数据分类汇总与统计
前言
推荐一个网站给想要了解或者学习人工智能知识的读者,这个网站里内容讲解通俗易懂且风趣幽默,对我帮助很大。我想与大家分享这个宝藏网站,请点击下方链接查看。
https://www.captainbed.cn/f1
数据分类汇总与统计是指将大量的数据按照不同的分类方式进行整理和归纳,然后对这些数据进行统计分析,以便于更好地了解数据的特点和规律。
在当今这个大数据的时代,数据分析已经成为了我们日常生活和工作中不可或缺的一部分。Python作为一种高效、简洁且易于学习的编程语言,在数据分析领域展现出了强大的实力。本文将介绍如何使用Python进行数据分类汇总与统计,帮助读者更好地理解和应用数据。
首先,我们需要导入一些常用的Python库,如pandas、numpy和matplotlib等。这些库提供了丰富的数据处理、分析和可视化功能,使得Python在数据分析领域独具优势。
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt接下来,我们可以使用pandas库来加载和处理数据。pandas提供了一个名为DataFrame的数据结构,它可以方便地存储和处理表格型数据。假设我们有一个包含学生信息的CSV文件,我们可以使用以下代码将其加载到DataFrame中:
python
df = pd.read_csv('student_data.csv')在加载数据后,我们可以使用pandas提供的方法对数据进行分类汇总。例如,我们可以按照学生的性别进行分组,并计算每个性别的学生人数:
python
gender_count = df.groupby('Gender')['Name'].count()
print(gender_count)此外,我们还可以使用pandas提供的聚合函数对数据进行更复杂的统计分析。例如,我们可以计算每个性别学生的平均年龄:
python
age_mean = df.groupby('Gender')['Age'].mean()
print(age_mean)除了分类汇总和统计分析,我们还可以使用matplotlib库对数据进行可视化。例如,我们可以使用柱状图展示不同性别学生的人数:
python
plt.bar(gender_count.index, gender_count.values)
plt.xlabel('Gender')
plt.ylabel('Number of Students')
plt.title('Gender Distribution')
plt.show()同样地,我们还可以使用其他类型的图表来展示数据,如折线图、散点图等。
在实际的数据分析过程中,我们可能需要对数据进行清洗、转换和预处理,以满足特定的分析需求。Python提供了丰富的数据处理工具,如数据清洗、缺失值处理、异常值检测等,使得数据分析过程更加高效和准确。
总之,Python作为一种强大的数据分析工具,可以帮助我们轻松地进行数据分类汇总与统计。通过掌握pandas、numpy和matplotlib等库的使用方法,我们可以更好地理解和应用数据,为实际工作和研究提供有力的支持。
一、Groupby分类统计
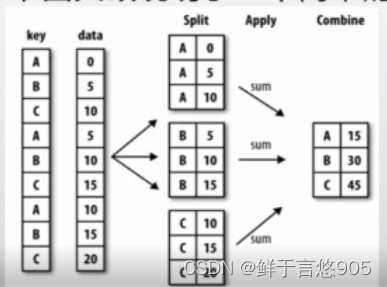
Hadley Wickham创造了一个用于表示分组运算的术语"split-apply-combine" (拆分-应用-合并)。第一个阶段,pandas对象中的数据会根据你所提供的一个或多个键被拆分(split)为多组。拆分操作是在对象的特定轴上执行的。
例如, DataFrame可以在其行(axis=0)或列(axis=1)上进行分组。然后,将一个函数应用(apply)到各个分组并产生一个新值。最后,所有这些函数的执行结果会被合并(combine)到最终的结果对象中。结果对象的形式一般取决于数据上所执行的操作。下图大致说明了一个简单的分组聚合过程。
语法
Pandas中的Groupby是一个强大的功能,用于将数据集按照指定的条件进行分组和聚合操作。它类似于SQL中的GROUP BY语句,可以对数据进行分组并对每个组进行统计、计算或其他操作。
下面是一些常见的使用Groupby的操作:
- 分组操作:通过指定一个或多个列名,将数据集分成不同的组。例如,可以将一个销售数据集按照不同的产品进行分组。
python
