论文地址:arxiv
摘要
为了解决视频理解中的局部冗余与全局依赖性的双重挑战。作者将 Mamba 模型应用于视频领域。所提出的 VideoMamba 克服了现有的 3D 卷积神经网络与视频 Transformer 的局限性。
经过广泛的评估提示了 VideoMamba 的能力:
- 在视觉领域有可扩展性,无需大规模数据集来预训练。
- 对于短期动作也有敏感性,即使是细微的动作差异也可以识别到
- 在长期视频理解方面有优越性,相比基于特征的模式,有显著的进步。
- 与其他的模态有兼容性,在多模态环境中表现出色。
正文
视频理解的核心在于掌握时空表征,这有两个问题:
- 短视频片段中的大量时空冗余
- 长语境中复杂的时空依赖关系
然而,CNNs 与 Transformer 的模型无法同时解决这两个问题。
由于 Mamba 存在选择性状态空间模型(SSM),使其在保持线性复杂度与促进长期动态建模之间取得了平衡。所以作者引入了 VideoMamba。它以原始 ViT 的风格和谐的融合了卷积和注意力的优势。提出了一种线性复杂度的方法来进行动态时空上下文建模,非常适合高分辨率长视频。
预备知识
状态空间模型(SSM)
状态空间模型基于连续系统构建,用于映射一维函数或序列,形式为
x ( t ) ∈ R L → y ( t ) ∈ R L x(t) \in \mathbb{R}^L \rightarrow y(t) \in \mathbb{R}^L x(t)∈RL→y(t)∈RL
通过隐藏的状态 h ( t ) ∈ R N h(t) \in R^N h(t)∈RN。形式上,SSM 使用以下常微分方程来建模输入数据:
h ′ ( t ) = A h ( t ) + B x ( t ) , y ( t ) = C h ( t ) , \begin{align*} h'(t) &= {\mathbf A}h(t) + {\mathbf B}x(t), \\ y(t) &= {\mathbf C}h(t), \end{align*} h′(t)y(t)=Ah(t)+Bx(t),=Ch(t),
其中, A ∈ R N ∗ N A \in R^{N*N} A∈RN∗N 表示系统的演化矩阵, B ∈ R B ∗ 1 B \in R^{B*1} B∈RB∗1, C ∈ R N ∗ 1 C \in R^{N*1} C∈RN∗1 是投影矩阵。这个连续的 ODE 通过离散化在现代 SSm 中进行近似。Mamba 是连续系统的离散版本之一,它包括一个时间尺度参数 Δ \Delta Δ,用于将连续参数 A , B A,B A,B 转换为离散对应物 A , B A,B A,B。这种转换通常采用零阶保持(ZOH)的方法,定义为:
A ‾ = exp ( Δ A ) , B ‾ = ( Δ A ) − 1 ( exp ( Δ A ) − I ) ⋅ Δ B , h t = A ‾ h t − 1 + B ‾ x t , y t = C h t . \begin{align*} \overline{{\mathbf A}} &= \exp({\mathbf \Delta \mathbf A}), \\ \overline{{\mathbf B}} &= ({\mathbf \Delta \mathbf A})^{-1} (\exp({\mathbf \Delta \mathbf A}) - {\mathbf I}) \cdot {\mathbf \Delta \mathbf B}, \\ h_t &= \overline{{\mathbf A}} h_{t-1} + \overline{{\mathbf B}} x_t, \\ y_t &= {\mathbf C}h_t. \end{align*} ABhtyt=exp(ΔA),=(ΔA)−1(exp(ΔA)−I)⋅ΔB,=Aht−1+Bxt,=Cht.
