【写在前面】 飞腾开发者平台是基于飞腾自身强大的技术基础和开放能力,聚合行业内优秀资源而打造的。该平台覆盖了操作系统、算法、数据库、安全、平台工具、虚拟化、存储、网络、固件等多个前沿技术领域,包含了应用使能套件、软件仓库、软件支持、软件适配认证四大板块,旨在共享尖端技术,为开发者提供一个涵盖多领域的开发平台和工具套件。 点击这里开始你的技术升级之旅吧
本文分享至飞腾开发者平台《飞腾平台Hbase2.4.9安装配置手册》
1 介绍
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。HBASE的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
2 环境要求
2.1 硬件要求
硬件要求如下表所示。
| 项目 | 说明 |
|---|---|
| CPU | FT-2000+/64服务器 |
| 网络 | 无要求 |
| 存储 | 无要求 |
| 内存 | 无要求 |
2.2 操作系统要求
操作系统要求如下表所示。
| 项目 | 说明 |
|---|---|
| CentOS | 8 |
| Kernel | 4.18.0-193.el8.aarch64 |
2.3 软件环境要求
软件环境要求如下表所示。
| 项目 | 说明 |
|---|---|
| JDK | 11.0.11 |
| Maven | 3.3.9 |
| Protpbuf | 2.6.1 |
| Hadoop | 3.2.2 |
3 安装与配置步骤
3.1 基本环境
因为HBase 是以 HDFS 作为底层存储文件系统的,所以Hadoop 是部署Hbase的基础。而JDK是 Hadoop 和 HBase 运行的环境,两者都采用 Java 语言实现,它们的守护进程都运行在JVM下,因此在安装Hbase前,确保系统中存在已经部署好的Hadoop以及JDK。明确Hadoop与JDK的版本与储存路径。本文使用的是Hadoop3.2.2和JDK11.0.11. 要部署的Hbase版本是2.4.9。
3.2 下载Hbase
1)下载Hbase安装包:
a)http://archive.apache.org/dist/hbase/2.4.9/ 官网
b)https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/2.4.9/ 清华镜像网站
注*:在下载Hbase安装包时,要选择编译好的,可以直接使用的压缩包,如下图所示:
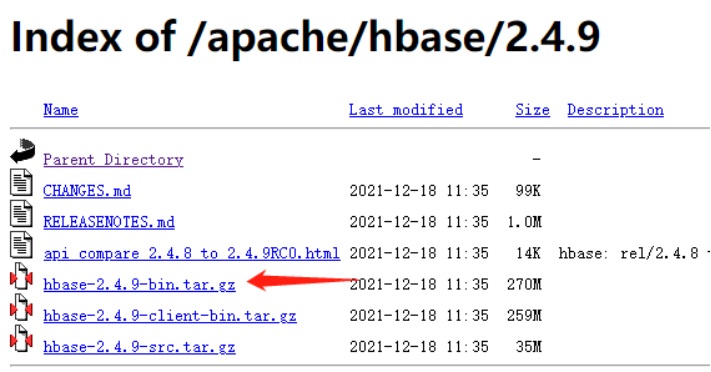
2)解压压缩包
>>tar -zxvf hbase-2.4.9-bin.tar.gz3)查看解压后的文件,并查看Hbase版本判断是否可用

>>bin/hbase version执行命令后,输出信息如下图所示:
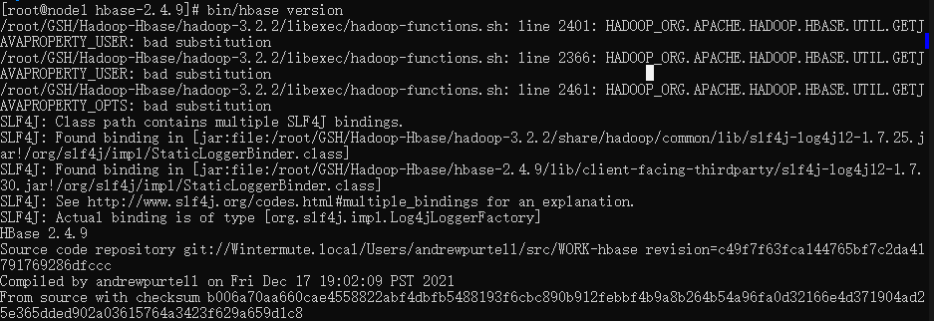
出现Hbase以及对应的版本号则说明已经安装成功。
3.3 添加Hbase权限
>> sudo chown -R XXX ./hbase注*:执行此命令的作用是将hbase下的所有文件的所有者改为XXX,XXX是当前用户的用户名(也有教程说是运行Hadoop的账户)。因此该命令存疑,在不清楚用户名的情况下可省略该步骤。
3.4 将Hbase添加至环境变量
编辑位于/etc目录下的profile文件
>> vim /etc/profile将以下代码追加至文件尾部