grouped = df.groupby('Product')- 聚合操作:对每个分组进行聚合操作,例如计算每个组的总和、平均值、最大值等。
python
grouped.sum() # 计算每个组的总和
grouped.mean() # 计算每个组的平均值
grouped.max() # 计算每个组的最大值- 过滤操作:根据条件过滤掉某些组或行。
python
grouped.filter(lambda x: x['Sales'].sum() > 1000) # 过滤掉销售总额小于1000的组- 转换操作:对每个分组进行转换操作,例如计算每个组的排名、百分位数等。
python
grouped.rank() # 计算每个组的排名
grouped.quantile(0.5) # 计算每个组的中位数- 组合操作:将多个分组的结果进行合并。
python
grouped1 = df.groupby('Product')
grouped2 = df.groupby('Category')
grouped1['Sales'].sum() + grouped2['Profit'].sum() # 将按产品和按类别分组的销售额和利润分别相加- 迭代操作:对每个分组进行迭代操作。
python
for name, group in grouped:
print(name)
print(group)这只是Groupby的一些常见用法,实际上还有很多其他功能和选项可以探索和使用。Pandas的Groupby功能非常灵活和强大,可以大大简化数据集的分析和处理过程。
按列分组
按列分组分为以下三种模式:
df.groupby(col),返回一个按列进行分组的groupby对象;df.groupby([col1,col2]),返回一个按多列进行分组的groupby对象;df.groupby(col1)[col2]或者df[col2].groupby(col1),两者含义相同,返回按列col1进行分组后col2的值;
首先生成一个表格型数据集:
python
import pandas as pd
import numpy as np
df = pd.DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),'data2':np.random.randn(5)})
df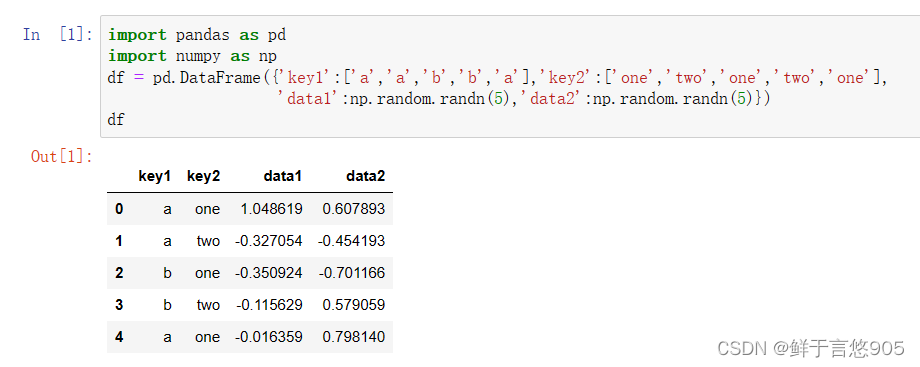
python
gg = df.groupby(df['key1'])
gg示例一
【例1】采用函数df.groupby(col),返回一个按列进行分组的groupby对象。
程序代码如下:
关键技术:变量gg是一个GroupBy对象。
它实际上还没有进行任何计算,只是含有一些有关分组键df['key1']的中间数据而已。换句话说,该对象已经有了接下来对各分组执行运算所需的一切信息。groupby对象不能直接打印输出,可以调用list函数显示分组,还可以对这个对象进行各种计算。
python
print(list(gg))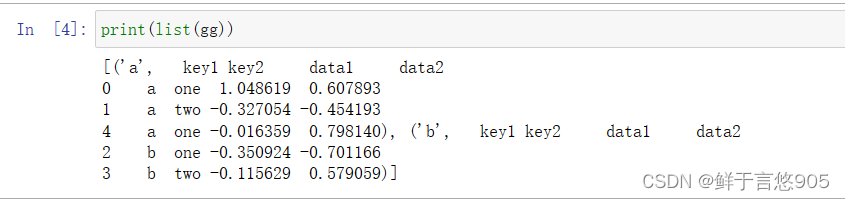
示例二
【例2】采用函数df.groupby([col1,col2]),返回一个按多列进行分组的groupby对象。
关键技术:对于由DataFrame产生的GroupBy对象,如果用一个(单个字符串)或一组(字符串数组)列名对其进行索引,就能实现选取部分列进行聚合的目的。
python
dfg = df.groupby(['key1','key2'])
print(list(dfg)) #分成a one a two b one b two 四组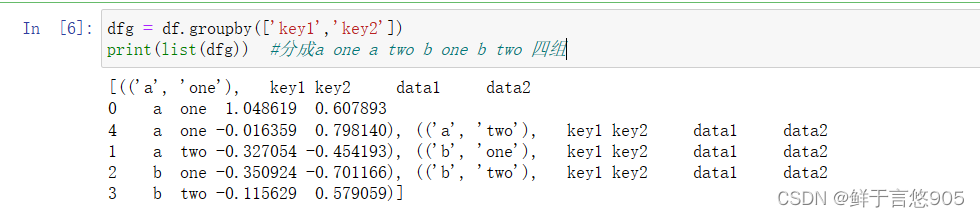
示例三
【例3】采用groupby函数针对某一列的值进行分组。
关键技术: df.groupby(col1)[col2]或者df[col2].groupby(col1),两者含义相同,返回按列col1进行分组后,col2的值。
python
grouped = df['data1'].groupby(df['key1'])
print(list(grouped))
python
grouped2 = df.groupby(df['key1'])['data1']
print(list(grouped2))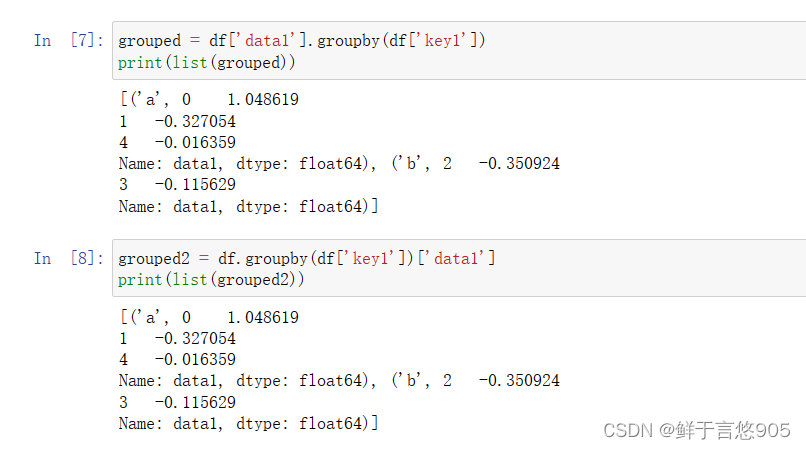
遍历各分组