Mamba 通过实施选择性机制(Selective Scan Mechanism,S6)作为其核心 SSM 运算符。在 S 6 中,参数 B ∈ R B ∗ L ∗ N B \in R^{B*L*N} B∈RB∗L∗N, C ∈ R B ∗ L ∗ N C\in R^{B*L*N} C∈RB∗L∗N 以及 Δ ∈ R B ∗ L ∗ D \Delta \in R^{B*L*D} Δ∈RB∗L∗D 直接从输入数据 x ∈ R B ∗ L ∗ D x \in R^{B*L*D} x∈RB∗L∗D 中导出,表明其具有内存的上下文敏感性与自适应权重调节能力。
以下左图是 Mamba 架构
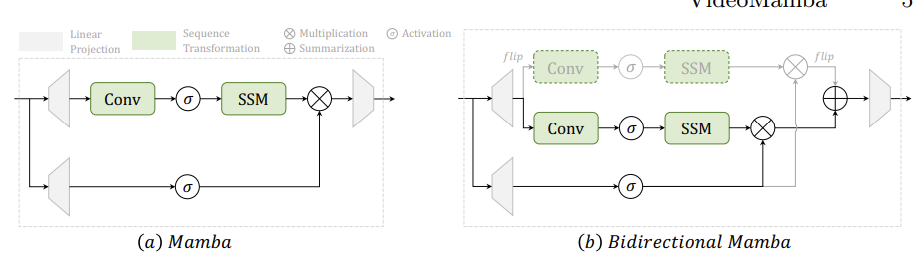
视觉的双向 SSM
原始的Mamba模块是为一维序列设计的,对于需要空间感知的视觉任务来说不够。基于此,Vision Mamba引入了图2b中的双向Mamba(B-Mamba)模块,它适应了专为视觉应用的双向序列建模。此模块通过同时的前向和后向SSM处理扁平化的视觉序列,增强了其空间感知处理能力。
在本文中,作者扩展了 B-Mamba 模块以理解三维视频。
模型架构
