最近在接触大模型相关内容,发现一种高效的向量搜索算法HNSW,这里做一下记录。
在之前自己也接触过一段时间的复杂网络(网络科学),没想到,将网络科学的思想引入到向量搜索算法中,可以产生令人眼前一亮的成果。在网络科学中,小世界现象(Small World phenomenon)指的是一个网络中的节点(或者个体)之间通过短路径(较少的中间节点)相互连接的现象。具体来说,小世界网络具有以下几个特点:
短路径长度:尽管网络可能很大,但任意两个节点之间的路径长度通常都很短。这意味着,大多数节点可以通过较少的中间节点相互到达,这种路径长度通常比网络的直径(最长最短路径之间的最长距离)短得多。
高聚类系数:虽然路径长度很短,但网络中的节点通常会聚集在彼此的周围形成社团或群体。这些群体内的节点之间通常有更多的连接,形成高聚类系数。
随机连接:小世界网络通常具有随机连接的特性,即节点不仅连接到其直接邻居,还可能通过较远的节点间接连接到其他节点。这种随机性导致了网络中的短路径现象。
更通俗的解释:小世界现象最早由社会学家斯坦利·米尔格拉姆(Stanley Milgram)在他的"六度分隔"实验中观察到。在这个实验中,人们被要求通过将信件转发给自己认识的朋友来试图将信件传递给一个陌生人。结果显示,平均只需大约六次传递就可以将信件传递给目标个体,因此产生了"六度分隔"的概念。
接下来,本文将会从该算法提出的业务背景、基础知识、原理分析、算法应用等方面进行阐述。
1. HNSW需要解决的业务问题
相似性搜索是目前广泛被用到的一种基本技术,用于查找数据集中与给定查询"最接近"的数据点;由于这些搜索通常在向量空间中进行,因此也被称为"向量搜索"。这类搜索被系统广泛应用于自然语言处理、语音识别、图像/视频检索和推荐系统(等等);最近,它已成为生成式人工智能中提高性能的主要驱动因素之一,通过检索增强生成(RAG)。
近似最近邻ANN 算法分为三大类:树、哈希和图。使用暴力搜索、基于树的结构(如 KD 树)和哈希(如局部敏感哈希)等方法,在大型高维数据集中的扩展性不佳,需要更有效的解决方案。而分层可导航小世界图(Hierarchical Navigable Small World, HNSW)在2016年被引入到学术视野中,逐步被业界证明是一种可行的技术解。HNSW通过引入层次("层级")来连接数据,类似于数字地图上添加"缩放"功能,能够解决在大型多维数据集中高效地找到最近邻居的问题。简而言之,HNSW 创建了一个多层次的图结构,其中每一层都是一个简化的、可导航的小世界网络。你可以将其类比为数字地图上的道路网络。放大地图,你可以看到城市和城镇通过主要道路连接。缩小到城市级别,你可以看到城市内部的人群如何相互连接。在最精细的缩放级别,你可以看到社区和社群之间的相互连接。
HNSW 之所以重要,是因为它提供了一种在复杂的高维数据中导航和搜索的高效方法。这种结构允许更快速、更精确的最近邻居搜索,通过按层次组织数据并启用可导航的快捷方式,HNSW 显著减少了进行这些搜索所需的时间和计算资源,使其成为处理机器学习和人工智能中大型数据集的关键工具。HNSW是向量相似性搜索中表现最好的索引之一,具有超快的搜索速度和出色的召回率。
2. 基础知识
HNSW中包含两种关键的基础技术:可导航小世界图以及概率跳表。利用基于图的数据结构,数据(节点)通过相似边相互连接,可以通过跟随这些边在图中进行导航。
2.1 可导航小世界(NSW)
其思想是,如果我们构建一个邻近图,使其既有长距离链接又有短距离链接,那么搜索时间可以减少到(多项式/)对数复杂度。图中的每个顶点连接到几个其他顶点。称这些连接的顶点为朋友,每个顶点保持一个朋友列表,从而创建我们的图。在搜索 NSW 图时,可以从一个预定义的入口点开始。这个入口点连接到几个附近的顶点。确定这些顶点中哪个最接近我们的查询向量并移动到那里。
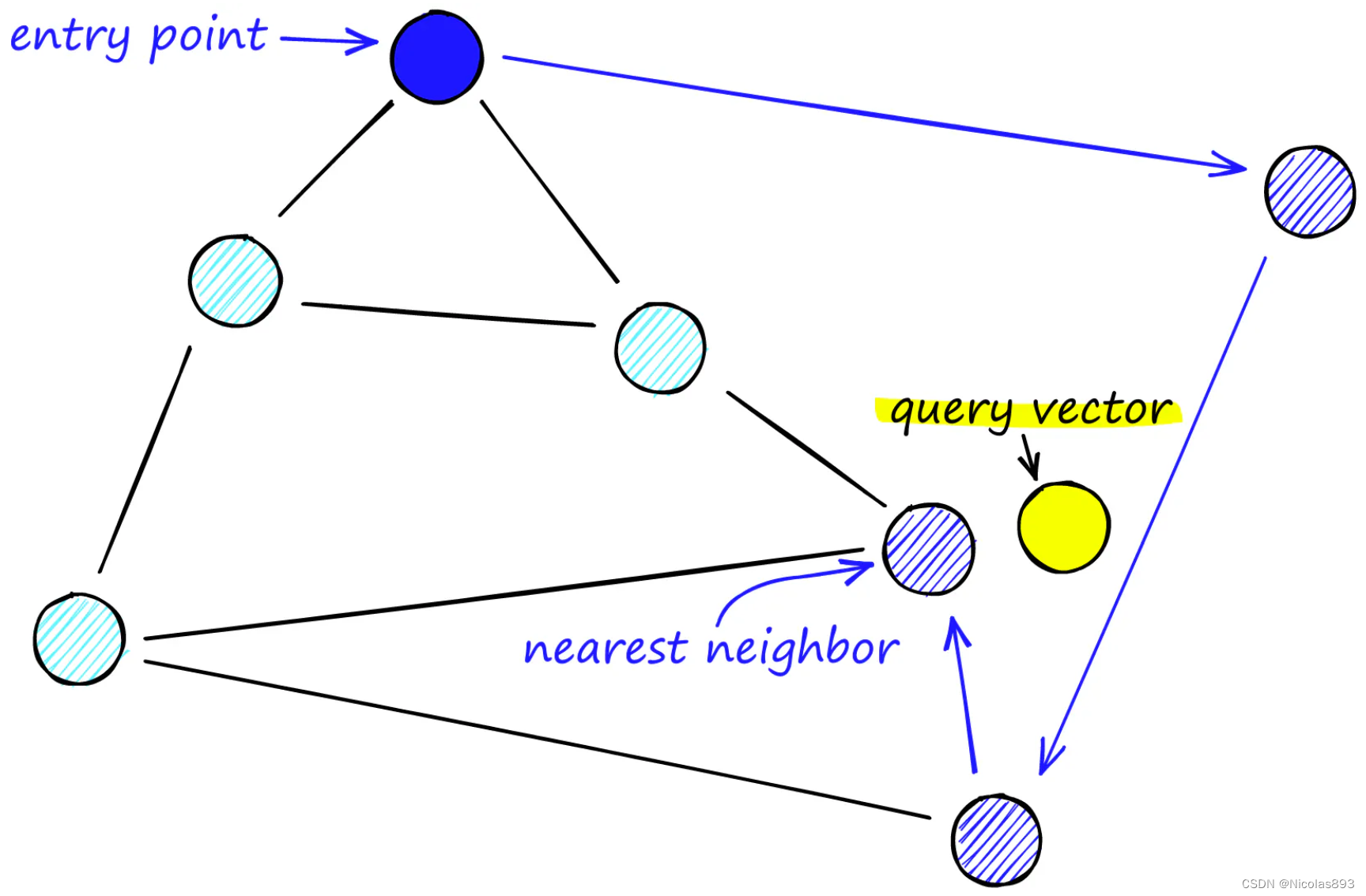
可导航小世界的原理是,从任何一个节点出发,可以在少量"跳跃"中到达任何其他节点。在确定了一个入口点之后(可以是随机的、启发式算法),搜索相邻的节点,看看是否有比当前节点更近的节点。搜索移动到这些相邻节点中最接近的节点,并重复这一过程,直到没有更近的节点。
在下面的示例中,我们正在搜索最接近"A"的节点,从节点"0"开始。该节点连接到三个节点,但最接近"A"的是节点"1"。然后我们从节点"1"重复这个过程,发现节点"2"比节点"1"更近,最后节点"3"比节点"2"更近。与节点"3"连接的节点都比"A"更远,因此我们确定节点"3"是最接近的节点:
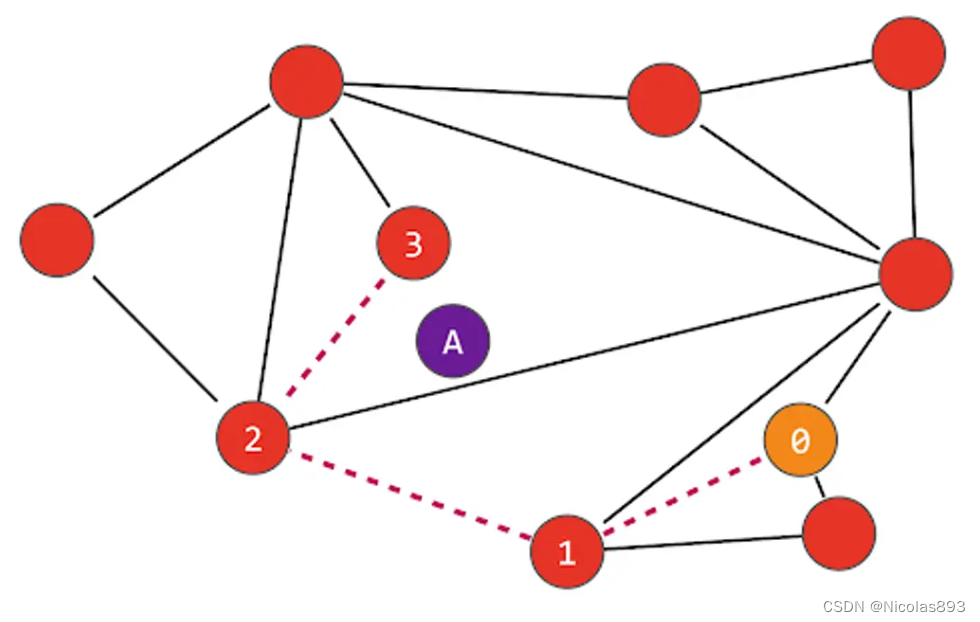
在构建图时,参数 M 设置了新节点与其最近邻居的边的数量(上面的示例使用 M=2)。更大的 M 意味着一个更互联、密度更大的图,但这将消耗更多的内存,并且插入速度更慢。随着节点被插入图中,系统搜索 M 个最近的节点并与这些节点建立双向连接。网络节点将具有不同程度的连接性,类似于社交网络中的用户,有些用户连接到成千上万(或数百万)的人,而其他用户仅连接到几百(或几十)的人。另一个 Mmax 参数决定了一个节点可以拥有的最大边数,因为过多的边会影响性能。稍后会重点介绍一下新增数据入图的过程,帮助理解。
NSW 搜索的一个缺点是它总是选择通往"最近节点"的最短路径,而不考虑图的更广泛结构;这被称为"贪婪搜索",有时可能会导致被困在局部最优或局部区域------这种现象被称为"过早停止"。考虑以下图中的情况,我们从不同的节点"0"进入,并且有一个不同的"A"节点:连接到节点"0"的两个节点都比"A"更远,因此算法确定"0"是最接近的节点。这种情况可能在导航过程中的任何点发生,而不仅仅是在起始节点。算法不会尝试探索任何更远的节点,因为它假设更远的节点会离得更远!
