介绍
本文概述了基础机器学习概念,并解释了机器学习在网络安全行业中日益增长的应用,以及主要优势、主要用例、常见误解和 CrowdStrike 的机器学习方法。
什么是机器学习?
机器学习 (ML) 是人工智能 (AI) 的一个子集,指的是教授算法从现有数据中学习模式以预测新数据答案的过程。
尽管术语 AI 和 ML 经常互换使用,但这两个概念之间存在重要差异。人工智能是指训练机器在现实世界环境中模仿或模拟人类智能过程的技术 ,而机器学习是指从数据中学习以做出预测的计算机系统("模型")。
从本质上讲,"学习"是指模型映射数学函数以转换基础数据以做出准确预测的过程。虽然计算机可以通过遵循显式编程或链式指令来执行简单、可预测的任务,但 ML 模型开发了一种解决问题的通用方法。
机器学习的 3 种类型
在本文中,我们将回顾三种常见的机器学习类别:
1. 监督学习
监督学习 发生在模型在标记输入和期望结果上进行训练时,其目的是教它在出现新的或不熟悉的数据时执行任务。在网络安全领域,监督学习的一个常见应用是在良性和恶意样本上训练模型,以教他们预测新样本是否是恶意的。
2. 无监督学习
当模型在未标记的数据上进行训练并找到数据中的结构、关系和模式(例如聚类或分组)时,就会发生无监督学习 。在网络安全中,这可用于在大型数据池中发现新的攻击模式或对手行为(例如,异常检测)。
3. 强化学习
当模型没有被赋予标记的输入或输出,而是通过反复试验来学习时,就会发生强化学习 ,旨在最大化累积奖励。这种形式的机器学习密切模仿人类学习的发生方式,对于识别解决问题的创造性和创新性方法特别有用。强化学习在网络安全中的一些应用包括网络物理系统解决方案、自主入侵检测和分布式拒绝服务 (DDOS) 攻击。
机器学习在网络安全中的优势
将机器学习应用于网络安全领域的问题有很多好处。这些包括:
**1. 快速合成大量数据:**分析师面临的最大挑战之一是需要快速合成在其攻击面上生成的情报,这些情报的生成速度通常比他们的团队手动处理的速度快得多。机器学习能够快速分析大量历史和动态情报,使团队能够近乎实时地操作来自各种来源的数据。
**2. 大规模激活专家情报:**定期训练周期使模型能够从不断变化的样本群体中不断学习,其中包括分析师标记的检测或分析师审查的警报。这可以防止反复出现误报,并使模型能够学习和执行专家生成的基本事实。
**3. 自动执行重复的手动任务:**将机器学习应用于特定任务可以帮助安全团队从平凡的重复性任务中解脱出来,充当力量倍增器,使他们能够扩展对传入警报的响应,并将时间和资源重新定向到复杂的战略项目上。
**4. 提高分析师效率:**机器学习可以通过实时、最新的情报增强分析师的洞察力,使威胁搜寻和安全运营中的分析师能够有效地确定资源的优先级,以解决其组织的关键漏洞并调查对时间敏感的 ML 警报检测。
机器学习在网络安全中的用例
机器学习在网络安全领域拥有广泛且不断增长的用例。我们可以将这些用例分为两大类:
- 自动威胁检测和响应
- 由机器学习辅助的分析师主导的运营
自主威胁检测和响应
在第一类中,机器学习使组织能够自动执行手动工作,尤其是在保持高精度和以机器级速度做出响应至关重要的流程中,例如自动威胁检测和响应,或对新的对手模式进行分类。
在这些场景中应用机器学习,通过一种通用方法增强了基于签名的威胁检测方法,该方法可以识别良性和恶意样本之间的差异,并可以快速检测新的野外威胁。
利用机器学习提高分析师效率
机器学习模型还可以通过提醒团队调查检测或提供优先漏洞进行修补来协助分析师主导的调查。在模型没有足够的数据来预测具有高度置信度的结果或调查恶意软件分类器可能未发出警报的良性行为的情况下,分析师评审可能特别有价值。
其他机器学习网络安全用例
以下是机器学习在网络安全领域的使用方式的常见示例列表(并非详尽无遗)。
| 用例 | 描述 |
|---|---|
| 漏洞管理 | 根据 IT 和安全团队的关键性提供建议的漏洞优先级 |
| 静态文件分析 | 通过根据文件的功能预测文件恶意性来启用威胁防御 |
| 行为分析 | 在运行时分析对手行为,以对整个网络杀伤链中的攻击模式进行建模和预测 |
| 静态和行为混合分析 | 组合静态文件分析和行为分析,以提供高级威胁检测 |
| 异常检测 | 识别数据中的异常情况,为风险评分提供信息并指导威胁调查 |
| 取证分析 | 运行反情报以分析攻击进展并识别系统漏洞 |
