1. 引言
近年来人工智能领域不断进步,大语言模型的崛起引领了自然语言处理的革命。这些参数量巨大的预训练模型,凭借其在大规模数据上学习到的丰富语言表示,为我们带来了前所未有的文本理解和生成能力。然而,要使这些通用模型在特定任务上发挥出色,还需借助微调技术。大语言模型的微调技术已经成为自然语言处理领域的一个焦点,其不断的演化和创新正引领着我们进入一个更加精细、个性化的文本处理时代。
在本文中,我们将选取目前大语言模型热点任务------代码生成,结合 StarCoder 模型微调实践介绍高效微调方法------LoRA。
2. LoRA 微调原理
论文:LoRA: Low-Rank Adaptation of Large Language Models
LoRA 基于大模型的内在低秩特性,增加旁路矩阵来模拟全参数微调,是目前最通用、效果最好的微调方法之一,而且能和其它参数高效微调方法有效结合。利用该方法对 175B GPT-3 微调,需要训练更新的参数量可以小到全量微调参数量的 0.01%。
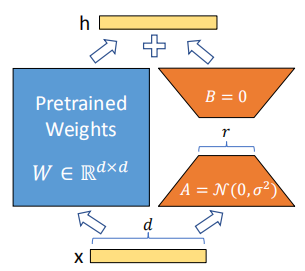
图1. LoRA原理
上图为 LoRA 的实现原理,其实现流程为:
-
在原始预训练语言模型旁边增加一个旁路,做降维再升维的操作来模拟内在秩;
-
用随机高斯分布初始化 A,用零矩阵初始化B,训练时固定预训练模型的参数,只训练矩阵 A 与矩阵 B ;
-
训练完成后,将 B 矩阵与 A 矩阵相乘后合并预训练模型参数作为微调后的模型参数。
研究表明,Transformer 等神经网络包含许多执行矩阵乘法的密集层,这些权重通常具有满秩。预训练的语言模型具有较低的"本征维度(Instrinsic Dimension)",并且可以和完整参数空间一样进行有效学习。受此启发,本文在微调过程中假设权重的更新也具有较低的"本征维度"。对于预训练模型的权重矩阵 ,通过低秩分解(Low-Rank Decomposition)来表示约束其更新。训练过程中 被固定不再进行梯度更新,只训练 和 ,其中 。训练结束后,更新参数为 。对于输入 ,模型的前向传播过程更新为 。
由于模型整体参数量不变,所以不会降低推理时的性能。作者通过实验比较了在内容理解任务、生成任务上的效果,相比全量微调参数量显著降低,性能上持平甚至超过,相比其他高效微调方法,增加参数量不会导致性能下降。需要注意的是此方法对低秩矩阵的秩数和目标模块的选择比较敏感,可能影响模型的性能和稳定性。使用LoRA微调有以下几个细节:
-
对哪些参数进行微调:基于 Transformer 结构,LoRA 只对每层的 Self-Attention 的部分进行微调,有 四个映射层参数可以进行微调。需要注意不同模型参数名称不同,像 StarCoder 模型 Multi-query 结构的 attention 层对应的参数名称是
attn.c_attn,attn.c_proj -
Rank® 的选取:Rank 的取值作者对比了 1-64,效果上 Rank 在 4-8 之间最好,再高并没有效果提升。不过论文的实验是面向下游单一监督任务的,因此在指令微调上根据指令分布的广度,Rank选择还是需要在 8 以上的取值进行测试。
-
alpha 参数选取:alpha 其实是个缩放参数,训练后权重 merge 时的比例为
alpha/r -
初始化:矩阵A是 Uniform 初始化,B 是零初始化,这样最初的 lora 权重为 0,所以 lora 参数是从头学起,并没有那么容易收敛。
3. LoRA 微调实践
本节以 StarCoder 微调为例,介绍使用 LoRA 微调的实践过程。
首先,StarCoder 是使用 86 种编程语言的 1 万亿个 token 训练,并在另外 35billion Python token 上微调出的模型,专注于解决编程问题,模型结构为:"GPTBigCodeForCausalLM",40层 decoder-only Transformer,Attention 层结构为 Multi-query,参数量约 15.5B。
3.1 环境配置
-
实例环境:A800 + python3.8 + torch2.0 + CUDA11.6
-
python环境:主要坑在 transforemrs 和 peft,这两个包建议使用"Development Mode"安装
环境中主要包的版本:
tqdm==4.65.0
transformers=4.31.0.dev0
peft=0.4.0.dev0
datasets==2.11.0
huggingface-hub==0.13.4
accelerate==0.18.0 3.2 模型加载
以下代码主要整合自 alpaca-lora 项目和 StarCoder 的 finetune 项目。其实 LoRA 微调的代码本身并不复杂,但是对于如何加速大模型训练,如何以时间换空间的降低显存占用处理值得学习。模型初始化代码如下,get_peft_model 会初始化 PeftModel 把原模型作为 base 模型,并在各个 self-attention 层加入 LoRA 层,同时改写模型 forward 的计算方式。主要说下 load_in_8bit,prepare_model_for_int8_training 和 get_peft_model 分别做了哪些操作。
from accelerate import Accelerator
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer, Trainer
model = AutoModelForCausalLM.from_pretrained(
args.model_path,
