如今,由于其出色的理解、生成和操纵人类语言的能力,语言模型已经成为焦点。据最新调查数据显示,大概30%的企业计划使用非结构化数据来提高大型语言模型(LLM)的准确性。在训练这些语言模型时,一个基本挑战是找到复杂性和泛化之间的正确平衡。也就是说,训练这些模型的时候,得找到一个刚刚好的点,就是别太复杂也别太简单,这个平衡点挺难抓的。这个平衡点就是咱们常说的过拟合和欠拟合,这俩概念在训练模型的时候特别关键,能大大影响最后模型的表现。
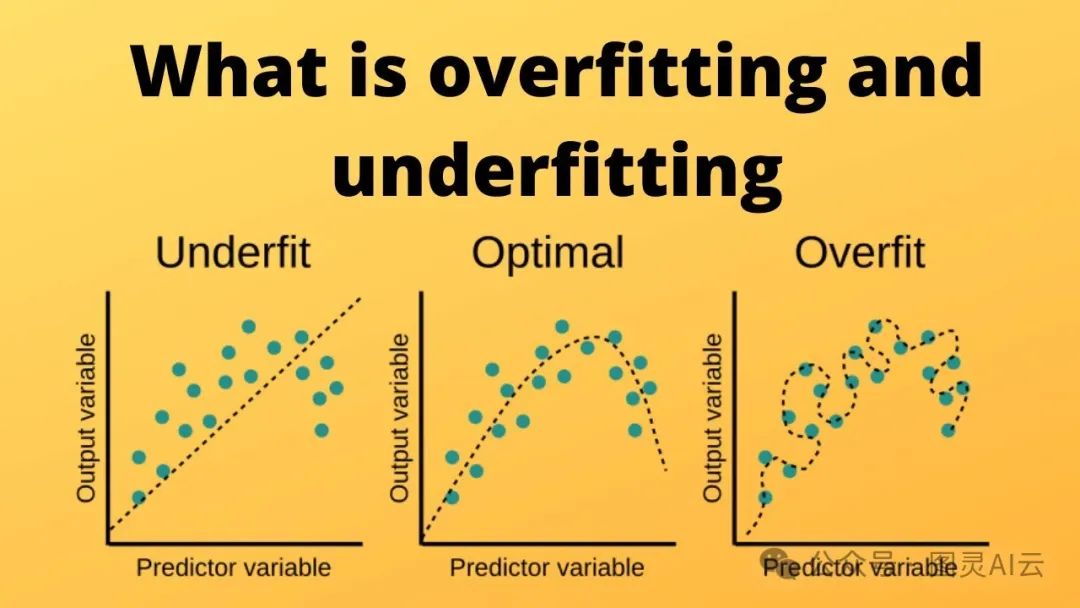
要让一个大型语言模型学会理解还能生成流畅的文本,这事儿挺有挑战的。咱们的目标是搞出一个模型,它不光在训练的时候表现好,碰到新的、没见过的数据也能照样给力。找到复杂和泛化的平衡点,就像跳一场需要很多技巧的舞蹈。还有两个东西在这里面也挺重要的:
-
偏差: 模型为使函数更容易学习而做出的假设。它实际上是训练数据的误差率。当误差率很高时,我们称之为高偏差;当误差率很低时,我们称之为低偏差。
-
方差: 训练数据和测试数据的误差率之间的差异称为方差。如果差异很大,则称为高方差;当误差差异很小的时候,则称为低方差。通常,我们希望降低方差以泛化我们的模型。
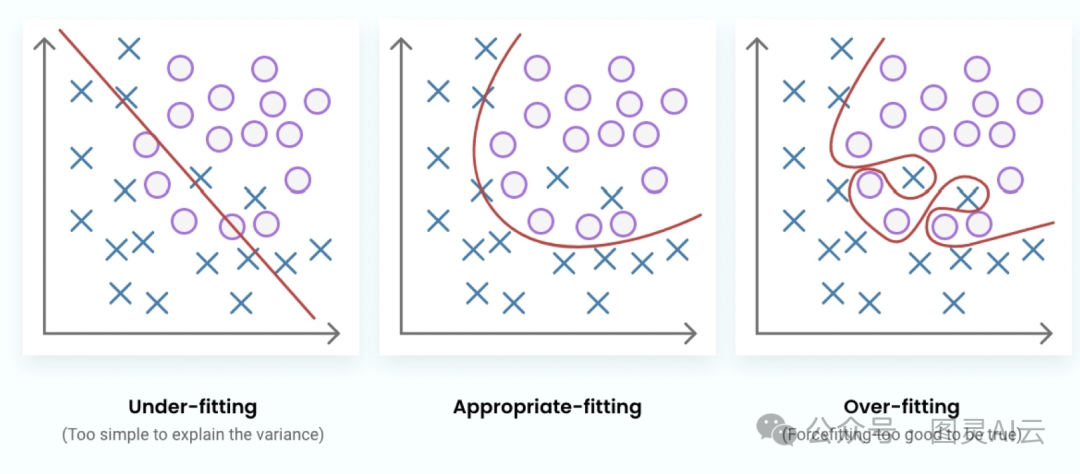
当一个模型学得太复杂了,开始死记硬背训练数据而不是真正理解背后的规律,这就叫做过拟合。这样的模型在训练数据上表现得特别好,但是一遇到新的没见过的数据就懵了。简单来说,就是模型对训练数据学得太死了,导致它没法把学到的东西用到新情况上,也就是所谓的泛化能力弱。