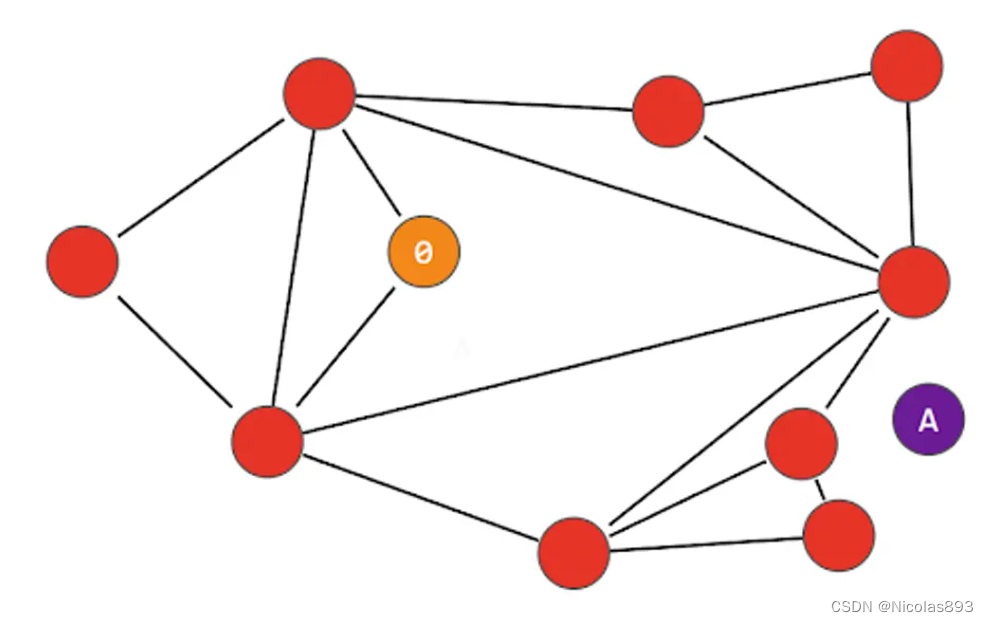
有一些解决这种贪婪性带来的早停问题。可导航小世界模型被定义为任何使用贪婪路由且具有(多项式/)对数复杂度的网络。当图不可导航时,贪婪路由的效率在较大的网络(1-10K+ 顶点)中会下降。路由是由两个阶段组成。从"缩放"阶段开始,经过低度顶点(度是顶点具有的链接数)------然后是"缩小"阶段,经过高度顶点。高度顶点有很多链接,而低度顶点的链接很少。 停止条件是,在当前顶点的朋友列表中找不到更近的顶点。正因为如此,在缩放阶段(链接较少,不太可能找到更近的顶点),我们更有可能碰到局部最小值并过早停止。为了减少过早停止的概率(并提高召回率),我们可以增加顶点的平均度数,但这会增加网络的复杂性(和搜索时间)。因此,需要在召回率和搜索速度之间平衡顶点的平均度数,后续会看到需要设置节点连接数的参数M、Mmax等。另一种方法是从高阶顶点开始搜索(先缩小)。对于 NSW 来说,这确实能提高低维数据的性能。这也是 HNSW 结构中的一个重要因素。
2.2 概率跳表
概率跳表允许像排序数组一样快速搜索,同时使用链表结构进行轻松(且快速)的新元素插入。跳跃表的结构允许插入和查询操作在平均 O(log n) 的时间内完成------操作时间随着数据量的增加呈对数增长,而不是线性、多对数或更糟。在跳跃表的底层,每个节点都按顺序连接到下一个节点。随着更多层的添加,序列中的节点会被"跳过"。以下是维基百科中的插图,展示了如何将十个节点组织成一个四层跳跃表:
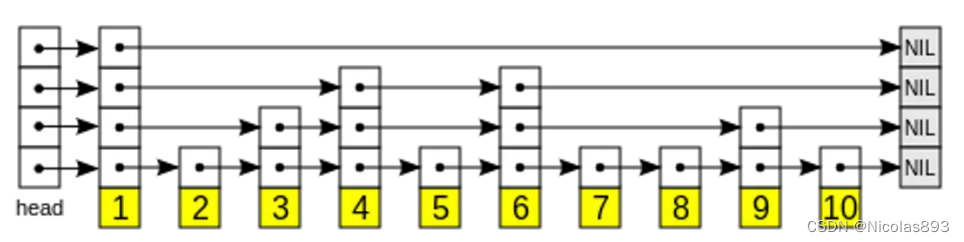
跳表通过构建多个链表层来工作。在第一层中,找到跳过许多中间节点/顶点的链接。当向下移动层次时,每个链接的"跳过"数量会减少。要搜索跳表,从具有最长"跳过"的最高层开始,并沿着边向右(下方)移动。如果发现当前节点的"键"大于正在搜索的键------已经超过了目标,因此向下移动到下一层中的前一个节点。
跳跃表通常是以概率方式构建的------节点出现在更高层的概率降低,这意味着更高层的节点较少。当搜索一个节点时,算法从顶层的"头部"进入,并继续前进到大于或等于目标的下一个元素。在这一点上,搜索元素已找到,或者它会下降到下一层(更细粒度的层),并重复这一过程,直到找到搜索节点,或者找到搜索节点的相邻节点。在跳跃表和相似性搜索的上下文中,"大于"意味着"更相似"------例如,在余弦相似度的情况下,最接近的相似度为1。
插入操作涉及确定节点进入结构的层,查找到第一个"大于"节点,但同时记录下"大于"节点之前的最后一个节点。一旦找到那个"大于"节点,它会更新最后一个节点指向新节点,并将新节点指向"大于"节点。然后它继续到下一层,直到节点出现在所有层中。删除操作遵循类似的逻辑来定位和更新指针。
概率跳表结构中,从顶层开始。如果当前键大于正在搜索的键(或者到达末尾),就下到下一层。
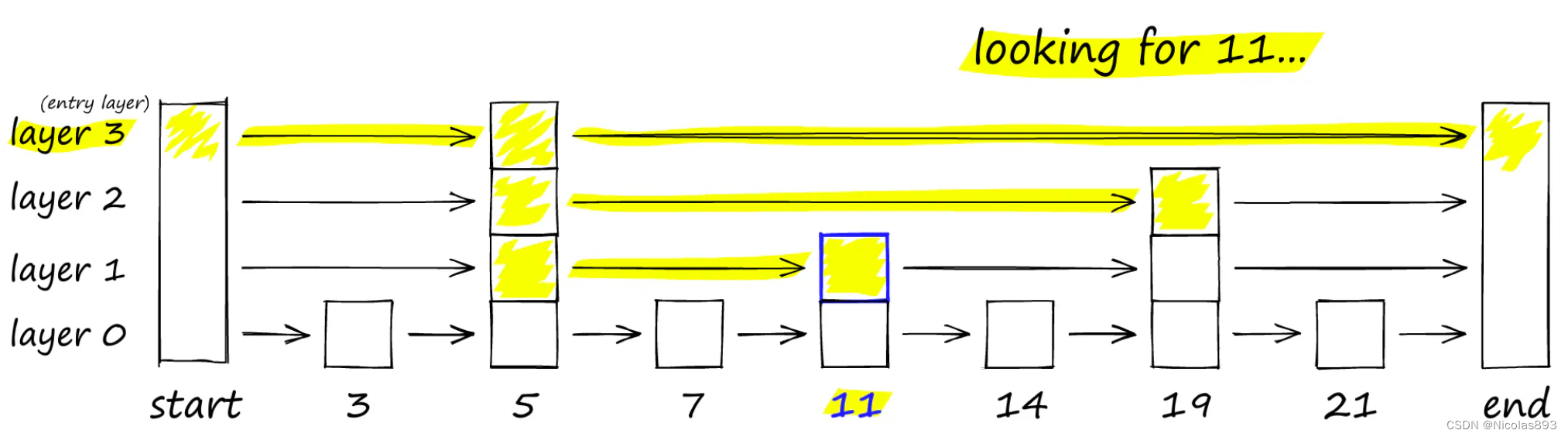
HNSW 继承了相同的分层格式,在最高层具有较长的边(用于快速搜索),在较低层具有较短的边(用于精确搜索)。将层次结构添加到 NSW 中会产生一个跨不同层次分离链接的图。在顶层,我们有最长的链接,而在底层,我们有最短的链接。
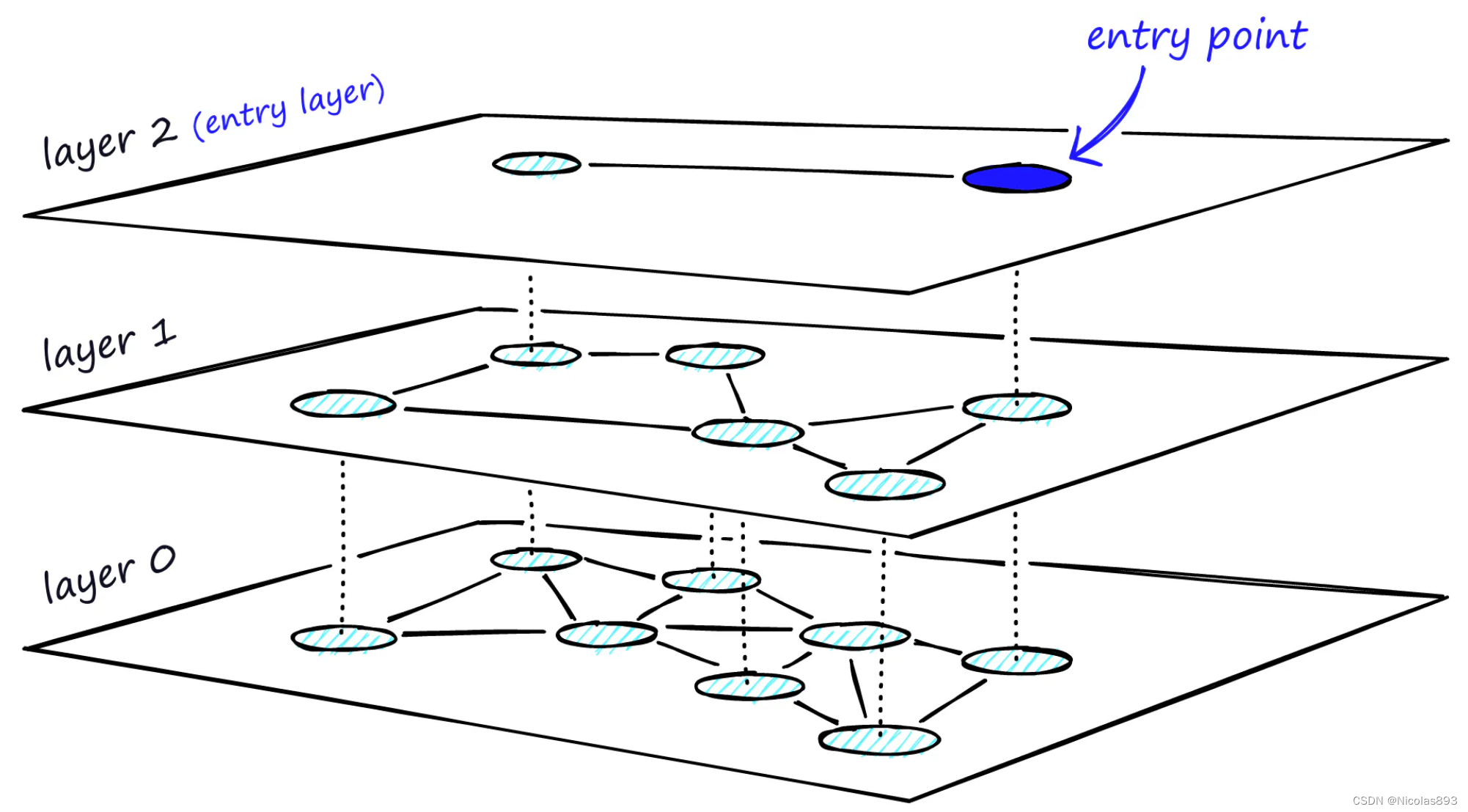
HNSW 的分层图,顶层是入口点,只包含最长的链接,随着向下移动层次,链接的长度变得更短且数量更多。 在搜索过程中,进入顶层,在这里找到最长的链接。这些顶点往往是高阶顶点(链接分布在多个层次上),这意味着默认情况下,从 NSW 所描述的缩小阶段开始。在每一层中遍历边缘,就像在 NSW 中一样,贪婪地移动到最近的顶点,直到找到一个局部最小值。与 NSW 不同的是,此时转移到当前顶点的下一层并重新开始搜索。重复这一过程,直到找到最底层------第0层的局部最小值。