GroupBy对象支持迭代,可以产生一组二元元组(由分组名和数据块组成)。
示例
【例4】对groupby对象进行迭代,并打印出分组名称和每组元素。
关键技术:采用for函数进行遍历, name表示分组名称, group表示分组数据。
程序代码如下所示:
python
for name,group in df.groupby(df['key1']):
print('name:',name)
print('group:',group)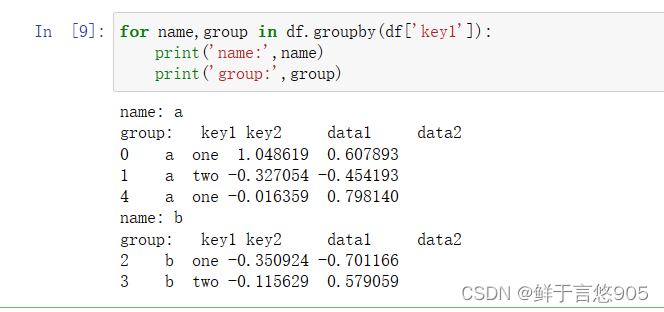
对于多重键的情况,元组的第一个元素将会是由键值组成的元组:
python
for (k1,k2),group in df.groupby(['key1','key2']):
print((k1,k2))
print(group)
当然,你可以对这些数据片段做任何操作。有一个你可能会觉得有用的运算,将这些数据片段做成一个字典:
python
pieces = dict(list(df.groupby('key1')))
print(pieces)
pieces['b']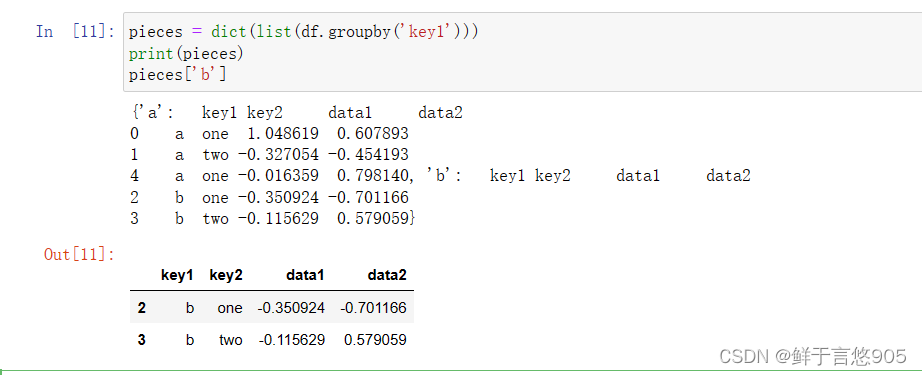
groupby默认是在axis=0上进行分组的,通过设置也可以在其他任何轴上进行分组。拿上面例子中的df来说,我们可以根据dtype对列进行分组:
python
print(df.dtypes)
grouped = df.groupby(df.dtypes,axis = 1)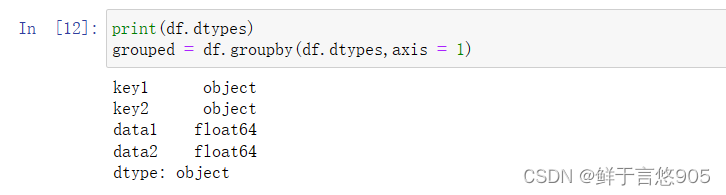
可以如下打印分组:
python
for dtype,group in grouped:
print(dtype)
print(group)
使用字典和Series分组
除数组以外,分组信息还可以其他形式存在。
示例
【例5】利用字典或series进行分组。
关键技术:可以将定义的字典传给a=groupby,来构造数组,也可以直接传递字典。
程序代码如下所示:
python
people = pd.DataFrame(np.random.randn(5,5),columns = ['a','b','c','d','e'],index = ['Joe','Steve','Wes','Jim','Travies'])
people .iloc[2:3,[1,2]] = np.nan
people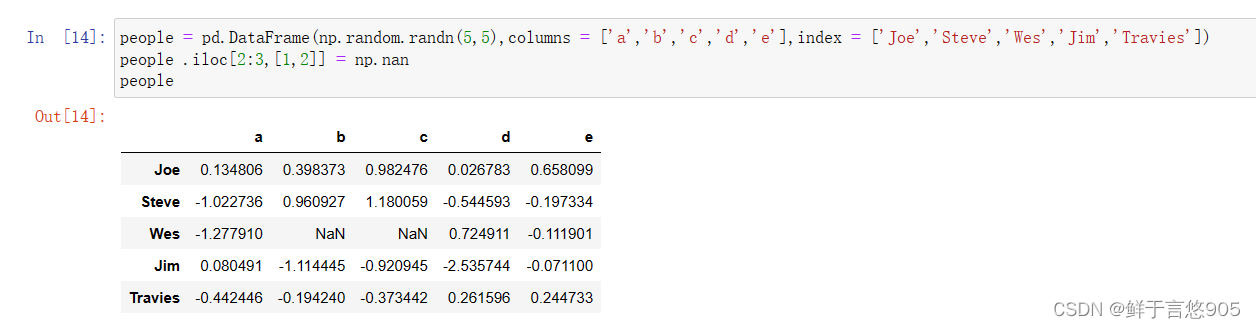
现在,假设已知列的分组关系,并希望根据分组计算列的和:
python
mapping = {'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'}
现在,你可以将这个字典传给groupby,来构造数组,但我们可以直接这传递字典:
python
by_cloumn = people.groupby(mapping,axis = 1)
by_cloumn.sum()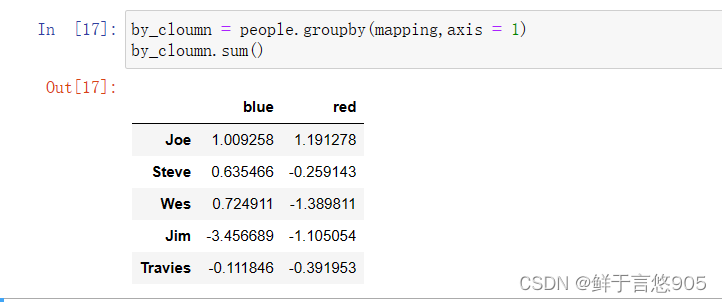
Series也有同样的功能,它可以被看做一个固定大小的映射:
python
map_Series = pd.Series(mapping)
print(map_Series)
python
people.groupby(map_Series,axis = 1).count()
使用函数分组
比起使用字典或Series,使用Python函数是一种更原生的方法定义分组映射。
示例
【例6】以上一小节的DataFrame为例,使用len函数计算一个字符串的长度,并用其进行分组。
关键技术:任何被当做分组键的函数都会在各个索引值上被调用一次,其返回值就会被用作分组名称。
程序代码如下所示:
python
people.groupby(len).sum()
将函数跟数组、列表、字典、Series混合使用也不是问题,因为任何东西在内部都会被转换为数组
python
key_list = ['one','one','one','two','two']
people.groupby([len,key_list]).min()
二、数据聚合
聚合指的是任何能够从数组产生标量值的数据转换过程,比如mean、count、min以及sum等函数。你可能想知道在GroupBy对象上调用mean()时究竟发生了什么。