这就好比一个学生,他把课本上的答案都背下来了,但其实并不理解那些概念。在机器学习里,过拟合的模型就是对训练数据学得太细、太具体了,而没有掌握更普遍的规律。
比如说,有个语言模型的任务是生成电影评论。训练的时候,模型可能不小心就把训练数据里的特定短语、角色或者情节细节都学进去了。这样生成的评论可能看起来很真实,因为它模仿了训练数据的风格,但一旦遇到新的电影情节,它就不知道怎么写了。
要发现过拟合,我们可以观察模型在验证数据集上的表现,这个数据集是模型在训练时没见过的。如果发现模型在验证数据上的表现开始变差,但训练数据上的表现还是很好,那就说明模型可能开始过拟合了。这时候,模型把新数据套用到旧知识上的能力就变差了。
过拟合的原因可能有:
-
方差太高,偏差太低
-
模型太复杂了
-
训练数据不够多
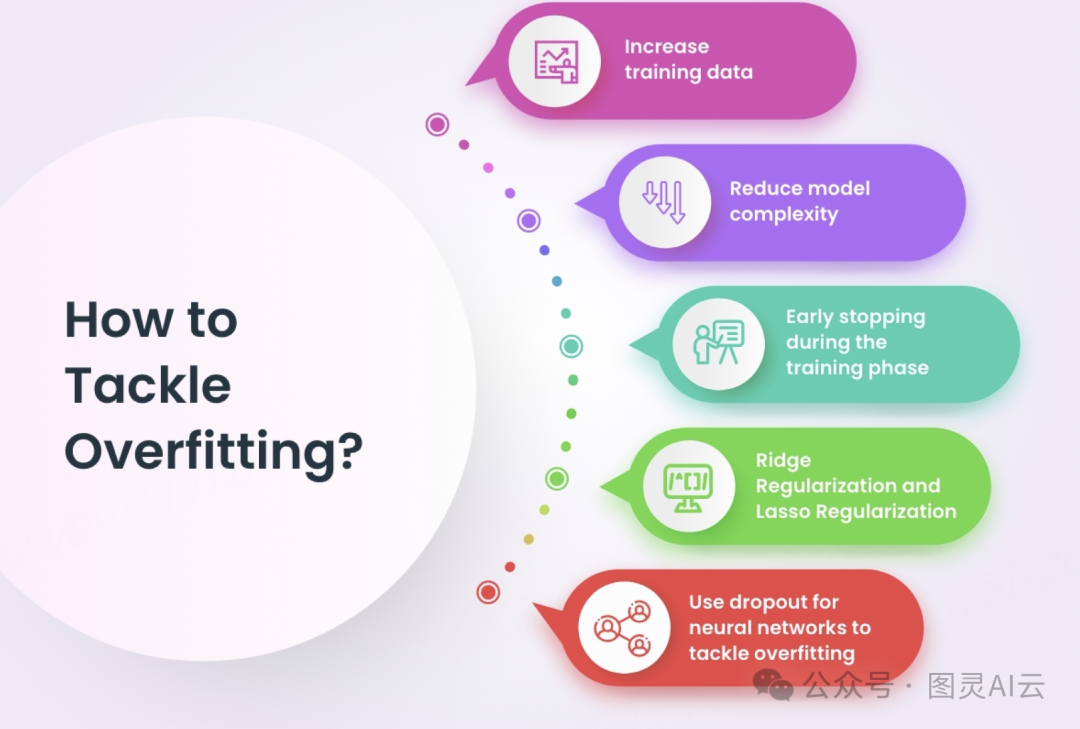
要解决过拟合,我们可以试试这些方法:
-
增加更多的训练数据
-
让模型简单一点
-
训练的时候早点停
-
用岭正则化或者套索正则化
-
对神经网络用dropout这个方法来避免过拟合
欠拟合呢,是模型太简单了,学不到训练数据里的复杂性。这样的模型连基本的规律都抓不住,不管是训练数据还是新数据,表现都不好。这就像让一个没准备好的运动员去比赛,不管他多努力,因为缺乏必要的技能和训练,所以表现肯定好不了。在机器学习里,欠拟合的模型就是没法捕捉到训练数据里的那些细节和复杂性。
想象一下,如果一个语言模型没有学到家,它生成的电影评论可能就会很肤浅,没啥逻辑,也没啥真知灼见。读起来可能东一句西一句的,跟电影的剧情或角色几乎扯不上关系。这是因为模型太简单了,没能认出数据里各种元素之间复杂的联系。
要发现模型是不是欠拟合,也挺直接的:只要看它在训练和验证数据上的表现都不怎么样,就很明显了。这种情况下,模型连最基本的规律都抓不住,整体表现自然好不了。
欠拟合的原因一般有这些:
-
偏差太高,方差太低
-
模型太简单
-
训练数据不够
-
训练数据没清理干净,有噪声
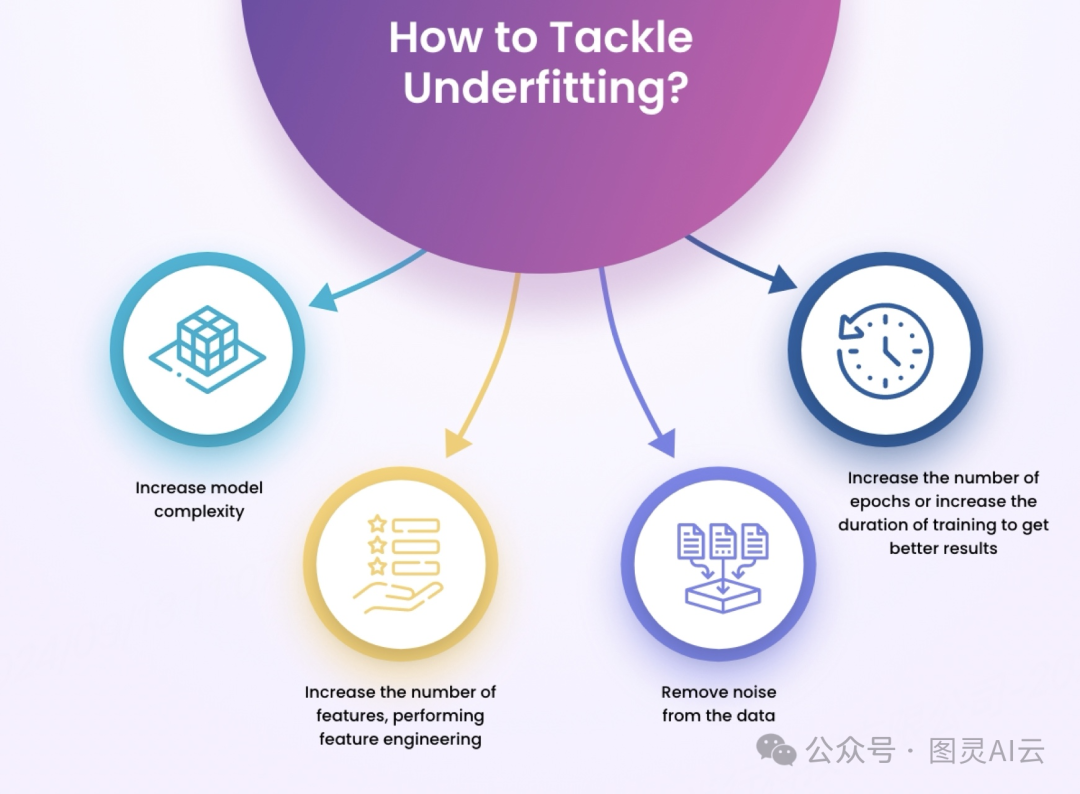
要解决欠拟合,可以试试以下几个方法:
-
让模型复杂一些
-
增加一些特征,做做特征工程
-
清理数据,把噪声去掉
-
增加训练的轮数或者延长训练时间,争取更好的结果
训练语言模型就像是在跳舞,得不断调整,找到那个动态的平衡点。要避免过拟合和欠拟合,就得仔细考虑,多做实验,不停地改进。
在训练的时候,要时刻关注模型在训练集和验证集上的表现。如果发现验证集上的表现开始下滑,但训练集上的表现还是挺好的,那就可能是过拟合的信号。这时候就得调整一下,控制一下过拟合的趋势。
咱们的最终目标是找到复杂性和泛化能力之间的黄金分割点。一个训练得当的语言模型能够流畅地生成既连贯又符合上下文的文本,不仅反映出训练数据的特点,还显示出对语言结构的深刻理解。
