节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集:

在不断发展的深度学习领域,数据的数量和质量问题一直是一个长期存在的难题。最近大语言模型(LLMs)的出现为合成数据生成提供了一种以数据为中心的解决方案,缓解了现实世界数据的限制。然而,目前对这一领域的研究缺乏统一的框架,大多停留在表面。
因此,本文基于合成数据生成的一般工作流程,整理了相关研究。通过这样做,我们突出了现有研究中的空白,并概述了未来研究的潜在方向。本研究旨在引导学术界和工业界向更深入、更系统地探究LLMs驱动的合成数据生成的能力和应用。
在深度学习领域不断演变的背景下,数据数量和质量的问题一直是一个长期存在的困境。大语言模型(LLMs)的革命性出现引发了深度学习领域的显著范式转变(Zhang et al., 2023a; Guo et al., 2023; Bang et al., 2023)。尽管有这些进展,大量高质量数据仍然是构建稳健自然语言处理(NLP)模型的基础(Gandhi et al., 2024)。具体来说,这里的高质量数据通常指的是包含丰富监督信号(通常以标签形式)并与人类意图紧密对齐的多样化数据。然而,由于高成本、数据稀缺、隐私问题等原因,依赖于人类数据来满足这些需求有时是具有挑战性甚至是不现实的(Kurakin et al., 2023)。此外,多项研究(Hosking et al., 2023; Singh et al., 2023; Gilardi et al., 2023)表明,人类生成的数据由于其固有的偏见和错误,可能并不是模型训练或评估的最佳选择。这些考虑促使我们更深入地探讨一个问题:是否有其他更有效和可扩展的数据收集方法可以克服当前的限制?
鉴于LLMs的最新进展,它们展示了生成与人类输出相当的流畅文本的能力(Hartvigsen et al., 2022; Sahu et al., 2022; Ye et al., 2022a; Tang et al., 2023; Gao et al., 2023a),由LLMs生成的合成数据成为了人类生成数据的一种可行替代品或补充。具体来说,合成数据旨在模仿真实世界数据的特征和模式(Liu et al., 2024)。一方面,LLMs通过广泛的预训练,积累了丰富的知识库,并展现出卓越的语言理解能力(Kim et al., 2022; Ding et al., 2023a),这为生成真实的数据奠定了基础。另一方面,LLMs深厚的指令遵循能力允许在生成过程中实现更好的可控性和适应性,从而能够为特定应用创建定制的数据集,并设计更灵活的流程(Eldan and Li, 2023)。这两个优势使LLMs成为极具前景的合成数据生成器。
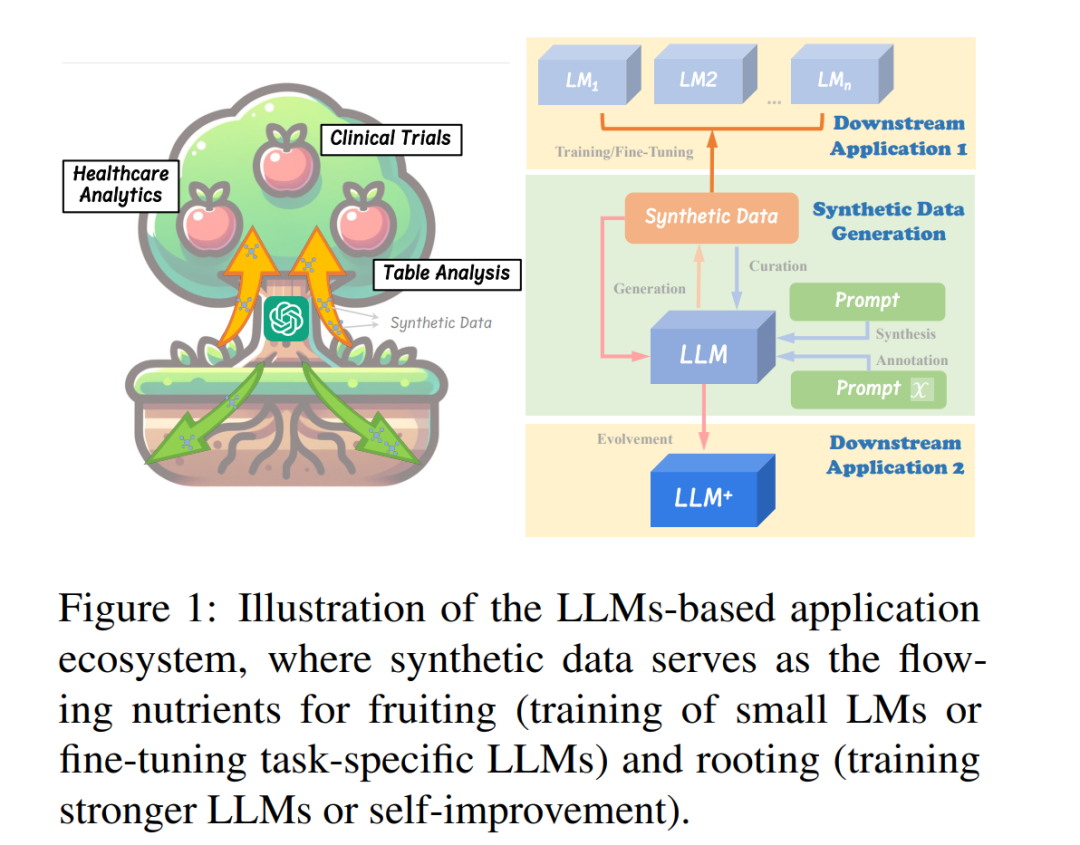
