在自动驾驶等机器人应用中,基于激光雷达(LiDAR)点云的目标检测是核心技术之一。激光雷达能够生成高精度的 3D 环境点云,为目标定位提供可靠的空间信息,但点云的稀疏性、3D 特性与传统 2D 卷积神经网络(CNN)的适配问题,一直是制约检测性能与速度的关键瓶颈。
2019 年发表的 PointPillars 论文,提出了一种创新的点云编码方案,成功将 3D 点云检测任务转化为高效的 2D CNN 运算,在 KITTI 数据集上实现了速度与精度的双重突破 ------62Hz 的实时推理速度较此前方法提升 2-4 倍,同时在鸟瞰图(BEV)和 3D 检测任务中超越多数融合方法。本文将逐章拆解这篇里程碑式论文的技术细节、实验设计与核心贡献,带大家全面掌握 PointPillars 的实现逻辑与优势。
原文链接:https://arxiv.org/pdf/1812.05784
代码链接:https://github.com/nutonomy/second.pytorch
沐小含持续分享前沿算法论文,欢迎关注...
一、论文核心背景与问题提出
1.1 应用场景与传感器选择
自动驾驶车辆需要实时检测道路上的车辆、行人、骑行者等目标,激光雷达作为核心传感器,通过激光扫描生成环境的稀疏 3D 点云,相比摄像头具有不受光照影响、测距精度高、无尺度模糊等优势。但点云的固有特性给目标检测带来了独特挑战:
- 稀疏性:点云在 3D 空间中分布零散,传统密集 2D CNN 无法直接应用;
- 3D 维度:点云的 x/y/z 三维信息难以直接适配成熟的 2D 检测架构;
- 实时性要求:自动驾驶需毫秒级响应,检测算法需在保证精度的同时满足高帧率。
1.2 现有方法的局限性
论文将此前的点云编码方案分为两类,均存在明显短板:
- 固定编码器(Fixed Encoders):如 MV3D、PIXOR 等,通过手工设计特征将点云投影为伪图像,速度较快但特征表达能力有限,精度不足;
- 数据驱动编码器(Learned Encoders):如 VoxelNet、SECOND 等,通过 PointNet 学习体素(Voxel)特征,精度更高但依赖 3D 卷积,计算复杂度高,实时性差(VoxelNet 仅 4.4Hz,SECOND 提升至 20Hz)。
1.3 核心研究目标
设计一种兼具以下特性的点云编码与检测方案:
- 端到端可学习:充分挖掘点云的深层特征,避免手工设计的局限性;
- 高效计算:摒弃复杂的 3D 卷积,利用 2D CNN 的高并行性提升速度;
- 无需手动调参:适配不同点云配置(如多激光雷达、雷达点云),降低工程成本;
- 性能超越现有方法:在 KITTI 等权威数据集上实现精度与速度的双重领先。
二、PointPillars 核心技术原理
PointPillars 的核心创新是将 3D 点云组织为 "柱体(Pillars)",通过高效编码转化为 2D 伪图像,再利用成熟的 2D CNN 完成检测。整体网络分为三大模块:柱体特征编码网络(Pillar Feature Network)、2D 卷积骨干网络(Backbone)、检测头(Detection Head),架构如图 2 所示。
