杂推理任务中得到有效的训练和评估。
EURUS
EURUS系列模型代表了在推理领域开源大型语言模型(LLMs)的最新进展。这些模型的开发利用了ULTRAINTERACT数据集,通过监督式微调和偏好学习两种方法进行训练,以提高模型解决复杂推理问题的能力。
监督式微调(Supervised Fine-Tuning, SFT)是提高模型性能的第一步。在这个过程中,研究者们选择了两个基础模型:Mistral-7B和CodeLLaMA-70B,分别对应EURUS-7B-SFT和EURUS-70B-SFT。微调的目标是让模型更好地适应ULTRAINTERACT数据集中的指令和行动对。
在SFT阶段,研究者们采用了一个独特的策略:他们只使用正确的行动(287K个)来训练模型,并且发现忽略交互历史,只训练每个偏好树中的正确叶节点会有更好的性能。此外,为了提高模型对指令的遵循能力,他们还将UltraChat、ShareGPT2和OpenOrca等数据集混合到SFT数据中。
在监督式微调的基础上,研究者们进一步探索了偏好学习(Preference Learning)。基于EURUS-SFT模型,他们尝试了三种不同的偏好学习算法:DPO、KTO和NCA。这些算法的目标是通过比较正确和错误的行动对来进一步优化模型的决策过程。
与SFT不同,偏好学习阶段包括了ULTRAINTERACT中的所有多轮轨迹对(220K个)以及UltraFeedback中的所有行动对(340K个)。这种方法使得模型能够学习如何在连续的交互中根据反馈进行调整。
奖励建模(Reward Modeling)是另一个关键的环节,它与偏好学习紧密相关。在这个阶段,研究者们使用了与偏好学习相同的多轮轨迹对,并额外加入了ULTRAINTERACT中的240K个单轮行动对,以及UltraFeedback和UltraSafety数据集中的行动对。
为了提高模型的推理能力,研究者们提出了一个新的奖励建模目标,它在传统的Bradley-Terry(BT)目标基础上增加了一个新的项LDR。这个新的目标鼓励模型在训练过程中增加被选择解决方案的绝对奖励值,并减少被拒绝数据的奖励值。
通过这些方法,EURUS模型不仅在单个任务上表现出色,而且在多任务学习中也展现了强大的泛化能力。这些模型的推出,标志着开源LLMs在推理领域的新里程碑,为未来的研究和应用提供了新的可能性。
评估EURUS-7B和EURUS-70B
在对EURUS系列模型进行评估时,研究者们设计了一套全面的测试方案,旨在全面考察模型在单轮和多轮推理任务上的表现。
 用于比较的开源大型语言模型基线,包括通用目的、编程和数学模型
用于比较的开源大型语言模型基线,包括通用目的、编程和数学模型
评估过程包括了对单轮推理和多轮推理的测试。单轮推理评估主要关注模型在一次性交互中解决问题的能力,而多轮推理评估则考察模型在连续交互中逐步改进答案的能力。
评估结果EURUS模型在与相似规模的开源模型相比时,展现出了卓越的整体性能。特别是在数学和编程领域,EURUS不仅超越了其他开源模型,甚至在很多情况下,它的性能还超过了专门领域的模型。例如,EURUS-7B在LeetCode和TheoremQA这两个挑战性基准上的表现,与比它大5倍的模型相当,而EURUS-70B的性能甚至超过了GPT-3.5 Turbo。
 EURUS模型与其他模型在不同基准测试上的性能比较结果
EURUS模型与其他模型在不同基准测试上的性能比较结果
这些结果证明了ULTRAINTERACT数据集和基于它的训练方法在提升模型推理能力方面的有效性。偏好学习算法,特别是KTO和NCA,进一步提高了模型在数学问题和多轮交互任务上的表现。
评估EURUS-RM-7B
除了对基础模型的评估,研究者们还对EURUS-RM-7B,即EURUS的奖励模型进行了评估。评估设置在三个奖励模型基准上进行:RewardBench、AutoJ和MT-Bench。这些基准测试旨在评估模型在不同任务上的表现,包括对话、安全性、编程、数学和其他类型的推理任务。
 使用EURUS-RM-7B奖励模型对Mistral-7B-Instruct-v0.2模型响应进行重新排序的结果,以及与其他基线模型的比较
使用EURUS-RM-7B奖励模型对Mistral-7B-Instruct-v0.2模型响应进行重新排序的结果,以及与其他基线模型的比较
评估结果显示,EURUS-RM-7B在7B大小的奖励模型中表现最佳。它在多个任务上达到了与更大基线相当的性能,尤其是在AutoJ和MT-Bench上,EURUS-RM-7B与人类评估者的一致性超过了所有现有模型,包括GPT-4。在RewardBench的"Chat-Hard"部分,EURUS-RM-7B超越了所有基线,在"Reasoning"部分也展现了极具竞争力的表现。