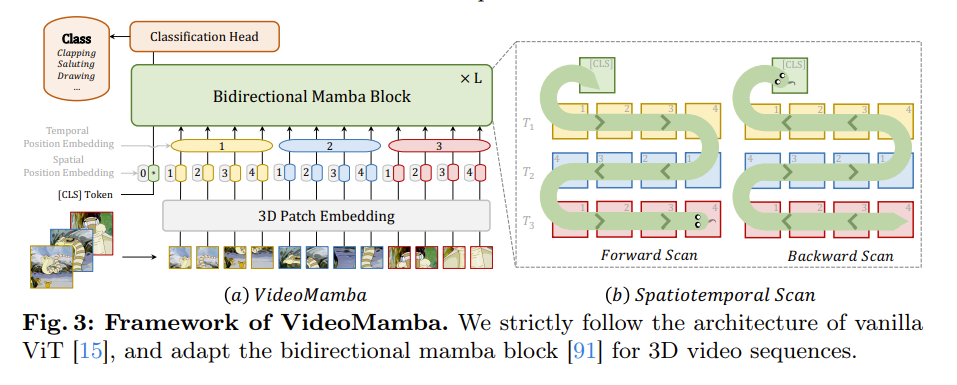
首先使用 3D 卷积(1*16*16 )将输入视频 X v ∈ R 3 ∗ T ∗ H ∗ W X^v \in R^{3*T*H*W} Xv∈R3∗T∗H∗W 投影到 L L L 个不重叠的时空补丁 X p ∈ R L ∗ C X^p\in R^{L*C} Xp∈RL∗C 中,其中 L = t ∗ h ∗ w ( t = T , h = H 16 , w = W 16 ) L = t*h*w(t = T,h = \frac{H}{16}, w = \frac{W}{16}) L=t∗h∗w(t=T,h=16H,w=16W)。输入到后续 videoMamba 编码顺路的标记序列为:
X = X c l s , X + p s + p t X = \left \\mathbf{X}_{cls}, \\mathbf{X} \\right + \mathbf{p}{s} + \mathbf{p}{t} X=Xcls,X+ps+pt
