文章目录
- 一、构建docker镜像
- 二、从docker镜像构建容器
-
- [2.1 构建容器](#2.1 构建容器)
- [2.2 测试环境是否正常](#2.2 测试环境是否正常)
- 三、下载预训练权重文件
- 四、数据准备
-
- [4.1 下载数据集](#4.1 下载数据集)
- [4.2 建立文件夹的软连接](#4.2 建立文件夹的软连接)
- [4.3 生成数据信息](#4.3 生成数据信息)
-
- [4.3.1 调整包的版本](#4.3.1 调整包的版本)
- [4.4 准备Motion Anchors](#4.4 准备Motion Anchors)
- 五、训练评估
-
- [5.1 测试环境是否正常](#5.1 测试环境是否正常)
- [5.2 训练模型](#5.2 训练模型)
- [5.3 评估模型](#5.3 评估模型)
一、构建docker镜像
UniAD源码地址https://github.com/OpenDriveLab/UniAD,源码文件中docker文件下的Dockerfile提供了构建环境镜像的文件,我根据这一文件略微做了修改,以下是我使用的Dockerfile,亲测可以构建成功。
Dockerfile
FROM nvidia/cuda:11.1.1-cudnn8-devel-ubuntu20.04
ENV DEBIAN_FRONTEND=noninteractive
ENV TZ=Europe/Stockholm
ENV http_proxy ""
ENV https_proxy ""
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
ENV NVIDIA_DRIVER_CAPABILITIES ${NVIDIA_DRIVER_CAPABILITIES},compute,display
SHELL [ "/bin/bash", "--login", "-c" ]
# To fix GPG key error when running apt-get update
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/7fa2af80.pub
#install libs first
RUN apt-get update -q && \
apt-get install -q -y \
wget \
python3.8-dev \
python3-pip \
python3.8-tk \
git \
ninja-build \
ffmpeg libsm6 libxext6 libglib2.0-0 libsm6 libxrender-dev libxext6 \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# intall pytorch
ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0 7.5 8.0+PTX"
ENV TORCH_NVCC_FLAGS="-Xfatbin -compress-all"
ENV PATH=${PATH}:/usr/local/cuda:/usr/local/cuda/bin
RUN pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
RUN pip uninstall numpy scikit-image pandas matplotlib shapely setuptools urllib3 -y
RUN pip install numpy==1.20.0 scikit-image==0.19.3 pandas==1.4.4 matplotlib==3.6 shapely==1.8.5.post1 setuptools==59.5.0
RUN pip install scikit-learn pyquaternion cachetools descartes future tensorboard
RUN pip install IPython
# Install MMCV-series
ENV CUDA_HOME=/usr/local/cuda
ENV FORCE_CUDA="1"
RUN pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
RUN pip install mmdet==2.14.0
RUN pip install mmsegmentation==0.14.1
# Install mmdetection3d
RUN git clone --branch v0.17.1 --single-branch https://github.com/open-mmlab/mmdetection3d.git
WORKDIR /mmdetection3d
RUN pip install scipy==1.7.3 scikit-image==0.20.0
RUN pip install --no-cache-dir -v -e .