| 沙盒恶意软件分析 | 在隔离、安全的环境中分析代码示例,以识别恶意行为并对其进行分类,并将其映射到已知的对手 |
评估机器模型的功效
恶意软件分类器的模型功效:
机器学习在网络安全中最常见的应用之一是恶意软件分类。恶意软件分类器输出关于给定样本是否为恶意样本的评分预测;其中"评分"是指与结果分类相关的置信度。我们评估这些模型性能的一种方法是沿两个轴表示预测:准确性(结果是否正确分类;"true"或"false")和输出(模型分配给样本的类;"正面"或"负面")。
请注意,此框架中的术语"正面"和"负面"并不意味着样本分别是"良性"或"恶意"的。如果恶意软件分类器进行"阳性"检测,则表明该模型正在根据观察到已学会与已知恶意样本关联的特征来预测给定样本是恶意的。
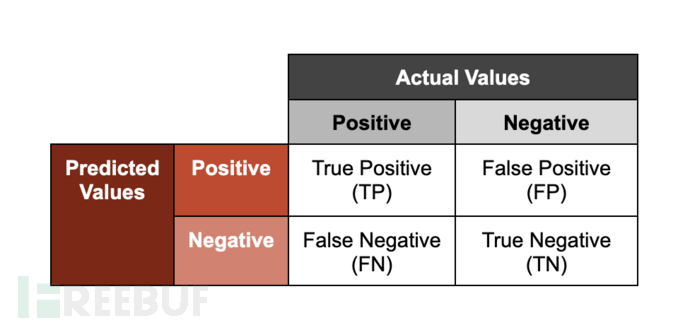
为了说明这些分组的含义,我们将使用经过训练来分析恶意文件的模型示例。
- **真阳性:**模型正确预测文件是恶意的
- **真阴性:**模型正确预测文件不是恶意的
- **误报:**模型错误地预测文件是恶意的(但事实并非如此)
- **漏报:**模型错误地预测文件不是恶意的(确实如此)
平衡真误报和误报
尽管真阳性对于威胁检测和响应至关重要,但误报也是衡量模型性能的重要指标。误报的机会成本与安全团队调查每次检测所花费的时间和资源相关,如果它们触发自动修正过程,阻止或中断对组织运营至关重要的应用程序,则误报的成本可能特别高。
在校准模型的攻击性或灵敏度时,数据科学家必须针对真阳性率和假阳性率进行优化,同时面临一个关键的权衡:降低真阳性的阈值(也就是说,模型将样本分类为"阳性"需要满足的要求)也存在降低误报阈值的风险(这可能导致分析师生产力下降并加剧警报疲劳)。我们将这种权衡称为检测效果。
构建高性能机器学习模型的最终目标是最大限度地提高检测效率:最大限度地提高真阳性检测率,同时最大限度地减少假阳性率。为了说明这种平衡的复杂性,请考虑恶意软件分类器的真阳性率等于或接近 99% 的情况并不少见,而误报率远低于 1%。
机器学习的挑战和限制
虽然机器学习模型可以成为强大的工具,但每个模型都在独特的限制下运行:
**充足的高质量数据:**训练高置信度模型通常需要访问大型数据集,以训练和测试机器学习模型。为了测试模型,通常从训练集中留出一部分数据来测试模型性能。此数据应与训练数据具有最小的特征重叠;例如,表示数据收集的不同时间跨度或来自不同数据源的数据。如果没有足够的高质量数据,则给定的问题空间可能不适合应用机器学习。
**真误报和假报之间的权衡:**如前所述,需要校准每个模型的灵敏度,以平衡真阳性和假阳性之间的检测阈值,以最大限度地提高检测效率。
**可解释性:**可解释性是指解释模型如何以及为什么执行的能力。这使数据科学团队能够了解样本中的哪些特征会影响模型的性能及其相对权重。可解释性对于推动问责制、建立信任、确保遵守数据策略以及最终实现机器学习的持续性能改进至关重要。
**重复性:**也称为可重复性,这是指机器学习实验一致再现的能力。可重复性提高了机器学习的使用方式、使用的模型类型、训练的数据以及运行的软件环境或版本的透明度。可重复性可最大限度地减少模型从测试到部署以及未来更新周期的歧义和潜在错误。
**目标环境优化:**每个模型都必须针对其目标生产环境进行优化。每个环境在计算资源、内存和连接性的可用性方面都会有所不同。随后,每个模型都应设计为在其部署环境中执行,而不会给目标主机的操作带来负担或中断。
**强化对抗性攻击:**机器学习模型有自己的攻击面,容易受到对手的攻击,攻击者可能会尝试利用或修改模型行为(例如导致模型对样本进行错误分类)。为了最大程度地减少模型的可利用攻击面,数据科学家在训练中"强化"模型,以确保强大的性能和抵御攻击的弹性。
2 关于机器学习的误解
误解#1。机器学习优于传统的分析或统计方法。
尽管机器学习可能是一种非常有效的工具,但它可能并不适合在每个问题空间中使用。其他分析或统计方法可能会产生高度准确和有效的结果,或者可能比机器学习方法占用更少的资源,并且更适合给定的问题空间。
误解#2。机器学习应该用于自动执行尽可能多的任务
机器学习可能非常耗费资源,通常需要访问大量数据、计算资源和专门的数据科学团队来构建、训练和维护模型。为了最大限度地提高维护模型的投资回报率,当目标问题价值高、经常重复、需要速度和准确性,并且有足够的高质量数据集进行持续训练和测试时,最好应用它。