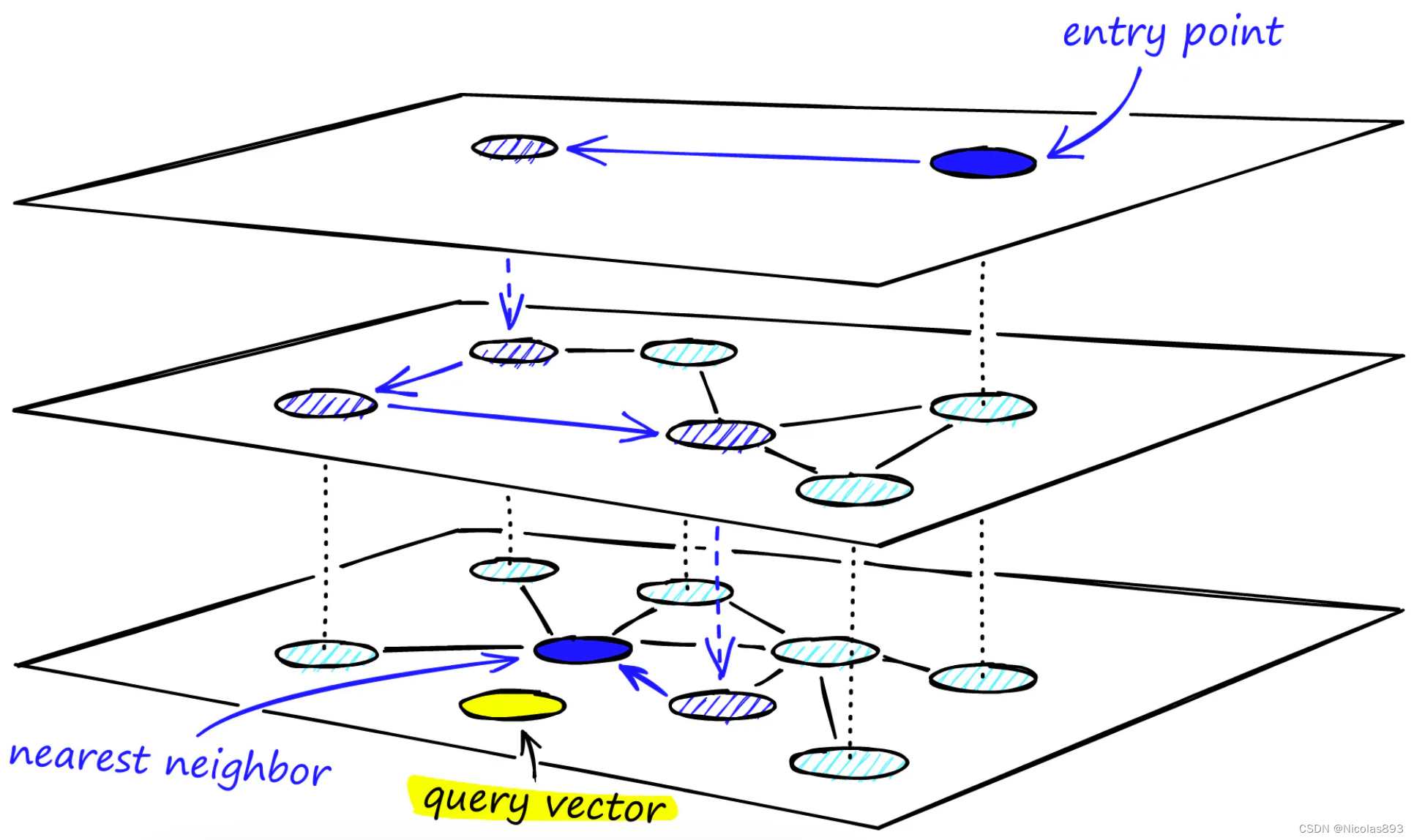
HNSW 将跳跃表的快速遍历与 NSW 的丰富互连性相结合,并添加了层次结构以增强搜索效率。HNSW 的核心是其分层架构,它将数据组织成相互连接的节点层,允许快速跳过不必要的计算,专注于相关的搜索区域。这种层次化的方法,加上小世界概念,优化了通往高精度结果的路径,对于需要快速准确检索的应用程序至关重要。
3. HNSW索引构建与搜索
3.1 构建层次结构
构建层次结构 HNSW 的基础在于其层次结构。构建这个多层图从代表整个数据集的基础层开始。随着层层上升,每个后续层作为下层的简化概览,包含更少的节点,并充当允许跨图更长跳跃的快速通道。HNSW 中的概率分层与跳跃表类似,由通常表示为 mL 的参数控制。该参数决定了节点出现在连续层中的可能性,随着层级上升,概率呈指数下降。正是这种概率的指数衰减在更高层级上创造了一个逐渐稀疏且更易导航的结构,确保了图在搜索操作中的效率。
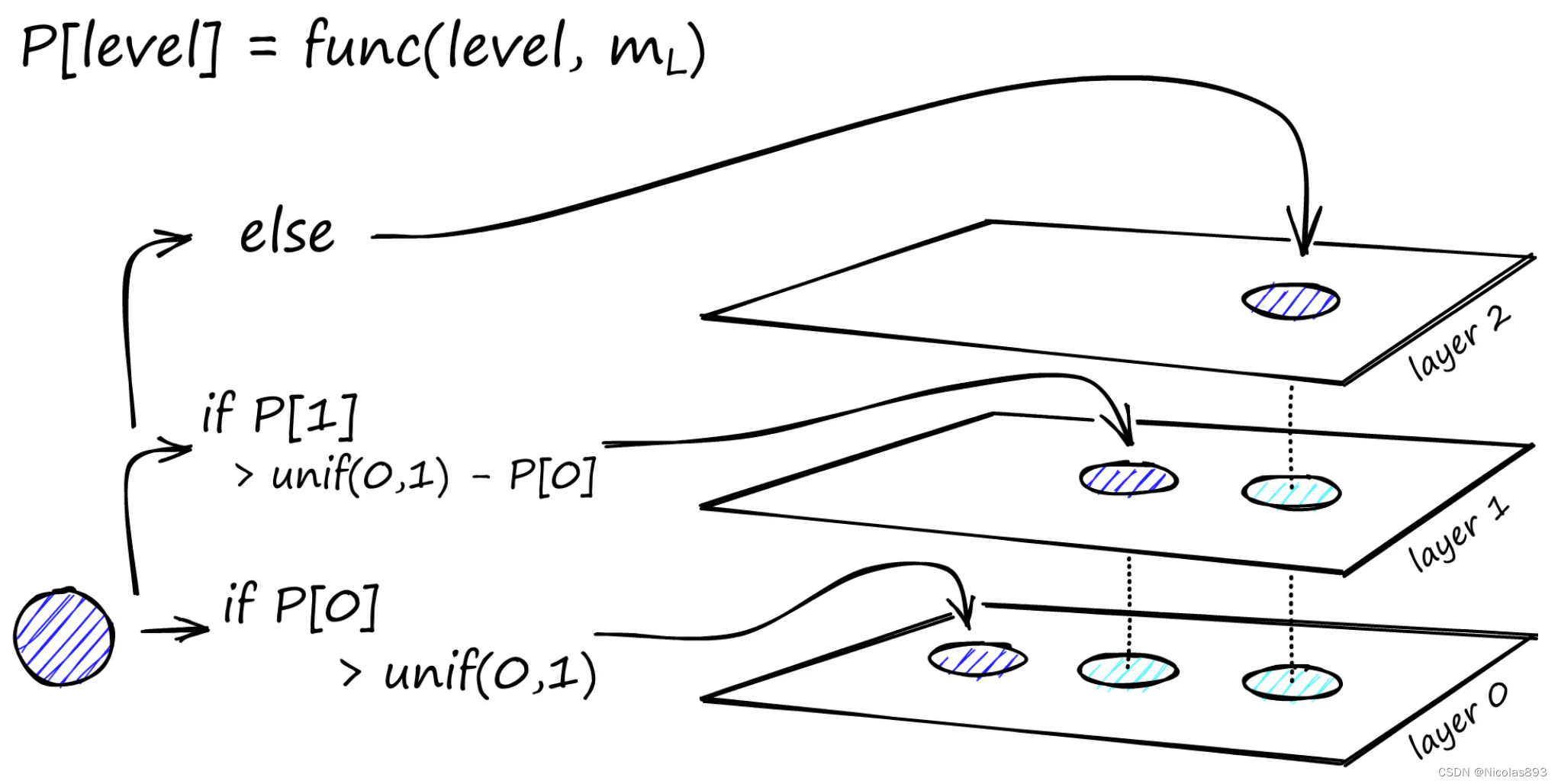
3.2 构建可导航图
在 HNSW 的每一层中构建可导航图是决定算法有效性的关键。参数 M 和 Mmax在此过程中起着至关重要的作用。新的参数 Mmax0 专用于基础层,允许该基础层比更高层具有更大的连通性。HNSW 还添加了 efConstruction 参数,该参数确定在添加新节点时动态候选列表的大小。较高的 efConstruction 值意味着建立连接的过程更彻底,但速度较慢。该参数有助于平衡连接密度,影响搜索的效率和准确性。这一阶段的一个重要部分是高级邻居选择启发式方法,这是 HNSW 的关键创新。该启发式方法不仅仅将新节点链接到其最近的邻居,还识别出能够改善整个图连通性的节点。这种方法在连接不同的数据簇时特别有效,创建了图中的关键快捷方式。如 HNSW 论文中所示,这种启发式方法促进了纯粹基于邻近性的方法可能忽略的连接,显著增强了图的可导航性:
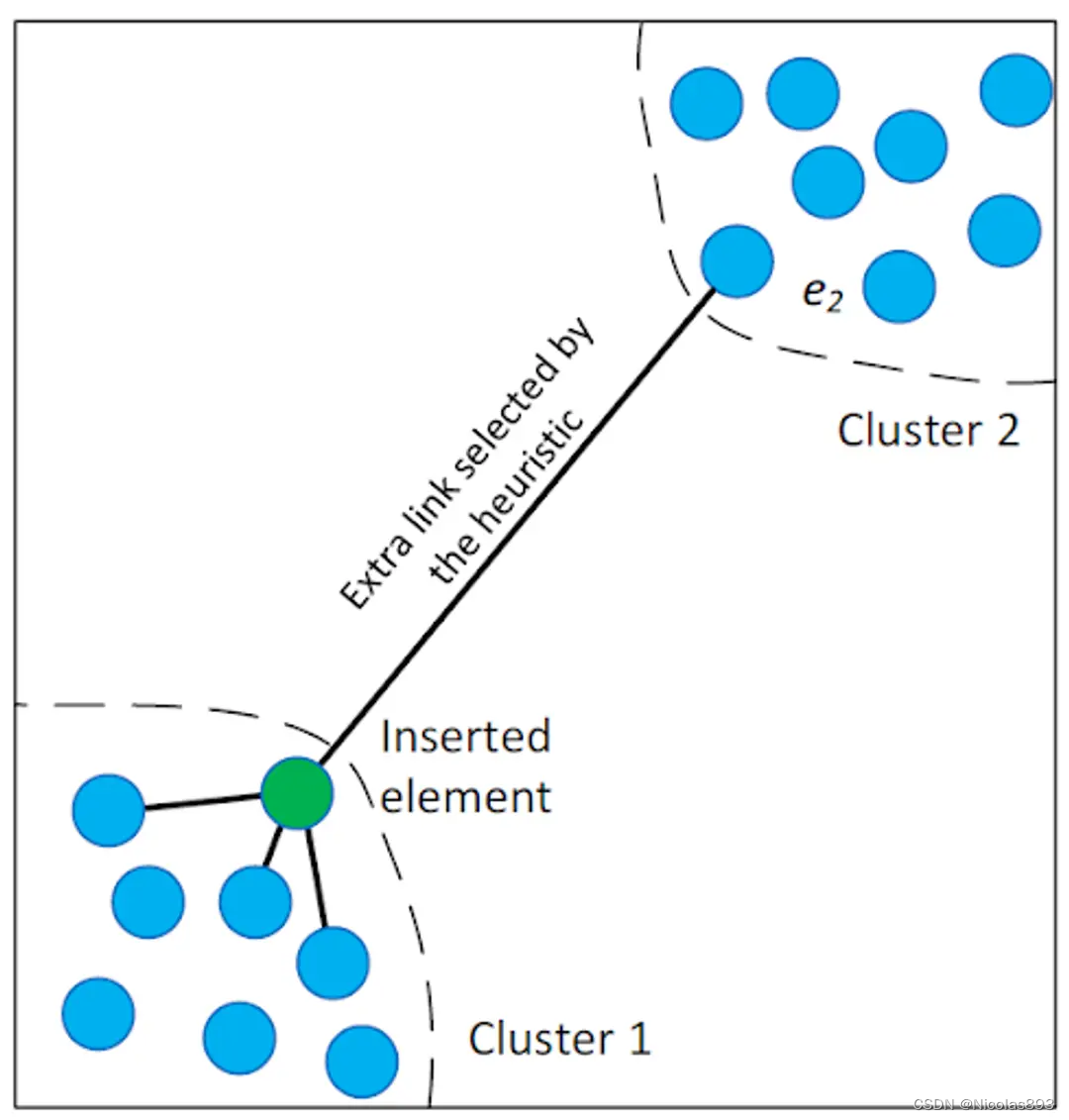
通过战略性地平衡连接密度和采用智能邻居选择,HNSW 构建了一个多层图结构,不仅对即时搜索有效,而且对未来的搜索需求也是最优结构。HNSW 在管理复杂的高维数据空间中表现出色,成为相似性搜索任务中的宝贵工具。
3.3 插入与删除操作
3.3.1 插入操作
HNSW 的创建者发现,当最小化各层之间共享邻居的重叠时,可以实现最佳性能。减少 m_L 可以帮助最小化重叠(将更多向量推向第0层),但这会增加搜索期间的平均遍历次数。因此,使用一个平衡两者的 m_L 值。一个经验法则是这个最优值为 1/ln(M)。
图构建从顶层开始。进入图后,算法贪婪地遍历边缘,找到与插入向量 q 最近的 ef 个邻居------此时 ef = 1。找到局部最小值后,它会下移到下一层(就像在搜索期间一样)。这个过程重复进行,直到达到我们选择的插入层。此时开始构建的第二阶段。ef 值增加到 efConstruction(设定的参数),这意味着会返回更多的最近邻居。在第二阶段,这些最近邻居是新插入元素 q 的链接候选项,并作为进入下一层的入口点。从这些候选项中添加 M 个邻居作为链接------最简单的选择标准是选择最接近的向量。经过多次迭代后,添加链接时还需要考虑两个参数M_max 和M_max0 。
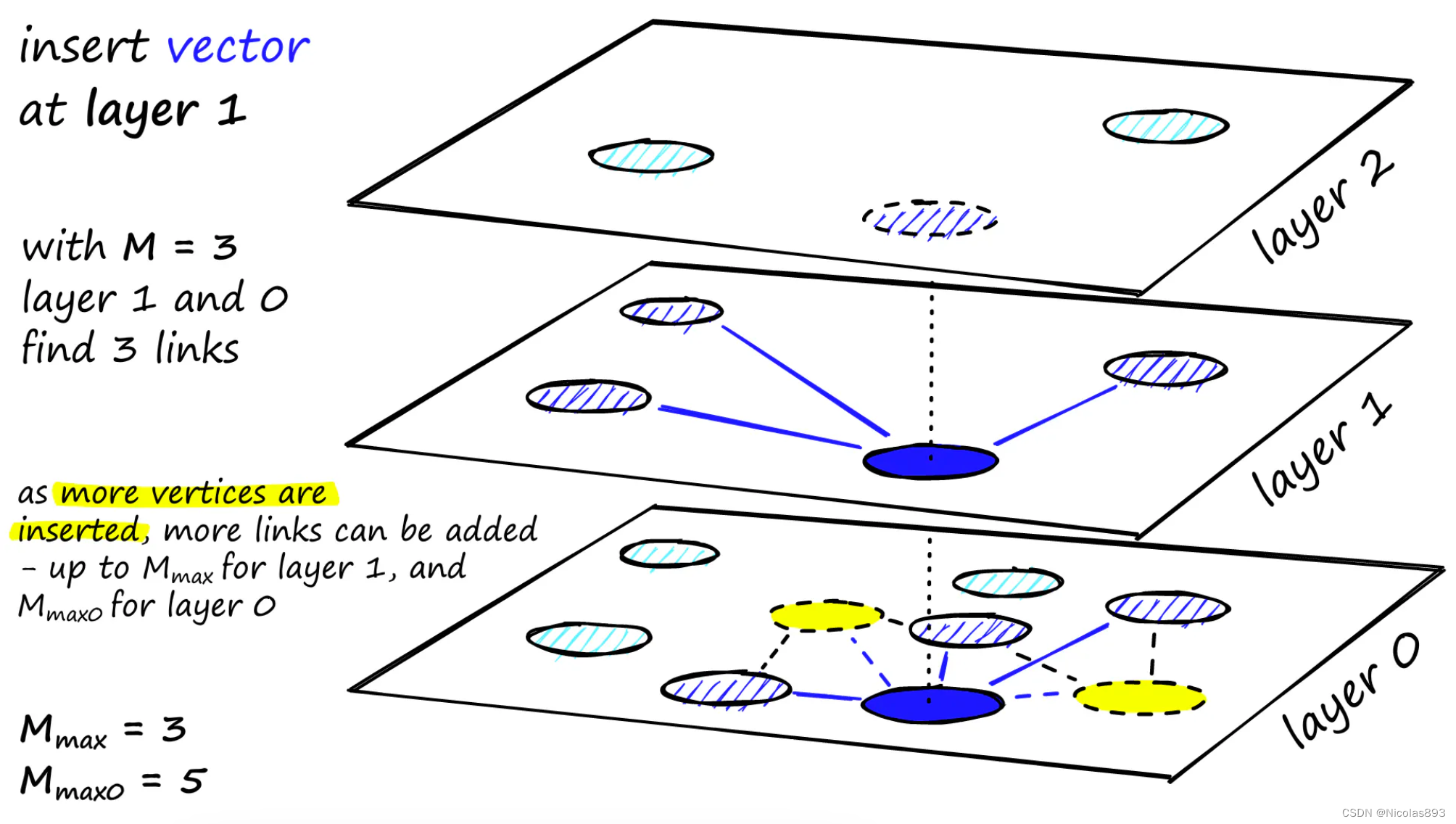
