标题: Neural Discrete Representation Learning
motivation
在没有监督的情况下学习有用的表示仍然是机器学习中的一个关键挑战。在本文中,作者提出了一种简单而强大的生成模型,该模型可以学习这种离散表示。作者的模型,即向量量化变分自编码器(VQ-VAE),在两个关键方面不同于传统的VAE:编码器网络输出离散的代码,而不是连续的代码;并且先验是学习得到的,而不是静态的。为了学习离散的潜在表示,作者引入了向量量化(VQ)的思想。使用VQ方法使得模型能够规避"后验塌陷"问题------在强大的自回归解码器配对下,潜变量被忽略------这是VAE框架中通常会出现的现象。通过将这些表示与自回归先验配对,模型可以生成高质量的图像、视频和语音,并实现高质量的说话人转换以及音素的无监督学习,从而进一步证明了所学习表示的实用价值。
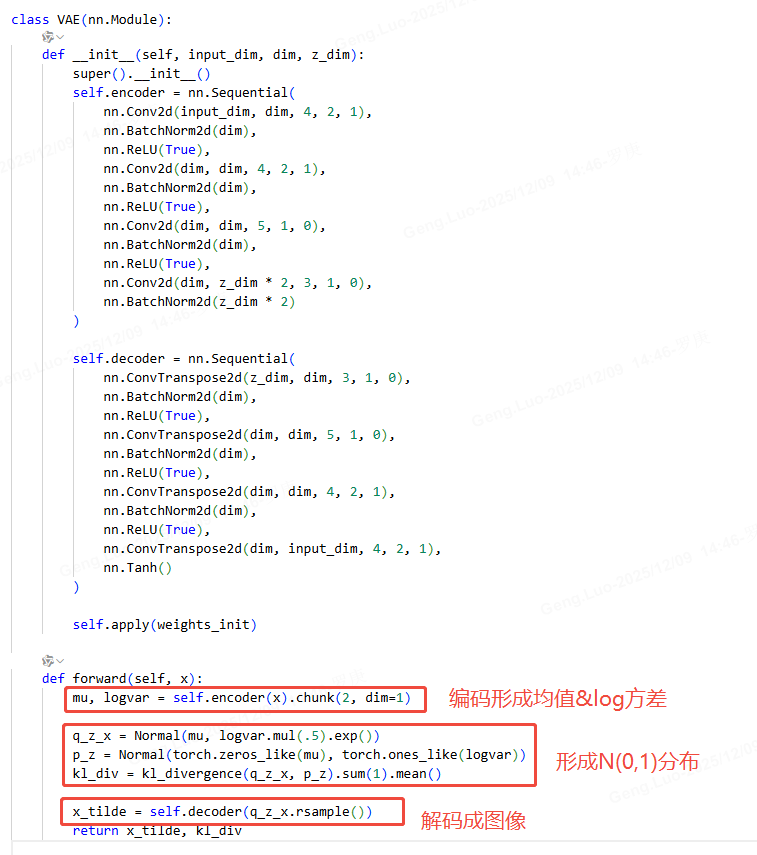
VAE部分:
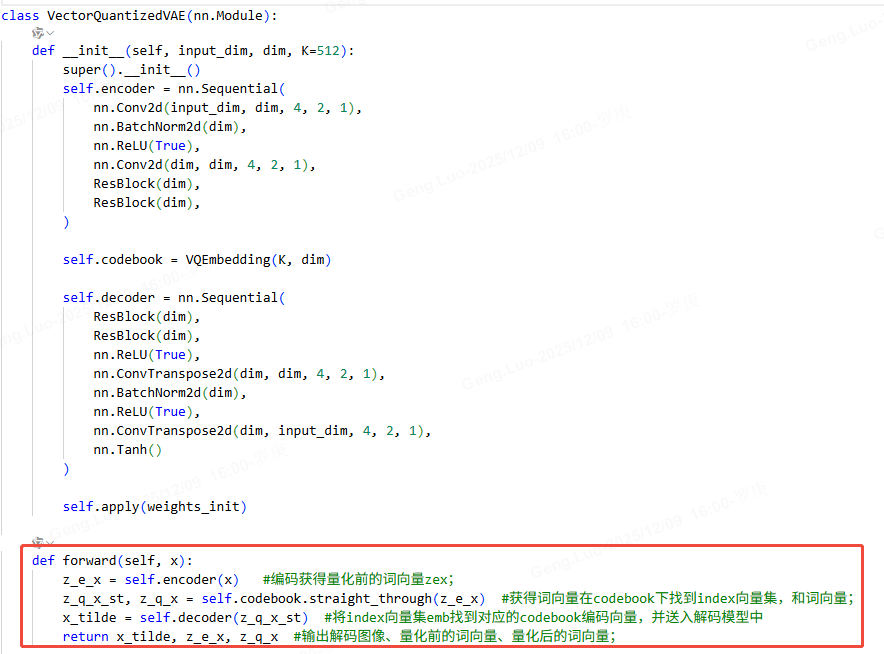
VQ-VAE模型主要代码
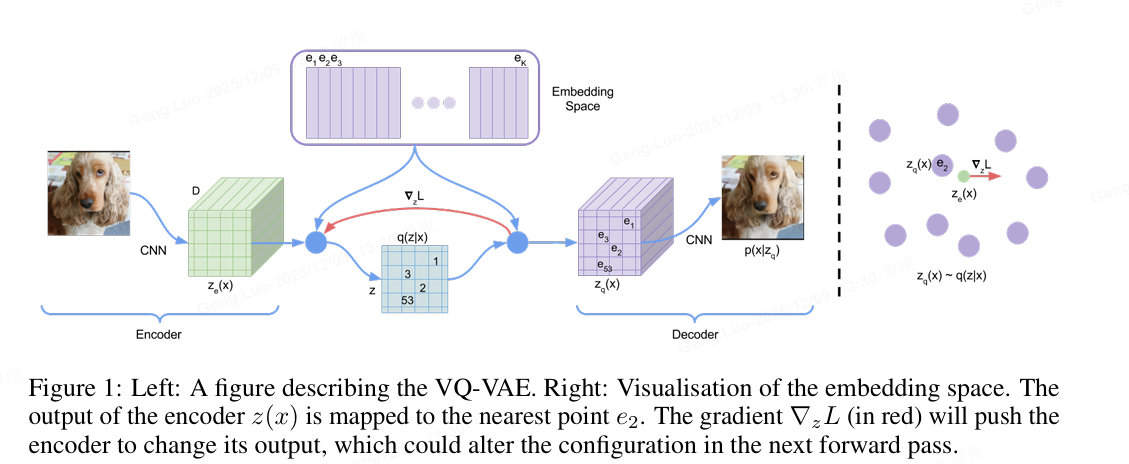
VQ-VAE 概述
VQ-VAE(Vector Quantized Variational Autoencoder)是一种结合向量量化的变分自编码器,由DeepMind提出。其核心思想是将连续隐变量离散化,通过码本(codebook)学习离散表示,适用于图像、音频等数据的生成与压缩。
模型结构
编码器(Encoder)
将输入数据 xxx 映射为连续隐变量 ze(x)z_e(x)ze(x),输出维度为 D×H×WD \times H \times WD×H×W,其中 DDD 为隐变量维度,H×WH \times WH×W 为空间维度。
向量量化(Vector Quantization)
通过码本 E={e1,e2,...,eK}E = \{e_1, e_2, ..., e_K\}E={e1,e2,...,eK}(包含 KKK 个 DDD 维向量)将 ze(x)z_e(x)ze(x) 离散化。每个空间位置的隐向量被替换为码本中最近的向量:
zq(x)=ek,其中k=argminj∥ze(x)−ej∥2 z_q(x) = e_k, \quad \text{其中} \quad k = \arg\min_j \|z_e(x) - e_j\|_2 zq(x)=ek,其中k=argjmin∥ze(x)−ej∥2
解码器(Decoder)
将量化后的隐变量 zq(x)z_q(x)zq(x) 重构为输出 x^\hat{x}x^,目标是最小化重构损失 ∥x−x^∥2\|x - \hat{x}\|^2∥x−x^∥2。
