在自动驾驶等依赖强 3D 感知能力的领域中,3D 目标检测与跟踪是核心技术之一。传统基于锚框(Anchor-based)的 3D 检测方法,在处理旋转目标、稀疏点云等问题时面临诸多挑战。由 UT Austin 团队提出的 CenterPoint 框架,创新性地采用基于中心点(Center-based)的表示方法,将 3D 目标建模为点而非边界框,极大简化了检测与跟踪流程,同时在性能上实现了突破性提升。
原文链接:https://arxiv.org/pdf/2006.11275
代码链接:https://github.com/tianweiy/CenterPoint
沐小含持续分享前沿算法论文,欢迎关注...
一、论文背景与核心问题
1.1 3D 目标检测的核心挑战
与研究成熟的 2D 图像检测不同,基于点云的 3D 目标检测面临三大核心难题:
- 点云稀疏性:3D 空间中多数区域缺乏测量数据,导致特征提取困难;
- 目标姿态无约束:3D 目标不存在固定朝向,轴对齐边界框难以适配旋转目标;
- 目标尺度与形状多样性:交通场景中,自行车、公交车、行人等目标的尺度、形状差异极大,传统锚框模板难以全覆盖。
1.2 传统方法的局限性
传统 Anchor-based 方法通过预定义不同尺度、朝向的锚框匹配目标,但存在明显缺陷:
- 为覆盖所有可能朝向,需设计大量锚框,导致计算量激增且假阳性率升高;
- 依赖 2D IoU 进行锚框分配,需为不同类别、数据集手动调整正负样本阈值,适配性差;
- 旋转目标的轴对齐锚框匹配精度低,尤其在车辆转弯等安全关键场景中性能下降显著(如图 1 所示)。
1.3 核心创新思路
CenterPoint 的核心突破在于目标表示方法的转变:将 3D 目标表示为中心点,而非边界框。这一转变带来三大优势:
- 中心点无内在朝向,天然具备旋转不变性,大幅缩减检测器搜索空间;
- 简化跟踪任务:目标跟踪转化为时空维度上的中心点匹配,无需复杂运动模型;
- 基于中心点的特征提取可设计高效的两阶段精炼模块,兼顾精度与速度。
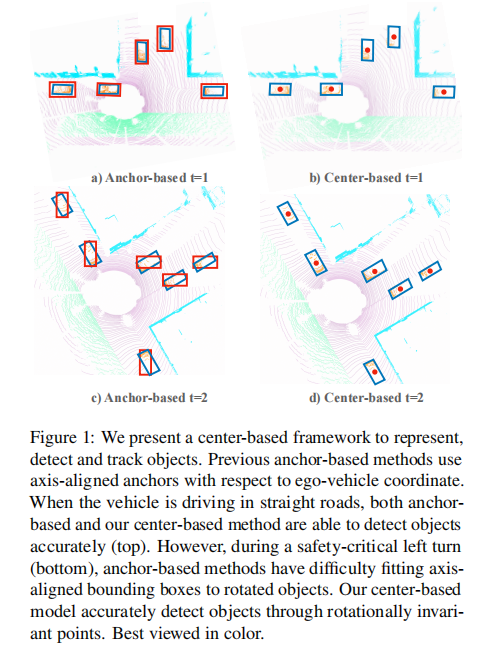
注:上图展示直道行驶(上)与左转(下)场景的检测效果。Anchor-based 方法在目标旋转时难以适配轴对齐框,而 CenterPoint 通过旋转不变的中心点实现精准检测。
二、相关工作综述
2.1 2D 目标检测的启发
2D 检测方法可分为三类:
- 两阶段方法(RCNN 系列):生成候选框后分类精炼;
- 单阶段方法(YOLO、SSD):直接预测类别特异性边界框;
- 中心点方法(CenterNet、CenterTrack):检测目标中心点并回归尺寸等属性,无需候选框。
CenterPoint 认为,中心点表示更适合 3D 场景,因为它规避了 2D 边界框与 3D 目标的适配矛盾。
2.2 3D 目标检测的演进
3D 检测方法的核心差异在于输入编码器(点云特征提取方式):
- 体素化方法:VoxelNet 将点云划分为体素,通过 PointNet 提取体素特征;SECOND 简化 VoxelNet 并加速稀疏卷积;
