|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 英文名称: Vector Search with OpenAI Embeddings: Lucene Is All You Need 中文名称: 使用OpenAI嵌入进行向量搜索:只需Lucene 链接: http://arxiv.org/abs/2308.14963v1 作者: Jimmy Lin, Ronak Pradeep, Tommaso Teofili, Jasper Xian 机构: 滑铁卢大学戴维·切里顿计算机科学学院, 罗马第三大学工程系 日期: 2023-08-29 |
读后感
嵌入领域新旧技术的最大不同点在于存储的是稠密向量(深度学习)还是稀疏向量(统计),对于稠密和稀疏的搜索和索引技术完全不同,所以继深度学习模型成为热点后,向量数据库也成为热点。作者认为,针对 Lucene 框架做少量调整,使其支持稠密向量,并不失为一种简单经济的解决方案。
作者挑战了主流观点,通过实验证明,对于很多应用,使用 Lucene+HNSW 可以在不大改动 Lucene 的情况下,完美支持当前基于大模型的文本编码,无需附加的向量数据库。与当前主流方法相比,这种方法成本和复杂度更低。简单来说,如果数据量不多且速度要求不高,Lucene 可以支持向量存储和搜索。
后来,Elasticsearch 也对向量搜索做了进一步优化;Postgres 提供了开源的向量相似性搜索。我们可以在不同情境不同预算下使用不同方案。
摘要
目标: 挑战当前普遍认为需要专门的向量存储才能利用深度神经网络进行搜索的观点。
方法: 使用 Lucene 和 OpenAI 嵌入,在流行的 MS MARCO 段落排序测试集上提供了一个可重复、端到端的向量搜索演示。
结果: 在标准双编码器架构中,Lucene 的层次可导航小世界网络(HNSW)索引足以提供向量搜索功能,从而不需要引入专门的向量存储。
1 引言
在大模型开始流行之后,主流观点认为,为了管理大量密集向量,企业需要专用的"向量存储"或"向量数据库"作为其"AI 堆栈"的一部分。
然而,目前许多生产基础设施由以开源 Lucene 搜索库为中心的广泛生态系统主导。其中最引人注目的是 Elasticsearch、OpenSearch 和 Solr 等平台。作者认为,在很多应用场景中没有必要单独使用专用向量存储。
Lucene 的最新主要版本(第 9 版,从 2021 年 12 月开始)包括 HNSW 索引和矢量搜索。嵌入可以通过简单的 API 调用来计算,索引和搜索密集向量在概念上与使用词袋模型索引和搜索文本相同。
2 从架构到实现
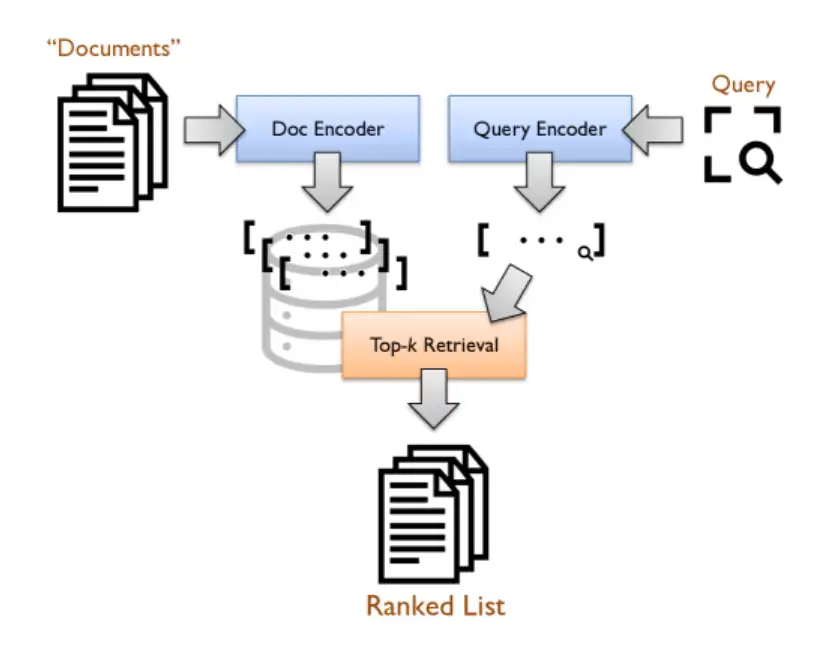
双编码器架构(见图 1)的核心思想是将查询和段落编码为密集向量(通常称为"嵌入"),使相关的查询 - 段落对能获得高分。这些高分是通过计算其嵌入的点积得出的。系统的任务是在给定查询嵌入的情况下,快速检索具有最大点积的 top- 段落嵌入。
用于生成向量表示的"编码器"使用 Transformer 实现。这些 Transformer 通常利用大量相关的 query--passage 对数据集,以监督方式进行微调。在比较密集向量时,这种搜索方法不同于传统的词袋稀疏表示。
在向量空间中,最近邻搜索是基于分层可导航小世界网络(HNSW)的索引。Faiss 库提供了一种流行的 HNSW 索引实现。
