本文旨在对任意模态输入-任意模态输出 (X2X) 的LLM的编解码方式进行简单梳理,同时总结一些代表性工作。
注:图像代表Image,视频代表Video(不含声音),音频代表 Audio/Music,语音代表Speech
各种模态编解码方式梳理
文本
- 编码:和LLM一样,使用tokenizer与位置嵌入转换为输入Embedding,选择性利用Transformer Encoder进行处理
- 解码:和LLM一致,使用Transformer Decoder解码获取输出文本
图像
- 编码:使用Vision Transformer (ViT) 将图像分割为patch序列,利用Transformer处理得到编码。之后选择MLP/QFormer/VQ-VAE中一个合适的connector得到表征
- 解码:使用Diffusion模型利用LLM生成的语义token得到图像
视频
- 编码:从视频中抽出若干帧图像代表视频,利用图像编码方式得到每个帧的表征,并按照相对顺序拼接在一起放进输入序列中
- 解码:使用Diffusion模型利用LLM生成的语义token得到视频
音频/语音
- 编码:使用声学采样技术将音频/语音转换为离散的序列,利用Encoder编码,再利用RVQ量化技术得到最终的输入表征。
- 常用编码器 :C-Former、HuBERT、BEATs 或 Whisper
- 解码:使用音频/语音Decoder或Diffusion模型解码LLM生成的语义token得到音频/语音
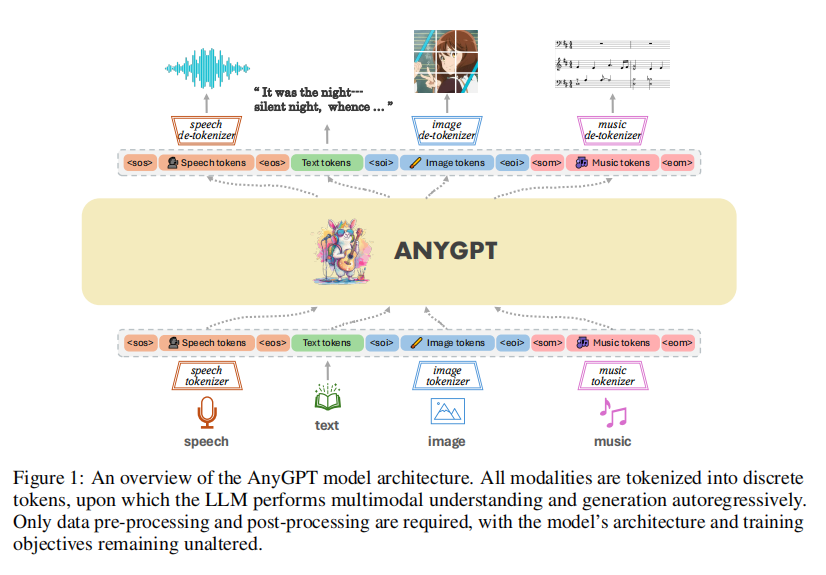
1.AnyGPT:文本,图像,语音,音频
论文标题:AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
来源:Arxiv2024/复旦
开源地址:https://github.com/OpenMOSS/AnyGPT
注:此部分参考了 老刘说NLP:多模态数据的tokenizer
编码:将各种模态的原始数据使用不同编码器编码,输入LLM得到语义token
解码:利用每个模态对应解码器将语义token解码为各种模态的原始数据。
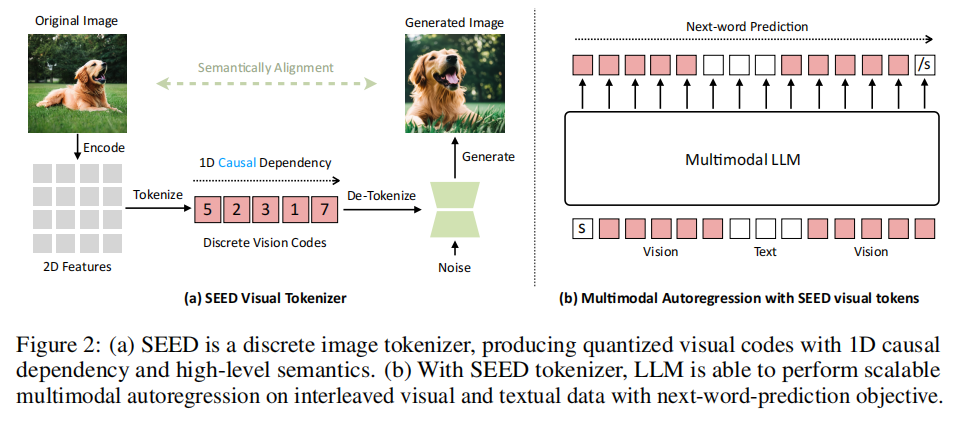
图像
使用 seed-tokenizer (ICLR2024'腾讯)