作为LLMs的一项关键应用,合成数据生成对于深度学习的发展具有重要意义。如图1所示,LLMs驱动的合成数据生成(Li et al., 2023c; Wang et al., 2021; Seedat et al., 2023)使整个模型训练和评估过程实现自动化,最小化了人类参与的需求(Huang et al., 2023),从而使深度学习模型的优势可以应用于更广泛的领域。除了提供可扩展的训练和测试数据供应之外,LLMs驱动的合成数据生成还可能为开发下一代LLMs铺平道路。来自TinyStories(Eldan and Li, 2023)和Phi系列(Gunasekar et al., 2023; Li et al., 2023b)的见解强调了数据质量对于有效模型学习的重要性,而LLMs赋予我们主动"设计"模型学习内容的能力,通过数据操作显著提高了模型训练的效率和可控性。截至2024年6月,Hugging Face上已有超过300个被标记为"合成"的数据集,许多主流LLMs利用高质量的合成数据进行训练,包括Alpaca(Taori et al., 2023)、Vicuna(Zheng et al., 2023)、OpenHermes 2.5和Openchat 3.5(Wang et al., 2023a)。
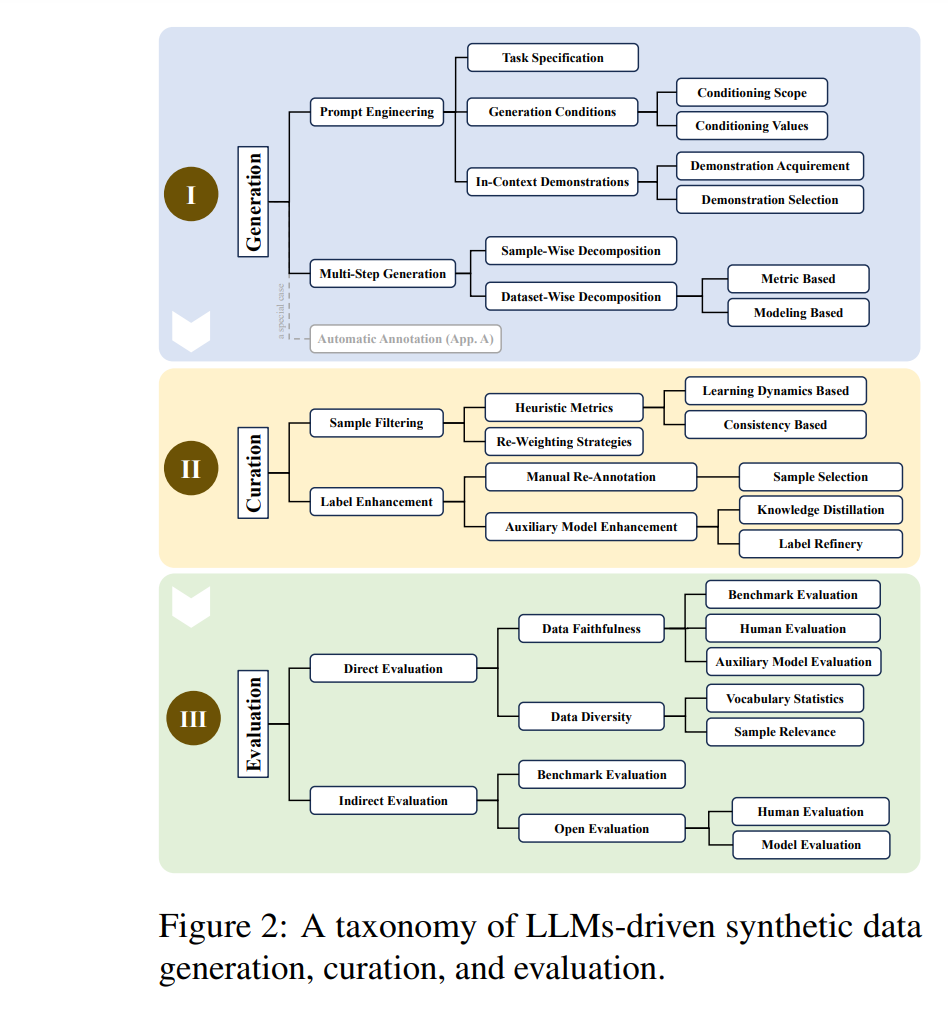
尽管看似简单,但生成同时具有高正确性和足够多样性的合成数据集需要精心设计过程,并涉及许多技巧(Gandhi et al., 2024),使得LLMs驱动的合成数据生成成为一个非平凡的问题。虽然大多数现有工作通常针对各种任务(如预训练(Gunasekar et al., 2023; Li et al., 2023b; Eldan and Li, 2023)、微调(Mukherjee et al., 2023; Mitra et al., 2023; Xu et al., 2023a)、评估(Feng et al., 2023; Wei et al., 2024))和不同领域(如数学(Yu et al., 2023a; Luo et al., 2023a)、代码(Luo et al., 2023b; Wei et al., 2023b)、指令(Honovich et al., 2023a; Wang et al., 2023d))进行数据生成,但它们共享许多共同的理念。为了应对LLMs驱动的合成数据生成这一新兴领域中缺乏统一框架的问题,并开发通用工作流程,本综述调查了最近的研究,并根据生成、策展和评估三个密切相关的主题进行组织,如图2所示。我们的主要目的是提供该领域的全面概述,确定关键关注领域,并突出需要解决的空白。我们希望为学术界和工业界带来见解,并推动LLMs驱动的合成数据生成的进一步发展。