Meta的Llama大型语言模型每次出新版本,都会是一大事件。前段时间他们不仅发布了3.1的一个超大型的405亿参数模型,还对之前的8亿和70亿参数的模型做了升级,让它们在MMLU测试中的表现更好了。
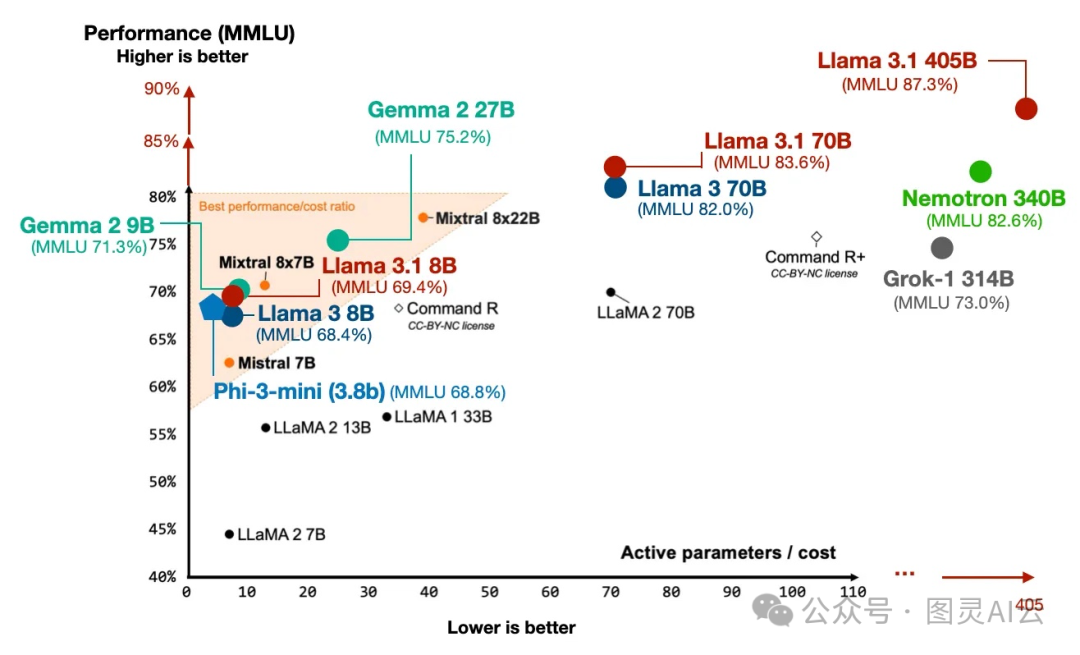
不同模型在MMLU基准测试中的表现
他们还出了一个92页的技术报告《Llama 3 Herd of Models》(https://arxiv.org/abs/2407.21783),里面详细介绍了这些模型。
说到Llama 3.1,它用了一个叫做群组查询注意力(group query attention)的技术,这和最近其他的大型语言模型挺像的。不过,Meta AI这次没有用滑动窗口注意力和专家混合方法,这还挺让人意外的。Llama 3.1看起来挺传统的,他们好像更注重预训练和后训练,而不是在模型架构上做创新。
和之前的Llama版本一样,这次的模型权重也是公开的。Meta还说,他们更新了Llama 3的许可协议,现在可以用它来生成合成数据或者做知识蒸馏,帮助改进其他模型了。
4.2 Llama 3.1 预训练
Llama 3.1的预训练过程真是下了大功夫。他们用了一个超级大的数据集,有15.6万亿个标记,比之前的Llama 2多了好多倍,Llama 2当时用的是1.8万亿个标记。而且,Llama 3.1至少能支持八种语言,虽然Qwen 2能处理的语言更多,有20种。
Llama 3.1还有一个亮点,就是它的词汇量达到了128,000,这是用OpenAI的tiktoken分词器搞出来的。
在保证预训练数据质量方面,Llama 3.1用了两种过滤方法:一种是启发式过滤,另一种是基于模型的过滤。他们还用了一些快速分类器,比如Meta AI的fastText和基于RoBERTa的分类器,这些工具也帮助他们决定在训练过程中用哪些数据。
Llama 3.1的预训练分成三个阶段。第一个阶段就是用那15.6万亿个标记做标准的初始预训练,上下文窗口大小是8k。第二个阶段继续预训练,但这次把上下文窗口扩大到128k。最后一个阶段是退火,就是为了让模型表现得更好。咱们再仔细看看这三个阶段都干了啥?