# Copy to python dist-package foldder
RUN cp -r /mmdetection3d/mmdet3d /usr/local/lib/python3.8/dist-packages
# Install UniAD from source
WORKDIR /
RUN git clone https://github.com/OpenDriveLab/UniAD.git
WORKDIR /UniAD
RUN pip install -r requirements.txt
# We need this old version of torchmetrics to run UniAD...
RUN pip install torchmetrics==0.8.2
# Link python to python3
RUN ln /usr/bin/python3 /usr/bin/python- 与Dockerfile文件同级,新建终端,执行以下命令,构建镜像
bash
docker build --network=host -t uniad:v1.0 .- 构建成功后如图所示

二、从docker镜像构建容器
2.1 构建容器
bash
docker run --name UniAD --gpus all -v /home/kemove/Downloads/data:/root/data -e NVIDIA_DRIVER_CAPABILITIES=all -v /etc/localtime:/etc/localtime:ro -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=unix$DISPLAY -e GDK_SCALE -e GDK_DPI_SCALE --network=host --privileged -v /dev/bus/usb:/dev/bus/usb -it uniad:v1.0 /bin/bash- 指令解析
docker run:Docker 命令,用于运行容器--name UniAD:给容器指定一个名字UniAD,便于管理和识别--gpus all:启用 GPU 支持,并将所有可用的 GPU 分配给容器,需要确保 Docker 已正确配置 NVIDIA 容器工具包-v /home/kemove/Downloads/data:/root/data:使用-v选项挂载卷,将主机上的/home/kemove/Downloads/data目录挂载到容器中的/root/data目录,这允许容器访问主机上的数据目录,这里把nuScenes数据集挂载进来-e NVIDIA_DRIVER_CAPABILITIES=all:设置环境变量NVIDIA_DRIVER_CAPABILITIES为all,启用所有的 GPU 功能(如图形加速、视频编码等),以确保容器可以使用 GPU 所有的能力-v /etc/localtime:/etc/localtime:ro:将主机的/etc/localtime挂载到容器的/etc/localtime,并以只读模式(ro),保证容器中的时间和主机系统一致-v /tmp/.X11-unix:/tmp/.X11-unix:挂载主机的 X11 Unix socket,使容器可以使用主机的图形显示系统。