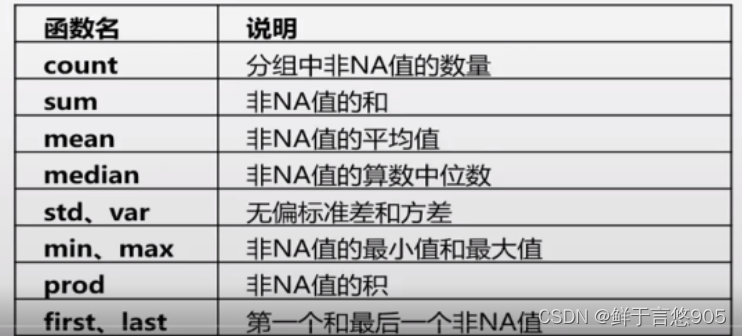
许多常见的聚合运算(如表5.1所示)都有进行优化。然而,除了这些方法,你还可以使用其它的。
下表是经过优化的groupby方法:
在使用groupby进行分组后,可以使用以下聚合函数进行数据聚合:
count():计算每个分组中的非缺失值的数量。sum():计算每个分组中的所有值的和。mean():计算每个分组中的所有值的平均值。median():计算每个分组中的所有值的中位数。min():计算每个分组中的所有值的最小值。max():计算每个分组中的所有值的最大值。std():计算每个分组中的所有值的标准差。var():计算每个分组中的所有值的方差。size():计算每个分组中的元素数量。agg():自定义聚合函数,可以使用numpy函数或自己定义的函数进行聚合。
这些聚合函数可以应用于单个列或多个列,也可以同时应用于多个列。
groupby的聚合函数
首先创建一个dataframe对象:
示例一
【例8】使用groupby聚合函数对数据进行统计分析。
python
df = pd.DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),'data2':np.random.randn(5)})
df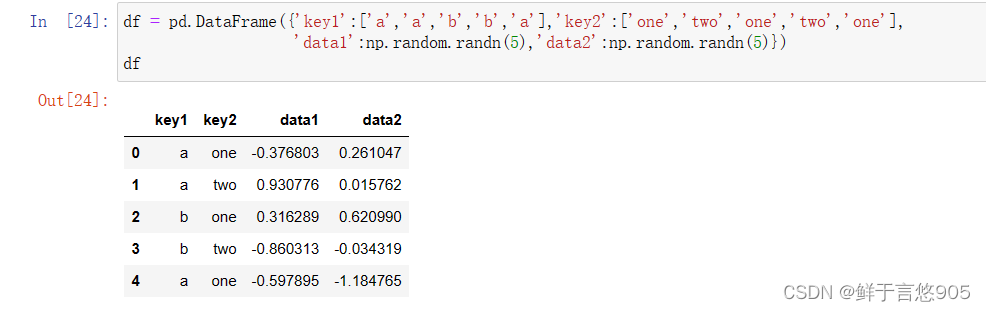
关键技术:采用describe()函数求各种统计值:
python
df['data1'].groupby(df['key1']).describe()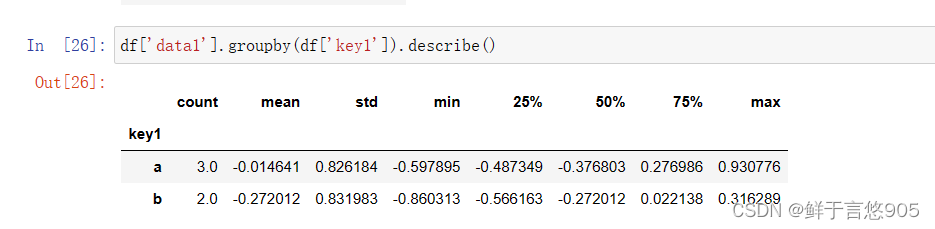
关键技术: size跟count的区别是: size计数时包含NaN值,而count不包含NaN值。


示例二
【例9】采用agg()函数对数据集进行聚合操作。
关键技术:采用agg()函数进行聚合操作。
agg函数也是我们使用pandas进行数据分析过程中,针对数据分组常用的一条函数。如果说用groupby进行数据分组,可以看做是基于行(或者说是index)操作的话,则agg函数则是基于列的聚合操作。
首先建立例数据集:
python
cities = pd.DataFrame(np.random.randn(5,5)
,columns = ['a','b','c','d','e'],
index = ['shenzheng' ,'guangzhou','beijing','nanjing','haerbin'])
cities .iloc[2:4,2:4] = np.nan
cities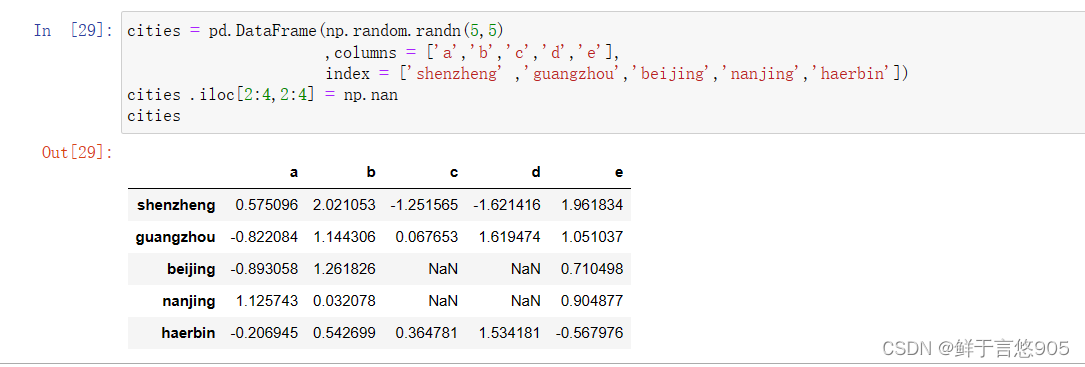
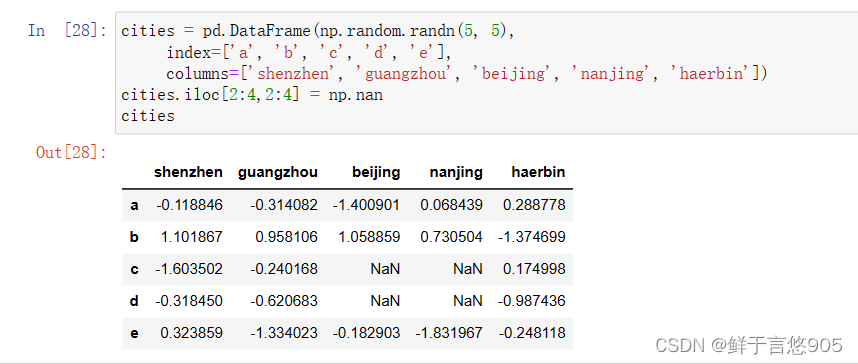
采用agg()函数计算各个城市的求和与均值:
python
cities.agg(['sum','mean'])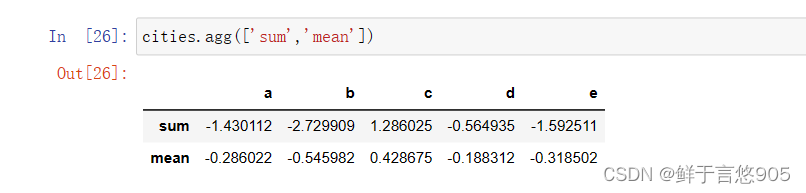
python
cities[['shenzhen','guangzhou','beijing','nanjing','haerbin']].agg(['sum','mean'])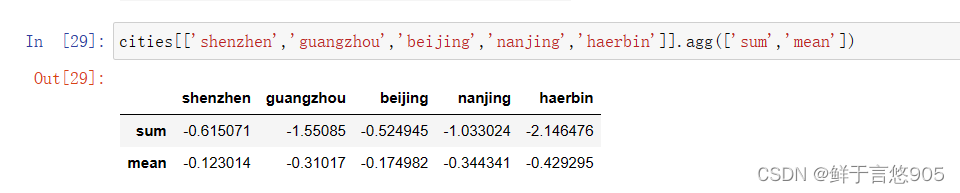
采用agg()函数针对不同的城市,使用不同的聚合函数:
python
cities.agg({'shenzhen':['sum'],'beijing':['mean'],'nanjing':['sum','mean']})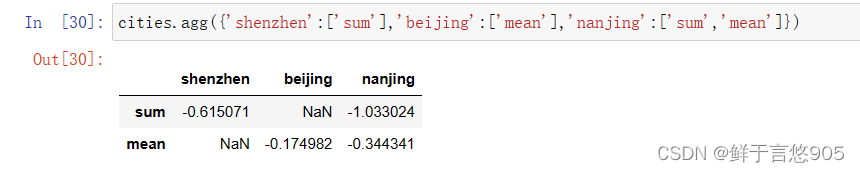
逐列及多函数应用
示例一
【例10】同时使用groupby函数和agg函数进行数据聚合操作。
关键技术: groupby函数和agg函数的联用。
在我们用pandas对数据进行分组聚合的实际操作中,很多时候会同时使用groupby函数和agg函数。
首先创建一个dataframe对象:
python
df = pd.DataFrame({'Country':['China','China', 'India', 'India', 'America', 'Japan', 'China', 'India'],