训练目标
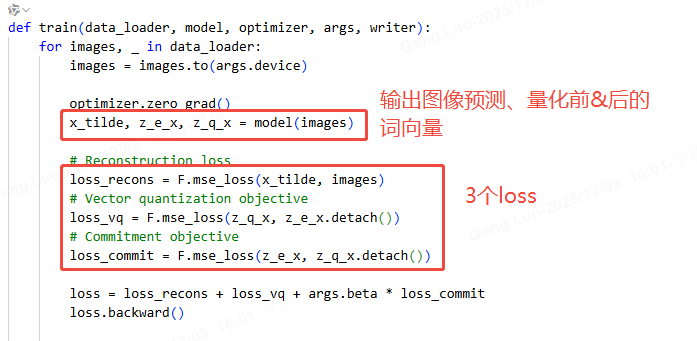
损失函数包含三部分:
- 重构损失:鼓励解码器输出接近输入。
- 码本损失:通过指数移动平均(EMA)更新码本向量。
- 承诺损失 :防止编码器输出波动过大,约束 ze(x)z_e(x)ze(x) 接近码本向量。
数学形式:
L=∥x−x^∥2+∥sgze(x)−ek∥22+β∥ze(x)−sgek∥22 \mathcal{L} = \|x - \hat{x}\|^2 + \|sgz_e(x) - e_k\|_2^2 + \beta \|z_e(x) - sge_k\|_2^2 L=∥x−x^∥2+∥sgze(x)−ek∥22+β∥ze(x)−sgek∥22
其中 sg⋅sg\\cdotsg⋅ 表示停止梯度,β\betaβ 为超参数(通常设为0.25)。
关键特点
- 离散隐空间:通过码本实现隐变量的离散化,适合建模离散模式的数据。
- 自回归先验:训练完成后,可用PixelCNN等模型对离散隐变量建模,生成新数据。
- 应用场景:图像生成、语音合成、压缩表示学习等。
代码实现示例(PyTorch)
python
import torch
import torch.nn as nn
class VQVAE(nn.Module):
def __init__(self, num_embeddings, embedding_dim):
super().__init__()
self.codebook = nn.Embedding(num_embeddings, embedding_dim)
self.encoder = nn.Sequential(...) # 定义编码器网络
self.decoder = nn.Sequential(...) # 定义解码器网络
def forward(self, x):
z_e = self.encoder(x)
# 计算最近邻码本向量
distances = (z_e.pow(2).sum(-1, keepdim=True)
- 2 * torch.matmul(z_e, self.codebook.weight.t())
+ self.codebook.weight.pow(2).sum(-1))
indices = distances.argmin(-1)
z_q = self.codebook(indices)
# 损失计算
commitment_loss = (z_e.detach() - z_q).pow(2).mean()
codebook_loss = (z_e - z_q.detach()).pow(2).mean()