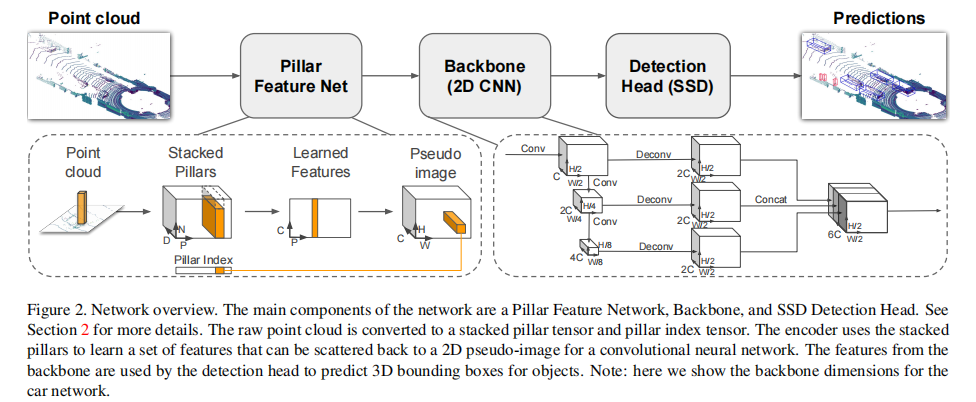
2.1 第一步:点云到伪图像的转化(Pointcloud to Pseudo-Image)
这一步是 PointPillars 的核心创新,解决了点云稀疏性与 2D CNN 适配的问题,分为三个关键步骤:
2.1.1 点云柱体划分(Pillar Partitioning)
- 空间离散化:在 x-y 平面(鸟瞰图视角)划分均匀网格,每个网格对应的垂直柱体(Pillar)作为基本处理单元,无需对 z 轴(高度)进行手工分箱(VoxelNet 需手动设置 z 轴体素大小);
- 点云增强(Point Decoration):对每个柱体内的点补充 5 个维度的特征,最终形成 9 维特征向量(原始 x/y/z/r + 增强特征):
:点到柱体内所有点的算术平均值的偏移;
2.1.2 稠密张量构建(Dense Tensor Construction)
由于点云稀疏,多数柱体为空,非空柱体的点数也不一致。为适配批量计算:
- 设定两个超参数:最大非空柱体数P(默认 12000)、每个柱体最大点数N(默认 100);
- 对超过数量的柱体 / 点进行随机采样,不足则补零,最终形成维度为
2.1.3 柱体特征编码(Pillar Feature Encoding)
采用简化版 PointNet 对每个柱体的点特征进行编码:
- 逐点特征变换:通过 1×1 卷积(等价于线性层)将 9 维点特征映射到C维(默认 64 维),后接 BatchNorm 和 ReLU 激活,输出张量维度
- 柱体内特征聚合:对每个柱体沿点数维度(
- 伪图像生成:将每个柱体的特征按照其在 x-y 网格的位置 "散射(Scatter)" 回 2D 平面,形成维度为
关键优势:柱体编码避免了 VoxelNet 的 3D 体素划分,所有运算均可通过 2D/1D 卷积实现,GPU 并行效率极高;无需手动调整 z 轴分箱参数,适配性更强。
2.2 第二步:2D 卷积骨干网络(Backbone)
骨干网络的目标是提取伪图像的多尺度特征,采用 "自上而下特征提取 + 自下而上特征融合" 的结构,与 VoxelNet、SECOND 的设计类似但更精简:
2.2.1 自上而下特征提取(Top-Down Network)
由 3 个 Block 组成,每个 Block 定义为:
- S:相对于输入伪图像的步长(下采样率);
- L:3×3 2D 卷积层数量;
- F:输出特征通道数;每个卷积层后均接 BatchNorm 和 ReLU。以汽车检测网络为例:
- Block1:
- Block2:
- Block3:
2.2.2 特征融合(Upsampling & Concatenation)
将不同尺度的特征图上采样至同一分辨率(步长)后拼接,增强多尺度特征表达:
- 上采样操作:通过转置 2D 卷积(Transposed Conv)将高步长特征图映射到低步长,定义为
- 拼接:将 Up1(Block1 输出,步长 2)、Up2(Block2 上采样至步长 2)、Up3(Block3 上采样至步长 2)的特征拼接,最终得到 6C=384 维特征图,输入检测头。
2.3 第三步:检测头(Detection Head)
采用单阶段检测架构 SSD(Single Shot Detector),适配 3D 目标检测的需求:
2.3.1 锚点设计(Anchor Design)
针对不同目标类别(汽车、行人、骑行者)设计专属锚点,每个锚点包含:
- 2D 尺寸:宽度(w)、长度(l);
- 3D 尺寸:高度(h)、z 轴中心(z_center);
- 朝向:0° 和 90° 两个方向(覆盖主要目标朝向)。
具体参数如下表:
| 目标类别 | 宽度(m) | 长度(m) | 高度(m) | z 轴中心(m) | x-y 范围(m) |
|---|---|---|---|---|---|
| 汽车 | 1.6 | 3.9 | 1.5 | -1.0 | (0,70.4)×(-40,40) |
| 行人 | 0.6 | 0.8 | 1.73 | -0.6 | (0,48)×(-20,20) |
| 骑行者 | 0.6 | 1.76 | 1.73 | -0.6 | (0,48)×(-20,20) |
2.3.2 匹配与回归策略
- 锚点匹配:基于 2D IoU(交并比)进行匹配,正样本为 "与真值 IoU 最高" 或 "IoU > 阈值"(汽车 0.6,行人 / 骑行者 0.5),负样本为 IoU < 阈值(汽车 0.45,行人 / 骑行者 0.35);
- 回归目标:除 2D 位置(x,y)、尺寸(w,l)外,新增 3D 维度的高度(h)、z 轴中心(z)、朝向角(θ),共 7 个回归参数;
- 朝向角处理:由于角度回归存在歧义(如 0° 与 180°),采用离散化方向的 Softmax 损失(
三、损失函数与训练细节
3.1 损失函数设计
总损失由定位损失()、分类损失(
)、朝向损失(
)加权组成:
其中:
- 权重参数:
3.2 训练配置
- 初始化:所有权重采用均匀分布随机初始化,不使用预训练模型;
- 优化器:Adam 优化器,初始学习率
- 批量大小:验证集 batch=2,测试集 batch=4;
- 数据增强:关键提升手段,包括:
- 真值采样:从训练集中随机采样 15 个汽车、8 个骑行者的真值框及对应点云,添加到当前样本中;
- 单框增强:对每个真值框进行随机旋转(
- 全局增强:x 轴镜像翻转、随机旋转与缩放、全局平移(x/y/z 服从
四、实验设计与结果分析
论文在 KITTI 目标检测数据集上进行了全面评估,KITTI 包含 7481 个训练样本和 7518 个测试样本,需检测汽车、行人、骑行者三类目标,评估指标包括鸟瞰图平均精度(BEV mAP)、3D 平均精度(3D mAP)、平均朝向相似度(AOS)。
4.1 定量结果:精度与速度双重领先