图像编码:SEED分词器以224×224RGB图像作为输入;经过ViT转成16×16的Patches;再经过CausalQ-Former把Patch的特征转化成32个causal embeddings;再通过一个大小为8192的codebook将特征转化成量化代码序列;再通过MLP解码成生成嵌入。
图像解码:经过UNetdecoder变回原始图像。
ViT编码器和UNet解码器直接源自预训练的BLIP-2和unCLIP Stable Diffusion(unCLIP-SD)
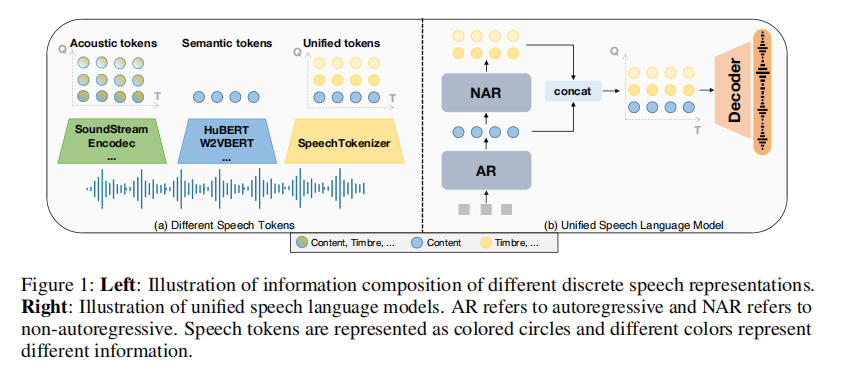
语音
使用 SpeechTokenizer (ICLR2024'复旦)
语音编码:使用8个分层量化器将单通道音频序列压缩为离散矩阵,每个量化器有1,024个条目,并实现50Hz的帧速率。第1个量化器层捕获语义内容,而第2层到第8层编码副语言细节,将10秒的音频转换为500×8的矩阵。
语音解码 :使用专门训练的SoundStorm (Arxiv2023'Google)。将从SpeechTokenizer得到的语义 (semantic) tokens 转换为声学 (acoustic) tokens。 再利用SpeechTokenizer的Decoder将声学token转换为声音音频。
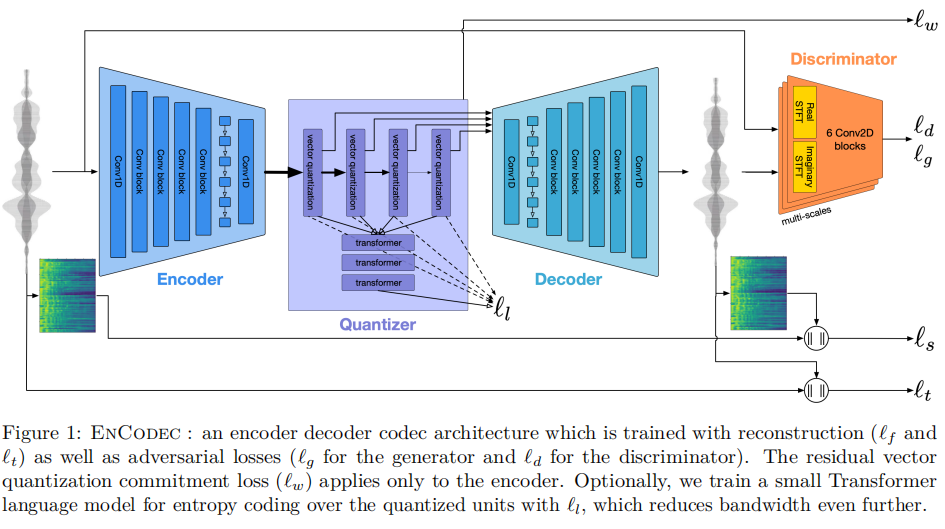
音频
使用 EnCodec (Arxiv2023'Meta)
音频编码:使用Encodec处理32kHz单音音频,实现50Hz的帧速率。生成的嵌入使用具有4个量化器的RVQ进行量化,每个量化器codebook的大小为2048,最终形成8192个组合音乐词表大小。
音频解码:使用Encodec token来过滤掉人类感知之外的高频音频细节,然后使用Encodec的解码器将这些token重建为高保真的音频数据。
2.NextGPT:文本,图像,视频,音频
论文标题:NExT-GPT: Any-to-Any Multimodal LLM
来源:ICML2024'Oral/NUS
开源地址:https://github.com/NExT-GPT/NExT-GPT
编码 :使用ImageBind (CVPR2023'Meta) 对多种模态进行编码,经过一个统一的映射头转换为表征输入LLM。其中音频使用 AST (Interspeech2021'Google) 编码,再将2D编码视为图像用ViT进行处理.