M_max 定义了一个顶点可以拥有的最大链接数,M_max0 则定义了第0层顶点的最大链接数。插入从所选层开始,将新节点连接到该层内最接近的 M 个邻居。如果邻居节点的连接数超过 Mmax,则移除多余的连接。然后以类似的方式将节点插入下一层,直到参考 Mmax0 作为最大连接数的底层。
HNSW 确定新数据插入的层是通过一个随机过程来实现的,主要依赖于两个关键参数:M 和 mL。这里简要说明一下:
-
M 参数:决定了每个节点在插入时连接的最近邻数量。这决定了在每层上节点的平均连接密度。
-
mL 参数:它是一个与层级相关的参数,用于控制节点在不同层级上出现的概率。随着层级的增加,节点在更高层级出现的概率会指数级地减少。
HNSW 通过使用概率方法来选择节点的插入层级,以便在构建图形时确保较高层级上的稀疏性,从而优化搜索效率。在 HNSW 中,插入新节点并构建连接的过程是通过节点之间的相似度或距离来确定它们之间的连接关系。具体来说:
-
相似度度量:通常使用的是向量之间的余弦相似度或欧氏距离。余弦相似度是常见的用于衡量向量之间相似程度的指标,特别适用于高维空间中的向量。
-
层级内的连接:在 HNSW 的每个层级中,当插入新节点时,算法会根据其与现有节点的相似度选择最近的 M 个邻居节点,然后建立双向连接。这些连接不是固定的,而是在搜索时动态调整的,以便在高维空间中有效地导航和搜索。
因此,HNSW 在插入新节点并构建连接时,通过相似度度量来确定节点之间的连接关系,以确保图形在高维向量空间中的有效性和可导航性。插入操作的停止条件是达到0层的局部最小值,这意味着当在0层中无法找到更近的邻居时,插入过程结束。
3.3.2 删除操作
从 HNSW 图中删除节点的过程涉及在层次结构的多个层中仔细更新其邻居的连接。这对于保持图的结构完整性和可导航性至关重要。不同的 HNSW 实现可能采用各种策略,以确保每层内的连接保持不变,并且没有节点被孤立或从图中断开。这种方法确保了图在最近邻搜索中的持续效率和可靠性。
总之,HNSW 中的插入和删除过程设计得既高效又能保持图的层次和可导航性,这对于算法快速准确的最近邻搜索能力至关重要。这些过程突显了 HNSW 的适应性,使其成为动态高维相似性搜索应用中的鲁棒选择。
3.4 搜索过程
在 HNSW 中搜索涉及穿越层次结构,从最顶层开始,逐层下降到底层,目标的最近邻居位于底层。该算法利用结构的分层优势------使用较高层进行快速粗粒度探索,较低层进行详细搜索------优化通往最相似节点的路径。启发式方法,如选择最佳入口点和最小化跳跃次数,被用来加速搜索,而不影响结果的准确性。
寻找节点 "A" 的最近邻居时,首先选择位于最顶层的 Layer 2 的一个节点,并像在 NSW 中一样导航到其最近的邻居节点 "1"。此时,下降一层到 Layer 1,搜索这一层是否有更近的邻居,找到的节点是 "2"。最终下降到底层 Layer 0,发现节点 "3" 是最近的:
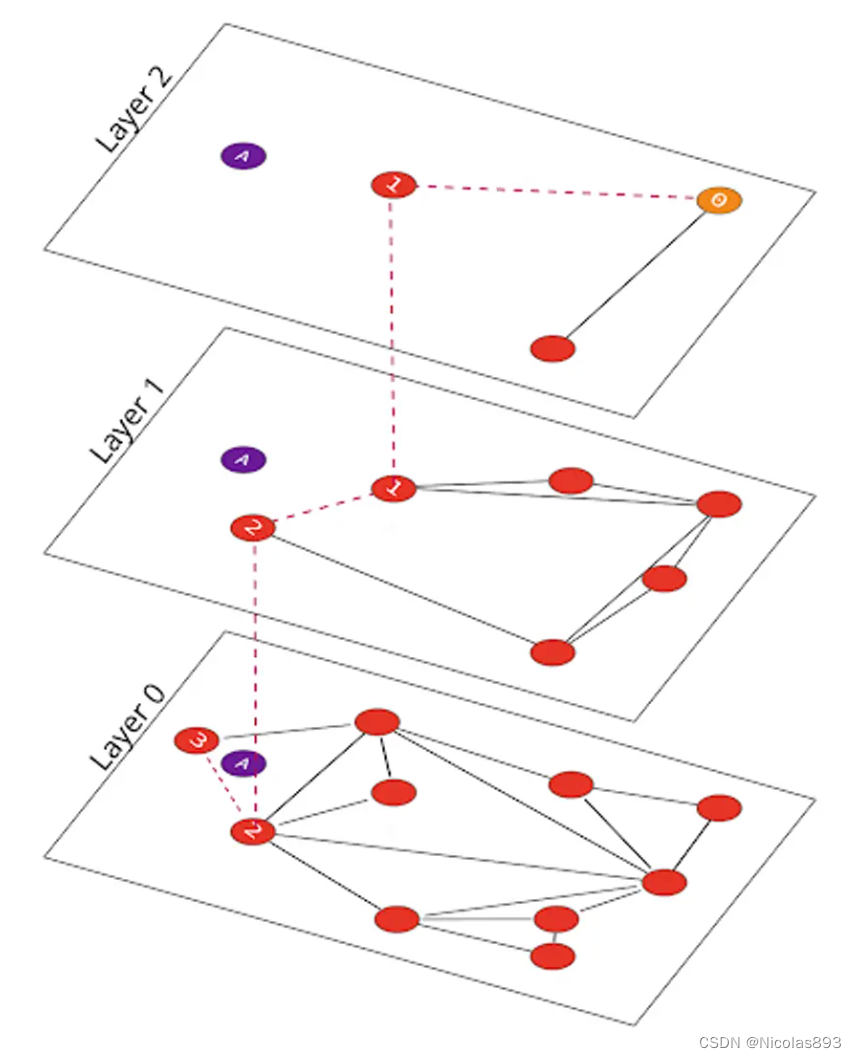
在 HNSW 中的搜索与在 NSW 中的搜索相似,但增加了"层"的维度,使得可以快速修剪图表,仅保留相关的邻居。
4. HNSW的实现
4.1 构建HNSW索引
使用Facebook AI的相似性搜索库(Faiss)来实现HNSW,并测试不同的构建和搜索参数,以观察这些参数如何影响索引性能。
要初始化HNSW索引,编写如下代码:
# setup our HNSW parameters
d = 128 # vector size
M = 32
index = faiss.IndexHNSWFlat(d, M)