- 柱体化方法:PointPillars 将体素替换为柱体(Pillar),提升骨干网络效率;
- 投票机制:VoteNet 通过点特征投票聚类检测目标;
- 两阶段方法:PointRCNN、PV-RCNN 等借鉴 2D RCNN,通过 RoIPool/Align 聚合 3D 区域特征,但计算成本高昂。
CenterPoint 的创新在于输出表示层,与任何 3D 编码器(VoxelNet/PointPillars)兼容,可直接提升现有模型性能。
2.3 3D 目标跟踪方法
传统 3D 跟踪依赖:
- 2D 跟踪算法直接迁移(忽略 3D 运动信息);
- 基于 3D 卡尔曼滤波的专用跟踪器(如 AB3D),虽能利用 3D 运动,但计算复杂。
CenterPoint 借鉴 CenterTrack 的思路,通过预测目标速度实现简单高效的中心点匹配跟踪,性能与效率远超传统方法。
三、预备知识铺垫
3.1 2D CenterNet 原理回顾
CenterNet 将 2D 检测转化为关键点估计:
- 输入图像经骨干网络生成热图(Heatmap),每个类别对应一个通道;
- 热图局部最大值对应目标中心点,置信度与峰值强度成正比;
- 同时回归尺寸图(Size Map)和偏移量(Offset),补偿下采样导致的量化误差;
- 无需 NMS(非极大值抑制),直接提取峰值点作为检测结果。
3.2 3D 目标检测定义
给定无序点云 (
为 3D 坐标,
为反射率),3D 检测目标是预测鸟瞰图(BEV)中的 3D 边界框集合
,每个边界框定义为:
其中:
:目标接地平面中心坐标;
3.3 3D 骨干网络输出
主流 3D 骨干网络(VoxelNet/PointPillars)的输出为鸟瞰图特征图 ,其中:
传统方法在该特征图上预定义锚框,而 CenterPoint 直接预测中心点及属性。
四、CenterPoint 核心框架详解
CenterPoint 采用两阶段架构:第一阶段检测中心点并回归目标属性;第二阶段利用边界框表面特征精炼预测结果。整体流程如图 2 所示。
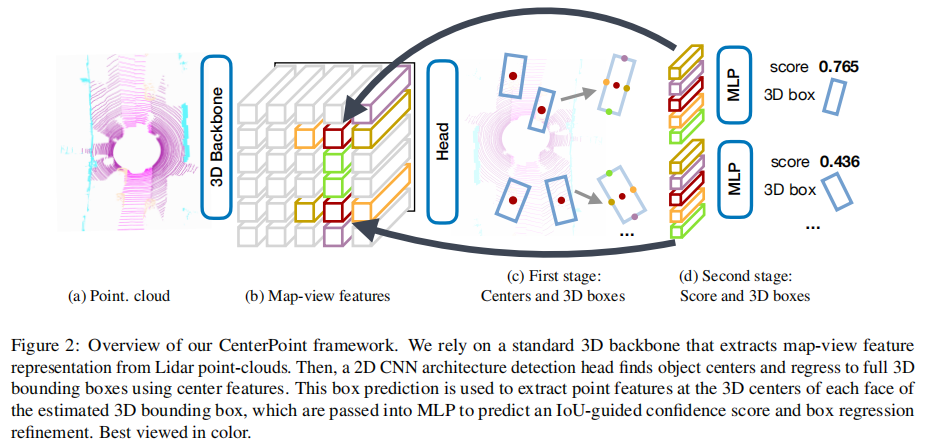
注:输入点云经 3D 骨干网络生成鸟瞰图特征;第一阶段通过 2D CNN 检测中心点并回归 3D 边界框;第二阶段提取边界框表面中心点特征,经 MLP 精炼置信度与边界框。
4.1 第一阶段:中心点检测与属性回归
第一阶段的目标是从鸟瞰图特征图中检测目标中心点,并回归完整的 3D 边界框属性。所有输出均为密集预测(Dense Prediction)。
4.1.1 中心热图头(Center Heatmap Head)
- 输出 :K 通道热图
- 训练目标 :在标注边界框的 3D 中心点投影位置,生成 2D 高斯核作为正样本区域。为解决点云鸟瞰图中目标稀疏导致的监督信号不足问题,高斯半径设置为:
- 损失函数:采用 Focal Loss,缓解正负样本不平衡。
4.1.2 回归头(Regression Heads)
为每个中心点回归以下属性(每个属性对应独立的回归头):
- 子体素位置精炼
- 地面高度
- 3D 尺寸