use_auth_token=True,
use_cache=True,
load_in_8bit=True,
device_map={"": Accelerator().process_index},
)
model = prepare_model_for_int8_training(model)
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules = ["attn.c_proj", "attn.c_attn"]
)
model = get_peft_model(model, lora_config) 模型加载时,load_in_8bit=True 的 8bit 量化优化的是静态显存,是 bitsandbytes 库赋予的能力,会把加载模型转化成混合 8bit 的量化模型。模型量化本质是对浮点参数进行压缩的同时,降低压缩带来的误差。8bit quantization是把原始 fp32(4字节)压缩到 int8(1字节)也就是 1/4 的显存占用。我们主要关注 attention 层的情况:
Parameter name: transformer.h.0.ln_1.weight
Data type: torch.float16
Parameter name: transformer.h.0.ln_1.bias
Data type: torch.float16
Parameter name: transformer.h.0.attn.c_attn.weight
Data type: torch.int8
Parameter name: transformer.h.0.attn.c_attn.bias
Data type: torch.float16
Parameter name: transformer.h.0.attn.c_proj.weight
Data type: torch.int8
Parameter name: transformer.h.0.attn.c_proj.bias
Data type: torch.float16 通过第一层模型可以看出,这一步,attention 层 c_attn 和 c_proj 的 weight 设为 int8,其他为 fp16。
下面,prepare_model_for_int8_training 是对在 LoRA 微调中使用 LLM.int8() 进行了适配用来提高训练的稳定性,主要包括
-
layer norm 层保留 fp32 精度
-
输出层保留 fp32 精度保证解码时随机 sample 的差异性
操作后区别如下:
Parameter name: transformer.h.0.ln_1.weight
Data type: torch.float32
Parameter name: transformer.h.0.ln_1.bias
Data type: torch.float32
Parameter name: transformer.h.0.attn.c_attn.weight
Data type: torch.int8
Parameter name: transformer.h.0.attn.c_attn.bias
Data type: torch.float32
Parameter name: transformer.h.0.attn.c_proj.weight
Data type: torch.int8
Parameter name: transformer.h.0.attn.c_proj.bias
Data type: torch.float32 prepare_model_for_int8_training 还设置了 gradient_checkpointing=True,这是一个时间换空间的技巧。gradient checkpoint 的实现是在前向传播的过程中使用 torch.no_grad() 不存储中间激活值,降低动态显存的占用,而只保存输入和激活函数,当进行反向传播的时候,会重新获取输入并计算激活值用于梯度计算。因此前向传播会计算两遍,所以需要更多的训练时间。
第三步 get_peft_model 的操作后,区别如下:
Parameter name: base_model.model.transformer.h.0.attn.c_attn.lora_A.default.weight
Data type: torch.float32
Require grads: True
Parameter name: base_model.model.transformer.h.0.attn.c_attn.lora_B.default.weight
Data type: torch.float32
Require grads: True
Parameter name: base_model.model.transformer.h.0.attn.c_proj.lora_A.default.weight
Data type: torch.float32
Require grads: True
Parameter name: base_model.model.transformer.h.0.attn.c_proj.lora_B.default.weight
Data type: torch.float32
Require grads: True 在 attention 层的 c_attn 和 c_proj 添加 LoRA 层,数据类型为 fp32,并且需要梯度计算。
3.3 模型训练