print(index.hnsw)到此为止,已经设置了 M 参数,即在插入时添加到每个顶点的邻居数,但我们还缺少 M_max 和 M_max0。在 Faiss 中,这两个参数在索引初始化时通过调用 set_default_probas 方法自动设置。M_max 值被设置为 M,而 M_max0 被设置为 M*2。
在通过 index.add(xb) 构建索引之前,会发现层(或在 Faiss 中的级别)数量尚未设置:
# the HNSW index starts with no levels
index.hnsw.max_level-1
# and levels (or layers) are empty too
levels = faiss.vector_to_array(index.hnsw.levels)
np.bincount(levels)
array([], dtype=int64)
如果继续构建索引,会发现这两个参数现在都已经设置好了。
index.add(xb)
# after adding our data we will find that the level
# has been set automatically
index.hnsw.max_level4
# and levels (or layers) are now populated
levels = faiss.vector_to_array(index.hnsw.levels)
np.bincount(levels)
array([ 0, 968746, 30276, 951, 26, 1], dtype=int64)
这里可以看到我们的图中有多少层,从 0 -> 4,这由 max_level 描述。而 levels 显示了从 0 到 4 层(忽略第一个 0 值)每一层上的顶点分布。甚至可以找到哪个向量是我们的入口点:
index.hnsw.entry_point这是对 Faiss 风格的 HNSW 图的高层视图,但在测试索引之前,深入了解一下 Faiss 是如何构建这个结构的。
当初始化索引时,传入向量的维度 d 和每个顶点的邻居数 M。这调用了方法 'set_default_probas',并传入了 M 和 1 / log(M) 作为 levelMult(相当于上面的 m_L)。这个方法的 Python 等效代码如下:
def set_default_probas(M: int, m_L: float):
nn = 0 # set nearest neighbors count = 0
cum_nneighbor_per_level = []
level = 0 # we start at level 0
assign_probas = []
while True:
# calculate probability for current level
proba = np.exp(-level / m_L) * (1 - np.exp(-1 / m_L))
# once we reach low prob threshold, we've created enough levels
if proba < 1e-9: break
assign_probas.append(proba)
# neighbors is == M on every level except level 0 where == M*2
nn += M*2 if level == 0 else M
cum_nneighbor_per_level.append(nn)
level += 1