这在容器需要运行图形界面应用时非常有用-e DISPLAY=unix$DISPLAY:设置DISPLAY环境变量,指定容器使用主机的 X11 显示,使得容器内的 GUI 应用可以在主机上显示,unix$DISPLAY表示使用主机上的显示-e GDK_SCALE和-e GDK_DPI_SCALE:这些环境变量用于调整 GTK 应用的缩放比例和 DPI 设置,通常用于高分辨率显示器,如果设置了这些变量,容器中的 GTK 应用将按照指定的缩放比例显示--network=host:指定容器使用主机的网络堆栈,这意味着容器将与主机共享相同的网络接口和 IP 地址,适用于需要与主机紧密集成的网络应用--privileged:以"特权模式"运行容器,授予容器更多的权限,允许它访问主机上的所有设备(如 USB 设备、显卡等),特权模式通常用于需要直接操作硬件的容器-v /dev/bus/usb:/dev/bus/usb:挂载主机的 USB 设备目录/dev/bus/usb,允许容器访问主机的 USB 设备(如连接的相机、存储设备等)-it:-i表示保持标准输入打开,以便与容器交互;-t表示分配一个伪终端,使你可以在容器内使用命令行uniad:v1.0:要运行的 Docker 镜像的名称和版本号(uniad:v1.0)/bin/bash:容器启动后运行的命令,在这种情况下,启动一个 Bash shell,允许用户在容器内执行交互式命令
PS:配置 NVIDIA 容器工具包参考我的博客在docker中构建深度学习环境
nuScenes数据集下载参考我的博客BEVFormer复现(使用docker搭建训练环境)
2.2 测试环境是否正常
- 测试显卡是否能够正常调用
bash
nvidia-smi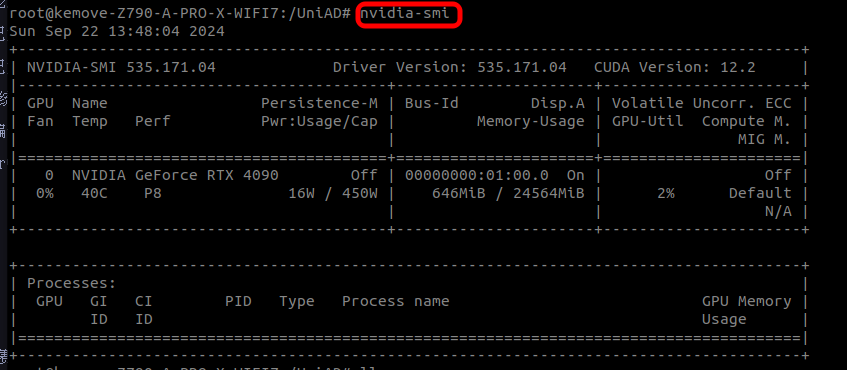
- 测试pytorch是否正常调用cuda等,依次输入以下指令,显示结果如图所示,说明环境基本正常
bash
python
python
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.backends.cudnn.version())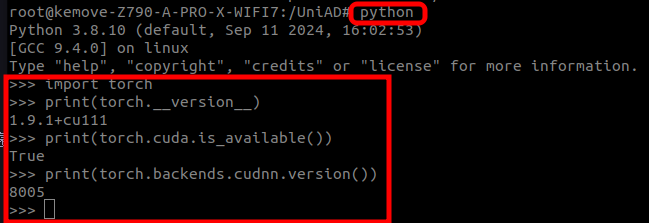
三、下载预训练权重文件
- 在Dockerfile文件中,已经下载UniAD的源码和依赖文件,因此不再需要下载源码,只需下载预训练的权重
bash
cd /UniAD
mkdir ckpts && cd ckpts
# Pretrained weights of bevformer
# Also the initial state of training stage1 model
wget https://github.com/zhiqi-li/storage/releases/download/v1.0/bevformer_r101_dcn_24ep.pth
# Pretrained weights of stage1 model (perception part of UniAD)
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0/uniad_base_track_map.pth
# Pretrained weights of stage2 model (fully functional UniAD)
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0.1/uniad_base_e2e.pth四、数据准备