4.2.1 预训练 I: 标准(初始)预训练
在Llama 3.1的第一阶段预训练里,他们开始的时候用的是400万个标记的批次,每个批次的序列长度是4096。这相当于每个批次有1024个标记左右,如果400万是四舍五入的数字的话。训练了2.52亿个标记之后,他们把序列长度增加到了8192。在训练的更深层次,也就是处理了2.87万亿个标记之后,他们又一次把批次的大小翻了一倍。
而且,研究人员并没有一直用同样的数据混合来训练模型。他们根据模型的学习情况和性能,调整了训练过程中用的数据混合。这种灵活的数据处理方法,可能帮助模型更好地适应不同类型的数据,提高它的泛化能力。
4.2.2 预训练 II: 继续预训练以延长上下文长度
在Llama 3.1的第二阶段预训练中,他们采取了一种渐进的方式来增加上下文长度,而不是像其他模型那样一次性增加。研究人员分六个阶段,逐步把上下文长度从8000个标记增加到128000个标记。这种逐步增加的方法可能有助于模型更平稳地适应更大的上下文环境。
这个过程中用到的训练数据量相当大,有8000亿个标记,大约占到了总数据集的5%。这样的训练量,对于模型理解和处理长文本信息的能力提升,肯定是大有帮助的。
4.2.3 预训练 III: 在高质量数据上进行退火
到了Llama 3.1预训练的第三阶段,研究人员选择了一种特别的方法:他们在一小部分但质量很高的数据上对模型进行了所谓的"退火"训练。这种训练方式被证明能够提升模型在基准数据集上的表现。比如,在GSM8K和MATH这两个训练集上进行退火后,模型在相应的验证集上的表现有了显著提升。
研究人员提到,用于退火的数据集大小大约是400亿个标记,这占到了总数据集的0.02%。这400亿个标记的数据集是用来评估数据质量的。他们又指出,实际上的退火训练是在更小的数据集上进行的,只有4000万个标记,这占到了退火数据集的0.1%。
这种在高质量小数据集上进行的退火训练,可能帮助模型在关键的性能指标上有所提升,同时也确保了模型不会在大量低质量数据上浪费时间。
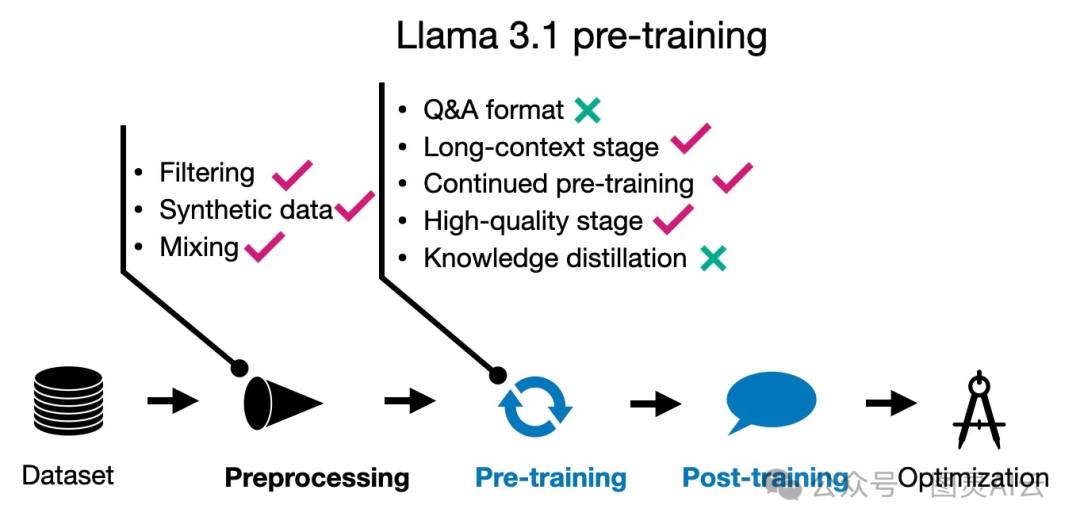
Llama 3.1预训练技术的总结
4.3 Llama 3.1 后训练
Llama 3.1的后训练过程,Meta AI团队采取了一种比较直接的方法,主要包括监督微调(SFT)、拒绝采样和直接偏好优化(DPO)这几个步骤。
他们发现,跟其他一些技术比如强化学习算法RLHF相比,使用PPO(Proximal Policy Optimization)的方法不够稳定,也更难扩大规模。特别值得一提的是,SFT和DPO这两个步骤是多次迭代进行的,也就是说,他们会结合人工生成的数据和合成数据来不断优化模型。