X c l s X_{cls} Xcls 是一个可学习的分类标记,预置在序列的开头。 p s ∈ R ( h w + 1 ) ∗ C p_s \in R^{(hw+1)*C} ps∈R(hw+1)∗C 是一个可学习的空间位置嵌入, p t ∈ R t ∗ C p_t \in R^{t*C} pt∈Rt∗C 是一个可学习的时间嵌入。这两个用于保留时空位置信息(SSM 建模对标记位置敏感)。之后,token X X X 通过 L L L 个堆叠的 B-Mamba 模块传递,最终层的 [cls] token 表示通过归一化和线性层进行分类处理。
时空扫描
为了将 B-Mamba 层应用于时空输入,将原始的 2D 扫描扩展为不同的双向 3D 扫描:
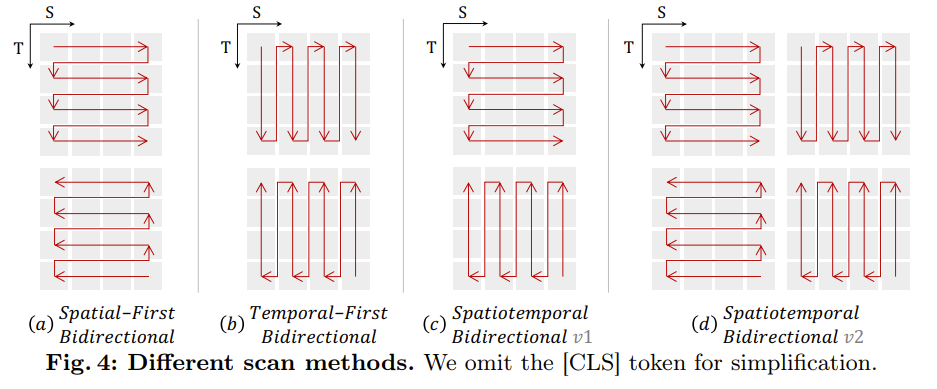
- (a)空间优先,按位置组织空间标记,然后逐帧堆叠
- (b)时间优先,基于帧排列时间标记,然后沿空间维度堆叠
- 时空,结合空间优先与时间优先
- (c):进行一半
- (d):进行全部(2 倍于 c 的计算)
经过消融实验表明,空间优先的双向扫描是最有效且简单的。
VideoMamba 是基于 Vim 构建的,通过省略中间 [cls] token 和旋转位置嵌入等特性简化了其架构,在 ImageNet-1 k 上有出色的表现。VideoMamba 严格遵循 ViT 设计,无下采样层。为了解决过拟合的问题,引入了一种有效的自蒸馏技术。