4.1 下载数据集
可以在百度网盘下载我整理好的数据集,完整版和mini版均有
链接: https://pan.baidu.com/s/1as03f6dn5_5ZB7y37iBMBA 提取码: 398k
4.2 建立文件夹的软连接
- 从镜像构建容器时,已经将数据集挂载到了/root/data目录下,此处将数据集从/root/data软链接到/UniAD/data/即可
bash
ln -s /root/data/ /UniAD/data/4.3 生成数据信息
官方提供了两种方案
- 下载准备好的数据信息
bash
cd /UniAD/data
mkdir infos && cd infos
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0/nuscenes_infos_temporal_train.pkl # train_infos
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0/nuscenes_infos_temporal_val.pkl # val_infos- 自己生成数据信息
bash
cd /UniAD/data
mkdir infos
cd /UniAD
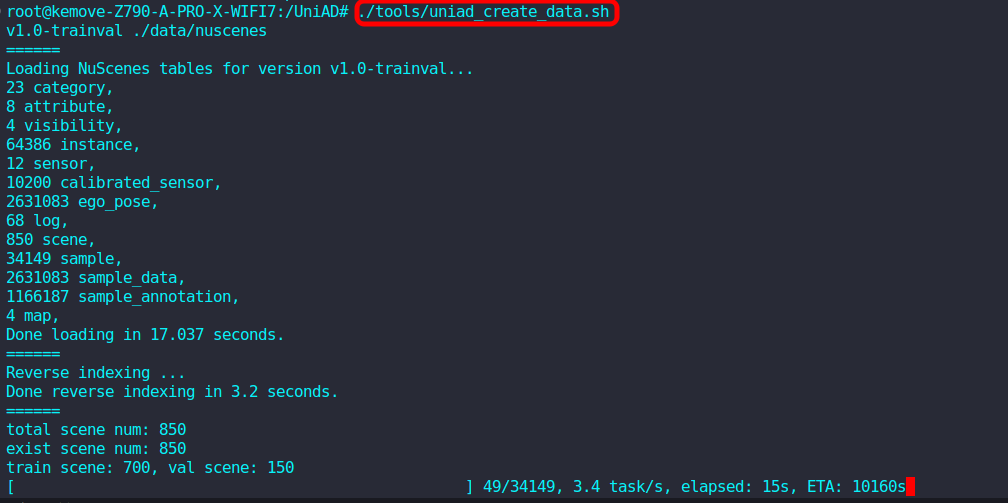
./tools/uniad_create_data.sh
# This will generate nuscenes_infos_temporal_{train,val}.pkl这里更推荐使用第二种方式,使用第二种方式可以检查以下程序能不能正常运行。
4.3.1 调整包的版本
这里果然会因为包的版本问题产生冲突,首先报错
bash
File "/usr/local/lib/python3.8/dist-packages/PIL/_typing.py", line 10, in <module>
NumpyArray = npt.NDArray[Any]
AttributeError: module 'numpy.typing' has no attribute 'NDArray'查询得知,这是因为numpy的版本过低,不支持NDArry,建议安装1.20.0版本以上,使用指令pip list | grep numpy查看numpy的版本发现当前numpy版本为1.20.0,因此使用以下指令更新numpy
bash
pip install --upgrade numpy更新完成后,包的依赖关系不满足,报了一堆版本依赖的错误,如图所示
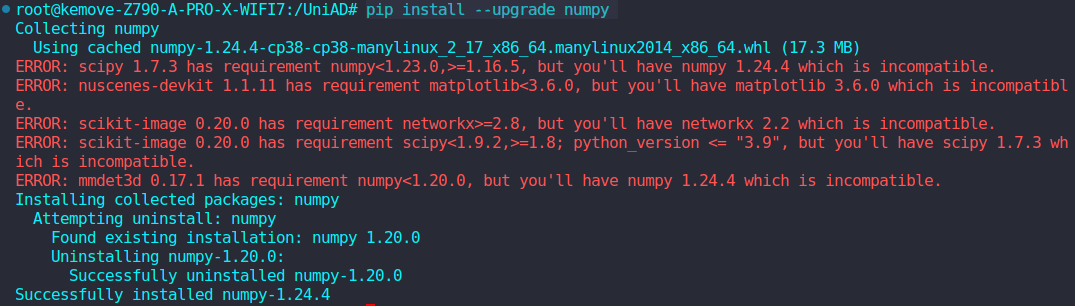
开始逐个解决,分析发现以下问题
- numpy更新完后版本过高
- matplotlib版本过高
- scikit-image版本过高
- nuscenes-devkit版本过高
bash
## 后来发现网上的信息是错误的,安装1.19.0版本的numpy完美解决NDArry报错的问题
pip install numpy==1.19.0
## matplotlib降版本
pip install matplotlib==3.5.3
## nuscenes-devkit降版本
pip install nuscenes-devkit==1.1.5
## scikit-image降版本
pip install scikit-image==0.19.3最后用以下指令检查,显示没有损坏的依赖关系,万事大吉
bash
pip check
重新执行以下指令生成pkl文件
bash
cd /UniAD
./tools/uniad_create_data.sh出现以下界面说明开始正常生成,数据集较大需要很久,这个时候就可以去遛个弯了
4.4 准备Motion Anchors
bash
cd /UniAD/data
mkdir others && cd others
wget https://github.com/OpenDriveLab/UniAD/releases/download/v1.0/motion_anchor_infos_mode6.pkl生成成功后,文件结构如下所示:
tree
UniAD
├── projects/
├── tools/
├── ckpts/
│ ├── bevformer_r101_dcn_24ep.pth
│ ├── uniad_base_track_map.pth
| ├── uniad_base_e2e.pth
├── data/
│ ├── nuscenes/
│ │ ├── can_bus/
│ │ ├── maps/
│ │ ├── samples/
│ │ ├── sweeps/
│ │ ├── v1.0-test/
│ │ ├── v1.0-trainval/
│ ├── infos/
│ │ ├── nuscenes_infos_temporal_train.pkl
│ │ ├── nuscenes_infos_temporal_val.pkl
│ ├── others/
│ │ ├── motion_anchor_infos_mode6.pkl五、训练评估
5.1 测试环境是否正常
bash
cd /UniAD
./tools/uniad_dist_eval.sh ./projects/configs/stage1_track_map/base_track_map.py ./ckpts/uniad_base_track_map.pth 1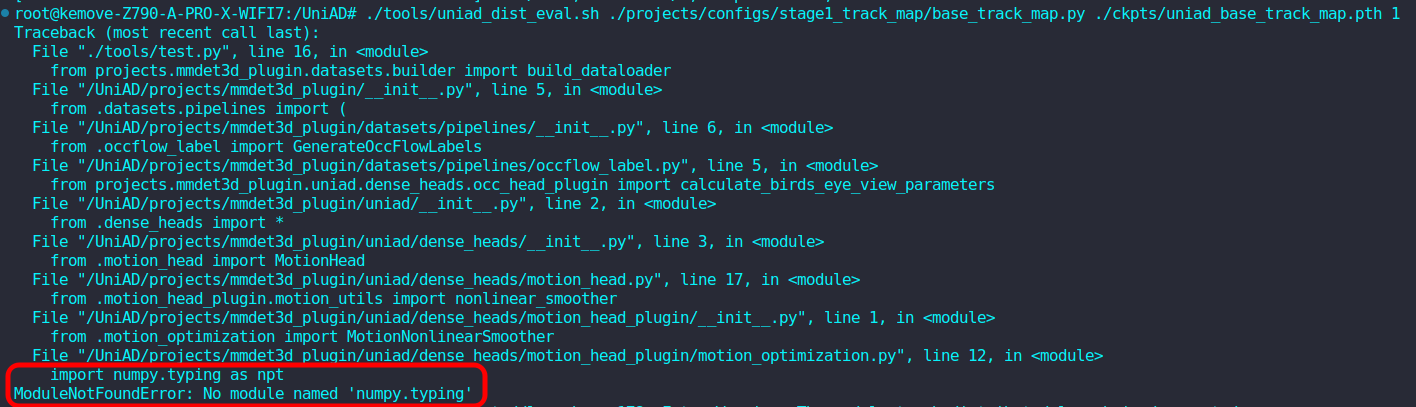
这里会报错说numpy库没有typing模块,总之感觉还是numpy库版本的问题,因此尝试安装不同版本的numpy,最后安装的numpy==1.21.0解决了问题
bash
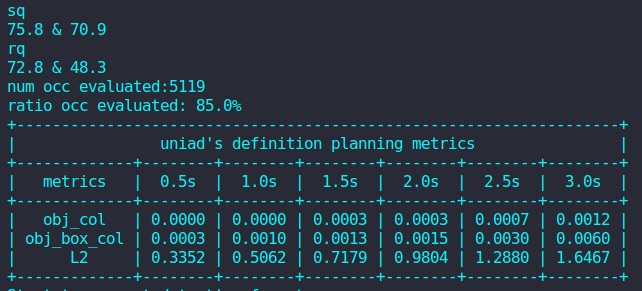
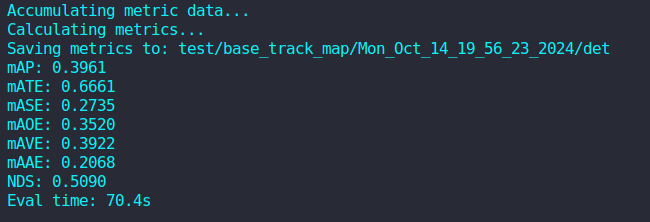
pip install numpy==1.21.0环境正常则输出结果如下:
5.2 训练模型
bash
./tools/uniad_dist_train.sh ./projects/configs/stage1_track_map/base_track_map.py 1果然,显存是不够的,报错如图

端到端果然不是一般实验室能玩得起的,这里可以尝试更改图片大小和缩小BEV网格的大小,尝试能不能训练起来,但训练效果肯定会大打折扣,这里就不实验了。
5.3 评估模型
4090推理还是可以的
bash
./tools/uniad_dist_eval.sh ./projects/configs/stage2_e2e/base_e2e.py ./ckpts/uniad_base_e2e.pth 1部分推理结果如图所示