'Income':[10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000],
'Age':[50, 43, 34, 40, 25, 25, 45, 32]})
df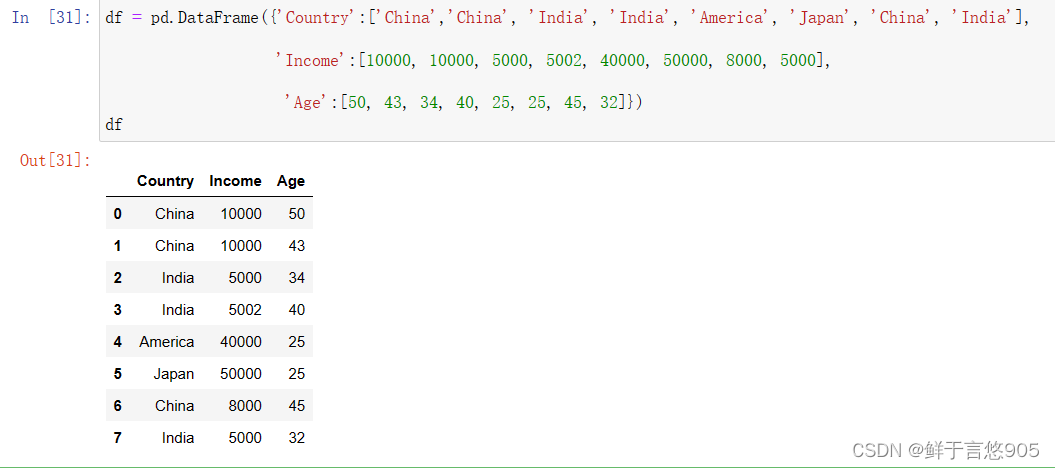
下面我们同时使用groupby和agg函数对该数据表进行分组聚合操作。
python
df_inc=df.groupby('Country').agg(['min','max','mean'])
df_inc
多重函数以字典形式传入:
python
df_age={'Age':['max','min','mean']}
df.groupby('Country').agg(df_age)
在我们对数据进行聚合的过程中,除了使用sum()、max ()等系统自带的聚合函数之外,大家也可以使用自己定义的函数,使用方法也是一样的。
python
df = pd.DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),'data2':np.random.randn(5)})
df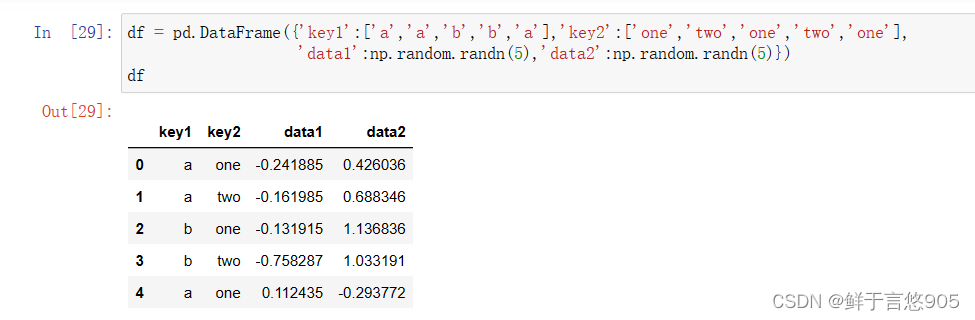
python
grouped = df.groupby(df['key1'])
print(list(grouped))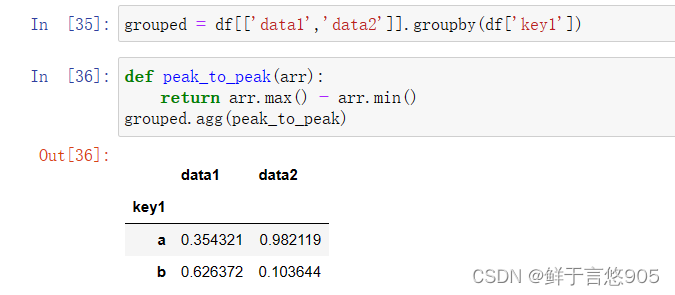
示例二
【例11】同时使用groupby函数和agg函数进行数据聚合操作。并且一次应用多个函数。
关键技术:对于自定义或者自带的函数都可以用agg传入,一次应用多个函数。传入函数组成的list。所有的列都会应用这组函数。
使用read_csv导入数据之后,我们添加了一个小费百分比的列tip_pct: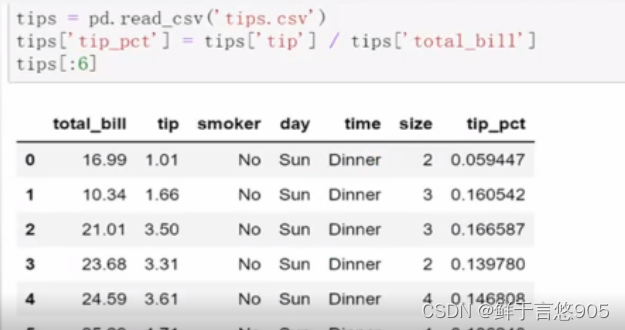
如果希望对不同的列使用不同的聚合函数,或一次应用多个函数,将通过下面的例来进行展示。首先,根据day和smoker对tips进行分组,然后采用agg()方法一次应用多个函数。
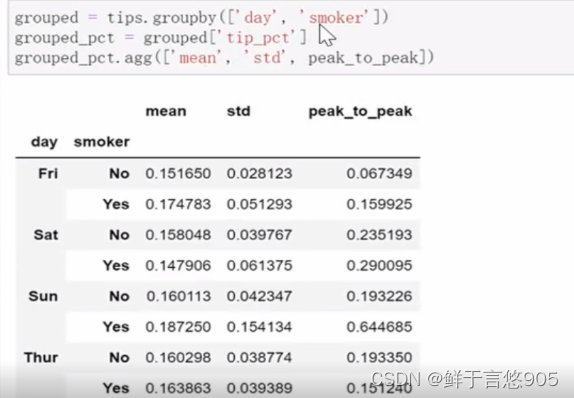
如果传入一组函数或函数名,得到的DataFrame的列就会以相应的函数命名。如果不想接收GroupBy自动给出的那些列名,那么如果传入的是一个由(name,function)元组组成的列表,则各元组的第一个元素就会用作DataFrame的列名(可以将这种二元元组列表看做一个有序映射)
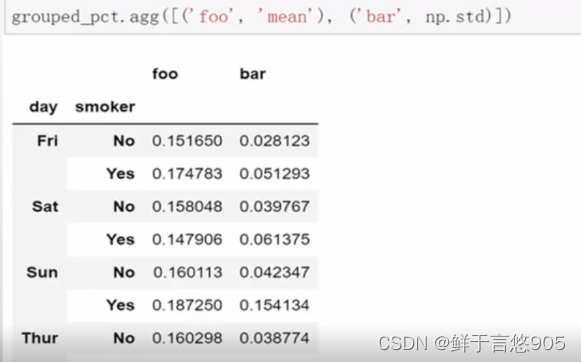
对于DataFrame,你可以定义一组应用于全部列的一组函数,或不列应用不同的函数。
假设我们想要对tip_pct和total_bill列计算三个信息:
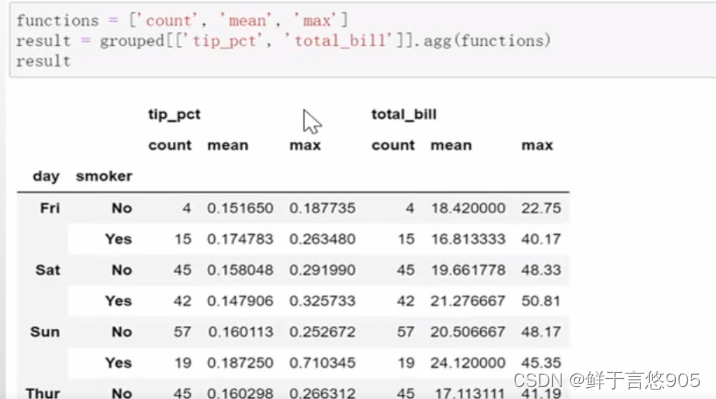
上面例子的结果DataFrame拥有层次化的列,这相当于分别对各列进行聚合,然后将结果组装到一起,使用列名用作keys参数:
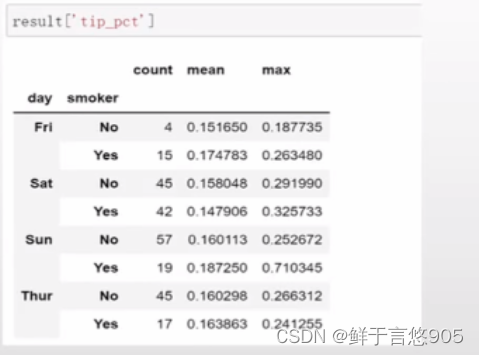
这里也可以传入带有自定义名称的一组元组: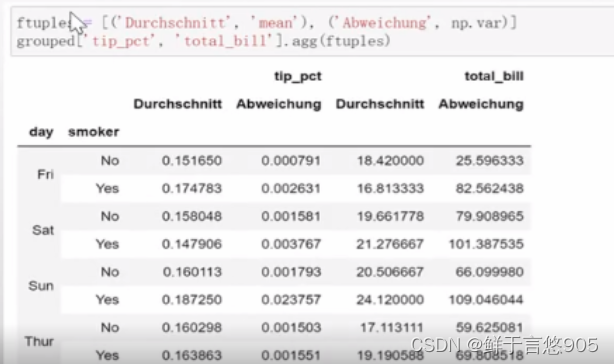
假设你想要对一个列或不同的列应用不同的函数。具体的办法是向agg传入一个从列名映射到函数的字典:
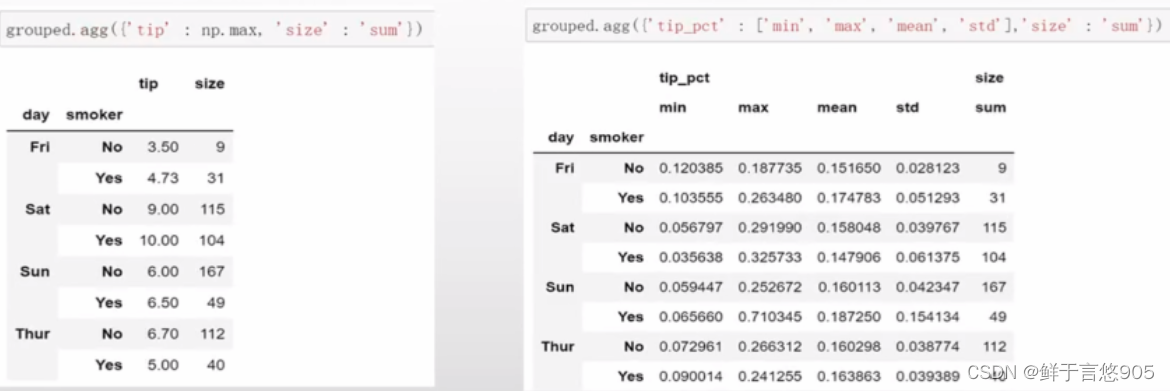
只有将多个函数应用到至少一列时,DataFrame才会拥有层次化的列
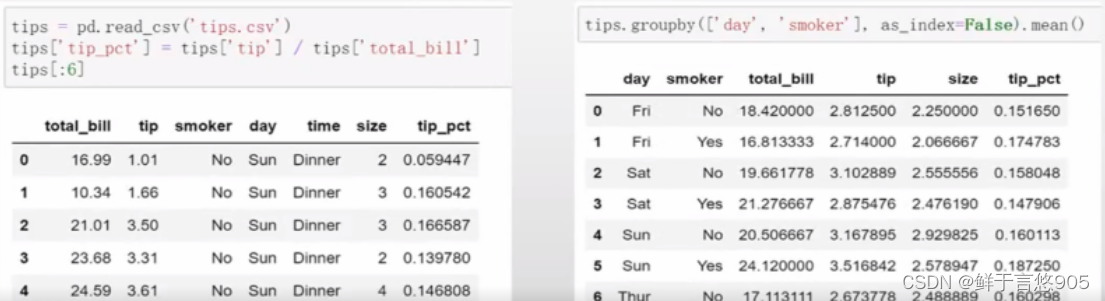
返回不含行索引的聚合数据
到目前为止,所有例中的聚合数据都有由唯一的分组键组成的索引(可能还是层次化的)。由于并不总是需要如此,所以你可以向groupby传入as_index=False以禁用该功能。
示例
【例12】采用参数as_index返回不含行索引的聚合数据。
关键技术:可以向groupby传入as_index=False以禁用索引功能。
三、一般性的"拆分-应用-合并"
最通用的GroupBy方法是apply,本节将重点讲解它该函数。
Apply函数会将待处理的对象拆分成多个片段,然后对各片段调用传入的函数,最后尝试将各片段组合到一起。
示例一
【例13】采用之前的小费数据集,根据分组选出最高的5个tip-pct值。
