

今天这篇文章将给大家介绍天猫订单数据分析及可视化案例。
import pandas as pdimport numpy as npfrom pyecharts.charts import Pie,Bar,Line,Map,Map3D,Funnelfrom pyecharts import options as optsimport matplotlib.pyplot as pltimport warningsimport seaborn as snsfrom pyecharts.commons.utils import JsCodefrom pyecharts.globals import ThemeType, ChartTypeimport textwrap# 中文设置plt.rcParams['font.sans-serif']=['Microsoft YaHei'] plt.rcParams['axes.unicode_minus']=Falseplt.rc('font',family = 'Microsoft YaHei',size = '15')warnings.filterwarnings("ignore")%matplotlib inline01
导入数据及数据预处理
数据来源:
https://www.heywhale.com/mw/project/62342cefae5cf10017aae52b/dataset
df = pd.read_csv('/home/mw/input/tmall6650/tmall_order_report.csv')df.head()输出结果:
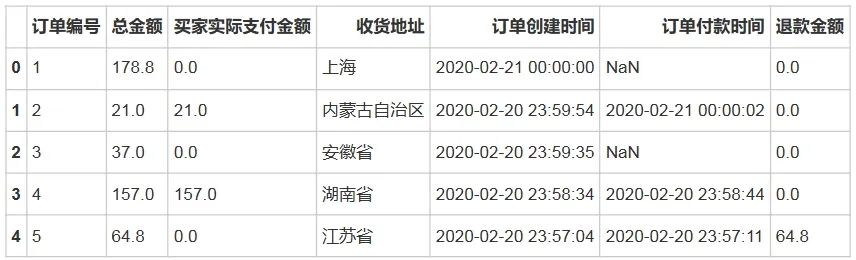
# 去除字段名中的空格new_columns = [col.strip() for col in df.columns]df.columns = new_columnsdf.info()输出结果:
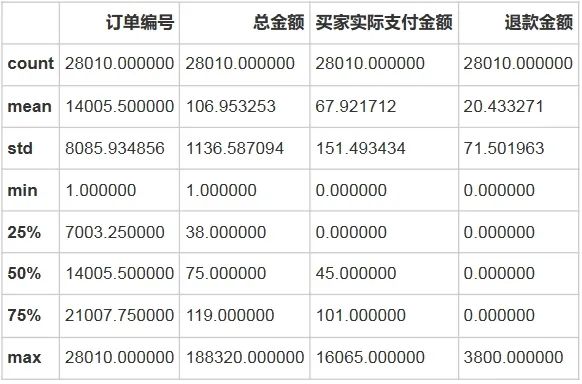
<class 'pandas.core.frame.DataFrame'>RangeIndex: 28010 entries, 0 to 28009Data columns (total 7 columns):订单编号 28010 non-null int64总金额 28010 non-null float64买家实际支付金额 28010 non-null float64收货地址 28010 non-null object订单创建时间 28010 non-null object订单付款时间 24087 non-null object退款金额 28010 non-null float64dtypes: float64(3), int64(1), object(3)memory usage: 1.5+ MB# 数据基本描述print('数据的时间区间为',df['订单创建时间'].min(),'到',df['订单创建时间'].max())print('收货地址总计有:',df['收货地址'].nunique(),'个')df.describe()数据的时间区间为 2020-02-01 00:14:15 到 2020-02-29 23:59:18。
收货地址总计有:31 个。
输出结果:
# 提取日期中的时间为后续分析做准备df['订单创建时间'] = df['订单创建时间'].astype('datetime64')df['订单付款时间'] = df['订单付款时间'].astype('datetime64')df['月'] = df['订单付款时间'].dt.monthdf['日'] = df['订单付款时间'].dt.daydf2 = df[~df['订单付款时间'].isnull()]df2['月'] = df2['月'].apply(lambda x:int(x)).astype('str')df2['日'] = df2['日'].apply(lambda x:int(x)).astype('str')df2['日期'] = df2['月'] + '月' + df2['日'] + '日'df2['周'] = df2['订单付款时间'].dt.weekday + 1df2['周'] = '星期' + df2['周'].astype('str')df2['月'] = df2['月'].astype('int')df2['日'] = df2['日'].astype('int')df2 = df2.sort_values(by = '订单付款时间')df2['小时'] = df2['订单付款时间'].dt.hourdf2.head()输出结果:
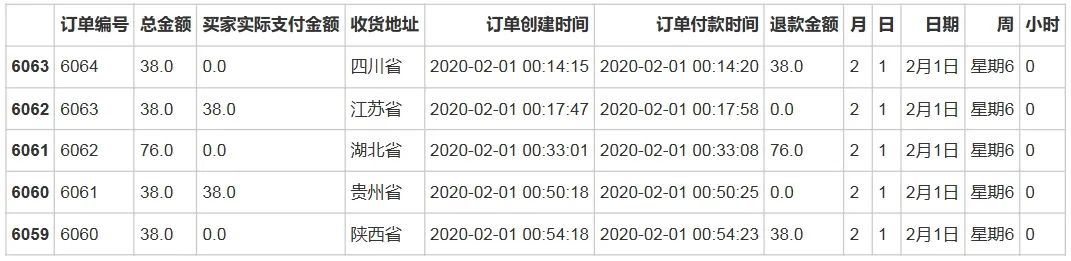
# 查看收货地址信息df2.收货地址.unique()输出结果:
array(['四川省', '江苏省', '湖北省', '贵州省', '陕西省', '上海', '重庆', '浙江省', '湖南省', '河北省', '北京', '广东省', '新疆维吾尔自治区', '河南省', '吉林省', '黑龙江省', '云南省', '安徽省', '天津', '山西省', '辽宁省', '江西省', '内蒙古自治区', '福建省', '广西壮族自治区', '海南省', '山东省', '青海省', '甘肃省', '宁夏回族自治区', '西藏自治区'], dtype=object)收货地址字段中,数据都为**"四川省"、** "西藏自治区" 的形式,且四个直辖市是以**"北京"、"上海"**的数据形式。
因为Pyecharts 在绘图时候,数据中不能包含**"省"、"自治区"** 这样的字眼,因此这里将收货地址数据做处理。
df2['收货地址'] = df2.收货地址.apply(lambda x:x.strip('省|自治区'))df2['收货地址'] = df2.收货地址.replace(['新疆维吾尔','广西壮族','宁夏回族'],['新疆','广西','宁夏'])df2.head()df2.收货地址.unique()输出结果:
array(['四川', '江苏', '湖北', '贵州', '陕西', '上海', '重庆', '浙江', '湖南', '河北', '北京', '广东', '新疆', '河南', '吉林', '黑龙江', '云南', '安徽', '天津', '山西', '辽宁', '江西', '内蒙古', '福建', '广西', '海南', '山东', '青海', '甘肃', '宁夏', '西藏'], dtype=object)# 查看缺失数据df[df['订单付款时间'].isnull()].head()输出结果:
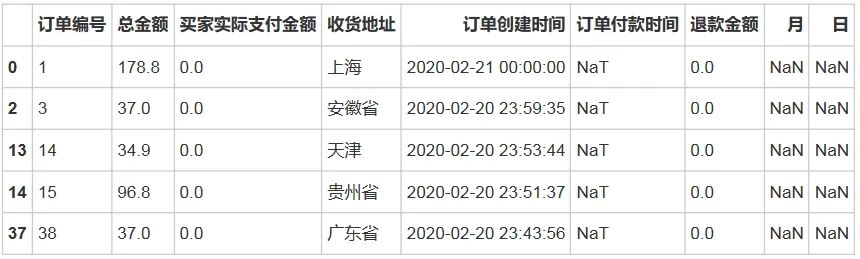
# 查看是否有重复值df[df['退款金额'] > df['总金额']]print('重复值数量为:',df.duplicated().sum())重复值数量为:0输出结果:
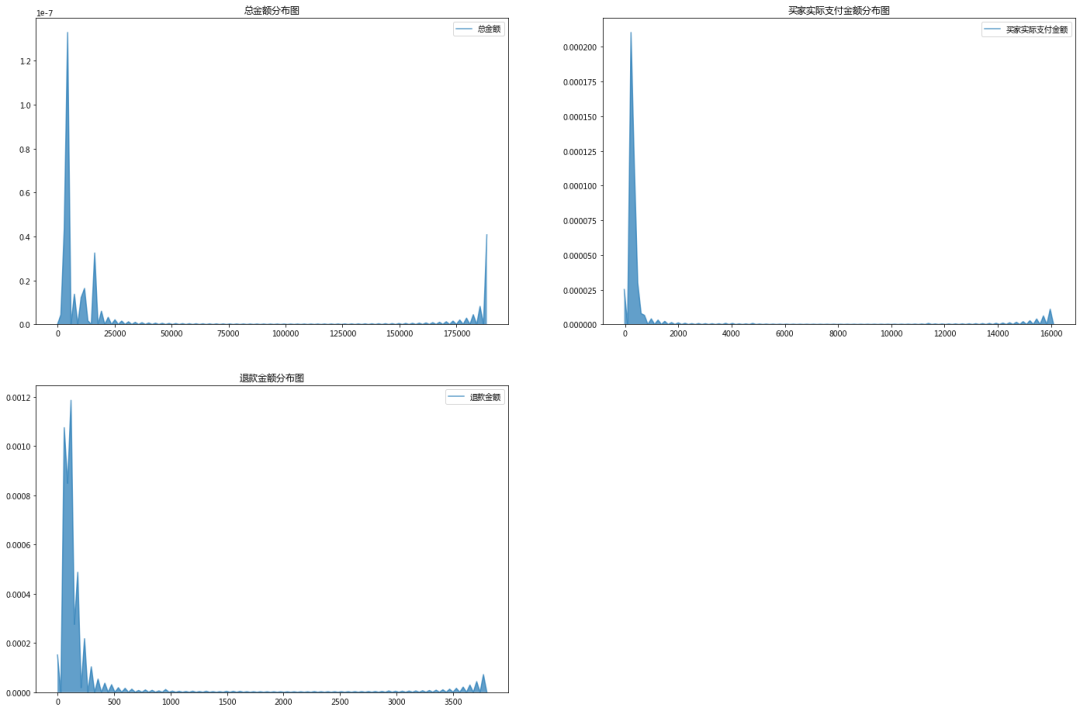
结论:
通过绘制【总金额】、【买家实际支付金额】、【退款金额】的分 布图,可以发现:
这几个字段均有金额特别高 的数据。有特别高的异常值 ,会影响我们对大部分订单金额分布的判断。
因此 接下来我们截取总金额小于500 ,退款金额小于400 的数据,绘制概率密度图,查看大部分数据都分布在哪个数值附近。
df.describe()df[df.总金额 > 5000]plot_df = df[(df.总金额 < 500)&(df.退款金额 < 400)][['总金额','买家实际支付金额','退款金额']]kde_plot_array(plot_df)输出结果:
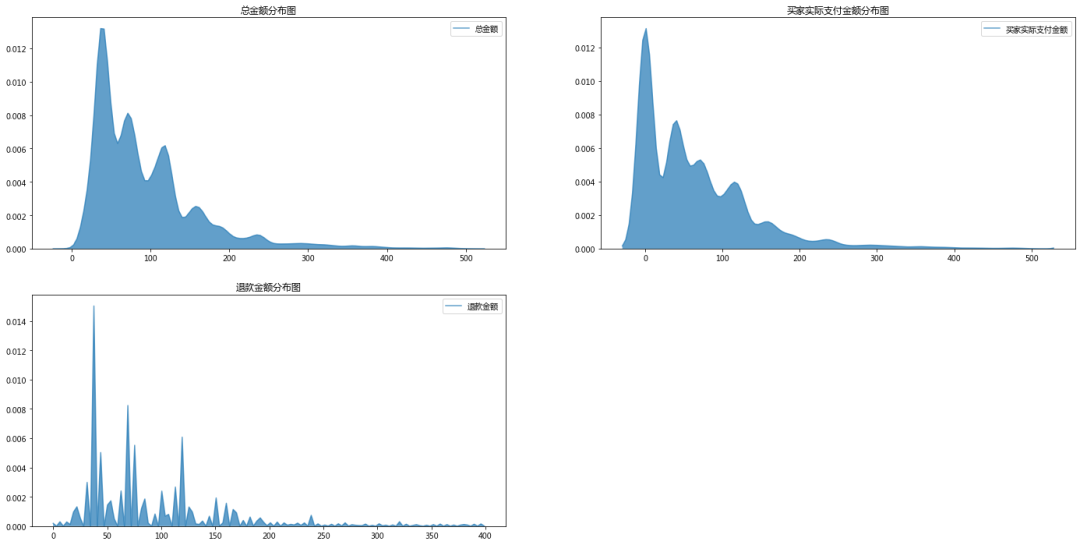
结论:
绘制截取后的金额分布后我们可以发现如下信息:
1、总金额分布在50元 和100元 附近。单笔订单总金额为0-100元的居多。
2、买家实际支付金额和总金额分布基本一致,因为有退款 行为的发生,会导致买家实际支付金额 要比总金额分布更靠左一点。
3、退款金额分布在25-125元附近,因为单笔订单的购买金额通常并不会很高,因此退款金额的分布也不会很靠右。
接下来我们看一下总金额特别高的几笔订单。
df[df.总金额 > 3000]输出结果:
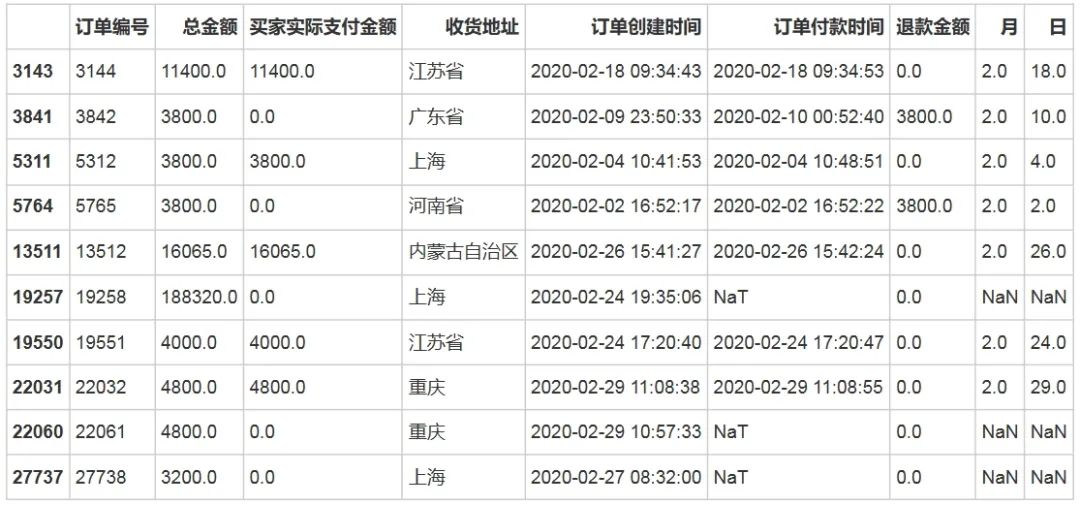
结论:
查看总金额很大的几笔订单可以发现,最大 的一笔订单为订单编号19258的订单,总金额为188320 元,但是这笔订单没有完成交易 ,实际支付金额为0 ,因此判断可能是误操作导致。
另外还有一万块以上的订单,也并没有发生未支付取消订单 的情况。因此说明也会有这种订单金额很高的订单成交。因此对于这样的数据,并不进行异常值 的处理,在后续分析中,将使用买家实际支付金额作为主要分析目标。
1、缺失值:在进行数据预处理 时,发现数据仅【订单付款时间】字段有3923 的缺失值,经过查看,发现订单付款时间缺失的数据中,【买家实际支付金额】都为0 ,且【退款金额】都是0。
说明这样的订单都是没有付款的,取消交易的订单类型。这样的订单也属于正常现象,因此并不做处理。
2、重复值:查看发现数据并无重复值。
3、异常值:数据中只有一条总金额很大的异常数据,怀疑是误操作导致。但是后续分析也不会用到总金额,因此这样的异常数据同样也是不做处理。
02
数据分析可视化
在处理完数据后,接下来要确定分析目标。
因为常有退款现象发生、以及交易未完成等现象,因此我们只用实际支付金额 作为分析目标,截取没有实际支付金额为0的数据。
而分析这份数据,我决定从成交金额、成交次数、转换率 这几部分作为分析目标来分析,并且从时间维度 和空间维度作为分析维度,分别来看各指标,看一看能否发现一些有价值的信息。
成交金额
a. 成交金额在时间维度上的变化
b. 成交金额在地区维度上的分布
退款金额
a. 退款金额在时间维度上的变化
b. 退款金额在地区维度上的分布
转换率
a. 整体转换率
b. 全国各省市创建-支付转换率
c. 全国各省市支付-成交转换率
成交金额
a. 成交金额在时间维度上的变化
change = df2[['买家实际支付金额','日']].groupby('日').sum().round(2).reset_index().sort_values(by = '日')把要绘制的折线图调整好样式后,封装成这样的函数,然后后边在绘制类似的折线图的时候,就可以直接调用这个函数了,很方便。
由于绘制折线图部分的代码属实太长了,为不影响对整体报告的阅读,只好隐藏掉了。需要代码的,滴滴我~
echarts_line(change['日'],change['买家实际支付金额'],title = '成交金额变化图',subtitle = "成交金额在时间维度上的变化", label = '成交金额')输出结果:
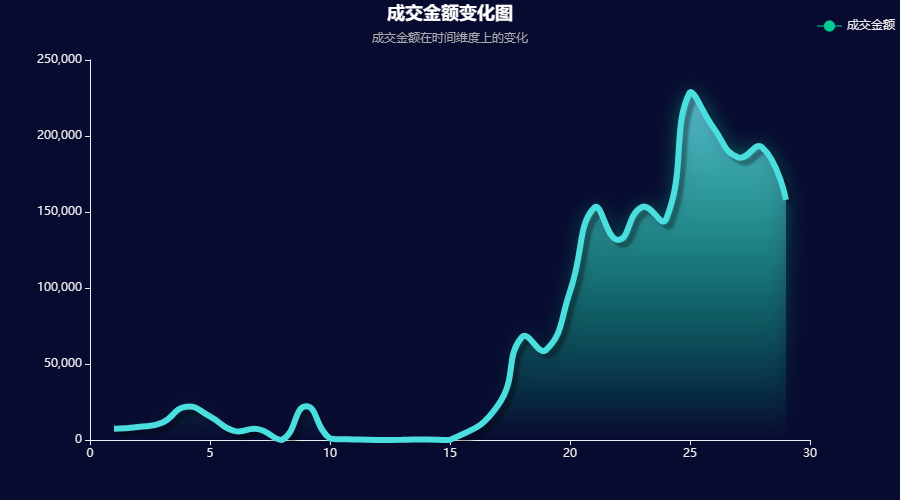
结论:
绘制成交金额在时间维度上的变化图,可以看到在2020年2月份的天猫成交金额在15日以前都是呈现一个较低的状态。
而从15日开始,出现一个稳步上升 的趋势,并且在22 日和25 日的时候分别达到了高峰。
2022年的1月25日是春节,因此怀疑导致成交金额如此低下的原因,可能是受到春节影响,大部分消费者和商家都在停业过春节。
而随着春节的结束,大部分人都开始逐渐进行了复工,因此从15日开始,成交金额开始逐步恢复正常,并且稳步提升。
week_change = df2[['周','买家实际支付金额']].groupby('周').sum().round(2).reset_index()echarts_bar(week_change['周'].tolist(),week_change['买家实际支付金额'].tolist(),title = '订单成交金额平均每周对比', subtitle = '每周对比图',label = '成交金额')输出结果:
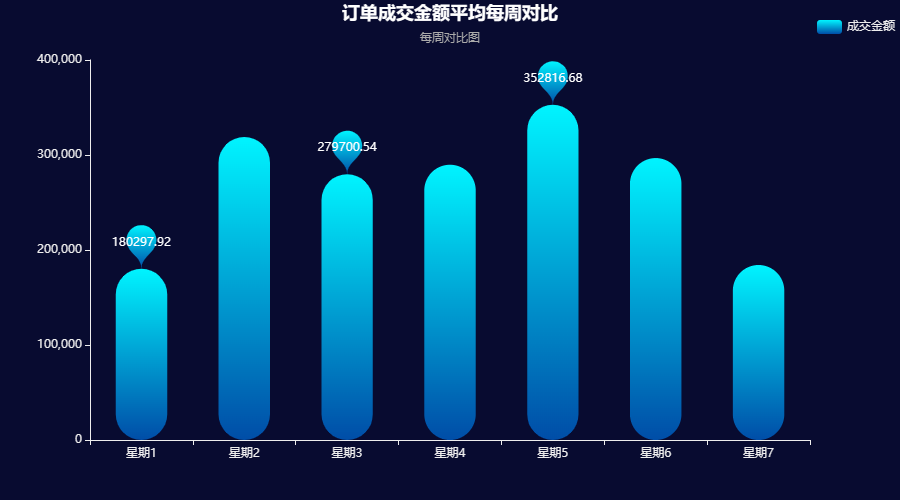
结论:
绘制成交金额每周的对比图可以发现,周六日 和周一 的成交金额通常来说是较少 的,每周的周二 和周五 的成交金额反而是较多的。
猜测是因为周末大家通常来说都比较想好好安排一下自己的周末的生活,出去玩或者直接去实体店进行逛街购物,而平时工作日的时候,由于要忙工作的原因,因此只能进行线上网购,因此工作日 期间网购的成交金额 会相对来说较高一点。
hour_change = df2[['小时','买家实际支付金额']].groupby('小时').sum().round(2).reset_index()因为前边已经封装好了绘制折线图的函数,接下来就只要吧数据传进函数,一行代码直接绘图。
echarts_line(hour_change['小时'],hour_change['买家实际支付金额'],title = '每天各时段成交金额变化图' ,subtitle = '一天24小时哪个时间段成交金额多',label = '成交金额')输出结果:

结论:
绘制每天各时段的成交金额变化图,可以发现,每天的早上10 点,下午的15 点,晚上的21-23 点的时间段,是成交金额的高峰期 。尤其是晚上 这个时间段,成交金额相对来说是最高的。
这可能因为人在晚上 是比较容易冲动消费的,也可能因为大家再进行了一整天的工作后,只有在晚上吃完饭,忙完所有工作以后,才有时间来天猫逛一逛,进行一些网购等。
b. 成交金额在地区维度上的分布
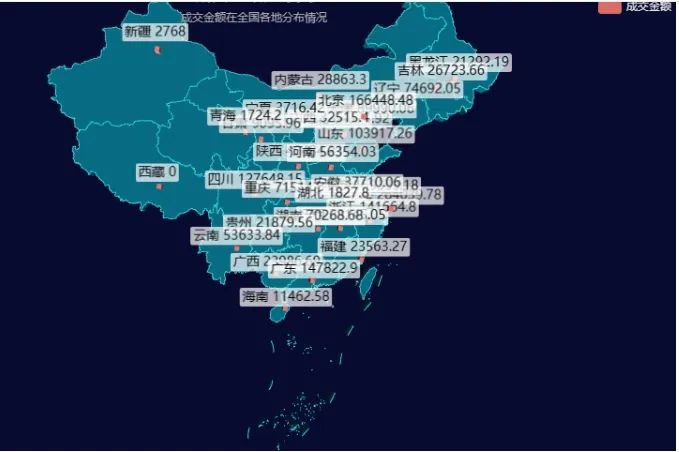
change_map = df2[['收货地址','买家实际支付金额']].groupby('收货地址').sum().round(2).reset_index().sort_values(by = '买家实际支付金额', ascending = False)echarts_map(change_map['收货地址'],change_map['买家实际支付金额'],title = '成交金额分布图' ,subtitle = '成交金额在全国各地分布情况',label = '成交金额')结论:
绘制成交金额在全国各地的分布,我们可以发现江浙沪 一带、以及北京、广东、四川等地区的成交金额是比较高的。
而新疆、西藏、 内蒙古 等其他地区的成交金额普遍较低 。北上广深等一线城市 本身就是人口较多、经济较发达的城市,所以成交金额自然也会较高。
change_map = df2[['收货地址','买家实际支付金额']].groupby('收货地址').sum().round(2).reset_index().sort_values(by = '买家实际支付金额', ascending = False)map3d_with_bar3d(change_map['收货地址'],change_map['买家实际支付金额'],title = '成交金额分布图' ,subtitle = '成交金额在全国各地分布情况',label = '成交金额')输出结果:
退款金额
a. 退款金额在时间维度上的变化
back_money = df2[['日','退款金额']].groupby('日').sum().round(2).reset_index()echarts_bar(back_money['日'].tolist(),back_money['退款金额'].tolist(),title = '退款金额变化图' ,subtitle = '退款金额日变化图',label = '退款金额')输出结果:
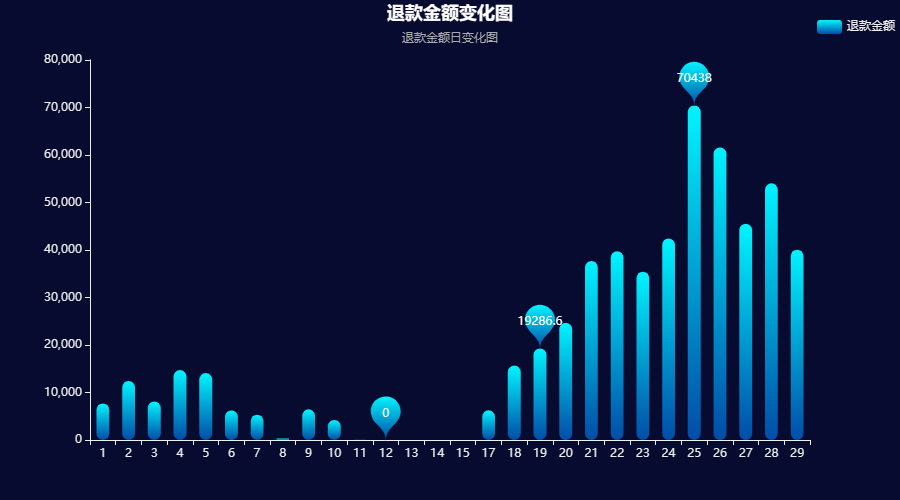
结论:
绘制退款金额在时间维度上的变化图可以发现,和成交金额几乎一致 ,都是在25 号达到了一个高峰 的状态,成交 的金额多的时候,退款的金额也相应的多。
hour_back_money = df2[['小时','退款金额']].groupby('小时').sum().round(2).reset_index()echarts_line(hour_back_money['小时'].tolist(),hour_back_money['退款金额'].tolist(),title = '退款金额变化图' ,subtitle = '退款金额每日小时变化图',label = '退款金额')输出结果:
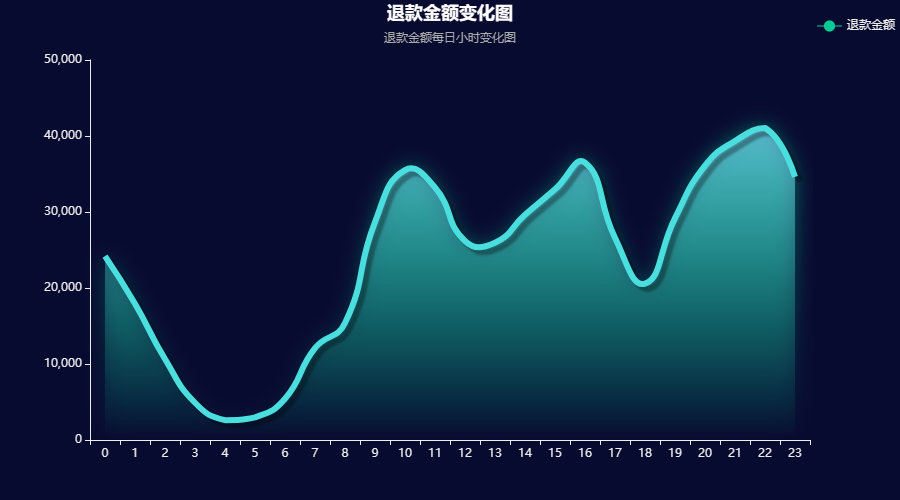
结论:
绘制退款金额在每天各小时的变化图,发现和成交金额的变化也差不多,都是在10点、15点、22点的时间段会比较多。
b. 退款金额在地区维度上的分布
local_back_money = df2[['收货地址','退款金额']].groupby('收货地址').sum().round(2).reset_index()echarts_map(local_back_money['收货地址'],local_back_money['退款金额'],title = '退款金额分布图' ,subtitle = '退款金额在全国各地分布情况',label = '退款金额')输出结果:
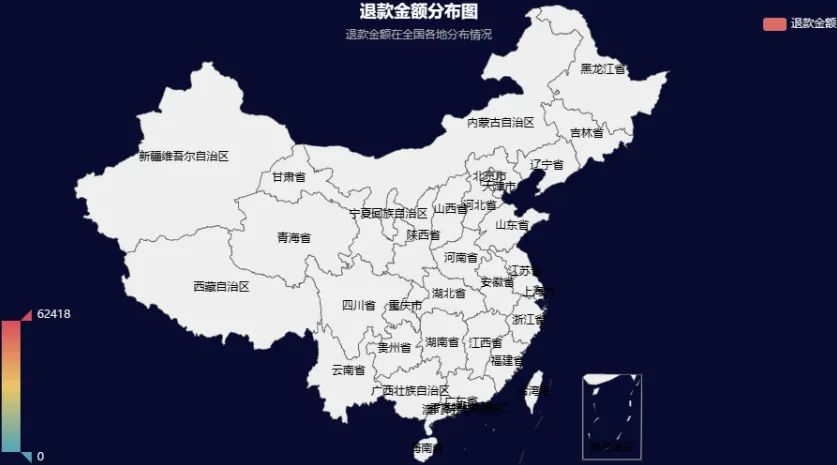
map3d_with_bar3d(local_back_money['收货地址'],local_back_money['退款金额'],title = '退款金额分布图' ,subtitle = '退款金额在全国各地分布情况',label = '退款金额')输出结果:

转换率
a. 整体转换率
# 计算各阶段订单量create_order = df.订单编号.count()print('下单数量为:',create_order)buy_order = df[~df.订单付款时间.isnull()].订单编号.count()print('支付订单数量为:',buy_order)finish_order = df[df.买家实际支付金额 > 0].订单编号.count()print('成交订单数量为:',finish_order)whole_finish_order = df[df.总金额 == df.买家实际支付金额].订单编号.count()print('全额成交订单量为:',whole_finish_order)输出结果:
下单数量为:28010支付订单数量为:24087成交订单数量为:18955全额成交订单量为:18441# 计算各阶段转化率transform = [['创建订单',round(create_order / df.shape[0],2)], ['支付订单',round(buy_order / df.shape[0],2)], ['成交订单',round(finish_order / df.shape[0],2)], ['全额成交订单',round(whole_finish_order / df.shape[0],2)]]transform输出结果:
[['创建订单', 1.0], ['支付订单', 0.86], ['成交订单', 0.68], ['全额成交订单', 0.66]]
结论:
1、通过销售额漏斗图可以发现:成交订单 到全额成交订单 的转化率还是蛮高的,只下降了2 个百分点,这说明通常来说只要订单成交了,那么基本上就是进行的全额成交 ,只会有小部分消费者有部分退款行为。
2、创建订单到支付订单的转化率有86% ,这说明有14% 的用户在创建了订单以后,没有选择支付,而是取消了该笔订单的支付。应当重点追溯一下导致这个情况的原因是什么。
3、支付订单 到成交订单 的转化率同样比较低,转换率下降了18% 。这就说明,有18% 的用户在支付了订单金额以后,选择了全额退款。这个问题也不容小觑。应当查明导致该问题的原因。
在整个销售漏斗中,这部分的转化率是最低的,因此应当结合其他数据,着重查找该环节的原因,从而提升销售额。
b. 全国各省市创建-支付转换率
通过前边一部分的分析,我们知道,在创建 -> 支付和支付 -> 成交的转换率是较低的。
因此我们猜测,是否受到地区 影响,导致物流等问题,发生了取消支付或者是退货等情况。因此接下来我们分别查看全国各省市创建-支付 转换率和全国各省市支付-成交转换率,看看到底是哪个省市的转换率较低。
# 全国各省市创建-支付转换率计算df['辅助计数'] = 1pay_order = df[~df.订单付款时间.isnull()]province_pay_order = pay_order[['收货地址','辅助计数']].groupby('收货地址').sum().reset_index()create_order = df[['收货地址','辅助计数']].groupby('收货地址').sum().reset_index()province_create_pay_transform = pd.merge(create_order,province_pay_order,how = 'left',on = '收货地址')province_create_pay_transform.rename(columns = {'辅助计数_x':'创建订单数','辅助计数_y':'支付订单数'},inplace = True)province_create_pay_transform['创建-支付转换率'] = province_create_pay_transform['支付订单数'] / province_create_pay_transform['创建订单数']province_create_pay_transform['创建-支付转换率'] = province_create_pay_transform['创建-支付转换率'].round(2)province_create_pay_transform.head()输出结果:
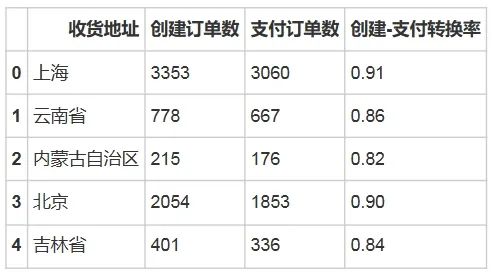
echarts_bar(province_create_pay_transform['收货地址'].tolist(),province_create_pay_transform['创建-支付转换率'].tolist(), title = '创建-支付转换率对比图' ,subtitle = '全国各省创建-支付转换率对比图',label = '创建-支付转换率')输出结果:
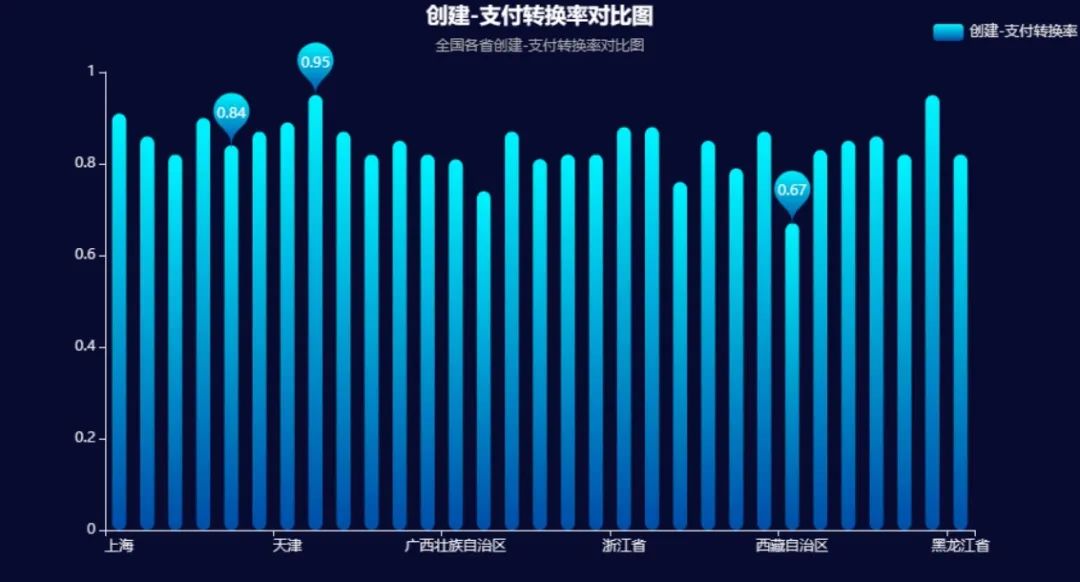
结论:
1、通过绘制全国各省市创建-支付 转换率的对比图我们可以发现,大部分省份的转换率都是处于一个相对稳定 的水平,都处在均值0.84附近。
而宁夏、上海、青海、北京 等地区的转换率更是高达**90%**以上的,说明大部分地区的用户在支付界面取消订单的现象并不严重。
2、有三个特别的地区,创建-支付 订单的转化率较低,分别是西藏、新疆和湖北。
西藏和新疆 因为处于偏远地区,交通并不是很便利,因此物流 是比较慢的,很多商家都是不往这两个地区发货的,因此可能受到物流影响,转换率会较低。
而湖北地区的转化率较低,很可能是因为受到疫情影响。2020年的2月份正是湖北疫情严重的时期,因此很多消费者会选择取消订单,这也可能是转换率较低的原因。
c. 全国各省市支付-成交转换率
# 全国各省市支付-成交转换率计算df2['辅助计数'] = 1finish_df = df2[df2.买家实际支付金额 > 0]province_finish_df = finish_df[['收货地址','辅助计数']].groupby('收货地址').sum().reset_index()province_buy_df = df2[['收货地址','辅助计数']].groupby('收货地址').sum().reset_index()province_transform = pd.merge(province_buy_df,province_finish_df,how = 'outer',on = '收货地址')province_transform.rename(columns = {'辅助计数_x':'支付订单数','辅助计数_y':'成交订单数'},inplace = True)province_transform['支付-成交转换率'] = province_transform['成交订单数'] / province_transform['支付订单数']province_transform['支付-成交转换率'] = province_transform['支付-成交转换率'].round(2)province_transform.head()输出结果:

echarts_bar(province_transform['收货地址'].tolist(),province_transform['支付-成交转换率'].tolist(), title = '支付-成交转换率对比图' ,subtitle = '全国各省支付-成交转换率对比图',label = '支付-成交转换率')输出结果:

province_transform[province_transform.收货地址 == '西藏']输出结果:

province_create_pay_transform[province_create_pay_transform.收货地址 == '湖北省']输出结果:
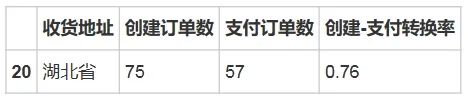
province_transform[province_transform.收货地址 == '湖北']输出结果:
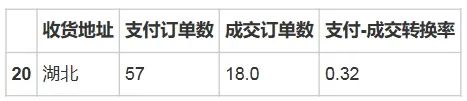
结论:
1、绘制全国各省市支付-成交 转换率对比图可以发现,该部分转换率较低的几个省份依旧是新疆、西藏和湖北。
西藏 的转换率为0,查询原因发现,西藏在2月份有过支付记录的订单总共就2个,因此西藏的转化率达到了0也不算异常。
2、而湖北的转换率达到了0.32 ,查询2月份湖北的订单创建数和支付数,发现湖北2月份创建的订单仅有75 个,支付的57 个,而真正成交的只有18 个订单,从支付到成交的转换率仅有32%。
说明有68% 的用户直接进行了全额退款。这可能是因为2020年2月份湖北疫情较为严重,湖北的物流基本上呈现中断的状态,大部分商品很可能不在发往湖北,因此出现了大量的全额退款等行为。
03
总结与建议
1、成交金额 方面,新年过后复工的一周左右,销售额会出现快速的增长,在月底前达到一个小高峰。因此可以在新年过后一周左右的时间,提前准备好库存,做好销售计划等。
2、每周的周二 和周五 是销售额较高的时间段。如果有促销计划什么的,可以重点在周二和周五进行。
3、每日的10点、15点、21-22点 的时间段是销售额较高的时间段,如果有促销活动、优惠券发放、新品推荐等推送内容,可以选择在这些时间段进行发放,效果会更佳。
4、地区方面,江浙沪一带、以及北京、广东、四川 等地区的成交金额是比较高的,而新疆、西藏、内蒙古等其他地区的成交金额普遍较低。
可以根据以后的发展计划、策略,综合考虑物流、成本等因素进行产品销售的调整。
5、退款金额和销售金额的趋势基本吻合。销售额高相应的退款行为发生次数也多。
6、转换率方面,创建订单->支付订单->成交订单的转化率均较低,应当从各方面寻找原因,加强物流管理、提升产品质量、提高服务态度等等,从而提高各环节转换率,增加销量。