由于结合密集和稀疏表示的混合方法已被证明比单独使用任何一种方法更有效,许多现代系统将单独的检索组件组合在一起以实现混合检索。这需要同时管理稀疏和密集检索模型。Lucene 的最新主要版本(第 9 版:2021 年 12 月)包括 HNSW 索引和搜索功能,这些功能在过去几年中稳步改进。这意味着 Lucene 和专用矢量存储之间的功能差异主要在于性能,而不是必备功能的可用性。Lucene 也可以对密集向量进行索引。
文中演示进一步展示了通过简单地将现成的组件"插入在一起"即可轻松实现最先进的矢量搜索。文本编码由 OpenAI API 实现,检索由 Lucene 实现。向量索引和搜索方式类似于使用词袋模型(如 BM25)进行索引和检索。
(小编注:TF-IDF 和 BM25 将每个文档表示为一个高维向量,其维度通常是词表的长度,其向量中的每个值都是浮点数。而 Embedding 编码后更稠密,同时可以不依赖库中的数据,产生较为通用的编码。)
3 实验
使用 MS MARCO 段落排名测试集合。该语料库包含从网络上提取的约 880 万个段落,采用标准开发查询以及 TREC 2019 和 TREC 2020 深度学习赛道中的查询。
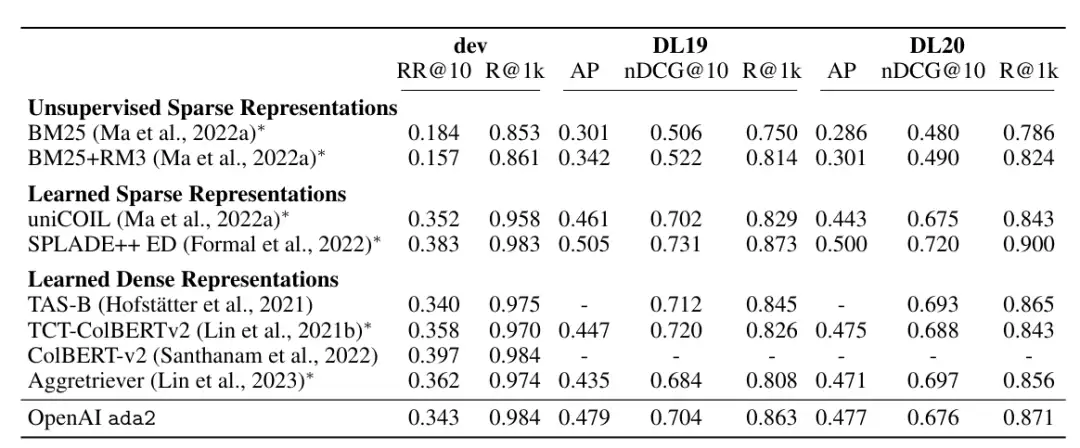
我们利用 OpenAI 的 ada2 模型生成查询和段落嵌入,输出嵌入大小为 1536 个维度。所有段落被截断为 512 个标记,总计约有 6.6 亿个 token。
所有检索实验均使用 Anserini IR 工具包进行,直接访问底层 Lucene 功能,实验基于 Lucene 9.5.0。
测试环境为一台装有两个英特尔至强 Platinum 8160 处理器(每个 33M 缓存,2.10 GHz,24 核)和 1 TB RAM 的服务器。服务器运行 Ubuntu 18.04 操作系统,并使用 ZFS 文件系统。使用 32 位浮点数表示,原始的 1536 维向量在磁盘上占用约 54 GB。以 JSON 文本表示,压缩后的文本文件占用了 109 GB。在向量搜索方面,使用了 16 个线程,能够达到每秒 9.8 个查询(QPS),每次查询获取 1000 个结果。
4 相关知识
4.1 Anserini IR 工具包
Anserini 是一个用于信息检索(IR,Information Retrieval)的开源工具包。它提供了一系列常见的信息检索功能,包括索引构建、查询处理、评估和实验管理等。Anserini 的底层实现基于 Apache Lucene,这是一个成熟的 Java 库,专门用于全文检索和信息检索任务。
4.2 HNSW
HNSW(Hierarchical Navigable Small World)算法是一种用于近似最近邻搜索(Approximate Nearest Neighbor Search, ANN)的高效算法。它通过构建多层次的小世界图来实现高效的近似最近邻搜索。
HNSW 算法基于"小世界"图的概念,即在图中,节点之间的连接结构既有局部性(近邻连接),又有全局性(长距离连接)。这种结构有助于快速搜索。算法采用多层次的结构来组织数据。每一层都是一个小世界图。较低层次的图用于快速定位候选集,而较高层次的图用于精细化搜索。每个节点都保存着指向其他节点的链接,这些链接被用来加速查询过程,使得算法能够高效地在大量数据中查找最接近给定查询点的数据点。