解码 :每种模态的语义表征先经过各自的映射头转换为新的表征,再利用不同模态的Diffusion模型进行解码得到生成的不同模态数据。其中图像使用 Stable Diffusion,视频使用 Zeroscope,音频使用 AudioLDM。
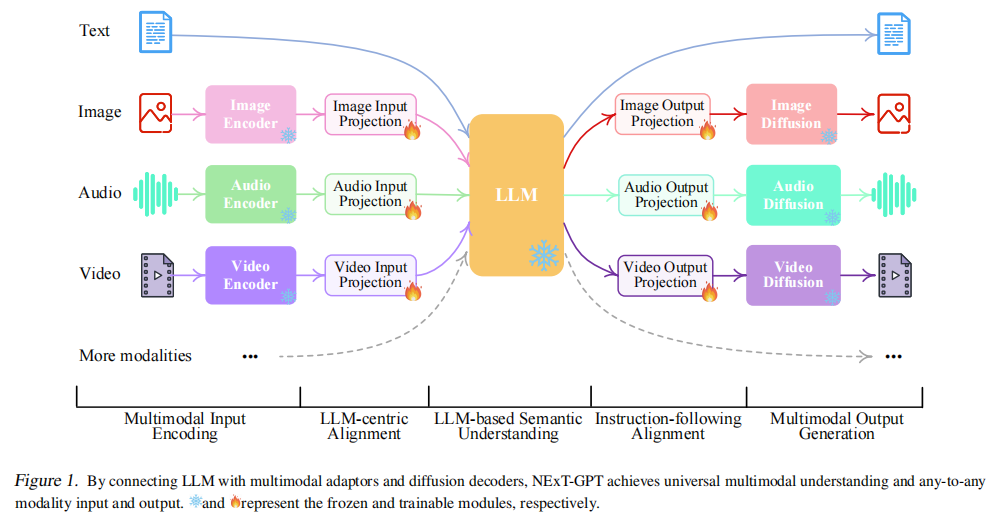

3.X-LLM:文本,图像,视频,语音
来源:Arxiv2023/中科院
开源地址:https://github.com/phellonchen/X-LLM
编码:利用Q-Former和Adapter将多种模态的Encoder得到的表征与LLM对齐。其中音频使用C-Former,即利用CIF模块将语音压缩采样,再经过Transformer得到表征。
解码:最后直接由LLM输出文本
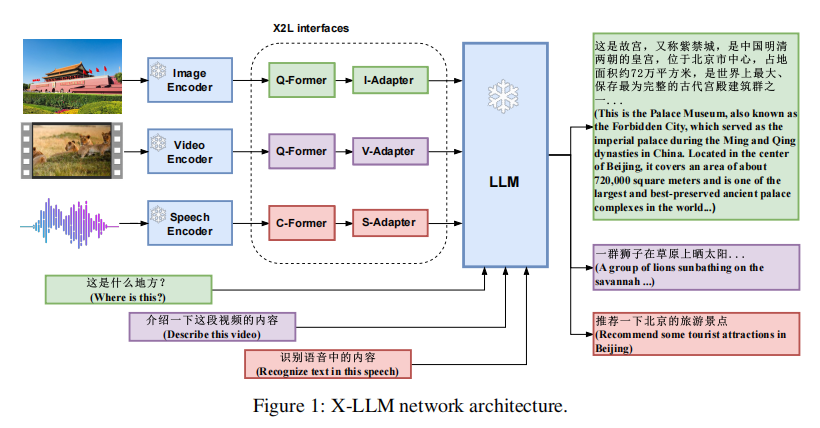
4.Audio-Video LLM:文本,视频,音频
论文标题:Audio-visual training for improved grounding in video-text LLMs
来源:PhroneticAI/Arxiv2024
编码:音频使用Whisper,视频使用sigLIP,分别过投射层转换为表征再拼接在一起
解码:LLM Decoder解码得到文本
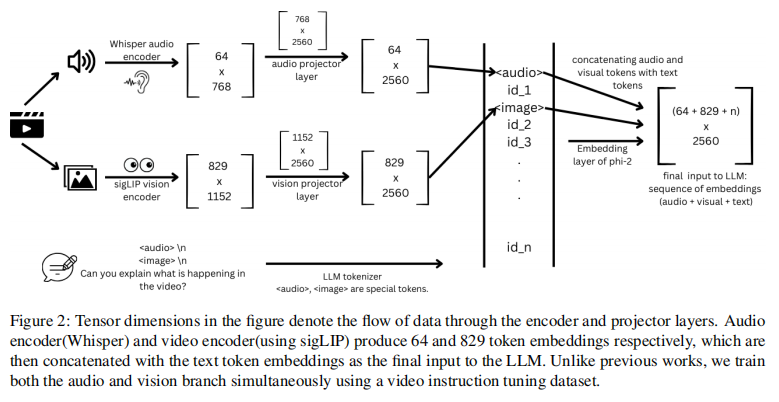
5.Qwen2-Audio: 文本,音频
论文标题:Qwen2-Audio Technical Report
来源:Arxiv2024/阿里
开源地址:https://github.com/QwenLM/Qwen2-Audio
编码:使用Whisper-large-v3进行编码
解码:生成文本
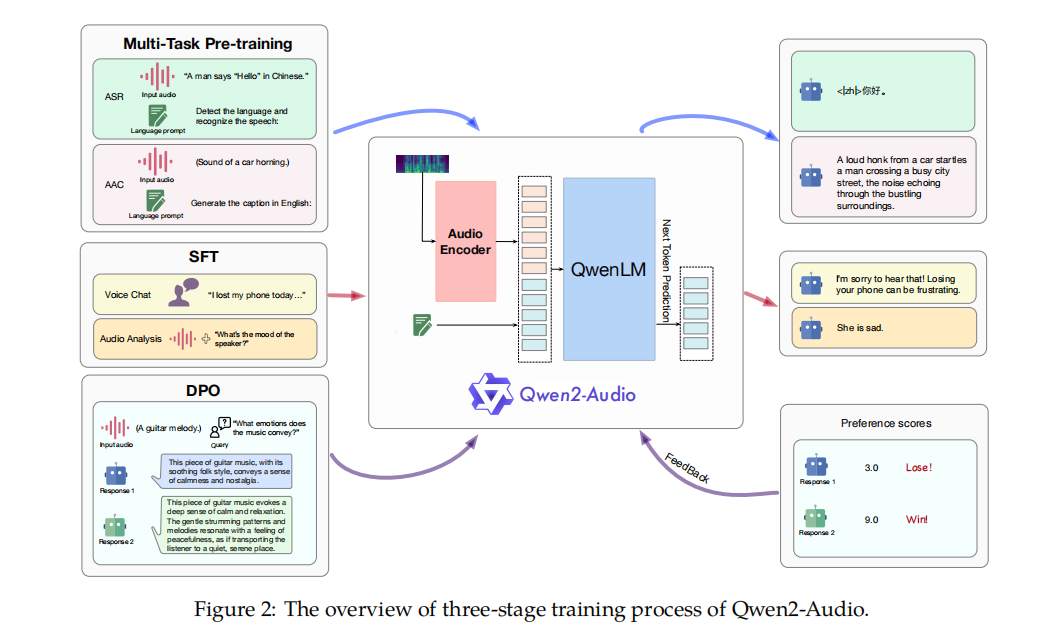
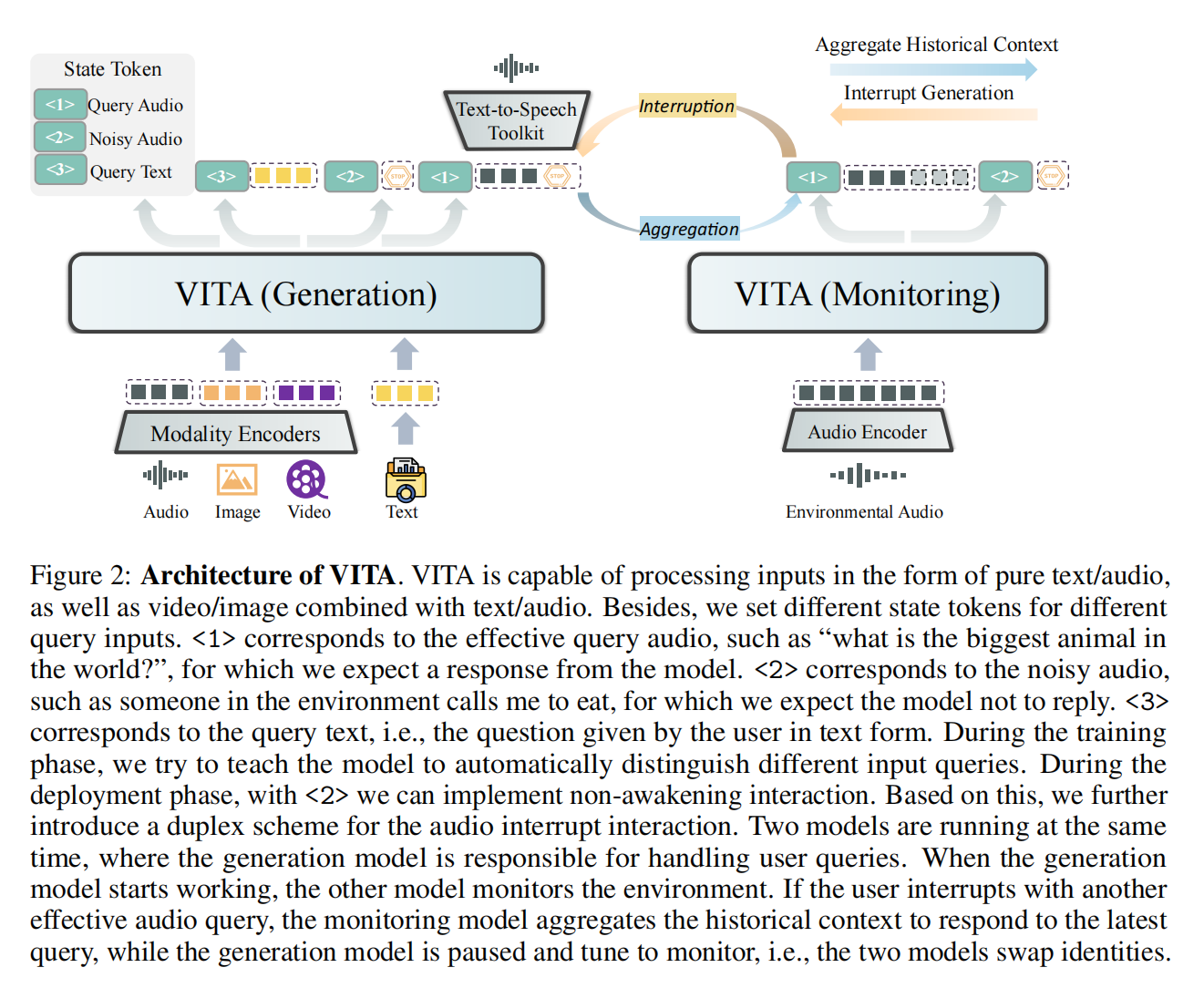
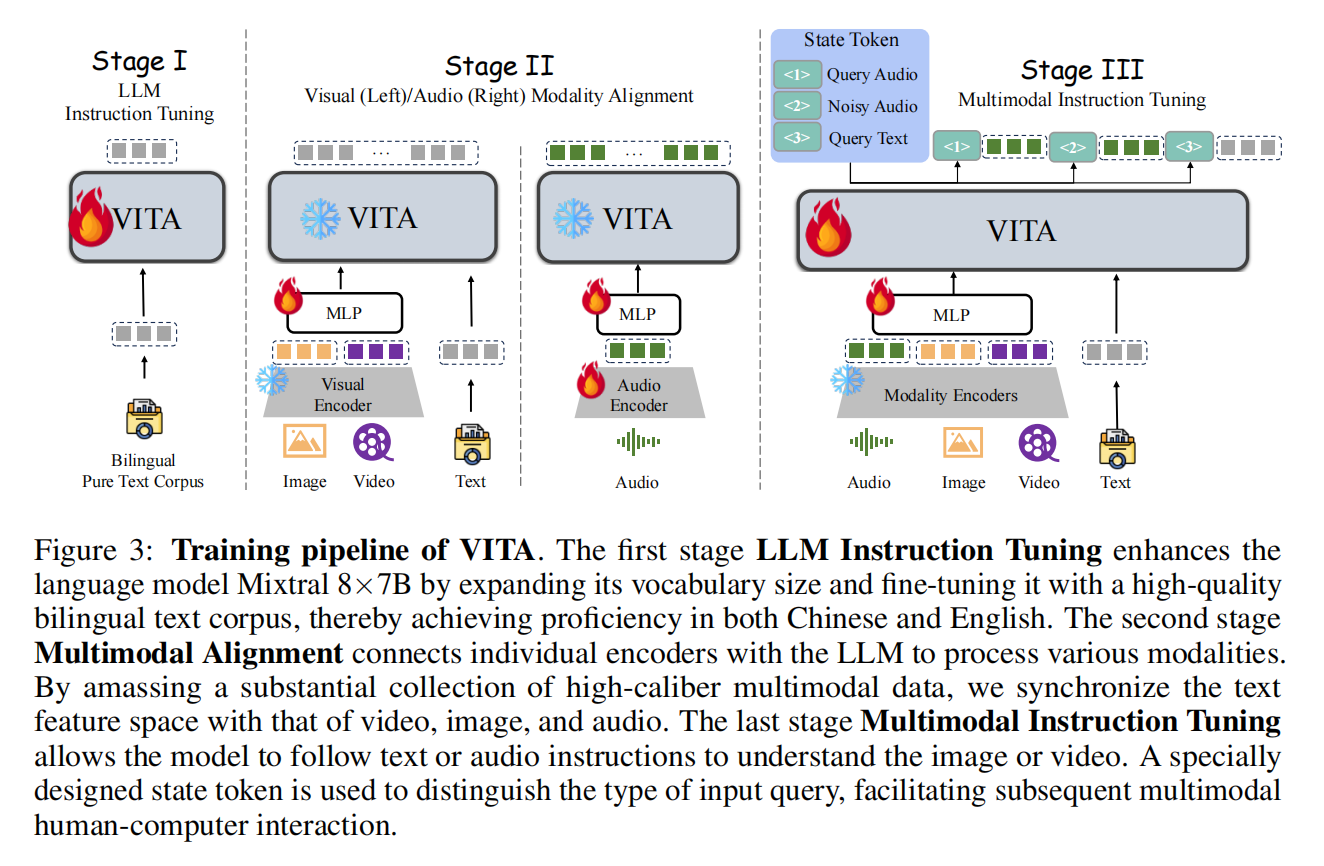
6.VITA:文本,图像,视频,音频
论文标题:VITA: Towards Open-Source Interactive Omni Multimodal LLM
来源:Arxiv2024/腾讯
开源地址:https://github.com/VITA-MLLM/VITA
注:参考了博客 VITA : 首个开源支持自然人机交互的全能多模态大语言模型
编码 :图像使用 InternViT-300M-448px 编码。音频首先通过 Mel 频率滤波器块处理,该块将音频信号分解为 Mel 频率尺度上的各个频带,模拟人类对声音的非线性感知;之后使用 4 层 CNN 下采样层和 24 层的Transformer,共计 341M 参数,处理输入特征;再采用简单的两层 MLP 作为音频-文本模态连接器,最终,每 2 秒的音频输入被编码为 25 个词元。
解码:生成文本。再根据需求用TTS转换为语音。
大家好,我是NLP研究者BrownSearch,如果你觉得本文对你有帮助的话,不妨点赞 或收藏 支持我的创作,您的正反馈是我持续更新的动力!如果想了解更多LLM/检索 的知识,记得关注我!