return assign_probas, cum_nneighbor_per_level正在构建两个向量 --- assign_probas,表示在给定层次上插入的概率,以及 cum_nneighbor_per_level,表示在不同插入层次上分配给顶点的累积最近邻数。
assign_probas, cum_nneighbor_per_level = set_default_probas(
32, 1/np.log(32)
)
assign_probas, cum_nneighbor_per_level([0.96875,
0.030273437499999986,
0.0009460449218749991,
2.956390380859371e-05,
9.23871994018553e-07,
2.887099981307982e-08],
64, 96, 128, 160, 192, 224)
从这里可以看出,在级别0插入向量的概率显著高于较高级别。这个函数意味着较高级别更稀疏,降低了"卡住"的可能性,并确保我们从更长的范围遍历开始。
assign_probas 向量被另一个名为 random_level 的方法使用 --- 在这个函数中,每个顶点被分配一个插入级别。
def random_level(assign_probas: list, rng):
# get random float from 'r'andom 'n'umber 'g'enerator
f = rng.uniform()
for level in range(len(assign_probas)):
# if the random float is less than level probability...
if f < assign_probas[level]:
# ... we assert at this level
return level
# otherwise subtract level probability and try again
f -= assign_probas[level]
# below happens with very low probability
return len(assign_probas) - 1使用NumPy的随机数生成器rng(在下面初始化)生成一个随机浮点数f。对于每个级别,检查f是否小于assign_probas中分配给该级别的概率 --- 如果是,那就是插入层级。
如果f太高,从f中减去assign_probas的值,并尝试下一个级别。这个逻辑的结果是,向量最有可能被插入到级别0。如果不是,每增加一个级别,插入概率会递减。
最后,如果没有级别满足概率条件,将向量插入到最高级别,即返回 len(assign_probas) - 1。如果比较我们的Python实现和Faiss的分布,我们会看到非常相似的结果。
chosen_levels = []
rng = np.random.default_rng(12345)
for _ in range(1000000):
chosen_levels.append(random_level(assign_probas, rng))
np.bincount(chosen_levels)
array([968821, 30170, 985, 23, 1], dtype=int64)
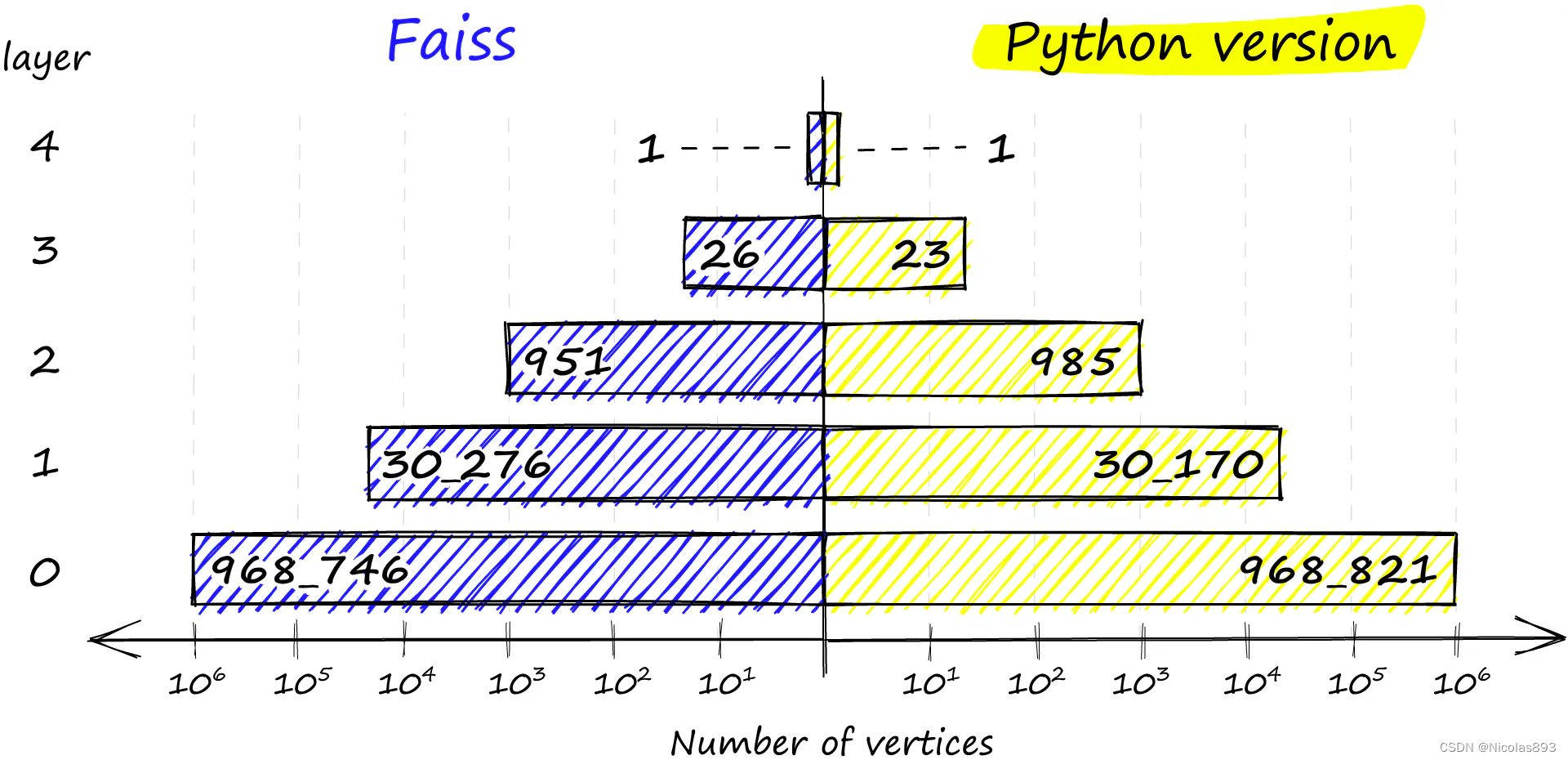
在Faiss实现(左)和Python实现(右)中各层级上顶点的分布。 Faiss实现还确保我们始终在最高层有至少一个顶点作为图的入口点。
4.2 HNSW性能
接下来观察不同参数对我们的召回率、搜索和构建时间以及内存使用的影响。将修改三个参数:M、efSearch和efConstruction。将对Sift1M数据集进行索引,可以使用此脚本下载和准备数据。