4.1.1 BEV 检测结果
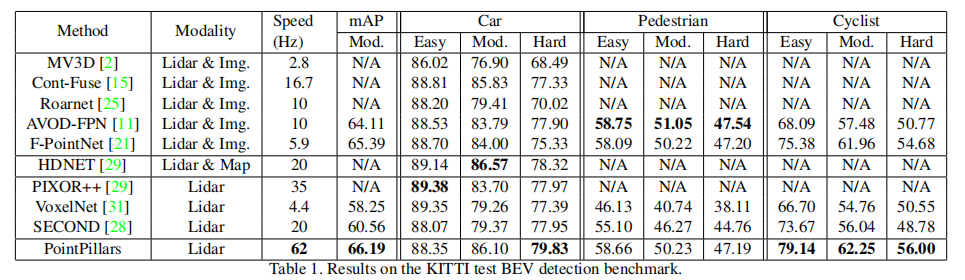
PointPillars 在仅使用激光雷达的情况下,显著超越现有方法(表 1 ):
- 综合 mAP(中等难度):66.19,远超 SECOND(60.56)、VoxelNet(58.25),甚至超过融合激光雷达与图像的 AVOD-FPN(64.11)、F-PointNet(65.39);
- 汽车(中等难度):86.10,超越所有激光雷达 - only 方法,仅次于融合地图的 HDNET(86.57);
- 骑行者(中等难度):62.25,大幅领先融合方法 F-PointNet(61.96)和激光雷达方法 SECOND(56.04);
- 速度:62Hz,是 VoxelNet(4.4Hz)的 14 倍,SECOND(20Hz)的 3 倍。
4.1.2 3D 检测结果
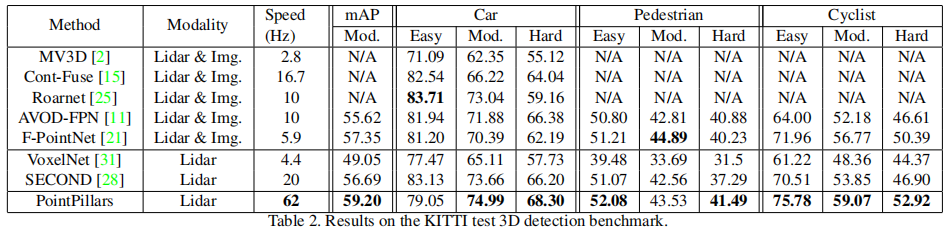
3D 检测更贴近实际应用场景,PointPillars 依然表现突出(表 2 ):
- 综合 mAP(中等难度):59.20,超越所有激光雷达 - only 方法,且优于多数融合方法;
- 骑行者(中等难度):59.07,领先 F-PointNet(56.77)和 SECOND(53.85);
- 行人检测:虽然略低于 F-PointNet(44.89),但速度快 10 倍以上。
4.1.3 朝向精度(AOS)
朝向预测对自动驾驶避障至关重要,PointPillars 在 AOS 指标上全面领先(表 3 ):
- 综合中等 AOS:68.86,远超 SECOND(54.53)和 AVOD-FPN(63.19);
- 骑行者中等 AOS:68.16,甚至超越图像 - only 的 SubCNN(63.41)。

4.1.4 速度 - 精度权衡
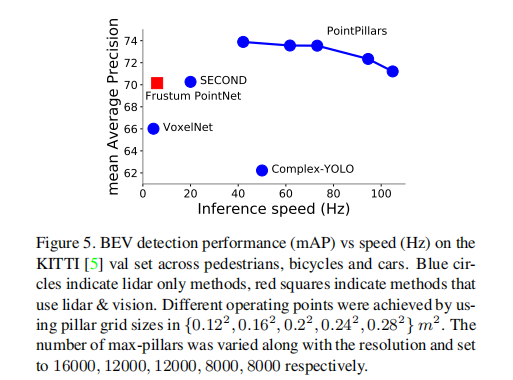
通过调整 x-y 网格分辨率(柱体大小),PointPillars 可灵活权衡速度与精度(图 5):
- 高分辨率(0.12×0.12m²):精度最高,速度约 40Hz;
- 中等分辨率(0.16×0.16m²):62Hz,精度最优;
- 低分辨率(0.28×0.28m²):105Hz,精度与 SECOND 相当。
4.2 定性结果与失败案例
4.2.1 成功案例
PointPillars 能准确预测三类目标的 3D 边界框,尤其是汽车检测的定位精度和朝向预测表现优异,边界框贴合度高(图 3)。
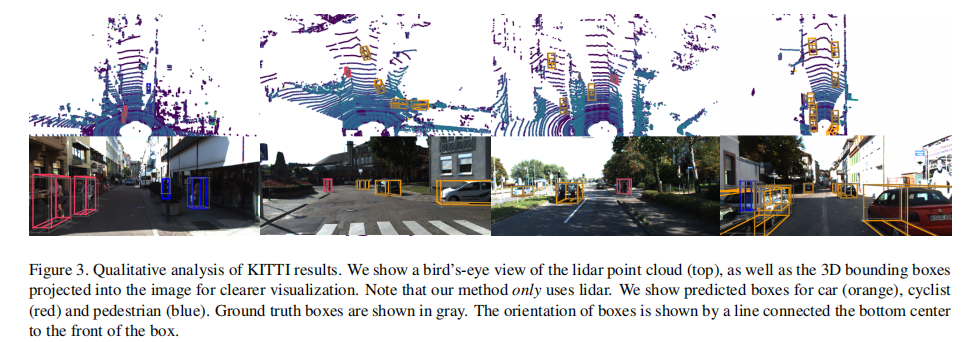
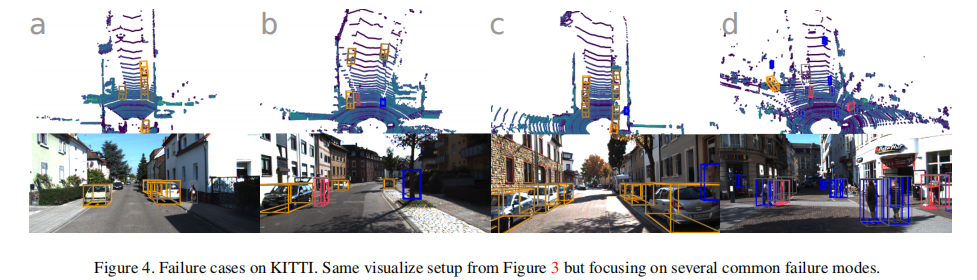
4.2.2 失败案例
主要失败模式包括(图 4):
- 类别混淆:行人和骑行者相互误判,行人与电线杆、树干等细长物体混淆;
- 遮挡与远距离目标:部分遮挡或远距离的小目标易漏检;