VideoMamba 比传统的基于注意力的模型更高效,同时也可显著减少使用的 GPU 内存。以下是两者的对比。
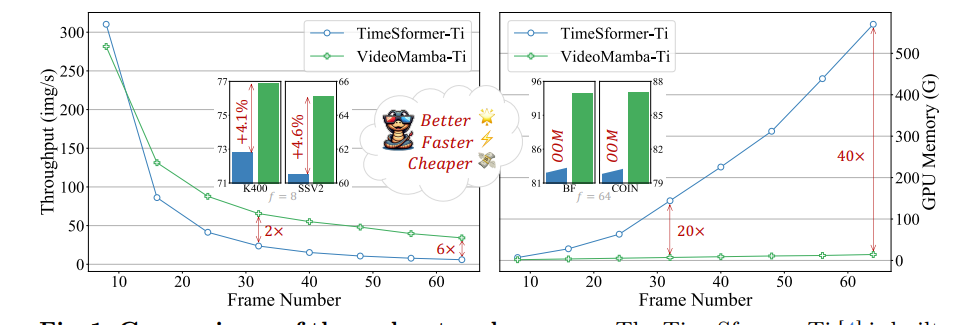
左图为图片处理速度,右图为 gpu 内存占用情况。
模型的超参数
使用 Mamba 中的默认超参数,将状态维度与扩展比设置为 16 与 2。而不同的深度与嵌入维度对应着不同规模的模型,以下是参数:
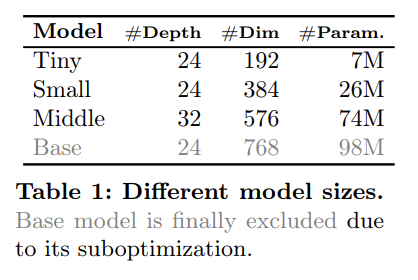
较大的模型会出现过拟合的现象,导致性能不佳,如下图 a 所示:
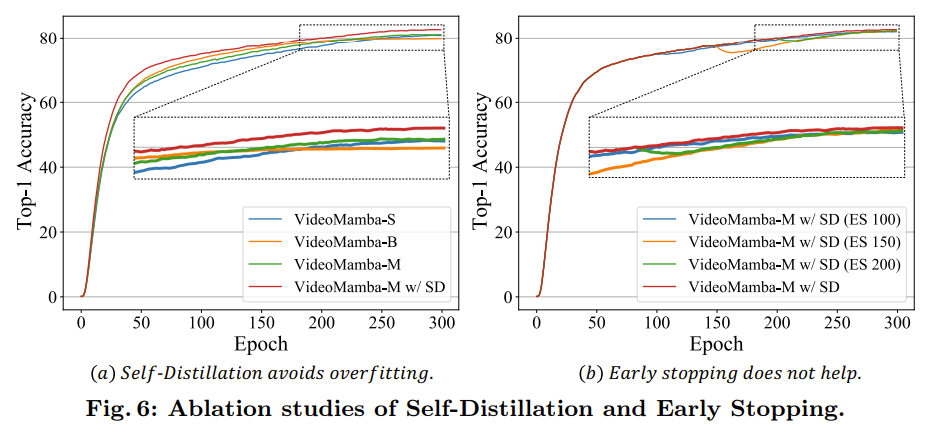
为了抵消较大 Mamba 模型中的过拟合,引入了一种有效的自蒸馏策略,使用一个较小且训练良好的模型作为教师,指导大的学生模型训练,结果如图 a 所示。
掩码建模
为了增强时间敏感性并验证其与文本模态的适应性,作者采用了一种受 UMT 启发的掩码对齐方法。
