工作经常要写离线数仓的SQL,由于历史项目很多是用Hive SQL写的,而在调试阶段,用Hive查询实在是太慢了。跟Impala查询对比起来,真是一个天一个地。于是有想把Hive SQL转化为Impala SQL的想法。
不过Impala SQL虽然大部分跟Hive是相同的,但有部分语法是有差异的。一个复杂Hive SQL,要手动来改太繁琐和费脑。试了一些大模型来自动改,效果并不是十分理想。于是有用扣子(coze.cn)增加知识库来解决问题。
根据自己工作总结和用ChatGPT的总结,第一个版本的知识库如下:
Impala和hive语法不同
字符串分割
Hive: split
Impala: split_part
实例:
Hive: split('hello world', ' ')[1]
Impala: split_part('hello world', ' ', 2)
当前日期
Hive: current_timestamp()
Impala: now()
实例:
Hive: SELECT current_timestamp();
Impala: SELECT now();
数组大小函数
Hive: 使用 size() 函数来获取数组或映射的大小
Impala: 使用 array_length() 函数来获取数组的大小
实例:
Hive:
SELECT size(array(1, 2, 3));
Impala:
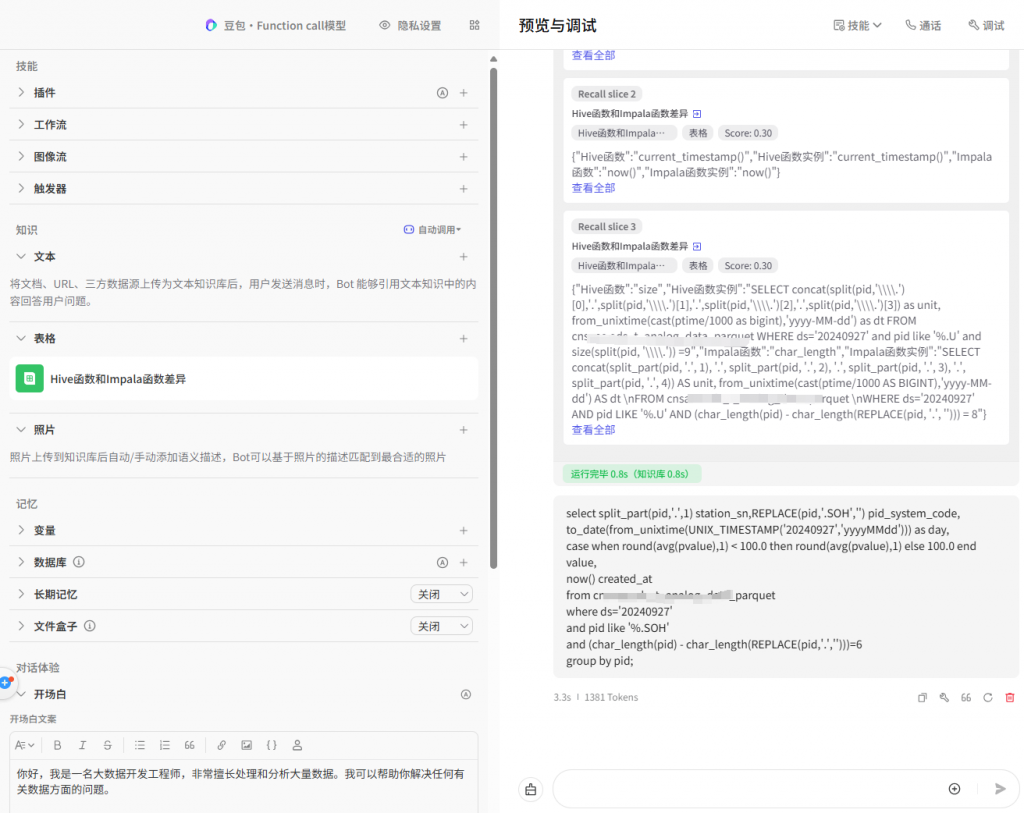
SELECT array_length([1, 2, 3]);把这一份word文档上传到扣子知识库后,发现调用hive 的split函数后要求转化为impala,扣子提示知识库无召回。
记得之前网友说excel文档效果更好。把这个word文档修改为excel文档。

由于自己是用sql,如果用语义搜索觉得效果并不是很好,把搜索策略修改为混合,最小匹配度进行调低。
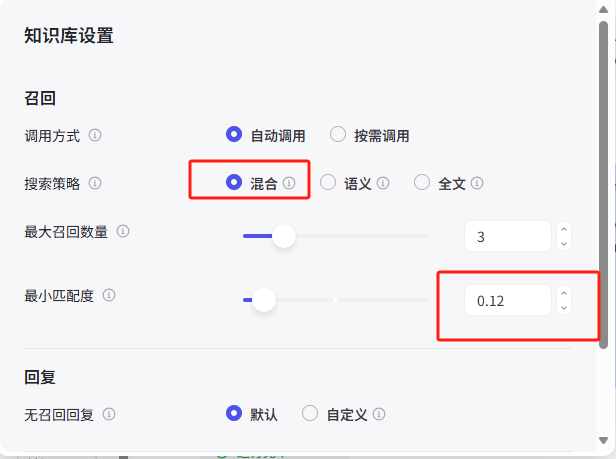
修改后果然匹配到知识库返回了,在自己知识库增强后,测了几个例子,回答的结果也从原来不正确的到现在的完全正确。以后工作可以不自己苦逼改sql,直接丢给扣子来自动完成了。