x_hat = self.decoder(z_q)
recon_loss = (x - x_hat).pow(2).mean()
return x_hat, recon_loss + codebook_loss + 0.25 * commitment_loss改进与变体
- VQ-VAE-2:引入分层结构提升生成质量。
- VQGAN:结合对抗训练增强细节保留能力。
- SoundStream:应用于音频压缩的轻量化版本。### Segment Anything Model (SAM) 架构解析
SAM 是一个通用的图像分割模型,由 Meta AI 提出,旨在实现零样本(zero-shot)分割任务。其核心架构分为三部分:图像编码器、提示编码器和掩码解码器。
图像编码器
图像编码器基于 Vision Transformer (ViT) 结构,采用预训练的 MAE (Masked Autoencoder) 方法进行初始化。输入图像分辨率默认为 1024x1024,通过 patch 嵌入层转换为 16x16 的 token 序列。编码器输出 64x64 的低分辨率特征图,通过轻量级处理提升计算效率。
提示编码器
提示编码器支持多种输入形式:
- 点提示:通过位置编码嵌入,区分正/负点(前景/背景)
- 框提示:用对角点坐标嵌入,采用两层 MLP 编码
- 文本提示:使用 CLIP 的文本编码器提取特征
- 掩码提示:低分辨率掩码通过卷积层嵌入
掩码解码器
掩码解码器采用类似 Transformer 的解码结构,关键设计包括:
- 交叉注意力机制:将图像特征与提示特征动态融合
- 动态掩码预测:输出多组掩码(默认 3 个)以处理歧义
- IoU 预测头:并行预测每个掩码的质量分数
数学表达形式:
\\text{Attention}(Q,K,V) = \\text{softmax}(\\frac{QK\^T}{\\sqrt{d_k}})V
其中 ( Q ) 来自提示特征,( K,V ) 来自图像特征。
训练策略
采用混合训练方式:
- 数据引擎:分三阶段(辅助手动标注、半自动标注、全自动标注)
- 损失函数 :线性组合 focal loss 和 dice loss
\\mathcal{L} = \\lambda_1\\mathcal{L}*{focal} + \\lambda_2\\mathcal{L}*{dice}
- 任务模拟:随机生成点/框提示模拟交互式分割场景
零样本迁移能力
通过设计实现无需微调的泛化能力:
- 图像编码器提取通用视觉特征
- 提示编码器支持开放词汇输入
- 动态输出机制适应未知类别
模型参数量约 635M,在 1100 万图像数据集上训练,支持实时交互(50ms/次推理)。