首先,VideoMamba 在仅视频数据上从头开始训练,将未掩盖的标记与来自 CLIP-ViT 的标记进行对齐。随后,它与文本编码器和跨模态解码器集成,以在图像-文本和视频-文本数据集上进行预训练。由于 VideoMamba 的独特架构(SSM 与 Transformer),我们仅对最终输出进行对齐。
以下是提出的不同的行掩码技术。从而来满足 B-Mamba 块对连续标记的偏好。
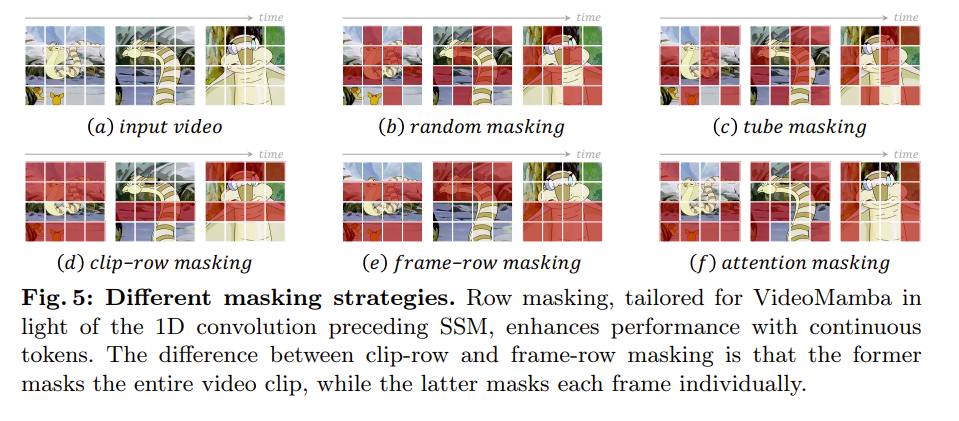
剪辑行掩码与帧行掩码的区别在于,前者掩盖整个视频剪辑,而后者则单独掩盖每一帧。
模型评估
自蒸馏效果
由上图 6 可知:
- 从头开始训练时,
VideoMamba-B更容易过拟合,表现不如VideoMamba-S,而VideoMamba-M则表现相似。 - 自蒸馏在实现所需优化方面表现出色,且仅需极少的额外计算成本。
为了减少教师的过度指导,作者在图 6 b 中尝试了早停法,但是没有有效的结果。
结果
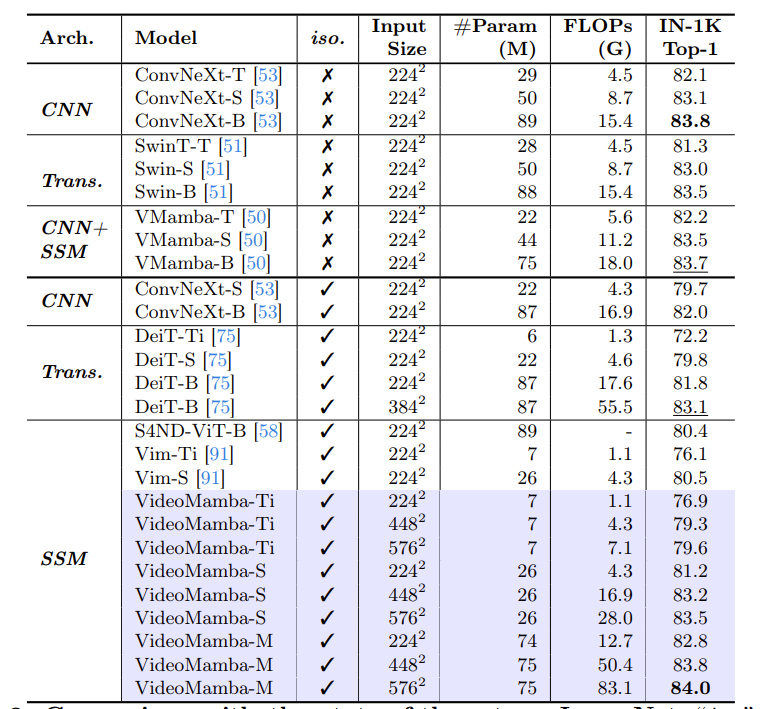
展示了在 ImageNet-1k 数据集上的结果。可以发现,VideoMamba-M 在使用更少的参数下,比其他同构架构有显著的优势。
同时,VideoMamba-M 在利用分层特征增强性能的非同构骨干网络中也表现出色。