通过使用EURUS-RM-7B对Mistral-7B-Instruct-v0.2的回答进行重排,研究者们发现它在所有任务上一致性地提高了pass@1准确率,并且在某些情况下,其性能甚至超过了比它大5倍的Starling-RM-34B。
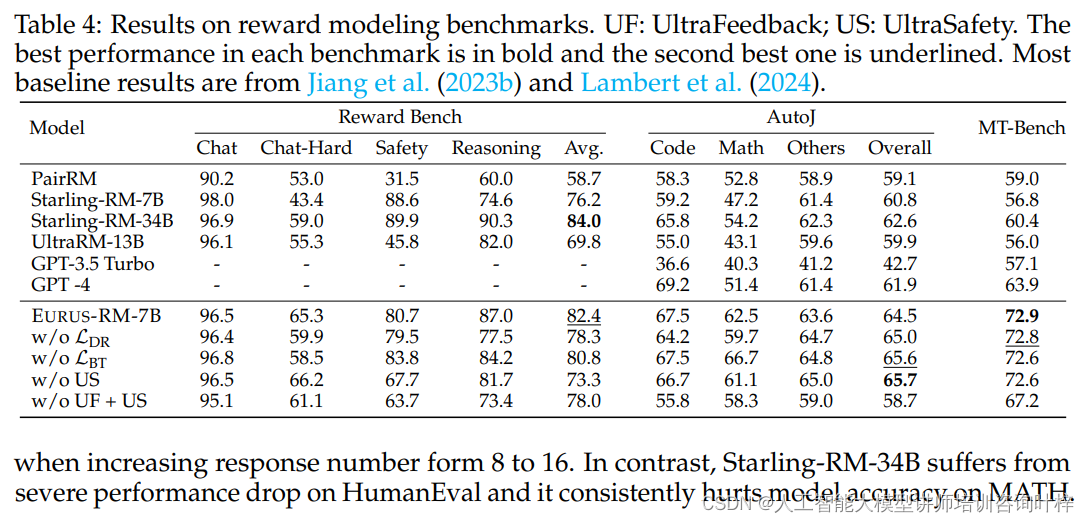 EURUS-RM-7B奖励模型与其他模型在奖励建模基准测试上的比较结果
EURUS-RM-7B奖励模型与其他模型在奖励建模基准测试上的比较结果
这些评估结果不仅证明了EURUS-RM-7B作为一个奖励模型的有效性,也展示了通过奖励建模来提升LLMs推理能力的潜力。通过这种方式,研究者们能够为开源LLMs提供更强大的工具,以解决更广泛的复杂问题。
分析
在对EURUS模型的偏好学习过程进行深入分析时,研究者们特别关注了DPO、KTO和NCA这三种算法的奖励模式,以理解它们在推理任务中的表现差异。
研究者们首先对DPO、KTO和NCA在偏好学习过程中的奖励模式进行了观察。他们发现,尽管这三种算法都会随着时间的推移减少对拒绝数据的奖励,但它们在处理选择数据的奖励时却表现出不同的趋势。DPO算法在优化过程中,虽然保持了选择数据的奖励高于拒绝数据,但最终选择数据的奖励值却降到了零以下。相反,KTO和NCA算法则持续增加选择数据的奖励,同时减少拒绝数据的奖励,使得选择数据的奖励始终保持正值。
 EURUS-7B 模型在应用 DPO(Direct Preference Optimization)、KTO(Kernelized Thompson Sampling for Optimization)、和 NCA(Noisy Comparison with Augmented Rewards)三种不同的偏好学习算法时的奖励模式分析
EURUS-7B 模型在应用 DPO(Direct Preference Optimization)、KTO(Kernelized Thompson Sampling for Optimization)、和 NCA(Noisy Comparison with Augmented Rewards)三种不同的偏好学习算法时的奖励模式分析
基于这些观察,研究者们提出了一个假设:在推理任务中,偏好学习的性能可能与选择数据的奖励绝对值有关。具体来说,更高的最终奖励值往往表明更好的推理能力。这一假设与一般对话任务中的情况形成对比,在对话任务中,偏好通常是相对的,可能有多个有效答案对应同一输入。然而,在推理任务中,正确答案的空间远小于错误答案,因此增加选择数据的奖励可能对提高模型性能特别有益。
为了进一步理解ULTRAINTERACT数据集对模型性能的贡献,研究者们进行了消融研究。他们比较了三种不同的数据使用设置对EURUS-7B-SFT模型性能的影响:使用原始数据集中的地面真实答案、仅使用开源数据、以及仅使用ULTRAINTERACT数据集。
消融研究的结果表明,当模型仅使用ULTRAINTERACT数据集进行训练时,除了BBH任务外,其在其他任务上的性能普遍下降,尤其是在指令遵循能力上。这表明,虽然ULTRAINTERACT数据集在提升模型的推理能力方面非常有效,但在指令遵循方面可能不足以独立支撑模型的训练。因此,将ULTRAINTERACT与其他对齐数据混合使用,对于实现全面的监督式微调是必要的。
研究者们还发现,当从训练数据中移除UltraSafety数据时,奖励模型在大多数任务上的准确度会高于EURUS-RM-7B,这进一步证实了多样化数据集在训练过程中的重要性。
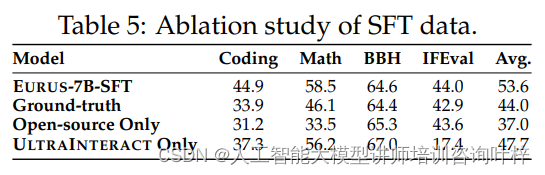 不同数据集配置对EURUS-7B-SFT模型性能的影响
不同数据集配置对EURUS-7B-SFT模型性能的影响
通过这些分析,研究者们不仅揭示了不同偏好学习算法在推理任务中的性能差异,还强调了在训练过程中使用多样化数据集的重要性。这些发现为未来LLMs的训练和优化提供了宝贵的见解。本文的研究推动了开源LLMs在推理领域的边界,通过发布ULTRAINTERACT数据集、引入EURUS系列模型,并提供了对推理中偏好学习的深入分析,为开源推理模型的发展提供了新的方向和强大的工具。
论文链接:https://arxiv.org/abs/2404.02078
GitHub 地址:https://github.com/OpenBMB/Eurus