关键技术:在调用某对象的apply方法时,其实就是把这个对象当作参数传入到后面的匿名函数中。
首先,编写一个选取指定列具有最大值的行的函数:
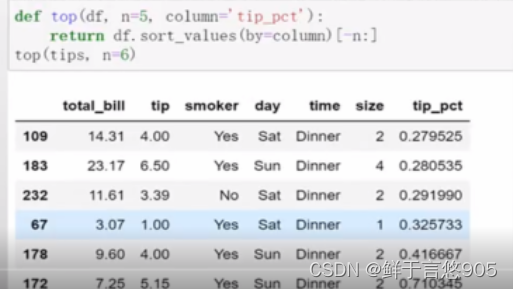
现在,如果对smoker分组并用该函数调用apply,就会得到: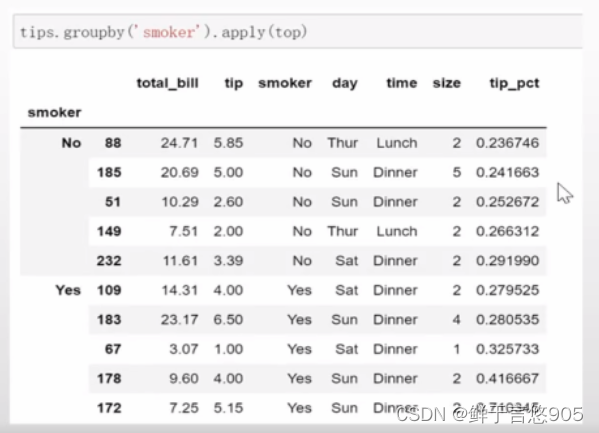
top函数在DataFrame的各个片段调用,然后结果由pandas.concat组装到一起,并以分组名称进行了标记。于是,最终结果就有了一个层次化索引,其内层索引值来自原DataFrame。
示例二
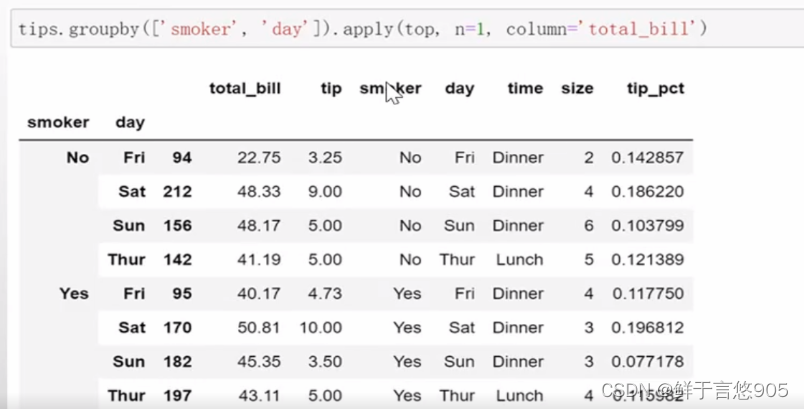
【例14】在apply函数中设置其他参数和关键字。
关键技术:如果传给apply的函数能够接受其他参数或关键字,则可以将这些内容放在函数名后面一并传入:
示例三
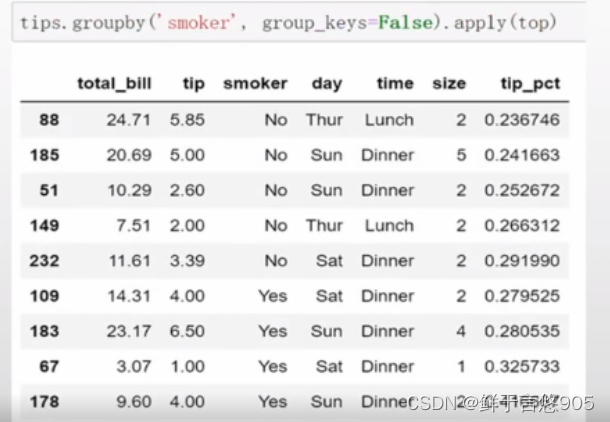
【例15】在apply函数中设置禁止分组键。
关键技术:分组键会跟原始对象的索引共同构成结果对象中的层次化索引。将group_keys= False传入groupby即可禁止该效果。
示例四
【例16】用特定于分组的值填充缺失值
对于缺失数据的清理工作,有时你会用dropna将其替换掉,而有时则可能会希望用一个固定值或由数据集本身所衍生出来的值去填充NA值。
关键技术:假设你需要对不同的分组填充不同的值。可以将数据分组,并使用apply和一个能够对各数据块调用fillna的函数即可。
下面是一些有关美国几个州的示例数据,这些州又被分为东部和西部:
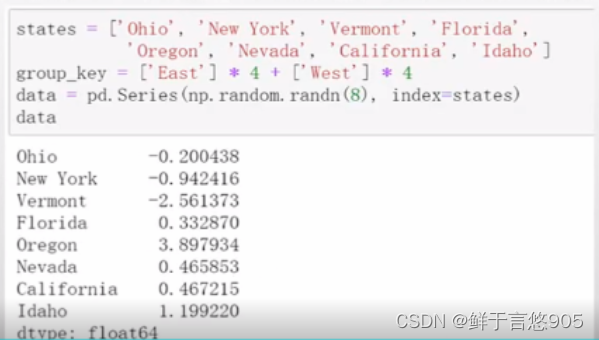
['East'] * 4产生了一个列表,包括了['East']中元素的四个拷贝。将这些列表串联起来。

我们可以用分组平均值去填充NA值:
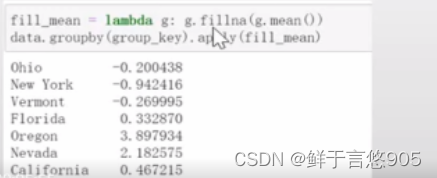
也可以在代码中预定义各组的填充值。
由于分组具有一个name属性,所以我们可以拿来用一下: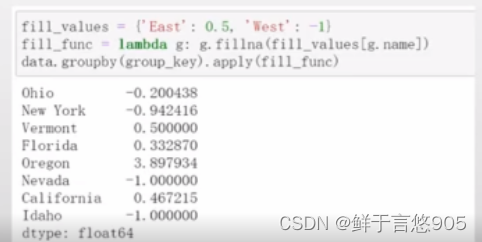
四、数据透视表与交叉表
数据透视表
pivot()的用途就是,将一个dataframe的记录数据整合成表格(类似Excel中的数据透视表功能),pivot_table函数可以产生类似于excel数据透视表的结果,相当的直观。其中参数index指定"行"键,columns指定"列"键。
Pandas是一个强大的数据分析工具,而pivot()函数是Pandas中的一个重要函数,用于数据透视操作。它可以根据某些列的值将数据重塑为新的形式,使之更易于分析和理解。下面详细解释pivot()函数的用法和参数。
pivot()
pivot()函数的形式如下:
python
DataFrame.pivot(index=None, columns=None, values=None)参数说明:
index:指定数据透视后的行索引。可以是单个列名、多个列名组成的列表或者数组,表示数据透视后的行的唯一标识。columns:指定数据透视后的列索引。可以是单个列名、多个列名组成的列表或者数组,表示数据透视后的列的唯一标识。values:指定数据透视后的数值。可以是单个列名或者多个列名组成的列表或者数组,表示数据透视后的数值的来源。
使用示例
假设我们有一个包含姓名、性别、年龄和成绩的数据集,如下所示:
python
import pandas as pd
data = {
'姓名': ['张三', '李四', '王五', '赵六', '钱七'],
'性别': ['男', '男', '女', '男', '女'],
'年龄': [20, 21, 19, 22, 20],
'成绩': [80, 78, 85, 75, 90]
}
df = pd.DataFrame(data)我们可以使用pivot()函数将这个数据集进行透视,例如将姓名作为行索引,性别作为列索引,成绩作为数值:
python
df_pivot = df.pivot(index='姓名', columns='性别', values='成绩')运行结果如下所示:
python
性别 女 男
姓名
李四 NaN 78
张三 NaN 80
赵六 NaN 75
钱七 90 NaN