- 假阳性:少数情况下将非目标(如桌子)误判为骑行者。
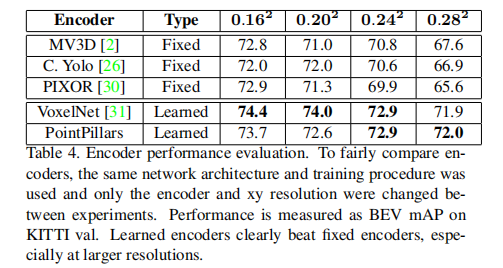
4.3 消融实验:关键设计的有效性验证
论文通过消融实验验证了核心模块的必要性,结果如下:
4.3.1 编码器类型对比
在相同骨干网络和训练策略下,学习型编码器(PointPillars、VoxelNet)显著优于固定编码器(MV3D、PIXOR),且柱体越大(分辨率越低),优势越明显(固定编码器的手工特征难以适配大柱体的稀疏点云)(表 4)。
4.3.2 点云增强(Point Decorations)
在 VoxelNet 的基础上新增(点到柱体中心的偏移)特征,带来 0.5 mAP 的提升,且实验可重复性更强。
4.3.3 数据增强策略
过度的单框增强会导致行人检测性能下降,而真值采样(Ground Truth Database Sampling)可有效弥补这一问题,提升 3% 左右的 mAP。
4.3.4 网络精简设计
- 移除 VoxelNet 中的第二个 PointNet,减少 2.5ms 推理时间;
- 将骨干网络第一层输出通道数从 128 降至 64,减少 4.5ms;
- 上采样特征通道数减半,减少 3.9ms;以上修改不影响精度,显著提升速度。
4.4 实时推理性能分析
在 Intel i7 CPU + 1080Ti GPU 环境下,PointPillars(汽车网络)的推理时间分解如下:
| 步骤 | 耗时(ms) | 占比 |
|---|---|---|
| 点云加载与过滤 | 1.4 | 8.6% |
| 柱体组织与增强 | 2.7 | 16.7% |
| 张量上传 GPU | 2.9 | 17.9% |
| 柱体特征编码 | 1.3 | 8.0% |
| 伪图像散射 | 0.1 | 0.6% |
| 骨干网络 + 检测头 | 7.7 | 47.5% |
| NMS(CPU) | 0.1 | 0.6% |
| 总耗时 | 16.2 | 100% |
关键优化点:
- 柱体编码仅 1.3ms,较 VoxelNet 的 190ms 快两个数量级;
- 采用 TensorRT 优化 GPU 推理,较原生 PyTorch 提升 45.5% 速度(从 42.4Hz 提升至 62Hz);
- 适配全场景点云:KITTI 仅使用 10% 的点云(投影到图像内),而实际自动驾驶需处理完整点云,PointPillars 的高效性更具优势。
五、相关工作对比与核心贡献
5.1 与现有方法的关键差异
| 方法 | 核心单元 | 卷积类型 | 速度(Hz) | 核心劣势 |
|---|---|---|---|---|
| VoxelNet | 体素(Voxel) | 3D 卷积 | 4.4 | 速度慢,需手动调 z 轴分箱 |
| SECOND | 体素(Voxel) | 3D 卷积(稀疏优化) | 20 | 仍依赖 3D 卷积,计算复杂度高 |
| MV3D | 多视角投影 | 2D 卷积(手工特征) | 2.8 | 精度低,特征表达有限 |