- 偏航角
- 损失函数:所有回归任务采用 L1 损失,仅在真实中心点位置进行监督。
4.1.3 速度头与跟踪(Velocity Head and Tracking)
为实现跟踪,额外回归目标在鸟瞰图中的 2D 速度 (表示相邻帧间的位置偏移):
- 训练输入:当前帧与前一帧的鸟瞰图特征图;
- 训练目标:真实目标在两帧间的位置差;
- 损失函数:L1 损失。
4.2 第二阶段:边界框精炼(Two-Stage Refinement)
第一阶段仅依赖中心点特征,可能因局部特征不足导致定位误差。第二阶段通过提取边界框表面特征,进一步精炼预测结果,且保持轻量化设计。
4.2.1 特征提取
从第一阶段预测的 3D 边界框的 5 个关键位置提取特征:
- 边界框的 4 个侧面中心点 + 1 个中心中心点(顶部和底部中心点在鸟瞰图中投影与中心重合,故不重复提取);
- 特征提取方式:从第一阶段的鸟瞰图特征图 M 中,通过双线性插值获取上述 5 个位置的特征,拼接后输入 MLP。
4.2.2 精炼任务
- 置信度分数精炼 :预测类别无关的置信度
- 边界框精炼:预测第一阶段边界框的修正量,损失函数为 L1 损失。
4.3 网络架构细节
- 第一阶段:所有输出共享 1 个 3×3 卷积层(含 BatchNorm 和 ReLU),之后每个输出分支独立使用 2 个 3×3 卷积(含 BatchNorm 和 ReLU);
- 第二阶段:共享 2 层 MLP(含 BatchNorm、ReLU 和 Dropout(dropout rate=0.3)),后续分为两个分支:3 层全连接层用于置信度预测,3 层全连接层用于边界框修正。
五、3D 目标跟踪算法
基于第一阶段预测的中心点和速度,CenterPoint 采用贪心最近点匹配策略实现跟踪,算法流程如 Algorithm 1 所示:

5.1 输入与输出
- 输入 :前一帧跟踪结果
- 输出 :当前帧跟踪结果
5.2 核心步骤
- 代价计算 :计算当前帧检测点与前一帧跟踪点的距离代价
- 贪心匹配 :按检测置信度顺序,为每个检测点匹配距离最近且满足类别距离阈值
- 新跟踪初始化:未匹配的检测点作为新跟踪目标,分配新 ID;
- 未匹配跟踪处理:未匹配的跟踪点,若未激活帧数未超过阈值 A,则按其历史速度更新位置并保留跟踪,否则删除。
5.3 关键优势
- 无需复杂的 3D 卡尔曼滤波或状态估计,仅依赖中心点和速度预测,计算开销极小(1ms / 帧);
- 类别特异性距离阈值
六、实验设计与结果分析
6.1 实验设置
6.1.1 数据集
- Waymo Open Dataset:798 个训练序列、202 个验证序列,64 线激光雷达(180k 点 / 帧),评估指标包括 3D mAP、mAPH(带朝向权重的 mAP)、MOTA(多目标跟踪精度)、MOTP(多目标跟踪精度);
- nuScenes Dataset:1000 个驾驶序列(700/150/150 训练 / 验证 / 测试),32 线激光雷达(30k 点 / 帧),评估指标包括 mAP、NDS(nuScenes 检测分数,加权 mAP 与位置、尺度等属性精度)、AMOTA(跟踪指标)、PKL(规划导向指标)。
6.1.2 模型变体
- CenterPoint-Voxel:基于 VoxelNet 编码器;
- CenterPoint-Pillar:基于 PointPillars 编码器。
6.1.3 训练与推理细节
- 优化器:AdamW(nuScenes)/SGD(Waymo);
- 数据增强:随机翻转、缩放、旋转,nuScenes 数据集额外采用地面真值采样(复制粘贴标注框内点云);
- 推理速度:Waymo 上 11 FPS,nuScenes 上 16 FPS(近实时)。
6.2 核心实验结果
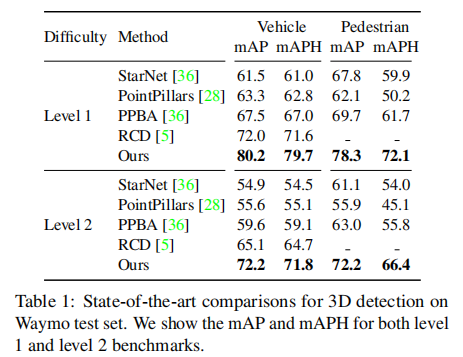
6.2.1 3D 检测性能(Waymo 测试集)
表 1 展示 Waymo 测试集上的 3D 检测结果,CenterPoint 在 Level 2(仅含 1 个激光雷达点的目标)场景中表现突出:
- 车辆检测:71.8 mAPH(超此前最佳方法 7.1%);
- 行人检测:66.4 mAPH(超此前最佳方法 10.6%)。
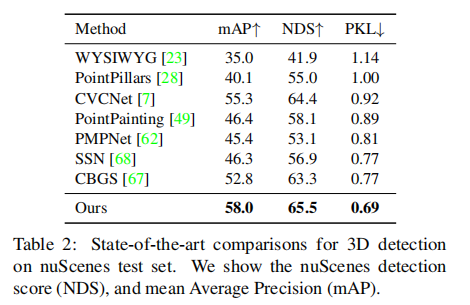
6.2.2 3D 检测性能(nuScenes 测试集)
表 2 显示,CenterPoint 在 nuScenes 测试集上以显著优势领先:
- mAP 达到 58.0(超 CBGS 5.2%);
- NDS 达到 65.5(超 CBGS 2.2%);
- PKL(规划导向指标)达到 0.69(最低,表明对下游自动驾驶规划任务的提升最大)。
6.2.3 3D 跟踪性能
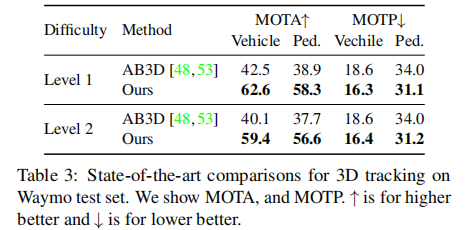
- Waymo 测试集(表 3):Level 2 场景中,车辆 MOTA 59.4(超 AB3D 19.3%),行人 MOTA 56.6(超 AB3D 18.9%);
- nuScenes 测试集(表 4):AMOTA 达到 63.8(超此前最佳方法 8.8%),同时 False Negatives(漏检)和 ID Switches(ID 切换)显著降低。
Waymo 测试集 3D 跟踪性能对比:
nuScenes 测试集 3D 跟踪性能对比:

6.3 消融实验分析
6.3.1 中心点 vs 锚框表示
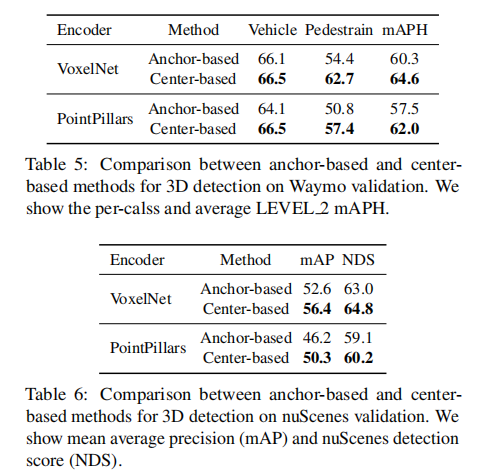
表 5 和表 6 对比了相同编码器下,Center-based 与 Anchor-based 方法的性能:
-
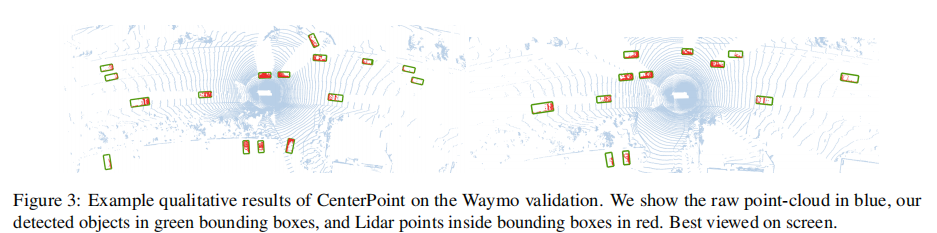
Waymo 验证集:VoxelNet 编码器下,Center-based 方法平均 mAPH 提升 4.3%;PointPillars 编码器下提升 4.5%;可视化结果如图 3 所示。
-
nuScenes 验证集:mAP 提升 3.8-4.1%,NDS 提升 1.1-1.8%。
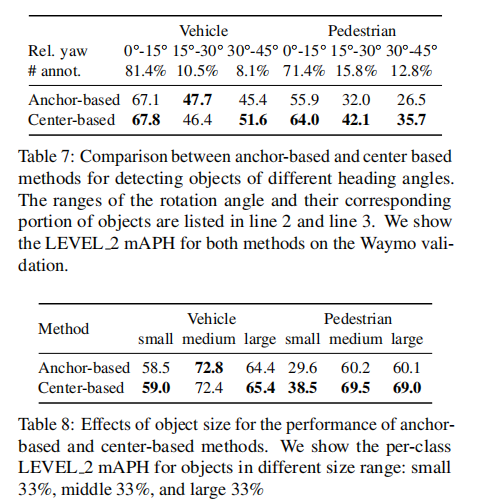