王五 85 NaN在运行pivot()函数后,我们可以看到结果是一个新的DataFrame对象,行索引为姓名,列索引为性别,数值为成绩。对于没有对应数值的单元格,Pandas会用NaN填充。
总结
Pandas的pivot()函数是一个非常有用的数据透视工具,可以根据指定的行、列和数值对数据进行重塑操作,方便数据分析和统计计算。通过合理使用pivot()函数,可以快速实现数据透视的功能。
示例
【例17】对于DataFrame格式的某公司销售数据workdata.csv,存储在本地的数据的形式如下,请利用Python的数据透视表分析计算每个地区的销售总额和利润总额。
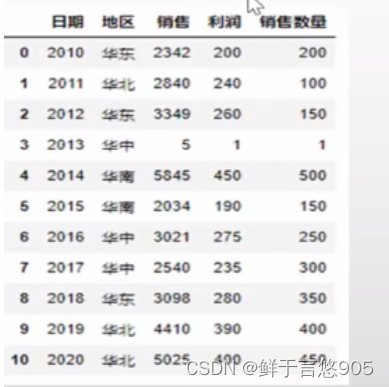
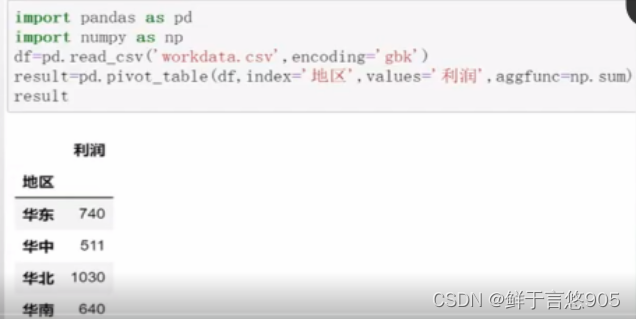
关键技术:在pandas中透视表操作由pivot_table()函数实现,其中在所有参数中,values、index、 columns最为关键,它们分别对应Excel透视表中的值、行、列。
程序代码如下所示:
交叉表
交叉表采用crosstab函数,可是说是透视表的一部分,是参数aggfunc=count情况下的透视表。
pandas的crosstab是一个用于计算交叉频率表的函数。交叉频率表是一种展示两个或多个变量之间关系的统计表格。pandas的crosstab函数可以根据给定的数据和索引来计算这些交叉频率表。
crosstab()
crosstab函数的语法如下:
python
pandas.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name='All', dropna=True, normalize=False)参数说明
index:设置交叉表的行索引。columns:设置交叉表的列索引。values:可选参数,用于填充交叉表的数据。rownames:可选参数,用于设置交叉表的行名称。colnames:可选参数,用于设置交叉表的列名称。aggfunc:可选参数,用于设置交叉表的聚合函数。margins:可选参数,用于计算行和列的总计。margins_name:可选参数,用于设置总计的名称。dropna:可选参数,用于控制是否删除缺失值。normalize:可选参数,用于控制是否对交叉表进行标准化。
下面是一个示例,展示了如何使用pandas的crosstab函数计算交叉频率表:
python
import pandas as pd
# 创建示例数据
data = {
'Gender': ['Male', 'Female', 'Male', 'Female', 'Male', 'Female'],
'AgeGroup': ['18-25', '26-35', '18-25', '26-35', '36-45', '36-45']
}
df = pd.DataFrame(data)
# 计算交叉频率表
cross_tab = pd.crosstab(df['Gender'], df['AgeGroup'])
print(cross_tab)输出结果如下:
python
AgeGroup 18-25 26-35 36-45
Gender
Female 1 1 1
Male 1 1 1这个交叉频率表展示了不同性别和年龄组的人数。
crosstab函数还可以使用其他参数来进一步定制交叉频率表,例如设置行和列的名称、使用聚合函数计算交叉表的值等。你可以根据具体需求来使用这些参数。
示例一
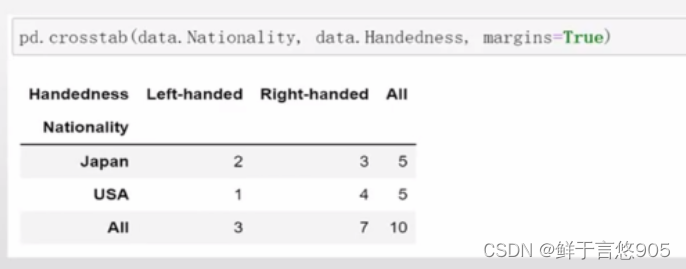
【例19】根据国籍和用手习惯对这段数据进行统计汇总。
关键技术:频数统计时,使用交叉表(crosstab)更方便。传入margins=True参数(添加小计/总计) ,将会添加标签为ALL的行和列。
首先给出数据集:
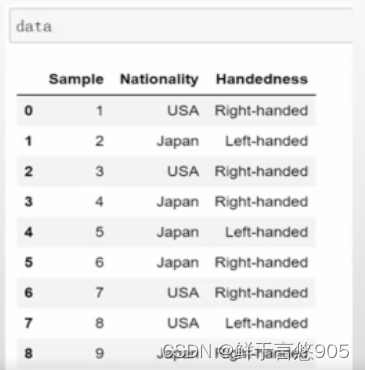
对不同国家的用手习惯进行统计汇总
示例二
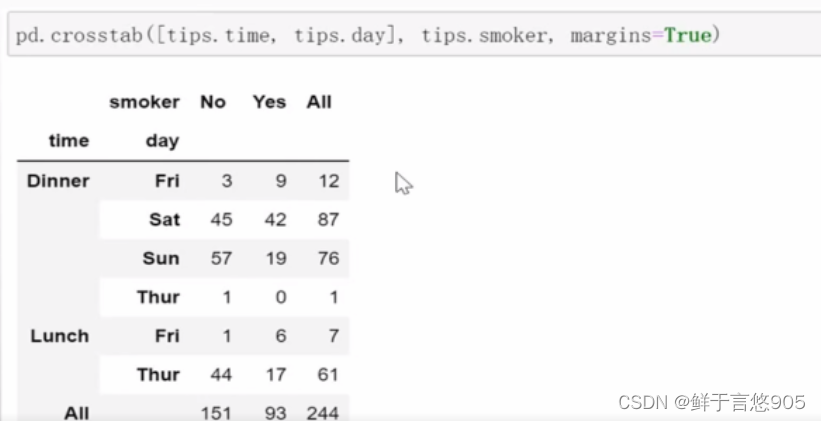
【例20】采用小费数据集,对time和day列同时进行统计汇总。
关键技术: crosstab的前两个参数可以是数组或Series,或是数组列表。
五、数据采样