export HBASE_HOME=/GSH/Hadoop-Hbase/hbase-2.4.9
export PATH=\$PATH:\$HBASE_HOME/bin保存后,执行命令使上述代码生效:
>> source /etc/profile3.5 Hbase配置
3.5.1 单机模式配置
Hbase相关的配置文档存储在解压目录的conf文件夹下
1)编辑位于/root/GSH/Hadoop-Hbase/hbase-2.4.9/conf下的hbase-env.sh
>> vim hbase-env.sh配置jdk路径:
export JAVA_HOME=/opt/jdk-11.0.11配置HBASE_MANAGES_ZK为true,表示由hbase自己管理zookeeper:
export HBASE_MANAGERS_ZK=true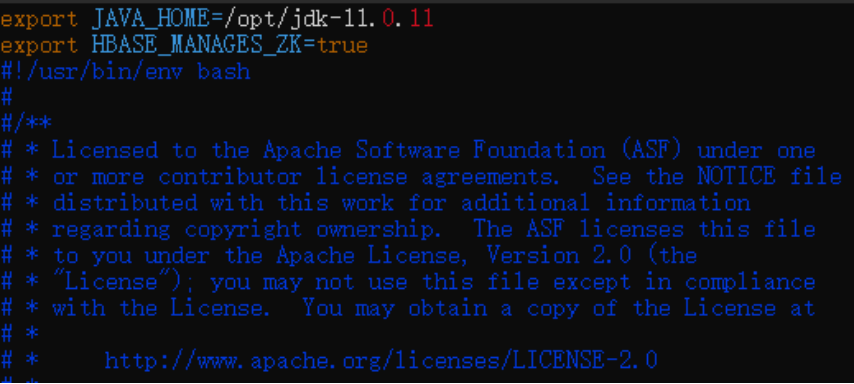
配置完成后保存并退出。
2)编辑位于/root/GSH/Hadoop-Hbase/hbase-2.4.9的hbase-site.xml:
>> vim hbase-site.xml将如下代码添加至hbase-site.xml文件中:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///root/GSH/Hadoop-Hbase/hbase-2.4.9/tmp</value>
</property>
</configuration>设置属性hbase.rootdir,用于指定HBase数据的存储位置,防止每次重启系统丢失数据。
保存并退出。
3.5.2 伪分布式模式配置
1)对/root/GSH/Hadoop-Hbase/hbase-2.4.9/conf下的hbase-env.sh内容更新:
>> vim hbase-env.sh配置HBASE_CLASSPATH:
export HBASE_CLASSPATH=/root/GSH/Hadoop-Hbase/hadoop3.2.2/conf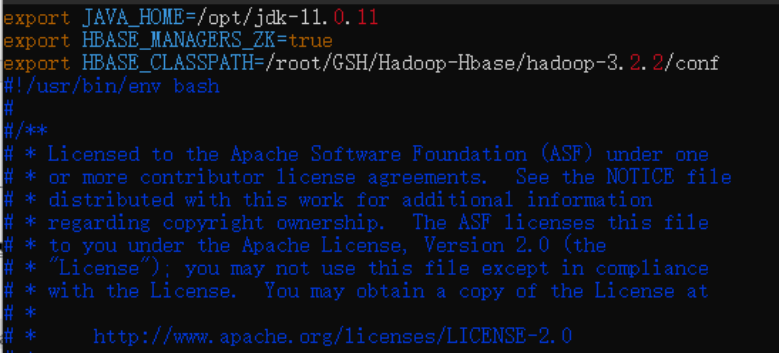
保存并退出。
2)对/root/GSH/Hadoop-Hbase/hbase-2.4.9/conf下的hbase-site.xml内容更新:
>> vim hbase-site.xml将<configuration>与</configuration>之间的内容修改成如下代码:
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
hbase.rootdir用于指定HBase的存储目录,hbase.cluster.distributed设置集群处于分布式模式,hbase.tmp.dir指定本地文件系统tmp目录。
4 启动Hbase
4.1 启动Hadoop
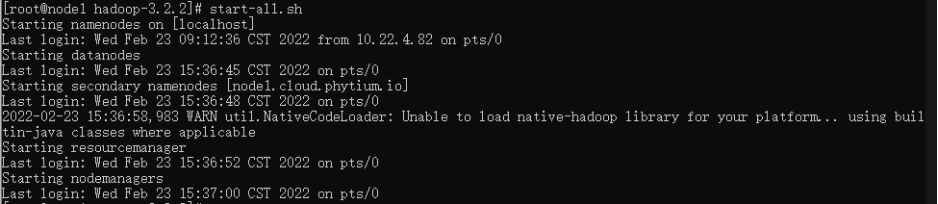
切换至/root/GSH/Hadoop-Hbase/hadoop-3.2.2目录下,启动Hadoop:
>> start-all.sh执行启动命令后,出现如下图所示输出信息说明启动成功
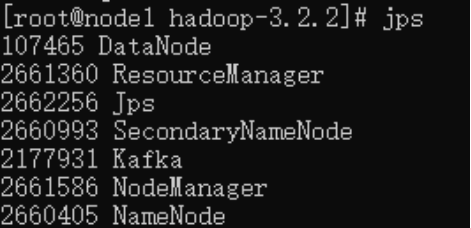
也可以使用jps命令查看是否启动成功:
>> jps出现NameNode, NodeManager等进程说明启动成功,如下图所示
4.2 启动Hbase
切换回到安装Hbase的目录:
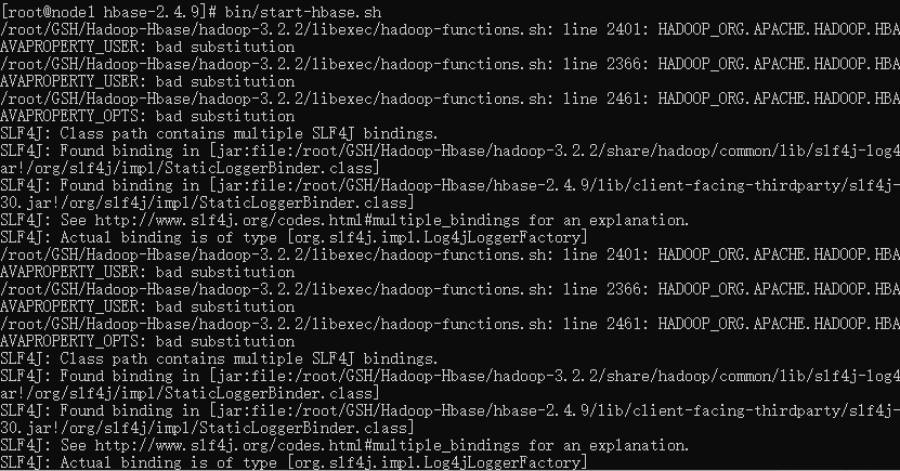
>> cd /root/GSH/Hadoop-Hbase/hbase-2.4.9启动Hbase:
>> bin/start-hbase.sh执行后的输出信息如下图所示:
输入命令jps:
>> jps看到如下界面说明Hbase启动成功:
4.3 关闭Hbase
关闭Hbase:
>> bin/stop-hbase.sh5 Hbase Shell基础命令
在命令行中输入hbase shell即可进入hbase shell命令行
1)创建表
create '表名' , '属性1' , '属性2'....
>> create 'student', 'name','grade','course'2)查看表结构
>> describe 'student'3)添加数据
HBase中用put命令添加数据,注:一次只能为一个表的一行数据的一个列,也就是一个单元格添加一个数据,
HBase的表中会有一个系统默认的属性作为行键,无需自行创建,默认为put命令操作中表名后第一个数据。
插入姓名为"GSH"的数据:
>> put 'student','1001','name','GSH'1001就是默认的行键,它对应了一个表中某一个独一无二的数据,可以理解为"学号","身份证号"等等。将GSH的"math"属性设置为90:
>> put 'student','1001','course:math','90'4)查看数据
a)Get
>> get 'student','1001'查看student表中1001号的数据
b)Scan
>> scan 'student查看student表中所有数据
5)删除数据
a)delete
>> delete 'student','1001','name'删除student表中1001行name列的数据
b)deleteall
>> deleteall 'student','95001'删除student表中的1001行的全部数据
6)删除表
需停止表的可用性,再删除表
>> disable 'student'
>> drop 'student'推荐阅读
欢迎广大开发者来飞腾开发者平台获取更多前沿技术文档及资料
如开发者在使用飞腾产品有任何问题可通过在线工单联系我们
版权所有。飞腾信息技术有限公司 2023。保留所有权利。
未经本公司同意,任何单位、公司或个人不得擅自复制,翻译,摘抄本文档内容的部分或全部,不得以任何方式或途径进行传播和宣传。
商标声明
Phytium和其他飞腾商标均为飞腾信息技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
本文档的内容视为飞腾的保密信息,您应当严格遵守保密任务;未经飞腾事先书面同意,您不得向任何第三方披露本文档内容或提供给任何第三方使用。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,飞腾在现有技术的基础上尽最大努力提供相应的介绍及操作指引,但飞腾在此明确声明对本文档内容的准确性、完整性、适用性、可靠性的等不作任何明示或暗示的保证。
本文档中所有内容,包括但不限于图片、架构设计、页面布局、文字描述,均由飞腾和/或其关联公司依法拥有其知识产权,包括但不限于商标权、专利权、著作权等。非经飞腾和/或其关联公司书面同意,任何人不得擅自使用、修改,复制上述内容。