关键原因在于中心点表示对旋转目标和尺度变化的适应性更强(表 7、表 8):
-
旋转目标(偏航角 30°-45°):Center-based 方法行人检测 mAPH 提升 9.2%;
-
小尺寸目标:Center-based 方法行人检测 mAPH 提升 8.9%。
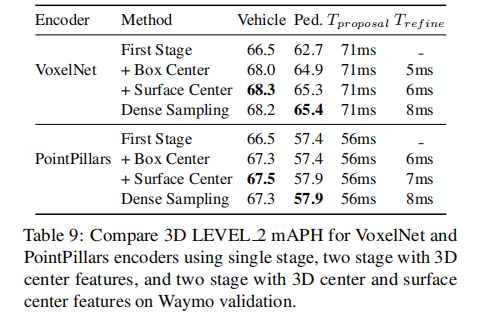
6.3.2 单阶段 vs 两阶段
表 9 显示,两阶段精炼仅增加 6-7ms 计算开销,却能带来显著精度提升:
- VoxelNet 编码器:车辆检测 mAPH 从 66.5 提升至 68.3,行人从 62.7 提升至 65.3;
- 相比 PV-RCNN 的密集采样(6×6 点),CenterPoint 的 5 个关键位置采样性能相当,但速度更快。
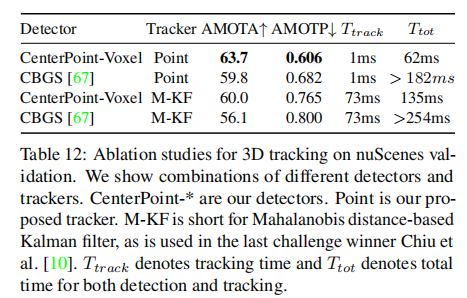
6.3.3 跟踪方法对比
表 12 显示,CenterPoint 的速度基中心点匹配跟踪显著优于卡尔曼滤波:
- 相同检测器下,AMOTA 提升 3.7%;
- 跟踪时间从 73ms 降至 1ms,总推理时间减少 50% 以上。
七、结论与展望
7.1 核心贡献总结
- 表示创新:首次将 3D 目标表示为中心点,解决了旋转目标适配、锚框设计复杂等核心问题;
- 高效架构:两阶段设计兼顾精度与速度,第二阶段轻量化特征提取避免了传统两阶段方法的高计算成本;
- 端到端跟踪:通过速度预测实现简单高效的中心点匹配跟踪,无需独立运动模型;
- 性能突破:在 Waymo 和 nuScenes 两大权威数据集上,检测与跟踪性能均达到 SOTA,且保持近实时推理速度。
7.2 局限性与未来方向
- 对极稀疏点云(如 nuScenes 的 32 线激光雷达),两阶段精炼提升有限,需优化特征提取方式;
- 小目标(如交通锥)的检测精度仍有提升空间,可结合多尺度特征融合;
- 目前仅支持激光雷达输入,未来可扩展至多模态(激光雷达 + 摄像头)融合场景。
7.3 实际应用价值
CenterPoint 的简单性、高效性和高性能使其成为自动驾驶感知系统的理想选择。其开源代码已被广泛应用于工业界和学术界,且在 NeurIPS 2020 nuScenes 检测挑战赛中,前 4 名中有 3 支队伍采用了 CenterPoint 框架,证明了其强大的泛化能力和工程实用性。
附录:关键补充信息
A. 实现细节
- 代码基于 CBGS 开源框架,适配 VoxelNet 和 PointPillars 编码器;
- nuScenes 数据集采用帧合并策略(将非标注帧点云合并至标注帧),提升点云密度和速度估计精度;
- 测试时增强(TTA):翻转测试、点云旋转(±6.25° 等),进一步提升性能。
B. 挑战赛优化策略
在 nuScenes 检测挑战赛中,CenterPoint 通过以下策略实现性能突破:
- 结合 PointPainting(激光雷达点云与图像实例分割融合);
- 多模型集成(5 个不同网格尺寸的模型);
- 过滤空点预测框;最终实现 68.2 mAP 和 71.7 NDS,远超 2019 年冠军 CBGS。