resample()是pandas库中用于时间序列数据重采样的一个方法。它可以改变时间序列数据的频率,将数据从高频率转换为低频率(如从天到月),或者将数据从低频率转换为高频率(如从月到天)。重采样可以帮助我们对数据进行更好的分析和可视化。
resample()
resample()方法的语法如下:
python
DataFrame.resample(rule, axis=0, closed=None, label=None, convention='start', kind=None, loffset=None, base=0, on=None, level=None, origin='start_day', offset=None)参数说明
rule:重采样规则,可以是字符串(例如'D'表示按天重采样,'M'表示按月重采样),也可以是pandas的一个偏移字符串(例如pandas.DateOffset对象)。axis:指定重采样的轴,默认为0,表示对行进行重采样。closed:指定左闭右闭区间还是左闭右开区间,默认为None,表示右闭。label:指定重采样结果的标签的位置,默认为None,表示重采样结果是标签区间的左边界。convention:指定重采样结果的一个整数倍数的位置,默认为'start',表示结果是一个标签区间的开始位置。kind:指定重采样方法,默认为None,表示使用默认方法,可以是'shill','pad', 'ffill', 'bfill'等。loffset:指定结果的行索引或列名向前或向后偏移的时间量,默认为None。base:指定抽样间隔的基数,默认为0。on:指定重采样的列,默认为None,表示对整个DataFrame进行重采样。level:指定重采样的行索引级别或列级别,默认为None。origin:指定重采样结果的时间标签,默认为'start_day',表示时间标签为开始日期。offset:指定重采样时对时间频率的偏移。
下面我们来看几个具体的例子:
首先,我们创建一个示例DataFrame,包含日期和销售额数据:
python
import pandas as pd
import numpy as np
data = {'date': pd.date_range('2020-01-01', periods=10, freq='D'),
'sales': np.random.randint(1, 100, size=10)}
df = pd.DataFrame(data)- 按月重采样:
python
df.resample('M', on='date').sum()结果如下:
python
sales
date
2020-01-31 149
2020-02-29 192- 按周重采样并求平均值:
python
df.resample('W', on='date').mean()结果如下:
python
sales
date
2020-01-05 34.833333
2020-01-12 57.333333
2020-01-19 23.000000
2020-01-26 46.000000
2020-02-02 84.500000- 按季度重采样并求最小值和最大值:
python
df.resample('Q', on='date').agg({'sales': ['min', 'max']})结果如下:
python
sales
min max
date
2020-03-31 5 91通过上面的例子,我们可以看到resample()方法可以帮助我们方便地对时间序列数据进行重采样,并进行各种统计计算。详细的用法可以参考pandas官方文档。
示例一
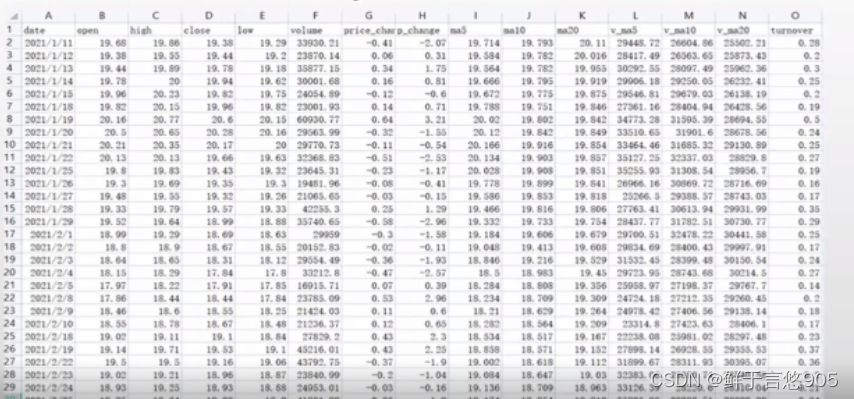
【例21】对于从tushare数据库平台获取到的股票交易数据集stockdata.csv,包括股票的开盘价格,最高价格,收盘价格,最低价格,成交量等特征,股票数据采集时间为2021/01/11-2022/01/10,默认采集时间以"天"为单位,请利用Python对数据进行以"周"为单位的采样

示例二
【例22】对于上面股票数据集文件stockdata.csv,请利用Python对数据进行以"月"为单位的采样。
关键技术:可以通过resample()函数对数据进行采样,并设置参数为'M',表示以"月"为单位的采样。程序代码如下所示
输出结果如下所示:
对于上面股票数据集文件stockdata.csv,请利用Python对数据进行以"年"为单位的采样。

输出结果如下所示:
