0. 资源链接
-
论文: Unleashing Generalization of End-to-End Autonomous Driving with Controllable Long Video Generation
1. 背景动机
-
端到端自动驾驶技术是当前的主流,对训练数据的规模和质量有更高的要求
-
危险、特殊场景的数据采集成本/风险过高,因而难以获得丰富的数据用以训练
-
当前的视频生成模型不能很好地实现时空连续性保持和精确控制,而且生成的是频段一般在 8 帧以下
2. 内容提要
-
提出 Delphi 视频生成方法,可生成 12秒(40帧)时间连续的多视角视频,是之前主流方法的 5 倍,而且具有控制目标和场景两个维度的能力
-
提出失败样例驱动的框架,实验证明基于失败样例生成的长视频段(规模仅为训练集的4%)能够将 UniAD 的精度提升 25%

3. 技术细节
之前的方法通常没有考虑时间和空间上的噪声设计,因而导致生成的长视频质量不如人意。本文针对这个问题提出两个关键模块:噪声重初始化和特征对齐的时间连贯模块。
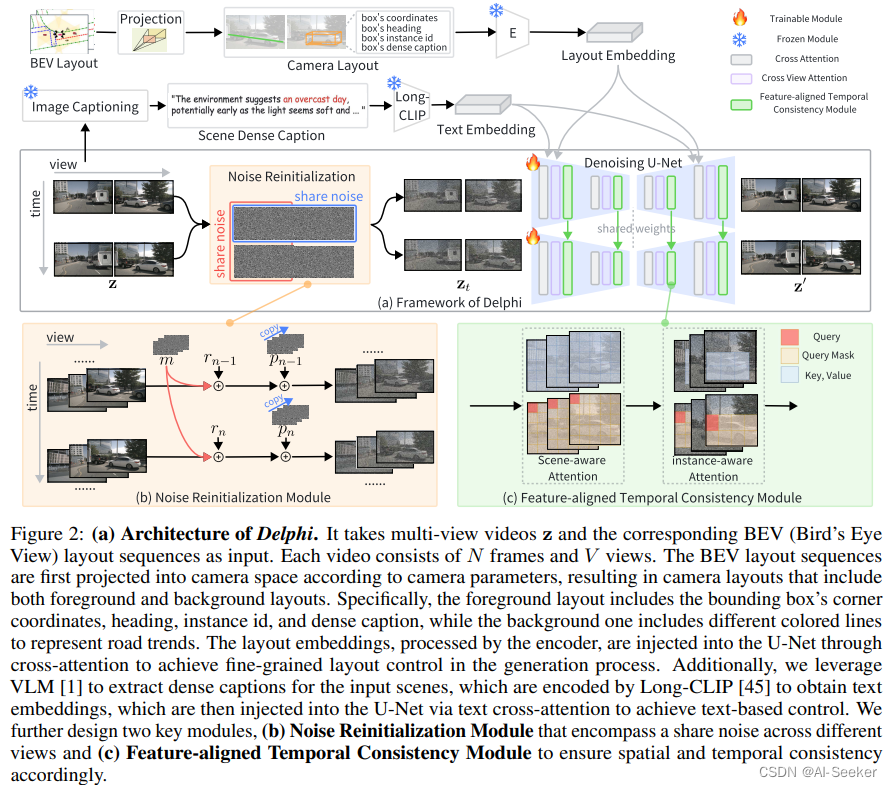
3.1 噪声重初始化模块 (Noise Reinitialization Module)
多视图视频在时间和视图维度上具有相似性。然而现有的两类方法没有同时在时空上很好解决该问题:1)并发单视图视频生成方法,不能直接应用于室外多视图场景;2)多视图生成模型添加的独立噪声,没考虑跨视图一致性。本文通过引入了沿时间维度的共享运动噪声 m 和沿视点维度的共享全景噪声 p 来解决这个问题。
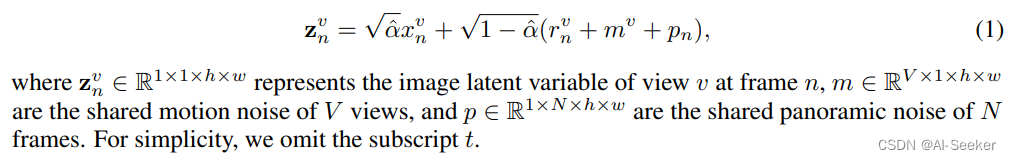
3.2 特征对齐的时间连贯模块 (Feature-aligned Temporal Consistency)
现有的方法在生成当前帧时,只利用简单的交叉注意力机制将先前的帧信息融合到当前视图中,但实际上位于不同网络深度的特征具有不同的感受野。因此,这种粗粒度的特征交互方法无法捕获来自前一帧不同级别的感受野的所有信息,导致视频生成效果受限。为在相邻帧中相同网络深度的对齐特征之间完全建立特征交互,本文设计场景感知注意力和实例感知注意力两种设计,以确保全局一致性和优化局部一致性。
场景感知注意力 (Scene-aware Attention) 对相邻帧之间相同网络深度的特征进行注意力计算

实例感知注意力 (Instance-aware Attention) 使用前景边界框作为注意力掩码来计算中的特征交互相邻帧之间的局部区域

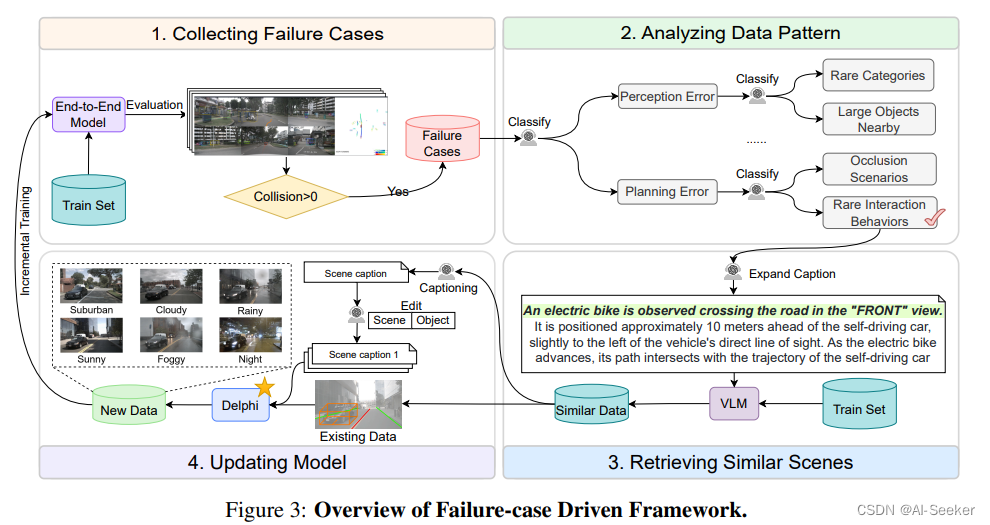
3.3 失败样例驱动的框架
该框架利用四个步骤来减少计算成本:收集失败样例、分析归类、检索相似样例、更新模型。
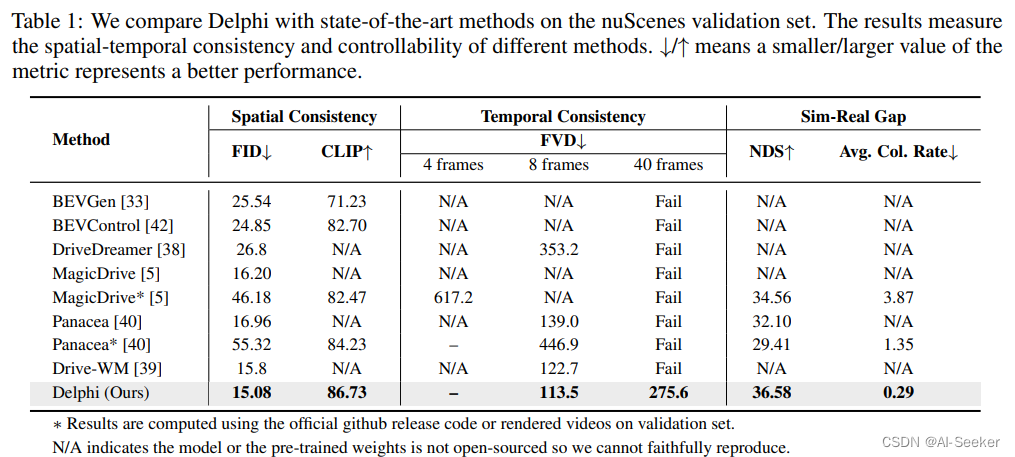
3.4 实验结果




4. 一些思考
-
自动驾驶场景的视频生成相对于一般的视频生成,除了时间连续性之外,增加了一个多视图一致性的要求,本文相较于之前的方法,这个 motivation 还是很合理的
-
尽管本文方法把生成长度推进到 40 帧,但其实相比大众预期的视频生成长度还是有差距
-
论文展示了部分简单的 scene、layout 编辑的结果,但是对于背景、目标等更精细化的编辑和控制有待进一步研究