像之前一样,初始化索引如下:
index = faiss.IndexHNSWFlat(d, M)初始化索引后可以修改的另外两个参数是 efConstruction 和 efSearch。
index.hnsw.efConstruction = efConstruction
index.add(xb) # build the index
index.hnsw.efSearch = efSearch
# and now we can search
index.search(xq[:1000], k=1)必须在通过 index.add(xb) 构建索引之前设置 efConstruction 值,但是 efSearch 可以在搜索之前的任何时候设置。
首先看一下召回性能。
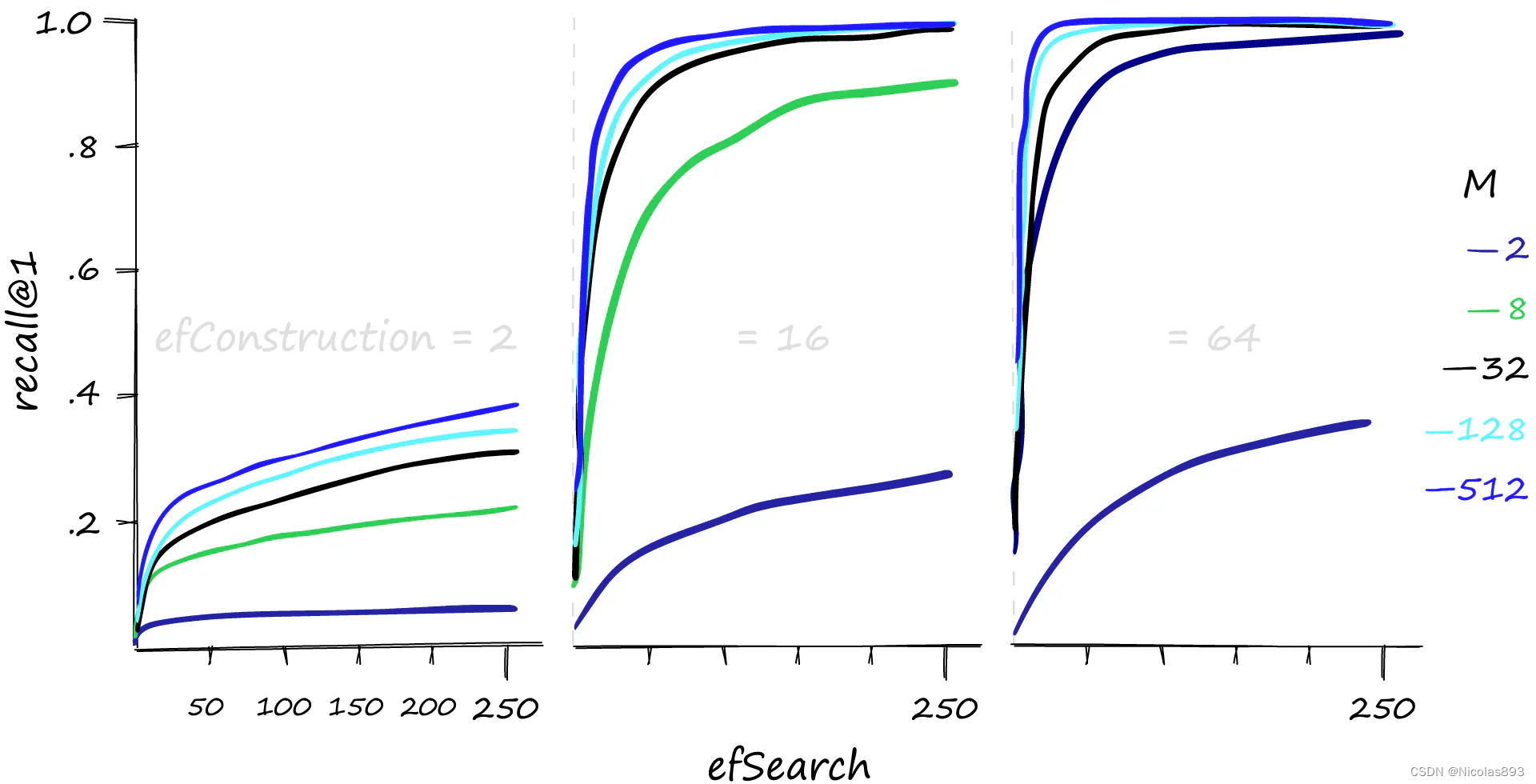
不同 M、efConstruction 和 efSearch 参数下的 Recall@1 性能。 较高的 M 和 efSearch 值可以显著提高召回性能 --- 同时也明显需要合理的 efConstruction 值。还可以增加 efConstruction 以在较低的 M 和 efSearch 值下实现更高的召回率。
然而,这种性能并非毫无代价。与往常一样,需要在召回率和搜索时间之间进行权衡 。
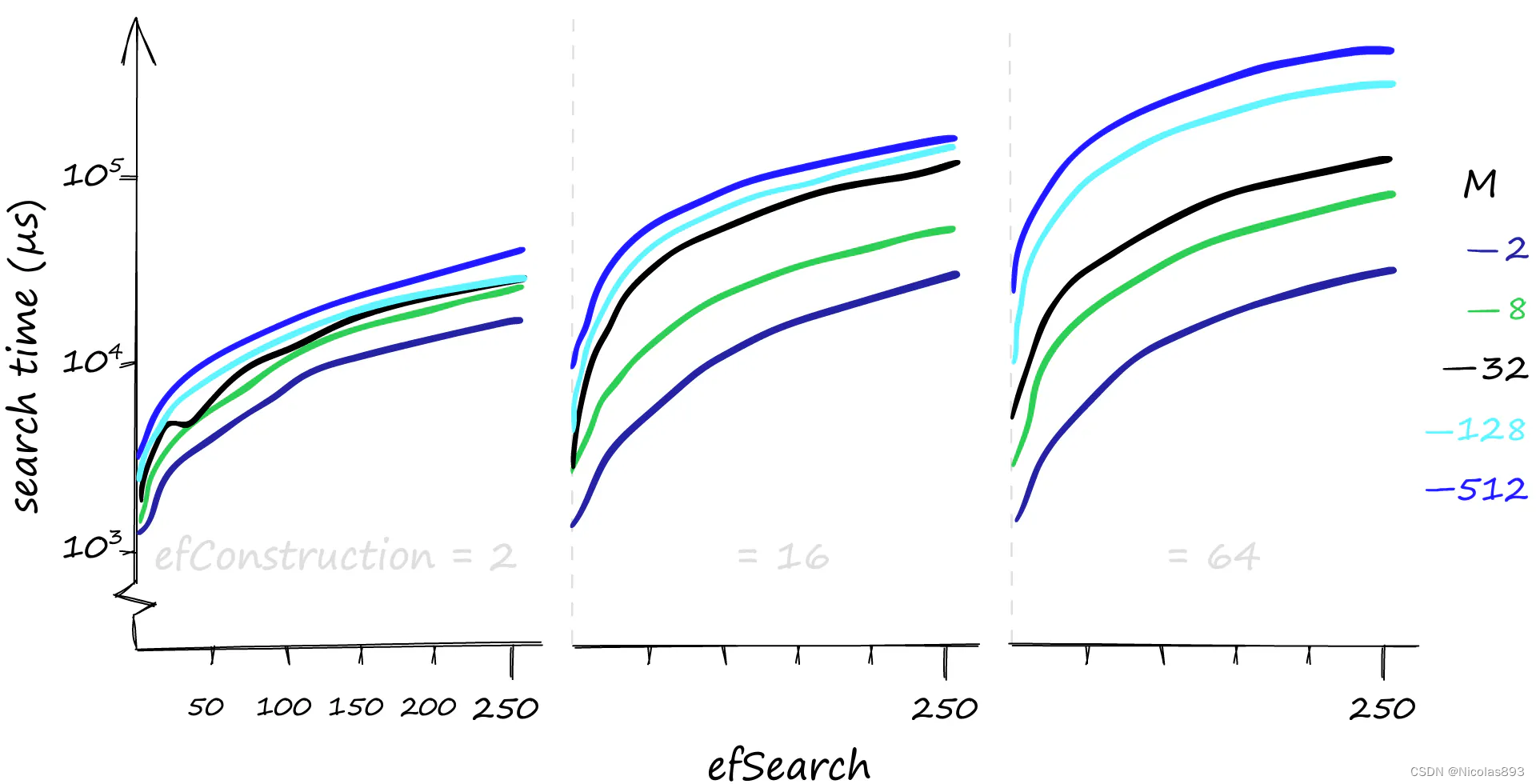
在搜索1000个查询时,不同 M、efConstruction 和 efSearch 参数下的搜索时间,单位为微秒(µs)。注意,y 轴使用对数刻度。 虽然较高的参数值可以提供更好的召回率,但对搜索时间的影响可能非常显著。在这里,搜索1000个相似向量(xq:1000),召回率/搜索时间可以从80%-1毫秒到100%-50毫秒不等。如果对召回率要求不高,搜索时间甚至可以达到0.1毫秒。
关于efConstruction和efSearch参数,做一下说明:
在HNSW(Hierarchical Navigable Small World)索引中,
efConstruction和efSearch是两个重要的参数:
efConstruction:
efConstruction是用来控制构建索引时的动态候选列表的大小。在构建索引过程中,为了确定节点的连接关系,HNSW算法需要动态地选择与新节点进行连接的候选节点。efConstruction定义了这个动态候选列表的大小。- 较大的
efConstruction值会导致更大的动态候选列表,这可能会增加索引构建的时间,因为算法需要在更多的节点中进行选择。但是,它可以帮助改善索引的质量,尤其是在处理高维数据时,能够更好地确保节点之间的连接质量和图结构的稳定性。efSearch:
efSearch是在搜索阶段用来控制搜索时的动态候选列表的大小。在进行查询时,HNSW算法会根据查询点的相似度动态地调整候选列表的大小,以加快搜索速度并且保证搜索结果的质量。- 较大的
efSearch值会导致更大的动态候选列表,在搜索时可能会增加计算量,但通常会提高搜索结果的召回率。相反,较小的efSearch值可能会加快搜索速度,但可能牺牲搜索结果的质量。总结来说,
efConstruction和efSearch都是在HNSW索引中用来控制动态候选列表大小的参数,分别影响索引的构建过程和查询过程中的性能和效果。
如果查询大多数情况下是低频率的,那么增加 efConstruction 是一个很好的选择。它可以在几乎不影响搜索时间的情况下提高召回率,特别是在使用较低的 M 值时。
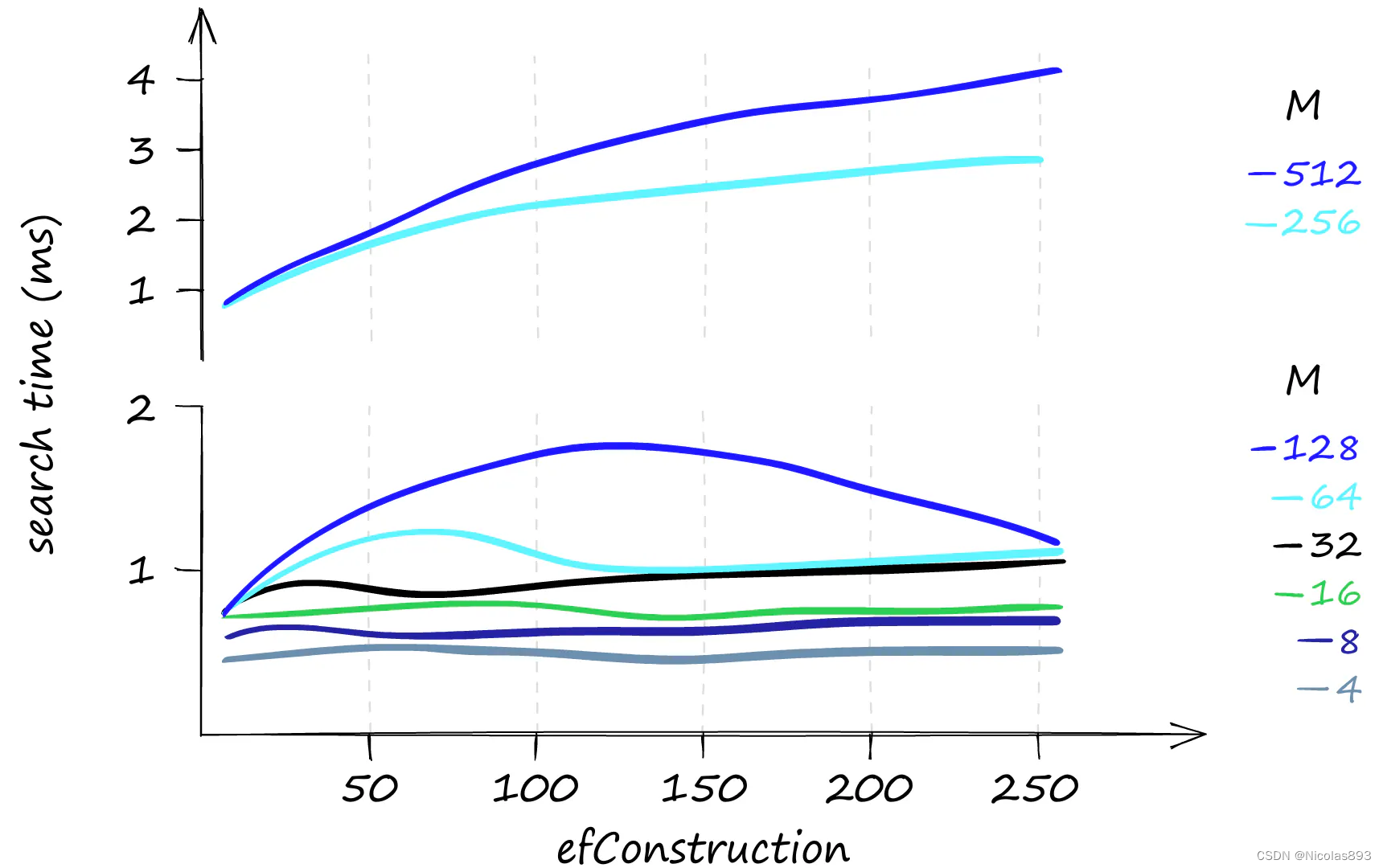