| F-PointNet | 图像引导的视锥体 | PointNet+2D CNN | 5.9 | 多阶段流程,无法端到端训练 |
| PointPillars | 柱体(Pillar) | 2D 卷积(学习特征) | 62 | 行人检测精度略低于融合方法 |
5.2 论文核心贡献
- 创新的柱体编码方案:首次将点云组织为柱体,实现端到端学习的同时避免 3D 卷积,兼顾精度与速度;
- 极致的计算效率:所有核心运算均为 2D/1D 卷积,GPU 并行效率高,62Hz 推理速度满足自动驾驶实时需求;
- 无需手动调参:无需设置 z 轴分箱参数,适配多激光雷达、雷达点云等多种输入;
- 性能突破:仅使用激光雷达,在 KITTI BEV 和 3D 检测中超越多数融合方法,建立新的性能标杆;
- 开源可复现:发布 PyTorch 代码,支持 105Hz 快速版本与 62Hz 高精度版本,便于工程落地。
六、总结与未来展望
6.1 核心结论
PointPillars 通过 "柱体编码 + 2D CNN" 的创新架构,完美解决了点云 3D 检测中 "精度与速度" 的矛盾,证明了仅使用激光雷达即可实现超越融合方法的检测性能,为自动驾驶的实时感知提供了高效解决方案。其核心优势在于:
- 端到端学习充分挖掘点云特征;
- 2D 卷积的高并行性保障实时性;
- 简洁的架构设计降低工程复杂度。
6.2 局限性与未来方向
- 行人检测精度:虽然速度领先,但行人(尤其是远距离、遮挡场景)的检测精度仍有提升空间,可结合注意力机制或多尺度特征增强;
- 多传感器融合:目前仅使用激光雷达,未来可融合摄像头、雷达数据,进一步提升复杂场景的鲁棒性;
- 动态场景适配:针对极端天气(雨、雪)、动态障碍物(快速移动的行人)等场景,需优化数据增强与特征提取策略;
- 嵌入式部署:适配自动驾驶的嵌入式 GPU(如 NVIDIA Jetson 系列),进一步优化模型体积与推理延迟。
6.3 工程应用价值
PointPillars 已成为激光雷达点云检测的主流基准模型,其开源代码(https://github.com/nutonomy/second.pytorch)被广泛应用于自动驾驶、机器人导航等领域。其核心思想 "将 3D 问题转化为 2D 高效运算" 也为后续研究提供了重要启发,如后续的 CenterPoint 等模型均借鉴了柱体编码的思路并进一步优化。
附录:关键术语与缩写说明
- BEV:Bird's Eye View(鸟瞰图);
- Pillar:柱体,x-y 平面网格对应的垂直空间单元;
- Voxel:体素,3D 空间中的立方体单元;
- mAP:mean Average Precision(平均精度均值);
- AOS:Average Orientation Similarity(平均朝向相似度);
- NMS:Non-Maximum Suppression(非极大值抑制);
- SSD:Single Shot Detector(单阶段检测器)。