模型训练的代码如下,和常规训练基本相同,需要注意模型存储和混合精度训练。StarCoder 项目推荐使用的数据集是 stack-exchange-instruction。Stack Exchange 是一个著名的问答网站,涉及不同领域的主题,用户可以在这里提出问题并从其他用户那里获得答案。这些答案根据其质量进行评分和排名。此数据集构建的即为问答对集合。可以在该数据集上微调语言模型,激活模型的问答技能。
train_dataset, eval_dataset = create_datasets(tokenizer, args)
training_args = TrainingArguments(
output_dir=args.output_dir,
evaluation_strategy="steps",
max_steps=args.max_steps,
eval_steps=100,
save_steps=100,
per_device_train_batch_size=1,
learning_rate=5e-6,
gradient_accumulation_steps=16,
fp16=True,
report_to="wandb",
)
trainer = Trainer(model=model, args=training_args, train_dataset=train_data, eval_dataset=val_data, callbacks=[SavePeftModelCallback, LoadBestPeftModelCallback)
trainer.train()
model.save_pretrained(os.path.join(args.output_dir, "final_checkpoint/")) (1)模型存储
需要注意 PeftModel 重写了原始 model 的 save_pretrained 函数,只把 LoRA 层的权重进行存储,因此 model.save_pretrained 只会存储 LoRA 权重。
(2)混合精度训练
实现原理是并非所有变量都需要全精度存储,如果把部分中间变量转化成半精度,则计算效率会大幅提升,加上一些 GPU 对 fp16 计算做了优化,吞吐上比全精度会快 2~5 倍。不过只使用半精度训练会带来量化误差,所以混合精度训练前向传播时,模型权重、激活值和梯度都使用 fp16 进行存储,同时会拷贝一份模型权重以 fp32 存储,反向传播 optimizer 更新时会更新 fp32 的参数。因此其并不会节省内存,只会提高模型训练速度,同时使精度不下降太多。
3.4 merge 权重
LoRA 权重和原始模型权重进行合并,合并后的参数会存储成新的 bin 文件,然后和加载常规模型一样加载合并后的模型参数进行推理,不会引入推理延迟,权重合并关键代码如下:
base_model = AutoModelForCausalLM.from_pretrained(
args.base_model_name_or_path,
load_in_8bit=False,
torch_dtype=torch.float16,
device_map={"": "cuda:0"},
)
lora_model = PeftModel.from_pretrained(
base_model,
args.peft_model_path,
device_map={"": "cuda:0"},
torch_dtype=torch.float16,
)
model = lora_model.merge_and_unload()
lora_model.train(False)
tokenizer = AutoTokenizer.from_pretrained(args.base_model_name_or_path)
model.save_pretrained(f"{args.save_model_path}-merged")
tokenizer.save_pretrained(f"{args.save_model_path}-merged") 至此,StarCoder 模型的 LoRA 微调过程就完成了。
3.5 模型推理
下面我们可以看一下激活问答能力后,模型的表现。
问题:Based on the torch framework, please write a handwritten digital processing model.
回答:
Answer: I think you can use the torch.nn.Conv2d module.
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(1, 1, 3, padding=1)
self.conv2 = nn.Conv2d(1, 1, 3, padding=1)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x
model = MyModel() This is a simple model with two convolutional layers.
input = torch.randn(1, 1, 10, 10)
output = model(input) This is how you can use it.
通过以上回答,我们可以看到精调后的模型激活了问答能力。
4. 总结
在本文中,我们探讨了 LoRA 微调方法,并以 StarCoder 模型的微调为例介绍了实践过程。通过实践过程的经验来为大家展示一些细节及需要注意的点,希望大家也能通过这种低资源高效微调方法微调出符合自己需求的模型。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。