短期视频理解
在场景相关数据集 Kinetics-400 与时间相关数据集 Something-Something V2 上评估了 VideoMamba,这两个数据集的视频平均长度分别为10秒和4秒。
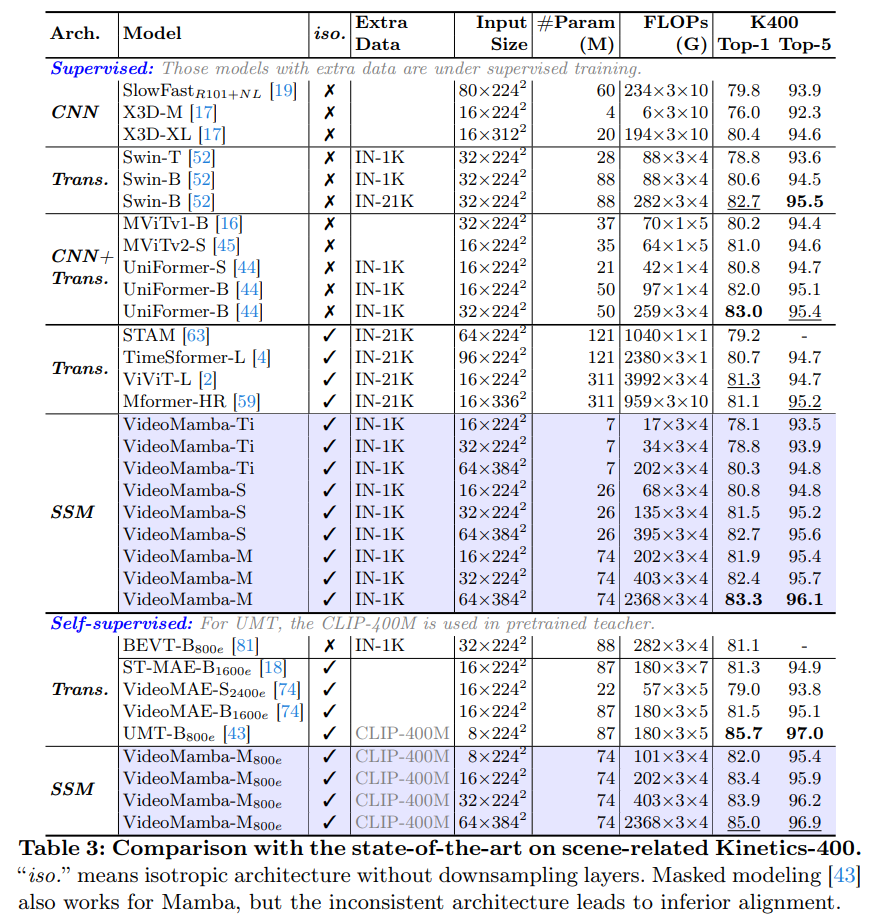
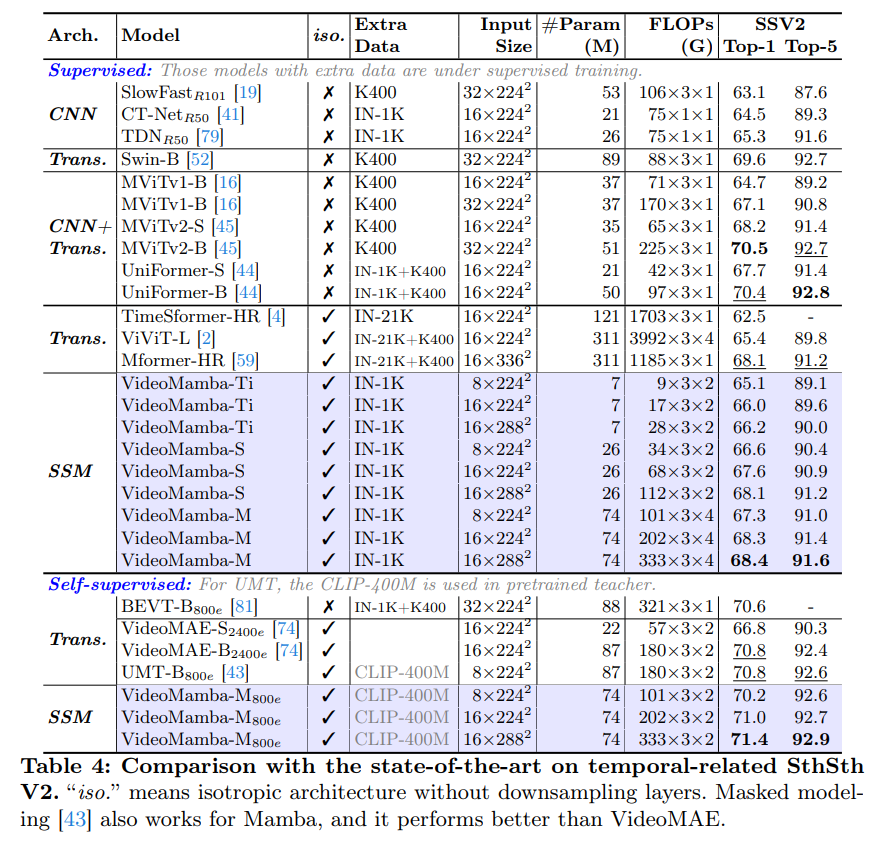
以上两表列出了在短期视频数据集上的结果。
- 监督学习:与纯注意力方法相比,
VideoMamba-M取得了显著的优势。在高准确率的同时有着显著减少的计算需求与较少的预训练数据。 - 自监督学习:在掩码预训练下,
VideoMamba超过了VideoMAE,突显了纯SSM模型在高效,有效理解短期视频方面的潜力。
消融研究

作者研究了各个方面
- 扫描类型:空间优先的方法最有效
- 帧与分辨率:更高的分辨率无法带来更好的性能,增加帧数在
K400数据集上有提升,但是在SthSthV2数据集上无提升。可能由于视频持续时间效短,无法有效容纳更长的输入 - 掩码预训练:行掩码与1D卷积特别兼容,优于常用的随机和管状掩码。剪辑行掩码因其较高的随机性而表现出色。注意力掩码通过优先保留相邻的有意义内容而成为最有效的方法。