在深入讨论更多细节之前,他们的工作流程图如下,可以帮助我们更直观地理解整个后训练过程是如何进行的。
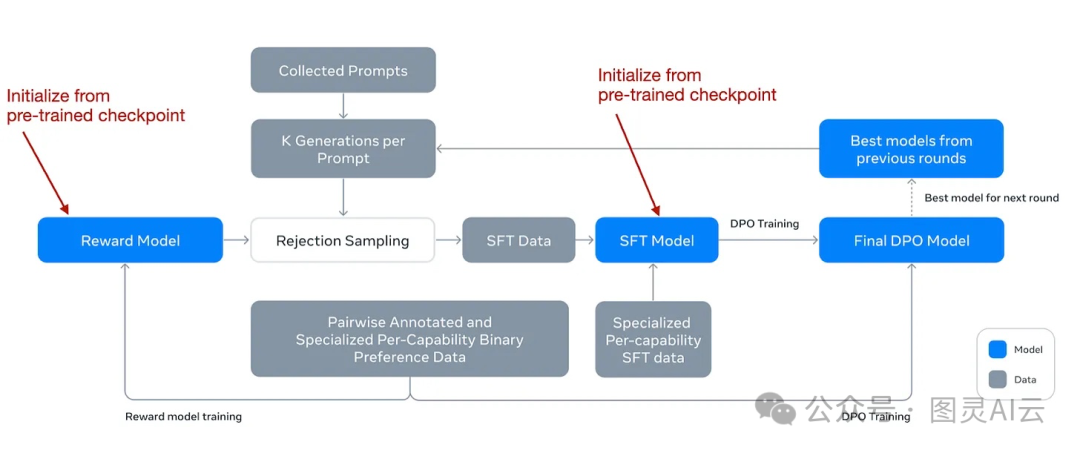
Llama 3.1论文中描述后训练过程的注释图
尽管他们采用了直接偏好优化(DPO),但他们还是像在RLHF(Reinforcement Learning from Human Feedback)中那样,开发了一个奖励模型。这个奖励模型的初始训练是基于预训练阶段的检查点,并且使用了人工标注的数据。想更多了解DPO,请查看《LLM 直接偏好优化(DPO)的一些研究》,想了解RLHF,请查看《您真的了解人类反馈强化学习(RLHF)吗?》
这个奖励模型在拒绝采样过程中发挥了作用,它帮助挑选出合适的提示来进行进一步的训练。在每一轮的训练中,他们不仅对奖励模型进行了更新,还对SFT(Supervised Fine-Tuning)和DPO模型进行了模型平均技术的应用。这种模型平均技术通过合并最近和以前的模型参数,有助于稳定并提升模型随时间的性能。
总的来说,他们的核心后训练流程包括了标准的SFT和DPO阶段,但这些阶段是多轮迭代进行的。他们还引入了奖励模型来进行拒绝采样,这与Qwen 2 《通义千问Qwen 2大模型的预训练和后训练范式解析》和AFM 《Apple LLM: 智能基础语言模型(AFM)》的做法相似。此外,他们还采用了模型平均技术,这不仅适用于奖励模型,还适用于所有参与训练的模型,这一点与Gemma的做法相仿。通过这样的方法,他们能够确保模型在训练过程中的稳定性和性能提升。
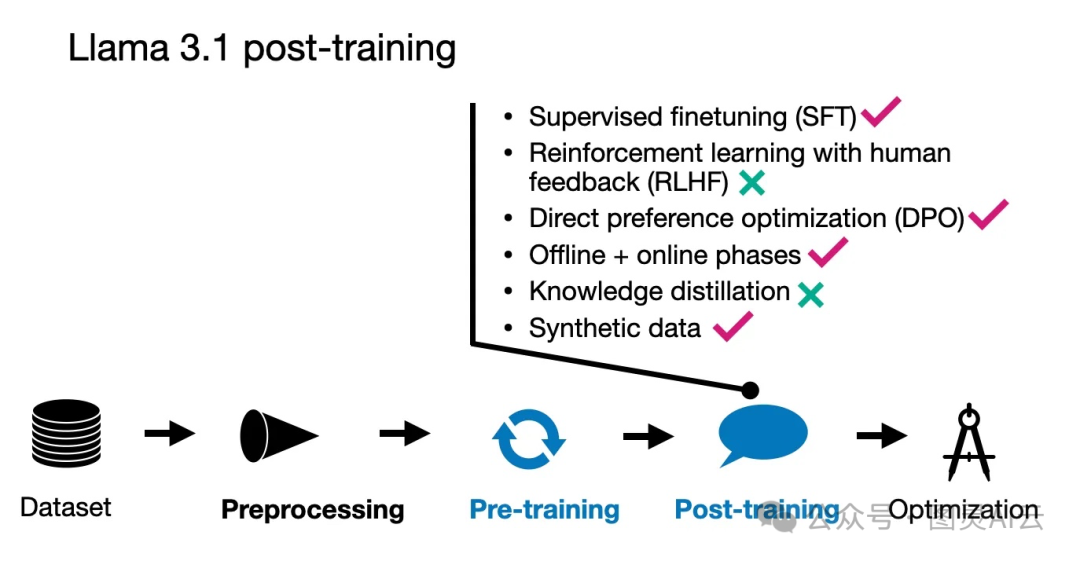
Llama 3.1后训练技术的总结
4.4 结论
Llama 3模型在很多方面都保持了一种比较传统的路线,跟之前的Llama 2模型相似,但也引入了一些新颖的方法。特别引人注目的是,它使用了高达15万亿个标记的庞大训练集,这让它在众多模型中脱颖而出。就像苹果的AFM模型一样,Llama 3也采取了一个三阶段的预训练流程。
与其他近期的大型语言模型(LLMs)不同,Llama 3并没有采用知识蒸馏技术,而是选择了一条更直接的模型开发路径。在后训练阶段,Llama 3采用了直接偏好优化(DPO),而不是其他模型中常见的更复杂的强化学习策略。总的来说,这种选择很有意思,因为它展示了通过更简单(但已经证明有效)的方法来提升大型语言模型性能的可能性。