在仅搜索一个查询时的 efConstruction 和搜索时间。使用较低的 M 值时,不同 efConstruction 值的搜索时间几乎保持不变。 这一切看起来都很不错,但是 HNSW 索引的内存使用情况如何呢?在这方面可能会稍显不尽人意。
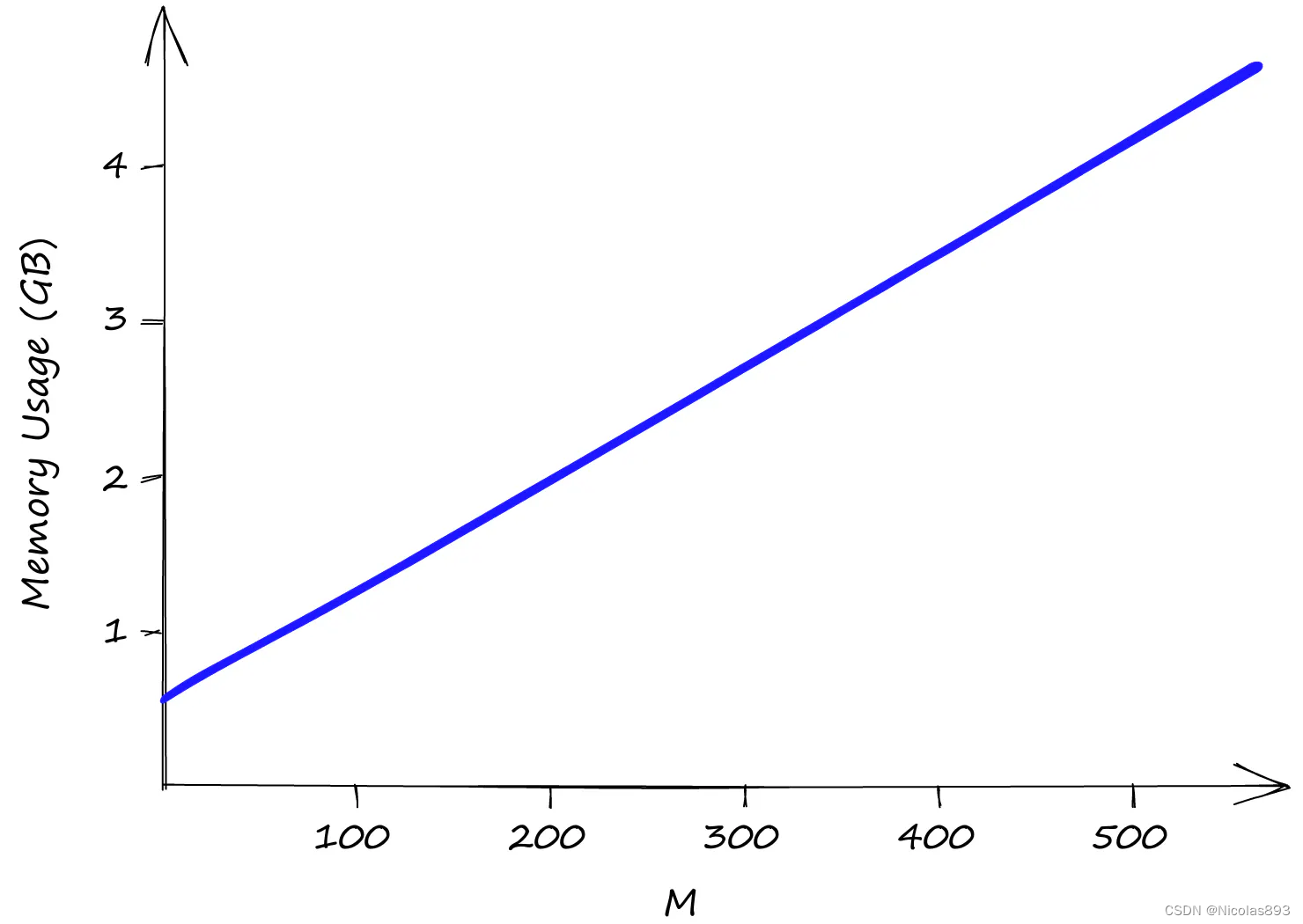
使用 Sift1M 数据集,随着 M 值的增加,内存使用情况也在增加。efSearch 和 efConstruction 对内存使用没有影响。 efConstruction 和 efSearch 均不影响索引的内存使用,因此只需考虑 M 值。即使将 M 值设为较低的 2,索引大小也已超过 0.5GB,在 M 值为 512 时接近 5GB。HNSW 在内存利用方面并不是最佳的索引方式。然而,如果这一点很重要且使用其他索引不是选项,可以通过使用产品量化(PQ)来改善。使用 PQ 将降低召回率并增加搜索时间。
另外,很多场景也可能将HNSW与IVF结合使用,提升整体的检索性能和效率。
IVF(Inverted File)是一种用于高效向量检索的数据结构,通常用于加速近似最近邻搜索(Approximate Nearest Neighbor Search,ANN)。它结合了倒排索引的思想和空间划分的方法,特别适用于处理大规模高维向量数据集。
主要思想是将向量空间划分为多个子空间(或者称为桶),每个桶中存储一组向量,通常使用一种聚类方法(如k-means)对数据集进行划分。在搜索时,首先根据查询向量的位置定位到对应的桶,然后只需在这个桶内进行精确或近似的最近邻搜索,避免了对整个数据集进行线性扫描,从而显著提高了检索效率。
IVF的优点包括:
- 减少搜索空间:通过空间划分,将搜索范围缩小到少数几个桶,极大地减少了需要搜索的向量数目。
- 高效的近似搜索:在每个桶内进行近似搜索,结合了高效的数据结构和查询算法,可以快速返回最相似的向量。
5. HNSW优劣势
HNSW 的优缺点 和大多数技术一样,尽管 HNSW 在向量搜索领域带来了诸多改进,但它也有一些不足,可能不适用于所有用例。
HNSW 的优点
- 高效的搜索性能:HNSW 在高维空间中显著优于传统方法,如 KD 树和暴力搜索,以及 NSW,使其成为大规模数据集的理想选择。
- 可扩展性:该算法随着数据集的增长而保持其效率,表现出良好的可扩展性。
- 层次结构:多层图结构允许快速浏览数据集,通过跳过无关数据部分实现更快的搜索。
- 鲁棒性:HNSW 在各种类型的数据集(包括高维数据集)中表现出色,而这些数据集通常对其他算法构成挑战。
HNSW 的缺点
- 内存使用:虽然 HNSW 的图结构在搜索操作中效率很高,但可能会消耗大量内存,尤其是在每个节点有大量连接的情况下。这对图的大小提出了实际限制,因为操作必须在内存中执行才能快速。
- 实现复杂性:与更简单的结构相比,该算法的层次和概率性质使其实现和优化更加复杂。
- 参数敏感性:HNSW 的性能可能对其参数(如每个节点的连接数)敏感,需要仔细调整以获得最佳结果。
- 动态环境中的潜在开销:虽然 HNSW 在静态数据集中的效率很高,但在动态环境中维护图结构(频繁添加或删除数据点)的开销可能很大。
6. 参考资料
【1】Malkov, Yu A., and Dmitry A. Yashunin. "Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs." IEEE transactions on pattern analysis and machine intelligence 42.4 (2018): 824-836.