长期视频的理解
使用了三个数据集:Breakfast 、COIN 和长视频理解(LVU)。
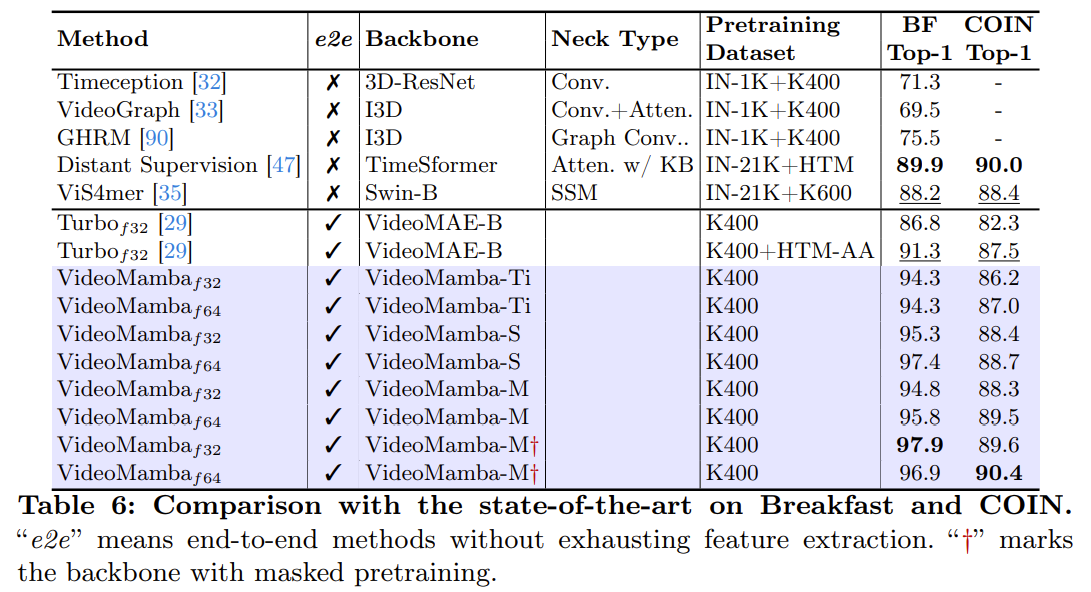
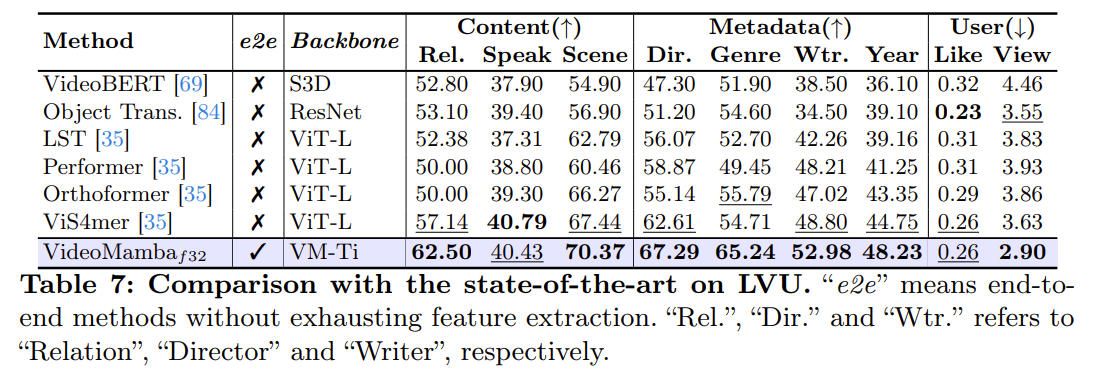
结果如上所示:即使在较小的模型规模下也能实现最先进(SOTA)的结果。
多模态视频理解
在五个主要基准上进行零样本视频-文本检索任务,包括 MSRVTT、DiDeMo、ActivityNet 、LSMDC 和 MSVD 。
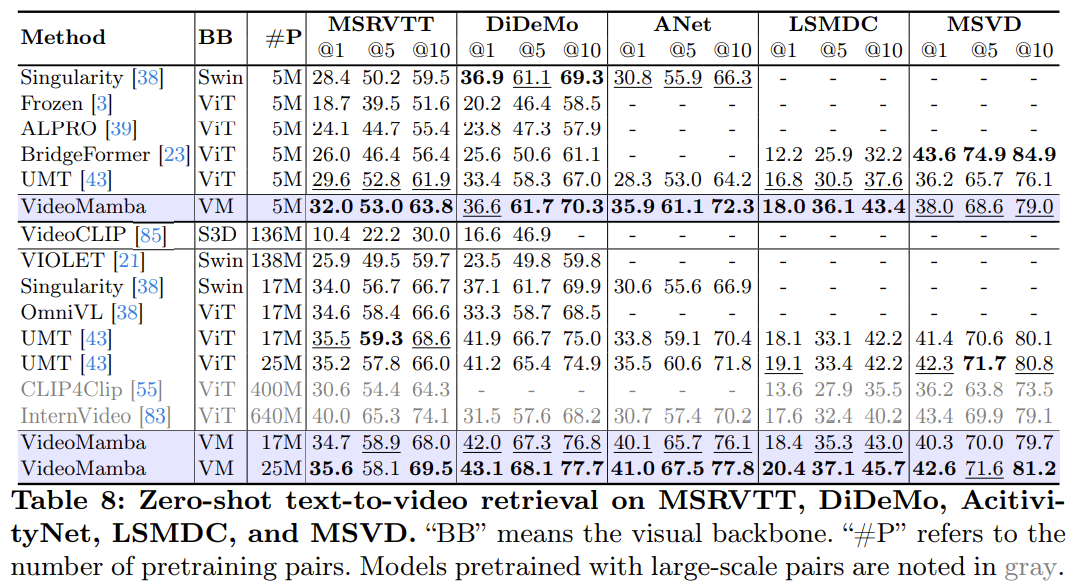
在相同的预训练语料库和相似的训练策略下,VideoMamba 在零样本视频检索性能上优于基于 ViT 的 UMT。这强调了 Mamba 在处理多模态视频任务时与 ViT 相当的效率和可扩展性。值得注意的是,对于包含较长视频长度(如 ANet 和 DiDeMo)和更复杂场景(如 LSMDC)的数据集,VideoMamba 表现出显著的改进。这表明 Mamba 即使在具有挑战性的多模态环境中,也能够满足跨模态对齐的需求。